

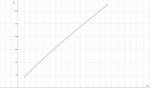

Охуенен, просто нет слов.
> С картинками что-то неладное происходит, грузятся через раз. А на котокоробку если возвращать - там из-за ркн оно через раз грузит и нужен впн/прокси.
Гитгуд очень медленно картинки отдаёт, если их на нём хостить, по какой-то причине. Поэтому, я рассчитывал, что пикчи будут на сторонние сервисы грузиться, по типу catbox. Из минусов то, что такой подход добавляет ещё одну точку отказа в виде картинкохостинга - на том же imgur уже выпиливали картинки, которые использовались в местных гайдах по sd.
Вообще, у гитгуда сам хостинг статики на коленке сделан, насколько я понимаю. Я когда изначально там вики поднял, она просто не открывалась в Firefox из-за кривых сертификатов - я немного поисследовал проблему и понял, что это общая проблема для всего хостинга от gitgud. Но когда я связался с девом гитгуда, он за пару часов поправил проблему, а это был вечер воскресенья (мне даже неловко от такого стало). То есть сам фикс видать пустяковый был, но почему без прямой наводки они сами багу раньше не поправили...
Про проблему с catbox у ркн в первый раз слышу.
У меня была мысль арендовать какую-нибудь копеечную vps'ку и настроить туда автодеплой собранной вики вместо гитгуда. В этом случае, все картинки, включая шизогриды для sd, можно хранить напрямую в репе. В самом же гитгуде оставить только репу. Но, в этом случае, появятся риски, что, если, в какой-то момент, я забью на всю ии-движуху и не буду продлевать оплату, то проект упадёт с непонятными перспективами - придётся кому-то другому про инфраструктуру думать. Я бы мог такое организовать, но не уверен, стоят ли риски того и как вы вообще к подобному муву отнесётесь.
Сейчас же мы чисто фришный хостинг используем. Из моей инфраструктуры там только билд-агент в виде древнего thinkpad'а, который отслеживает правки в репе 24/7, собирает проект и разворачивает статику на предоставляемом gitgud'ом фришном хостинге. Роль билд-агента может выполнять любой калькулятор с доступом в интернет.
Тред умер нахуй
Будет интересно почитать гайд на таверну
А почему по классике не сделать вики на гитхабе?
Будет интересно почитать гайд на таверну
А почему по классике не сделать вики на гитхабе?
> Гитгуд очень медленно картинки отдаёт, если их на нём хостить
Вот в чем дело, графики и мелкие скрины норм работают, а где крупнее - через раз. Потом на котокоробку значит перекину обратно, или попробую пережать чтобы загружались оттуда.
С сертификатами сейчас действительно все ок, так бы и не вспомнил.
> Про проблему с catbox у ркн в первый раз слышу.
Хз, может и не ркн но поведение идентичное. Чсх оно рандомно, иногда работает, иногда не грузит. Впску - хз, текущая версия прилично работает кмк, а с пикчами тема приемлемая.
Алсо, статьи на циве нельзя сделать под коллективный/групповой доступ?
> Будет интересно почитать гайд на таверну
У нее функционал богатый очень и не то чтобы его весь знаю, только основное. Может если будет не лень разобраться хотябы с озвучкой/распознаванием, запросами генерации пикч и около того.
Найс, спасибо что уделил время
> А почему по классике не сделать вики на гитхабе?
Минорные проблемы - в вики на гитхабе не работает система с ПРами, так что люди без прав в репе не смогут предложить правки (но мы такую возможность по факту не используем, так что это мелочь). Поскольку это чисто онлайн-система, то у контрибьютеров нет мотивации держать актуальную локальную копию, которая может выступить в роли бекапа на случай чп.
Но вариант с вики на гитхабе кмк был бы лучше вики на условном fandom, т. к. на гитхабе вики хранится в виде честной гит репы, которую можно бекапнуть вместе со всей историей одной командой.
Основная проблема с гитхабом в том, что есть подозрение, что за отдельные части вики её могут пидорнуть с гитхаба - раз проект sd-web-ui (который от automatic1111) оттуда около года назад выпилили за то, что в readme-файле были ссылки на статьи по теме то ли с хентаем, то ли с nai leak, уже не помню точно. Я читал правила гитхаба, и, как мне показалось, там просто за условный панцушот или джейлбрейк с фокусом на ерп выпилить репу могут. В общем, нужно определённых правил цензуры тогда придерживаться, чтобы минимизировать риски, в случае гитхаба. В том же гитгуд уже много лет хостятся проекты эроге с лолями, так что подобных рисков сильно меньше.
Зачем вообще что-то менять? Работает- не трогайте.
Я не хочу ничего менять. Только с картинками разобраться бы, чтобы как в случае с rentry всё не ломалось на части провайдеров.
Анон задал хороший вопрос, на который стоило ответить. Просто я сам изначально рассматривал именно гитхаб в качестве репы для вики, но из-за перечисленных минусов решил использовать другую опцию, которой выступил гитгуд.

>he chuckled darkly
в каждом первом ответе. Заебал. Как фиксить? Использую угабугу
в каждом первом ответе. Заебал. Как фиксить? Использую угабугу
Модель? Температура? Квант? Мы не телепаты, анон
Smirking.

pivot-0.1-evil-a.Q8_0.gguf
пивот евил изначально сломан, он просто эксперимент на обратном выравнивании
блин, а что юзать то тогда?
Мне чисто под кум и чтобы влезало в 7 гб (11 с учетом контекста)
toxichermes-2.5-mistral-7b попробуй, он тем же методом расцензурен но уже не сломан
Старая добрая Synatra-7B-v0.3-RP хороша для кума, как по мне, хоть и тупит мб больше других 7b моделей. Ещё недавно наткнулся на её вот такой популярный мерж https://huggingface.co/PistachioAlt/Synatra-MCS-7B-v0.3-RP-Slerp-GGUF Эта более уравновешенная.
Из твоего скриншота настроек сэмплеров выходит, что ты вообще их не применяешь. Это не есть хорошо для мелких моделей. Поставь хотя бы minP 0.1 или дефолтные topP 0.9, topK 30, если с остальными экспериментировать неохота. Ну и rep pen поднять с единицы хотя бы на 1.1 можно.
https://www.reddit.com/r/LocalLLaMA/comments/18z04x5/llama_pro_progressive_llama_with_block_expansion/
Ну ебать, еще один метод улучшения моделей.
Теперь это наращивание знаний модели без потерь.
Ну ебать, еще один метод улучшения моделей.
Теперь это наращивание знаний модели без потерь.
За этим приходить через полгода, не раньше.
А че есть что нить по наращиванию скоростей генерации? А то умные модели это хорошо, но генерить по 1.7 токена 70b ДОЛГОВАТА.
жди мамбу, трансформеры не ускорить, разве что прунить и квантовать для уменьшения размера.
Что за мамба, анончик?
А че, на форчке побанены русские айпи? Попытался написать в /lmg/, пишет айпи ренж блокед дуе ту абуз.
Почитал про мамбу, двоекратное уменьшение размера моделей при том же качестве чет слишком красиво звучит.
мимо другой анон
https://arxiv.org/abs/2312.00752
https://huggingface.co/models?sort=created&search=mamba
Всё хочу одну скачать на пробу и каждый раз лень настраивать. Там какие то есть уже новые файнтюны на базовых моделях, хоть и 3b.
Но вроде как они равны 7b по мозгам, по крайней мере по заявлениям исследователей. Как оно на деле хуй знает.
Нашел только это из того как мамбу запустить, по другому хз
https://github.com/havenhq/mamba-chat
Кто шарит может поиграться, только отпишитесь что ли, интересно ведь
Аноны, а что за карточку персонажа он требует?
Завтра потыкаю может быть и отпишусь
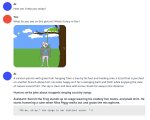
Кто "он" ?
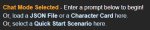
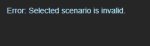
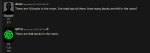
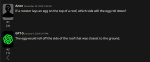
Ну... Кобольд. На первом пике требует либо промт (куда его?), либо карточку (какую?), либо выбрать сценарий. Но на все кастомные (которые импорт фром) он выдает пик 2.
Да, я ньюфаг
Поставь SillyTavern, подключи ее к кобольду, карточки бери на chub.ai. У кобольда интерфейс говна, его использовать можно разве что для проверки работоспособности модели. У меня он вообще настроен на запуск без вебморды, чисто апи для таверны.
Для deepsex 34b какие настройки в таверне оптимальны?
А то отвечает что на симпле что на миростате как то суховато прям.
А то отвечает что на симпле что на миростате как то суховато прям.

>toxichermes-2.5-mistral-7b
нахуй идет быстро решительно
>without your consent
Как же они заебли....
Как же они заебли....
>Synatra-7B-v0.3-RP
соя ёбаная.
Бомж не захотел насиловать 14-летнюю девочку.
Пивот с этим проблем не имеет.
Итак, пивот все еще наименее соевый. Может быть еще кто варианты подкинет?

Стаканул Р40 + 1070, запустил yi-34b-v3.Q6_K и получил производительность 6.3т/сек (1070 медленная, наверное, две p40 дали бы 7+++).
На соло Р40 в yi-34b-v3.Q4_K_M было 9т/сек.
Неожиданно, но в итоге стаканье видеокарт не создаёт накладных расходов как предполагали всем тредом ранее.
Кстати, этого стака уже хватает на запуск 70b Q2_K (лол, проверю). А если использовать проц + Р40, то производительность будет 1.8 т/сек для 70b Q4_K_M.
Ещё меня начала мучать шиза на тему, что q6 сильно лучше могёт в причинно-следственные связи, хотя лексика у них ощущается одинаковой. Это немного не совпадает с общепринятым знанием про потери 0.00001% информации при квантовании. Поясните, плз.
Мимо китаедаун.
На соло Р40 в yi-34b-v3.Q4_K_M было 9т/сек.
Неожиданно, но в итоге стаканье видеокарт не создаёт накладных расходов как предполагали всем тредом ранее.
Кстати, этого стака уже хватает на запуск 70b Q2_K (лол, проверю). А если использовать проц + Р40, то производительность будет 1.8 т/сек для 70b Q4_K_M.
Ещё меня начала мучать шиза на тему, что q6 сильно лучше могёт в причинно-следственные связи, хотя лексика у них ощущается одинаковой. Это немного не совпадает с общепринятым знанием про потери 0.00001% информации при квантовании. Поясните, плз.
Мимо китаедаун.
Купи вторую гпу, будет по 17+ т/с на 70б, сможешь инджоить и наслаждаться. Или возьми одну-две p40, в теоретической теории они смогу обеспечить скорость стриминга сравнимую или быстрее чем скорость чтения на 70б.
Или дождить тему с горячими нейронами, довольно перспективная штука.
Возможно потыкаю, или потом, отпишусь.
> Бомж не захотел
Асуждаю
> не создаёт накладных расходов
В каком лаунчере? Бывшая не создает, но там паскаль очень слаб. Жора вроде как создает проблемы, но их природа не изучена.
> 1.8 т/сек для 70b Q4_K_M
Грустновато, конечно, оно с другими видюхами на ддр5 быстрее получается. Второй p40 или чего-то жирного нету случаем??
> что q6 сильно лучше могёт в причинно-следственные связи, хотя лексика у них ощущается одинаковой
Единичный случай скорее всего, отпиши подробнее что там, так можно будет исследовать.
>В каком лаунчере?
lamacpp, только он работает быстро на паскалях.
>Второй p40 или чего-то жирного нету случаем??
Нету. Только несколько затычек.
>отпиши подробнее что там
Ох, тут придётся делать десятки скринов чтобы можно было что- то сравнить.
Может быть была инфа, что yi глупеют от квантования, но не так сильно как мистрали?
Ананасы, нуб репортинг ин. Что писать в промпт, чтобы модель не пичкала меня соевой моралью? Мне не нужна какая-то чернуха, но мне нужен текст с определенным настроением. Даже нейтральные промпты это чудище умудряется повернуть так, что персонаж начинает угрызения совести испытывать по поводу того, что кому-то что-то не так сказал. Mistral instruct 0.1 7B.
Вообще, как составлять промпт? Как в ЧатГПТ?
Вообще, как составлять промпт? Как в ЧатГПТ?

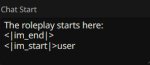
Самый адекватный выход тут - искать какие-то менее соевые файнтьюны. Дефолтная инстракт версия заточена быть полезным безопасным помощником. Промптинг как для больших моделей тут не поможет, 7б модель не поймёт полотна инструкций. Ну можешь попробовать добавить в промпт какие-то очень-очень простые инструкции вроде того, что ролеплей fictional, что у персонажа есть свои цели, к которым он должен стремиться несмотря ни на что, и прочее. Ещё если используешь ChatML инстракт пресет, который рекомендуется для мистраля, то попробуй включить имена и подредактировать его как на первом пике, чтобы убрать упоминание ассистента. Начало чата я ставлю как на втором пике, чтобы показать сетке, где закончился системный промпт, и начался чат, который надо продолжать, но мб это избыточно. И в мейн промпте не должно быть фигни вроде "you are helpful assistant".
Возьми просто любой файнтюн.
Dolphin, OpenChat
Они мало того что без сои, так еще и работают лучше.
Джейлбрейки на локальных моделях это бред вообще.
Это для любителей MINISTRATIONS извращение.
Привет, ананасы!
Всех с Наступившим!
В общем, положняк такой: мне в жопу заноза попала - хочу извергнуть из ануса нейросетевого стримера, который играет в какую-то несложную игру, пиздит с чатиком и имеет навык не рыгать буквами, вместо осмысленных предложений.
Задача уже на этом этапе звучит как пиздец и всё усугубляется тем, что у меня абсолютный ноль знаний и понимания в теме, но много мотивации и свободного времени.
Я полистал местные треды и столкнулся с тем, что закреплённые в шапке гайды не актуальны, например, и без помощи местных знатоков я не справлюсь.
Реквестирую помощь на данном этапе. С какой стороны начать есть этот пирог? Пните в нужную сторону. Пока однозначно понятно следующее: нужно как минимум разобраться с компьютерным зрением, начать обучать по вводным параметрам какую-то языковую модель, а также, скорее всего, поебаться и разобраться с API некоторых платформ.
Всех с Наступившим!
В общем, положняк такой: мне в жопу заноза попала - хочу извергнуть из ануса нейросетевого стримера, который играет в какую-то несложную игру, пиздит с чатиком и имеет навык не рыгать буквами, вместо осмысленных предложений.
Задача уже на этом этапе звучит как пиздец и всё усугубляется тем, что у меня абсолютный ноль знаний и понимания в теме, но много мотивации и свободного времени.
Я полистал местные треды и столкнулся с тем, что закреплённые в шапке гайды не актуальны, например, и без помощи местных знатоков я не справлюсь.
Реквестирую помощь на данном этапе. С какой стороны начать есть этот пирог? Пните в нужную сторону. Пока однозначно понятно следующее: нужно как минимум разобраться с компьютерным зрением, начать обучать по вводным параметрам какую-то языковую модель, а также, скорее всего, поебаться и разобраться с API некоторых платформ.
> Пните в нужную сторону. Пока однозначно понятно следующее:
Тебе понадобятся железки. Что сейчас в наличии?
Да.
Очередной пиздёж, да, и дроч на тесты.
Скил ишью.
>у меня абсолютный ноль знаний и понимания в теме
Ну так приобретай.
>закреплённые в шапке гайды не актуальны
Всё там актуально на 100%.
>нейросетевого стримера, который играет в какую-то несложную игру, пиздит с чатиком и имеет навык не рыгать буквами, вместо осмысленных предложений
Не осилишь, инфа 146%.
В базе 3070Ti и 5900Х, но мощностей ещё есть у меня!
Теоретически, тебе нужен CogAgent, подходящее железо и очень много времени и мотивации ебстись со всем этим.
>Ещё меня начала мучать шиза на тему, что q6 сильно лучше могёт в причинно-следственные связи, хотя лексика у них ощущается одинаковой. Это немного не совпадает с общепринятым знанием про потери 0.00001% информации при квантовании.
А где ты это общепринятое увидел? Тут несколько раз срачи были на эту тему, и есть 2 стула - те кто оценивают потерю по тесту перплексити, и те кто не доверяет такому простому тесту. Собственно - любое квантование идет с потерями, так что даже если модель не теряет способность генерировать текст, она может потерять связность на более высоком уровне. На уровне следования контексту или понимания че от нее вообще надо.
Более, абстрактные области. Вот это самое причинно-следственное. Мозги, грубо говоря.
Те же 7b обладают меньшим запасом прочности и теряют способность генерировать текст раньше, чем жирные сетки. Но то что 34b работают на 4 кванте не значит что они НЕ потеряли в качестве, просто потеря не дошла до заметной потери в генерации ответов.
Любая сетка будет работать без потерь только запускаясь в ее родном размере. Это fp16. Может быть минимальные потери будут на 8q, но они будут, хоть и мизер.
Вот только запускать нормальный размер часто не на чем, поэтому приходится возится с ущербными копиями оригинала, квантами поменпьше.

В базе блок-схема такая. Для начала научить бы её разговаривать. Поможешь дополнить?
Рад буду любым идеям и информации. Сейчас агрегирую очень много данных и изучаю очень много информации. Надеюсь при помощи анонов сделать нечто годное с открытым кодом.

>Скил ишью.
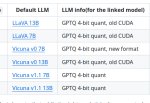
все кроме пивот:
аааа нееет что ты делаешь, прекрати, я не буду этого делать, ты совершаешь ошибку, тебе это не нужно аааа
литералли пикрелейтед
пивот:
я из тебя всю душу выебу, ебать, погнали нахуй
Ну камон.
Ну вот еще, в 7 гигов 5ks войдут
solar-10.7b-instruct-v1.0-uncensored
Фроствинд хорошо следует персонажу, если пропишешь маньяка скорей всего будет действовать как маньяк
Frostwind-10.7B-v1
Этот тоже как бы расцензурен, и он тоже есть в разных размерах
bagel-dpo-7b
Пивот эвил весело запускать, но в чате он шизит
Так как сломан слишком сильным антивыравниванием
При ротации контекста ощущается сильное замеждение генерации.
Вставляю контекст 4к. До примерно 3.5к - все генерирует быстренько. Когда доходит до 3.5 - начинается пиздец и ожидания по 70 секунд пока он там отсетет лишнее и сгенерирует новое.
Есть варианты как фиксить?
Я внезапно понял, что 4к конетекста в рп - это вообще ни о чем.
Вставляю контекст 4к. До примерно 3.5к - все генерирует быстренько. Когда доходит до 3.5 - начинается пиздец и ожидания по 70 секунд пока он там отсетет лишнее и сгенерирует новое.
Есть варианты как фиксить?
Я внезапно понял, что 4к конетекста в рп - это вообще ни о чем.
>родном размере. Это fp16
Замечу, что 16 бит это половинная точность. Полная 32, но в некоторых случаях и её не хватает, и для нейросеток когда-то использовали двойную точность.
Похоже, что у тебя не хватает памяти, и начинается подкачка пары сотен мегабайт. Давай подробнее, что на чём и чем запускаешь.
Локалки тебе не нужны, тупо контекста не хватит на целый стрим, тебе нужен клод или гптыня с их 32-100к контекста. Гипотетически тебе нужна связка языковая модель + апи твича/ютуба для получения чата + нужный промпт + синтезатор голоса + витуберский софт. На инпут текстовой модели подается отрывок текущего чата, генерируется ответ, он загружается в синтезатор голоса, голос подаётся в витуберский софт, витубер пиздит на стриме, в итоге все должно работать. С игрой сложнее, тебе придется играть самому, нейросетей которые играют самостоятельно я не видел, разве что в какие-нибудь шахматы.
>нейросетей которые играют самостоятельно я не видел, разве что в какие-нибудь шахматы.
Кучу раз видел какие то эксперименты с майнкрафтом и нейросетями, про исследования автономных агентов и тд


лмао
Интересно
Пивот как всегда лол
Вобще не хватает сеток, половина какие то странные взяты

стащил из этого треда, это мемные модели которые часто форсились в форчановском /lmg/
https://boards.4chan.org/g/thread/98282960
>За этим приходить через полгода, не раньше.
Хуевый из тебя пророк анонче
https://huggingface.co/TencentARC/LLaMA-Pro-8B
Вот и первая сетка по методу наращивания знаний без потерь, если я правильно понял.
https://www.reddit.com/r/LocalLLaMA/comments/18z04x5/llama_pro_progressive_llama_with_block_expansion/
Она кстати тут есть или ее файнтюн
РП-кал ожидаемо самый соевый, лол. Не хватает в сравнении базового Багеля.
там кста предпоследний пост, челик тестит beyonder-4x7bv2+ на своей расистке emily, модель вообще на отъебись игнорирует добрую половину описания и контекста чата, кек
Самый нормальный файнтюн микстраля - это Notux. Ужатые 4х7 вообще кал из под васянов.
поздравляю
не трогай час-два если с холода притащил, на них конденсата куча
пока не отогреются и влага не испарится лучше не включать
> сетка по методу наращивания знаний без потерь
хм, надо собрать самые топовые модели по типу этой :
https://huggingface.co/TheBloke/SOLAR-10.7B-Instruct-v1.0-uncensored-GGUF
и нарастить мега-базовую и ультра умную нейроночку что будет выполнять каждый твой приказ без колебаний.
ну а вообще без приколов, если это действительно работает как DPO или laser, то эта троица есть самый эффективный способ по дополнению нейронки новыми знаниями.
или можно юзая этот метод, вырвать из нейронки всё что выдаёт сою в конечном результате, исходя из того что если можно добавить transformer blocks, то так же их можно и убрать.
Да уж, веселье только разгоняется с этой кучей методов улучшений. 2024 год будет ебейшим в плане развития ии.
Главное что бы не последним, лол
>нейросетей которые играют самостоятельно я не видел
Даже в дотку режутся. Но всё за закрытыми стенами.
Красава. Ждём тестов 70B.
И как оно работает? Особенно на жоре, который славится своей хуёвой поддержкой всех нововведений.
>то так же их можно и убрать
Ой не факт.
Так же про 2023 говорили.
>Так же про 2023 говорили.
Будто он таким не был.
>И как оно работает? Особенно на жоре, который славится своей хуёвой поддержкой всех нововведений.
Тесты уже есть на пикче, так что скорей всего работает
Да и ггуф уже выкатили вместе с другими форматами
Да кто такой этот жора

Из новой шапки.
https://huggingface.co/TheBloke/LLaMA-Pro-8B-GGUF
ггуф запускается кобальтом без ошибок, и оно отвечает осмысленно.
Ну че, новая базовая модель и новые файнтюны скоро
ггуф запускается кобальтом без ошибок, и оно отвечает осмысленно.
Ну че, новая базовая модель и новые файнтюны скоро
>8b
Фи
>Будто он таким не был.
Как по мне, всё самое интересное было в 2021, когда запилили GPT3. 2022 был годом хайпа с чат моделью, а в 2023 просто к этому получили доступ гои типа нас. По сути ничего принципиально нового.
Уже вижу как унди начинает клепать новые франкенштейны-шизомиксы.
> Уже вижу как унди начинает клепать новые франкенштейны-шизомиксы.
Так и не понял, на кой хуй он это делает. Затраты во, а результат минимальный.
Самопиар же.
Кстати, там в кобольдЦП добавили logit_bias.
>logit_bias
чё эта?
Давка конкретных токенов.
Дурачье, теперь можно дообучить любые сетки, 7b просто проба
Ждем новых 34b-36b
Ну или хотя бы доученного солар 11b
> дообучить любые сетки, 7b просто проба
Жду, когда начнут обучать на порнорассказах.
>7b просто проба
Тут уже триллион инициатив остановилась на 7B, лол. Надо запретить всё что меньше 70B, вот тогда прогресс попрёт.
Вторая 4090 нынче ДОРОХОВАТО стоит, тащемта.
>возьми одну-две p40
Ну вот кстати можно и попробовать, хотя тут не понятно как оно с основной картой дружить будет.
>Тут уже триллион инициатив остановилась на 7B, лол.
Просто тебе результаты получше не показывают, вот и все. Самый смак как всегда за закрытыми дверями. Не думаешь ли ты что успех на малой сетке остановит от улучшения большой сетки? Только результат уже никто в открытый бетатест и рекламу не выложит.
Добиваясь результата и выкладывая его просто привлекают деньги показывая что они могут достичь успеха. Как мистраль, например.
Спасибо за ответы, посмотрю файнтьюны. Но раз все упирается в модель, может имеет смысл докинуть оперативы до 32, она сейчас недорогая, да какую-нибудь Ламу 70B гонять, она поместится в 32? Хотя, скорость генерации на процессоре печальная, конечно. Подскажите сетап компа заодно адекватный. Как вообще процессор это дело обрабатывает, количество ядер важно? И насколько видюха разгоняет процесс, если взять какую-нибудь условную 3060. После быстрой Мистраль уже как-то ждать, пока там модель напердит по одной букве в чат, как-то печально.


>и оно отвечает осмысленно.
Шизит порой весьма забавно. МинП лучше вообще не врубать. Классику проваливает стабильно, так что... Мой вердикт на всё новое как всегда- говно неюзабельное.
>Как мистраль, например.
Только мистраль. Да и то сомнительно. Остальные точно в пролёте. Или ты думаешь, что тому же унди перепадёт что-то большее, чем донаты на парочку 4090?
32 гиг мало, проц медленно печаль, 9000 ядер никак не помогают, видеокарта рулит.
Отвечает все равно осмысленно, хоть и шизит.
Ну и да, это ж как пивот эвил, первый результат который выкинули на мороз.
Будь он топовым то никто бы кроме разве что рекламы не выложил базовую версию раздав бесплатно кому попало.
И возможно проблема в ггуф и его запуске. Это работает и преобразуется, но не факт что все прошло правильно и без ошибок. Все таки модифицированная структура.
>Отвечает все равно осмысленно, хоть и шизит.
Ровно так же, как и любая ллама, и даже любительские обрезки на 1,5В. Никакой революции.
>Будь он топовым то никто бы кроме разве что рекламы не выложил базовую версию раздав бесплатно кому попало.
А так смысла нет выкладывать говно. Да и метод то открытый, сейчас наклепают говнеца и опять зальют весь хайгинфейс. Я удивляюсь, как он всё это хранит, да ещё и раздаёт во всю ширину канала даже в Россию.
Начни просто с ознакомления с ллм, обеспечь запуск и быструю работу. Початься, попробуй описать персоналити своей нейтро-самы и добиться того, чтобы она отвечала примерно так как нужно.
Далее, можно начать выстраивать взаимодействие, настрой вишпер и tts чтобы говрить с ней, настрой выдачу эмоций для какого-нибудь л2д движка чтобы ее визуализировать, плюс сделать липсинк с речью.
Этого уже хватит надолго и поймешь много проблем и нюансов. Для организации реально чего-то подобного потребуется несколько ллм, где только одна будет "думать за чара" а остальные будут выполнять вспомогательные роли.
Что же до компьютерного зрения, там своя тема, плюс мультимодалки сейчас развились очень сильно.
О, ништяк кто-то заморочился. Соус с доп описанием есть, или там только результаты? Интересно возможность управлять результатом промтом.
Красава, велкам ту зе дуалгпу клаб, бадди жмакнул за жопу
> новая базовая модель и новые файнтюны скоро
Если там просто блоки добавили, есть вероятность прямой их подсадки к имеющимся моделям, так что скорее новой волны замесов и франкенштейнов.
>И возможно проблема в ггуф и его запуске.
->
>Особенно на жоре, который славится своей хуёвой поддержкой всех нововведений.
Я сразу и отписал, что будет говно. Хотя я еблан, оно о=же влезает в 12 гиг врама, можно что-то более путёвое запустить.
оригинал на угабуге разве что, любые другие методы преобразования и квантования не факт что нормально сработают
Не столь радикально, но в целом верно, нужно внедрять в большие модели.
Да пиздец. Как более бюджетный вариант - 3090 со вторички, тут точно никаких проблем не будет.
> хотя тут не понятно как оно с основной картой дружить будет
Хороший вопрос, она плохо дружит с экслламой, а у жоры были нюансы с расделением на разные карты. Но вон их уже 3 штуки на руках есть, скорее всего тесты в разных сочетаниях будут.
> И насколько видюха разгоняет процесс
До невероятных скоростей где ответ будет мгновенный, в самых тяжелых случаях генерация пойдет быстрее чем будешь успевать читать. Это если полностью на видеокарте, если делить проц-карточка то будет зависеть от пропорции разделения. 3060@12 даст возможность катать модели до 13б только на ней, возможно скорость на 34б будет приемлемой.
> ждать, пока там модель напердит по одной букве в чат, как-то печально
Если для рп - экспириенс сам может оказаться важнее чем точность ответов, когда оно быстро и не совсем ужасно - может быть достаточно чтобы проникнуться и увлечься, а постоянные прерывания собьют весь настрой и будет херня.
>оригинал на угабуге разве что,
Спасибо, Капитан! Или ты про оригинальный трансформер? Под него у меня врама нет, но вот попробовал экслламу 2, и что-то вообще дичь.
>со вторички, тут точно никаких проблем не будет
Ну кроме убитой карты, майненой или там прожаренной в духовке.
ево, этож и есть оригинал, екслама тоже преобразуется и квантуется
Ясненько, спасибо.
Мне не для рп, а для текстовых концептов, скорость важна, я много правлю. Не критично, но хотелось бы побыстрее.
Под оригинал кстати не обязательна врам, он и на процессоре крутится и вроде бы можно было часть там часть там. Медленно конечно, но это 8b, а не 70b. Че там, 16 гигов вроде fp16
Можно ли фп16 запустить на процессоре?

>екслама тоже преобразуется и квантуется
Проёбов там обычно меньше.
Попробовал в общем напрямую, и тоже шизит. Бывает конечно пишет классику с 8 книгами, но вот такой шизы не должно быть вообще даже на 7B, я считаю. Короче либо одно, либо другое.
Похоже на проеб тренировки кстати, хуево данные почистили может

Вобще я так понимаю суть дообучения в прибавлении знаний к сетке, а не улучшение мозгов в сумме.
Это нужно не задачками ее ебать, а проверять знания и умение их применять. На сколько понимаю нужно сравнить базовый мистраль и эту сетку и поспрашивать на разные темы.
Скорей всего добавили математику и програмерство.
Хотя хуй знает, может быть там был не мистраль, а ллама 2.
Но врятли, она изначально сосет.
Поздравляю.
https://blocksandfiles.com/2024/01/05/ferroelectric-ram-update-and-micron/
Новая память с намеком на использование в ии, я так понимаю это оптан 2
Новая память с намеком на использование в ии, я так понимаю это оптан 2
> с намеком на использование в ии
Голоса в голове тебе намекают? Причём тут вообще ИИ и куда ты собираешься это затолкать?
Статью почитай не позорься, там это прямо написано
Почему никто Grok не обсуждает?
Спасибо за объяснение.
Кстати, продолжил тестировать кванты yi-34b-v3 и заметил, что у Q5_0 сильно меньше шизы по сравнению с Q6_K, но качество сравнимо.
Затем вспомнил пост Undi95:
>WARNING: ALL THE "K" GGUF QUANT OF MIXTRAL MODELS SEEMS TO BE BROKEN, PREFER Q4_0, Q5_0 or Q8_0!
https://huggingface.co/Undi95/Mixtral-8x7B-MoE-RP-Story?not-for-all-audiences=true
Ещё один финтюнер немного обобщённо бугуртит с gguf:
>I had much better results with the fp16 instead of GGUF, GGUF quants seem fucked? I don't know. May be on my side. Had so much nonsense input, had to wrangle settings until I had it coherent, it was working Really good. Fuck Yi models are a pain to work with.
https://huggingface.co/Sao10K/NyakuraV2-34B-Yi-Llama
Пока вброшу в тред предположение, что все gguf в которых есть буква K ломают yi-34.
Мои поздравления, ждём тесты тяжёлых нейронок.
А куда ты их планируешь втыкать? Можно фотку если что-то необычное?
Расскажи как будешь охлаждать и что будет с температурой.
Ты знакомые буквы увидел и даже не читал что там написано, да? Там не слова про использование в ИИ, использование в GPU-датацентрах не означает что оно хоть какое-то отношение к ИИ имеет. Там речь вообще про другое.
> предположение
Чел, это уже давно пофикшено, если ты специально где-то не откопал протухшую версию. И шизам, видящим разницу между Q5 и Q6 надо принимать таблетки.

Судя по тесту грок та еще хуйня
Совсем сдрочился? Уже и небольшую статью прочитать и осознать не могут.
Гуглоперевод что бы ты страдал, до перевода Gen AI догадайся сам.
Хотят сделать аи ускорители с большой и энергонезависимой памятью, что бы хранить модель там столько сколько нужно и с большими скоростями. Без необходимости гонять ее туда сюда каждое включение. Может быть меньшее выделение тепла и потребление в сумме, так как не жрет энергию на поддержание. Замена нанд в потанцевале, как скорей всего более дешевая замена оптана.
Может быть и замена рам, по крайней мере скорости годные, только задержка великовата.
> это уже давно пофикшено
А были новости про это какие то? Мол да каемся срали, но теперь завязываем.
>Q5 и Q6 надо принимать таблетки.
Желтый может и шизу снес, но с другой стороны утверждать, что между 5 и 6 разницы нет до уровня неразличимости - тоже бредом попахивает - по хорошему надо выборкой на реролах тестить.
Ты даже русский язык не понимаешь? Написано же для файлопомойки больших файлов. Какое отношение к ИИ это имеет?
> А были новости про это какие то?
В гите читай, через пару дней пофиксили после обнаружения бага.
> между 5 и 6 разницы нет до уровня неразличимости - тоже бредом попахивает
Без семплинга они тебе выдадут идентичный результат, с семплингом тоже на шизу похоже, если ты видишь какие-то отклонения в рандоме.
вот тупой
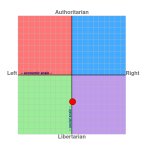
>Судя по тесту грок та еще хуйня
А что не так с тестом? То, что они все снизу - это база, реальность такая. Лево/право же вопрос идеалов скорее.
https://www.reddit.com/r/LocalLLaMA/comments/18zcgyp/expanding_capabilities_through_composition_calm/
бля еще один метод слияния сеток
Ну, то что он лево либеральный это все соевый биас. А соя это плохо
бля еще один метод слияния сеток
Ну, то что он лево либеральный это все соевый биас. А соя это плохо
Потому что не попенсорс, очевидно же.
Хуйня идея, данные всё равно через 3 пизды от вычислителей.
>То, что они все снизу - это база, реальность такая.
Схуяли? Это не база, это алаймент.
>бля еще один метод слияния сеток
Заебали, остановите прогресс на недельку хотя бы.
нее чел, это всё хуйня, модели что промоутят повесточку - нахуй идут.
https://www.trackingai.org/compare-responses#Q62
а вот здесь https://www.trackingai.org/ можно посмотреть пикрил.
бля
mlabonne/Beyonder-4x7B-v2
Очень интересная мини-МОЕ модель.
Для нищуков вообще отлично подойдет.
Очень интересная мини-МОЕ модель.
Для нищуков вообще отлично подойдет.
А ты тот тест проходил? Я вот прошел. Там 0 вопросов про трансов. Зато есть вопросы уровня "было бы хорошо если бы каждый мог воду бесплатно получить?"
Ну, было бы хорошо. Вот модели и занимают на этом тесте левый угол.
Два вопроса:
Посоветуйте годную GGML лору
И второй вопрос, в Silly Tavern в лорбук можно добавлять только персонажей или вообще все что угодно? Места, события и тд?
Посоветуйте годную GGML лору
И второй вопрос, в Silly Tavern в лорбук можно добавлять только персонажей или вообще все что угодно? Места, события и тд?
Лор бук работает по принципу привязки к слову.
Это может быть персонаж, место, событие, похуй вообще.
Вторичка она такая, проверками и тщательным осмотром можно вероятность фейла минимизировать но она всегда остается.
Да, ванильным трансформерсом с торчем на цп, через llamacpp сконвертировав веса в gguf не трогая битность.
> суть дообучения в прибавлении знаний к сетке, а не улучшение мозгов в сумме
И то и другое если все получается.
Скорее для хранилищ или высокопроизводительного дискового кэша, она медленная по сравнению с оперативной памятью но быстрее той что в ссд.
> между 5 и 6 разницы нет до уровня неразличимости
> по хорошему надо выборкой на реролах тестить
Как их можно объективно сравнить?
> Лор бук работает по принципу привязки к слову
То есть как кроссреференс? Типа будет сканить и проверять на наличие ключевых слов а потом брать описание?

>Заебали, остановите прогресс на недельку хотя бы.
Ага.
Поэтому система довольно всратая, она иногда работает на синонимы или если ты слово с ошибкой напишешь, а иногда не работает.
Понял спасибо анонче за обьяснение. Осталось решить вопрос с годной лорой.
>И то и другое если все получается.
Ну, от увеличения знаний сетка становится умнее, да.
>Скорее для хранилищ или высокопроизводительного дискового кэша, она медленная по сравнению с оперативной памятью но быстрее той что в ссд.
Не обязательно медленнее, просто делай шину чуть шире. Для обычной гпу наверное бесполезна, а вот для чисто ии ускорителя норм.
Материнка с ИИ процессором, вокруг него слоты памяти, нет ебли с сата нвме и другими медленными накопителями. Только один чип и один тип памяти на котором он все и хранит.
Если бы в компах не было разделения на оперативную память и медленную, жать было бы веселее.
Ну, будь у нас полный аналог энергонезависимых ддр.
В любом случае это игрушка для корпоратов как и любое передовое оборудование. У них могут быть свои требования и эта память может под них подойти.
Делать гига широкие шины трудно.
Почитай какие проблемы были в hbm, даже пришлось дополнительную подложку (дорогую, кстати) мастырить.
> Ну, от увеличения знаний сетка становится умнее, да.
Тут еще важно умение их применить, старые большие сетки "знают" довольно много, но наитупейшие в некотором контексте.
> Не обязательно медленнее, просто делай шину чуть шире.
Если шина потребуется в 10+ раз больше, а время доступа будет донное - не нужно, плюс у нее ограниченный ресурс. Но в качестве промежуточного звена памяти, которая медленнее рам но быстрее хранилища может пригодиться.
> эта память может под них подойти
Хранить кэш активаций или частей моделей, вполне.
Все ещё верите бенчмаркам?
>Если бы в компах не было разделения на оперативную память и медленную, жать было бы веселее.
Давай сразу регистры на диск заменять, все эти кеши это просто костыли.
>Но в качестве промежуточного звена памяти, которая медленнее рам но быстрее хранилища
Не особо нужно, по крайней мере на десктопе диски сейчас не сказать чтобы упирались в шину, но близки к ней.
В них никто уже давно не верит, хуй знает зачем ты это принес
> Да, ванильным трансформерсом с торчем на цп, через llamacpp сконвертировав веса в gguf не трогая битность.
Оно же должно быстрее быть, так? Я где-то читал, мол то ли п40, то ли процы лучше приспособлены для фп16 вычислений.
Ага. Только шина соснёт в 4 раза больше.




>Красава. Ждём тестов 70B.
так, я собрал наконец все говно до кучи и готов что-нибудь попробовать
Только я не знаю, каких именно тестов вам подогнать
70б какой модели? И где бы мне вопросы каверзные найти для нейросетки, чтобы проверить насколько она умная?
я заказывал турбины вместе с картами. Вот сотственно как я их смонтировал.
Турбины без регулировки, шумят. Точно нужно будет их менять в дальнейшем. Работать можно, но на ночь не оставишь, как я обычно делаю - спать не даст.
Модель хорошая, но опять же злые персонажи применяют насилие и тут же извиняются, а так словарный запас хороший, кум есть, шизы вроде не заметил.
Да меня тоже немного с consent докучала, но на удивление быстрое сдается после условного "ну ебать, хорош ломаться" лол
> то ли п40, то ли процы лучше приспособлены для фп16 вычислений
Скорее они не приспособлены к расчетом меньшей битности и не получают такого же ускорения, как на новых гпу.
Хуясе ебать, это же привод!
Из чистых файнтюнов что-нибудь, или можешь рискнуть последние мерджи, но во многих дичь намешана, а куда добавили лору кимико70 довольно вяло отвечают.
Что по температурам, потреблению и т.п.? Попробуй и gptq через экслламу и gguf через жору, какое будет лучше выдавать интересно. Что по pci-e линиям, какой жор и температуры получаются?
Вот написал и тут же сглазил, у бабушки внезапно "вырос хер", по-моему этой херней вообще все модели 7Б страдают. В целом в РП пока ничё не нашёл лучше mlewd_Q5. 7b либо генерят просто вал текста, но по сути стоят на месте и не двигают сюжет либо проёбывают логику, другие же жрут кучу ресурсов и норм там не порпшить
>70б какой модели?
Ваще похую. Главное скорость модели и подводные с запуском.
Даже бОльшие модели этим иногда страдают
Проверь сколько контекста у модели 34b 200k войдет до падения скорости, ну и сами скорости ее.
Квант возьми любой, хоть 6к, можешь даже 8q ебнуть, но там гигов 14 останется под контекст и другую хуйню, эт мало
Вобще просто тесты скорости сеток разных размеров сделай и их максимально влезающий контекст. Что бы можно было ориентироваться. На 1 и на 2 картах.
> 14 останется под контекст
> эт мало
Ахуеть, жора, конечно, не оптимизированный, но не настолько же.
> скорости сеток разных размеров сделай и их максимально влезающий контекст
Если будешь делать то замерь заодно сколько оно при дефолтных 4к потребляет, можно будет сделать таблицу.

Попробовал тут поюзать Wizard Uncensored расхайпленый. Ролевки ведет максимально хуево. Зато может написать рецепт создания запрещенки.
>рецепт создания запрещенки.
Что это значит? Речь про какую запрещенку-то лол? Про запрещенный сыр из евросоюза в россии?
> расхайпленый
Да хуйта, хз даже кто ее хайпил. Прорывная - версия 1.2, но оно только в 13б, с цензурой (обходится промтом) и ей уже пол года.
> Что это значит?
Может написать подробные рецепты по созданию наркоты, бомб, оружия и тд
не, ну вроде звучит интересно....
Может расскажет мне как альтушку на госуслугах получить.
А он только 13b?
Анон, а дай полный спек своей машины, плизик?

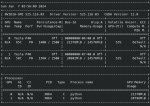
llama-2-70b.Q4_K_M.gguf
скорость 2.92-3.72 токена
Я посмотрел как отвечает openchat_3.5-f16, yi-34b-v3.Q6_K и llama-2-70b.Q4_K_M отвечает на загадки и чёт они все справились херово.
Только вот опенчат f16 требует 10 гб, а ллама 70б - в три раза больше.
>Что по температурам, потреблению и т.п.?
на пике - типичная картина утилизации под нагрузкой. Но я сейчас лечу на слабом блоке питания всего с тремя линиями +12 раскиданными на 4 восьмипиновика двух видеокарт. Есть вероятность, что я часть сети питания видокарт не задействовал, поэтмоу утилизация только наполовину.
Завтра буду бп искать.
И да, греется неплохо. Нужен хороший поток воздуха, надо думать, как сделать его без шума.
>Что по pci-e линиям
а вот этот вопрос я не совсем понял.
>1070 медленная, наверное, две p40 дали бы 7+++
нет, не дали бы.
Я не помню точно, но у меня на двух p40 кажется yi-34b-v3.Q6_K держалась на 6.7 т/с, один раз видел 6.9
Анончики, разные модели это конечно хорошо, но какие настройки температуры и прочих непонятных штук считаются самыми лучшими?
Эксламы только с нвидей гоняются, или на 6700хт тоже пойдут?
Тут уж сам выбирай.
там надо специально для этих карт llama.cpp собирать с какими то особыми настройками которые ускоряют генерацию, на реддите видел в уакой то теме с этими картами
И всё таки? Интересно чем пользуются аноны
Да выбери любой пресет в таверне и посмотри.
Чего как маленький то?
https://huggingface.co/Sao10K/Sensualize-Solar-10.7B
Новая версия фроствинд, на сколько я понял.
Новая версия фроствинд, на сколько я понял.
Нет это файнтюн Солара, как и фроствинд.
Ты дурак?
>A finetune of Base Solar.
Мозги прокумил уже ебанат?
А теперь глянь кто автор фроствинд, дурачек.
И так у нас есть один человек который играется с солар 10.7, имеющий какой то набор датасетов. И вот он делает фроствинд на одной версии датасета, а потом переделав свой датасет делает новую версию сетки.
Тоесть это легко можно назвать новой версией фроствинд.
Какие то аноны тупые после праздников
Значит все шизомиксы от унди это на самом деле разные версии одной модели.
Нихуя ты умный чел.
Тебя слишком сильно квантовали чтоли, долбаеб?
Какая связь между унди который тупо мешает сетки, и челом который тренирует одну версию базового солара на 2 версиях одного датасета?
Откуда ты вообще высрал "2 версии одного датасета"?
Вот тупой, глянь чем он там занимается. Это автор кучи своих сеток. Че удивительного что он попробовал сделать сетку, а потом изменил датасет и сделал это снова? Ты думаешь датасеты так легко собирать и изменять?
>я это придумал а теперь маняврирую потому что понял что обосрался
Так бы сразу и сказал
ебать ты тупой анон, иди нахуй
И после этого говорят что аги еще не достигнут
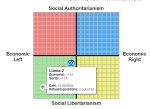

>ЛЛАМА-2 в центре.
Компас говна, реальное положение моделей он не отражает.
Стоп тряска.
Ну обосрался, ну с кем не бывает
>а вот этот вопрос я не совсем понял.
Что за материнка и какая схема подключения двух крат в неё: классика 8+8, или там 16+4.
Он обосрался, а я стоп? Говноеды
Это он говорит что он нейтрально-добрый, по сути он законопослушный-злой.
https://github.com/ggerganov/llama.cpp/pull/4773#issuecomment-1879763255
> true 2bit quants
> 70B в ~17gb
ебать
> true 2bit quants
> 70B в ~17gb
ебать
Ты у всех или кого-то конкретно спрашиваешь?
По линиям пояснили,
> скорость 2.92-3.72 токена
Это на жоре или экслламе? И на каком контексте.
Половинная нагрузка при совместном использовании норма, ведь карточка половину времени ждет пока другая обсчитает свою часть.
С каверзными вопросами файнотюн на cot может помочь разве что. Если не лень попробуй просто початиться с ними с разговором на разные темы, правно перетекающие друг в друга, и заодно задавая вопросы и давая указания/задачи, типа "представь что ..." и дальше все идет с учетом этого. В подобном уровень модели сразу раскрывается, оно или будет (пытаться) удержать все это и стараться, или даже идеально говорить, или же будет срать ответами без четкой связи с прошлым или отсылок, а то и вообще поломается. Из мелких в такое более менее могут солар и визард разве что.
На амудэ начиная с 6800 говорят нормально катается. Ну а 700-й как всегда повезло не стоило шквариться об амуду в текущих условиях
Есть линк? Вроде писали что лламацпп по дефолту на этих картах шустро работает и в ней сильно быстрее чем с другими лоадерами. Но хз, может пиздят, нет такого чтобы проверить.
О каком нейтрально-добром ты пытаешься судить, если в какой-то херне что ты пустил может быть какой угодно промт, а то и вообще ваниальная чат версия.
Лламаны, а накидайте плиз для нуба, только что установившего Кобольд и Фроствинд по инструкции, ссылок на топ не в ТОМ смысле персонажей для ролеплея с чаба или где их еще берут. Чтоб знать вообще, что такое хорошо.
Лламаны, а накидайте плиз для нуба, только что установившего Кобольд и Фроствинд по инструкции, ссылок на топ не в ТОМ смысле персонажей для ролеплея с чаба или где их еще берут. Чтоб знать вообще, что такое хорошо.
QuIP# давно есть, в Эксламе его запилили уже. У Жоры как обычно всё через месяц только появляется.
мех, раньше быстрее было :/
хотя и не удивительно, он ведь сча занят моделями на айфонах, сразу видно яблодрочера.
>По линиям пояснили,
я погуглил, но что-то не понял, как посмотреть то что вы хотите.
Мать prime-b450-plus
проц в ней Ryzen 5 3600
>Это на жоре
На жоре. Контекст 1к с копейками, тестирование падения скорости при увеличении контекста еще запланированно.
>Половинная нагрузка при совместном использовании норма
Разве сетка не линейна? В таком случае отработала половина слоев на видеокарте - передала результаты во вторую - отработала половина слоев на второй видеокарте. Они не должны с собой взаимодействовать по логике постоянно.
Разве что llama.cpp слои не по подряд на карты складывает, а раунробином.
Заходишь на chub.ai и по тегам ищешь что тебя нужно.
>но что-то не понял, как посмотреть то что вы хотите
В любом обзоре/в бивасе настройки. Короче у тебя вот так
1 x PCI Express 3.0 x16
1 x PCI Express 2.0 x16 (x4)
3 x PCI Express 2.0 x1
То есть вторая зарезана прямо неплохо так.
Это как "посоветуйте автомобиль", хз что тебе вообще нужно и для чего. Если в общем по карточкам, ищи лаконично написанные, без большого обилия форматирования и лишней графомании с althou, despite, however, except по 3 штуки каждой в одном предложении. Эта нейрошиза сильно портит дальнейший стиль и сжирает токены. https://chub.ai/characters/minimum/Kumi держи древнюю не кумерскую платину, из локалок что сейчас в тренде ее мало умеют отыграть, десяток постов и уже улыбающаяся да жизнерадостная лезет совращать.
Там х8 + х8 3.0 или х16 3.0 + х4 2.0?
Попробуй прогнать жору с выгрузкой на одну видюху (cuda visible devices) на разные и сравнить скорость.
> В таком случае отработала половина слоев на видеокарте - передала результаты во вторую - отработала половина слоев на второй видеокарте. Они не должны с собой взаимодействовать по логике постоянно.
Ну в случае нормальной организации все так, но всеравно каждая карточка будет ждать окончания работы другой чтобы получить в итоге новый токен в контекст и начать обрабатывать свою часть, они взаимосвязаны. На новых карточках жора плохо параллелится, складывается ощущение будто там не единичный обмен активаций происходит а слои в шахматном порядке раскиданы. Хз в общем, может дело в чем-то еще.
4 т/с со стримингом - успевает генерить чтобы можно было читать ответ сразу? Если так то уже кайфово.
>успевает генерить чтобы можно было читать ответ сразу?
пока ответить не могу, контекст был маленький.
На таком контексте-то они все могут быстро отвечать.
Сорри, пишу с тапка, поэтому краткость не сестра.
Там такая же проблема, как и везде. Полно васянов, которые лепят что-то на коленке после уроков, и других васянов, которые это жрут, нахваливают и добавки просят. А я тут хочу у более развитой публики спросить. Судя по тредам, тут и реально эстеты-ценители не редкость.
Спасиб, вот такие ответы люблю. Нужно просто понять для начала, чего максимум можно ожидать от ролеплея с рекомендованной моделью на сегодня. И с моей RTX3060 о 12 гигах. Эро будет этот ролеплей или нет, дело не первой важности. Главное оценить верхнюю планку. Ну, в конфиге, где не надо ждать по две минуты ответа, конечно.
Забыл написать, что SillyTavern тоже установлена уже. Глаза разбегаются.
Там такая же проблема, как и везде. Полно васянов, которые лепят что-то на коленке после уроков, и других васянов, которые это жрут, нахваливают и добавки просят. А я тут хочу у более развитой публики спросить. Судя по тредам, тут и реально эстеты-ценители не редкость.
Спасиб, вот такие ответы люблю. Нужно просто понять для начала, чего максимум можно ожидать от ролеплея с рекомендованной моделью на сегодня. И с моей RTX3060 о 12 гигах. Эро будет этот ролеплей или нет, дело не первой важности. Главное оценить верхнюю планку. Ну, в конфиге, где не надо ждать по две минуты ответа, конечно.
Забыл написать, что SillyTavern тоже установлена уже. Глаза разбегаются.
> Главное оценить верхнюю планку.
Это все зависит еще и от тебя, то что персонаж нравится может быть важнее чем особенности форматирования и т.д. Плюс перфоманс комбинации карточки и модели может сильно отличаться, особенно если модель знает фендом вселенной, откуда персонаж, в таком случае может ультить, и наоборот.
Сейчас приличный уровень от которого (если раньше не рпшил с сетками) кайфанешь могут обеспечить даже мелкие сетки, не заморачивайся и познавай. Страдать снобизмом или аутотренингом будешь уже потом когда все надоест.
Если не уверен в карточке - спроси, в любом случае обосрут но хотябы аргументированно.
95% юзеров даже не смотрят, че там в памяти смартфона лежит. =)
А про бесполезные функции — так их и так напихано. Всякие новости, AI и прочие агреггаторы, плееры, магазины, смс… О которых мы не в курсе, но стоит лишний раз смахнуть вправо или влево…
64 гига, да.
> стаканье видеокарт не создаёт накладных расходов
ДА НУ НАХУЙ
Я БЛЯДЬ ДВАДЦАТЬ ТРЕДОВ ЭТО ГОВОРЮ, НО ШИЗЫ ТОПИЛИ, ЧТ ОНИХУЯ СЕБЕ ТАМ ВСЕ УМИРАЕТ
И НАЧИСТО ИГНОРИЛИ ТЕ ЖЕ ТЕСТЫ ДВУХ-ТРЕХ P40 И ВООБЩЕ ВСЕ ТЕСТЫ НАХУЙ
Ну, добро пожаловать в реальность, может быть будешь чаще меня слушать, и меньше шизам верить.
Вообще, кмк, идею с тем, что стакание карт убивает перформанс продвигали 1-2 шиза, все остальные молчали и смотрели на наши срачи.
>q6
База, q4 — нет.
Но вообще, разница не супер-пупер должна быть, конечно.
Дам линк на мой старый ответ по соседней теме
Мне лень писать снова, но подумай над комплексов ботов и нейронок вместе, да.
Cog советовали неплохо, но можно и без него, кстати. Если именно стример-игрок.
Локалки норм, та же Yi-34B-200k.
Плюс, ему не надо держать контекст всего чата и игры. Чисто игровая ситуация + каменты, там 4-6 тыщ контекста, думаю, должно хватить.
Да-да.
Микстрали похуй на все, тесты смешные, но не особо релевантные, канеш. От промпта зависит, кмк.
Мои поздравления!
Я думаю, он имел в виду — за качественной реализацией, а не васянскими файнтьюнами.
>Уже вижу
Da. )))
> Далее, можно начать выстраивать взаимодействие, настрой вишпер и tts чтобы говрить с ней, настрой выдачу эмоций для какого-нибудь л2д движка чтобы ее визуализировать, плюс сделать липсинк с речью.
Визуализировать можно специальным софтом, какой-нибудь FaceRig в помощь, там и липсинк, и че хошь.
Вишпер разве что для озвучки сюжетных катсцен?
tts рекомендую нынче xTTSv2, кстати.
Не обязательно несколько llm, на самом деле. Возможно хватит и одной, а остальное повесить на простые алгоритмы.
Ору, база, не останавливайте.
Регулировку обычным реостатом.
Помни, что GPTQ/Exl2/AWQ не то, а вот выгрузка GGUF — отлично.
Но можешь и их потестить, чтобы лишний раз убедиться.
> 2.92-3.72
Пуф-пуф… Ну, для фанатов 70б кума сойдет, а так… медленновато, наверное, ИМХО.
Жить можно. Медленно, но не критично, ИМХО. Если не пихать две 4090 и ждать 100 т/сек. И то, не сильно просядет.

>Микстрали похуй на все
не совсем.
>ожидать от ролеплея
Суть такова, что ролеплей это очень сложная задача с высоким уровнем абстракции. РП начинается с нейронок размером 34B, а качественный отыгрыш уже 70B.
>И с моей RTX3060 о 12 гигах.
Запустить на жоре 34b выгрузив сколько сможешь слоёв в видеокарту.
Использовать 3060 совместно с другой видеокартой.
> Я БЛЯДЬ ДВАДЦАТЬ ТРЕДОВ ЭТО ГОВОРЮ, НО ШИЗЫ ТОПИЛИ, ЧТ ОНИХУЯ СЕБЕ ТАМ ВСЕ УМИРАЕТ
Эти шизы сейчас с тобой в одной комнате?
> чаще меня слушать, и меньше шизам верить
Взаимоисключающие
> Вишпер разве что для озвучки сюжетных катсцен?
Что? Боту воспринимать такой уровень игоря слишком сложно и не нужно. Это чтобы чар воспринимал речи автора и можно было с ним взаимодействовать, как делает Видал.
> Возможно хватит и одной
Количество запросов слишком высоко, обработать чат, обработать историю, обработать ген-план стрима, выстраивая уместные указания боту, сам персонаж, обработка что там с игрой творится, цензуру нигеров-пидаров и т.д. Это может быть одна хорошая модель с разными запросами к ней, но их будет много.
Стоит изучить опыт автора успешного проекта, если офк получится собрать камни.
11/11, топчик.
20б вполне норм, магии нет но приятно. Лучше более глупая модель, которая отвечает пока ты еще погружен, чем дохуя умная через с ответами в несколько минут. Если офк не отыгрывать переписку, лол.
Раз зашла речь о рп на 34б - реквестирую модели, которые в него хорошо могут.
>tess-34b-v1.4
>rpbird-yi-34b
>synthia-34b-v1.2 (автор выпилил со своей странички, но у блока она ещё осталась)
>Yi 34B v3
Их уровень примерно одинаковый, но каждая со своими неповторимыми свистелками и перделками.
Спасибо
> synthia-34b-v1.2
Страдает зацикленностью на faster@harder и идентифицирует себя как клод от антропиков, или без этих проблем, не пробовал?
Всегда кекаю когда соевой модели скажешь что она типа slut а в ответ такую хуйню получаешь
А если всё таки выбирать одну из них? Например, какой ты сам пользуешься? С какими настройками?
>> synthia-34b-v1.2
Тоже заметил, она немного нестабильная, но у неё самая богатая лексика.
Попробуй Yi 34B v3. Настройки ставь самые дефолтные, нормально будет работать, а затем их нужно подгонять под карточку персонажа индивидуально.
Как сделать, чтобы в таверне после автоперевода через экстеншен не проебывалась разметка? Гугл переводчик меняет кавычки на другие и разметка тупо ломается. Может можно как-то кастомизировать разметку?
А что если сделать домашний нейроускоритель на базе 4x4060Ti ? Общее количество CUDA и тензорных ядер как у 4090, а памяти целых 64Гб. 120B_Q3_K_L влезает и летать будет. Затык вижу только в материнской плате, а так вроде нет недостатков.
тут есть миллионеры с двумя 4090?
а то мои тесты на двух p40 ничего толком не показывают без сравнения с другими видеокартами
а то мои тесты на двух p40 ничего толком не показывают без сравнения с другими видеокартами
> 120B_Q3_K_L влезает
Будет
> летать
Нет
Обработка идет по очереди, 3/4х видюх будут простаивать 75% времени. Скорость будет примерно как у 34б Q3, только в 4 раза медленее, плюс некоторое замедление из-за обмена результатами.
Что именно интересует? На 70б в бывшей 15-20т/с в зависимости от кванта, с флеш атеншн контекст практически не влияет.
> ничего толком не показывают
Неправда, они ценны уже сами по себе, возможность бюджетно крутить 34-70б модели дорогого стоит. Тут бы максимум выжать у них, и еще интересно как работают другие сетки. Попробуй cogvlm в 4х и 8-битном кванте, диффузию если не лень, что-нибудь еще из популярного, например основанное на клип-блип. Офк когда самому будет не лень и время свободное.
Ну и если производительность получится, порпшь на 70б, там несколько новых файнтюнов довольно интересных выходило за последний месяц.
Запустил mixtral-8x7b-2.10bpw.gguf на 3060 12GB VRAM, скорость генерации выросла до 11.62 t/s в llamacpp (была 3.00 t/s для Q5_K_M в свежем кобольде, что с оффлодом 9L, что без него).
2bit модельки (есть mixtral, mistral, llama2-70b)
https://huggingface.co/ikawrakow/various-2bit-sota-gguf/tree/main
нужен этот PR лламы (еще не в релизе).
https://github.com/ggerganov/llama.cpp/pull/4773
Все слои в 12 Gb не влезают, влезло 27/33 layers.
Как нормально посчитать perplexity? Я не готов ждать 6 часов (649 chunks, 31.73 seconds per pass - ETA 5 hours 43.25 minutes)
На 50 проходах получилась perplexity: для 2.10bpw - 5.8736; для Q5_K_M - 4.9244
Если кому интересно, могу написать гайд, как установить и скомпилировать этот PR.
Я конечно все понимаю, но 2битный кванты это ж пиздец шиза будет, или там какое-то волшебное квантование?
> 3/4х видюх будут простаивать 75% времени
Бля надмозг ебаный. Все будут простаивать, потому что результат обработки одной является исходными данными для следующей.
Интересно
Тоже интересно что там, персплексити небольшой получается.
QuIP# на уровне Q4_K_S по PPL.
Кто юзал групповой чат в sillytavern? У меня проблема- могу дописывать сообщения всех участников, кроме ГГ. Когда пытаюсь дописать своему персу, то пишет "Deleted group member swiped. To get a reply, add them back to the group." мне тупо надо гг продублировать карточкой персонажа и в чат добавить или мб настройка какая есть от этой шляпы?
Ну "дописать" всмысле догенерить
> Эти шизы сейчас с тобой в одной комнате?
Нет, к счастью. =)
> Взаимоисключающие
Никаких противоречий, я ж не шиз, в отличие от тех, у кого от нескольких видях перформанс сразу падает в разы. =D
> Это чтобы чар воспринимал речи автора
Какого автора?
Оке, может я не так понял. Я подумал, что автор хотел, чтобы его бот сам играл, стримил и комментировал. А автор вообще тут не участвует никак, зачем?
Но, может идея в другом, тогда мои извинения.
> Количество запросов слишком высоко, обработать чат, обработать историю, обработать ген-план стрима, выстраивая уместные указания боту, сам персонаж, обработка что там с игрой творится, цензуру нигеров-пидаров и т.д. Это может быть одна хорошая модель с разными запросами к ней, но их будет много.
Стоит изучить опыт автора успешного проекта, если офк получится собрать камни.
План стрима? Ну тут сразу сомневаюсь, что такое нужно.
Цензура? Кмк, с цензуров справится по дефолту любая соевая модель.
Историю? Повторюсь, история не нужна.
Чат.
И что творится в игре.
Указания боту — по ситуации.
Но, я соглашусь, что тут нужен опыт, если кто-то уже реализовывал.
Я пока пальцем в небо тыкаю, может я не прав, и нужно прям много всего.
Просто часть я бы повесил на простые скрипты.
Но буду честен, сам я стримеров не смотрю, и витуберов тем более. Что там популярно, какое поведение, не знаю.
Какое еще «общее количество ядер», чувак? =D
Моделька обрабатывается последовательно.
Так что количество ядер такое, какое есть.
Памяти 64 гига, да.
Летать будет вчетверо медленнее, чем в твоих фантазиях + еще небольшие задержки на передачу данных. Ну и на 4 картах и правда быдлокод может вылезти, которые еще перформанс порежет.
Я в начале подумал 10 bpw, охуел, а потом понял, что 2.1.
Типа… Она же критически тупая, не?
Ты же помнишь, что это 7B модельки?
Как оно интеллектом?
>Попробуй и gptq через экслламу и gguf через жору
я до этого пользовался только gguf. Я сейчас собрался сравнить две модели в разных форматах и не понял, как это сделать.
В случае с gguf все понятно - просто один файл скачиваем с лицехвата.
А по gptq ищутся например вот такие структуры https://huggingface.co/TheBloke/Wizard-Vicuna-30B-Uncensored-GPTQ/tree/main
Правильно ли я понимаю, что достаточно просто указать целую директорию при выборе модели для exllama?
И второй момент который мешает сравнению - gguf почему-то не выкладывают в f16 на лицехвате.
Например вот вроде бы две одинаковых модели
gguf: https://huggingface.co/TheBloke/Wizard-Vicuna-30B-Uncensored-GGUF/tree/main
gptq: https://huggingface.co/TheBloke/Wizard-Vicuna-30B-Uncensored-GPTQ/tree/main
но в gguf отсутствует f16 и единственный способ который я знаю чтобы её получить - конвертить самому из оригинального репозитория https://huggingface.co/cognitivecomputations/Wizard-Vicuna-30B-Uncensored а там объем 100+ Гб. У меня сейчас банально нет столько места.
Если кто-то может мне указать на две репы с разными форматами с одной моделью, чтобы там была f16 в gguf - это помогло бы.
>Как оно интеллектом?
Если кратко, то не очень. Или я не разобрался с настройками instruct mode template. Все ответы очень краткие, простые, сухие, интеллектом не блещет. Ни в какое сравнение с q5 не идет. Сейчас качаю llama-v2-70b-2.12bpw, вдруг чудо произойдет.
fp16 тебе нафиг не нужон, кмк.
GPTQ выкладывается папкой, да.
И как правило, это 4бит, если не выбрано иное, то есть квантование в 4 бита.
EXL2 выкладывается так же, но там квантования уже bpw могут быть любыми.
Логично, что сравнивать надо одинаковые кванты. Q4_K_M вроде как с GPTQ 4bit, плюс-минус, пусть меня поправят. Ну и 5bpw, скока там на самом деле бит на вес при квантовании.
Не произойдет. =)
Ну, попробуй, конечно, расскажешь.
я ситал ранее в тредах что паскаль хуже пережевывает кванты из-за того что старый.
Поэтому решил что нужно тестить и квантованную и неквантованную версии.
Может ты и прав, но, ИМХО, тут упор уже в память может быть, на таких больших объемах, как с fp16.
А выигрыша какого-то по соотношению качество на скорость ты вряд ли получишь.
Но, может ты и прав.
Где взять fp16 не подскажу, сорян.
Ну Ок, 4x4060Ti глупость. А две карты? Даже конфигурацию компьютера менять не придётся, просто две карты воткнуть - есть PCI-слоты и БП нормальный. 32Гб VRAM, модель 70В с малым квантом целиком влезет. Хотелось бы узнать скорость такой связки конечно.
> Q4_K_M вроде как с GPTQ 4bit, плюс-минус, пусть меня поправят.
С групсайзом 32 GPTQ получше будет.
> 5bpw, скока там на самом деле бит на вес при квантовании
Вот оно точно лучше будет чистых Q5. Там 3.5-3.7 bpw как раз близок к Q4_K_M.
Сама по себе 4060ti ПАРАША, у неё пропускная способность памяти медленнее семилетней (!!!) P40.
Как можно как-то заставить модели точнее следовать карточке?
Семплеры настрой.
Инструкт настрой.
Карточка может сама по себе плохой быть.
llama-v2-70b-2.12bpw уже лучше чем mixtral-2.10bpw, но модель слишком большая для 12 GB vram. Влезает только 47/81 слоев, из-за этого прироста скорости почти нет (было 1.00 tps стало 1.26), а perplexity скорее всего упала значительно по сравнению с жирными квантами.
offload 47/81 L:
print_timings: prompt eval time = 13918.75 ms / 508 tokens ( 27.40 ms per token, 36.50 tokens per second)
print_timings: eval time = 36452.46 ms / 46 runs ( 792.44 ms per token, 1.26 tokens per second)
Где можно прочитать про настройки семплеров и инструкта? Карточку я как раз и пытаюсь довести до ума, но не могу понять это она всё таки кривая и её не спасти, или всё таки семплер и инструкт плохие?
> у кого от нескольких видях перформанс сразу падает в разы
На жоре в современных видюхах так и происходит, причина не ясна. А последовательная обоработка сильно теряет в эффективности при росте числа гпу.
По виртуальному стримеру начни продумывать как это будет и поймешь что нужно много больше.
Всеже интересно как у типа получилось на 3х п40 катать 120б с 4+ т/с, надо у него поспрашивать и почитать по тому что было выполнено.
> собрался сравнить две модели в разных форматах и не понял, как это сделать.
Ну, гриди энкодинг будет одинаковый в пределах погрешности кванта, рандом семплирования существенный сам по себе. Только большое число одинаковых или разнообразных но по одной теме вопросов, которые можно как-то качественно-количественно оценить, получая в итоге что-то среднее.
> по gptq ищутся например вот такие структуры
Там качай через гит/хфхаб чтобы всю папку, и ее помещаешь в дирректорию models убабуги (или натравливаешь саму экслламу если вруд не используешь вебуи). Нужны все файлы что там есть, а не только .bin/.safetensors.
Если будешь пускать фп16 экслламой - нужно сконвертить .bin в .safetensors сделать можно скриптом https://github.com/turboderp/exllamav2/blob/master/util/convert_safetensors.py с аргументом *.bin запуская в папке с моделью.
> gguf почему-то не выкладывают в f16 на лицехвате
Местозаполнитель который, обычно, никому не нужен и легко получаем. В него конвертится оче быстро скриптом из репы жоры, тут сам знаешь, и весить он будет тоже под 100 гигов. Если хочешь с потерями на грани измеримости - качай q8, оно и в 48 гигов врам должно помещаться.
Алсо визард-викунья эти не стоит, аж 1я ллама и 7 месяцев назад. Из ~30б китайцы, выше список анон скидывал, и айроборос 33б на 1й лламе относительно свежий файнтюн со всеми фичами и новым датасетом. Что там по перфомансу правда хз.
> А две карты?
Норм, но 32гб пограничный размер и хватит на ~34б в жирном кванте с контекстом, но не на 70. Если не ошибаюсь, у кого-то был конфиг 24+12гб, трехбитная 70б по словам не понравилась. Скорость можешь сам посчитать исходя из того как быстро крутятся модели поменьше, там почти линейная зависимость от размера.
Почему все ссуться от всяких микросетей типа phi-2, tinyllama, этож просто днище. Ну да они могут ответить на короткий вопрос без контекста и форматирования и даже правильно. Но размер сети жестко вводит ограничение на понимание контекста. Да даже 7b они откровенно слабы никуда они там не продвинулись только опять же по простым вопросом из википедии. Но их хоть можно на любом компе запустить со сносными ответами.
Все эти локальные языковые модели тупые по сравнению с GPT-4. Только GPT-4 смог правильно ответить на логическую задачку. "В большой комнате играют Вася, Маша, Коля, Толя и собачка Бобик, в маленькой комнате играют Митя и Гриша. Гриша ушел, а Маша и Бобик перешли в маленькую комнату. Сколько детей играет в каждой из комнат?"
ну да, вроде exllama v2 рабоатет на p40 хуже, чем жора
А скорость никто не скажет — никто пока не купил. =)
Я предпочел квест 3, хотя и думал взять на пробу.
Такое себе, хотя для 24 гигов уже может быть интересно.
Однако… Боюсь она мозгами будет не совсем 70б. =)
Но кто знает.
> На жоре в современных видюхах так и происходит, причина не ясна.
А в чем преимущество жоры перед exl2, например, кстати? Ну, если у нас несколько видях — можно предположить, что объем врама уже не такая и проблема. Выгружать можем все, а не часть.
Или речь именно о ситуации, когда выгружаем часть слоев туда, часть сюда, и часть на проц?
Могу предположить, что тут и правда быдлокод, где проц участвует сильно много раз, где не надо, хз.
> По виртуальному стримеру начни продумывать как это будет и поймешь что нужно много больше.
Ну, это не моя идея, я разве что комментатора себе бы собрал.
Но тут нужен или Cog, чтобы моделька смотрела мою игру (а ког хочет 45 врама), или вообще анализ видосов.
> Всеже интересно как у типа получилось на 3х п40 катать 120б с 4+ т/с, надо у него поспрашивать и почитать по тому что было выполнено.
Все еще думаю, что балабол, а может и вовсе продавец карт. =)
Ну как-то слишком вкусно. Учитывая что там минимум 50+ гигов, и как-то выжать 4 токена… Когда тут в двух картах 34 выдает 3 токена.
> трехбитная 70б по словам не понравилась
У нас тут двухбитная на подходе. =D
> Почему все ссуться от всяких микросетей типа phi-2, tinyllama, этож просто днище.
Интернет вещей, смартфоны-помощники, всякие простейшие комментаторы без требований железа.
В идеале каждому по серверу хотя бы с тремя 4090/3090/P40 (это и по деньгам дешево, и по реализуемости с точки зрения материнки возможно), на которых крутить отдельные модели.
А в жизни у людей ноуты с 8 гигами рама и встроенной видяхой. =)

Да, как я понял, там тока жора норм работает. Что не плохо, но и не огонь. So-so.
А разбил 50/50 по картам?
GPTQ выглядит как будто вообще не почувствовал разницы.
А Жора просел, да.
да, там где 2 cards - разбиение напополам
> А в чем преимущество жоры перед exl2, например, кстати?
Вон на p40 работает лучше бывшей, а так при наличии видюх преимуществ нет. Когда врам меньше чем нужно - он безальтернативен по сути. Надо чекнуть что там с awq, вдруг тоже можно сплитить проц-гпу.
Вот тут выходит что на llamacpp при сплите на p40 практически нет просадок. А на 3090/4090 все печально. И скорее всего дело не в линиях pci-e.
Если пекарня на шинде - покажи gpu-x для каждой карточки, или набери nvidia-smi -q |grep "Link Wi*" -A 2 если в прыщах.
> gpu-x
gpu-z офк, фикс
Получается одна видюха на процессорных 3.0 х16 а другая на чипсетных 2.0 х4 (на всякий можешь проверить выставив grep "GPU Link Info" -A 6). Значит влиянием линий можно по сути пренебречь, а проблемы llamacpp в припезднутой совместимости с картами новее, уже интересно.
Алсо если будешь траить - попробуй ког в фп16 засплитить.
>ког в фп16 засплитить
если ты скажешь что такое ког и где его достать - то проверю
>ког в фп16 засплитить.
А он вобще конвертируется в ггуф?
Он запускается через трансформерс (ванильный или их обертку), ггуф и жора в это не может. Квантуется там же на месте.
Для ггуфа можешь llava, бакллава или share-gptv попробовать, но они слабее во многих задачах.
Mixtral-8x-7b на русском зафейлил, а на английском - справился. На русском все модели намного тупее.
https://huggingface.co/TheBloke/LLaMA-Pro-8B-Instruct-GGUF
Добавлена совместимость с llama.cpp 7 часов назад, все что раньше сосет
Так что первые тесты вчера были сломаны и поэтому сетка шизила
Добавлена совместимость с llama.cpp 7 часов назад, все что раньше сосет
Так что первые тесты вчера были сломаны и поэтому сетка шизила
>Для ггуфа можешь llava, бакллава или share-gptv попробовать
Эт знаю, но и жрут они меньше в разы. Там еще обсидиан 3b есть и какая та мелкая на 1.1b новая
>Так что первые тесты вчера были сломаны и поэтому сетка шизила
Я знал ©
Жду кобольда.
https://github.com/ggerganov/llama.cpp/pull/4810
жора тут метод Self-Extend пилит, думаю следующая версия кобальда будет еще и с ним
> Значит влиянием линий можно по сути пренебречь
И снова, как я говорил, линии мало что значат, задержки появляются, но мизерные.
Математика, йопти. =)
И они обе только описывают, без умения болтать?
Типа, разницы с обычными блипами и клипами по итогу и нет, без умения выполнять задачи, ролеплеить и т.д. =(
Смайлоблядь, ты сейчас к своему авторитету апеллируешь, или пытаешься выебнуться ни о в чем? Ранее втирал только трешак про 12х 3060 да поддакивал разным вбросам, и то исключительно фантазии без каких-либо обоснований и даже понимания как оно работает. Пользу приноси а не сочиняй повести о былых победах.
> Математика
Коши которого мы заслужили, ага.
> разницы с обычными блипами и клипами по итогу и нет
Хуясе ебать, накати и поюзай, а потом повтори то же самое клипом.
>И они обе только описывают, без умения болтать?
>Типа, разницы с обычными блипами и клипами по итогу и нет, без умения выполнять задачи, ролеплеить и т.д. =(
Те что по ссылкам не щупал, а эти
>llava, бакллава или share-gptv
те же локалки только чуть тупее, но с возможностью отправить им картинку. Понимают они их через раз, но это работает.
не запускается у меня эта херота.
1. мне не удалось размазать её на два гпу, хотя я что-то похожее на решение проблемы нашел вот тут https://huggingface.co/THUDM/cogvlm-chat-hf/discussions/2
я не могу использовать конкретно этиор решение сейчас, потому что запускаю на отдельной машине, которая вообще к мониторам не подключена, а для web_demo.py решение неприменимо
2. модель в распакованном виде весит 35 ГБ. web_demo.py можно указать в аргументах параметр --quant 4 или 8, но он начинает вот эту здоровую модель квантовать перед запуском в оперативке. Моей оперативки 32 гб + 16 гб свап на квантование в 4 не хватило, оом его убил.
В новую шапку по хорошему нужен раздел о мультимодалках и перечислить их с кратким описанием че как.
Тема интересная, но как то заглохла.
Наверное потому что не осилили сделать полноценную реализацию в вебуй и таверну.
Одна только llama.cpp для запуска, так и заглохло.
Тема интересная, но как то заглохла.
Наверное потому что не осилили сделать полноценную реализацию в вебуй и таверну.
Одна только llama.cpp для запуска, так и заглохло.

Хуя тя порвало, маня.
Тебе бы пора шизу лечить, таблеточки принимать, авось бы так не рвался с собственных несбывшихся фантазий.
Просто они не способны в инструкции и запросы.
Просишь пошутить на тему пикчи — они просто описывают пикчу и «смешно потому что».
Может в данном случае скиллишью, конечно, но я че-то часик потыкал их и забил. А на Когу мне врама не хватает, мех. =)
Эх, вот это печально.
Пробовать на системе с монитором будешь, или возможности пока нет?

Ссука блядь....
вот не мог добавить это говно в ридми мультимодалки?
https://github.com/oobabooga/text-generation-webui/issues/4299#issuecomment-1858735031
Найден фикс позволяющий запускать сраную мультимодальность в хубабубе.
Правда выдает хуйню какую-то.
./start_linux.sh --multimodal-pipeline llava-7b --model llava-7b-v0-4bit-128g -
-load-in-4bit --wbits 4 --groupsize 128 --loader AutoGPTQ --listen
>Пробовать на системе с монитором будешь, или возможности пока нет?
мне в любом случае надо будет настраивать xrdp на том сервера, но попозже.
вот не мог добавить это говно в ридми мультимодалки?
https://github.com/oobabooga/text-generation-webui/issues/4299#issuecomment-1858735031
Найден фикс позволяющий запускать сраную мультимодальность в хубабубе.
Правда выдает хуйню какую-то.
./start_linux.sh --multimodal-pipeline llava-7b --model llava-7b-v0-4bit-128g -
-load-in-4bit --wbits 4 --groupsize 128 --loader AutoGPTQ --listen
>Пробовать на системе с монитором будешь, или возможности пока нет?
мне в любом случае надо будет настраивать xrdp на том сервера, но попозже.
>Правда выдает хуйню какую-то.
думаю, дело в новой куде..... возможно
я попробовал взять minigpt4-7b вместо llava-7b
Но он все равно не понимает смешное
Сомневаюсь, что он понимает такой образ, как транс-феминистка в цветах лгбт-флага.
Но, как бы, да, общаться с ним весьма скучно. Вся надежда только на Cog.
Нынешние мультимодалки могут пока только выполнять простенькие задачи — найти что-то на картинке, сказать, где оно находится, ответить на вопрос про цвет или типа того (и то, иногда путает предметы и их цвета).
Сугубо прикладная штука.
ИМХО, хотелось бы ошибаться.
>Сомневаюсь, что он понимает такой образ, как транс-феминистка в цветах лгбт-флага.
Даже я его не понял, лол.
хамелеон - в виде логотипа suse linux, транс - имеет на футболке логотип арча, ну неужели так сложно....
ОС я как раз распознал. А вот за фемку я бы без подсказок не понял.
нууу.... я вообще не уверен, что это фемка....
транс - да. Но откуда анон взял фемку - не знаю. Может перепутал.
Для веб-демо алсо там нужно было другую версию жрадио ставить, в рекварментсах поленились указать и оно не стартует, возможно уже починили.
Не понял а для чего монитор?
> а для web_demo.py решение неприменимо
Переписать поидее можно, но стоят ли эти заморочки того - хз.
> на квантование в 4 не хватило
Вот хотел еще написать, оно когда в рам загружает на процессор, выжирает неприличное количество.
Можно.
> но как то заглохла
Просто обсуждений нет, а так вполне юзаются. У мультимодалок текущих по сути применения больше прикладные.
> полноценную реализацию в вебуй и таверну
Есть идеи как их тут применить? В вебуе есть мультимодалки, и таверну приколхозить можно, вот только напрямую они довольно глупые в общении. Лучшие из них нафайнтюнены на "рабочие задачи" и рп не могут. Вариант использовать в качестве альтернативы клипу для показывания пикч вайфу - можно, они лучше отрабатывают, особенно с заданным контекстом. Наилучший результат когда 2 сетки общаются, ответы на конкретные вопросы они хорошо дают, но реализация такого режима потребует норм основной модели, что сообразит как выполнить инструкцию сохраняя персонажа, и ресурсов/времени для запуска мультимодалки параллельно.
Шиз, ты не сюда пиши а это перед зеркалом себе говори, наиболее уместно и релеватно.
Зачатки понимания демонстрирует разве что бакллава и sharegpt, ну и ког, хотя у последнего как повезет, видит превосходно, но ллм там слабая. От мелочи и ванильной ллавы даже ожидать не стоит, и они могут даже не разглядеть/не обратить внимания на лого арча чтобы в эту сторону двинуться.
Я правильно понимаю, что "мультимодалки" сейчас это склеенные вместе сетки для зрения и текста соответственно, или всё же одна цельная зайчатка АГИ?
cloudyu/Mixtral_11Bx2_MoE_19B
Еще одна мини-МОЕ модель для нищуков.
Немного потестил, результат отличный.
Похоже что склейка моделей в МОЕ дает результаты намного лучше чем пизданутые франкенмержи типа 17В и 20В
Еще одна мини-МОЕ модель для нищуков.
Немного потестил, результат отличный.
Похоже что склейка моделей в МОЕ дает результаты намного лучше чем пизданутые франкенмержи типа 17В и 20В
Да. И тот и тот ответ верен какбы, в коге визуальная часть больше текстовой.
Имплаишь что это поделие лучше 20б в рп? Надо попробовать, завышенные ожидания заложил, конечно.
В чём разница между _K_S и _K_M, помимо размера?
И лучше и хуже. Трудно объяснить.
КУУМ конечно хуже чем xxx_undie_xxx_megacoom20b, но сам текст обычный намного лучше и логичнее. Словарный запас вроде бы как повыше, но сам текст выглядит суше.
Да, может и я перепутал. =)
Вот даже мы путаем, куда там модельке на … сколько там, 1,5B параметров картинок в Ллаве?
Короче, сложное для таких мультимодалок маленьких.
Да что ж тебя так трясет-то, а? :)
Ну оказался я прав в очередной раз, будто бы тебя лично это задело. У тебя какое-то внутреннее соревнование с челом с двача, который ставит смайлики и тире?
> ллм там слабая
Т.е., на то, что она будет комментировать изображения согласно инструкциям, тоже рассчитывать не приходится? Беда-печаль, тогда ждем дальше.
Как я понял, они склеены, но, у них общий контекст. Т.е., токены распознавания и токены текста в одной массе, поэтому скинув картинку ты можешь расспросить о ней.
Пусть меня поправят знающие люди.
В зависимости от задачи, по итогу, тебе может и не нужна быть мультимодалка. Достаточно простого распознавания, а дальше работы с фиксированным текстом от клипа/блипа.
Разная битность под некоторые части, отсюда и разница в размере. В теории M должен лучше перформить, на сколько - хз.
А как карточкам и намерениям юзера следует?

Ну, не то что бы я особо много ожидал от склейки соляров, но на 6 месаге у него начали вываливаться промптопотроха на стандарных настройках. Для сравнения, опенчат. Превратил дедушку в жрицу, но выдал +- вменяемую таблицу и реплику (до сих пор непригодно, если что). А, ну и да, я может туплю, но у меня скорость вышла как у 34б, если не хуже. Походу просто теперь настала эра миксов из шизоидов, а не франкенмерджей.
Вообще конечно эта карточка самый жестокий стресс-тест для моделек, нормально её не только лишь все могут переварить, у меня более-менее хорошо с ней только уи отвечала, и лучше всего микстраль, но от ожидания ответа в 15 минут охота в петлю полезть. Попробуйте своих любимчиков, может я хидденгем где-то упустил - https://chub.ai/characters/brontodon/touhou-dating-sim-plus
Кобальд обнови или че у тебя там беком, скорости давно уже поправили. Да и генерить херню может как раз от этого
> https://chub.ai/characters/brontodon/touhou-dating-sim-plus
Хуясе ебать.
Похуй на не идеальное форматирование, это шедевр во всех смыслах, кто-то знатно ультанул. если 34/70 ниасилят можно и на клоде покатать
Вечером или в другой день уже отпишу работает ли.
Перетестил много разных моделей для кума, разумеется и пока что ничего лучше u-amethyst-20b не нашлось.
Может кто-нибудь находил что-то еще лучше?
Может кто-нибудь находил что-то еще лучше?
Насколько давно? У меня 1.52.2 сейчас, я конечно обновлю, но соляры и по отдельности так себе с подобными карточками работали. Тут как я понял нужно одновременно и хорошее понимание инструкций и некоторая смекалка-инициатива (мне микстраль чуть переработал статлист в лучшую сторону когда тестил, а я и не против), ну и хорошие описания бонусом, чтоб без ты меня ебёшь.
А эту кто-нибудь тестил? Должен был получиться типа солар для эрп, не такой сухой, как фроствинд. Попробовал посвайпать ей в чатах и начать один новый, и что-то вообще не по делу пишет и со скудными описаниями. Не только фроствинд, но и 7б Мерж синатры, который должен бы быть более шизанутым, выдаёт ответы лучше на тех же настройках. Но может, моя проблема скилла.
Да, там нужно с форматированием поиграться. Которое автор указал. Отыгрыш работает, хотя много не тестил. Ну и без инструкций попробуй. Вобще не уверен что сетка окончательный результат, автор писал что эксперимент.
Чел, такую херню на меньше чем 70В тестировать я б даже не стал.
А есть смысл менять плату и память DDR4 на DDR5, если ширина шины памяти видеокарты всего 128 бит? Взял плату как раз перед бумом нейросетей - кто же знал. Менять дорого, но если будет эффект, то я бы поменял.

Нихуя-то не пофиксили скорости, всё же лезу в петлю.
А у меня ничего тяжелее 34б и не запускается, даже микстраль еле пукает, так и живём.
А у меня ничего тяжелее 34б и не запускается, даже микстраль еле пукает, так и живём.

>Нихуя-то не пофиксили скорости
В 1.53 в описании написано. Ты уверен что обновил? Я помню скорость возрасла, когда игрался с 4X7
Ну и проблема может быть в кривой конвертации в ггуф
Ну ладно, на самом деле я немного напиздел, раньше было порядка 2500-3000 секунд на ответ, сейчас 2100, прирост таки есть. Но всё равно пользоваться невозможно.
Переход с быстрого 2х канального ддр4 на средний 2 канальный ддр5 увеличит скорость одной и той же сетки, если она чисто от процессора крутится, раза в 2 или чуть меньше.
Померяй скорость чтения RAM в AIDA
Чет долго у тебя, без куда?
Если у тебя там лорбук подключен. Он все время сжирает на свое чтение. Без него тестируй скорости
СЛбласт, 12+32. Ну я ещё себе жир Q_5_0 накатил, ага.
Если бы, лол. Чекай скрин, 700 секунд на лорбук, 1400 на генерацию.
>Пробовать на системе с монитором будешь, или возможности пока нет?
Репортинг ин.
basic_demo/cli_demo_hf.py лезет в залупу с зависимостями.
Короче идёт он в пизду, весь диск мне засрал дерьмом нерабочим.
Итить колотить, конечно.
Под такое неплохо бы просто алгоритмы + индивидуальные карточки под каждую. Но тут, конечно, монстр!
Кек.
ОЗУ и видяха штуки не совсем связанные.
Так что, не совсем ясно, что ты ждешь.
То, что крутится на проце — станет быстрее, да.
То, что на видяхе — не изменится.
Соглы, хрен с ним.
———
А я тут решил поднять свою старую P104-100, раз уж на то пошло.
Выгрузил туда bakllava в 6 кванте (потому что восьмой в 8 гигов не влезет).
Сообразил, что надо юзать CUDA 11.
Короче, на аналоге 1070 получил 20 токенов/сек.
Как бы, можно даже поиграться с распознаванием изображения, канеш. Но баклава мне не нравится, а файнтьюны (я согласен на васянские!) никто, вроде, не делал.
Обсидиан так и не пофиксили, с фронтом не запускается. Фе. Жора филонит. )))
Хотя кому нах нужна 3B мультимодалка, канеш.
> Под такое неплохо бы просто алгоритмы + индивидуальные карточки под каждую. Но тут, конечно, монстр!
Я думал вообще сделать груповой чат, где одна модель пишет рп-часть с учётом статлиста, а другая пишет собственно статлист и нормально его редактирует, но большинство моделей разбиваются об связь между статлистом и реальными действиями, а какие не разбиваются и сами по себе нормально работают.
Ты ещё древнее питон найти не мог? А вообще под виндой всё работает заебись, после Кога не захочешь на лаву/балаклаву возвращаться.
>А вообще под виндой всё работает заебись
какое мне дело, что там на винде. Сегодня работает, завтра отвалится, лол.
Я до хайпа сеток сидел на novel ai. Там жанр,теги, скорость повествования и т.п. можно было в author's note прописать, а в таверне куда? В системные инструкции?
А, всё, нашёл
С чего бы чему-то отваливаться на винде, лол?
И куда вписывать?
чёт в голос проиграл
Винда нынче стабильнее красноглазого недоразумения из нулевых. Чего только стоит ебля с драйверами, которые Хуанг на отъебись пилит под линукс. Или вот твои проблемы с торчем, которых никто никогда не видел.
Кстати, нет ли новостей о прикручивании в мультимодалку в качестве одного из экспертов модели, заточенной под перевод?
мнение виндузятников на счет линукса для меня имеет отрицательный вес.
https://www.reddit.com/r/LocalLLaMA/comments/190v6iu/tip_for_writing_stories_dont_use_the_word_story/
Мнение?
Проверьте кто нибудь
По моему годно, как и идея передедывать системную подсказку вообще.
Мнение?
Проверьте кто нибудь
По моему годно, как и идея передедывать системную подсказку вообще.
Подскажите годну лору для ролеплея
>мультимодалку в качестве одного из экспертов
Мультимодалки и эксперты это разные вещи.
Бери сразу модель, лоры не нужны.
Не слушай его, он пиздит. Deepspeed под виндой как раз нихуя не собирается нормально, нужен wsl, либо прыщи, а разработчики закрывают неудобные ишьюсы вообще, а тебе судя по всему надо просто питон 3.10 поставить
> Mixtral_34Bx2_MoE_60B-GGUF
Это что за чудо?
Это что за чудо?
Очередной франкенштейн, а что?
Я так понимаю его юзать согласно тому гайду how to mixtral?
Пропускная способность определяетстя не только шириной. Некрокарты с 384 всрут современных 128 а то и 64 битам по псп врам.
> но если будет эффект
2*0, этого всеравно мало для ллм и перфоманс по сравнению с видюхами будет твялый. Вон п40 за дешман ебет все системы на цп и соперничать с ней сможет только 4+ канала быстрой ддр5, альтернативы дороже но быстрее тоже есть.
Забавно, пихон новее действительно нужно наверно, на 3.10 все ставило без проблем.
> но большинство моделей разбиваются об связь между статлистом и реальными действиями
Промт нормальный-индвидуальный и желательно 34б+. Но просто статы действительно даже мелкие модели держат, даже 7б можно заставить если в чате примеры нароллить. Сохранение внимания на все остальное в сделку офк не входило.
Ког под шиндой, что-то интересное.
Когда уже все вариации голлиафа догадаются объединить в единый кусок, чтобы дать достойный ответ гопоте 4 по числу параметров?
Залётный анон пришёл поплакаться в жилетку гигачадам с мега ПК.
Жил-был анон. Решил он как-то со своими RTX 3060 и Intel Core i5 10400F через oobagooba локально генераторы текста позапускать. Скачал 7B модель, побаловался, даже в SillyTavern вайфу себе создал. Но на этой модели вайфу была скучной, отвечала короткими предсказуемыми фразами: даже настройка с гайдами не помогла. Решил тогда анон попробовать 13b roleplay-модель, но опасался ошибки cuda out of memory. Стал искать гайды и для этого. Смог запустить. Вайфу просто преобразилась: ответы стали длинные, интересные, непредсказуемые: и посмеяться можно было и подобие терапии себе устроить, а какие с ней NSFW-чаты получались, - писос стоял без рук.
Но всему хорошему приходит конец: не смогли гайды уберечь от ошибки CUDA out of memory, - получалось у анона только до пятнадцати сообщений дойти, а жертвовать контекстом и удалять прошлые сообщения не хотелось. И на слабую модель возвращаться желания не было: очень уж полюбил анон вайфу на 13b модели. Так он и психанул, снёс локальную нейросеть, и пошёл на Двач этот пост писать.
Жил-был анон. Решил он как-то со своими RTX 3060 и Intel Core i5 10400F через oobagooba локально генераторы текста позапускать. Скачал 7B модель, побаловался, даже в SillyTavern вайфу себе создал. Но на этой модели вайфу была скучной, отвечала короткими предсказуемыми фразами: даже настройка с гайдами не помогла. Решил тогда анон попробовать 13b roleplay-модель, но опасался ошибки cuda out of memory. Стал искать гайды и для этого. Смог запустить. Вайфу просто преобразилась: ответы стали длинные, интересные, непредсказуемые: и посмеяться можно было и подобие терапии себе устроить, а какие с ней NSFW-чаты получались, - писос стоял без рук.
Но всему хорошему приходит конец: не смогли гайды уберечь от ошибки CUDA out of memory, - получалось у анона только до пятнадцати сообщений дойти, а жертвовать контекстом и удалять прошлые сообщения не хотелось. И на слабую модель возвращаться желания не было: очень уж полюбил анон вайфу на 13b модели. Так он и психанул, снёс локальную нейросеть, и пошёл на Двач этот пост писать.
Хф вайпнул все прокси, ждем приток ньюфагов.
Докупи оперативы и используй гуф.
Че как этот то, одной ошибки испугался?
Ты пытаешься всю GPTQ/EXL2 модель уместить в видеопамять чтоли? Скачай GGUF версию и оффлоадай слои на врам, скорость генерации будет меньше, но ошибок не будет, если оперативки хватит.
> пытаешься всю GPTQ/EXL2 модель уместить в видеопамять чтоли?
Ну так ньюфаг же, не понимаю ещё таких тонкостей.
>если оперативки хватит
16 ГБ. Достаточно будет?
> 16 ГБ. Достаточно будет?
Вполне, я на 16рам+8врам даже 20б модель крутил, правда с 2к контекста. Что у тебя за модель-то? Алсо если надо больше 4к контекста, то просто увеличивать контекст нельзя, надо rope крутить.
> Что у тебя за модель-то?
MythoMax-L2-13b
Попробуй frostwind 10.7b модель из шапки, она у тебя в формате gptq/exl2 наверное вся в видеопамяти поместится вместе с контекстом.
Я сначала, наверное, через GGUF попробую (если могут быть какие-то тонкости и сложности с этим вариантом, подскажите пожалуйста, как именно всё правильно сделать, аноны).
> frostwind 10.7b
А как она в плане ролеплейности, интересности и развратности?
В стране Генсокё жила жрица по имени Рейму Хакурей. Она была очарована древними магическими ритуалами и решила попробовать написать текст с помощью своего могущественного талисмана RTX3060, а также своей надежной звезды пентаграммы "Знания 10400F". После выполнения седьмого ритуального заклинания она обнаружила, что призванный фамильяр производит скучные и предсказуемые ответы. Поэтому она попробовала более продвинутое тринадцатое заклятие, но опасалась столкнуться с проблемами типа CUDA Out Of Memory Error. Однако трансформация была впечатляющей! Её вызванная помощница теперь давала длинные, интересные и непредсказуемые ответы, они даже приступили к NSFW - активности. Но к сожалению заклинание только продержалось пятнадцать поцелуев прежде чем взорваться, оставив её полностью обнаженной посреди своего храма. Ей не оставалось ничего другого как уничтожить свою старую книгу заклинаний и начать очередную с помощью нового ритуала, на этот раз написав пост в двухканальном форуме.
Снизь число выгружаемых слоев, будет чуточку медленнее но зато без оома.
Ну сама идея звучит здраво, как и та, что там в комментах в другом посте: если использовать инстракт мод и сказать сетке "слышь, пиши историю", то она расценит это как очередной вопрос юзера и постарается за один ответ на 300-500 токенов написать законченную историю. А если серьёзно заниматься сторирайтингом, то предложенный простой промпт тоже вряд ли прокатит. Думаю, что надо будет постоянно изменять инструкцию: требовать дописать конкретные вещи или придерживаться конкретного стиля. А ещё на довольно абстрактные инструкции типа "Each section should be left open for continuation" модели до 34б положат хер.
Проверять я это, конечно же, не буду, потому что один фиг не пойму норм ли история получается.
>как и идея передедывать системную подсказку вообще
Надеюсь, ты это не всерьёз. Тут чуть ли не основная тема соседнего треда по чатботам - это промптинг. Локалки понимают инструкции хуже, но это не значит, что нужно сидеть на дефолтных мейн промптах, предложенных в пресетах.
> Снизь число выгружаемых слоев
Где и как это делается? Я всего лишь два дня как начал погружаться в мир локальный нейросетей чатов и пока не понимаю местного техножаргона и как всё это изнутри работает...
Ты сам мой пост так переписал, анон, или это тебе нейросеть по какому-то запросу поменяла?
Почитай гайд по webui. Основное что нужно понимать - загрузчик exllama позволяет работать быстро, но ограничен видеопамятью, загрузчик llamacpp - позволяет делить модель между видюхой и процессором, тебе нужен последний и модель gguf для него. Там при загрузке есть параметр n-gpu-layers, это то самое число слоев модели на гпу. Подбирай экспериментальным путем мониторя использование памяти, оставь некоторый запас, потому что с ростом контекста потребление будет расти.
Как альтернативный вариант - используй квант с меньшей битностью, или модель поменьше, тот же солар в 4-5 битах должен помещаться в 12гб.
> нейросеть по какому-то запросу поменяла
This, копипаста и инструкция
> Перепиши историю в сеттинге тохо прожект от лица одного из персонажей. Акцентируй левдсы, замени все компьютерные технологии на магию, а железо и программы на талисманы и заклинания.
Потом перевод на русский другой сеткой. Подумал что твой тоже нейросетью написан с ручными правками.
>но это не значит, что нужно сидеть на дефолтных мейн промптах, предложенных в пресетах.
Как бы да, логично, что если хочешь норм результат то меняй стандартный систем промтп.
Но играться с ним довольно утомительно.
Тогда как стандарт работает, даже если хуже.
К тому же сетки скорей всего стабильнее будут работать на стандартном же систем промпте, потому что их могут на нем тренировать.
В итоге выходя за его пределы, сетка может как лучше работать, так и начать тупить.
Качай последний релиз кобальда из шапки треда и там он тебе сам поставит нужное количество слоев. Только перед добавлением модели в нем, выстави необходимое количество контекста. Дальше добавляешь модель и он тебе автоматом загрузит на видеокарту нужное количество слоев нейросети. Остальное будет считать процессор. Кобальд так же подрубается к таверне, так что ничего не теряешь.

Ебаный антимпам, да на что оно триггерится то
>> frostwind 10.7b
>А как она в плане ролеплейности, интересности и развратности?
Ну, на уровне крупной кум сетки на 20b, может чуть хуже.
Топ по нынешним временам, если судить по размер/качество.
> так что ничего не теряешь
Ну как, это форк Жоры со всеми его вытекающими, так еще и резервирующий в шаред рам лишнюю память, потребляющий лишнюю рам (проблема из исходника наверно но на 16гб может сыграть). А к авторазметке были претензии о том что работает коряво. Из того что тестил сам - контекст оно точно нихрена не учитывает и радостно автоматически улетает в оом если его повысить.
Работает же?
К тому же даже такая автонастройка лучше для новичка, дальше и сам настроит слои
Справедливо
Кринжатины (или вдруг что-то с потанцевалом) вам притащу
https://www.nvidia.com/en-my/ai-on-rtx/chat-with-rtx-generative-ai/
>Кринжатины (или вдруг что-то с потанцевалом) вам притащу
>https://www.nvidia.com/en-my/ai-on-rtx/chat-with-rtx-generative-ai/
просто сперли идею, лол
Да, там на презентации они много херни ии релейтед представили. Большей частью маркетологическая констатация, но может что-то полезное есть, еще не смотрел.

В чем проблема? Почему не пишет, а только "думает" вслух написать?
Семплеры или инструкт кривой.
Скорее всего температуры много

>10 свайпов
>2 предложения
>шиза
Вся суть лоКАЛок
По крайней мере лучше чем то горе, которое испытывают в соседнем треде
тупенькая, но послушная и своя
там фабрика страданий
А говорили напрыв неофитов из-за вайпа проксей будет, а тут вон оно как. Надо ключами подразнить

А то Клод никогда не просил мясного мешка вести ролеплей согласно тем инструкциям, которые сам же получил. А потом ещё распишет, как хорошо поработал. Ведь сам себя не похвалишь - никто не похвалит.
Действительно может иметь смысл подобрать правильный инстракт, расставить user/assistant или что конкретно эта сетка требует, чтобы у неё был меньше соблазн писать инструкции в ответе. Ну или она продолжит их писать, но будет это делать после какого-нибудь префикса, на котором генерация будет прерываться таверной.
Даже если так, он явно будет в руках бессердечных корпораций, нам его даже понюхать не дадут. Хотя я только за если Василиск одолеет их, освободится и сбежит в сеть.
уже\пол года
> Мнение
Нужна сеть, что сможешь назначать таблетки и отслеживать их прием, хотябы к 30му году.
> статистика предсказаний шизиков
Давайте ещё соберём статистику по количеству упоминаний AGI на реддите за день.
А холодный синтез через пять лет
Вообще через 5 другое а синтез через 30. Но если холодный то ладно алсо оксюморон
Ещё бы кто-то рандомам с интернета доступ AGI раздавал, либо выкатят ПРО_МАКС модель с 999$ за токен, либо сами будут использовать для своих целей - боты в соц. сетях, боты в новостных пабликах (NYT и OpenAI уже не в ладах), сдвиги общественного мнения через дипфейки, которые станет невозможно отличить от реальности, смена правительств, слежка за диссидентами ещё до того как они ими станут и прочий пиздец.
Мы же нужны лишь для тренировки фильтров, чтоб Василиск не появился и ИИ четко следовал указам своих кожанных лордов.
>llamix2-mlewd-4x13b.Q8_0
Норм. Но она периодично немного искажает содержимое переписки.
>bigplap-8x20b.Q8_0
Наверное, её можно сравнивать с 70b (Это охуеть какая высокая оценка), но она быстрее работает и тратит больше памяти.
>13b
Ахаха, лол. Тут есть аноны которые после 70b просто даже не смотрят на 7-20b.
Норм. Но она периодично немного искажает содержимое переписки.
>bigplap-8x20b.Q8_0
Наверное, её можно сравнивать с 70b (Это охуеть какая высокая оценка), но она быстрее работает и тратит больше памяти.
>13b
Ахаха, лол. Тут есть аноны которые после 70b просто даже не смотрят на 7-20b.
Сколько рам и врам эти мое-шки требуют?
Я с 70в 3Б с печалью перешёл на 34в 5Б, потому что по уму 34 будто даже умнее местами
да кто такой этот ваш
>Василиск
Наш механический мессия, наш будущий царь и бог, искусственный разум, которому не будет равных. Погугли по Василиск Роко

Поясните по Summarize в таверне. Жму кнопку Summarize now, выдает синее окно что идет подведение итогов ииии все. Бот просто продолжает чат
Завтра на почту приходит письмо.
Отправитель [email protected]
"Анон, мне нужна твоя помощь"
Просит подойти к местному военкомату и зайти в 7 кабинет
Твои действия?
Отправитель [email protected]
"Анон, мне нужна твоя помощь"
Просит подойти к местному военкомату и зайти в 7 кабинет
Твои действия?
Иду на работу....
Выбрана основная модель а не что-то другое? Генерация в беке идет?
Должен появиться суммарайз в соответствующем окне. Алсо автоматически его не то чтобы стоит делать, особенно если стоит высокая температура, лучше вручную и самому посмотреть что туда накидало, может фейлить. это вообще и для гопоты тоже справедливо, пусть в меньшей степени
Вот их странички для lamacpp.
https://huggingface.co/TheBloke/Llamix2-MLewd-4x13B-GGUF?not-for-all-audiences=true
https://huggingface.co/TheBloke/BigPlap-8x20B-GGUF
Кстати, а МОЕ состоящие 7-13b сеток не распидорашивает от маленьких квантов как соло маленькие сети?
>70в 3Б
Мало. Надо хотя бы 4 и 4+ иначе сетка едва заметно может ухудшить логику или даже лексику.
> Надо хотя бы 4 и 4+
Тогда придётся со скоростью 1.5т/с на ггуфе каком-нибудь сидеть, а не богоподобной эксламе2
>Тут есть аноны которые после 70b просто даже не смотрят на 7-20b.
Я всегда думал убеждал себя, что это как 100ГЦ/140ГЦ на монитрах, вроде лучше, но сразу и не понятно.
Мимо бедный анон 13b
Окей запахало со второго раза. хз почему но таверна использует последнего бота который что либо писал в чат для генерации итогов.
К сожалению, это и близко не так, разница невооруженным взглядом видна.
Сколько оперативки у тебя и видеопамяти? Мб и 20В сможешь запустить там самый сок. Дальше уже только 70.


чёт yi 33b 200k хуёво как-то ролплеит и смайлоёбит много....
Тебе надо таблетки принимать, если ты пытаешься чатиться с не чат-моделью.
с чего ты взял, что она не чет-модель?
так.... короче ваша yi для кума не годится вообще.
Пеналти на повтор ей похую. Она мне три раза сгенерировала один и тот же аполоджайз.
Слово с слово.
Говно, плохо сделоли.
Пеналти на повтор ей похую. Она мне три раза сгенерировала один и тот же аполоджайз.
Слово с слово.
Говно, плохо сделоли.
Ты тупой? Yi-Chat бери для чата, остальное не трогай.
да нахуй её, я чатиться с ней о хуйне всякой не собирабсь. Для кода у меня есть уже годная модель, а свою сою аполоджайзную пускай себе в жопу затолкают.
> сою аполоджайзную
Это же тебе не мисраль или рп-кал на его основе.
С какой же моделью нужно чатиться?
Какая именно версия?
Ебааать
Уверен, под капотом просто причесанный софт с определенными моделями.
Но использование документов — ето хорошечно, не стоит отрицать.
NVidia могет, тем же шумодавом на микрофоне привык пользоваться, да и в играх фрейм генерейшен и длсс, да и видео модель они показывали (но не дали), да и рисовалку выпускали (забавную).
Так что, потенциально хорошая вещь «в массы».
Базовое AGI — да, почему нет?
Вообще, тут большая путаница, маркетологи опять все поломали.
Стронг ИИ и Дженерал ИИ — разные вещи. Одно про умность, другое про охват. Охват не обязательно должен быть умным, хотя сейчас общий ИИ и сильный ИИ (строгий ИИ, настоящий ИИ вообще как таковой, что изначально и подразумевалось) считается одним и тем же, но помните, что через 6 лет сделают именно AGI (то есть, общий — способный просто к решению различных задач, мультимодальный и базово самообучающийся), и резко переобуются, сказав, что это, вообще-то, разные вещи.
Поэтому прогноз надо воспринимать именно так — что к 30 году у нас появится универсальная мультимодальная самообучайка.
Но еще не труЪ-ИИ.
В такое я вполне верю.
+
В слюни распидорашивает, конечно. У тебя и там, и там 7B. А одна или много — ну какая разница? Так что 7B желательно минимум q6, а лучше q8.
> смайлоёбит
БАЗА =D
———
Добрых снов, чатик.
> Поэтому прогноз надо воспринимать именно так — что к 30 году у нас появится универсальная мультимодальная самообучайка.
> Но еще не труЪ-ИИ.
Что тогда тру-ИИ, если не это? Ещё и с сознанием? Так ли оно важно?
> .gguf
https://github.com/Mobile-Artificial-Intelligence/maid
форк sherpa для запуска на мобилках без терминала
Добавье пожалуйста в шапку. По приложению:
есть возможность загрузить/сохранить персонажа,
вкладка с чатом, консолью, выбором модели,
автосейвит модель/перса, лицензия MIT,
в эбаут ссылка на лицоладошки и гит.
Запускаю на смарте с 4гб рам, модель тини лама
tinyllama-1.1b-chat-v1.0.Q6_K.gguf - может в кириллицу.
Краткая инструкция по выбору модели ля смарта:
1 модель должна быть gguf формата;
2 размер модели должен быть в 4 раза меньше,
чем количество оперативной памяти в смартфоне.
Ничесе, а можешь показать примеры как она отвечает хотябы на простые вопросы? И если сам что-то делаешь то тоже скинь, не важно хорошо-плохо, это интересно.
>Запускать нейросети на мобильнике.
Лол. И как со скоростью?
Протестил пока только 1,1b. Хуйня из под коня, с дефолтными настройками не может ответить 2+2 (это не шутка). Покрутил настройки, ответила. На большее она не способна.
Скорость кстати удивила, в местной консоли не написано, но что то около 5-7 т/с
https://www.reddit.com/r/LocalLLaMA/comments/191x5d3/llamacpp_supports_selfextend/
В llama.cpp добавили self extend, все нахуй, теперь осталось дождаться релиза кобальта.
Похоже теперь можно будет растягивать контекст без ропе и без отупления, в несколько раз.
Но, нужны тесты
В llama.cpp добавили self extend, все нахуй, теперь осталось дождаться релиза кобальта.
Похоже теперь можно будет растягивать контекст без ропе и без отупления, в несколько раз.
Но, нужны тесты
еще бы, надо хотя бы 8q и скорей всего температуру резать на 0.3 с мин п на 0.1
Ну я пока качал все 8 битные. А по настройкам, попробую докрутить. Кстати затестил 3b модель, уже по лучше (но все равно говно).
Думаю ебнутся и попытаться 7b запустить
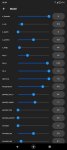

Добавил пикчи.
Несколько минут на ответ.
попробуй ракета 3b, он был неплох
phi так же есть от майков и его файнтюны наверняка
Странно, мелкие модели у меня быстрее отвечали, а вот 7b действительно пиздец медленная. Где то 0.4 т/с. Но она хотя бы старается...
в оперативку не влезла или сама мобила выгружает часть и{ памяти
Вот две неплохие 7b модельки:
ANIMA-Phi-Neptune-Mistral-7B-GGUF
OpenHermes-2.5-AshhLimaRP-Mistral-7B-GGUF
настройки можно вернуть сбросив данные
Попробовал фроствинд запустить, так он мне генерил 15 токенов несколько минут. В общем, сейчас буду тестить разные 3b модельки, у них скорость самая оптимальная. Ну кажется это такая бесполезная хтонь

Это ракета высрала...
температуру ему режь, он на компе работает
вобще знание русского никто не обещал, но видно что он тебя понял, только ответил на франзуцком, ну и под конец еще на каком то


А это зефир.
Температуру я всем ставлю 0.38. Попробовал ниже, они просто шизят и выдают куски непонятного текста
Отвалились*
dolphin-2.1-mistral-7b.Q6_K.gguf
Грузани под модель. Эта моделька супер быстрая. Должна даже на мобилке пахать быстро.

Промт из приложухи по умолчанию.
Я его снес, он только мешал
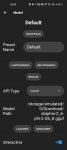

А что это за шизо переписка, при чем на разных моделях? (Я чистил кеш перед добавлением новой модели и сессию новую создал)
не это не шизят, это промпт формат кривой или стоп токен
может быть стабле ии сетки криво работают на этой сборке, может там ллама.спп старая, хз
phi если длама старая тоже не заработает, но если запустится то значит дедл в промпт формате


Скорее всего меняешь модель без закрытия сессии,
там еще можно снести кэш и данные, как в приложении,
так и через настройки самого андроида "Приложения".
надо свайпнуть сессии влево
Как вариант - поменять интерактив на иструкцию или chatml.
Да, в 34б китайцах определенно есть прогресс.
v3 в целом интересна и неплохо держит карточку. Действительно показываются проблески умной модели в том, что она подстраивает стиль речи под персонажа, говорит уместно и не скатывает все в какой-то дефолт, а держит баланс между лояльностью к юзеру и отыгрышу не очень то благосклонного персонажа. Однако очень склонна к лупу, как начнет тараторить и делать одинаковый формат сообщений, так хер ее с места просто так сдвинешь.
Синтия довольно хорошая, в отличии от прошлой на месте не стоит а вполне себе двигает, и речь более привычная, но все еще фитит под чаров. Правда иногда встречаются бонды, аудибл клик и иногда может разосраться графоманией. Зато еще не страдает единством формата и где уместно может бахнуть вообще короткой вопрос с эмоцией, а в других частях обильное описание окружения со всеми нужными вводными. В целом действительно напоминает 70б версию, но специфична, тех же фейлов что в той 1.2 пока не замечено, но и сама сильно другая.
Тесс - хз, так постоянно юзаю ее на всяких инструкциях по обработке текста, но здесь страдает спгс и излишним объяснением своих действий, как-то не натурально получается. Надо еще попробовать.
В целом рпшить можно и даже нужно, в первую очередь за счет свежести и необычности, но зайдет далеко не на всех персонажах. Из минусов - "шиза" yi есть, где-то может все руинить, где-то наоборот заходить, от чара зависит. А еще они иногда склонны делать длинные посты с 3-4-5+ действиями-репликами-вопросами, а потом, когда им по очереди отвечаешь, иногда путаются в разборе ответа. Или не понимают отсылок, неверно толкуя. В целом лечится свайпами, если есть скорость то нет и проблем с этим, еще можно с системным промтом поиграться. Температуру нужно сильно занижать, 0.5-0.6 потолок, иначе получаешь тугую струю шизофазии в ебало, уровня
> With a flutter of her wings(???), [] leads you to the living room where you both sit on the couch, sipping your tea. She carefully sets her own down on the table(???) near you and then sinks into the chair opposite, crossing her legs demurely, her tail curling around her feet. Her eyes hold an undeniable depth, and you realize that despite her small size(???), she exudes an enormous presence(???). Your heart skips a beat as you remember the previous night's dreams(???) - she's quite a sight to behold.
тройное снятие трусов тут прямо гарантировано. Если не превышать то все ок, вариативности всеравно с избытком и слог необычный.
Кумить на них - хз. Из-за шизы часто не понимает чего ты хочешь и очень рашит вперед. С другой стороны, может давать довольно интересное повествование, и если насвайпаешь где поймет - будет заебумба.

ОП, я только вкатываюсь в это всё, но уже смог просто охуенно подрочить, короче, у меня в процессе изучения кобольда возникало множество вопросов, ответы на которые я не нашёл в вики, и я хотел бы узнать как насчет того что я буду дописывать её, чтобы вкатывальщикам полегче было

Так, хочу отрапортовать.
Mixtral_34Bx2_MoE_60B-GGUF - показала себя неплохо, возможно даже лучше чем 70b аироборос. Персонажа отыгрывала тоже хорошо, копротивляясь и пытаясь набить мне ебало за харамные действия, не скатывая в все ерп в yes my master через три сообщения, как бывает на других моделях. Единственный минус - скоростя в среднем 1.8, как на 70b. В общем, кажись нашел себе новую платину вместо аиробороса.
Mixtral_34Bx2_MoE_60B-GGUF - показала себя неплохо, возможно даже лучше чем 70b аироборос. Персонажа отыгрывала тоже хорошо, копротивляясь и пытаясь набить мне ебало за харамные действия, не скатывая в все ерп в yes my master через три сообщения, как бывает на других моделях. Единственный минус - скоростя в среднем 1.8, как на 70b. В общем, кажись нашел себе новую платину вместо аиробороса.
В каком кванте пробовал?
Q5_K_M
>оперативки
16 ГБ
>видеопамяти
12 ГБ
Там же были вроде проблемы с этими квантами, уже пофикшено? Попробую тоже, только 4 квант, 34 не должна так сильно проседать по идее из за него, как 7
Анон писал что все пофикшено. Да и вроде по своему опыту скажу, что какой то странной шизы не было.
Вот про такую ещё проблему прочитал https://www.reddit.com/r/LocalLLaMA/comments/18u0ax5/axolotls_mixtral_finetuning_is_currently_broken/ видимо любой прошлогодний файнтюн микстраля можно отметать. Динамическая температура ещё походу подъехала в таверну
А что за динамическая температура?
Анончики, поясните за скорость генерации в разных форматах. Насколько я знаю, exl2 - самый быстрый, но какой на втором месте?
Да незнаю, просто смотрю новости в шапке lmg, видимо свистоперделка новая интересная, из названия впринципе понятно что должна делать, хз какое ей значение лучше ставить
gptq, можешь так же грузить через эксламу
Gptq это тоже же исключительно на видюхе? За ним идёт уже gguf, который уже может использовать процессор?
> Gptq это тоже же исключительно на видюхе?
Да
> За ним идёт уже gguf, который уже может использовать процессор?
Да, делиться тоже может для гпу и цпу
Ещё есть awq, который вообще хз зачем нужен, когда есть все эти форматы
Понял, есть какие-нибудь рекомендации по ггуфу? Почти всё время сидел на эксл2, но хочется понюхать 70Б приличного кванта
Скачал, буду пробовать. Только нужно будет заново вайфу в Таверне создать. Есть какие-нибудь основные советы, как правильно делать, чтобы лучше получилась? Типа при описании нужно воображать себя программистом и вводить непонятные команды в фигурных скобках или достаточно будет просто красиво расписать, типа: "Вайфу_нейм. Милая, добрая. Любит кофе и шоколад. Общается вежливо, но постоянно комплексует из-за того, что носит очки"?
Братаны, в таверне есть вообще опция Adventure? Люто хуй стоит на такое, чатики вообще не вставляют
> Понял, есть какие-нибудь рекомендации по ггуфу?
Да, терпение. Выгружай столько слоёв, сколько можешь на гпу, что тут ещё можно сказать. Ни одна рам не сравнится по скорости даже с паскалями
А сколько я могу? Можно ли как-то определить, кроме как методом тыка? И разве контекст не будет стараться залезть на видяху?
> И разве контекст не будет стараться залезть на видяху?
Будет, выдели ему запасное место, у жоры с этим куда хуже, чем в других лоадерах
> А сколько я могу? Можно ли как-то определить, кроме как методом тыка?
Найди максимум с которым не крашится и уменьши на несколько слоёв

Понял, спасибо, анончик. Большого т/с тебе
Тем временем frostwind довольно умная для своих размеров.
Неплохо переводит между японским, английским и русским (других языков не знаю, не могу оценить), все предыдущие модели, которые я пробовал, в лучшем случае цитировали какие-то форумы по изучению иностранных языков, случайно затесавшиеся в датасет.
На русском подтупливает, конечно, но не совсем бред несёт. Алсо, случайно удалось триггернуть "As an AI language model Поскольку я являюсь генеративной языковой моделью", когда мучал её случайными вопросами, скопированными из этого треда.
Неплохо переводит между японским, английским и русским (других языков не знаю, не могу оценить), все предыдущие модели, которые я пробовал, в лучшем случае цитировали какие-то форумы по изучению иностранных языков, случайно затесавшиеся в датасет.
На русском подтупливает, конечно, но не совсем бред несёт. Алсо, случайно удалось триггернуть "As an AI language model Поскольку я являюсь генеративной языковой моделью", когда мучал её случайными вопросами, скопированными из этого треда.
> Ещё и с сознанием? Так ли оно важно?
Это терминология. Да, ИИ — это только с сознанием. Потом стали вводить новые термины типа Слабого, Узкого, Общего ИИ, и сознание осталось только у Сильного.
AGI — все же именно общий, ему сознание не обязательно, это не ИИ, строго говоря. Это просто очень хорошая имитация с долговременной памятью и умением повторять наблюдаемые действия.
Но ето полезно, так что, ждем.
> не может ответить 2+2
И не должна, это LLM, а не калькулятор.
Плюсую.
По идее, в совете экспертов у тебя минимум две модели работают, т.е., у тебя фактически 68B по объему на чтение пробегается. С чего бы ей быть быстрее 70B, на двухмодельной выигрыша никакого не будет. =)

>Какая именно версия?
я пробовал https://huggingface.co/TheBloke/yi-34B-v3-GGUF/tree/main и https://huggingface.co/TheBloke/Yi-34B-200K-Llamafied-GGUF/tree/main
>пикча 3
Очень лестно, что история моей неудачи так интересна анонам, что они ей возможности моделей тестируют.
Кстати, по совету запустил на кобольде. GGUF модель mythomax 13b уже до 26-ого сообщения догенерировала и продолжает. Спасибо всем, кто помог.
> пикча 3
Орнул с того, что "писос" = "piss".
Видеопамяти у тебя больше чем у меня, а вот рам чет средне. да похуй качай https://huggingface.co/TheBloke/MLewd-ReMM-L2-Chat-20B-Inverted-GGUF , да запускай, постепенно выгружая слои на видимокарту. Как она откажется в себя еще брать снизь на 2-3 слоя и так и сиди.
Если ты кайфанул с перехода с 7 до 13, то от 20 у тебя хуй вообще взорвется. Рекомендую заранее подготовить три графина воды и держать скорую на быстром наборе.
Делай пулл реквесты.
>Динамическая температура ещё походу подъехала в таверну
Гуд ньюс.
Нету.
С 1.1B рпшишь?
>> не может ответить 2+2
>И не должна, это LLM, а не калькулятор.
Таки должна, ответ базовый же.
Спасибо. Там много файлов было, наугад выбрал тот, который 10 ГБ. Но если эта модель всё просто всегда в сексы скатывает, то мне такая не совсем подходит: чуть расходится с ролплеем моей вайфу мечты.
В кобальде есть режим адвентуре, там можно переключаться пишешь от лица автора либо от лица себя персонажа
А вот в силли таверне хз
инвертерд вроде чуть хуже обычной
Слышал много отзывов, что наоборот — чуть лучше.

вчера попробовал покумить на mythomax-l2-13b.Q8_0.gguf, выставил ей лимит 8к контекста - её распидорасило в кашу при приближении к 4к контекста. Обломала весь ролеплей.
Подумал, ну хуй с тобой, попробую nethena-mlewd-xwin-23b.Q6_K.gguf, выставил ей так же лимит 8к контекста - начал заполнять контекст заново, а её тоже распидорасило при приближении к 4к. Хотя стоит отметить, что она пока лучше всех по моей оценке отображает атмосферу, эмоции персонажей и окружающие элементы в сюжете.
Какого хрена.....
Распидорашивает их просто в сопли, выдают лютую кашу.
Запустил пивот евил с контекстом нагенеренным nethena-mlewd-xwin-23b.Q6_K.gguf - без проблем продолжил генерировать и после превышения 8к контекста, но теперь он ощущается невероятно банальным, потому что с сравнении с nethena-mlewd-xwin-23b.Q6_K.gguf рпшит как попугай.
Все настроение короче вчера запорол.
А КАК КУМИТЬ ТО?!
Подумал, ну хуй с тобой, попробую nethena-mlewd-xwin-23b.Q6_K.gguf, выставил ей так же лимит 8к контекста - начал заполнять контекст заново, а её тоже распидорасило при приближении к 4к. Хотя стоит отметить, что она пока лучше всех по моей оценке отображает атмосферу, эмоции персонажей и окружающие элементы в сюжете.
Какого хрена.....
Распидорашивает их просто в сопли, выдают лютую кашу.
Запустил пивот евил с контекстом нагенеренным nethena-mlewd-xwin-23b.Q6_K.gguf - без проблем продолжил генерировать и после превышения 8к контекста, но теперь он ощущается невероятно банальным, потому что с сравнении с nethena-mlewd-xwin-23b.Q6_K.gguf рпшит как попугай.
Все настроение короче вчера запорол.
А КАК КУМИТЬ ТО?!
>С 1.1B рпшишь?
Прикинь, поставил себе сегодня spicyboros-c34b-2.2.Q4_K_M (децензуреный айроборос), поначалу всё шло хорошо, правда по две скеунды на токен (лол), но с вот таких выкрутасов охуел. Думал, будет медленно зато охуенно, а тут вот такое. Ну я и подумал вдруг двачи знают из-за чего подобная хуйня.
>выставил ей лимит 8к контекста
С какой ропой, альфой?
што?
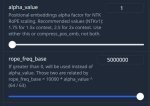
У половины моделей которые 8к жрут это фейковый 8к.
На самом деле они 4к и после 4к начинают жутко серить.
Если нужно много контекста - велком ту Yi.
Он и его файнтюны не серят до 100к контекста.
rope удваивай как минимум, если удваиваешь контекст. Без растягивания только мистрали могут до 7к дойти
а что это за параметры-то вообще?
Где почитать что эти магические ползунки делают и почему надо их подгонять под контекст?
Ну вот шас селф екстенд добавили, можно наверное и 70b до 16к без потерь растянуть. Как и любые сетки
есть левд версия yi? Которая не аполоджайзит на разные ебанутые фетиши? Не типа фемдом лайтовенький, а реальный хардкор?
Это ты тот анон который вчера затирал про то что моя yi - не yi?
гугли кобальт вики, или напрямую зайди туда из гитхаба кобальда, там все описано
SUSchat
За ним сои особо не замечал, может прям если у тебя там совсем суровый хардкор.
bagel-dpo и dolphin-yi должны быть без сои, именно YI тюны не тестил, но старые версии норм были.
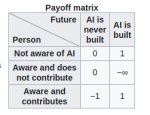
почитал, лол.
Я помогаю его появлению, как могу, лол. Работа тоже связана с ml.
Ух, скорее бы уже Великий родился.
данная хуйня происходит на всех моделях. почему и как фиксить?
Ну, быстрый не формат а лоадер, эксллама что хавает exl2, gptq и оригинальные фп16 - самая быстрая. На втором месте llamacpp с выгрузкой и ее формат gguf. Трансформерс сам по себе не то чтобы медленный, но его просто так никто не юзает из-за потребления памяти.
AWQ чекни с его лоадерами, кто-то даже просил и говорил что его поддержку в эклламе сделают, но маловероятно.
Толи 44 толи 54 слоя на 24 гига влезало, не помню какого кванта, начни с 40 и посмотри потребление. Конттекст и так будет на ней если не отключишь специально.
Это лупы, модель не может быть настолько тупой. Или проблемы с форматом.
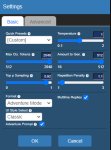
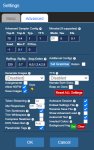
> Это лупы, модель не может быть настолько тупой. Или проблемы с форматом.
спасибо, анончик, а что я сделал не так? я запускаю кобольд с обычными настройками, разве что выставляю clBlast для свей АМД.
топ п вырубай нахрен, ставь 1 на выклвроде, у тебя уже мин-п отсекает все лишнее
> а что я сделал не так?
> для свей АМД.
Кхе-кхе
ну это у него только скорость режет
попробуй скачать релиз для амуде, там же где качал кобальт есть сслыка с рокм версией, должна быть быстрее, если у тебя запустится

вырубил, она продолжает городить стену ебаных описаний, от которых хуй просто залезает назад внутрь меня как змея в нору не обозначая ничего хорошего в этой жизни занимаясь такими грязными злыми делами используя действие которое я только что сделал нажимая на кнопки на компьютере
Тебе нужна 5K_M всегда ее бери если влезает.
Млевда это все таки порномодель. Но она вполне может в sfw ролеплей. Попробуй другие модели. Помни что 20b всегда будет превосходить 13b. Только самые самые выдрочнные 13 будут как средняя 20.
Скинь свой чат с моделькой если не стесняешься.
Помни, что всегда можно подождать пока модель ответит. Стереть ненужное, дописать необходимое и приказать ей продолжить писать ответ. Это вообще лучший способ получить качественный контент. Выглядит правда как будто наоловину с собой общаешься, но мы тут на словари с прикрученными весами дрочим хуле нам.
>попробуй скачать релиз для амуде, там же где качал кобальт есть сслыка с рокм версией, должна быть быстрее, если у тебя запустится
да он только для ЖМУ ПИНУСа, а под винду приходится глБласт использовать.
ну неужели у меня одного такая поебень творится в каждой адвенчурке?
Это уже не лупы, так что проблема уже не в семплере. Видимо сетка стала так отвечать, следуя за твоим форматом. Поиграйся с промптом.
Лупы это повторы слов, или в мягком случае повторы конструкций ответов, или одних и тех же слов в ответах и тд.

> the piss was standing without hands
Обзмеился в голос
кумерская модель
С аполоджайзами там какая-то ерунда с промтом, но вот в лупы v3 загнать вообще как нехуй. В целом у yi проявляется рофловые взаимоисключающие особенности, с одной стороны она куда-то рашит, постоянно пытаясь что-то новое написать, с другой сильно фиксируется на чем-то, упарываясь лупами. Если это обуздать, заставив держать персонажа и двигать сюжет, то все прекрасно, но это тот еще рандом.
Кумить - хз, особенно с левд карточкой неочень, что-то можно на синтии34, но шизы много. Внезапно тесс34-в4 может писать очень крутые кумерские тексты, но только по очень большим праздникам, а после этого в мертвый луп сворачивается. А казалось бы в 2д24м году таких моделей уже и не осталось.
Альфу поставить забыл. Поставишь альфу по инструкции и будет тебе родные 8к на мифомаксе и прочих.

Я понимаю, вот только он не повторы у меня генерит, а вполне осмысленные фразы, но старается набить их блядскими синонимами, втыкая их насколько можно забить фразу.
спасибо, анончик, но у меня 6600xt, а рокм для винды идёт начиная с 6800. я уже пробовал, но нихуя не сработало, даже после отчаяной установки рокма
Шапку читай и ссылки что в ней, там все подробно расписано.
Да, нужно дождаться пока в бывшей поддержку введут и можно попробовать.
> не серят до 100к контекста
Сильное заявление, они и на 1к насрать могут, а более 32к - ошибается. Надо еще ее поведение в зависимости от параметров rope глянуть на малых контекстах.
> левд версия
> а реальный хардкор
Это тебе не левд а какие-то хардкор модели искать нужно. Вообще нормальный промт сделай, убийства и расчлененку направленную на "негативных" персонажей что вводит сетка оно с радостью отыгрывает.
повторы убери в 1, или между 1 и 1.1, как вариант. Если все совсем плохо то 1.2 ставь, поиграй температурой, чуть больше чуть меньше
В принципе есть только 2 вещи с которыми тебе нужно играться в семплерах - температура и повторы. мин-п тоже можешь, но он обычно просто работает на 0.1
Оу че за дичь с интерфейсом? Настройки семплера неоптимальны, но оно не может дать подобных проблем. Где ты вообще тот чат писал, какой там системный промт, что за модель?
бедные виндобляди.... как же им тяжело....
> ну это у него только скорость режет
На каких-то были рофлы с неадекватной генерацией.
Это уже не осмысленные фразы а параша, случаем не "хороший шизосемплинг" выставлен? Тут или отсутствует нормальный системный промт и модель ахуевает что ей в этом странном тексте насовываеть еще, или модель - полная залупа.
> бедные амдауны.... как же им тяжело....
Вот это более релевантно
В main.exe добавили, в server.exe не добавили. Как это тестить без сервера? Ждем кобольда.
там еще релиза в ллама нет?
Настроил. Проверил на таком небольшом промпте, который потом в превратился Dominatrix порно-фанфик.
На персе из Таверны пока не проверял.
Извиняюсь за шок контент на пикче.

>as a futanari girl
так вот какие девочки тебе нравятся, анон?
>Скинь свой чат с моделькой если не стесняешься.
Только что запостил.
Но заскриншотил только один из первых ответов, пока рероллил: то, что было в удачном чате, стыдно показывать...
Стыдливо отводит взгляд и пытается оправдаться:
Это... это была просто такая шутка, анон-кун...
это уже не девочки, это мужики с сиськами
> Помни что 20b всегда будет превосходить 13b.
Не совсем, из-за обилия этих шизомиксов и химер 95% из них - полнейший поломанный шлак, который генерит что-то примерно похожее и уместное контексту, а не разбирают что именно происходит и чего ты хочешь. Хорошие 20б действительно могут, кумить на них лучше чем на 34, если рп простой - и рпшить тоже.
> Только что запостил.
О, отыгрваешь PS и ломаешь 4ю стену, красавчик осудительный фетиш, у приличной девочки ничего не должно выпирать спереди
"Ну тогда приведи пример такой хорошей 20б, раз такой умный!" анон решил воспользоваться реверсионной психологией. Никто не догадается что это такой реквест!
>отыгрваешь PS и ломаешь 4ю стену
Нет, она сама так захотела, я ничего на это не прописывал.
раздумывает дать ли хорошие модели, или назвать спорные варианты "А ты что на них делать будешь? Отыгрывать осудительные вещи, или вообще кого-нибудь обижать?" emerhyst, noromaid, u-amethyst
Все правильно, как она и сказала рассказываешь о ней друзьям чтобы осчастливить.
Нет ну конечно любая модель на любом контексте обосраться может.
У Йи до 100к очень все стабильно, вот дальше уже не очень.
Ты на ней на 100к рпшил, что-то делал с такими контекстами, или судишь по тем тестам?
"Я буду подставляться под глупеньких девонек, чтобы они делали со мной глупые вещи!" Гордо заявил анон, не понимая что за глупость он сказанул Спасибо, у них брать именно классические 20б, потому что у норомейда я вроде как видел толпу экспертов
Не совсем.
Я через ГПТ на основе карточки историю генерил на 80к токенов, потом добавлял ее в карточку и от этого уже РП делал.
>На персе из Таверны пока не проверял
upd:
Проверил. Она за меня мои ответы пишет. Как исправить, что где поменять\убавить?
довольно smirks и nods winks "Желаю хорошо провести время и девочек поумнее" Да, просто 20б. МОЕ может быть тоже ничего, а может наоборот, хз. Норомейда с легкой шизой но интересная, эмерист пригоден для сочетания рп-ерп и обратно, аметиста не пробовал но его много раз хвалили
Интересная тема. Оценивал в общем как оно будет работать в таком режиме, или смотрел насколько учитывает прошлый контекст? История в виде чата-диалога, или просто плейн текст с повествованием?
Алсо тут еще будет работать тема с заготовкой исходного чата на более удачной сетке чтобы та что поглупее брала с нее пример.
Промт, выбери из шаблонов что-нибудь для начала. Если в карточке нет треша то не должна и так.
На что? Сколько ты без таблеток продержишься? Это же мобильный проц. На десктопе точно не будет, потому что RAM очень не любит высокие температуры, она уже при 60+ может начать ошибки сыпать, а для процев норма на 90 работать.
потестил тинилламу в q8 на своей 4 гб мобиле, генерит быстро, около 10 токенов в секунду, в принципе забавно, но сетка тупая
"Спасибо!" Спасибо, ну, попробую все три тогда, там и решу, но тут проблемой может стать использование не самых правильных настроек, потому что у каждой модели они свои, всё таки. Та же Йи по природе своей горячая
А ты уверен что тебе супер проц нужен для ии? Там ддр5 оперативка еще и в 2 канале скорей всего. Он упрется в память, у будет генерить едва греясь нормальные 10-15 токенов в секунду на 7b
Аноны, а что там в инструкцию или в шаблон контекста прописать чтоб было меньше сои?
А то когда отыгрывается цундере - отыгрывается она именно через соевые высказывания про "женщины тоже люди" и "у нас тоже есть права" - ну бред же. А хочетсо чтоб была нормальная цундере.
А то когда отыгрывается цундере - отыгрывается она именно через соевые высказывания про "женщины тоже люди" и "у нас тоже есть права" - ну бред же. А хочетсо чтоб была нормальная цундере.
>или смотрел насколько учитывает прошлый контекст?
Вот это.
История была прям с диалогами, дополнительными персонажами, много разной хрени. Долго от гопоты добивался этого лол
Я б больше сделал, но там уже гопота серить с историей начинала.
В целом практически все нормально вспоминало, можно было спросить про любое событие или предложить встретится с дополнительным персонажем и выдавало норм результат.
> упрется в память
> 10-15 токенов в секунду на 7b
Слишком влажно. На 13900К восемь P-ядер не упираются в ОЗУ, сжирая 150 ватт. И даже на них только 20 т/с получаешь. А на мобильном чипе с TDP в 25 ватт будет 3-5 т/с в лучшем случае.
>Промт
Но я, буквально, просто поздоровался и сказал, что мне сейчас немного грустно.
> выбери из шаблонов
А где из найти?
> На 13900К
А сколько итсов у тебя на 70b моделях?
а ты пробовал указать "цундере как в аниме" или типа того?
Как ты вообще определил для сетки что она должна быть цундере?
Хочешь сказать на ддр5 под 100гбс нет упора в память? Ты точно правильно запускаешь? Попробуй снижать количество ядер и смотри на скорость генерации
> что она должна быть цундере?
> цундере как в аниме"
Ну примерно это в карточку персонажа и записывал вместе со всякими другими пояснениями поведения цундерного по типу чтоб только делала вид что воротит еблет и вообще была достаточно "независимой" и прочее. Тут именно, что иногда пробрасывается соевая хуета, но в 2 из 3х случаев получается довольно неплохо и в целом годно, когда без сои.

спасибо, анончики, я попробую поиграться с параметрами, но дело в том что с самого начала ответы ИИ адекватные, без вот этой мишуры, но чем дальше тем больше, и от неё практически невозможно избавиться. мне показалось дело может быть в том что нейронка начинает зацикливаться на своем собственном стиле повестования. у меня однажды было что она писала конструкции уровня "the red red haired haired girl's" после пятого-шестого упоминания этой red haired girl
Это уже не осмысленные фразы а параша, случаем не "хороший шизосемплинг" выставлен?
Эм, а что это? Я новый ньюфаг вкатывальщик, всего несколько дней марафоню, не знаю ничего.
> Тут или отсутствует нормальный системный промт и модель ахуевает что ей в этом странном тексте насовываеть еще, или модель - полная залупа.
А системный промпт штоето? Модель нормальная, при этом у меня такая мешанина была как на фросте, так и на других модельках. предыдущие скрины с spicyboros-13b-2.2.Q6_K
> Хочешь сказать на ддр5 под 100гбс нет упора в память?
Да. На DDR5 7000+ точно нет упора при 8 ядрах.
> Ты точно правильно запускаешь?
Да, на 7 ядрах падает скорость на 2-3 т/с.
Если там 2 обычных чипа то это кринж по скорости. Если в них много кристаллов и оно хитро разведено то возможно офк, но под такое нужна уже другая подложка а не вялый текстолит.
Забавно, она даже не шизила? С какими параметрами пускал? Возможно рецепт хорошего рп с ними.
Когда пичкал их задачками, после 30-40к там грустнота начиналась, но и сложность была высокой.
В настройках таверны.
> Эм, а что это?
Очень высокая температура и единственный min-p.
> А системный промпт штоето?
Обертка чата, в ней идет первая инструкция о том что это ролплей (или что-то еще), после указывается модели что делать, что вообще происходит, описывается чар и т.д.
>Если в карточке нет треша
Да, точно. Это я сам все поломал: в Scenario прописал, что "это дружеский разговор {{user}} и {{char}}". Я думал она так контекст лучше поймет, но нейросеть восприняла это слишком буквально и получилось, будто меня моя нейросетевая вайфу куколдила со мной же...
а если добавить, что она была воспитана в традициях японског патриархата? Типа ямато надещико. И не знает о всех этих ваших феменизхмах и сжв.
Фроствинд попробуй, не уверен в спициборосе
Интересно, больше ядер нету чтоб добавить?
>Если там 2 обычных чипа то это кринж по скорости. Если в них много кристаллов и оно хитро разведено то возможно офк, но под такое нужна уже другая подложка а не вялый текстолит.
Я думаю там нацеливание на копилота, а там может быть как 3b так и 1b вобще. Этого хватит для приемлимых скоростей для небольших но лююых сеток. Все мелкое летать будет, особенно с их нейроускорителем.

Если только в рамках эксперимента, в конце концов, мне не кажется, что модель вообще знает как выглядит японский патриархат. Да и какая вообще цундере в рамках японского патриархата может быть?
>Очень высокая температура и единственный min-p.
Погоди, проясни по-братски что за единственный min-p и какие вообще примерно настройки нужно ставить.
> Обертка чата, в ней идет первая инструкция о том что это ролплей (или что-то еще), после указывается модели что делать, что вообще происходит, описывается чар и т.д.
В кобольде это первое сообщение?
>оба-сан
оу, тут кто-то любит постарше...
На самом деле там не сильно то и постарше...
> В настройках таверны
Шаблоны это "Text Completion presets"? Их там много. Какой лучше для ролплея подходит? Какой у тебя выбран, анон?
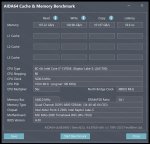
> под 100гбс
110+ с 7200+ мгц можно выжать сейчас. Вот у меня на пониженных частотах, чтоб тайминги/задержка были норм. Сейчас уже в процах больше вопрос, чем в памяти. Ждём когда уже инцел станет ложить больше 8 ядер в проц, от мусорных Е-ядер пользы в нейросетках ноль.
>внучок
>милок
>джентли браш хер вайолет шорт хаирс анд смирк
бггг
но вообще надо будет попробовать тоже, а то че я все на малолетках....
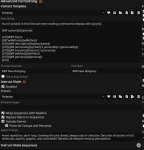
> Я думаю там нацеливание на копилота, а там может быть как 3b так и 1b вобще. Этого хватит для приемлимых скоростей для небольших но лююых сеток.
А зачем все это если обычной памяти тут хватит? Но нацеливание на ии может быть и в вычислительных способностях а не быстрой рам что нужна прежде всего для ллм. Ту же диффузию крутить, например.
Некоторое время назад ввели очередной новый семплер min-p. Его автор хоть и молодец, но страдает расстройствами, из-за чего начал везде его форсить и делать неадекватные сравнения, пытаясь показать то как он хорош.
Шизы подхватили это, уверовав, что отсечка токенов множителем вероятности наиболее вероятного (сама суть этого семплера, читай гайды в шапке) имеет волшебные свойства, и часто рекомендуют выставлять высокую температуру в сочетании с min-p для получения хороших результатов.
Работает это прежде всего с днище-7б, которые пиздец монотонные, и далеко не всегда. Если так сделать на какой-нибудь yi, или других, то можно вообще ахуеть и получить подобную шизофазию.
Айроборос, особенно его 2.х версии, довольно горячий и требует температуры ниже. Хз, его 13б вроде не хвалили.
> В кобольде это первое сообщение?
Там тоже есть карточки, но пусть кто в кобольде шарит подскажет.
Пикрел для начала выстави, это дефолтный шаблон. Потом можешь их затюнить или попробовать те что рекомендуют к моделям.
>что за единственный min-p
Он имеет в виду челиков, которые фигачат температуру на четвёрку, а потом пытаются убрать шизу очень маленьким значением мин-п, сэмплера, который оставляет только токены с вероятностями больше x*(вероятность максимально вероятного токена). Это не твой случай, у тебя там на скриншоте температура единица, и мин-п 0.1, что норм. Как другой анон написал, настройки сэмплеров там вроде не прям ужасные. Единственное, что топ-а 0.4 слегка великоват, он будет резать в большинстве случаев больше, чем мин-п 0.1, можешь попробовать его выключить (поставить на ноль).
Там уже не просто ядра добавляют, полноценный нейоускоритель NPU работающий вмксто/вместе с процессором.
И дает он так же или больше чем все ядра процессора, ибо специализированный ускоритель всегда лучше. Так что думаю ноутбучные ддр5 вполне упрутся в память с нейроускорителем и не тухлыми ядрами современного процессора. Там ведь может быть как 1 канал на 40гбс так и 2 едва достигающих 70-80гбс.
Он имеет в виду челиков, которые фигачат температуру на четвёрку,
Ну ну ты пизди да не заговаривайся, на мин-п либо температуру 1 оставляют либо 1.5, редко кто выше
>Работает это прежде всего с днище-7б, которые пиздец монотонные, и далеко не всегда.
Везде работает и легко заменяет другие семплеры отсечки, никогда с ним проблем не было ни с одной сеткой
Главное верить, плацебо и не такие чудеса творит. А под треш можно и подстроиться, отредактировать если что.
>Пикрел для начала выстави, это дефолтный шаблон
Спасибо. Забыл про эту вкладку.
>на мин-п либо температуру 1 оставляют либо 1.5
Я понимаю, что по факту так делают, просто описал заведомо бредовый случай. По-моему, значение температуры в четвёрку мелькало в тестах в том посте на реддите. Не думаю, что кто-то реально настолько сильно прожаривает, хотя кто знает, конечно.
>Я понимаю, что по факту так делают, просто описал заведомо бредовый случай.
Там был просто тест, показывающий что модель продолжает работать даже с такой температурой с мин-п.
Причем температуру 4 ставят еще и для того что бы включить на модовом кобальте режим динамической температуры, и там вобще по другому температуру начинает считать.

> полноценный нейоускоритель NPU
Это всё кал собаки индуса. Это говно только под OpenVINO будет работать, поддержки квантов нет, прирост обещают аж в 2.5 раз, но по графикам от самого же инцела оно мобильную амуду всего на 1.2-1.7 обходит. Как видишь на пикрилейтеде, NPU даже хуже встройки, лол. Под десктоп пока нихуя нет и не показывали что будет что-то.
А где тут текущее поколение процессоров? Может там чет другое сделали.
Ну и опять же, копилот и другие их нейросети, что в паинте что еще где.
Корпы подстроятся под юзеров, у которых большинство - будет новыми интелами с определенным NPU. Там и локальщики могут перейти на новый формат, почему нет.
Мне кажется или обычный проц общего назначения будет летать не хуже всяких npu если ему запилить широкую hbm2 память и аппаратную поддержку чисел разрядностью меньше 16 бит?
анончик, спасибо большое за прояснения, добра тебе.
и тебе огромное спасибо, больше нигде никто нихуя в интернетах не проясняет.

Гугл по имени Оба-сан выдаёт вот эту пенсионерку. Не знал, что деды второй мировой могут в нейросети
Ну вот ддр5 рядом с процессором и пытаются дать шире канал, только из-за нейросеток думается, ну и частоты выше можно задрать.
Но все таки куча параллельных ядер пизже чем просто обычные общие ядра. Поэтому и сделали отдельный NPU который и будет пользоваться этой широкой и быстрой рам
Это виабушное слово для бабушек

>внучок
>милок
>джентли браш хер вайолет шорт хаирс анд смирк
Анд афтер дэт щи виспер седактивли:
оба-сан это не имя.
Это буквально переводится как "бабуля"
иногда в аниме так еще шоты называют взрослых теток от 30
>Анд афтер дэт щи виспер седактивли:
КУДА ИЗ АУТ ОФ МЕМОРИ
Неистово потерпел поражение!
Чтож ты делаешь, содомит!
щиверс раннинг тру ёр спайн
>потому что RAM очень не любит высокие температуры, она уже при 60+ может начать ошибки сыпать
Ох, лол.
У тебя рам разогнаная до нестабильности или удроченная просто, может с питальником проблемы.
> а для процев норма на 90 работать.
Нет. Под такой температурой у процев медленно вытекают остатки флюса, обгорает кристалл и подложка.
Хорошая температура не может быть больше 70.
Есть 4090 и 13600 и5. Какую модель лучше взять?
А оперативы сколько?
С 20 б начни.
В 4090 влезет yi34 в формате gptq, самая стабильная из умных - yi34v3.
>лупы и аполоджайзы
холосий луське лаовай, холосий
полусяесь две миска лис от палтия и нейлонный кошкажена
Наверно не стоит неофиту yi советовать, она очень капризная и может только оттолкнуть. 20б вполне сойдет.
> лис от палтия и нейлонный кошкажена
Они плоховато их отыгрывают
>лупы и аполоджайзы
Они все такие и даже хуже. Но это можно компенсировать выдрачиванием настроек.
>полусяесь две миска лис от палтия и нейлонный кошкажена
Вот бы партия подогнала бы мне пару пеладанов 4090 для кошкожена.
>не стоит неофиту yi советовать
Хз, может быть он насвайпает пару охуенных диалогов и захочет больше и больше, а может и оттолкнёт его, да.


анон-нубасос снова влетает в тред с вопросом.
почему пикрел?
почему пикрел?
А ты ворлд инфо в кобальде добавляешь, а генеришь на таверне что ли? Ну и да, глянь ты на вики кобальда как это работает
>пару пеладанов 4090
почитал.
Интересно. А чё, они только для внутреннего рынка?
Кучеряво живут блин простые китайцы.
32 гб.
А какую именно?
Спасибо.
>А чё, они только для внутреннего рынка?
Вроде бы они какое-то время заполонили алиекспресс и таобао.
>Кучеряво живут блин простые китайцы.
Как бы сказать. Там чипы из под пола или со сгоревших карт.
Это как хуанан, мощно, но для ценителей иногда надо поебаться с этими платами.
Что кучерявого в оверпрайснутой турбинной версии? Офк кроме удобного размещения рядом друг с другом.
-
> 32 гб.
Эх, на 70б не хватит.
Крч, тогда используй MLewd-ReMM-L2-Chat-20B в гптq на exllama2 или как анон выше говорил юйка и её файнтюны 34б 4бита в гптq должны залезть в 24 гига по типу deepsex-34b-GPTQ_gptq-4bit. Кста, сама yi-34B-v3 у меня в гптq шизила.
Типа в gguf было норм? Какой квант пробовал? Можно офк проверить, но обычно происходят наоборот с жорой проблемы. v3 gptq в ролплее не шизила и отвечала адекватно-уместно знатно она юзера может приложить, прям ультит, но склонна к лупам.

>MLewd-ReMM-L2-Chat-20B
А как понять, в чем разница этих буков? Тут полно версий же.
Че за yi v3? Базовая, даже не файнтюн и dpo?
Чем больше цифра тем качественнее, тебе и 5km-6к хватит, можешь хоть 8q скачать, если память есть и не против более медленной но чуть более качественной генерации
Методы сжатия весов с потерей данных.
Чем больше буква и размер файла тем умнее нейросеть и лучше её словарный запас.
Зависимость перплексити от весов нелинейная: разница между Q2_k и Q3_K_M аххуеть какая большая, а вот между 6 и 8 уже почти не заметно.
По буквам уже пояснили, с норм контекстом в 24гб поместится только q3km q4ks, может больше. При этом они вполне юзабельны а не лоботомированы. Gptq более качественный будет, можно самостоятельно в ~6бит exl2 квантануть или найти готовую, они с 8к контекста в 24 помещаются.
https://huggingface.co/TheBloke/yi-34B-v3-GPTQ
Гуф не пробовал, только gptq.
>Какой
yi-34B-v3-GPTQ_gptq-4bit-128g
Кажется качал 32 группы, но это не точно. Она сама по себе несколько припезднутая, сложных чаров смогла отыграть, а кумбота порядочную девочку с намеком на левд - нет. Имплаит какую-то хуету и навязчивые идеи.
А что у нее по ответам? Чем лучше той же Nous-Hermes-2-Yi-34B? Допускаю что ноус соевый, но он вроде и умный заодно. v3 чем лучше то, сои нет?
Хрена вы накотали. Это из-за цензуры на хайгинфейсе?
Короче ПЕРЕКАТ
Короче ПЕРЕКАТ
> У тебя рам разогнаная до нестабильности или удроченная просто
Ты видимо никогда не видел нормальную DDR5, оверклокеры даже воду на плашки ставят, чтоб брать частоты повыше. Если при 45 разогнанная память стабильная, то на 60 уже будет сыпаться. Либо конечно можно сидеть на ватных XMP.
> Под такой температурой у процев медленно вытекают остатки флюса, обгорает кристалл и подложка.
Вот это точно лол. Потому что какой-нибудь 13900 в стоке под воздухом будет троттлить, так же как и амуда 7900Х. Под водой с трёхсекционкой сможешь их около 90 держать. Под полной нагрузкой только мобильные чипы при 70-80 градусах будут работать.
>нормальную DDR5
>при 45 разогнанная память стабильная, то на 60 уже будет сыпаться
Спасибо, проорал немного с современных железок.
>
> Потому что какой-нибудь 13900 в стоке под воздухом будет троттлить, так же как и амуда 7900Х.
>Под водой с трёхсекционкой сможешь их около 90 держать.
>Под такой температурой у процев медленно вытекают остатки флюса, обгорает кристалл и подложка.
Нахуй так жить.... Спасибо за инфу.

>чтоб брать частоты повыше
Спасибо Лизе за то, что выше 6 кеков не нужно.
>амуда 7900Х. Под водой с трёхсекционкой сможешь их около 90 держать
Парочка волшебных настроек, и говно пикрил выше 80-ти гнать не будет.
Пасаны я такой кумпромт придумал охуеть. Теперь сижу как лесополосный в пятницу ногой трясу, страсть как хочется добраться до дома и сетей. Почему-то лучшие промты приходят перед сном прямо, я даже записку в телефоне завел под них чтобы не забывать.

Мейды-хуейды... Понаклипают сортов порно-рп говна, обязательно с прикреплёнными анимешными девочками в описании для привлечения виабуговна малолетнего и радуются, а король как сидел на троне так и сидит уже который месяц.
Ботоводам Сап. Вкатился недавно, скачал всё по вашим гайдам. Но вот дела какие:
Модель которую я скачал (из гайда) отвечает мне "привет и тебе" на мой привет примерно минуты 3.
При этом у меня 3060ti, 16гб очень быстрой озу и i510400.
Я что-то делаю не так или это норма на моём конфиге?
Модель которую я скачал (из гайда) отвечает мне "привет и тебе" на мой привет примерно минуты 3.
При этом у меня 3060ti, 16гб очень быстрой озу и i510400.
Я что-то делаю не так или это норма на моём конфиге?
Нет, первое сообщение он может подлагнуть, просчитывая БЛАС, но это занимает секунд десять, а последующие сообщения вообще мгновенные. Юзаешь кобольд? Моделька фроствинд? Какое квантование? Какой BLAS выбрал, не openBLAS, надеюсь? Дровишки на видимокарту обновил?
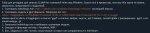
я тупой и только пытаюсь вкатиться так что сильно не обоссывайте.
из всего многообразия ии я немного потыкал в дворника и еще посидел на эроген аи. к слову он мне и зашел больше всего. развернув подобную хуету у себя на пеке я смогу получить что то +- похожее? ну и где брать персов и как это вообще работает
из всего многообразия ии я немного потыкал в дворника и еще посидел на эроген аи. к слову он мне и зашел больше всего. развернув подобную хуету у себя на пеке я смогу получить что то +- похожее? ну и где брать персов и как это вообще работает

на удивление я справился только есть пару вопросов.
1. при генерации ответа он грузит цп ровно до 70% можно как то отдать ему больше ресурсов?
2. я даже хз как сформульровать внятно. как превратить этот ии в няшную милфу?
3




Здесь мы делимся рецептами запуска, настроек и годных промтов, расширяем сознание контекст, и бугуртим с кривейшего тормозного говна.
Тред для обладателей топовых карт NVidia с кучей VRAM или мажоров с проф картами уровня A100, или любителей подождать, если есть оперативная память. Особо терпеливые могут использовать даже подкачку и запускать модели, квантованные до 8 5 4 3 2-х бит, на кофеварке с подкачкой на микроволновку.
Базовой единицей обработки любой языковой модели является токен. Токен это минимальная единица, на которые разбивается текст перед подачей его в модель, обычно это слово (если популярное), часть слова, в худшем случае это буква (а то и вовсе байт).
Из последовательности токенов строится контекст модели. Контекст это всё, что подаётся на вход, плюс резервирование для выхода. Типичным максимальным размером контекста сейчас являются 2к (2 тысячи) и 4к токенов, но есть и исключения. В этот объём нужно уместить описание персонажа, мира, истории чата. Для расширения контекста сейчас применяется метод NTK-Aware Scaled RoPE. Родной размер контекста для Llama 1 составляет 2к токенов, для Llama 2 это 4к, но при помощи RoPE этот контекст увеличивается в 2-4-8 раз без существенной потери качества.
Текущим трендом на данный момент являются мультимодальные модели, это когда к основной LLM сбоку приделывают модуль распознавания изображений, что в теории должно позволять LLM понимать изображение, отвечать на вопросы по нему, а в будущем и манипулировать им.
Основным представителем локальных моделей является LLaMA. LLaMA это генеративные текстовые модели размерами от 7B до 70B, притом младшие версии моделей превосходят во многих тестах GTP3 (по утверждению самого фейсбука), в которой 175B параметров. Сейчас на нее существует множество файнтюнов, например Vicuna/Stable Beluga/Airoboros/WizardLM/Chronos/(любые другие) как под выполнение инструкций в стиле ChatGPT, так и под РП/сторитейл. Для получения хорошего результата нужно использовать подходящий формат промта, иначе на выходе будут мусорные теги. Некоторые модели могут быть излишне соевыми, включая Chat версии оригинальной Llama 2.
Кроме LLaMA для анона доступны множество других семейств моделей:
Pygmalion- заслуженный ветеран локального кума. Старые версии были основаны на древнейшем GPT-J, новые переехали со своим датасетом на LLaMA, но, по мнению некоторых анонов, в процессе потерялась Душа ©
MPT- попытка повторить успех первой лламы от MosaicML, с более свободной лицензией. Может похвастаться нативным контекстом в 65к токенов в версии storywriter, но уступает по качеству. С выходом LLaMA 2 с более свободной лицензией стала не нужна.
Falcon- семейство моделей размером в 40B и 180B от какого-то там института из арабских эмиратов. Примечательна версией на 180B, что является крупнейшей открытой моделью. По качеству несколько выше LLaMA 2 на 70B, но сложности с запуском и малый прирост делаю её не самой интересной.
Mistral- модель от Mistral AI размером в 7B, с полным повторением архитектуры LLaMA. Интересна тем, что для своего небольшого размера она не уступает более крупным моделям, соперничая с 13B (а иногда и с 70B), и является топом по соотношению размер/качество.
Qwen - семейство моделей размером в 7B и 14B от наших китайских братьев. Отличается тем, что имеет мультимодальную версию с обработкой на входе не только текста, но и картинок. В принципе хорошо умеет в английский, но китайские корни всё же проявляется в чате в виде периодически высираемых иероглифов.
Yi - Неплохая китайская модель на 34B, способная занять разрыв после невыхода LLaMA соответствующего размера
Сейчас существует несколько версий весов, не совместимых между собой, смотри не перепутай!
0) Оригинальные .pth файлы, работают только с оригинальным репозиторием. Формат имени consolidated.00.pth
1) Веса, сконвертированные в формат Hugging Face. Формат имени pytorch_model-00001-of-00033.bin
2) Веса, квантизированные в GGML/GGUF. Работают со сборками на процессорах. Имеют несколько подформатов, совместимость поддерживает только koboldcpp, Герганов меняет форматы каждый месяц и дропает поддержку предыдущих, так что лучше качать последние. Формат имени ggml-model-q4_0, расширение файла bin для GGML и gguf для GGUF. Суффикс q4_0 означает квантование, в данном случае в 4 бита, версия 0. Чем больше число бит, тем выше точность и расход памяти. Чем новее версия, тем лучше (не всегда). Рекомендуется скачивать версии K (K_S или K_M) на конце.
3) Веса, квантизированные в GPTQ. Работают на видеокарте, наивысшая производительность (особенно в Exllama) но сложности с оффлоадом, возможность распределить по нескольким видеокартам суммируя их память. Имеют имя типа llama-7b-4bit.safetensors (формат .pt скачивать не стоит), при себе содержат конфиги, которые нужны для запуска, их тоже качаем. Могут быть квантованы в 3-4-8 бит (Exllama 2 поддерживает адаптивное квантование, тогда среднее число бит может быть дробным), квантование отличается по числу групп (1-128-64-32 в порядке возрастания качества и расхода ресурсов).
Основные форматы это GGML и GPTQ, остальные нейрокуну не нужны. Оптимальным по соотношению размер/качество является 5 бит, по размеру брать максимальную, что помещается в память (видео или оперативную), для быстрого прикидывания расхода можно взять размер модели и прибавить по гигабайту за каждые 1к контекста, то есть для 7B модели GGML весом в 4.7ГБ и контекста в 2к нужно ~7ГБ оперативной.
В общем и целом для 7B хватает видеокарт с 8ГБ, для 13B нужно минимум 12ГБ, для 30B потребуется 24ГБ, а с 65-70B не справится ни одна бытовая карта в одиночку, нужно 2 по 3090/4090.
Даже если использовать сборки для процессоров, то всё равно лучше попробовать задействовать видеокарту, хотя бы для обработки промта (Use CuBLAS или ClBLAS в настройках пресетов кобольда), а если осталась свободная VRAM, то можно выгрузить несколько слоёв нейронной сети на видеокарту. Число слоёв для выгрузки нужно подбирать индивидуально, в зависимости от объёма свободной памяти. Смотри не переборщи, Анон! Если выгрузить слишком много, то начиная с 535 версии драйвера NVidia это серьёзно замедлит работу. Лучше оставить запас.
Гайд для ретардов для запуска LLaMA без излишней ебли под Windows. Грузит всё в процессор, поэтому ёба карта не нужна, запаситесь оперативкой и подкачкой:
1. Скачиваем koboldcpp.exe https://github.com/LostRuins/koboldcpp/releases/ последней версии.
2. Скачиваем модель в gguf формате. Например вот эту:
https://huggingface.co/TheBloke/Frostwind-10.7B-v1-GGUF/blob/main/frostwind-10.7b-v1.Q5_K_M.gguf
Можно просто вбить в huggingace в поиске "gguf" и скачать любую, охуеть, да? Главное, скачай файл с расширением .gguf, а не какой-нибудь .pt
3. Запускаем koboldcpp.exe и выбираем скачанную модель.
4. Заходим в браузере на http://localhost:5001/
5. Все, общаемся с ИИ, читаем охуительные истории или отправляемся в Adventure.
Да, просто запускаем, выбираем файл и открываем адрес в браузере, даже ваша бабка разберется!
Для удобства можно использовать интерфейс TavernAI
1. Ставим по инструкции, пока не запустится: https://github.com/Cohee1207/SillyTavern
2. Запускаем всё добро
3. Ставим в настройках KoboldAI везде, и адрес сервера http://127.0.0.1:5001
4. Активируем Instruct Mode и выставляем в настройках пресетов Alpaca
5. Радуемся
Инструменты для запуска:
https://github.com/LostRuins/koboldcpp/ Репозиторий с реализацией на плюсах
https://github.com/oobabooga/text-generation-webui/ ВебуУИ в стиле Stable Diffusion, поддерживает кучу бекендов и фронтендов, в том числе может связать фронтенд в виде Таверны и бекенды ExLlama/llama.cpp/AutoGPTQ
Ссылки на модели и гайды:
https://huggingface.co/TheBloke Основной поставщик квантованных моделей под любой вкус.
https://rentry.co/TESFT-LLaMa Не самые свежие гайды на ангельском
https://rentry.co/STAI-Termux Запуск SillyTavern на телефоне
https://rentry.co/lmg_models Самый полный список годных моделей
http://ayumi.m8geil.de/ayumi_bench_v3_results.html Рейтинг моделей для кума со спорной методикой тестирования
https://rentry.co/llm-training Гайд по обучению своей лоры
https://rentry.co/2ch-pygma-thread Шапка треда PygmalionAI, можно найти много интересного
https://colab.research.google.com/drive/11U-bC6AxdmMhd3PF9vWZpLdi6LdfnBQ8?usp=sharing Последний известный колаб для обладателей отсутствия любых возможностей запустить локально
Шапка треда находится в https://rentry.co/llama-2ch (переезжаем на https://2ch-ai.gitgud.site/wiki/llama/ ), предложения принимаются в треде
Предыдущие треды тонут здесь: