

оп, дрёмбудка давно уже на 16 ГБ едет, если речь о полторашке. Вот сдохля - там да, 20 минимум, ЕМНИП.
> дрёмбудка давно уже на 16 ГБ едет, если речь о полторашке
А в прошлом ноябре-декабре спокойно крутилась на 12.
мимо
аноны кто пользуется готовой кохой на васт.ай, помогите подключить логи. инстанс походу тупо перетащили с рунпода, видимо есть некоторые отличия. лог по команде tail -f /workspace/logs/kohya_ss.log не работает. подключил setup.log из кохи , но он не выдаёт прогресс тренировки, только первые команды.
Чел, с такими тупыми вопросами не пищи сюда.
Ну вот кто будет копаться в левых васянских покакуньках? Возьми да запили свой контейнер, и засунь в него коху с нуля. Я лог вообще смотрю в консоли, например, а сессию держу открытой через tmux, так что могу подключаться и отключаться когда захочу.
Готовый контейнер нормально работает, заводится быстро. Можно и не пилить свой если кто-то уже сделал.


Какой же коха дегенерат, столько времени убил на казалось бы простые вещи, которые надо юзеру сразу говорить.
Во-первых, блядские bucket, за каким-то хуем коха всегда ресайзит неквадратные пики, а если отключаешь bucket - кропит до квадрата. Вот у меня есть пики 768х1024 в датасете, я ставлю разрешение обучения 768, а они даунскейлятся до 640р. Что ещё хуже - если я поставлю разрешение 1024, эта хуита их заапскейлит, алгоритмом nearest. Хорошо хоть можно прописать костыль --bucket_no_upscale и ёбнуть разрешение обучения побольше, чтоб эта пидорасина не трогала мои пики. Остаётся только догадываться сколько лор запорото этим говном.
Во-вторых, про тренировку конволюшенов. Где-то в кишках документации ликориса хотя бы пик2 есть, но ни слова почему - просто возьмите такой-то пресет, нет времени объяснять. Потратил кучу времени чтобы выяснить какие слои конволюшенов вызывают пережарку и распидорашивание - это ебучие конволюшены в двух крайних ResNet с обоих концов сетки, естественно у кохи они тренируются. Опять надо костылить и отключать их через список conv_block_dims. У ликориса, кста, крайние ResNet нельзя выключить, ты либо тренишь конволюшены, либо нет, заебись. Алсо, лоры и так не тренируют все 25 слоёв, не понятно почему в ликорисе придумали тренировать конволюшены, но не протестили какие лучше не надо трогать, как это было сделано изначально с ванильными лорами.
Во-первых, блядские bucket, за каким-то хуем коха всегда ресайзит неквадратные пики, а если отключаешь bucket - кропит до квадрата. Вот у меня есть пики 768х1024 в датасете, я ставлю разрешение обучения 768, а они даунскейлятся до 640р. Что ещё хуже - если я поставлю разрешение 1024, эта хуита их заапскейлит, алгоритмом nearest. Хорошо хоть можно прописать костыль --bucket_no_upscale и ёбнуть разрешение обучения побольше, чтоб эта пидорасина не трогала мои пики. Остаётся только догадываться сколько лор запорото этим говном.
Во-вторых, про тренировку конволюшенов. Где-то в кишках документации ликориса хотя бы пик2 есть, но ни слова почему - просто возьмите такой-то пресет, нет времени объяснять. Потратил кучу времени чтобы выяснить какие слои конволюшенов вызывают пережарку и распидорашивание - это ебучие конволюшены в двух крайних ResNet с обоих концов сетки, естественно у кохи они тренируются. Опять надо костылить и отключать их через список conv_block_dims. У ликориса, кста, крайние ResNet нельзя выключить, ты либо тренишь конволюшены, либо нет, заебись. Алсо, лоры и так не тренируют все 25 слоёв, не понятно почему в ликорисе придумали тренировать конволюшены, но не протестили какие лучше не надо трогать, как это было сделано изначально с ванильными лорами.
>Какой же коха дегенерат
Сейчас бы не прочитать доокументацию, пользоваться не гуи от Кохи, а потом бомбить..
> доокументацию
Как будто у кохи она есть. В ней ни слово про то как надо делать, только описание параметров. Про то что он апскейлит пикчи говном можно только в коде узнать, а про конволюшены только проверив.
> гуи
Только хлебушки пользуются гуем от васянов, там уж точно про такое никто никогда не слышал, тренят как есть, а потом веса лор ставят 0.5-0.7, фактически выкидывая половину натрененого потому что говняк в паре слоёв пидорасит пикчу.
Добрый день мне понравился https://app.textcortex.com, но он платный кто-нибудь знает аналоги реальные? Именно аналоги, а не просто похожие чаты.
Было бы неплохо свести это в пасту, чтобы усилия не пропали зря. Только объяснив внятно.
> ставлю разрешение обучения 768
> подает на вход 886
> Почему он ресайзит или кропает?
Ебать ты, оно даже пишет все наборы разрешений которые получаются и про это вроде где-то написано.
Но момент действительно может быть показаться неочевидным, двачую
> Опять надо костылить и отключать их через список conv_block_dims
Раз тестировал, есть иллюстрация сравнения с ними и без них? Ликорис сам по себе странный, дефолтная реализация кохи лучше работают по ощущению.
В других слоях подобного не проявлялось, или еще какие-то выявил?
> Потратил кучу времени
Вбрасывай если замечаешь не стесняйся, другие подключатся и быстрее будет в худшем случае дебилом назовут
https://genforce.github.io/freecontrol/
Какой-то новый контролнет. От китайцев? Корейцев?
Пока без кода.
Кто разбирается - почитайте, расскажите, в чем там разница.
Какой-то новый контролнет. От китайцев? Корейцев?
Пока без кода.
Кто разбирается - почитайте, расскажите, в чем там разница.
Очередной контроль во время семплинга. Можешь посмотреть на FreeDoM, уже был ранее. Нахуй не нужно из-за скорости.
https://github.com/vvictoryuki/FreeDoM
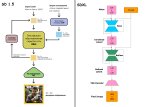
Товарищи из КНР навалили годноты: любая анимация для персонажа, любой шмот на персонажа... Теперь можно сгенерировать по референсу любого персонажа в любой нужной позе, одеть в шмотку, сделать анимацию по шаблону, взятого из любого видео, - и всё это внутри одного workfow.
Это особенно радует меня как сторонника тотальной рандомизации (аатоматизации) в создании ИИ-арта.
Это особенно радует меня как сторонника тотальной рандомизации (аатоматизации) в создании ИИ-арта.
Где?
А, вот ты о чём. Ну так-то зирошот методов для пикч и раньше немало было, эта хуитка просто для видео.
Будущее - за видео
Nope
Разве что только будущее. В настоящем разве только за движухой следить, пока что покакуньки кривые до ужаса.
Я больше за трёхмеркой слежу. Вот тут реализуется новьё: https://github.com/threestudio-project/threestudio
Как они хитро ни на одном пике топологию не палят.
Потому что это те же покакуньки что и в видео, в юзабельных мешах вообще конь не валялся пока. Там вообще большинство в не-полигональных представлениях работает, полигоны если и выводить то классическими методами. А так гауссовы сплаты в анрилах с юнитями есть, не удивлюсь если рано или поздно их станут применять напрямую для каких-нибудь специфических элементов сцены.


>вообще конь не валялся пока
Не скажи, работы ведутся. Через вокселизацию перегоняют в полигоны. И это на самом деле самое перспективное направление. Зачем кинематограф, художники, игори, когда весь контент можно генерировать на ходу по запросу, перестраивать сюжеты, внешний вид, выбирать удобный ракурс, если предложенный нейросетью не понравится.
https://developer.nvidia.com/blog/omniverse-kaolin-app-now-available-for-3d-deep-learning-researchers/
>рано или поздно их станут
Рано или поздно - да. Но не ближайшие 10 лет, там расход пяти ебический, а кожаный, как всегда, зажопил.
> это на самом деле самое перспективное направление
Никто уже так не делает, зачем ты притащил протухшую статью. Брутфорс вокселями очень медленный и имеет кучу проблем с мелкими деталями. Уже давно придумали gaussian splatting.
https://gsplat.tech/excavator/
Вокселизацией можно замешить кое-как, но юзабельным для риггинга это всё равно не будет, там надо учитывать топологию для анимации.
>Но не ближайшие 10 лет, там расход пяти ебический
Хуйня, как раз модная тема это эффективные репрезентации, жрущие всё меньше и меньше. В ближайший год-два может уже стать юзабельным для каких-нибудь вспомогательных штуковин, если так пойдёт.
У жужла другой интерес от 3Д - ресинтез фоток. Синтезируют 3Д представление из нескольких 2Д фоток, затем перегоняют обратно в 2Д. Таким образом можно снимать на смартфон в темноте с гораздо меньшим количеством мыла, свойственного даже стаку в GCam. Правда тоже пока не лезет в смартфонное железо, но скоро будет.
Есть ещё риэлторские конторы, заинтересованные в виртуальных турах по хате, полученных из допустим сотни фоток, им тоже полигоны нахуй не нужны.
Так про них и речь. Только как ими замешить? Гауссовы сплэты это просто облако точек, в котором каждая точка имеет цвет/альфу/размер/ориентацию.
>gaussian splatting
Для реального использования бесполезно.
>заинтересованные в виртуальных турах по хате
В этой гауссовой залупе невозможно просчитывать освещение, только запеченное с картинки. А если клиент захочет лампы-фонари, приглушить освещение? Уже всё, нужны полигоны.
> Только как ими замешить?
SuGaR есть из свежего, до этого ещё несколько алгоритмов было. Но ещё было бы зачем, к сплатам уже анимации и физон даже прикрутили, у мешей производительность рендеринга сильно хуже чем у сплатов.
>В этой гауссовой залупе невозможно просчитывать освещение, только запеченное с картинки. А если клиент захочет лампы-фонари, приглушить освещение?
https://shunsukesaito.github.io/rgca/
Ну и вообще, потанцевала дохуя. С нейронками к этим штукам можно много чего прикрутить, от анимации до интерактива и нейро-имитации рейтрейсинга. Но это всё будет не скоро, если вообще будет.
>к сплатам уже анимации и физон даже прикрутили
Анимации там пока что запечённые, нет интерактива.
>у мешей производительность рендеринга сильно хуже чем у сплатов
Не у мешей скорее, а у всего комплекса в целом, надо ещё смотреть как сплаты будут перформить в полноценных играх, если они вообще доберутся до них. А то облака точек уже лет 15 пророчат, а воз и ныне там.
Может так статься что протегированные меши и скелеты, обрисованные через контролнеты (условно говоря) темпорально стабильной нейронкой, будут быстрее и гибче и того и другого. Как тут https://isl-org.github.io/PhotorealismEnhancement/
а может и не статься
>https://shunsukesaito.github.io/rgca/
А эта штука основана на обучении. Никакого рилтайма, замены объектов на лету, всё приколочено гвоздями и требует очень, очень много времени на подготовку. То есть потанцевал околонулевой. Ну, для кинца ещё может быть, но памяти жрёт как не в себя.
Вообще, оно уже тоже "протухло". Было год назад на выставке меты.
https://www.youtube.com/watch?v=2mnonWbzOiQ
>А эта штука основана на обучении.
https://nju-3dv.github.io/projects/Relightable3DGaussian/ рейтрейсинг напрямую на сплэтах
>В этой гауссовой залупе невозможно просчитывать освещение, только запеченное с картинки.
А там нет ничего запрещающего кастомное освещение. Это же просто облако анизотропных пиздюлинок, можно его как обычную поверхность юзать для шадоумаппинга, рейтресинга, AO всех сортов и мастей и т.п. Там главное интерактив, физон и т.п. движение/коллизии/симуляция - можно это обеспечить обычным риггингом.

>bounding volume hierarchy
Это не вокселизация случайно? И, опять же, оно не рилтаймовое.
>Pre-processed DTU
>For real-world DTU data, we follow the Vis-MVSNet to get the depth maps and then filter the depth map through photometric and geometric check. We then convert the depth map to normal through kornia. And we get perfect masks from IDR.
Восемь гигов предварительно запеченных данных.
>рейтресинга
Денойзер ебанётся. АО тоже, все алгоритмы заточены на детект краёв, а в этом облаке заебёшься искать, где краёв нет. Физика похуй, там всё равно используются упрощённые меши, можно на основе тех же объёмов генерировать меши для физики. Да они, по сути, и не нужны, всё равно деревья на основе тех же объёмов под капотом. На счёт ригинга не уверен, GPU ускорение отваливается, всё либо на вычислительных шейдерах, либо вообще на CPU, что гарантированно медленнее существующих решений. И без поддержки старых карт.
>Это не вокселизация случайно?
Это та самая хуйня которую RTX призван аппаратно ускорять
Легкий/удобный способ конвертировать имя с пиксива на бурятском или id в общепринятые теги существует?
В итоге https://danbooru.donmai.us/artists основное покрывает, есть api с приемлемым рейтлимитом.
аноны посоветуйте параметры дримбудки дл sdxl
датасет человек, 20 фото, качество норм, разные, капсы подробные
сколько стоит поставить повторов, всего шагов, LR?
датасет человек, 20 фото, качество норм, разные, капсы подробные
сколько стоит поставить повторов, всего шагов, LR?
>датасет человек, 20 фото
10 фото.
Спасибо
LR дефолтный 1e-5 не много?
> 20 фото
> дримбудки
Надеюсь, ты про лору хотябы?
Такой норм, ставь 250 шагов и тестируй накидывая по 50
Дримбут дает лучшее качество чем твои говнолоры куцые. Конечно, не у каждого есть боярские 10 гигов на модель.
нахуй лору ебаную
дримбут полноценный
если уж очень надо лору можно потом из будки выдернуть. хотя лучше натренить будку на нужной модели.
> 20 фото
> дримбут полноценный
> лору можно потом из будки выдернуть
Обучение лоры и ее извлечение - разные процессы и качество результата также будет отличаться в зависимости от конкретного случая, описанный подход - провальный.
Хочешь страдать - ебись. Нынче много любителей познать все ошибки на себе, не меньше и тех кто будет хвастаться своими идиотскими поступками.
На всех лорах перекошенные ёбла. Они всегда были компромисом. Для тренировки лица на дримбуте 10 фоток достаточно. Особенно если брать ванильные модели, где с весами все хорошо.
Покежь результат на 10 фото. Вангую что выйдет хуйня.
Дело не в гигах, а в невозможности потом композить несколько в одной пикче. Тогда уж локон делать, или что-то более продвинутое.
> На всех лорах перекошенные ёбла
Проблема в обучении какая-то. Даже на циве большое количество реалистичный лор, которые работают прилично. Будка переломает все остальное и обойдется огромной ценой, лучше решить проблему чем заправлять шубу в трусы.
у меня с одним и тем же датасетом дримбудка дает однозначно лучший результат, чем лора. и лору, и будку тренил на разных параметрах.
боярином не обязательно быть, 4090 на васте менее 50 центов в час. за час можно успеть всё завести и натренить будку в 2000 шагов в сдхл.
боярином не обязательно быть, 4090 на васте менее 50 центов в час. за час можно успеть всё завести и натренить будку в 2000 шагов в сдхл.

>На всех лорах перекошенные ёбла.
На моей лоре охуенно получается лицо. Но я вам ее не покажу потому что это лора еотовой и существует поиск по лицу, не хочу чтобы она знала что кто-то генерит миллионы ее нудесов потому что из ее знакомых таких может быть 1,5 человека. Но что сука характерно - делал наугад и в первый раз, потом пробовал по гайдам и получалось говно. Надо расковырять лору и достать настройки, но вроде бы в большинстве они были стандартные, 1 эпоха, 200 фото 512х512 с включенным Flip augmentation по 100 интераций на каждую и адамв потому что от 8 бит мое железо скукоживается. Еще я смутно припоминаю что мог увеличить LR на еще один 0 после точки.
Ебать ты крип, я б тебя скрысил
SDXL с настройками, позволяющими влезть в 24 гига, нихуя не запоминает нормально.
А другие типы лор? Тот же локон.
Значит ты тренишь через жопу.
> локон
Он наоборот для дампинга тренировки.
Иногда кажется что в фетишах совсем обдвачевался, но потом видишь такое.
> с настройками, позволяющими влезть в 24 гига
Ты про gradient checkpointing? Он ухудшает качество тренировки а не просто ее замедляет?



>Иногда кажется что в фетишах совсем обдвачевался, но потом видишь такое.
Ты не знаешь насколько глубока кроличья нора.
Кто-нибудь знает нейронку для смены эмоций на фото. Такие вообще есть даже во всяких инстаграм масках, но что-то опенсорсного с ходу не нахожу
Это ЕОС, не трогай.
В комфи забабахай конвеер - ip-adapter пересаживает то же самое лицо под управлением контролнета с mediapipe физиономией
Это не правильно. Использовать sd просто для смены эмоции. На телефоне инстаграм далеко не sd гоняет
Правильно или нет, главное результат. Специфичных открытых сеток для этой задачи не знаю, знаю только универсальные.
LAION-5B убрали из онлайна, ибо нашли в нём цопэ. а они быстрые, ещё бы в 5.8 миллиарда пикч со всего интернета не затесалось
https://www.404media.co/laion-datasets-removed-stanford-csam-child-abuse/
https://www.404media.co/laion-datasets-removed-stanford-csam-child-abuse/
Фрики не удивляют, есть и больший пиздец. А то, насколько поехавшими могут быть нормисы, преподносит сюрпризы.
Вот это лолита, выходит его зеркала - распространение?
Похуй, DataComp качественнее даёт результаты после обучения.
Слушай, братишка, мы все так или иначе нет-нет да удовлетворяем себя глядя на кого-то или представляя кого-то. У меня вот шишка колом на одну тян, но она замужем и влезать третьим не в моих правилах. Кроме того даже если бы она была одна - это все равно вариант без перспектив, потому что вместе я нас не вижу при любом раскладе. Что плохого в том что я стираю шишку в одиночестве на AI-генерации нудесов этой тян, при том что это является только моим маленьким секретом и кроме меня об этом никто никогда не узнает? Чем принципиально отличаются генерации на какую-нибудь Эмму Ватсон не будем упоминать что она светанула сиськи и трусы, Бель Дельфин не будем вспоминать про онлифанс или сорт оф, на которых тоже есть лоры? И в конце концов тысячи кулстори когда одна тян просит починить комплюктер/телефон из которого сливаются ее нудесы inb4 Желева - чем это принципиально отличается? Не этично? Возможно. Но вред это может принести только если это окажется в публичном доступе, но в этом мне интереса нет. Что же до нормисов - у всех есть загоны, выходящие из ряда вон. Даже их отсутствие на фоне прочих - это тоже девиация.
А между тем я пытаюсь вспомнить и повторить настройки, с которыми была натренена лора. Если получится - я вам их принесу.
Это да, лаион по сути гигантский скрейп говна с минимальной инженерией. (эстетический скор который нихуя не фильтрует)
Да один хуй, почистят и вернут.
>выходит его зеркала - распространение?
Если нефильтрованные - да, очевидно.
Да вообще без осуждения, каждый дрочит как хочет. Просто настолько преисполнились поехали, что подобные простые вещи вызывают удивление.



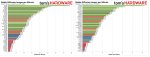
автоматик добавил fp8 вычисления, неплохо экономят память для SDXL, для 1.5 результаты не такие заметные
на рендерах слева fp8 вкл, справа выкл, разница есть, но небольшая
на рендерах слева fp8 вкл, справа выкл, разница есть, но небольшая
Уже месяц как.
В этом режиме кстати помедленнее на 1.5 работает, чем в обычном fp16. По крайней мере при замере на дефолтных 512 шакалах
разницы не заметил, возможно от видеокарты зависит

у кого скорость повысилась от этого hypertile? у меня что-то нет. перезапускал SD конечно же.

Миджорня тем временем продвинулась настолько что в ответ на промпт непосредственно выдает картинки на которых обучалось. Еще немного и сбудется моя мечта, можно будет использовать нейросетки с моделью в качестве оффлайнового поиска по картинкам, без этой вашей генерации шестипалых уродов.
Оверфит бывает везде, вопрос в том как его найти.
>можно будет использовать нейросетки с моделью в качестве оффлайнового поиска по картинкам, без этой вашей генерации шестипалых уродов.
Для этого нужно параметров в сотни тысяч раз больше, и сетку перетренить так что она всё запомнит.
О, это чтобы копирастам было проще набутылить тебя за использование их закопирайченной собственности. Найс.
Деградирует же.
>параметров в сотни тысяч раз больше, и сетку перетренить так что она всё запомнит.
Я верю в миджорни
обнаружил, что тензорное смешение двух схожих моделей отфайнтюненых даже через трейндифренс по итогу увеличивает консистенцию результата и качетсво ответа на токен, ничеси приколы
>в качестве оффлайнового поиска по картинкам
Это другая тема, про хранение информации в нейронках

Сап двосч. Подскажите, пожалуйста. У меня есть большой текст. Я натренил его на tesorflow. Но выдает он не то что можно. Как я могу дообучить какую-то крутую модель своему тексту? Есть гайд для тупых? Lora только для картинок или так же можно текст тренировать?

Сап двосч. Подскажите, пожалуйста. У меня есть большой текст. Я натренил его на tesorflow. Но выдает он не то что можно. Как я могу дообучить какую-то крутую модель своему тексту? Есть гайд для тупых? Именно для теста. Странно, я вроде заплатил уже и не увидел свой пост. Как-то потерся
Всем привет! Может кто-то поделиться пример дообучения какой-то сети на своем тексте?
Поздравьте меня. Натренировал своё первое Lora. 10 эпох, сутки. Сейчас пойду смотреть как работает.


Аноны, а подскажите, пжлста, если я хочу на мохнатую вагину натянуть эротические трусы, то это мне как такой датасет подготовить для лоры? Фоток таких для обучения у меня, естественно что, нет.
Есть только фотки, получается что:
1. Мохнатых вагин
2. Вагин с обычными трусами
3. Эротических трусов.
Как такое обучается?
Есть только фотки, получается что:
1. Мохнатых вагин
2. Вагин с обычными трусами
3. Эротических трусов.
Как такое обучается?
для того, чтобы в итоге получить возможность генерировать эротические трусы на мохнатых вагинах, датасет тоже ложен быть из пикч с эротическими трусами на волосатых пездах.
Поищи то, что тебе подходит в паках ATKHairy на порнлабе или где получится найти.
Ты тренить для SD или XL собираешься?
>Аноны, а подскажите, пжлста, если я хочу на мохнатую вагину натянуть эротические трусы, то это мне как такой датасет подготовить
Удали фон трусов до прозрачности и кинь их на свою пизду в фотошопе, затем обработай имидж ту имидж чтоб убрать швы. Можешь обойтись без фотошопа, нарсисовов труселя руками в маске.
Зачем для этого обучать, инпеинтом не получается, что ли? Если нужно конкретную модель трусов - IPAdapter'ом перенеси.
https://github.com/rockerBOO/lora-inspector пробовал кто-нибудь? Что скажете?
Нужно выдернуть настройки, с которыми обучалась лора, потому что методом тыка повторить не удается, а результат получился заебись.
Нужно выдернуть настройки, с которыми обучалась лора, потому что методом тыка повторить не удается, а результат получился заебись.
аноны, поделитесь, плиз, работающей SDXL inpaint моделью для автоматика.
все, что пробовал, либо не загружаются, либо выдают черное пятно в месте инпейнта.
все, что пробовал, либо не загружаются, либо выдают черное пятно в месте инпейнта.
К сожалению автоматик их не поддерживает. Наверное в будущем добавят, хотелось бы иметь возможность, вдруг она может более сложные вещи адекватно понимать
спасибо!
Так посмотри просто в интерфейсе автоматика, или в адднетах
Стабилити ведь не релизили инпеинт модель для хл, откуда ты взял вообще что она существует? На 1.5 и 2.0 вижу, а к хл так до сих пор и нету
Когда в кохе в поле "Model Quick Pick" указывается runwayml/stable-diffusion-v1-5 - что она грузит? v1-5-pruned или v1-5-pruned-emaonly? Или что? Или куда сохраняет чтобы посмотреть? В tmp чет не нашел.



пытаюсь смержить 2 лоры в одну но не понимаю что я должен в "save to" указать так или иначе выдает еррор, не уверен что это в целом должно так работать или какие еще есть способы это сделать
Если они были записаны в метаданные, то эти настройки проще в Авто найти. Там ж есть кнопочка для показа всех метаданных на миниатюре для лоры.
Если настройки не были записаны - никакой плагин тебе нифига не вытянет.
Так целиком путь пропиши. Типа E:\LoraMerge.safetensors
Или что-то вроде того.
Можешь вообще супермеджер накатить.
>Так посмотри просто в интерфейсе автоматика, или в адднетах
>есть кнопочка для показа всех метаданных на миниатюре для лоры
Так он мне через интерфейс показывает "ss_color_aug": "False", а через инспектор "ss_color_aug": true лол. И хуй знает кому верить.
Он грузит диффузоры в папку %userprofile%\.cache\huggingface\hub\
Спасибо. Добра.
avr_loss=nan ето плохо? Кое-где в инторнетах пишут что плохо, и что обучение можно килять. В другом месте пишут что норм и это потому что шедулер используется другой, а в третьем к шедулеру прибавляют проблемы bitsandbytes. А по факту что?
Если одиночный, то жить можно. Если все пошли NaN, то лору в мусорку. При нормальном обучении он никогда таким не будет, это определённо признак кривых рук.
Это пиздец означает, можешь заканчивать обучение
У меня с самого начала обучения nan лол.
а как интегрировать эти 4 файла в автоматик?
Здравствуйте, я новенький, а что здесь надо делать?
Как я понял, качаешь патч https://github.com/AUTOMATIC1111/stable-diffusion-webui/pull/14390.diff, и в ветке master с помощью git apply ставишь. Сам делать не буду, подожду 1.8, или где его добавят в релиз
спасиб, попробуем
Полгода будешь ждать, пока его в мастер пульнут. В дев, наверное, быстрее, но каломатик с 17 декабря хуи пинает.
Есть тут кто с амуде 6800ХТ или 6900ХТ
Какую модель посоветуете, за сколько у вас изображение генерится?
У меня щас за 20 сек на турбо хл 512х512 20 шагов, можно ли быстрее?
Есть ли гайд какой то по пердолингу настроек для амуды в виндоусе?
Какую модель посоветуете, за сколько у вас изображение генерится?
У меня щас за 20 сек на турбо хл 512х512 20 шагов, можно ли быстрее?
Есть ли гайд какой то по пердолингу настроек для амуды в виндоусе?
>6900ХТ
>для амуды в виндоусе
Ты же судя по карте не нищеброд как я, купи отдельный SSD и сделай дуалбут с линуксом.
Я ваще не шарю в этой хуйне, это жестко пердолиться придется? У меня как раз лежит нераспечатанный ссд на 500 гигов на полке
Ладно, так уж и быть, поставил. Дело то пару секунд, и ждать еще долго
Работает с базовой моделью, а вот с мержем у меня не получилось
Линукс - это синоним пердолинга. Но тут как обычно, гуглишь гайды и делаешь по ним.
Upd, с juggernaut xl получилось смержить inpaint разницу. Это значит из-за даунского кастомного запечённого vae в realvisXl 3.0 не работает, который видимо не сохраняется при мерже
> juggernaut xl
Заметил что с ним какие-то цветные полосы появляются. Но он хоть генерирует, realvis просто латентные нули выдаёт (просто бежевая заливка)

зачем 20 шагов для турбохл? там 5-6 с DPM++ SDE Karras хватает для вменяемой картинки


тоже самое но с 20 шагами - очевидный пережог. турбо и LCM модели требуют других настроек
Это на амуде?
У меня на 6900ХТ 1.5 мин генерится, пиздос...
нет, нвидиа. просто самое простое ускорение без пердолинга для тебя это уменьшение количества шагов, 20 не нужны для турбо.
мержить надо после обновления автоматика до dev версии? а то на 1.7 ошибку выдаёт
У меня на амуде почти не меняется от количества шагов время
С 20 где то 1 мин 40 сек генеринг с 5 шагами 1 мин 20 сек
может на процессоре генерится? провеь нагрузку на видеокарту

попробуй это https://github.com/nod-ai/SHARK
тут есть возможность выбрать на чём рендерить
на хилой встройке AMD аж заработало, думал она никуда не годится в SD
На винде такое запустится или надо линукс?
Окей спасибо попробую
Я в master 1.7.0 мержил
подскажи настройки пожалуйста
Не понял, как связан git и настройки?
настройки объединения кастомной xl модели с inpaint моделью
А - sdxl base inpaint
B - твоя модель
С - sdxl base
M - 1
сработало, но модель не грузится. ладно да и хер с ним, подожду официальной поддержки от автоматика вместо тыканья дев билдов

Оцените inpaint с помощью realVisXL 3.0
-кун реквестирует помощь.
Реквестирую работающий конфиг, который не будет выдавать avr_loss=nan, я заебался искать причину. Но у меня не работает bf16 и AdamW8bit потому что невидия 16 в это не умеет.
Если с вашим конфигом будет все хорошо - значит вот этот господин прав насчет рук.
И еще пара вопросов:
Допустим я хочу использовать runwayml/stable-diffusion-v1-5, он его конечно закачивает в .cache (спасибо вот этому доброму человеку), но я хочу держать его в другой директории. Как зделоть? При выборе custom я просто не ебу что указывать, там ёбаная куча safetensors в поддиректориях.
У меня довольно много всякого говна нагружено и помнить про что оно только по названию можно ебануться, поэтому я поставил https://github.com/butaixianran/Stable-Diffusion-Webui-Civitai-Helper и оно нагрузило мне превьюх, может подставлять триггеры и вообще оче удобно, но проблема в том что нагрузило оно в ту же директорию, где лежат модели. Можно как-то их разделить, чтобы модели были в одной директории, а их потроха в другой? очевидно что нет
Реквестирую работающий конфиг, который не будет выдавать avr_loss=nan, я заебался искать причину. Но у меня не работает bf16 и AdamW8bit потому что невидия 16 в это не умеет.
Если с вашим конфигом будет все хорошо - значит вот этот господин прав насчет рук.
И еще пара вопросов:
Допустим я хочу использовать runwayml/stable-diffusion-v1-5, он его конечно закачивает в .cache (спасибо вот этому доброму человеку), но я хочу держать его в другой директории. Как зделоть? При выборе custom я просто не ебу что указывать, там ёбаная куча safetensors в поддиректориях.
У меня довольно много всякого говна нагружено и помнить про что оно только по названию можно ебануться, поэтому я поставил https://github.com/butaixianran/Stable-Diffusion-Webui-Civitai-Helper и оно нагрузило мне превьюх, может подставлять триггеры и вообще оче удобно, но проблема в том что нагрузило оно в ту же директорию, где лежат модели. Можно как-то их разделить, чтобы модели были в одной директории, а их потроха в другой? очевидно что нет
> закачивает в .cache (спасибо вот этому доброму человеку), но я хочу держать его в другой директории. Как зделоть?
Гугли символические ссылки. Очень полезная вещь
Но вообще кеш hugging face можно через переменную окружения перемещать, гуглится за секунду. Так что осиль сам
Кэш SD у меня и так лежит в директории SD (спасибо дружку хача, рили удобно), но runwayml/stable-diffusion-v1-5 я бы хотел держать в директории models например, а перемещать туда кэш переменной - это значит насрать туда всем остальным, что в кэш пишется.
Симлинки это канеш все хорошо, но немного не то. Я хотел бы в директории с чекпоинтами/лорами/etc видеть только чекпоинты/лоры/etc. Кроме того, я не знаю корректно ли обрабатывает SD симлинки - мне встречался софт, который в упор этого не делал.
В дополнение к этому
Вероятно дело не в настройках или кривых руках (по крайней мере не моих), а в том что с какого-то релиза обучение сломано https://github.com/bmaltais/kohya_ss/issues/1758
Укажите пожалуйста, какой версией (или когда она была скачана/установлена) вы пользуетесь, пожалуйста. Попробую откатиться, но не знаю куда.
Вероятно дело не в настройках или кривых руках (по крайней мере не моих), а в том что с какого-то релиза обучение сломано https://github.com/bmaltais/kohya_ss/issues/1758
Укажите пожалуйста, какой версией (или когда она была скачана/установлена) вы пользуетесь, пожалуйста. Попробую откатиться, но не знаю куда.


Расширение, снижающее артефакты при больших CFG: https://github.com/scraed/CharacteristicGuidanceWebUI
Может быть это станет спасением для lcm лор, чтобы негативы включить? Надо будет протестировать
Может быть это станет спасением для lcm лор, чтобы негативы включить? Надо будет протестировать
Block merge охуительный underrated метод, когда берешь из другой модели только освещение и эффекты поверхностей. Гораздо лучше и практичнее чем обычный мердж. Ничего сложного там нет, делаешь две кривые на ползунах и всё, так что теперь запилю свой собственный зоопарк оранжей для XL.
Что, ещё одно? Это, старое, не помогало с лцм, если что. https://github.com/mcmonkeyprojects/sd-dynamic-thresholding
Ну что вы блядь, немощи, ни у кого не закомменчен git pull в батнике и никто не может посмотреть дату создания файлов/директорий в проводнике блядь?
Какой нахуй батник, у нас запуск через скрипт на питоне, последняя версия кохи работает без проблем.
> с какого-то релиза обучение сломано
Нихуя там не сломано. С таким припизднутым lr, как по твоей ссылке, и должны NaN идти через 100 итераций, ничего в этом нет что надо было бы чинить. Алсо, bf16 уже можно называть признаком дебила, потому что использующие его думают что оно как-то спасает от говна ебанутых настроек тренировки. Наоборот у bf16 точность значимой части ниже 7 бит вместо 10 у fp16, экспонента большая никогда не нужна, если всё нормализовано.
Давно не обновлял, но на этой должно всё работать, хз что там с последней версией 2a23713f71628b2d1b88a51035b3e4ee2b5dbe46
> думают что оно как-то спасает от говна ебанутых настроек тренировки
Ну а что же тогда спасает?
>у нас запуск через скрипт на питоне
Ну каждый дрочит как он хочет, мне например удобно срать только в директорию с кохой, а не в юзердир, поэтому у меня запуск через батник. Это вощем-то не отменяет моего вопроса, но ты уже ответил на него, спасибо.
Благодарю, я попробую.
Олсо повторяю реквест, дайте пожалуйста работающий конфиг. В кохе же 1,5 настройки в вебморде, ну не мог же я блядь объебаться конечно же мог, просто в упор не вижу где.
> когда берешь из другой модели только освещение и эффекты поверхностей.
Очередной чел с магическим мышлением по отношению к sd. Нет в моделе специальных областей с "освещениями и эффектами поверхностей", к которым нейронка обращается, когда "выбирает освещение и эффекты поверхности" что бы это не значило
> Ну каждый дрочит как он хочет
Это конечно верно. Но пользоваться виндой в 2023 - это, конечно, пиздец...
Ну извинити, у меня нет свободного времени впрочем и желания чтобы натянуть и настроить гуй на голый линупс, а искаробочными решениями пользоваться вызывает рвотный рефлекс наравне с виндой, поэтому из двух зол.
Не у всех есть деньги на Мак, а пользоваться гну-высером из нулевых - это вообще зашквар, ты бы ещё предложил на ХР перекатываться.
> Не у всех есть деньги на Мак
Щаз бы SD на маке запускать лол.
Лучше чем на амуде, лол.
Одинаково, вообще-то.
Что-то мне кажется, что на амд совместимость подучше. А на маке на уровне видеокарт интл
Амуде бы сейчас не видеокарты пилить, а бросить силы штата разрабов пилить либы для нейросетей. А то ёбаная куртка жмется на память словно она бешеных денег стоит, хотя стоит она почти нихуя на самом деле.
> А на маке на уровне видеокарт интл
На Маке автоматик из коробки работает так-то, в отличии от амуды.
Куртка начнёт конкурировать сам с собой, если добавит дохуя памяти в потребительские карты. Жди новый тип ядер для жёсткого ускорения нейросетей, которых не будет в потребительских картах. Тогда памяти доложат побольше. А пока куртка финансирует ии-сжатие текстур, чтобы можно было класть ещё меньше памяти.
>бросить силы штата разрабов пилить либы для нейросетей
Они и пилят, ROCm уже есть.
> дайте пожалуйста работающий конфиг
Для какой гпу и чем именно тренишь?
Я имею в виду конфиг для webui, параметры тренировки. Я где-то наебываюсь именно здесь, потому что ранее получал значения avr_loss хотя бы отличные от nan. Но в то же время это происходило на более ранней версии, примерно 22.1.1. Однако я попробовал ее и все равно получаю nan. Возможно конечно дело не в кохе а в модулях пердона, я попробовал откатить на более древние но и это не решило проблему.
Офк я попробовал чистую реинсталляцию (которую рекомендуют в 95% при решении проблем потому что никто нихуя не знает).
У меня 1063 и 1630@4gb, треню кохой, пытаюсь запуститься на runwayml/stable-diffusion-v1-5.
Я сам себе злобный буратина, поначитавшись всяких гайдов включил Full fp16 training (experimental). Корочи я дебил и еб бы вам голову зря, но... Отключив его я наконец начал получать на 1063 валидный avr_loss, наконец сохранил работающий пресет чтобы больше не заниматься такой хуйней, но перенеся его на другую тачку с 1630@4gb я снова начал получать nan. Охуеть, что за магия бля?
-кун
-кун
> 1063
Да какое обучение на 3 гб vram, успокойся. Для адекватного взаимодействия с сетью 8 гб мало, чтобы без постоянных компромиссов, а ты в обучение со своими тремя полез
Что в наличии есть - на том и учу. Пару раз даже успешно потом начал обсираться с каждым разом все жиже, но разговор не об этом, так что нормальное обучение, принципиально все работает, это я мудак конфиги кручу и не могу понять где сломалось.
Ля, вот вы...
Короче я сделал еще один тест. Голый конфиг, единственное что поменял - это оптимизатор AdamW8bit на AdamW (чтобы было одинаково, одна машина в AdamW8bit не может).
На 1063 голый конфиг заводится, на 1630@4gb получаю nan. Правда я не могу сказать с уверенностью, тренил ли я на 1630@4gb уже или еще нет, могу только сказать что генерил. Возможно этому огрызку отрезали что-нибудь нужное для обучения.
А так как вы молчите, я пожалуй скастую одного юродивого в этот тред: Я ИСПОЛЬЗУЮ ВЕРСИЮ ОТ ДРУЖКА ХАЧА
а потом буду его тыкать носом в хачевский батник, где написано git remote add origin https://github.com/bmaltais/kohya_ss.git && git pull origin master и размазывать по ебальнику user environment variables. Да, мне наконец совершенно нечем заняться в этот новый год, как же пиздато заниматься вот такой хуйней. С НГ всех, целую-обнимаю.
Короче я сделал еще один тест. Голый конфиг, единственное что поменял - это оптимизатор AdamW8bit на AdamW (чтобы было одинаково, одна машина в AdamW8bit не может).
На 1063 голый конфиг заводится, на 1630@4gb получаю nan. Правда я не могу сказать с уверенностью, тренил ли я на 1630@4gb уже или еще нет, могу только сказать что генерил. Возможно этому огрызку отрезали что-нибудь нужное для обучения.
А так как вы молчите, я пожалуй скастую одного юродивого в этот тред: Я ИСПОЛЬЗУЮ ВЕРСИЮ ОТ ДРУЖКА ХАЧА
а потом буду его тыкать носом в хачевский батник, где написано git remote add origin https://github.com/bmaltais/kohya_ss.git && git pull origin master и размазывать по ебальнику user environment variables. Да, мне наконец совершенно нечем заняться в этот новый год, как же пиздато заниматься вот такой хуйней. С НГ всех, целую-обнимаю.
Дегенератина, показывай свой конфиг и используй нормальную версию от кохи, а не всяких хачей-трюкачей.
> bmaltais/kohya_ss.git
Это ещё что за мокрописечная хуета? Оригинальная репа тут - https://github.com/kohya-ss/sd-scripts

Ладно, я нашел в чем дело https://github.com/kohya-ss/sd-scripts/issues/293
И действительно указав mixed_precision=no обучение на 1630@4gb начало отдавать значения avr_loss.
Кроме того, там же лежит решение чтобы mixed_precision=fp16 заработал, но у меня чет не получилось его завести. Ну да и хуй с ним, посмотрю на результат при =no.
>Это ещё что за мокрописечная хуета
Это мокрописечная хуета, в которую коха сделал 600+ коммитов, так что ебальничек завали.
> коха сделал 600+ коммитов
Принятия пул-реквестов и мержей из основной репы? Не вижу ни одного коммита с кодом от кохи за последние месяцы один багфикс нашёл всё же на 5 строк, да. И речь тут в первую очередь про то что авторы этого кала в конфигах по умолчанию делают, пользовался бы оригинальной репой - не было бы вопросов кто насрал.
>Принятия пул-реквестов и мержей из основной репы?
Хотя бы это делает мокрописечную хуету потенциально рабочей. На данный момент большинство мокрописечных хует - это суть то же самое, что развернуто на твоей пекарне, только ставится из гита. И я ебал ставить все руками когда можно почти полностью развернуть автоматически, тем более что (!) в мокрописечной хуете принятия (!) пул-реквестов и мержи (!) из основной репы (!). Не понимаю как даже не форк, а по сути аддон вдруг делает оригинальный код неоригинальным.
И как показывает практика - насрал обычно сам пользователь, но и вы далдоны не знаете нихуя как исправить ту или иную проблему, вся ваша помощь - это сиплые вскукареки на тему оригинальности источника и неканоничности мокрописечных хует. С одной стороны это не ваша вина - насколько я слышал но не читал, да маны кохи крайне неинформативны, что-то уровня "делай так и будет заебись". Но если такой подход вполне канает в треде, то в качестве официальной документации это полное говно.
И однако я удачно тебя скастовал лол.
> проблему
Ты пока ни одной проблемы не обозначил. "Не работает" без показывания что ты там напердолил - это не проблема, а диагноз об умственной отсталости.
>Не вижу ни одного коммита с кодом от кохи за последние месяцы
Хорошо, давай я повожу твоим ебальником по говну немного иначе: идешь в свою ультра-мега-гипер-оригинальную репу и в readme.md находишь
>For easier use (GUI and PowerShell scripts etc...), please visit the repository maintained by bmaltais. Thanks to @bmaltais!
А в браузере на странице "the repository maintained by bmaltais" вообще выполнено ссылкой на мокрописечную хуету.
Неудобненько вышло, коха ссылается на мокропиську, вот так новость.
>Ты пока ни одной проблемы не обозначил. "Не работает" без показывания что ты там напердолил
Я обозначил что получаю nan, и будь у нас всех чуть больше информации об этом - можно было бы сказать в каких кейсах это может происходить, прочекать эти кейсы и найти проблему.
Уже в этом посте можно предположить проблемы с совместимостью, а не проблемы в настройках или дистрах. А вот в этом посте я специально сказал что попробовал голый (читай - дефолтный) конфиг только с одним изменением, то есть я нихуя там не накрутил.
А уж указывать что дистрибутив не был инсталлирован руками - это вообще для вас, долбаёбов, красный флаг. Не перестаю лолировать с этого ощущения исключительности на самоподдуве - "я поставил все руками вместо автодеплоя, какой же я охуенный".
анончики, а есть какой-то нормально работающий теггер для НСФВ, без разницы на базе чего, данбору или нет - просто смотрю в гитхаб и там какая-то ебань для красноглазых, а в kohya гуе нет нифига нормального теггера для всяких пезд и жоп
и поделитесь пожалуйста нормальным гайдом по обучению лор на сдхл - карточку купил новую, а чето нихуя kohya не тренит - когда-то давно 1.5 модели нормально обучались, а щас sdxl какая-то пиздатня, и все гайды это сука двухчасовые видосы на ютубе от индусов и иранцев каких-то
>в kohya гуе нет нифига нормального теггера для всяких пезд и жоп
Ну обычно они прописываются в промт, стандарта как правило нет, но как одно из предположений - скачай другой чекпоинт, какой-нибудь эпикреализм или сорт оф. Дефолтный чекпоинт хуево рисует пезды и жопы.
Еще на пезды и жопы можно задействовать лору, им иногда нужен триггер.
Ну давай попробуем, хз. Расскажи модель новой карты и что происходит при обучении - какой выхлоп в сосноль дает, ошибки там чи шо?
> mixed_precision
> на 1630
Она разве вообще умеет в него? Все через жопу костыльно всегда было на недо-тьюрингах.
> вместо автодеплоя
Автодеплой что заменяет 2.5 строчки кода? Гуйня bmaltais в целом неплоха и для будки пригодна для формирования параметров запуска, хотя многого там всеравно нет. О чем у вас спор вообще?
> я поставил все руками вместо автодеплоя, какой же я охуенный
Случаем сам не имплаишь что юзать васянскую залупу - норма? Или что вообще хочешь сказать?
WD теггер работает с нсфв хорошо, не так давно там новая модель вышла которая знает оче интересные концепты и теги но при этом очень обильно срет и надо с ней устроить правильное обращение.
> там какая-то ебань для красноглазых
Все так, нормальный путь - пачка из нескольких моделей. Есть ленивый путь - экстеншн к автоматику, позволяет тегать батчами, выбирать модельки, делать базовые настройки и т.д., для простых задач хватит.
>Она разве вообще умеет в него?
1063 поколением ниже внезапно заводится норм, хотя казалось бы.
>Автодеплой что заменяет 2.5 строчки кода
В случае bmaltais - нет, но в случае портабельного варианта, который развертывает дружок хача - вполне себе годно, зависимости развернутся сами.
>хотя многого там всеравно нет
Вот с этого момента подробнее. Мне интересно, без сарказма.
>Или что вообще хочешь сказать?
Я хочу сказать что предмет нашего спора (конкретно репа bmaltais, на которую ссылается деплоер дружка хача) - сорт оф плейбук. Если взять эту аналогию, нихуя криминального в использовании плейбука из инторнетов в случае если он тебе подходит и работает - нет. И более того, сейчас это стандарт, никто не дрочится с деплоем и конфигурированием руками, но почему-то в этом треде это вызывает жопное горение.
>Я хочу сказать что предмет нашего спора (конкретно репа bmaltais, на которую ссылается деплоер дружка хача) - сорт оф плейбук. Если взять эту аналогию, нихуя криминального в использовании плейбука из инторнетов в случае если он тебе подходит и работает - нет. И более того, сейчас это стандарт, никто не дрочится с деплоем и конфигурированием руками, но почему-то в этом треде это вызывает жопное горение.
Ну или вот еще одну аналогию приведу. Вот есть SD, у него есть дефолтный чекпоинт. Приходит в тред анон и говорит "у меня не генерируется пиздохуй, что делать? Генерирую на чекпоинте пиздохуй.safetensors". В ответ на свой вопрос анон получает взвизги про то, что генерировать пиздохуй надо только на дефолтном чекпоинте, а все остальное мокрописьки и вообще пошел нахуй.
Я не призываю использовать одно, но не использовать другое, если что - дрочитесь как угодно, хотите ставить руками, срать в кэш юзердира и переменные среды - ваше право, никаких претензий, это дефолтный и рабочий вариант.
> 1063 поколением ниже внезапно заводится норм, хотя казалось бы.
Все верно, паскаль был полноценным, хоть и уже старенький, а обрезки тьюринга проблемные, хотя чипы мощнее и новее.
> В случае bmaltais - нет
Для гуйни офк нет, но просто поставить коху - гит пулл, венв@торч@реквайрментс, при необходимости раскомментировать дополнительные модули. Бмалтис еще много лишнего тащит для обеспечения остального функционала, он норм, особенно если начинаешь, но потом - неудобен. Например, лоры лучше тренить пачками с варьированием параметров, для будки там отсутствуют нужные параметры
> Вот с этого момента подробнее
Аргументы шедулеров (под них есть поле но для половины оно делает неверное форматирование из-за чего лезут ошибки), аргументы оптимайзеров (в основном работают), тренируемые слои, zero_snr - первое что в голову приходит, были еще. Ну и банально неудобно каждый раз все тащить-вбивать или переназначать даже при наличии сохранения конфигов (если речь о лорах).
> нихуя криминального в использовании плейбука из инторнетов в случае если он тебе подходит и работает - нет
Абсолютно, а что такое плейбук?
> никто не дрочится с деплоем и конфигурированием руками
Там нет дрочки и все относительно просто, проблемы прежде всего в отсутствии норм документации. Как только запросы выходят за рамки дефолта типа (натренить вайфу/натренить на еот) или не удовлетворяет их качество - придется вникать.
> но почему-то в этом треде это вызывает жопное горение
Хз, тут может вызвать пожар разве что когда варебух приходит и начинает что-то требовать, а на вопросы что не так - говорит "а вот у меня хуйня из под хача он мастер и знает как надо, настраивайте".
> Генерирую на чекпоинте пиздохуй.safetensors
Очевидно что сначала нужно проверить на заведомо нормальном, чтобы исключить релейтед к васянизации проблемы. А потом уже разбираться по дефолту. Хз чего тебя тригернуло на этом.
Ну и не эктраполируй мнение возможно вполне уместное, лень сильно сейчас ту нить читать на всех, и сам тут явно предвзят и напираешь на эту тему. Тред не быстрый и сейчас праздники.
Спасибо за пояснения.
>а что такое плейбук?
Суть скрипт с необходимыми действиями для получения готового к работе хоста или внесения изменений в существующий, используется в ansible, но есть еще пяток аналогов. В принципе это можно и шелл/помершелл/бат-скриптами делать, но возможно существуют некоторые нюансы. В основном используется в интерпрайзе, например когда нужно поднять очередной хост с типовой конфигурацией.
>проблемы прежде всего в отсутствии норм документации
Да, я выше уже посетовал на это. Возможно что-то сформирует комьюнити со временем.
>а вот у меня хуйня из под хача
А вот у меня хуйня из-под хача. Но по крайней мере я осознанно сделал этот выбор и осознаю что хуйня из-под хача разворачивает из репы bmaltais - а это дает возможность работы с проблемой не смотря на все прочее энивей. Приходится либо умалчивать про хача чтобы у очередного хлебушка не полыхнуло, либо тыкать носом под настроение.
>сначала нужно проверить на заведомо нормальном
Верное замечание с одной стороны, и я сам хотел его сделать, но по опыту в большинстве случаев к этому прибегают если попробовали уже все что можно.
Как завести коху ебаного на гетерогенной системе?
>гетерогенной
Подробности?
> Вот с этого момента подробнее.
В ваших гуях очень много чего нет из того что появилось за последние пол года.
Разные виды демпинга, типа debiased_estimation_loss. DPO и тренировка RL с ревардами от OpenPose или CLIP. Multistep-тренировка с дополнительными шагами на высоких timestep чтоб меньше уродов было. Референс-модели.
Можно кучу всего ещё по мелочи перечислить.
3090+3060
Дело в том что так называемый "сложный деплой" что кохи, что гуйни - это несколько дефолтных строк в консоль, а гуй - вообще склонировать репу и запустить один скрипт. В случае васян-инсталляторов требуется сначала понять что именно там наделано внутри, чтобы потом не страдать из-за левых костылей или идиотских решений. Особенно если эти васяны - недостойный гной и гниль, не раз пойманная на воровстве и включении вишмастеров. Реакция именно поэтому, а не потому что тут недружелюбные или надрачивают, что именно там внутри врядли кто-то будет разбираться и смотреть.
> В основном используется в интерпрайзе
Здесь не тот случай.
По докам все сложно, если найдешь их - скидывай, в основном обрывки в обсуждениях между теми кто понимает, что печально.
> но по опыту в большинстве случаев к этому прибегают если попробовали уже все что можно
А что у тебя не работает то?
Не стоит. Если реально хочешь - ставь wsl, под шинду в теории сделать можно, но придется собирать аккселерейт с нужными либами, или искать альтернативные пути.
Но вся проблема в заточенность на синхронное исполнение, 3060+3090 дадут скорость как две 3060 и скорее всего окажется медленнее чем 3090. Такое имеет смысл на близких по перфомансу гпу типа 3090+4090 и подобное. Если при конфигурировании выключишь параметр синхронизации - вообще вылетит вскоре после запуска.
Хочешь больше батчсайз - юзай градиент аккумулейшн.
Алсо есть альтернативный путь - трень разные модели на разных карточках, cuda visible devices в помощь.
И обе задействовать нужно, чи шо? Я чет слышал что такое возможно только при обработке разными картами разных же словоев.
Если разные - можно указать нужную при запуске accelerate config, но вот здесь вроде бы эту проблему решили https://github.com/bmaltais/kohya_ss/issues/521 правда с нюансами - зделоли использование VRAM+CUDA на одной карте, и CUDA на второй карте. При том что у 4090 больше VRAM - это может иметь смысл даже если
>>3060+3090 дадут скорость как две 3060 и скорее всего окажется медленнее чем 3090
>Здесь не тот случай.
Для дома тоже используется иногда, например один анон из треда про умный дом в /dom держит плейбуки для ядра, чтобы в случае падения железки можно было развернуть замену за 5 минут.
>А что у тебя не работает то?
Да все уже работает, я имел в виду опыт не с нейросетями, а в принципе - волею случая приходится воевать с разным софтом по работе, запускаться на нестандартных конфигурациях или чинить такой запуск. Но для полноценного девопса мои задачи будут детскими шалостями так-то.
>При том что у 4090 больше VRAM
Наебался. Имел в виду 3090 конечно.
>Здесь не тот случай.
Ну и вообще это аналогия была, я не предлагаю использовать деплой через энтерпрайзные инструменты для нейросетей лол.
>не раз пойманная на воровстве и включении вишмастеров
Соглашусь. Учитывая что пердон разворачивается из архива, а не скачивается из официального источника - это опасненько, тут уж хуй знает что могли туда впихнуть. В остальном firstrun на 10 строк и запуск примерно во столько же, особо вникать не нужно. Вообще ты навел меня на хорошую идею разворачиваться примерно так же, но закачивать тот же гит или пердон через curl из инторнетов. Не думаю что скрипт для этого сильно больше получится, а опасности меньше.
> И обе задействовать нужно, чи шо? Я чет слышал что такое возможно только при обработке разными картами разных же словоев.
Еще как можно и скорость пропорционально выше количеству, каждая видюха обрабатывает свои пикчи (считай батчсайз в N раз больше), а потом результат определенным образом усредняется.
> VRAM+CUDA на одной карте, и CUDA на второй карте
Вут? Это немного другая степь.
> из треда про умный дом
Там нужно быстро провести кучу автоматизированных типовых действий и все. Тут даже действий нет, скачал, нажал и все. Зато потом уже сидишь пердолишься, занимаясь подготовкой датасетов или настройками.
Суть не в нейросетях а в опенсорце. Там где нужно что-то готовое простое использовать - да. Но тут даже не готовый инструмент а кит-набор, с помощью которого разобравшись и настроив можно что-то делать.
> закачивать тот же гит или пердон через curl из инторнетов
Все что нужно - гит клон а потом запустить батник или шеллскрипт. Ну и после установки акселерейт конфиг под свое железо, если хачелла там конфигурирует под бф16 по дефолту а у тебя карточка младше ампера - то земля пухом бай дефолт скорее всего.
>https://github.com/bmaltais/kohya_ss/issues/521
У меня при таких же настройках происходит краш как в ишуях, фикс в library/train_util.py помогает, но тренировка происходит только на первом гпу, а если задать число процессов 2 то там такие ошибки, как будто запустили 2 раза тренировку на разных гпу, лол.
Какая система стоит на пекарне где идет обучение?
Винда, а акселерейт запускает гуи от дериана, который уже запускает коху. Пробовал и наоборот, чтобы гуй запускал акселерейт фиксом в main_ui_files/MainWidget.py, тоже что-то не получилось. Позже попробую без гуя короче.
> DPO и тренировка RL с ревардами от OpenPose или CLIP. Multistep-тренировка с дополнительными шагами на высоких timestep чтоб меньше уродов было. Референс-модели.
И это всё уже есть у кохьи? В патч ноутах только про debiased_estimation_loss
Под шинду дефолтный акселерейт не может в мультигпу. Если пройдешь по пути поиска ошибок то придешь к отсутствию нужных параметру и заглушке о том что ваша версия - говно, а при попытке собрать нормальную столкнешься с отсутствием всякой херни, если писать коротко.
На любом линуксе или wsl аккселерейт из коробки может. Просто установи убунту из магазина, а на нее накати тот же гуи и пользуйся им. Бонусом будет работать быстрее.
При конфигурировании аккселерейта выставляешь this mashine, multi-gpu, 1, Should distributed operations be checked while running for errors? - Yes, FullyShardedDataParallel - No, all или 0,1 на списке гпу. При запуске оно само запустится на двух гпу без доп параметров, но можешь их указать, в мане к аккселерейту есть. Эффективный батчсайз будет больше в 2 раза, учитывай это при задании числа шагов/эпох/повторов датасета.
>Эффективный батчсайз будет больше в 2 раза, учитывай это при задании числа шагов/эпох/повторов датасета.
Как он может быть в 2 раза больше, если у 3060 не хватит на такое видеопамяти? Придется урезать заданный батч сайз ровно в два раза, чтобы уместить? Какая же неповоротливая хуита.
>wsl
б-же упаси
> Как он может быть в 2 раза больше, если у 3060 не хватит на такое видеопамяти?
Ты не понял, при запуске будет работать в 2 потока каждый с заданными параметрами и на своей видюхе. Результат будет как с батчсайзом в 2 раза выше, поэтому нужно скорректировать число шагов, уменьшив в 2 раза.
> Придется урезать заданный батч сайз ровно в два раза, чтобы уместить?
Нет, на 3060+3090 придется выставлять тот, который влезет в 3060 ибо она ограничивающий. Возможно полезут еще какие-то подводные из-за асиметричного конфига или будет вылетать, оно и на симметричной системе может упасть если, например, подключать мониторы/телек.
> б-же упаси
Тогда ставь полноценный линукс и грузись в него. Или займись добавлением поддержки в шиндовскую версию, оба варианта несравнимо затратнее.
> И это всё уже есть у кохьи?
Ну коха слишком тупой чтоб это запилить, но в форках есть.
Да, вообще покури доки пустил слезу и код кохи, возможно всеже можно задать разный батчсайз на девайсах чтобы получить ускорение на подобных ассиметричных, или это уже как-то реализовано.
Так это ты не понял, я вот это имел в виду
>на 3060+3090 придется выставлять тот, который влезет в 3060 ибо она ограничивающий
На 3090 получается 12 гигов будут простаивать, что есть половина.
>ставь полноценный линукс
Давно бы уже накатил и радовался бы жизни. А так бля какая же хуйня, только на линуксе не под wsl блядь работает одна половина софта, только на винде другая половина, а я использую комп как сервер блять и мне нужно чтобы он 24/7 работал. Пидорасы.
>задать разный батчсайз на девайсах
Походу все же придется курить. Пиздец бля, уверен что запилить такую фичу с уже рабочим аккумулейшеном на мультигпу это дело 10 минут, просто прописав опции в конфиге, но ее до сих пор походу нет.

>в форках
Тише, тише, а то услышит юродивый и завизжит про мокрописечную хуету
Бля, на пик не обращайте внимания. Я хотел ответит с ним, но потом понял что вощем-то просто и не за чем.
> На 3090 получается 12 гигов будут простаивать, что есть половина.
Ага, увы, может получиться не ускорение а наоборот замедление. Возможно как-то можно, но вероятность сделать малой кровью, без больших правок кохи, мала, когда в свое время смотрел - было крайне примитивно средствами аккселерейта.
Если что-то получится - выкладывай.
> Пидорасы
Двачую
Блять, васяны рили этот пиздец с зашкваренными бинарниками хавают, вместо того чтобы скачать полноценные версии гита и питона?
Почему вы все до сих пор дрочитесь с юнетом и сд, когда есть дит и пиксарт?
Говно же
А ты пробовал?
О, точно, нужно их хотябы понюхать пока есть свободные дни. В любом случае наличие комьюнити и уже готовых средств запуска и обучения - крайне серьезный фактор.
Да





>пиксарт
Попробовал загуглить и проиграл
Пиксарт как модель ничего нового не предлагает, оно и понятно, бюджет у них меньше чем у сд 1.X почти в 12 раз. Да, понимание промпта присутствует (в первую очередь за счет большого Т5), но вот картинка все равно получается говном из-за малого размера денойзера, тут уже ничего не поделать.
Какой-то уровень дримбудок образца сентября 2022г.
Там основная причина говна — всратый и маленький датасет
И это тоже.




На самом деле я неправильно загуглил прост, но проигрывать не перестаю.
Их там много, в каких конкретно?
а при чем тут чекпоинт СД и чекпоинт клипа, это ж разные вещи. Если использовать клип через интерргейтор, то ты модель прям там выбираешь, и там нифига не СД модели a всякие vit16-h

В поисках информации попался видос (из тех, что 3,5 штуки на русском) про сравнение базовых настроек при обучении лор. Таблица пикрил, оценка субъективна.
От себя добавлю что dim=16 alpha=8 тоже канают.
Сам видос тут https://www.youtube.com/watch?v=_8_k9LUOEes
От себя добавлю что dim=16 alpha=8 тоже канают.
Сам видос тут https://www.youtube.com/watch?v=_8_k9LUOEes
Уже пара месяцев прошло, а sd 1.6 так и не открыли...
А оно его живое? Вроде как упоминание повышенных разрешений из релиза вообще убрали...
Кстати о повышенном разрешении. Realistic Vision 6 тоже планировался как повышенное разрешении. Но в итоге и на заявленном 800+px выходит глючное говно
И еще там в комментах пишут, что переобученно на голых девушках, и выдает их даже тогда, когда не просят. Ну и в плане реализма - тоже говно, даже близко не EpicPhotogasm
Короче очень разочарован в realistic vision 6
Когда завезут в SD zero-shot персонализацию и фидбэк? (Типа как finetune в реальном времени, когда пользователь оценивает сэмплы и модель медленно дообучается по оценкам, в CharacterAI было такое)
Завези. Софт развивается сообществом
(А вообще звучит как что-то очень требовательное)
> когда пользователь оценивает сэмплы
Такое уже есть, 24гб врам для простых генераций приготовил?
> в CharacterAI было такое
Это вообще не близко к файнтюну и влияло крайне редко и опосредованно, 99.x эффекта - плацебо для пользователя.
Какое хорошее значение constrain для COFT?
> Такое уже есть, 24гб врам для простых генераций приготовил?
Где? 24Гб врам есть.
1
А, это я уже видел. Мертворожденный проект.
Как в публикации - 1е-5. На 1 от него результата ноль, с тем же успехом можешь выключить просто.
Пробовал уже по пейперу, с 1е-5 слишком слабо, без него пережарка быстрая, видимо надо пробовать промежуточные.
Алгоритм прошлогодний https://github.com/KohakuBlueleaf/LyCORIS/blob/main/docs/Algo-List.md#diag-oft
> с 1е-5 слишком слабо
Чем меньше, тем эффект сильнее.
> пережарка быстрая
OFT тренируется сильно быстрее, он не работает с теми же lr что и обычные лоры. Ставь lr раз в 10 ниже, не выше 5е-5. И я надеюсь ты там не жаришь по 10+ эпох. А лучше вообще не используй его, если не можешь осилить настройку.
С constrain 1e-3 уже почти не отличается от лоры, надо его чуть понизить вместе с лром и будет норм.
> И я надеюсь ты там не жаришь по 10+ эпох.
Скорее всего слишком долго тренил и лр был слишком большим.
У меня есть около 4к картинок с тегами, мне нужно протегать еще столько же в подобном стиле. Есть ли где то гайды как можно натренить свою модель для распознавания того что на картинке?
Берешь и файнтюнишь BLIP2. В чём проблема? Всё найдёшь в документации HF.
> Алгоритм прошлогодний
Ха ха 🤦🏻♀️
> протегать еще столько же в подобном стиле
Что за стиль? 4к пикч, наверно, будет маловато для тренировки клипа или чего подобного, но можно попробовать.
Если стиль описания дефолтный (натуртекст или буру теги) то есть готовые решения.
Если там что-то хитровыебанное то поможет комбинация вд-теггера, клипа, мультимодалки и ллм, с ними можно сделать почти любые описания без необходимости тренировки, если офк там не что-то суперспецифичное.
В большинстве своем это рендеры с койкатсу, моя цель что бы она узнавала персонажей и только. Если есть гайды как это все сделать, то я бы был крайне рад.
Можно меня лицом тыкнуть, куда мне копать?
Если персонажи популярные и их модельки там качественные - их имеющиеся модели будут узнавать. Если такого нет - нужно свою тренить. Если в этом будешь успешен или что полезное накопаешь - поделись потом.
Нахуй не нужно, неудобная хернь.
Зерошот должен быть в виде промпта - даёшь ему набор рефов, даёшь промпт что именно из них вытащить (бабу, дерево, веснушки, спицы колеса, прямые углы, красные цвета, стиль наброска), он вытаскивает и это потом можно использовать при генерации.
Лороделы! Ай нид ё хелп!
Какой пресет выбрирать в kohya_ss?
Я пытаюсь сделать лору на простой концепт. Для этого как я понял надо поставить Network Rank и Network Alpha поменьше, что бы не сильно корявило стили. Но эксперименты показали что очень сильно на результат влияет Optimizer. Пробовал разные, но так и не понял какой самый крутой.
Вроде в кохе есть куча пресетов, но хрен просышь какой и для чего нужен.
Какой пресет выбрирать в kohya_ss?
Я пытаюсь сделать лору на простой концепт. Для этого как я понял надо поставить Network Rank и Network Alpha поменьше, что бы не сильно корявило стили. Но эксперименты показали что очень сильно на результат влияет Optimizer. Пробовал разные, но так и не понял какой самый крутой.
Вроде в кохе есть куча пресетов, но хрен просышь какой и для чего нужен.
Не все мысли написал. Генерю для sdxl.
И суть проблемы в том, что какой бы я пресет не выбирал, такое чувство что через 20 минут лора перестаёт обучаться. avr_loss - не меняется (даже увеличивается). Семплы которые я через каждые 200 шагов делаю по качеству не отличаются.




Интересно, на этой херне контролнет возможно сделать? Было бы прикольно
https://orhir.github.io/pose-anything/
https://orhir.github.io/pose-anything/
Нахуй не нужно, сам попробуй демо, работает крайне погано с очень плохой точностью.
Листаю твиттер градио - они там видосы с демками выкладывают разные. И их ссмщик не знает как звук при записи с экрана отключать, и слышны сопения, зеляик мыши и т.п. Кринж бля
> зеляик мыши
Бля
Ну так если будет контролнет, то это особо значения не будет иметь, что точность приблизительная. А так, поза - это, наверное, самый главный концепт для контроля. Т.к. форма и всякие линии - это слишком уникально


В общем говно это все. За 2 месяца пролистал, из интересного - это только этот pose anything, и magic animate. Нашел что тут его вскользь обсуждали, сказали говно качество. Да и по примерам видно
А еще StyleAligned Controlnet - круто. Наверное даже круче тех двух
Остальное - бесконечные text2image, нашли чем удивить. И еще хуже: text2music. Этим нейронкам уже лет 5 наверное
А еще StyleAligned Controlnet - круто. Наверное даже круче тех двух
Остальное - бесконечные text2image, нашли чем удивить. И еще хуже: text2music. Этим нейронкам уже лет 5 наверное
Но этот твиттерский левацкий вайб, конечно, дико бесит. Пошел он нахуй
Тебе перед использованием ещё надо будет референс рисовать руками.
Печалька
На я больше боюсь, что он для контролнета вообще не сгодится, лол
Можно, конечно, его на что угодно можно натренить, включая и на парах картинка-выхлоп этой штуки. Получится годно. Как тренить, показано здесь. https://github.com/lllyasviel/ControlNet/blob/main/docs/train.md
> Note that if you find OOM, perhaps you need to enable Low VRAM mode
> Note that training with 8 GB laptop GPU is challenging.
Выходит тренировка доступна на десктопных гпу, почему тогда моделей контролнета так мало?
Это получается можно как минимум сделать свой скелет, отличающийся от имеющихся, потратить какое-то время на составление датасета, где он выставлен под генерации, и новый контролнет готов?
Сап аноны, экспериментирую с лорами, треню конкретные участки тел тянок. Например сейчас зеттай область. Да, они скорее всего есть, но у меня научный интерес. Датасеты без лиц и мишуры, чисто тематический ручной кроп. В целом выходит неплохо, но картинка слегка желтеет и становится какой-то немного другой стилистически. Это проходит, если уменьшать номер эпохи и веса, но тогда проходит и целевой эффект.
Мне копать в сторону понижения ранга/альфы? Насколько я понимаю, ранг соответствует количеству "идей", которые лора усвоит в тренинге, возможно желтизна одна из них. Но непонятно, усвоит ли она именно геометрию, а не что-то другое.
Фиксить ли колор левелы в датасете? (Они в целом не желтые)
Алсо стараюсь фиксить кепшены после блипа, но они куцые и повторяются.
Может мне вообще кепшены не делать?
Не делать тематический кроп? (Тогда вылезают особенности окружения)
Вредна ли регуляризация в таком случае? Например supermodel подходит, судя по пикчам. Если правильно понимаю, она помимо всего участвует в контрасте между как обычно и как с лорой.
Делал ли кто свой класс регуляризации?
Из того, с чем пока игрался, это snr gamma, swn. Треню обычно lr=1e-4, ulr={1,2}e-4, dim/a=128, adafactor+cos (12гб жрет), bs=2, ориентирусь на 3000 шагов / 10 эпох. База 1.5 прунед 7гб с морды. Пришел к этому набору на лицах.
Советуйте плиз, датасаентисты.
Я и сам пробую, но полчаса на итерацию -- печально как-то все это дерево вариантов перебором искать.
Все гайды тренят чаров или хуй в пизде, которые вместо мягкого добавления меняют вообще все. Бесполезные
Мне копать в сторону понижения ранга/альфы? Насколько я понимаю, ранг соответствует количеству "идей", которые лора усвоит в тренинге, возможно желтизна одна из них. Но непонятно, усвоит ли она именно геометрию, а не что-то другое.
Фиксить ли колор левелы в датасете? (Они в целом не желтые)
Алсо стараюсь фиксить кепшены после блипа, но они куцые и повторяются.
Может мне вообще кепшены не делать?
Не делать тематический кроп? (Тогда вылезают особенности окружения)
Вредна ли регуляризация в таком случае? Например supermodel подходит, судя по пикчам. Если правильно понимаю, она помимо всего участвует в контрасте между как обычно и как с лорой.
Делал ли кто свой класс регуляризации?
Из того, с чем пока игрался, это snr gamma, swn. Треню обычно lr=1e-4, ulr={1,2}e-4, dim/a=128, adafactor+cos (12гб жрет), bs=2, ориентирусь на 3000 шагов / 10 эпох. База 1.5 прунед 7гб с морды. Пришел к этому набору на лицах.
Советуйте плиз, датасаентисты.
Я и сам пробую, но полчаса на итерацию -- печально как-то все это дерево вариантов перебором искать.
Все гайды тренят чаров или хуй в пизде, которые вместо мягкого добавления меняют вообще все. Бесполезные
>почему тогда моделей контролнета так мало?
Технических препонов немного. Просто 99% сообщества кумеры с выжженными мозгами, и кроме дрочбы рулетки и прумптинга 24/7 ничем не интересуются. В SD довольно много непочатых краёв, которые дадут неплохой арт-инструмент если ими заняться. Но диаграмма Венна между людьми которые могут сделать что-то интересное и знают какой инструмент им нужен, людьми которые умеют тренить что-либо, и людьми которые юзают SD, исчезающе мала. (
>Это получается можно как минимум сделать свой скелет, отличающийся от имеющихся, потратить какое-то время на составление датасета, где он выставлен под генерации, и новый контролнет готов?
Ну да, и не обязательно скелет. Контролнет это универсальный механизм. Можно его натренить на пары "позиция камеры"-"пикча", или на нарисованную позицию источников света (на цивите есть такие эксперименты), на всё что угодно.
Это то же самое, но с другой оболочкой.
Попробуй разбавить кропы некропнутыми примерно пополам или в другой пропорции, желательно чтобы были разнообразны. Что по описанию к пикчам?
> копать в сторону понижения ранга/альфы?
Альфу попробуй снизить (с повышением лра), размерность для начала не трогай.
> прунед 7гб
Вут?
> которые вместо мягкого добавления меняют вообще все
Нормальные не портят ничего лишнего.
Грусть-печаль.
Про универсальный механизм - согласен, просто новый скелет кажется достаточно простым с точки зрения составления датасета и дальнейшего использования, как раз чтобы попробовать. Если есть что релейтед почитать про это - будут благодарен.
Пробую завести Nerogar/OneTrainer. Кто-то пробовал уже эту казуальную штуку с одной кнопкой "зделоть лору заебись"?
Нет, она бы наверное у меня завелась и так, поставь я в систему гит с питоном. А так я ей накидал потрохов от хача и насрал в батник с запуском кастомными set env по аналогии. Чето качает теперь наверное майнеры, ух бля.
Нет, она бы наверное у меня завелась и так, поставь я в систему гит с питоном. А так я ей накидал потрохов от хача и насрал в батник с запуском кастомными set env по аналогии. Чето качает теперь наверное майнеры, ух бля.


Однако здравствуйте, кое-как запустил руками.
Я не знаю что будет на выходе, но в кохе у меня было 50s/it+, а здесь просто космические 3-5s/it.

Одна беда, из памяти она не выгружается, VRAM так и забит. Возможно для этого есть где-то в интерфейсе триггер, но я пока не искал. А запускать ее заново руками мне дико лень, буду завтра пердолить батник, половину которого спиздил из-под хача. Нагенерю хуйни сегодня, а завтра тестировать буду.
А еще эта штука может тренить по маске, и более того, сама эту маску генерит. Ну охуеть вообще.
А можно как-то отдельно мёрджить текст и юнет?
Оно уже научилось работать без гуёв, чтобы можно было запустить не на жалких 24ГБ, а на большом утюге?
>в кохе у меня было 50s/it+, а здесь просто космические 3-5s/it
Скорее всего потому что в кохе врубил/не врубил что-либо, не должно быть такой разницы. Коха наркоман, хуёво документирующий свои поделия
Думается мне что оно умеет работать без гуев, просто разраб не выложил ключи запуска. И кто-то с более сильным кунг-фу вполне может расковырять/отдебажить чтобы ты мог запуститься на своем ботнете из роутеров лол.
Разбавить попробую да, чот не думал об этом.
>прунед 7гб Вут?
v1-5-pruned.safetensors https://huggingface.co/runwayml/stable-diffusion-v1-5/tree/main
Я поначалу тренил на чекпоинтах, потом прочитал, что правильно на базе. В автоматике была по-дефолту(?) емаонли (== 4.1гб по ссылке), подумал - она. Но выходило говно. Потом я допер и где-то прочитал, что это не для тренинга модель и скачал v1-5-pruned. Не знаю правильно или нет, но стало нормально.
>Что по описанию к пикчам?
Делаю блипом за что меня обосрали в базовом треде и послали в cogvlm с докой на китайском, по которой я кажется сам должен написать плагин для кохи, хз и правил руками / смотрел. Но конкретно щас пикчи такие, что и блип норм справляется. Там 90% собственно концепция на симпл фоне, плюс минус цвет одежды.
-
Вчера сам альфу скинул до 1, желтизна ушла. Лучше всего получилось вообще без кепшенов, видимо из-за датасета. Лры пока не трогал, попробую. Я их вообще боюсь трогать, потому что их три за каким-то хером.
Спасибо за советы, анон!
В целом все правильно, только без капшнов совсем лучше не стоит, оно будет всирать когда более гибко применить захочешь.
Блип для простых пригоден более чем, ког для чего-то заморочного, и то не факт что обучится. Лры - тот что для unet равен базовому, тот что для te - в диапазоне от 0.5 до 1 от базового.
Вот эти
https://github.com/Nerogar/OneTrainer/blob/master/modules/util/args/TrainArgs.py#L253
Передавать судя по всему надо сюда
https://github.com/Nerogar/OneTrainer/blob/master/scripts/train.py
И в целом смотрите "modules/utils/args/xxxx.py" для аргументов scripts/xxxx.py.
Питонисты, вечно распиздячат все по разным папкам в папках в папках в классах в бейзклассах в метаклассах, блять. Кода на три копейки, но хуй чо найдешь, будто в миллионнике ковыряешься. Хвала всевышнему за иде прям в гитхабе


Что может вызвать отключение питания на видеокарте и отрубание компа с крит ошибкой питания, после нескольких генераций в sd, даже если нету нагрузки, а только был открыт webgui с загруженым в память sdxl чекпоинтом? На фукусе была та же фигня с другими моделями Он там 60% памяти занимал примерно из 12гб на 4070 от гигабайта. Стресс тесты и игры нормально держит
может кто встречался с таким
может кто встречался с таким
а что предшествовало кернел пауэру то глянь в журнале событий
обычно полное отключение это невывоз блока питания пука с просадкой по одной или несколким линиям и уход блока в защиту, или может файлы винды поломались и надо восстанавливать чрез дисм и сфцсканнау, но во втором варике обычно бсод
из-за драйвера видяхи маловероятно, т.к. саму видяху просто ебануло бы и переключило на встройку, если конечно у тебя не старый срузен без встроенного граф ядра
>даже если нету нагрузки, а только был открыт webgui с загруженым в память sdxl чекпоинтом?
а нагрузка на видяху с процем есть даже если ты вебуи запустил, питоновская среда исполнения, в вебуйке даже багуля есть забавная которая ломает карту если недостаточно памяти - вставка через ктрл+в изображения в инпеинт и попытка начать рисовать маску поверх, начинается бесконечное расширение виртуального рабочего разрешения окна для рисования что вызывает фризы вебуя и в итоге краш карты если не успеть нажать крестик на рабочем поле
Спасибо за рассказ про все варианты, я думаю ты прав насчет блока питания, скорее попался дефектный и не держит на малых нагрузках
Вообще хуйня какая-то, БП должен норм держать в простое, это под нагрузкой он может посыпаться если хуевый.
Ну канеш есть еще вариант когда БП и в простое хуевые показатели дает, просто потому что хуевый сам, но тогда отказы были бы и просто при серфинге с выгруженными AI-инструментами.
Бп не модный сосоник невысокой мощности или его аналоги случаем? Они триггерились на всплески потребления амперов-ады, хотя мощность при этом не была превышена.
Были косячные серии, в которых "умная защита" была настроена чрезмерно агрессивно, срабатывание шло по скорости изменения потребления а не самой мощности. Могло отрубить и на малой нагрузке, такие бп меняют по гарантии.
Но это только версия, стоит проверить журнал как расписано
https://www.dns-shop.ru/product/8dfa7785edb83332/blok-pitania-cooler-master-mwe-gold-850---v2-full-modular-mpe-8501-afaag/opinion/
Сейчас долго ставил тесты на стабильность с 10% 40% нагрузкой, а потом комп опять вырубился, да еще и вместе с еще с сетевым фильтром и монитором.
А потом сразу после загрузки винды стал обрывать питание. Резкие всплески при генерации как раз могли тригернуть дефектный бп, который до этого еще держался при стабильных нагрузках. В днс в коментах у некоторых он тоже накрылся. Спасибо за помощь, может по гарантии пройдет
>мусор мастер
Хотел выпендриться? Нет денег - бери любой DeepCool. Есть деньги? Бери дорогой DeepCool. Брат жив: PF750 год 4(!) 3060 непрерывно держал, сейчас PX1000 держит как скала 4090
> DeepCool
Это же китай говна. У кулер-мастера хорошая 1200 платина есть, в отличии от глубокого охлаждения.
Точнее у меня тоже на 750, я его специально брал из этого списка b tier
https://cultists.network/140/psu-tier-list/
> Это же китай говна.
От владельца
>мусор мастер
смешно слышать.
Почитай про платформы, что использует DeepCool. Это хотя бы что-то, в отличие от вентилятор-мастера.
да не это другой анон, я согласен, что дип кул делает качественные вещи, у меня корпус и охлад от него, просто на момент сборки не было доступных моделей по типу
https://www.dns-shop.ru/product/56ad175cfa53d763/blok-pitania-deepcool-pq750m-r-pq750m-fa0b-eu/
Вы оба бредите. Что у мусормастера, что у дуплокула, нет топовых платинум моделей. Я бы не стал втыкать две 4090 в дупло кула.
> две 4090
Уже появился смысл?
> Требования к системе для обучения SDXL выше, чем для обучения SD 1.x.
Сколько надо VRAM для XL лоры? Мне 12 не хватает даже обучение 128x128 пикч запустить.
Сколько надо VRAM для XL лоры? Мне 12 не хватает даже обучение 128x128 пикч запустить.


>Нет денег - бери любой DeepCool. Есть деньги? Бери дорогой DeepCool
Я б не был столь радикальным в брендах, это ж всетаки просто сборный компонентный девайс. То есть ситуация с бп как с оем смартфонами - бренды просто заказывают сборку с нужными хар-ками заводам других брендов (или подвалу) в корпус со своей шильдой. То есть буквально покупка любого бп это лотерея, где ты только посмотрев внутрь сможешь понять чей на самом деле это бп и где был сделан. Конкретно дипкул заказывает у Channel Well Technology бп, которые делают естественно не только для дипкула. Собственно поэтому с кулермастером больше лотерея - они сборку заказывают не у одного завода, а у нескольких, то есть по факту в одной и той же модели может быть разная компонентная база, то есть больший рандом.
Так что я бы выбирал бп примерно так: берем вендора, смотрим с какими бп заводами сотрудничает, если там больше одного - скип просто потому что труднее контролировать качество, далее смотрим на спецификации и наличие всех нужных защит, далее на шильду 80Plus по 12в, и наконец пытамеся найти видос с разборкой блока, желательно от челика который разбирается в пайке, обвязках и кондерах (с видяхами проще, есть ремонтники ютуберы которые нормально рассказывают про то почему и в каких местах видяхи сосут и насколько часто).
То есть если выбирать из условного дипкула и кугара, то я бы выбрал кугаровские, потому что кугар это прямой дочерний бренд завода по производству бп HEC, а дипкул это оемщики.
>PF750 год 4(!) 3060 непрерывно держал, сейчас PX1000 держит как скала 4090
Статистически несущественный опыт на самом деле.
У меня вот есть бп ocz stealthxstream 2, этот бп работает не выключаясь уже 13 лет, со стоковым вентилятором причем, и даже спустя столько лет спокойно вытягивает 2 карты за раз под свою мощность, притом что у него есть софтверная просадка по 12в линии на 11.7в (не напрямую зачеканная, а через датчики имею в виду), я его один раз вскрывал и там ни намека на какие-то неполадки в обвязке. И не у меня одного судя по пикам. Оем ли ocz? Нет, сами производили. О чем это говорит? На самом деле ни о чем, просто квалити контрол выше из-за безоемности и всё.


>PF750 год 4(!) 3060 непрерывно держал, сейчас PX1000 держит как скала 4090
Типичная ошибка выжившего - я вот выиграл в лотерею и вы играйте, деняк заработаете ух бля.
Напомню положнях из /hw, не дипкулом единым.
Разумные слова, не поспоришь
Емнип для обучения XL минимум 16, но это не точно.. Попробуй включить все оптимизации, в т.ч. эффективный атеншн и градиент чекпоинтинг (меняет результат тренировки!).
> Хотел выпендриться?
А только пукнул в лужу, устроив анрелейтед срач, пиздуй в hw на бренды дрочить, и суперфлавер тебе в анус.
> Я б не был столь радикальным в брендах
Абсолютно, особенно учитывая что даже у "именитых" до половины ассортимента - странный OEM, а самые йобы имеют провальные и проблемые модели. Плюс от брака никто не застрахован, увы.
Алсо прилично расписал за анализ. Вообще есть смысл рассматривать конкретные модели и обзоры на них после отсеивания, а 80+gold и dc-dc на +5 вместо не дай бог ДГС это вообще входной порог.
>это творчество душевнобольных
Хорошо что я не хожу в /hw/
Аноны, есть ли какой-то тул, чтобы из видео вынимать кадры с лицами, причем желательно:
- только без артефактов
- только при существенном изменении (смена выражения, позы, етц)
?
Вынималки гуглятся, но хочется именно фильтр по качеству и дифференциальность.
- только без артефактов
- только при существенном изменении (смена выражения, позы, етц)
?
Вынималки гуглятся, но хочется именно фильтр по качеству и дифференциальность.
Подскажите пожалуйста, почему kohya_ss сначала выдавала нормальную скорость, а теперь работает в 10 раз медленнее, хотя никакой конфиг не менялся. По сути все осталось тем же самым, что было до.
>Оно уже научилось работать без гуёв
>Передавать судя по всему надо сюда
Внезапно на гитхабе расписано че и куда передавать.
Но помимо этого можно не лопатить тысячи параметров руками в текстовом виде, а запустить на пеке, намышевозить в гуе и сделать экспорт параметров. И экспортированный файл запускать в CLI хоть где.
Все, я разобрался, я идиот, делал дримбут, а не лору.
Мне кажется, или автоматик на неактивной вкладке генерит значительно медленнее, чем если ее на экране держать?
> Мне кажется
Да. Таблетки два раза в день и пройдёт.


Таблетки не помогут. Ведь мне таки не кажется.
Латентный и2и х2 апскейл с двумя модулями контролнета, DPM++ 2M Karras, 20 шагов, 4 картинки подряд.
Первый пик - держал вкладку открытой.
Второй - переключался между двачом и ютубом (ютуб в фоне работал и на первом прогоне тоже), на вкладку с автоматиком принципиально не заглядывал, пока прогресс до 100 не добрался.
Причем, судя по ощущениям, максимум тормозов случается на финализациях картинок. Т.е. на 23-47-073-97%
Такой хуйни не должно быть, потому что бровзер только отображает что происходит внутри каломатика. (что за браузер кстати?)
Навскидку могу предположить что фоновая вкладка гасится по-максимуму, поэтому либо отображает пикчу 4 минуты (превьюшки включены?), либо ещё как-то тормозит отображательную часть процесса, а не саму генерацию.
>что за браузер
Мозилла.
>превьюшки включены
Нет. Выключены. Вообще на медврам запускаю.
>Такой хуйни не должно быть
Вот и у меня такая же реакция сейчас.
Что? Почему? Непонятно.
Сейчас без контролнета запустил, просто и2и - тоже тормоза. Виснет на финализации картинки наглухо практически. На вкладку переключаюсь - и тут же генерация продолжается.
Нашел .json в гугле для kohya. Завелось на 11.7гб 1024x1024.
Обычно на неактивной быстрее если включен лайфпревью, тогда его не делает.
Используешь видеопамять другими вкладками, дело не в активности вебуя а другой нагрузке.
> максимум тормозов случается на финализациях картинок
Отрабатывает VAE, на разрешениях побольше требует много памяти. Tiled Diffusion костыль и tiled vae в его составе в помощь, или просто снизь батч сайз.
Какое разрешение пытаешься делать? Оптимизации (xformers/sdp) включены?
Какие там параметры, можешь скинуть?

Это были буквально две абсолютно идентичные генерации, но на активной вкладке весь процесс занял в пять раз меньше времени.
Не думаю, что VAE, батчи, иксформерсы и тайлад диффужн тут хоть как-то влияют - в браузере же тоже ничего не менялось, набор вкладок оставался тот же самый, я просто сменил активную с автоматика на двач.
Очень странные вещи у тебя происходят. Процессы там асинхронны, ты можешь нажать кнопку generate, подождать долю секунды чтобы запрос достиг хоста, а потом вообще закрыть браузер - генерация будет продолжаться пока не отработает то что было задано и браузер на это никак не повлияет. Потому наиболее вероятен описанный случай, попробуй для начала отключить аппаратное ускорение в браузере.
Алсо включи в шинде gpu hardware scheduling, выстави план питания на перфоманс и проверь что происходит с частотами и нагрузкой на видеокарту в момент когда вкладки переключаешь. Или нет у тебя там какого-нибудь майнера, который проц на 100% занимает.
Также чекни dpi и аппаратные ошибки, первое в latency mon, второе сразу в hwinfo можно глянуть в самом конце.
>максимум тормозов случается на финализациях картинок
У меня так происходит когда врам кончился.
И он будто "свапается", видимо в рам хз что там на самом деле
> Мозилла.
Я в последнее время тоже испытываю проблемы - на финале генерации отваливается сессия по таймауту, хотя раньше такой хуйни не было. Плюс ко всему после окончания генерации страница подвисает и фурифокс спамит сообщениями о замедлении на этой странице. ЧСХ если на страницу перезайти - все ок становится до следующего раза. Дико бесит
Vae decoder
Да, я знаю про асинхронность и всё такое.
Сегодня решил на хроме потестить - так проблема и на мозилле перестала воспроизводиться. Хотя все условия воссоздал - и набор вкладок, и запущенный видос, и открытый файл в фотошопе.
Майнера точно нет, заметил бы.
Аппаратное ускорение отключил на всякий случай.
Ничерта непонятно, короче.
Можно ли зафайнтюнить wd tagger, чтобы распознавало новые таги?

Рейт график
Надо просто заменить danbooru.csv в расширении на новый. Вроде как в imageboard grabber можно было скачать теги в таком виде. https://github.com/Bionus/imgbrd-grabber
Бля, жопой вопрос прочитал.
Разобрался с тем, как запустить magic animate. На самом деле поразительно, не смотря на плоховатое качество
Решил сравнить оригинальное видео со сгенерированным на снятом с него же denpose, и первым кадром. Прикольно, но не практично. Я думал можно синпаинтить что-то на первом кадре и распространить это на все видео. Но не получится, так как видно, что видео хоть и похожи, скомбинировать их малозаметным швом не получится
По поводу скоростей, rtx 3060, генерация denpose рose быстрая, в magic animate получается сгенерировать видео максимум 2 секунды (25фпс), на большее не хватает памяти. Время генерации около 10 минут
Установить саму демку проблем не было, разве что тупой hugging face качал в кеш сразу весь репозиторий sd1.5, с моделями во всех возможных форматах в сумме на 44гб. Но больше проблем не было
А вот с denpose проблем было куча. Криво настроены зависимости как-то. Долго мучился, чтобы запустить локально
Решил сравнить оригинальное видео со сгенерированным на снятом с него же denpose, и первым кадром. Прикольно, но не практично. Я думал можно синпаинтить что-то на первом кадре и распространить это на все видео. Но не получится, так как видно, что видео хоть и похожи, скомбинировать их малозаметным швом не получится
По поводу скоростей, rtx 3060, генерация denpose рose быстрая, в magic animate получается сгенерировать видео максимум 2 секунды (25фпс), на большее не хватает памяти. Время генерации около 10 минут
Установить саму демку проблем не было, разве что тупой hugging face качал в кеш сразу весь репозиторий sd1.5, с моделями во всех возможных форматах в сумме на 44гб. Но больше проблем не было
А вот с denpose проблем было куча. Криво настроены зависимости как-то. Долго мучился, чтобы запустить локально
Хотя не, на самом деле 5 секунд влезает в 12 гб. Что ж тогда влезает в 24 гб, если разница между 2 и 5 всего пара гб
А если заморочиться с интерполяцией кадров, то можно и 10-20 секунд выжимать
Нихуя нипонимаю, как оценить качество лоры? Допустим я натренил 50 эпох, начиная с 30 уже получаю то что мне нужно. Есть ли какой-то объективный метод выбора, чтобы не запускать на лору с каждой эпохи генерацию в сотню изображений и смотреть какая лучше? Где-то тут инфа проскакивала что нормальная лора будет выдавать результат от 0.8 до 1.2, но это все равно вкусовщина же. Смотреть логи через тензорборд и кривую обучения? А на что внимание обращать?




У меня то что нужно с 6-7-й получается, треню 10 для галочки, там все равно косинус.
У вас какие-то особенные эпохи что-ли, или 1 рипит из 20 пикч на эпоху?
У меня получается говно? Речь о сложных концепциях?
Объясните плес.
У лор с цивика тоже бывает вижу 000005-000009, 000030-40 не видел.
>У вас какие-то особенные эпохи что-ли, или 1 рипит из 20 пикч на эпоху?
>У лор с цивика тоже бывает вижу 000005-000009, 000030-40 не видел.
Я треню на черты лица. Глянул мельком три с цивика (img-repeat-epoch) - для гарольда 1100-100-1, Эмма Ватсон 999-9-3, Даддарио 3600-100-1 и то говно какое-то генерирует, у меня лучше. Так что я еще малой кровью обхожусь со своими 400 пикчами на 1 репит и 50 эпох лол.
2000-3000 шагов же стандарт обычно.
И то 3000 - это лютый оверкилл, я что ни тренил - обычно насыщение наступало в районе 1500 шага, а иногда вообще на 700-м бывало.
>черты лица
А чо это такое, из разных лиц черты собираешь что-ли?
Типа "усредненный расовый кавказский монголоид"?
>пикчи
Говно или как? У них 3-3.5к степов в сумме.

Я тоже думаю он куда-то не туда смотрит
"ss_dataset_dirs": {
"100_harold": {
"n_repeats": 100,
"img_count": 11
}
},

Хуй знает как у тебя так, у меня все параметры близкие к дефолтным, LR:0.0001, ND:16, NA:8 и пиздец. Ну еще шум подмешиваю в районе 0,1. На 30 эпохе, которая вот только начала выдавать нужный мне результат, это 12к+ шагов, а сейчас 40 эпоху тестирую и она мне нравится даже больше, а это уже 16к. У вас там либо батчсайз накручен, либо градиент чекпоинтов, что вы в 1,5к укладываетесь, а мне мощности не позволяют.
>А чо это такое, из разных лиц черты собираешь что-ли?
Нет, лицо определенного человека.
>Говно или как?
Когда как. Я попробовал отдельно потренить на HQ и не увидел особой разницы с датасетом где пикчи вперемешку вместе с шакальными. Более того, этот вариант мне зашел даже лучше.
Я из веб-морды информацию глянул, пикрил для гарольда, как раз с твоего пика.
Вообще вопрос не о том как тренить - как тренить никто нихуя не знает например, просто потому что четких мануалов нет (и быть не может, потому что слишком много вводных) или вы жлобы. Вопрос в том, как объективно оценить качество лоры и выбрать по этой оценке эпоху. Но похоже тут та же ситуация как и с манами - объективных критериев нет, только тесты и субъективная оценка.
>пикрил для гарольда, как раз с твоего пика
Все верно, у меня мозги от параметров поплыли, не понял сразу о чем ты.
>>>Говно или как?
Я про свои пикчи спрашивал. Не понятно просто, зачем ты столько степов делаешь, поэтому спрашиваю -- говнолоры у меня или нет, с твоей точки зрения.
Щас напишу как треню если интересно
Батч всегда на 2 стоит. ЛР тоже базовый.
Тэги, может, влияют?
16к шагов - это я даже и не знаю, что столько тренить можно без того, чтоб оно там нафиг не пережарилось в одну сплошную запеканку.
>Не понятно просто, зачем ты столько степов делаешь
Потому что лично у меня с меньшим количеством степов стабильно получается говно. Единственный раз вышла ультра-годнота при 4000 шагов, которую я до сих пор не могу переплюнуть почему-то.
>говнолоры у меня или нет
А на какой паттерн ты тренил свою лору? Я вижу схожие черты лица на 3 и 4 пике, но это разная стилистика же, а ничего другого не угадываю.
>Тэги
Насколько я понял, можно не тегать, и я так и стараюсь делать чтобы просто подключать лору и не прописывать триггер-ворды в промт. Ну максимум писал tyan_name, но и то в промт ее подключал без триггера, и работает заебись.
>Насколько я понял
Неправильно ты понял.
99.5% лор без нормальных тэгов выходят говном.
Сетка просто не понимает, что ей тренировать. Чем более подробно ты всё протэгаешь - тем лучше и гибче будет результат. Это применительно вообще ко всему - от тянок до стилей.
> 99.5% лор без нормальных тэгов выходят говном.
А схуяли? Не, это не попытка оспорить, это вопрос о механизме.
Вот допустим тебе нужно натренить лору на желтый гудок - ты готовишь датасет с сотней пикч желтого гудка в разных ракурсах, с разным фоном, с разным удалением и прочим разным. Сетка начинает учить паттерн - и она выучит желтый гудок просто потому что на каждой из сотни пикч он повторяется. Нахуя ей теги нужны? Чтобы что?
Теги оправданы на сложных лорах и нужны на чекпоинтах, иначе оно просто не поймет что рисовать. Но указывая лору ты фактически даешь сетке трафарет, и триггер здесь ни к чему.
Поэтому объясни мне пожалуйста нахуя, потому что я рили не знаю, а все вот это мое объяснение - субъективное впечатление с дивана.
> Ну максимум писал tyan_name, но и то в промт ее подключал без триггера, и работает заебись.
Кстати триггер-ворд для лоры я тоже пробовал писать. Изменений в генерациях не заметил, поэтому и хуй забил это делать, по крайней мере для своих лор.
>Нахуя ей теги нужны? Чтобы что?
Чтобы лучше отделить желтый гудок от фона и понять его как концепт.
Вот у тебя гудок на фоне леса/улицы/кровати/бассейна/космоса/белой пустоты.
Сам гудок в проекции снизу/сверху/сзади/кверху ногами.
Вот он ночью/днем/утром/вечером.
Вот гудок держит тянка/мужик/собака/рыба/ктулху.
Чем точнее ты это все протэгаешь - тем лучше сетка сможет вызывать этот гудок в разных комбинациях. Без этого у тебя в большинстве случаев будет дикая нестабильность результатов.
Да, сетка поймет этот гудок как что-то такое, желтое и определенной формы, но это всё. Как это применить и куда его рисовать - уже будут проблемы.
Втройне будут проблемы, если изначально у исходной сетки были нулевые или около-нулевые знания об этом желтом гудке, тут вообще полная катастрофа может случиться.
>Как это применить и куда его рисовать - уже будут проблемы
Чтобы парировать мне придется вернуться к своему частному случаю - ни разу еще не было проблем с лорами на определенные черты лица без тегов. Из 10 лор и порядка 20к+ нагенеренных пикч было все что угодно - хуевая анатомия, двойная генерация, не слишком похожие черты лица, но ни разу лицо не рисовало на коленке или вместо жопы, оно всегда на своем месте, при том что кроп датасета примерно в районе плеч, только самые шакальные фото (10-15%) по пояс.
>Втройне будут проблемы, если изначально у исходной сетки были нулевые или около-нулевые знания об этом желтом гудке
Ну с этим проще, гудок тут действительно оверкилл для примера.

Я думаю если бы была объективная оценка, то был бы и параметр отсечки по ней. А такого нет
'--resolution=768,768',
'--network_alpha=' + alpha_value, // для лиц 128, для остального пробую от 1
'--text_encoder_lr=0.0001',
'--unet_lr=0.0001',
'--network_dim=' + dim_value, // обычно 128
'--lr_scheduler_num_cycles=10', // вроде не юзается, но пусть
'--learning_rate=0.0001',
'--lr_scheduler=adafactor',
'--train_batch_size=2',
'--max_train_steps=' + String(n_steps), // обычно выходит 3к+
'--save_every_n_epochs=1',
'--mixed_precision=bf16',
'--save_precision=bf16',
'--optimizer_type=Adafactor',
'--keep_tokens=1',
Вот к этому пришел пробами и ошибками. Это не все параметры, только те, что я менял/раскуривал. Остальные дефолт.
>с меньшим количеством степов стабильно получается говно
Хм
>Единственный раз вышла ультра-годнота при 4000 шагов, которую я до сих пор не могу переплюнуть почему-то
У меня тоже такая есть. Чисто звезды сошлись один раз.
>на какой паттерн ты тренил
Паттерн не знаю чо такое. Я вкидываю регуляризаций скриптом (да, щас обосрут) и делаю блипом кепшены. Без регуляризаций выходит хуже. Без кепшенов лица выходят хуже, а концепции лучше, если на пикчах ничо нет кроме нее. С к3йв0рдом не заморачиваюсь, если он не прям ебучее слово. Если совсем все плохо, иду кепшены править руками.
Возможно пора что-то менять, но я не знаю что.
>разная стилистика
Да, я в sweetMint генерил. В реалистичных иногда выходит, иногда нет, см.пик. Они все примешивают свой изначальный "дефолтный стиль" или типа того. Во всяких киберах например всегда азиатки выходят. И к пику еще вае чужой прилепился, но и хер с ним.
Вообще для себя я это воспринимаю как норму. Четкого прям идентичного соответствия не жду, т.к. даже в рамках одного чекпоинта и набора лор, лица... ну, как бы, чуть разные. Перевесишь одну лору, она насрет в черты. Переставил теги, все поменялось. То есть как бы практическая ценность-то какая?, даже если я добьюсь 100 процентов сходства в пустом промпте.
В теории, идея тегов (кепшенов) в том, чтобы сказать "на пикче Х, У, Й". И потом при генерации сказать "надо Х, У". Так Й отпадет. Я так наушники относительно успешно удалял у асмрщиц например. Также в теории, в теги не надо писать то, что тебе всегда нужно -- пусть оно вжарится в триггер и в сами веса. Не спец, но думаю если у тебя на пикчах прям только то чо надо, то можно без тегов. (Я так делал, норм.)
>триггер/без триггера
У меня иногда бывает что можно не писать, а бывает что НАДО писать. Не ебу от чего это зависит. Так что я бы не скипал это по дефолту.
>Вот допустим тебе нужно натренить лору на желтый гудок - ты готовишь датасет с сотней пикч желтого гудка в разных ракурсах, с разным фоном, с разным удалением и прочим разным.
Из такого датасета без тегов эта хуйня обязательно пикнет паразитные общие черты помимо твоего ебучего гудка. Невозможно подобрать 100 пикч с абсолютно 100% изолированными жёлтыми гудками. Точнее тебе может показаться что можно, но она найдёт лазейку и схлопнется на ненужном. И 1000 нельзя. И 10000. Нужны миллионы. Лора это не про количество, это про качество.
А с очень подробными тегами можно даже на одной пикче натренить, и оно худо-бедно поймёт что где, зерошотом. (что можно легко проверить, удаляя/заменяя теги по одному в инференсе). Попробуй натренить лору на одной пикче без тегов, чтобы не было оверфита (т.е. выделить из неё субъект, а рисовать потом всю картинку) и сразу поймёшь разницу.
Вот например чел демонстрирует эксперименты с однокартиночной лорой. https://civitai.com/articles/3021/one-image-is-all-you-need
Штука специфичная, но то что это вообще в принципе работает, возможно лишь из-за подробного кэпшена. Попробуй провернуть это без кэпшенов в принципе.
О чем и речь.
Если ты тренируешь тян без тегов, то когда ты вызываешь просто 1girl, то результат тренировки тупо накладывается поверх, без разбору, и получается что-то похожее или нет.
А вот когда тебе захочется гибкости - то начнутся проблемы. Эта твоя тянка из лоры будет влиять вообще на всё - потому что при тренировке не сформировался правильный концепт, и она не была отделена от фона/других предметов/одежды.
Почему тестом "на качество" является картинка тянки, держащей в руках свинью? Как раз потому - если тэги были правильные, и параметры тоже, то и тянка, и свинья получатся нормально и раздельно. Если ты где-то проебался, то либо у тянки пятачок нарисуется, либо свинья человекоподобная выйдет. Именно от непонимания общего концепта.

> Хм
Ну это у меня, я не знаю что это - правило, ошибки в настройках или что-то еще.
>Паттерн не знаю чо такое
Нечто повторяющееся, что лора должна заучить и воспроизводить. В случае с тренировкой на определенного человека - черты лица, в случае с желтым гудком выше - собственно желтый гудок. А вот что ты написал дальше уже не понял я лол.
>Во всяких киберах например всегда азиатки выходят
Просто добавляй european или сорт оф.
>В теории, идея тегов (кепшенов) в том, чтобы
Да, именно это я и имел в виду под "сложными лорами". В твоем варианте вроде бы можно указать для Й (ну или наушников у АСМРщиц) отрицательные значения, кстати.
>в теории, в теги не надо писать то, что тебе всегда нужно -- пусть оно вжарится в триггер и в сами веса
Ну так блядь вот это мне и надо, лол. И вообще как правило именно это от лоры и надо.
>Я так делал, норм.
Вот и мой опыт показывает что норм.
>Лора это не про количество, это про качество.
>с очень подробными тегами можно даже на одной пикче натренить
Не до конца согласен, лора должна понимать черты лица с разных ракурсов, а для этого нужна вариативность датасета. Если бы я хотел иметь пикчи с лицом с одного ракурса - я бы тупо использовал инпейнт, и примерно это и получается по линку. Тренировка лица на одном пике - это суходроч от безысходности, можно за неимением лучшего, но не надо если есть возможность. С остальным может и проканает.
>Почему тестом "на качество" является картинка тянки, держащей в руках свинью? Как раз потому - если тэги были правильные, и параметры тоже, то и тянка, и свинья получатся нормально и раздельно.
Или мне просто повезло, или теги в конкретном случае все-таки не нужны. Промт просто woman holding a pig in her arms, <lora:loraname:1>, обучение без тегов, часть лица оставил просто показать что там нет пятачка.
> Да, именно это я и имел в виду под "сложными лорами". В твоем варианте вроде бы можно указать для Й (ну или наушников у АСМРщиц) отрицательные значения, кстати.
В смысле тренить лору на наушники, а потом в промте давать ей отрицательные значения. Так будет понятнее что я имел в виду.
>Или мне просто повезло, или теги в конкретном случае все-таки не нужны.
Возможно и повезло.
Само лицо то хоть похоже получилось?
Хрюшка с виду "очеловечилась" немного.
>Возможно и повезло.
Сделал еще несколько генераций, на текущей тестируемой лоре и самой первой, на которой сошлись звезды и получилась ультра-заебись - факапов нет, обе тренились без тегов, у обоих в промте триггер отсутствует, только имя лоры.
>Само лицо то хоть похоже получилось?
Похоже, черты лица в основном заучены, но прям фотореалистичное сходство примерно на каждой десятой пикче - в остальных случаях 2-3 пикчи в мусор, а остальные более-менее норм.

>отрицательные значения наушников
Да, если вылазит, я в негатив пишу (ну или сразу, если лора проблемная)
>что ты написал дальше уже не понял я лол
Это все термины из дефолтных туториалов, blip captioning, regularization [+ class], keyword = trigger-word. Про кейворд говорят "пиши n4t4sha вместо natasha, чтобы не совпадал с известными словами" - они примешивают якобы свои веса. Но на практике хер поймешь чего происходит, то хуже, то лучше. Чувство такое, что если в кейворд писать имена, то он как-то лучше понимает, что это тня, что-ли, и ему проще докинуть из лоры. Но иногда это селебрити с другим луком, и тогда от этого хуже.
У меня тоже хрюшки няшные выходят, хоть и с тегами
> --network_dim=' + dim_value, // обычно 128
Кстати
Я треню на гораздо меньших значениях (16/8), как только получу идеальный результат - собираюсь попробовать их снизить, dim оставить 16 а альфу спустить до 4 например, или 8/4 сделать.
>Не до конца согласен, лора должна понимать черты лица с разных ракурсов, а для этого нужна вариативность датасета. Если бы я хотел иметь пикчи с лицом с одного ракурса - я бы тупо использовал инпейнт, и примерно это и получается по линку. Тренировка лица на одном пике - это суходроч от безысходности, можно за неимением лучшего, но не надо если есть возможность. С остальным может и проканает.
Речь не о том. Ты сможешь получить лицо с ракурсов, нет проблем. Речь о том что у тебя модель должна обобщать и отсеивать мусорные признаки, не принадлежащие твоему объекту. Каждая новая модальность (картинки, текст, видео, звук...) это новый короткий путь через многомерное пространство в обход уже имеющихся длинных в других измерениях, и добавляет качества экспоненциально. Естественно данные для этого должны быть реально связаны.
> Нахуя ей теги нужны? Чтобы что?
Чтобы желтый гудок был для нее понятным концептом, связанным с текстовой частью, а не просто неуправляемым мусором что отравляет модель.
Господа хорошие, кто на XL тренил, поделитесь рецептами хороших результатов, будьте же людьми. Насколько параметры совпадают с 1.5, в чем отличия и т.д.
Я пробовал d32/a32 - для лиц хуже. Где-то на d70-90 по ощущениям становилось норм, так что я просто забил и стал 128/128. Отдельно альфу тоже менял: d128/a1 например прям сильно хуже для лиц, но было сильно лучше для лоры тонких ног. Она на 128/128 желтила пц, а щас красота, на плотах тупо линейное утоньшение без артефактов (до 1.4 ясно дело, дальше пиздец).
Алсо, раньше я сидел на AdamW и constant, быстро с них ушел на Adafactor adafactor. У последних меньше "артистичность" что-ли или типа того, хз как передать. Они более реальные и менее "дримерские". Но зато они "стабильные" между разных датасетов, не надо вечно переподтюнивать, нет пережарки. Я бывает даже не смотрю эпохи, если нет косяков.
Я вот думаю допилить свой скрипт и заставить его за ночь-две нахерачить разных лор по уже готовым датасетам. И напилить огромных плотов по параметрам тренинга. А то задолбало в темноте бродить и ждать пока очередной эксперимент выйдет говном.
дратути
Xen или kvm чтобы чтобы можно было пробрасывать видеокарту в гостевые win и nix? Ну и еще если в контейнере крутить - норм работает, или цпу-онли говно?
Что тред затих
Расползлись по тематика xl тренировать.
Есть модель, которая может определить "качество рук" на пикче? Нужно детектить поломку на сгенерированных, или кривого артиста. Наверняка ведь что-то натренили готовое.
Чем можно тренировать лору и просто файн тюн на нескольких картах?
Стандартным кохой, распараллеливанием будет заниматься аккселерейт. Под шиндой на мультигпу с такими вопросами даже не надейся, костыльно через wsl, хорошо на линуксе. Просто работать параллельно для удвоения скорости тренировки - на любых карточках, так чтобы складывалась память - без нвлинка можешь не надеяться.
Если бы такая была, её бы использовали для обучения модели, которая всегда даёт идеальные руки.
Что значит детектить? Можно натренировать контролнет или типа OpenCV детектор сделать
Классифаер же, можно в комбинации с модялями что в адетейлере для выделения области. Если кто-то тренил и есть изи ленивый путь - прошу поделиться.
Если бы, нормальный датасет составить и от мусора почистить не могут, а тут такое. Стоит узнать как делались котируемые многими модели - удивляешься насколько оно толерантно к пиздецу.
https://crowsonkb.github.io/hourglass-diffusion-transformers/
Кто-то пытается воскресить пиксельную диффузию без латентной компрессии, скрещивая юнет с трансформерами
Кто-то пытается воскресить пиксельную диффузию без латентной компрессии, скрещивая юнет с трансформерами
Уже давно есть такое.
где?
>Кто-то
Два автора из Stability AI, не совсем они видимо сдохли, что-то готовят.
Заявы по ссылке выглядят неплохо, интересно насколько оно соответствует.
> из Stability AI
Значит точно будет кал. Или опять придётся допиливать месяцами за этими говноделами.
Главное чтобы было что допиливать

Технари, поясните за comfyUI, как можно перегенерировать картинку из батча? Например мне 4я нравится. Хочу её взять только для неё начать плавно менять промпт или примешивать другой шум к основному.
И не знаю, то же это самое или нет, но в автоматике была настройка смещения шума. Это как проворачивать в комфи?
Пока что я тупо сую картинку в VAEencode и кручу денойз
И не знаю, то же это самое или нет, но в автоматике была настройка смещения шума. Это как проворачивать в комфи?
Пока что я тупо сую картинку в VAEencode и кручу денойз
> ищет функционал автоматика, которого в комфипараше просто нет
Ты тупой?
Да, я тупой. Пожалуйста помоги мне.
Виляет жопой
Используй автоматик. Нахуй ты взял эту парашу и теперь жалуешься тут?
Точно также как в автоматике берешь и ставишь ее сид, вариэшны толи в стандартной ноде были, толи нужно было кастомную добавлять, но все было.
Ну так вопрос как раз в этом сид-вариаэйшн, где его взять.
так же я могу предположить, что сид тот же, шум тот же, но есть сдвиг шума, так как картинка является тайлом внутри батча.
Я сомневаюсь, что в комфи чего-то нет. Вот в автоматике точно нет, просто в силу устройства.
> в комфи чего-то нет
Там до сих пор нет fp8 или нормального инпейнта. Вообще в комфи много чего нет из того что в автоматике из коробки. Про гуй я вообще молчу.
> в силу устройства
В плане экстеншенов комфи менее гибок, потому что там каждая нода изолирована, в отличии от автоматика, в котором можно поставить хуки хоть где.


Сам разобрался.
Variation seed есть в к-сэмплере Inspire.
Для извлечения сегмента Latent нужен Latent from batch, но конкретно с Euler_a он не работает.
А ты иди нахуй.
Variation seed есть в к-сэмплере Inspire.
Для извлечения сегмента Latent нужен Latent from batch, но конкретно с Euler_a он не работает.
А ты иди нахуй.

>или нормального инпейнта
В наличии 2 или 3 редактора в браузере.
Нормальнее чем в Автоматике с его ужасной кистью, отсутствием нормального зума, слоёв и прочей хуйни. Я даже маски рисовал во внешнем редакторе.
>fp8
не ебу что это. Вроде написано «Less VRAM», но по факту комфи у меня делает батчи по 32, автоматик же лимитировал батч 8ю, если не ошибаюсь. И то падал.
Ну и пикрил, конец прошлого года, твои данные устарели.

Поставил себе задачу натренить себе модель по типу этой https://www.youtube.com/watch?v=j2dI0B4VHxk чтобы генерировать пиксельные тайлы к играм через imgtoimg. Накачал картинок, заскейлил в нужный размер и порезал на части 512x512. Натренировал модель и вот пока что у меня пока выходит в режиме imgtoimg на пике. Собсна мои вопросы:
1. Увеличение размера датасета поможет сделать пиксель арт более похожим на пиксель арт? А то будет такое себе заготовить огромный датасет, а в итоге после обучения результат останется тем же.
2. Увеличение количества эпох сделает пиксель арт более похожим на пиксель арт? Христ говорил что эпохи вообще нихуя не дают, может это и так, если ты просто лицо копируешь, однако я ща потестил на двух эпохах, результат сильно лучше чем на одной.
3. Нейросеть сама хорошо понимает что за предметы находятся на каждом изображении или все таки правильнее указывать промпты в тхт файле для каждого изображения? Христ опять же говорил, что нейронка нихуя не использует промпты и всю инфу в основном берет с CLIP'а, но в моем случае хуй она поймет, что там на пикче есть цветок, например. Обязательно это прописывать?
4. Этот способ с разбиением на рандомные куски 512х512 это вообще нормально? Вот есть на пикче дерево, пенек и пол дома например, оно нормально поймет все эти концепции если оно все будет вперемешку?
1. Увеличение размера датасета поможет сделать пиксель арт более похожим на пиксель арт? А то будет такое себе заготовить огромный датасет, а в итоге после обучения результат останется тем же.
2. Увеличение количества эпох сделает пиксель арт более похожим на пиксель арт? Христ говорил что эпохи вообще нихуя не дают, может это и так, если ты просто лицо копируешь, однако я ща потестил на двух эпохах, результат сильно лучше чем на одной.
3. Нейросеть сама хорошо понимает что за предметы находятся на каждом изображении или все таки правильнее указывать промпты в тхт файле для каждого изображения? Христ опять же говорил, что нейронка нихуя не использует промпты и всю инфу в основном берет с CLIP'а, но в моем случае хуй она поймет, что там на пикче есть цветок, например. Обязательно это прописывать?
4. Этот способ с разбиением на рандомные куски 512х512 это вообще нормально? Вот есть на пикче дерево, пенек и пол дома например, оно нормально поймет все эти концепции если оно все будет вперемешку?
> но по факту комфи у меня делает батчи по 32, автоматик же лимитировал батч 8ю, если не ошибаюсь. И то падал.
Ахуеть, это все, что надо знать про Комфи даунов. Не осилили как изменить максимальное значение ползунков, и веулючить medvram, поэтому выбрали Комфи
fp8 - это квантизация. В 2 раза меньше потребление памяти без видимой потери качества. Пока в релизе не завезли
> Увеличение размера датасета поможет сделать пиксель арт более похожим на пиксель арт?
Да. Для начала надо хотя бы пару десятков тысяч. Больше - лучше.
> Увеличение количества эпох сделает пиксель арт более похожим на пиксель арт?
2-3 - оптимально. Больше 5 лучше не делать. Но вот батчсайз нужен как можно больше. Оптимальные значения для стандартных оптимизаторов на 16+.
> Обязательно это прописывать?
Без капшенов это просто мусор, а не датасет.
>по факту комфи у меня делает батчи по 32
тому що вместо того чтобы крашиться он автоматически переключает тебя в lowvram режим, подкачивая куски модели с оперативки, соответственно замедляя инференс
>Без капшенов это просто мусор, а не датасет.
А как на десятки тысяч изображений это прописывать? Не в ручную же, а если CLIPом, то sd же итак его юзает
> 1.
Да. Огромный не нужен, нужен разнообразный и примерно охватывающих все возможные области (по яркости, содержимому и т.п.).
> 2.
Правильные-оптимальные настройки сделают это, просто эпохи в отрыве от всего не интересны.
> правильнее указывать промпты в тхт файле для каждого изображения
this
> Христ
Зашкварный петушара, который запизделся.
> Этот способ с разбиением на рандомные куски 512х512 это вообще нормально?
Может быть использован. Алсо увеличь разрешение, особенно если планируется использовать не на стоковом сд, лучше пойдет и будет лучше работать если потом соберешься апскейлить.
Алсо качественный пиксельарт в 1.5 всеравно не получить, потребуется пост обработка. Можешь про это найти в популярной подборке лор на циве.
> 2-3 - оптимально. Больше 5 лучше не делать
Вот это довольно странно, почему такие значения?
> Для начала надо хотя бы пару десятков тысяч.
А это уже откровенный троллинг
> а если CLIPом
Им или другими моделями.
> а если CLIPом, то sd же итак его юзает
Что за бред, там тренится в соответствии с тем что задал, если нет капшнов - на вход текстовый пойдет название концепта в структуре датасета, это плохо.
Хотя вообще если задача только делать img2img на одну единственную тематику, можно просто тренировкой все поломать и оно как-то будет работать.
>качественный пиксельарт в 1.5 всеравно не получить
Вообще не тру. Нашел классную лору, которая хорошо пиксель арт делает, именно сам стиль. В text to image конечно проскакивает дефолтная полтарашная хуйня типа трех рук, но в image to image и с controlnet мое почтение
> Вообще не тру.
Ты приблизь и посмотри на те пиксели, они все разного размера, округлые, с градиентами на краях и т.д., требуется доработка. Общий стиль будет выдерживать офк.
Не, прям все топ и по сеточке, при скейлинге в 64х64 получается то же самое >



Ты думаешь, я время не замерял и просто так батчи гоняю?
Да, потребление памяти прыгает до 9—10Гб. Но никакого торможения и падения качества нет. Огромный батч эффективнее. Это всё, что меня волнует как пользователя. Вот скрин из консоли.
В скобках — время на одну картинку.
512х744
Практически же батчи по 32 я заряжаю редко. Чаще 4, 8, 16
>инференс
Выебнулся, да?
1. была очень приличная лора на пиксель-арт
2. Проще генерировать сначала что-то типа тюринговского шума с примесью другого в малом разрешении, чтобы создать пятна и «реки», затем на базе этой пиксельной сетки генерить обычные картинки а потом уменьшать и пропускать через слои эффектов в фотошопе. Постеризация/индексированная палитра, шахматная клеточка (диффузия).
> видео
Хуйня, чё-то совсем. Прям совсем унылый пиксельарт, однородная каша. По базовым цветам неприятно, по структуре невнятно и его даже взять в доделку до нормальных тайлов не хочется.
Классические генераторы на базе шумов, «червей» и прочих внятных правил, а так же симуляций во времени, выглядят гораааздо лучше.
Ну такое… Если говорить о превращении слева направо то неплохо, можно руками дотянуть.
>тюринговского шума
Это как? Может шум перлина?
>затем на базе этой пиксельной сетки генерить обычные картинки а потом уменьшать и пропускать через слои эффектов в фотошопе.
Ну во-первых, пиксель арт нихуя не так прост, весь искуственный пиксель арт палится на раз два, тут процедурной генерацией не отделаешься. Во-вторых не только же реки и травка нужны, хорошая модель должна и данжи генерировать и домики, вообще все знать. Тут нужен охуенный датасет пиксельных top down картинок как не крути, но к сожалению нихуя такого нет в интернете. Есть датасеты игровых тайлсетов. Вот если бы была возможность процедурно генерировать когерентные пиксель арт пикчи из пиксельных тайлсетов (чтобы оно вручную все эти травинки и домики расставляло), вот это уже было бы круто.
Ну вот как раз оно, требует доработки. Про отступлении от 512х512 и в других ар становится хуже, но тоже можно вытянуть. В исходном виде неюзабельно.
> потом уменьшать и пропускать через слои эффектов в фотошопе. Постеризация/индексированная палитра, шахматная клеточка (диффузия)
База. Но изначально нужную палитру и особенности детализации чтобы не херилось все можно задать как раз лорой. Сами пиксели после диффузии мэх, использовать как исходник можно но не обязательно.
>Может шум перлина?
Нет. https://rreusser.github.io/multiscale-turing-patterns/
Тут из шума эволюционируют паттерны пятнисто-полосатые. В демке они затайлены.
>тут процедурной генерацией не отделаешься.
Я имею в виду процедурную генерацию базовой канвы.
>охуенный датасет
Как минимум длинный список разных тайлов и их свойств (что с чем стыкуется).
Инфы валом, вот например
https://www.youtube.com/watch?v=YShYWaGF3Nc&list=PLsk-HSGFjnaH82Bn6xbQNehatj3sIvtMQ
Забыл как эта система называется, где к каждой стороне своё правило стыковки.
А вот конкретно рисовать тайлы и их стыковку, хотя бы основу, уже можно подрядить нейронку.
да, ограничить цвета лорой или эмбеддингом — мысль хорошая.
Все эти ваши попытки хуйня, с таким же успехом можно фотку пикселизовать/соляризовать в фотошопе. В нормальном пиксельарте по сетке выровнены фичи, Т.е например дом стоящий наискосок будет стоять так что край будет ровный или точной лесенкой.
Есть такой проект retrodiffusion https://www.retrodiffusion.ai . Это самая пиздатая модель на сегодня, она обучена на горе пиксельарта, который предоставляли сами пиксельхудожники. Она умеет это и многое другое, например аутентичные палитры с ретродевайсов, обводку и т.п. тонкости. Смотрите на сравнения внизу страницы, каким должен быть правильный пиксельарт.
Жаль что она закрыта, но я уверен что если дотренить SD соответствующим образом то получится нечто похожее. RD это по идее вроде и есть файнтюн SD.
Есть такой проект retrodiffusion https://www.retrodiffusion.ai . Это самая пиздатая модель на сегодня, она обучена на горе пиксельарта, который предоставляли сами пиксельхудожники. Она умеет это и многое другое, например аутентичные палитры с ретродевайсов, обводку и т.п. тонкости. Смотрите на сравнения внизу страницы, каким должен быть правильный пиксельарт.
Жаль что она закрыта, но я уверен что если дотренить SD соответствующим образом то получится нечто похожее. RD это по идее вроде и есть файнтюн SD.
> В нормальном пиксельарте по сетке выровнены фичи, Т.е например дом стоящий наискосок будет стоять так что край будет ровный или точной лесенкой.
Правильно говоришь. Только при должной внимательности к обучению сетка эти свойства вполне себе усвоит, а кривые пиксели -
> пикселизовать/соляризовать в фотошопе
> RD это по идее вроде и есть файнтюн SD.
Никто не мешает сделать также, насобирать датасет, обработать должным образом, и зафайнтюнить. Для 1.5 это более чем доступно на хайль-энд десктоп железе, на то чтобы со всем разобраться и сделать уйдет от нескольких вечеров до месяца+, но результат будет.
> самая пиздатая модель на сегодня
Они ее продают? Хотя почему бы и нет раз сделали, просто сложность такого по современным меркам не столь высока.
К слову о палитрах, я попробовал контролнет, но он именно зонирует цветами с картинки, а хотелось бы использование палитры.
Какой постпроцессор для этого нужен?
Какой постпроцессор для этого нужен?
Когда же до толстолобых долбоебов дойдет, что для пиксельарта нужно тренить вае.
И как он тебе поможет, даунёнок? Ты с таким же успехом можешь вообще выкинуть вае и латент конвертить в одноцветные кубы.
Ананасы, выручайте. Черт дернул обновить мою сборочку афтоматик1111 и гитхаб теперь меня нахуй шлет.
RuntimeError: Couldn't fetch Stable Diffusion.
Command: "git" -C "C:\nai\stable-diffusion-webui-directml\repositories\stable-diffusion-stability-ai" fetch
Error code: 128
stderr: error: RPC failed; curl 92 HTTP/2 stream 23 was not closed cleanly: CANCEL (err 8)
Пробовал с впн, хттп прокси (за 60 рублей, охуеть), просто так тыкался, гитхап для шиндовс обновил - нихуя не выходит. Это чо, я без сисиков остался?
Интересная тема, есть примеры? Есть предположение что даже его тренинг не поможет обеспечить идеальный пиксельарт, что делается более простыми средствами. Но это не точно, кайфану если ты опровергнешь.
Погугли ошибку гита 128. Ты точно просто скачать обновлений а не пытаешься запушить свои модификации? Удали git.lock, используй гугл. Прокси и прочее тут не причем.
Помогло отключение всего нахуй что юзает сеть и дёрганье ануса адаптера. Отключил/включил и держишь пальцы крестиком что бы докачалось.
Пиздец. Миллионы юзают гитхаб а докачку впилить не осилили. Даунлоад мастер мог 20 лет назад а эта залупа жиденько обсирается.
Короче, пришлось перекачивать весь юяй в новую папочку, потому что при обновлении эта параша что то ломала. Ну хоть опять генерация писек работает, это победа.
Похоже на превышение лимитов API. У них нет лимита на трафик, хотлинкинг или ещё какую хуйню, но есть лимит на тилибоньканье программных верёвочек в минуту/час

Иногда бывает такое. Есть этому решение?
Видеопамять не переполняется, судя по графику, а оперативы вообще 64.
Сегфолт питона, вот это чудеса.
Это больше на битое железо или малварь похоже, лол.
Какие есть технические тэги ракурсов, помимо "high angle, low angle, wormeye angle возможно некорректно написал, fisheye тут хз как точно, wide shot" ещё есть? Где-нибудь была по этому статья?
Любые пространственные хинты довольно паршиво работают. Для пространственной композиции лучше img2img по грубой мазне и/или контролнеты.
Ну это от модели зависит. Если она говно, то да не работают.
Чаю этому господину.
Еще негативно/позитивно могут влиять остальные теги-описания. Например, если запросить фейс-клозап но при этом запромтить туфли то будет ерунда, и наоборот подробно описав черты лица без всего остального - будет стремиться сделать портреты.
Описывай натурально что нужно, pov еще хорошо работает, можно противоположные пары размевать в негативе/позитиве. Алсо без всяких тегов ракурса можно получить направление если указать ceiling/sky и типа такого.

Попробовал уже ставшие классическими тесты на Далли
Прогресс, ебать! Наконец-то, сука!
Не работают нормально хинты ни на какой модели. Хит-энд-мисс. Не пытайтесь меня подъебать, я на этом собаку съел. (далишную)
Есть лоры-слайдеры под это дело, но они регулируются не промптом, а силой влияния, и всё это кривое-косое и мутирует результат.
Единственный, я повторяю единственный способ указывать пространственную композицию по-человечески - напрямую нахуярить её в пространстве. Пердолиться с текстом и рероллами это мрак сознания.
На твоих говномоделях не работает, у меня работает всё, поэтому я и спрашиваю, какие ещё есть.
>У меня не работает, значит у всех не работает
типичный скуф, сидящий на делиберейт, поясняющий, что все вокруг говно, а он один шарит

Поясните, где к каломатику модели качать на вот это?
Расширение sd-webui-controlnet https://github.com/Mikubill/sd-webui-controlnet
Занимаюсь гравировкой на станке с ЧПУ. Через эти ваши нейросети можно сделать ЧБ PNG? У кого-то, возможно, есть примеры?
Спасибо!
Можно обучить лору на имеющихся картинках, и оно будет тебе генерить в том же стиле. Но если у тебя гравюра должна соблюдать определённые правила (например не делать слишком тонкие линии или что-нибудь в этом духе), не жди от сетки чудес, она в это не умеет. Например если её заставить делать витраж, обучив на реальных витражах, она тебе нарисует что-то очень похожее, но нарезать и собрать реальный витраж, который ещё и не рассыплется при этом, будет проблемно. Ну или понадобится очень сильно ебаться при обучении. В общем та же проблема что с пиксельартом, татухами и прочими специфичными штуками.
Кто-нибудь уже пробовал здесь Yi-VL для теггинга датасетов? По тестам бьёт даже CogVLM, но тесты это тесты.
Спасибо за развернутый ответ!
Что по факту делает эта галка? Меняет промпт и снова запускает? Как указать набор промптов? Комфи.
> По тестам
Это тесты в текстовых задачах, они тебе не важны, а визуальная часть там обычный клип. Ког по визуальной части даже жпт выебать сможет.
На одной 4090 ког может работать?
На гитхубе написано "For INT4 quantization: 1 * RTX 3090(24G) (CogAgent takes ~ 12.6GB, CogVLM takes ~ 11GB)" — это оно?
Насколько он тупой становится с 4-битной квантизацией?
Любую пикчу можно превратить в подходящее для гравировки математикой, но результат не всегда будет хорош. Сетку изначально можно заставить генерировать что-то типа чб скетча и даже рисунка чернилами, который потом легко и качественно можно сконвертировать.
Также возможно переделывать уже имеющуюся картинки в нужный стиль-формат, для такого подойдет отлично. Но будь готов вникать и разбираться, кнопки "сделать готовое" тут нету.
Да, так себе. Галюны встречаются, нсфв не хочет, внимания к деталям не то чтобы сильно много. 34б версия чуточку лучше, но всеравно мэх.
Тебе что именно тегать? Для анимца и нсфв есть очень шустрый и прилично работающий вариант, но его нужно чуток затеймить ибо в редких случаях ломается.
На 4090 ког влезает в 8 битах, yi34vl в 4х, 6б в полных весах.
> Насколько он тупой становится с 4-битной квантизацией?
Хз, надо сравнить, так норм.
Мультимодалки и их прикладное применение вообще интересут тут кого-то?
> Мультимодалки и их прикладное применение вообще интересут тут кого-то?
Меня интересуют, как пользователя и как перспектива будущего.
В целом с оптимизмом смотрю на «яйцеголовых», которые уже поняли, что исполнение узкой локальной задачи это для лабораторий и очень узких мест производства, а бизнесу и пользователям нужно что-то с чем можно общаться хотя бы немного эффективнее, чем с обезьяной или малолетним ребёнком.
Ащемта я не многого ожидаю. Додумались к чатгпт модули разные прикрутить, типа вольфрама, калькулятора, фактчекере/поисковика и умения говорить «да не знаю я, блядь!» — уже отлично. Прикручивают к рисовальным нейронкам умение рубить промпт и сегментировать, а так же проверять чё нагенерилось (GAN) — уже чудно. Прогресс и так прёт ебать как.
> как пользователя и как перспектива будущего.
Смотря какого пользователя. Если обывателя или просто инджиера - рано еще. Даже жпт4в ни разу не юзерфрендли для применения и областей его использования не так много.
Юзать можно прямо сейчас для подготовки датасетов, сортировки, обработки пикч (универсальное сегментирование), взаимодействия с интерфейсом (см все демки к когу). Для разработки чего-то с той же обработкой/генерации изображений.
Это подходит под пользование, или не то?
Оказывается, цивитаевские баззы теперь можно обналичить, переведя в доллары, 1$ за тысячу.
Сначала вспомнил, что у меня есть пара акков с около 30к баззов, нафармленных махинациями с партнеркой и трансфером. Чтоб трейнить лоры на сайте. 30 долларов - это не много и не мало, это средне.
Но потом я также вспомнил, в какой стране живу. Родина мамонтов, страна-мистер-сидр, страна-под-санкциями, страна-железный-занавес-снаружи. Пойду что ли накачу за родину лол.
Сначала вспомнил, что у меня есть пара акков с около 30к баззов, нафармленных махинациями с партнеркой и трансфером. Чтоб трейнить лоры на сайте. 30 долларов - это не много и не мало, это средне.
Но потом я также вспомнил, в какой стране живу. Родина мамонтов, страна-мистер-сидр, страна-под-санкциями, страна-железный-занавес-снаружи. Пойду что ли накачу за родину лол.
Ой спасибо, хорошо!
30 баксов сравнимо с кучей баззов это ни о чём.
Там так и задуман курс, чтобы выводить или фармить было не выгодно.
Реквестирую вопрос на ответ, для чего нахрен нужны инпеинт модели и в чем их отличии от обычных, когда работаешь с инструментом инпеинтом.
для SD 1.5 разницы нет
для SDXL в инпейнт моделях дефекты на швах импейта в разы меньше чем на обычных моделях, но все еще есть. sdxl пока еще существенно хуже чем полторашка импейтит
Что за даунские вопросы и еще более даунские ответы?
Инпеинт модели нужны для инпеинта. Не инпеинт модели работать не будут, они напрочь маску игнорируют, потому что у них нет слоя, обученного на масках
For inpainting, the UNet has 5 additional input channels (4 for the encoded masked-image and 1 for the mask itself) whose weights were zero-initialized after restoring the non-inpainting checkpoint.
> Не инпеинт модели работать не будут
При использовании адетейлеров каждый раз переключаешься на инпеинт модель?
С такими формулировками ответ тоже даунский выходит.
Они могут работать лучше обычных. Хотя учитывая что "дополнительные веса" хрен знает какой давности, может оказаться и наоборот. Сделай по инструкции ту инпеинт модель и сравни, это недолго.
> При использовании адетейлеров каждый раз переключаешься на инпеинт модель?
Ты понимаешь как работает адетейлер? Он находит на изображении требуемый объект, вырезает прямоугольный кусок изображения с объектом, прогоняет его через img2img и вставляет обратно.
Да, если выставить высокий "Inpaint denoising strength" в параметрах адетейлера, то инпейнт модели работают гораздо лучше (обычные модели обсираются уже на денойзе 0.6). На стандартном денойзе 0.4 обычные модели в целом работают нормально, но в некоторых случаях могут давать заметные артефакты по краям маски.
Если снять галочку "Inpaint only masked", то тогда адетейлер прогонит через img2img всё изображение, вырежет из него нужный кусок и вставит на исходное. В этом случае от инпейнт модели никакого толку не будет.
> Хотя учитывая что "дополнительные веса" хрен знает какой давности
Какие веса, какой давности, что ты несёшь? Там дополнительные 5 слоёв в модели, у неё банально больше входов. Модель принимает на вход не только кусок изображения для перерисовки, но и всё изображение целиком (4 слоя, так как VAE кодирует изображение (WxHx3) в латентное пространство в виде тензора размером (W/8)x(H/8)x4 ) + альфа-маску (1 слой). Да, там есть дополнительные масочные веса (для лучшей согласованности результатов с исходным изображением), но устареть они никак не могут.
>Смотря какого пользователя
продвинутый пользователь пекарни, умеющий её собрать, не боящийся командной строки и начинавший с доса и нортона.
То есть даже если нужно задротствовать ради рабочего результата, я могу, но при гарантии что оно вообще работает.
Но запрос мой — решение задач графического дизайнера.
>Это подходит под пользование, или не то?
ну разве что сортировка и обработка пикч — моё.
Инпейнт всегда смотрит на то, что окружает маску. Обычная только на то, что непосредственно внутри.
Если понизить денойз до 0.5, то благодаря имеющейся инфе обычная модель не сильно проебётся.
Инпейнт ограничен окружением, обычная — подложкой. Но обычной можно снизить вес подложки, а как снизить значимость окружения инпейнту я хз, подскажите.
>На стандартном денойзе 0.4 обычные модели в целом работают нормально
Это если перетасовать примерно схожее мыло.
А вот если заменить большие сиськи на малые — уже проблема, от больших сисек останутся следы на фоне например. Или огромная грудная клетка.
В общем я использую обычную модель вместе с контролом контуром (руками рисую), чтобы радикально что-то поменять, резко снизив опору на имеющееся изображение.
> прогоняет его через img2img и вставляет обратно
Уверен что так? Заявлялось что там не просто кроп img2img, который легко сильно уедет от оригинала, а как раз инпеинт по маске в повышенном разрешении.
> гораздо лучше
Есть сравнение этого гораздо? Пока главное вариант где это демонстрировалось - с костылем на автораздевание, и то там достаточно специфичная-сложная задача + реализм.
> Там дополнительные 5 слоёв в модели
И они не менялись годы.
> там есть дополнительные масочные веса (для лучшей согласованности результатов с исходным изображением), но устареть они никак не могут
Ну хуй знает, может и так. Ты описываешь их поведение как абсолютно детерминированное, типа накладывают маску, это действительно так? Если же их влияние более опосредованное то эффект их "устаревания" по сравнению с основными весами, которые хорошо ушли от ориганала, не стоит недооценивать.
> ну разве что сортировка и обработка пикч — моё.
Потребует написания своих скриптов скорее всего.
Простая гуйня, которая может работать с разными моделями, настраивать параметры, умеет в батчи и их визуализацию. Возможно паттерны на какие-то базовые задачи. Есть интерес? Готовность содействовать?
> А вот если заменить большие сиськи на малые — уже проблема, от больших сисек останутся следы на фоне например. Или огромная грудная клетка.
И как в этом поможет инпеинт модель? Если Если окружение не в маске инпеинта - его и не затронет, если в ней - будет согласовано при нормальном исполнении. Странные вещи тут у вас происходят.
>Есть интерес? Готовность содействовать?
Интерес на уровне хотелки и ожидания,
содействовать, увы, некогда.
Инпейнт смотрит не маску, а, как минимум, на маску+отступы.
И, вероятно, какую-то самую общую инфу берёт с картинки. В деталях не знаю, но практически ощущается так.
Инпейнт модель даже при 100% денойзе редко всё выворачивает нахуй относительно начальной картинки.
вопросы к знатокам, я помню,
SD-модели были по 4—6Гб, сейчас подрезанные по 2Гб
SDXL ещё не научились так подрезать или оно невозможно?
И почему лоры бывают под 30МБ а бывают по 6 но очень даже эффективные.
От чего это зависит. Я так чувствую, что не удержусь и начну обучать лоры рано или поздно, хочется понять, есть ли смысол делать толстые.
SD-модели были по 4—6Гб, сейчас подрезанные по 2Гб
SDXL ещё не научились так подрезать или оно невозможно?
И почему лоры бывают под 30МБ а бывают по 6 но очень даже эффективные.
От чего это зависит. Я так чувствую, что не удержусь и начну обучать лоры рано или поздно, хочется понять, есть ли смысол делать толстые.
За такие тупые вопросы тут пиздят и обоссывают.
Вот это ты тупишь. Это подрезание называется fp16
> SDXL ещё не научились так подрезать или оно невозможно?
Умела сразу и уже была подрезана, иначе изначально весила бы 15+гигов.
> почему лоры бывают под 30МБ а бывают по 6 но очень даже эффективные
Разная размерность, у нее нет прямой корреляции с эффектиновстью. Но для чего-то сложного большой размер необходим, а регулировать толщину лайна или среднюю гамму можно и мелочью.
На 1.5 для персонажа dim 64 с головой, даже несколько поместятся, но, например, в 8 может запоминать мелочи хуже и вызывать побочные эффекты.
На xl нормально получится и с меньшей размерностью.
я в курсе, что такое точность floating point.
Тем не менее ответов на вопросы вы не дали
>битое железо
Железо справляется и память может быть загружена плотно и надолго, к тому же адрес видишь? инструкция обращается в теоретический конец памяти.
почитал на ремонтке, похоже что решил.
Засада была в том, что SSD под нейронки, с которого всё читается и на который пишется уже подзабит неприлично во-первых. А во-вторых на нём был выставлен ещё и файл подкачки. Походу, питон не вывозил нормально всё чтение и запись разом на одно устройство.
Принудительно выставил размер и перенёс на более свободный диск — пока не падало.
> Походу, питон не вывозил нормально всё чтение и запись разом на одно устройство.
Ерунда, больше похоже на кривой разгон памяти или ошибки фс. Адрес куда обращается ни о чем не говорит.
После длительного дрочения и сотен генераций, всё-таки опять упало.
Память не гналась, идеально исправна, надёжна как Калашников.
Процу отключал анлок и андервольт — абсолютно без разницы.
Да и не падало никогда на более страшных задачах на проц и ОЗУ. Они проверены и симуляциями и рендерами.
Ну хз, чо думать. Разве что на сам кривой питон/комфи, ибо ничто больше проблем не вызывает, бсодов нет.
Диск на ошибки проверь и системные файлы. Если их нет - время переустанавливать шиндоуз. Если и это не поможет - железо.
ну ок, погоняю, может быть.
Тенденция к падению в случаях:
1. сбросил пару раз генерацию и запустил сразу снова (пока идёт генерация, поправляю ключи, вижу что уже хуйня выходит, прерываю)
2. После отгенерированного большого батча на следующем падает
Ещё один вопрос по комфи.
У него есть болячка, начинает вставлять либо по 2 копии нодов по Ctrl+V либо вместе с нодой вставляет load image с картинкой из буфера. То есть будто предыдущее значение буфера вставляет.
Не встречалось такой хуйни?
Если что, использую мультибуфер CLCL, попробую ща отключить.
У него есть болячка, начинает вставлять либо по 2 копии нодов по Ctrl+V либо вместе с нодой вставляет load image с картинкой из буфера. То есть будто предыдущее значение буфера вставляет.
Не встречалось такой хуйни?
Если что, использую мультибуфер CLCL, попробую ща отключить.
Перенёс папки аутпут/темп с этого диска и поставил печку генерить батчи по 48.
И параллельно 3д-моделить.
Пока ни одного отвала.
Раньше после 1-2 батчей почти с гарантией падало.
Пока что всё сходится на старом ССД. ШТОШ, нужно делать резервную копию с него. Все свои сроки он давно отслужил.
Например для этого
Без примердженной инпеинт модели с аниме и тем экстеншеном просто не работало как задумывалось
XL и так уже в фп16 по 6.5 гигов, сама модель просто намного больше, а размер лор зависит от выбранного дима, ну и естественно они тоже больше, до 32 так же как и на 1.5 не особо заметны потери при тренировке или ресайзе чего нибудь не особо сложного, для простых чаров мб можно и меньше
Спасибо за ответ.
>выбраного дима
что такое?
>для простых чаров мб можно и меньше
была такая догадка, что мелкие лоры оч прицельные и внутри простые концепции. Но ащемта мне такие и нравятся, узконаправленные слайдеры.
Понял, ещё раз спасибо.
SVD 1.1 вышла. Качаю. Кто-нибудь уже тестил, есть разница?
Обещают лучшее качество для 25 frames at resolution 1024x576.
https://huggingface.co/stabilityai/stable-video-diffusion-img2vid-xt-1-1
Обещают лучшее качество для 25 frames at resolution 1024x576.
https://huggingface.co/stabilityai/stable-video-diffusion-img2vid-xt-1-1
Гуй нормальный сделали для него? Или всё так же одно говно пердольное настолько что проще скрипт написать?
Комфи, чтобы править всеми
Вопрос косвенно касаемо темы. В Fooocus нет уменьшителя, только апскейл. В фотошоп лень таскать картинку. Надо всё в браузере. Можно ли самому написать простое приложение на градио? Буквально надо уменьшитель изображений в х раз. Кидаешь картинку в окно, задаешь масштаб и жмешь кнопку. Со скриптами на питоне немного знаком. Джава-скрипт в глаза не видел. Есть у меня шансы вообще?
А для фокуса можно свои расширения делать (никогда им не пользовался)?
То, о чём ты говоришь на градио делается как нехуй, но держать отдельный градио-вебсервер, только ради того, чтобы уменьшать картинки — такое себе.
Либо нужно глянуть исходники фокуса и посмотреть как там реализован апскейл. Думаю, прикрутить туда уменьшатель как нех делать.
Расширений нет. В фокусе всего два предустановленных выбора апскейла 1.5х и 2х. И я заменил в его коде 1.5х на даунскейл 0.5х. Но проблема в том, что фокус потом не обновляется из-за вмешательство в его файлы. Как этот момент разруливать не знаю.
Если делать даунскейл через графический редактор, то возникает необходимость открывать окно с проводником и вот это вот всё.
А так я бы держал градио во вкладке браузера и перетаскивал картинки из вкладки фокуса во вкладку с приложением. Удобно. Памяти 32.
К чему вообще нужен даунскейл: при апскейле повышается детализация. Типа как инпаинт всего изображения. Но размер картинки-то увеличивается. И я уменьшаю её до исходного размера в фотошопе, а затем снова апскейлю в фокус. Очень хорошо подвышает детализацию, автоматически выправляет лица, пальцы.

Такблэт. Пытаюсь установит insightface для faceID в автоматике.
Мне пишет как-то невнятно пик1
Типа библиотеки у тебя дохуя новые, не соответствуют, но что-то я там установил.
Мне с этим что делать нахуй? Откатиться на питон 3.10?
или искать эти библиотеки под 3.11?
И, вероятно, как следствие, инсайтфэйс не инсталлировался полноценно или конфликтует и выдаёт пик2
Облазил уже кучу страничек. Там или неведомая хуйня и «ставь VC и билди сам» или методы, проблему не решающие
модели апскейла работают на фиксированный апскейл x2 x4 x8
если тебе нужно меньшее разрешение, быстрее апскейл моделью и даунскейл до нужного
Мне пишет как-то невнятно пик1
Типа библиотеки у тебя дохуя новые, не соответствуют, но что-то я там установил.
Мне с этим что делать нахуй? Откатиться на питон 3.10?
или искать эти библиотеки под 3.11?
И, вероятно, как следствие, инсайтфэйс не инсталлировался полноценно или конфликтует и выдаёт пик2
Облазил уже кучу страничек. Там или неведомая хуйня и «ставь VC и билди сам» или методы, проблему не решающие
модели апскейла работают на фиксированный апскейл x2 x4 x8
если тебе нужно меньшее разрешение, быстрее апскейл моделью и даунскейл до нужного

Много ебатории ради все равно возить картинку мышкой.
Напиши лутше батник
@magick %1 -resize 50%% %1.out.png
и добавь его в правую кнопку в проводнике
```dobavit_batnik.reg
Windows Registry Editor Version 5.00
[HKEY_CURRENT_USER\SOFTWARE\Classes\pngfile\shell\Downscale_x2]
@="Downscale x2"
[HKEY_CURRENT_USER\SOFTWARE\Classes\pngfile\shell\Downscale_x2\command]
@="c:\\Users\\User\\MoeGovno\\downx2.cmd \"%V\""
```
Папку с пикчами кинь в избранное, сортировку по новые сверху
ImageMagick лежит в интернетах
Код не тестил, сляпал из шаблонов
хз, никогда не думал писать своё, потому что есть у меня XnView, а в нём есть пакетная обработка макросом.
А в макрос можно напихать всего, что умеет программа. Базовую редакцию умеет (обрезка, ватермарки, размер, уровни, пересжатие форматов)
У тебя обычный или мп?
написано MP, хз чем отличаются.
Помню, что он бесплатен для некоммерческих задач официально, потому и выбрал. И он мне перекрыл все нужды. Так что imagemagic просто пылится в архиве на всякий случай. Я его использовал для каких-то ну очень специфичных задач типа сравнить поканально, намазать разницу, извлечь палитру 8-битную
Прискорбно, но ничего так и не решилось малой кровью.
Видел коммент такого же невезучего. Пришлось последовать его совету, тупо накатить свежий комфи, на него ipadapter и insightface, а потом намазать сверху все кастомноды.
Ну и заодно выпиздил все крупные модели в папку common и прокинул симлинки, чтобы в случае ахтунга просто их заново прокинуть.
Есть подозрение, что конфликт непосредственно с обновлённым комфи или питоном был.
уже февраль 2024, ну и где 1.6
што?
Кто-нибудь пользовался контролнетом outfitToOutfit? Я уже второй раз пытался разобраться, и понял, что он лучше работает в инпеинте (даже с заездом на лицо и подобное), и он ультра чувствителен к промпту. Буквально удаляешь из негативного промпта одно слово без изменения смысла, и он уже тупа не работает
То есть работает очень не стабильно, но если работает, то прям конкретно заменяет или убирает одежду, оставляя все элементы +- как они есть в оригинале. Может как-то можно стабильности добиться, на цивите в комментах пишут что даже в video2video у них работает
То есть работает очень не стабильно, но если работает, то прям конкретно заменяет или убирает одежду, оставляя все элементы +- как они есть в оригинале. Может как-то можно стабильности добиться, на цивите в комментах пишут что даже в video2video у них работает
Да у меня тоже мп, чот не найду где там макросы делать.
А так удобный да, юзаю для дедупа, кропа, конверта, ренейма.
Хуле никто не сделоет мне нормальный единый графический
Заебали, в одном одного нет, в другом другого
релиз стаблдифужена 1.6

>и даунскейл до нужного
Да блин нет там. Читай выше.
>все равно возить картинку мышкой.
>Напиши лутше батник
Это надо открывать проводник. В него тянуть. Мне кажется не удобно, но спасибо.
>есть у меня XnView
Это еще хуже. Сохранять кртинку. Открывать редактор. Потом еще раз сохранять.
----------------
Вот что я имел в виду gif(на второй вкладке представим что там не 2х, а 0.5х). Сейчас подумал. А можно же такое сделать на джава-скрипте? Типа локальную страничку в браузере. Без градио.
>В него тянуть
А, я думал оно у тебя куда-то сохраняет по дефолту. Если нет, то да, удобно не будет. В автоматике например можно сохранять все генерации в указанную папку, и пикчи просто появляются в xnview уже выделенными. Там забиндены на альт-1-2-3... всякие действия типа апскейла и пр. Появилось - сразу жмешь. В окно пикч самого автоматика я вообще особо не смотрю, разве что прервать заранее, если на превью очевидная херня.
>А можно же такое сделать на джава-скрипте? Типа локальную страничку в браузере.
Можно найти где у фокуса лежит фронтенд и в него программно добавить кнопку, которая по клику найдет в document нужный элемент с пикчей, положит ее данные в canvas, поресайзит его и выплюнет куда-то как img+dataurl. Либо в отдельный всплывающий див, либо сразу в дроп-таргет ручным событием. Если есть дохера времени и не боишься заныривать, нет преград.
https://github.com/lllyasviel/Fooocus/blob/main/javascript/
Начинать видимо тут.
Алсо, имей ввиду, что нейропухтонщики обожают в update.bat засовывать git reset --hard, так что при обновлении все твои правки улетят в пизду. Выноси бакапы за пределы папки.
Еще есть варик поднатореть в ahk и автоматизировать сами шевеления мышкой/етц. Наркомания пиздец, и язык там делал ебучий мухоморщик, но по итогу часто проще, чем все это внутри ковырять, реальный опыт.

https://github.com/lllyasviel/Fooocus/blob/1bcbd6501bb3e5db5674a18a8a8074034cda318b/entry_with_update.py#L37
Короче отбой, об ин-пейдж яваскрипте можешь не мечтать, да и об ин-прожект градио правках тоже
Короче отбой, об ин-пейдж яваскрипте можешь не мечтать, да и об ин-прожект градио правках тоже

Я делал проще. Изменял в бакенде кнопку 1.5х на 0.5х. Но проблема в том, что потом Fooocus не обновляется. Надо как-то самому разруливать эти гит пулы, мёрджи и вот это вот всё.
>на джава-скрипте
Я имел в виду что-то отдельное офлайн html++js страничка. Вот нашел пример https://pencilsketch.imageonline.co/ правда там нет масштабирования. Да, наверно так будет лучше всего.
>Сохранять кртинку
она автоматически сохраняется на диск в temp
>открывать редактор, потом ещё раз сохранять
не закрываешь редактор, выделил всё, пакетная обработка, выбрал макрос, всё.
Макрос сам сохраняет картинки, куда укажешь.
Ты будто никогда не работал с файлами массово.
вы нашли что дрючить. Фокус для простых васьков с завода, он не подразумевает кастом. Хотите кастома — идите в комфи
поясните за sdxl, что-то в сети невнятное.
1. clip_l и clip_g нахуя выдумано?
2. чем турбомодели отличаются
3. снизить потребление памяти можно? а то у меня в потолок 12Гб уже чуть ли не долбится.
хз почему так, ведь модель 6Г ест.
1. clip_l и clip_g нахуя выдумано?
2. чем турбомодели отличаются
3. снизить потребление памяти можно? а то у меня в потолок 12Гб уже чуть ли не долбится.
хз почему так, ведь модель 6Г ест.
git reset origin/master --hard
> пакетная обработка
Ясно, ты не читал вообще зачем это надо. Надо:
1. Апскейл в Fooocus в 2х одного файла - этим повышается детализация, улучшаются все лица в картинке и т.п.
2. Довнскейл 0.5х в исходное разрешение
3. Goto 1 пока результат не устроит
Ты же в курсе что при шаге 1 в твоем пункте картинка увеличивается до попадания в sdxl? Ты сначала делаешь 0.5х, затем 2х, чем просто подшакаливаешь изображение
Просто картинку повторно пусти в img2img. В sd-webui есть для этого скрипт loopback
>Ты же в курсе
Я хотел облегчить и упростить, то что я уже делаю сейчас через сохранение и уменьшение в редакторе и т.д. То есть это практически рабочий метод. Не надо теории. Всё уже получается шикарно. По сути многократный хайрезфикс. А хайрезфикс всегда хорошо. Кроме растущего разрешения картинки.
И да: речь не об автоматике или комфи.
Видели вот эту вещь?
https://github.com/lllyasviel/stable-diffusion-webui-forge
Как я понял, это совсем новый ui, полностью совместимый с расширениями для автоматика
https://github.com/lllyasviel/stable-diffusion-webui-forge
Как я понял, это совсем новый ui, полностью совместимый с расширениями для автоматика
А нахуя ты это делаешь? Используй этот хайрез не с 2х, а с 1х, и увеличиваться не будет
Этот шизоид уже не знает какого бы говна ещё сделать. Сдохнет так же как и sd-next, ибо пердольное говно. Про совместимость с автоматиком пиздит конечно. Я чекнул и сходу вижу что Neg-PiP и супермерджер не работают.
Ты какую-то хуйню выдумал нелепую.
Чтобы улучшать лица есть фэйсрефайнер, который сам вырезает-апскейлит-даунскейлит
Чтобы деталей нагнать есть лоры всякие и грамотный подбор промпта, шагов и cfg

Антуаны, поясните.
Вот есть у меня адаптер стиля.
Можно каким-то образом ослабить его действие?
Пробовал и аверэйдж кондишн и таймстеп, нихуя на него не действует чё-то.
Даже совал батчем картинки, включая исходную, чтобы смешать стиль с основным. Тоже не особо помогает.
Или нахуй это всё и юзать лору?
Вот есть у меня адаптер стиля.
Можно каким-то образом ослабить его действие?
Пробовал и аверэйдж кондишн и таймстеп, нихуя на него не действует чё-то.
Даже совал батчем картинки, включая исходную, чтобы смешать стиль с основным. Тоже не особо помогает.
Или нахуй это всё и юзать лору?
> комфипараша
> ищет функционал
Чел, зачем очевидные вещи спрашиваешь? Не можешь сам напердолить что-то в этот говне - идёшь нахуй.
Попробуй concat conditioning. В inspire pack даже вариант с весом есть вроде.

>Видели вот эту вещь?
Спасибо анон. Потестил. На 1.5 примерно одинаково, а на ХЛ этот быстрее на 16% автомитика. Автоматик почему-то в конце больше лезет в озу цп.
На скрине хайрезфикс 1024х1024 х2.
На практике такие штуки, как комфи, рождаются, чтобы решать проблему, которой они позже сами же и становятся. Убить дракона, вот это все. Но поскольку юзеры растут внутри нее, им она проблемой не кажется. Это такой гровтх хак. Ни хорошо, ни плохо, но с нуля вкатываться ради одной механики - тот же хуй, только в другой руке. Я для себя предпочитаю простые систем-левел нашлепки, чем залочиваться в рамки чего-то, потому что опыт никуда не денется при смене обстановки или области. С годами понял, насколько это охуенно, когда он просто есть, переносится и не устаревает.
Дая у него какой-то странный менеджмент памяти. У меня 12 гб medvram-sdxl стоит только для уверенных контролнетов, хайрезов и т.п. Но по графику илюхоматик использует medvram, хотя мог бы смело лезть в fullvram для простой генерации 1024х1024
При включении fp8 потребление поднялось, всетаки вылез в fullvram
Это конечно, хорошо. Но если мне память нужна для чего-то другого, а он сам решает сколько жрать? Сомнительно в общем
Включи сжатие vae. Будут лица разъёбанные в щщи, но со сжатием и fp8 я гонял XL где-то 8-9 гигах vram. Выше расход не поднимался.

А это апскейл в Fooocus тоже 1024х1024 х2. Выброса в озу цп нет вообще. 38 секунд генерация + 150 сам апскейл. Как так - х.з. Я бы комфи показал, но как там сделать тот же апскейл не знаю.
Блять, этот шиз на полном серьезе даунскейлит, а затем апскейлит по сотням секунд, вместо того, чтобы поставить сд апскейл 1х или как он там в фокусе называется - результат будет чуть лучше, и без сотен секунд мусорной работы
Вроде все перепробовал, и бленд и комбайн и конкат, ебошит стиль поверх всего оч жёстко. Буду ковырять ещё
Ради одной механики не стоит с нуля, но можно спиздить готовый пайплайн и не думая запускать.
Я тут на днях говорю челу с цивитая:
— Ты почто все ноды слепил и запинил? выглядит как говно, неудобно.
— А их и не надо двигать.
Ну и ниже пишут челики «вай как круто и удобно».
Выглядит это пикрил. Всё в кучу, что к чему подключено хуй разберёшь и сопли на верх.
А кому-то проблемой не кажется.
а как работает апскейл х1?
Разве это не просто добавление шума и перегенерация?
> 150 сам апскейл
Шо? Какой-то инвалидный lsdr?
> результат будет чуть лучше
Там суть не в апскейле-даунскейле, а в том что обработка диффузией в повышенном разрешении добавляет деталей. Оставить как есть, продолжить увеличивать, или даунскейлить и повторять этот процесс - вопрос отдельный.
> Разве это не просто добавление шума и перегенерация?
Именно, энкодинг в латентное пространство и процесс диффузии с заданной интенсивностью и последующим декодингом обратно.
> а в том что обработка диффузией в повышенном разрешении
А кто тебе мешает в повышенном разрешении на 1х прогонять? Ты просто не даунскель
> а как работает апскейл х1?
Так же, как и при других икс, только без масштабирования
Ну и даунская херня. Как человек с таким магическим мышлением по отношению к сд апскейлу можно вообще писать в технотред
> в повышенном разрешении
> на 1х прогонять
Речь не о повышенном размере тайла, а об обработке пикчи большего размера, будь то одним тайлом, или ее более укрупненных кусков несколькими тайлами. И даунскейлить потом не обязательно, перечитай пост на который отвечаешь.
> к сд апскейлу
Сам придумал@сам подорвался. Там братишки повышают детализацию достаточно старым и простым способом, а ты бомбишь.
К слову про апскейл.
Сколько раз ни пробовал тайлед — у меня стабильно видны границы между тайлами, чуть отличающиеся по тону. Это вообще ликвидируется как-то (кроме рефайна границы на полтайла и ещё так же по круну) или пошло оно всё нахуй и нужно брать модели х4 и х8 сразу и не ебать мозги?
Сколько раз ни пробовал тайлед — у меня стабильно видны границы между тайлами, чуть отличающиеся по тону. Это вообще ликвидируется как-то (кроме рефайна границы на полтайла и ещё так же по круну) или пошло оно всё нахуй и нужно брать модели х4 и х8 сразу и не ебать мозги?
> Это вообще ликвидируется как-то
Если отличия именно по тону - увеличивай оверлап при генерации (вплоть до максимально возможного), увеличивай область смешивания, используй контролнет. Если же на стыках госты и наслаивания - наоборот уменьшай маску.
> нужно брать модели х4 и х8 сразу
Вут?
Алсо эта ерунда может быть если используешь низкое разрешение тайла, от 1к на современных 1.5 и выже для XL.
Ну есть конкретно модели nmkd x4 и x8, сразу хуярят без всяких тайлов. Но такое разрешение потом не посэмплировать почище.
>низкое разрешение
использовал дефолтные 512 для сд1.5
Ну да, я догадывался, что перекрытие надо увеличивать, но это сильно затягивает время рендера. Ну да ладно, ради годноты какой можно подождать.
Ок, попробую ещё повозиться.
>использовал дефолтные 512 для сд1.5
Как там в каменном веке 2022 году?
> Ну есть конкретно модели nmkd x4 и x8, сразу хуярят без всяких тайлов.
Ну это типичный ган апскейл, в автоматике для нужной кратности оно потом даунскейлится до получения нужного целевого разрешения, и уже на нем идет обработка диффузией.
> использовал дефолтные 512 для сд1.5
Вот, проблема обозначена, для тайлового апскейла дефолты другие были еще давно, для современных 1.5 даже для генерации сейчас это мало.
> но это сильно затягивает время рендера
С 512 - да. С 1024 увеличение с 64 до 128 - незначительно.
понял, спасибо.
Я как раз в 22м бросил, а ща вкатился, да и в ноде по дефолту 512 стояло.
Щас бы называть субъективное экспериментальное магическим мышлением. Это термин из точных маломерных областей, от которых генеративная херь настолько далеко, насколько еще ничего наверное не было в истории технологий.
Намерен прошариться в регуляризациях для лор. Поясните еще раз, что они делают.
1. Первое, что я понял, это предотвращение класс дрифта, т.е. тот факт, что в кепшенах будет "a huy v sapogah", не будет делать остальные "huys in background" похожими на целевой объект/концепцию.
2. Второе, что я вроде бы понял, это то что в самой лоре, в имени `img/5_sapogi huy` после пробела указывается базовый класс "о чем речь".
Так ли это? На что влияет?
3. В пнг инфо видно, что стандартные регуляризации это просто результаты базовой модели с промтом равным имени класса + ддим, кфг 7.
Можно ли делать классы дву/много- словными? Как тогда называть папку, `img/5_sapogi huy v palto`? Как вообще воспринимается текст после пробела? Как промт, как отдельные слова?
Алсо, даже в обычном случае, зачем нужен этот суффикс в img, если в `reg/1_huy` и так есть это слово?
Без обид всем, но хотелось бы инфу от конкретно знающих или практиков-экспериментаторов. Балабольство из туториалов всё уже прочитано, и доверия к нему немного, т.к. их клеймы я проверял, и они не бились с реальностью. Например, что нельзя апскейлить датасет, что кропать плохо, что тренить на генерациях смертный грех, что регуляризации это пережиток -- на поверку все это категоричный булщит.
Так что просьба не пересказывать слепые догмы, т.к. я не могу различить, кто проверил, а кто поверил. Зрячие догмы приветсвуются. Я их энивей проверю, но хочу начать с чего-то очевидного или наоборот.
1. Первое, что я понял, это предотвращение класс дрифта, т.е. тот факт, что в кепшенах будет "a huy v sapogah", не будет делать остальные "huys in background" похожими на целевой объект/концепцию.
2. Второе, что я вроде бы понял, это то что в самой лоре, в имени `img/5_sapogi huy` после пробела указывается базовый класс "о чем речь".
Так ли это? На что влияет?
3. В пнг инфо видно, что стандартные регуляризации это просто результаты базовой модели с промтом равным имени класса + ддим, кфг 7.
Можно ли делать классы дву/много- словными? Как тогда называть папку, `img/5_sapogi huy v palto`? Как вообще воспринимается текст после пробела? Как промт, как отдельные слова?
Алсо, даже в обычном случае, зачем нужен этот суффикс в img, если в `reg/1_huy` и так есть это слово?
Без обид всем, но хотелось бы инфу от конкретно знающих или практиков-экспериментаторов. Балабольство из туториалов всё уже прочитано, и доверия к нему немного, т.к. их клеймы я проверял, и они не бились с реальностью. Например, что нельзя апскейлить датасет, что кропать плохо, что тренить на генерациях смертный грех, что регуляризации это пережиток -- на поверку все это категоричный булщит.
Так что просьба не пересказывать слепые догмы, т.к. я не могу различить, кто проверил, а кто поверил. Зрячие догмы приветсвуются. Я их энивей проверю, но хочу начать с чего-то очевидного или наоборот.
Речь об 1.5 если что
> в регуляризациях
Чего добиться хочешь?
Практика показала что если капшнинг хороший - можно немного разбавить датасет чем-то нейтральным, что частично повторяет особенности тренируемого (тоже вангерл, похожая одежда и т.п.) но отсутствует ключевая тренируемая фича, и она же не указана в капшнах. Позволяет точнее разделять концепты и снизить импакт от хуевости датасета. Т.е. "регуляризировать" пихая в основной пулл а не в регуляризации, требования к качеству картинок там аналогично высокие, а не "всратая генерация с минимальным промтом".
Если на 1.5 и тренировать стиль, то с подобным осторожнее нужно быть, ее текстовый энкодер сильно слабее и такое может снизить усвояемость.
С регами сколько не пробовал - или эффект не заметен, или херь. Если поведаешь как ими можно что-то улучшить - велкам.
> что нельзя апскейлить датасет, что кропать плохо, что тренить на генерациях смертный грех, что регуляризации это пережиток
Дьявол как всегда в деталях
>Чего добиться хочешь?
Чуйки. Обзорное исследование, оценка влияния при неизменных датасетах и капшенах. У меня набралось лор, и я стал хорошо знаком с ними и их комбинациями, теперь смогу более-менее понимать разницу.
>Если поведаешь как ими можно что-то улучшить - велкам
Да, отпишу позже, что усвоил. Если лень не будет, сделаю репу с плотами.
На текущий момент пробовал только с/без регов, а также их количество. Когда "с" - юзал стандартные woman, реже sexy_woman, supermodel, для области жопоног, но тут без задней мысли. Без регов woman лица всегда выходили не те, что надо, с ними лучше. Количество странно влияло, опытным путем как-то пришел к (пикчи х 6). Это все мутный стихийный опыт, собираюсь его ломать и смотреть прям детально. Кепшенинг у меня тоже эволюционировал во времени, поэтому оценивать результаты по памяти сложно.
>"регуляризировать" пихая в основной пулл
Попробую так тоже, сравню, спс
бамп вопросу
По мне так хуйня без задач этот сдхл. Пикчи borderline uncanny. Жрет как не в себя, и врам, и место, и время. Лоры наверное вообще помрешь пока натренятся. Единственный плюс, что композиция поточнее, но в остальном трейдофф так себе.
>в потолок 12Гб уже чуть ли не долбится
Да явно долбится, на вае-этапе специфичная пауза и картина ресурс-мониторинга такие же, как если разрешение задрать туда, где в 1.5 хайрес фиксу памяти не хватило. Только в сдхл так происходит в каждой пикче.
> clip_l и clip_g нахуя выдумано?
Изначальная задумка предполагала описание в маленьком энкодере стиля, в большом всего остального, до сих пор имеем что их даже раздельно нормально тренить не получается
> чем турбомодели отличаются
Быстрое семплирование за несколько шагов в обмен на качество
> снизить потребление памяти можно?
Пробуй оптимизации, самая важная фп8 режим, с ним могут быть проблемы при использовании нескольких лор
Благодарю.
А то на реддите какие-то домыслы уровня «я пробовал пилить позитив на куски, совать в оба поля, дублировать и как-то что-то примерно не очень понятно»
>быстрое
Понял, аля LCM.
>фп8
знаю про понижение точности но не знал про лоры, спасибо.
Кде перекат?
> Когда "с" - юзал стандартные woman, реже sexy_woman, supermodel
Это про капшны для них, или какие-то "стандартные наборы"?
> ез регов woman лица всегда выходили не те, что надо, с ними лучше.
Каков был состав датасета и как были описаны пикчи с лицами? Хотябы примерно.
Это про папки с пикчами регов вот отсюда:
https://huggingface.co/datasets/ProGamerGov/StableDiffusion-v1-5-Regularization-Images
Встречал эту ссылку не в одном туториале по лорам. Хз насколько оно "стандартное", честно говоря.
>Каков был состав датасета и как были описаны пикчи с лицами? Хотябы примерно.
С/без регов пробовал как с кропами, так и с оригиналами. Кепшены из блипа выходили примерно такие:
a woman with brown hair and a red sweater looking at her phone
Я фиксил пиздеж, и от себя добавлял что-то вроде touching her hair, outdoors, trees with leaves, in a bathroom, beige walls, blurry background, furniture to the right, в таком духе (алсо см.сноску). Но без избытка, 2-4 запятых итого, не считая кейворда. Для кропов недавно стал добавлять close up - вроде чутка помогает.
Раньше мало правил кепшены, позже стал править больше, т.к. написал удобные скрипты. Опыт с с/без регов есть и в прошлом, где кепшены хуевые, и сейчас, где они неплохие кмк.
* Обычно я описываю то, что по моему мнению не является объектом тренинга. Но честно говоря это как-то конфликтует с "a woman with a long hair and a red sweater". Чо мне, не воман что-ли нужен? Или мне теперь всегда прописывать woman в промт? Я например girl/1girl пишу, т.к. woman их местами старит/жирнит, а я чот не по толстым старухам. Вот такие вопросы я и собираюсь расковырять.
> https://huggingface.co/datasets/ProGamerGov/StableDiffusion-v1-5-Regularization-Images
Учитывая что они 512 - лучше отправить на свалку истории.
С капшнами вроде все делаешь правильно.
> написал удобные скрипты
Что за скрипты?
> Обычно я описываю то, что по моему мнению не является объектом тренинга
А то что является игнорируешь?
> Или мне теперь всегда прописывать woman в промт
Пропишешь всегда вумэн и оно сместит выдачу по этому тегу в сторону твоего датасета, если грубо и упрощенно описывать.
>Что за скрипты?
Один запускает блип в текущей папке, потом собирает все в один файл вида:
```cap.tmp.txt
0001.txt::a woman with foo bar
0002.txt::a woman posing in baz
```
Слева xnview, справа файл. Потом как закончил, второй обратно его разделяет по отдельным файлам.
>А то что является игнорируешь?
В целом да.
Есть предложения по правкам для шаблона шапки? Хочу завтра днём перекатить.
Может кто подтвердить, по будке это актуальная инфа? 1.5 можно тренить начиная с 16 GB VRAM, а XL начиная с 20 GB VRAM?
Может кто подтвердить, по будке это актуальная инфа? 1.5 можно тренить начиная с 16 GB VRAM, а XL начиная с 20 GB VRAM?

А че, разве нельзя две лоры в одну соединить?
Ты про dreambooth-lora или полноценный файнтюн?
TLDR: Можно тренить лору на сдохлю и в 8 гигах. Качественный результат и адекватная скорость в сделку не входят.
Нормальный файнтюн XL недоступен обывателю, так что стоит ожидать повышенного наплыва лор и чекпоинтов, где живых нейтронов и половины не наберется.
Тренировка ниже 20 гигов достигается за счет градиент-чекпоинтинга, ниже 12 - треш типа загрузки базовой модели в 8 битах. Как это повлияет на выход - хз.
Чекпоинтинг позволяет легко бустануть батчсайз без сильного роста жора памяти и необходимости в аккумуляции, но снижает скорость тренировки.
Потребление памяти в гб:
> дримбус с тренировкой всех слоев
обычный запуск: бс1 38.5, бс2 44.0
градиент чекпоинтинг: бс1 34.4, бс2 35.2, бс8 40.5
> лора дим 32
обычный запуск: бс1 17.4, бс4 47.7
обычный + фуллбф16: бс1 16.7
градиент чекпоинтинг: бс1 9.4, бс2 13.1
фулл бф16 + чекпоинтинг: бс1 9.1
fp8base + чекпоинтинг: бс1 6.4
> лора дим 128
обычный запуск: бс1 20.5, бс3 41.7
обычный + фуллбф16: бс1 18.3, бс4 47.8
градиент чекпоинтинг: бс1 12
фулл бф16 + чекпоинтинг: бс1 10.3, бс4 15.0
fp8base + чекпоинтинг: бс1 9.9
> ликорис дим64+32
обычный запуск: бс1 18.6, бс2 30.4
градиент чекпоинтинг: бс1 10.6
фулл бф16 + чекпоинтинг: бс1 9.7
fp8base + чекпоинтинг: бс1 7.2
Хочешь не 8битный оптимайзер, аккумуляцию градиента или что-то еще - добавить еще несколько гигов к потреблению.
> Как это повлияет на выход - хз.
Стоит читать как
> Насколько сильно всрет
Алсо все значения - только потребление пихона, если делается на шинде с ускоряемым браузером, ютубчиком, парой мониторов и т.д. - можно гиг-два еще накидывать.
Аноны, я натренил лору и она при весе 1.0 несколько пережареная, но при весе 0.8 выглядит идеально. На меньших эпохах то же самое. Нужно снижать количество повторов (их 4 сейчас) или крутить нетворк альфу?
Просто юзай ее с весом 0.8. Причин пережарки может быть множества и одна из основных - датасет. Если других побочек нет то просто забей.
Ого, серьёзный подход, спасибо.
Мда, жозенький гейткип по железу для тренировки полноценных XL-чекпоинтов выходит. Получается, для полноценного запуска будки для XL нужна пара видеокарт топа потребительского сегмента (34-39 GB VRAM для бс1). Без них только лоры/ликорисы тренить остаётся.
> нужна пара видеокарт топа потребительского сегмента
Если расскажешь как можно объединить врам двух десктопных карт для использования в скриптах кохи (не в голом диффузерсе) - буду очень благодарен.
Подскажите как тренить Лору, если у меня только 37 картинок перса:(
Этого вполне достаточно. Я тренил лоры и с 15 картинками и заебись получилось.
Бамп.
Можно, в редких случаях оно действительно объединится, в большинстве просто поломается.
Окей, а какие параметры надо ставить?
Я ставлю lr 0,0001 по один повтор и 10 эпох но она явно не готова:(
37 картинок по 1 повтору и 10 эпох = 370 шагов. Она точно не будет готова.
Для обучения лоры на перса нужно 1500-2000 шагов. Поставь хотя бы 5 повторов.
Окей, попробую.
А что лучше крутить, эпохи или шаги?
Лорам с цивика 1.0 часто тоже дохера. Особенно если лора в пикче не одна, они воевать начинают. Это норма, попробуй комбинации типа <лора:0.8> (кейворд:1.2).
Если это первая лора, то еще лучше убедиться, что это именно лернинг пережарка, а не задранные дим/альфа например.
Или поиграться с параметрами - лр, шедулер. Ну или взять адаптивный оптимизер, может понравиться.
>Причин пережарки может быть множества и одна из основных - датасет
По какому критерию?
Тоже интересно, но лично у меня такое чувство, что никто толком не знает. Вот этот https://rentry.org/59xed3#number-of-stepsepochs в начале пишет что репиты теперь чутка переоценены, а в #-секции пишет что репиты чутка лучше эпох, и эпох якобы надо немного, и то только чтобы если вдруг пережарил, то можно было взять предыдущую и не начинать заново.
Туториалы от индусов вообще без задней мысли советуют какие-то догмы по методичке. Сколько читал, ни разу не видел внятного объяснения различия например 10-ти эпох по 5 репитов против 50-ти эпох по одному репиту.
>у меня только 37 картинок перса
Депендс, натренишь увидишь. У меня иногда бывало, что из 30-50 выкинуть 10-20 пикч которые "не в тему" давало даже лучший результат, чем просто все что есть. А так в целом цифра неплохая.
> Сколько читал, ни разу не видел внятного объяснения различия например 10-ти эпох по 5 репитов против 50-ти эпох по одному репиту.
Тоже искал инфу по этому поводу. По идее разницы вообще не должно быть. Количество эпох удобно только количеством сохраненных промежуточных результатов.
На качество лоры (не беря во внимание другие параметры/качество датасета) влияет только общее число шагов и количество повторов каждого изображения в рамках одного обучения (в случае 5 повторов по 10 эпох и 50 повторов с одной эпохой эти числа одинаковые).
Снизил количество эпох до 16 (до этого было 20, косинусный планировщик, оптимизатор prodigy) и поставил альфу равную половине дима (до этого была 1) и всё заебись стало.
Тоже так думаю, но меня смущает существенная пауза между эпохами. Она долговата для просто скидывания на диск, хотя возможно там какой-то процесс, который рабочее представление лоры в враме выводит в он-диск веса, и он нетривиальный. Плюс для сохранения не каждой эпохи есть параметр, что антинамекает.
Муть короче. Всегда так лень тестить то, что скорее всего правда...
Мой опыт для лиц таков, что низкая альфа даже не напоминает чара. А когда только общая геометрия важна, типа поз, объектов, то наоборот с альфа 1 лучше выходит. По ощущениям, альфа как бы тянет пикчу конкретнее в датасет.
>prodigy
Чо как он вообще по сравнению с адамом?
Лр имеет мало смысла без указания оптимайзера и альфы. Эпохи ни о чем не говорят без количества повторов (и батчсайза хоть в меньшей степени).
> По какому критерию?
Много их, хреновое содержимое, однообразие в чем-то помимо тренируемого, капшнинг если в общем.
> что никто толком не знает
Не то чтобы там много нужно знать. Раз в эпоху идет сохранение результата (если не задано иное), перемешивание капшнов (поправьте если не так), порядок прохода датасета с несколькими папками (раньше по очереди каждая прогонялась число повторов и только потом шел переход к следующей, если одна то не актуально).
> 10-ти эпох по 5 репитов против 50-ти эпох по одному репиту
Если дефолтные настройки и обычнолора без каких-то нюансов - получишь 50 файлов вместо 10, вот и все. Ну и где 50 эпох будет трениться дольше из-за перерывов на сохранения. Результаты будут чуть ли не идентичными в пределах рандома на одинаковом числе шагов, специально сравнивалось, так что стоит выбирать исключительно из удобства оценки. Получить меньше-больше файлов можно приказав сохранять каждые N эпох, или наоборот каждые N шагов.
Так что похуй, ставь 6-8-10 эпох, повторами подгоняй до нужного числа и инджой. Или наоборот выставляй космическое количество эпох, а потом выискивай какая из десятков плацебо покажется лучше.
Нюанс с батчсайзом и аккумуляцией градиента, не нужно увеличивать число шагов пропорционально им. Если стоит 2-3 то вообще не трогай, если 5+ то можешь процентов на 20-30 увеличить.
> но меня смущает существенная пауза между эпохами
--persistent_data_loader_workers
> для лиц
Анимублядские лица и все черты с альфой 1 запоминает превосходно, бонусом не тащит лишнего. Скорее всего дело не в 2д-3д а в том что учишь на клозапах вместо более общих планах, потому и нужен больший вес.
А лр крутить то пробовал?
Альфа 1, Адам оптимайзер
Для альфы 1 и адама это низкий лр, начать стоит хотябы с 5e-4. Так, приличные лоры на адаме получались даже с 3e-3 на альфе 1 или 1..2e-3 на альфе 8, но это с бс побольше на 1.5.




Предыдущий тред:
➤ Софт для обучения
https://github.com/kohya-ss/sd-scripts
Набор скриптов для тренировки, используется под капотом в большей части готовых GUI и прочих скриптах.
Для удобства запуска можно использовать дополнительные скрипты в целях передачи параметров, например: https://rentry.org/simple_kohya_ss
➤ GUI-обёртки для sd-scripts
https://github.com/bmaltais/kohya_ss
https://github.com/derrian-distro/LoRA_Easy_Training_Scripts
https://github.com/anon-1337/LoRA-train-GUI
➤ Обучение SDXL
https://2ch-ai.gitgud.site/wiki/tech/sdxl/
➤ Гайды по обучению
Существующую модель можно обучить симулировать определенный стиль или рисовать конкретного персонажа.
✱ LoRA – "Low Rank Adaptation" – подойдет для любых задач. Отличается малыми требованиями к VRAM (6 Гб+) и быстрым обучением. https://github.com/cloneofsimo/lora - изначальная имплементация алгоритма, пришедшая из мира архитектуры transformers, тренирует лишь attention слои, гайды по тренировкам:
https://rentry.co/waavd - гайд по подготовке датасета и обучению LoRA для неофитов
https://rentry.org/2chAI_hard_LoRA_guide - ещё один гайд по использованию и обучению LoRA
https://rentry.org/59xed3 - более углубленный гайд по лорам, содержит много инфы для уже разбирающихся (англ.)
✱ LyCORIS (Lora beYond Conventional methods, Other Rank adaptation Implementations for Stable diffusion) - проект по созданию алгоритмов для обучения дополнительных частей модели. Ранее имел название LoCon и предлагал лишь тренировку дополнительных conv слоёв. В настоящий момент включает в себя алгоритмы LoCon, LoHa, LoKr, DyLoRA, IA3, а так же на последних dev ветках возможность тренировки всех (или не всех, в зависимости от конфига) частей сети на выбранном ранге:
https://github.com/KohakuBlueleaf/LyCORIS
Подробнее про алгоритмы в вики https://2ch-ai.gitgud.site/wiki/tech/lycoris/
✱ Dreambooth – выбор 24 Гб VRAM-бояр. Выдаёт отличные результаты. Генерирует полноразмерные модели:
https://rentry.co/lycoris-and-lora-from-dreambooth (англ.)
https://github.com/nitrosocke/dreambooth-training-guide (англ.)
✱ Текстуальная инверсия (Textual inversion), или же просто Embedding, может подойти, если сеть уже умеет рисовать что-то похожее, этот способ тренирует лишь текстовый энкодер модели, не затрагивая UNet:
https://rentry.org/textard (англ.)
➤ Тренировка YOLO-моделей для ADetailer:
YOLO-модели (You Only Look Once) могут быть обучены для поиска определённых объектов на изображении. В паре с ADetailer они могут быть использованы для автоматического инпеинта по найденной области.
Подробнее в вики: https://2ch-ai.gitgud.site/wiki/tech/yolo/
Не забываем про золотое правило GIGO ("Garbage in, garbage out"): какой датасет, такой и результат.
➤ Гугл колабы
﹡Текстуальная инверсия: https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb
﹡Dreambooth: https://colab.research.google.com/github/TheLastBen/fast-stable-diffusion/blob/main/fast-DreamBooth.ipynb
﹡LoRA [1] https://colab.research.google.com/github/Linaqruf/kohya-trainer/blob/main/kohya-trainer.ipynb
﹡LoRA [2] https://colab.research.google.com/drive/1bFX0pZczeApeFadrz1AdOb5TDdet2U0Z
➤ Полезное
Расширение для фикса CLIP модели, изменения её точности в один клик и более продвинутых вещей, по типу замены клипа на кастомный: https://github.com/arenasys/stable-diffusion-webui-model-toolkit
Гайд по блок мерджингу: https://rentry.org/BlockMergeExplained (англ.)
Гайд по ControlNet: https://stable-diffusion-art.com/controlnet (англ.)
Подборка мокрописек для датасетов от анона: https://rentry.org/te3oh
Группы тегов для бур: https://danbooru.donmai.us/wiki_pages/tag_groups (англ.)
Гайды по апскейлу от анонов:
https://rentry.org/SD_upscale
https://rentry.org/sd__upscale
https://rentry.org/2ch_nai_guide#апскейл
https://rentry.org/UpscaleByControl
Коллекция лор от анонов: https://rentry.org/2chAI_LoRA
Гайды, эмбеды, хайпернетворки, лоры с форча:
https://rentry.org/sdgoldmine
https://rentry.org/sdg-link
https://rentry.org/hdgfaq
https://rentry.org/hdglorarepo
https://gitgud.io/gayshit/makesomefuckingporn
➤ Legacy ссылки на устаревшие технологии и гайды с дополнительной информацией
https://2ch-ai.gitgud.site/wiki/tech/legacy/
➤ Прошлые треды
https://2ch-ai.gitgud.site/wiki/tech/old_threads/
Шапка: https://2ch-ai.gitgud.site/wiki/tech/tech-shapka/