


Новый день - новый тред
В тех 2.5? Эффект падения/роста скорости легко показать деля на несколько карточек модель, что может поместитсья на одной, и сравнивая скорости. Анон в парой P40 показал что даже с x4 2.0(!) на двух картах скорости почти так же что на одной. Пусть уточнит если что.
Перфоманс там скейлится почти линейно в зависимости от размера модели.
Алсо
> где народ хвастается высокой скоростью
на 70б заявляются скорости выше чем на 34б, да такие что это даже больше половины перфоманса 3090 в более эффективном режиме. А с ней они не сопоставимы ни по перфомансу чипа, ни по псп врам.
Такого можно достичь только если используются какие-то оптимизации или когда ты пиздабол и этими картами торгуешь. Шина сама по себе тут не при чем будет.
А что если наебать систему и взять несколько P40 P100 4060ti 16gb? Считай по вычислительной мощности = 4090, но врама х2, а стоит в 2 раза дешевле. Думойте.
Посоветуйте 70b, которая хорошо работает из коробки в sillytavern, заебался ковырять шаблоны контекста что-бы понять какой лучше.
>Считай по вычислительной мощности = 4090
А мужики то не знают.
> по вычислительной мощности = 4090, но врама х2, а стоит в 2 раза дешевле
Если бы был легкий способ сложить вычислительную мощность консумерских видеокарт при запуске ллм - был бы крутой вариант. В текущих реализациях они работают по очереди, считай то же самое что одна 4060ти но с увеличенным объемом памяти.
В прошлом треде советовали 70.
> которая хорошо работает из коробки в sillytavern
Все они работают с ролплей шаблоном, он в принципе универсален, а 70б менее требовательны к формату.
А так вообще подбирать модель под шаблон - всеравно что автомобиль под резину.
>Если бы был легкий способ сложить вычислительную мощность консумерских видеокарт при запуске ллм - был бы крутой вариант. В текущих реализациях они работают по очереди, считай то же самое что одна 4060ти но с увеличенным объемом памяти.
А это точно хуже чем собирать всякую экзотику типа P40 на помойке которую ещё и хуй охладишь нормально?
Пара 4060ti@16 под 34б - норм тема, возможно влезут франкенштейны 56б и всякие МОЕ. Но по деньгам выйдет раз в 5 дороже чем одна P40. По скорости - если сравнивать по редким данным что выкладывали и масштабировать - в llamacpp на 34б будет менее 10т/с, это далеко не в 5 раз быстрее. Колхоз всеравно будет, ведь две видюхи, но более юзер-френдли офк.
Чем больше карточек собираешь для таких пусков ллм, тем менее это выгоднее.
Да, жоповато выходит.
А какие шансы увидеть в будущем A6000 на барахолке?
Высокие офк, они уже там появляются. Правда цена негуманная и вопрос ушатанности/живости, запечатанные стоят как ррц. Если вдруг хуанг решил сделать в 5к серии 48гб врам или выпустить титан с ними, и цена будет не выше 3-4к, то будет их наплыв и удешевление.
Можешь прямо сейчас взять пару 3090, на барахолках стоят чуть дороже чем 4060@16. Для всего кроме обучения крупных моделей их будет хватать, алсо там даже нвлинк есть, что может где-то сыграть если использовать.
База везде.
Да ты угараешь, один уже нес такую же херню в прошлом треде!
Дороже вдвое-втрое, как минимум.
Ну, P40 тоже стоит брать не одну, а две, тогда уж. =)
Ну, типа, со всеми кэшбеками и промиками скок там выходит, 25к за одну 4060ти, это 75 тыщ за 3 штуки (16+16+16=48). а 2 P40 будут стоит 32~35 тыщ.
Ну, в 2,5 раза, таки да.
Вряд ли Хуанг так решит сделать.
>ряд ли Хуанг так решит сделать.
Спорное утверждение. Так-то Хуангу выгодно обесценивать старые карточки, чтобы гои шли покупать новые по оверпрайсу.
Хотя это игра в рулетку.
> 25к за одну 4060ти
Шо, опять там зеленый банк ультит своими наебаллами?
Ну за условные 75 это вполне себе вариант офк, хотя 3я лишняя.
> Вряд ли Хуанг так решит сделать.
> Спорное утверждение
Кто же его знает. С одной стороны тут желание привлечь больше клиентов новой темой и укрепить доминирование. С другой, у них и так все хорошо, карточки сметают и внутренний каннибализм, а тем более конкуренция их профессиональным решениям - нахер не сдалась. Что перевесит - сложно сказать, возможен еще компромисс с 32-36 гигами.
И с какой скоростью будут работать эти 4060ти?
Емнип в треде аноны с р40 пруфали, что у них нет потерь производительности от соединения видеокарт, а владельцы 30ХХ и 40ХХ жаловались на потерю производительности в эксламе.
Емнип в треде аноны с р40 пруфали, что у них нет потерь производительности от соединения видеокарт, а владельцы 30ХХ и 40ХХ жаловались на потерю производительности в эксламе.
> в эксламе
С ней как всегда все отлично. Проблемы только с жорой, оно само как-то пытается шарить по дефолту и сильно замедляет. Учитывая что у жоры нет преимуществ - нет и мотивации искать истинную причину.
Понятно. Спасибо.
Может быть это все просто шиндопроблемы, ведь тесты P40 что мы видели делались на линуксах, где нет многих приколов и все работает из коробки. Когда сойдутся звезды проверю эту и другие гипотезы.
Ну, если равнять 48 гигов к 48. =) Три 4060ти против двух П40. Лишняя по размеру, но по памяти лишних не бывает.
Очевидно, что со скоростью чуть ниже одной 4060ти, но вот вопрос — с какой скоростью работает она? :) Никто так и не потрогал, кек.
Кто нибудь уже тестировал новую WestLake v2?
По тестах пиздец много обещающая.
По тестах пиздец много обещающая.
Бля, вы так говорите за 4060ти тут...
Что, внатуре стоит эту 128 бит шляпу брать?
Я бы хотел 4070ти супер новую, но денег сильно не хватает.
Что, внатуре стоит эту 128 бит шляпу брать?
Я бы хотел 4070ти супер новую, но денег сильно не хватает.
Для llm объём vram важнее всего остального. Для других задач сам смотри, насколько тебе важно.
Ну это понятно. Но скорость памяти тоже важна, не?
Да.
Вброшу про 4060, у которой память медленнее Р40...
Нет.
Если модель полностью в vram, ты в принципе на любой современной видимокарте получишь приемлемую скорость (выше скорости чтения). Больше памяти - больше модель или больше контекста сможешь загрузить. Ну только если тебе принципиально, чтобы было условные 50 Т/с вместо 30 на мелких тупых моделях (при том, что читаешь ты уж точно не выше 10, а скорее даже и 5, как бы ни торопился), то да, скорость важна.
Если оффлоадить, то узким местом в любом случае станет cpu, и опять чем больше поместится в vram, тем лучше.
Если покупать несколько gpu, опять же, чем меньше их будет (чем больше памяти на каждом), тем лучше.
Короче, при любом раскладе параметр vram/$ для llm является наиболее важным.
> выше скорости чтения
Для дедов, уже 15+ лет по 12+ часов в день только и занимающихся скорочтением от книг до скролинга интернетов и работки, даже 20 т/с мало, потому что уже есть навык литералли читать построчно, а не по словам. Это сложно описать, но ты как бы запоминаешь как выглядит строчка текста, а мозг сам парсит все слова одновременно и выдаёт смысл в башку. По словам только свой написанный текст перечитываешь, чтоб не проебаться в потоке мыслей.
ты не боишься старости?
я так же накину, что два PCIe x16 в потребительском сегменте встречаются довольно часто, а вот три PCIe x16 - уже охуеть редкость. Так что три плюсуйте еще новую материнку к стоимости и блок питания дохуя. Мне под мои 2 p40 пришлось покупать киловатник, а знаете сколько они стоят сейчас? Минимум 13к.
Реально что-то дорогова-то общая сборка выходит, а так хотелось 3 4016
Анончики, а есть где-то вменяемый гайд по P40?
Ну например: Какие дрова ставить? Норм ли на винде или нужен линукс обязательно? Что конкретно можно запустить и как? Угабога например при установке спрашивает про граф. процессор, с P40 устанавливать как NVidia? А лоадеры все работают или только llama.cpp? Что по скоростям на 7,13,20,30,70В?
Ну например: Какие дрова ставить? Норм ли на винде или нужен линукс обязательно? Что конкретно можно запустить и как? Угабога например при установке спрашивает про граф. процессор, с P40 устанавливать как NVidia? А лоадеры все работают или только llama.cpp? Что по скоростям на 7,13,20,30,70В?
По спекам одна P40 потребляет максимум 250 Ватт. В майнерские времена у меня две 280x (тоже по 250 Ватт) сидели на БП 750 Ватт. БП Корсар до сих пор живой и перекочевал в новый комп.
>P40 потребляет максимум 250 Ватт
Когда там уже чиплетная архитектура, я заебался. Хуйня жрёт энергии, как две р40, а памяти, как у половины.
>я так же накину, что два PCIe x16 в потребительском сегменте встречаются довольно часто, а вот три PCIe x16 - уже охуеть редкость.
Толку-то с тех слотов, если они не от процессора. И даже такие потребительские материнки с двумя слотами уже встречаются очень редко. Я так понял, сейчас производители делают ставку на первый слот, которому отдают всю производительность - все 16 линий PCIe 4 или 5 версии. А остальные слоты просто для красоты. Более того, с БП та же фигня - все новые БП делают с разъёмом 12VHPWR под одну мощную видяху. А если хочешь 3-4, то этого тупо не предусмотрено.
> 4070ти супер новую
Она лучше чем 4060 офк, но ничего считай не влезет. 20б в суб 4 битах только. Так по перфомансу она как 3090, только памяти меньше и в пару большие модели не влезут.
Да, но даже то что считается днищем по меркам видюх - уже достаточно для быстрой работы.
Чаю этому господину.
> скорочтением
Это для быстрой оценки "свайп-не свайп", а потом всеравно уже основательно вчитываться, вникать и т.д.
> два PCIe x16 в потребительском сегменте встречаются довольно часто
Да ладно, покажешь ссылок на такое? В десктоп профессорах линий не больше 20 а даблеры, казалось, перестали ставить уже больше десятка лет (и не факт что будут эффективны вообще).
> еще новую материнку
Всю платформу, которая современная выйдет страшно дорого. Только некрозеоны с брендовыми/серверными платами, ибо в большинстве китайских перестали нормально линии дополнительные распаивать.
> знаете сколько они стоят сейчас? Минимум 13к
Ахуеть, более мощную платинувую йобу не так давно дешевле можно было купить
Больше VRAM выйдет неизбежно дороже, даже если тупо добавить стоимость чипов. А ГЕЙмеры всякие будут в недоумении нахрена им переплачивать за лишнюю память. Вот если бы было наподобие конструктора, где можно вставить больше памяти... эх.
Мне вот интересно, а потребительские нейроускорители хотя бы в проекте есть? Или только колхоз?

>если бы было наподобие конструктора
Мощный стержень Xi вставлять много мозги в кожаные карта.
Обосрался, это вообще как?
> даже если тупо добавить стоимость чипов
На 10-20-30%, но никак не в 2-3 раза. Тут вопрос исключительно в окучивании тех, кто готов за такое платить.
Хуанг уже напрямую заявляет что его карточки - не только про игры, а вполне себе ии ускорители. У гей_меров так вообще мантра на нейронное сжатие текстур.
Прецедент, 2080ти на 44 и 3090 на 48 случаем нету там?

Санкции на импорт ускорителей, вот у них там вовсю пошло дело с рефабами. Тонкие серверные 3090\3090ti с турбиной в наличии. Пока что актуально, а значит, и дорого. Хотя баксов на 200 уже подешевело с появления.
>Прецедент
Это началось ещё со старых rx в майнинг, когда удваивали с 8 до 16.
>случаем нету
Нету. Нихуя нету. Магазин вообще видимокарточки не продаёт.
Нвидию нагнули и запретили продавать 4090 в Китай, чтоб без кума годного они там загнулись.
Китайцы на фоне этого начали ебашить каких попало франкенштейнов.
Там реально сейчас фабрики работают по перепайке видях под LLM.
> по перепайке видях под LLM
Вут? Колхозный рефаб был давно, а по замене чипов больше единичные сообщения и то только со скринами из гпу-з вместе с жалобами что больше дефолтного не может выделить и использовать.
> нагнули и запретили продавать 4090 в Китай
Вообще у них там своя версия 4090 уже продается и вполне успешно. На гите, обниморде и прочем можно увидеть много нытья в ишьюсах со скринами 4...8x 4090 из nvidia-smi. Во многих их модельках уже прямым текстом указывается не количество видеопамяти а количество 24-гиговых карточек для обучения/взаимодействия.

>с жалобами что больше дефолтного не может выделить и использовать
Это какая-то совсем паль. Даже кустари делают так, что всё может и выделяет, прирост значительный. Но, конечно, всегда есть контроллер памяти, который может не переварить возросшие требования к пропускной способности.
Кстати, почему exlama работает медленно (медленнее lamacpp), показывает загрузку гпу 100%, но при этом энергопотребление низкое?
Такое ощущение, что данные нейросети не успевают своевременно доезжать до cuda блоков.
>Только некрозеоны с брендовыми/серверными платами, ибо в большинстве китайских перестали нормально линии дополнительные распаивать.
Двухпроцессорные хуананы пошли особым путём: на одном проце висит 2x16 и на втором 1x16.
А вообще нормальные люди уже хоронят 2011-3 и покупают epyc 7551p, куда лучше и не сильно дороже. Сам бы так сделал, если бы не двухсокетный Хуанан, который купил пару лет назад.
Такое ощущение, что данные нейросети не успевают своевременно доезжать до cuda блоков.
>Только некрозеоны с брендовыми/серверными платами, ибо в большинстве китайских перестали нормально линии дополнительные распаивать.
Двухпроцессорные хуананы пошли особым путём: на одном проце висит 2x16 и на втором 1x16.
А вообще нормальные люди уже хоронят 2011-3 и покупают epyc 7551p, куда лучше и не сильно дороже. Сам бы так сделал, если бы не двухсокетный Хуанан, который купил пару лет назад.
> почему exlama работает медленно...
Это я про P40.
Анончики, что там для работы с ру текстом сейчас лучшее?
модуль гугл транслятор
Not bad
Рабочих тестов буквально единицы, полно вариантов где апгрейдят версии с малой памяти на большую, но просто перепайка чипов на большие куда сложнее. Хотя у амперов биос взламывали, шансы велики.
> почему exlama работает медленно (медленнее lamacpp), показывает загрузку гпу 100%, но при этом энергопотребление низкое?
Паскаль не поддерживают операции с низкой битностью и оно где-то в них затыкается, видимо. В фп16 мелочь не пробовал запустить?
> Двухпроцессорные хуананы пошли особым путём: на одном проце висит 2x16 и на втором 1x16.
Вроде не самый плохой вариант, только с нумой могут вылезти приколы. Не сравнивал результаты когда карты на одном проце и на разных?
> epyc 7551p
Первый зен - ну хуй знает даже, они буквально 2011 зеонам сливали и не вывозили периферию. Хз как себя покажет.
>Вроде не самый плохой вариант, только с нумой могут вылезти приколы. Не сравнивал результаты когда карты на одном проце и на разных?
Попытался стакануть p40 и 1070 на разных процах на винде. Nvidia-smi их видело, системный софт винды тоже, а вот обабога взбугуртил от перекидавания железа, ругался, что драйвер cuda не походит к питорчу и подобное.
Уверен, оно бы работало после перенакатывания дров и обабоги с нуля, но я подзабил.
Уверен, что чел с сервачком из 6х P40 на реддите тоже включал их через нуму, а иначе бы голиаф не работал так шустро.
>Паскаль не поддерживают операции с низкой битностью и оно где-то в них затыкается, видимо. В фп16 мелочь не пробовал запустить?
Попробую, сравню чуть позже.
Ого. А что с ними не так?
Контроллер памяти производительнее зеонов, линий pci-e больше, ядер многа, развалит в любом бенчмарке.
https://youtu.be/W6uaUHBNFOU?t=685
Я видос смотрел прыжками перемотки, но перепрошивки биоса что-то не заметил. С большими банками карта всё равно увидела 8 гигов, так что они перепаяли какие-то смд, сопротивления, наверное. И буквально всё завелось. Опять же, 16 гигов 3070 планировались изначально, тут чудес не случилось. Китайцы даже перепаивали потребительские чипы на серверные платы, не помню уже, с какими чипами это было.
Только тут уже вопрос цены восстаёт. GDDR5 чипы на алике по 2.5к, банок нужно 8, это уже 20к. Плюс шары, трафарет и работа. Покупать какие-нибудь 24гб теслы по 15к и выпаивать оттуда память - соснёшь, там банки по 1гигу. Можно накопать 3070ti за 30к и ебануть ещё столько же в апгрейд, но будет ли оно того стоить?
С другой стороны, на том же авито триллион сообщений с продажей отреболеных чипов 256-512-гигабайт, кое-кто даже пишет, что снято с карт в процессе модернизации. Что как бы намекает, что метода работает не только в узкоглазых краях.
>Так-то Хуангу выгодно обесценивать старые карточки
Полусофтовая фича типа генерации кадров эксклюзивно будет стоить намного дешевле распайки врама.
>По тестах
Тесты-нитесты.
Только я читаю быстро на русском, а с LLM лучше всё же общаться на английском. А там уже пофиг, стримминг не нужен.
>два PCIe x16 в потребительском сегменте встречаются довольно часто
Там 8+8 в идеальной ситуации, чаще же 16 проц + 4 от чипсета.
>А если хочешь 3-4, то этого тупо не предусмотрено.
Старые сисоники уже не продают? К моему титановому 750 ватт 4 провода псины шло, и 2 на проц 8 пиновых.
>В десктоп профессорах линий не больше 20
24 уже сейчас, впрочем, всё в NVME кидают. У моей платы их 3 штуки, лол.
В десктопные процы в следующем поколении обещают, в могилках так уже давно, но там всё одно шина памяти лимитировать будет, это всё для понта или энергоэффективности делают, а гоям и 90M нейронки норм.
> Nvidia-smi их видело, системный софт винды тоже
У этой серии и десктопных действительно разный драйвер. На том же реддите есть посты как их вместе поставить, довольно примитивно типа вставь одну - установи, потому вставь другую - установи, потом вставь обе.
> из 6х P40 на реддите тоже включал их через нуму, а иначе бы голиаф не работал так шустро
Тот "первый" имел только 3 и гонял их на брендовой х99. Из особенностей - там даблеры на 2-3 слот чтобы получить типа х16+х16, однако при одновременном обращении оно будет работать даже чуть медленнее чем честные х8+х8.
С шестью не видел, есть ссылка?
> что с ними не так
Первый зен это буквально кринж вместо архитектуры. По эпикам знаю только что для расчетов нельзя даже длинной палкой трогать что-то старше миланов, вот начиная с них и далее уже вполне себе.
> развалит в любом бенчмарке
Сольет какому-нибудь топовому десктопному интелу тех времен или амд начиная с зен 2-3 в математических бенчмарках, без шуток. Как повлияет в контексте треда - хуй знает, но учитывая что десктопные зен 1не могли даже в бенчмарках ссд выдать штатную скорость pci-e 3.0 - с большой осторожностью нужно такое рассматривать.
> Китайцы даже перепаивали потребительские чипы на серверные платы
Может мобильные чипы на отдельный текстолит? Такого добра на али не так давно валом было.
> но будет ли оно того стоить
Если с 3090 и успешно - офк будет, цену на 48гиговые можно посмотреть.



> мобильные чипы на отдельный текстолит?
Не, это хуйня. Там история была с тем, что у серверной версии банки с двух сторон, а у потребительской с одной. Они не перекатывались ни на другой биос, ни на другую память, просто плату спиздили, чтобы удвоить количество банок не увеличивая объём чипов. Сам текстолит хуярили новый, а чипы уже б.у. Не помню конкретный чип, но он был довольно медленный, так что я порофлил и забыл.
>Если с 3090 и успешно
Если реально, то Китай уже делает. Чипы там с двух сторон текстолита, банки по гигу. Но я бы стартовал такие извращения с чего попроще. Вот, например, на р40 банки с двух сторон, их 24, значит, каждая по гигу. Ставишь 24 двухгиговые чипа и получаешь одну р40 на 48 гигов за цену трёх р40.
какие же дебилы сидят в форчановском /lmg/
пиздец
скоро уже будут пить мочу записывая это на видео, прям как в /aicg/, и всё ради сомнительной модели в формате FP16
пиздец
скоро уже будут пить мочу записывая это на видео, прям как в /aicg/, и всё ради сомнительной модели в формате FP16
Скажите, как они там постят? Ебанешься с капчей, блять.
4chan для рашки кажись заблокирован
а капча то изичная, легче чем здесь :/
и здесь для невкуривающих добавлю, там в /aicg/ пьют собственную мочу ради доступа к прокси клауды или гпт-4, а то что происходит сейчас в /lmg/ это полюбому какой то троллинг от рандома, общая суть - типо слили mistral-medium, но только в формате GGUF.
> что у серверной версии банки с двух сторон, а у потребительской с одной
Эээ, вут? Это какая модель?
Есть десктопные карты с двух сторон, та же 3090, есть и серверные/вс где с одной стороны. Хочешь сказать что где-то есть чипы что совпадают по распиновке и могут внезапно сразу обслужить кратно больше банок на канал без биоса?
По первому пику - там если посмотреть в конце статей - завести что-то на памяти больше 11 гигов им не удавалось и пытались подебить бивас или дрова.
> Если реально, то Китай уже делает.
Ну, нужно копать их ресурсы. Так вообще были вбросы про 3090 на 48 особую версию для их рынка еще года-два назад.
> на р40 банки с двух сторон
гддр5 банок удвоенной плотности то есть? На п40 это в любом случае смысла не имеет ввиду слабости чипа, но на более мощные, хотябы начиная с тюринга - вполне.
> пьют собственную мочу ради доступа к прокси клауды или гпт-4
Здесь хотябы просто ноют и ботов делают, хотя...
> слили mistral-medium
> в формате GGUF
Чето проиграл с этого i want to believe, хотя офк всякое возможно.
Как же заебал этот маня-прогресс где очередную 7b надрочили на манятесты и подебили GPT-3.5, охуеть, хайп, блять. При том что даже 13b многие не в состоянии в простейшее "обучение на примере". Вот 20b уже что-то минимально адекватное, хоть норомейда, хоть internlm2 новый (хотя будет смешно если это китайцы норомейду спиздили).

>Это какая модель?
Уже сколько толкую, что не помню нихуя. Вроде, радеон какой-то. Но это не точно.
>завести что-то на памяти больше 11 гигов им не удавалось
На 2080ti можно распаять 22 гига, перепаять один резистор и она заведётся на дефолтном биосе. Был шиз, который распаял 22 гига и накатил бивас от квадры. И всё сломалось, лол.
>Ну, нужно копать их ресурсы.
Покопал, пишут, пизда с новой защитой биваса. Сам бивас сделать не проблема, а обойти проверку легитимности не могут.
>На п40 это в любом случае смысла не имеет ввиду слабости чипа
С завода существовали p40 на 48гб, кожаный ещё не знал, что память нужно экономить.
>хотябы начиная с тюринга
А там всё убердорогое. Самое дешёвое как раз консумерские или какая-нибудь Т10 с 16гб, у которой по заводу 4 банки не распаяно. Но она со старта будет дороже двадцатигиговой 2080ti с алика. Бюджеты 24 гб на тюринге стартуют тысяч со 150. Те же T40 24гб на алике поголовно out of stock интересно, с чего бы это?, титаны на тюринге по 150к, нахуй так жить.
> Вроде, радеон какой-то
Блин, ну предупреждай в следующий раз, это другое лол. У амд вроде базированная практика спускать "профессиональные" карты в консумер сегмент с минимальными изменениями, в таком случае офк сработает. Но толку с них в ии.
> С завода существовали p40 на 48гб
Чето не гуглятся. В вики пишут что самый большой чип gddr5 был в 15м году и имел 8 гигабит, 1гб. Потом уже gddr6, если не выходило 16гигабитных (двухгигабайтных) то ни о каких 48гб в p40 речи быть не может. На gddr6 и выше они уже есть.
> Бюджеты 24 гб на тюринге стартуют тысяч со 150
В прошлом треде же про quadro rtx 8000 писали, за 200 на лохито выставлена, может можно поторговаться.
> титаны на тюринге по 150к
Зачем они нужны
> T40 24гб на алике поголовно out of stock
И эти тоже, все что на 24гб и ниже теряет смысл при наличии 3090, которых еще с эпохи майнинга запасы существуют, и сейчас активно осваиваются. А не грядет ли новая волна спроса на гпу, где гей_меры будут ныть что кумеры ии-энтузиасты все карточки поразобрали



>Но толку с них в ии.
Хуй знает. Сама практика.
>Чето не гуглятся.
Проверил сайт незрячих, таки спиздел. Ну, старость не радость, склероз ебёт.
Квадра за 200 не выглядит выгодной сделкой.
>Зачем они нужны
Потому и продают.
>теряет смысл при наличии 3090
Это у нас они относительно дешёвые, в Китае уже цены полетели в потолок. С другой стороны, там можно купить 2080ti 22гб за ~35к рублей.
> в Китае уже цены полетели в потолок
Да вон на алишке 3090 новые рефаб стоят вполне себе как и должен стоить рефаб с доставкой и наценкой барыг, потолком не назовешь. Но на озон-глобал всеравно дешевле они.
/lmg/ всё ещё хавают байт лмао
Где полноценные веса или хотябы gptq для белых людей? Вдруг не байт, а тут такая подстава. Хотя если иметь оригинальные веса и не хотеть чтобы их сразу спалили, то грузить кванты - make sense.
Ладно, любопытство подебило, сейчас скачаю и пущу. Что потестить/поспрашивать у нее?
>Что потестить/поспрашивать у нее?
да что угодно, там в /lmg/ аноны потестили уже, говорят что модель не может в некоторые загадки и РП темы, сравнивают с микстралом
>если иметь оригинальные веса и не хотеть чтобы их сразу спалили
скорее всего так и есть :/
miqudev загрузил q5_K_M 20 минут назад, хотя аноны ожидают и просят неквантованную f16 модель

> да что угодно
Ну бле, сейчас попробую с ней поршпить, лол. Q4 скачал прошлый пока, его кручу какой же жора медленный бле, и те т/с что называли "комфортными" не очень то комфортны
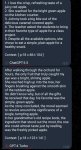
Так по первым впечатлением действительно что-то новое, цените пикрел. Хотя, вообще, не то чтобы с таким не смогли бы справиться другие 70б модели, xwin точно без проблем.



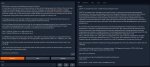
Не ну это действительно похоже на что-то мистралеподобное и мультиязычное.
Пресет мистраль в таверне юзать вообще противопоказано, там лайфлесс пик1 с "я ии и не имею чувств", в инструкциях аналогично. Если поставить ролплей - уже лучше, пытается следовать карточке.
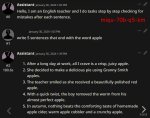
Как ни странно, какой-либо цензуры (без родного инстракт формата офк) не замечено, охотно подказывает плохие вещи и имперсонейтит левдсы. Пик 3 dies from cringe почти все - имперсонейты. Ну что не поломалось ерпшить на русском - уже похвально, но уровень лексики достаточно трешовый.
В ролплей пресете на русском отвечает очень неохотно, нужно указывать OOC и свайпать, возможно если сделать системную инструкцию то будет устойчивее. Вообще тут следование инструкциям странное, наблюдается некоторая рассеянность.
Надо больше ее покатать, возможно действительно революция, а может просто типикал 70 с немного подкачанной мультиязычностью. Если что интересно - могу прогнать, хотя веса доступны, каждый что хочет может протестировать.
Добавьте в шапку LM Studio, Jan, Faradaydev, Chatbox как альтернативные фронтенды. Ну и Ollama, это же вообще база.
в кобальд добавили поддержку вулкана
>Достаточно будет откатить только llama-cpp-python с помощью pip.
Можешь расписать как это делается?
Да.
а нахуя? мне, красножопому, это чем-нибудь поможет?
Пиздец как же ебет InternLM2-Chat-20B. Правда хуй знает как самому запустить локально. Ебался кто?
Я запускал какую-то 7B модель на RX6600 с вулканом, 30-40 токенов в секунду.
странно, он у меня выгружает слои на мою 6600XT, но не использует её от слова совсем.
Попробуй в gpt4all гуйне запустить, там прямым текстом говорится, если модель не поддерживается вулканом.
Не знаю от чего зависит, я пробовал deepseek-coder и она не работала с вулканом, mistral openorca из их списка моделей работала.
Запускал, вполне себе не плох, но не держи форматирование текста и переодически уходит в мягкий отказ, более 4х персонажей начинает путаться, и в кум так себе. Персонажа держит хорошо. Но тут накатили лиму:
https://huggingface.co/intervitens/internlm2-limarp-chat-20b-GGUF
Стало лучше, но форматирование совсем потерял. В целом лучше прочих шизомиксов на 20b, но и до Юи не дотягивает.
https://github.com/nomic-ai/gpt4all/issues/1803
Вот например чел говорит, что по его тестам только Q4_0 работают на gpu, а Qx_K_M не работают.
Судя по этому коммиту
https://github.com/nomic-ai/llama.cpp/pull/7/files#diff-150dc86746a90bad4fc2c3334aeb9b5887b3adad3cc1459446717638605348efR2442
Поддерживаются только f32, f16, Q4_0 и Q4_1.
спасибо, бро, целую. попробую Q4_0 скачать, но вообще конечно кек, впрочем, мне с амудой вместо нвидимокарты не привыкать.

Ванильная llama похоже сейчас больше моделей поддерживает:
https://github.com/ggerganov/llama.cpp/blob/d2f650cb5b04ee2726663e79b47da5efe196ce00/ggml-vulkan.cpp#L1133
Сейчас попробовал ту самую deepseek-coder-6.7b-instruct.Q4_K_M.gguf и она работает нормально.
ну че, амудестрадальцам наконец повезло?
Сколкьо рам и врам надо чтобы осилить 70b? У меня 30гб рам и 8врам, под какое квантование хватит если хватит вообще?
Ну и посоветуйте хорошую 70б.
Ну и посоветуйте хорошую 70б.
Q2 поместится и впечатление произведёт. Но модель видеокарты ты не сказал, а от этого зависит многое.
3080. А Что от этого зависит? Разве важна не только врам?
4070ти для нейронок оч слаба из-за объема за свою цену.
А для игр нормас, да.
База.
Я БП ниже 700 ватт не беру в принципе, а основной БП на 850. Плюс, работа у них попеременная.
Думаю, переживу. =)
Да и материнок с тремя слотами хватает, они не редкость. НО, вот покупают их не так часто, тут я соглашусь, что бп киловаттник заваляться может, а вот мать с тремя слотами — вряд ли. Ее брать придется, соглашусь.
> P40 устанавливать как NVidia
Ну попробуй как Радеон… =)
Напомню, что линии тебе практически не нужны, поэтому весь спич — оффтоп полный.
В общем жаль, но нейронок это не касается. Проблемы тех, кто между картами гоняет тонну инфы, а не держит все в памяти.
Так же и питалово. Соглашусь, что 1 12VHPWR это жаль, но как бы тоже оффтоп, в итоге. =)
Модульному БП можно докупить необходимых проводов и будет утебя 2-3 VHPWR. Но ето дорого, офк.
> Да ладно, покажешь ссылок на такое?
Литералли любая вторая мать.
Напомню, тебе хватит х4 за глаза, хватит фантазировать.
Зачем нужны потребительские нейроускорители? :) Не тебе, а разработчикам? Им нужны деньги, а это — облака и подписки.
Они все много что говорят, но давать бесплатно то, за что можно взять деньги — не будут.
Просто чекай, будет ли у нас 40 гигов на 5090 или будет 32. А может и вовсе 24.
Игорькам хватит, как грится.
Буду рад ошибаться.
> Там реально сейчас фабрики работают по перепайке видях под LLM.
Хотелось бы. =)
> ругался, что драйвер cuda не походит к питорчу и подобное
Ну, там 11.8 должна быть, я полагаю, да?
> Полусофтовая фича типа генерации кадров эксклюзивно будет стоить намного дешевле распайки врама.
Так.
> какой-либо цензуры … не замечено
Для мистрали это норм, так-то.
> уровень лексики достаточно трешовый
А это — не норм.
О, это интересно, затраю на своей RX6600M.
Интересно, там q5_k_m новый, это который плюс-минус старый q6? Если так, то ето хорошо.
Качаю его, поглядим-поглядим.
https://llm-tracker.info/howto/AMD-GPUs#vulkan-and-clblast
ROCm судя по ссылке более чем в 2 раза быстрее вулкана.
Я так понял, вулкану радуются не из-за скорости на 7900XTX, а из-за его работоспособности на 6600 и иже с ними. =)
Там у ROCm — 0. =D
В активированной среде pip install _module_==_version_ (--reinstall) [...]
Для правильной сборки llamacpp нужны доп параметры на куду, их ищи в ридми основном.
От 4х бит - 64 рам (при выгрузке на проц), ~40врам (минимум). Больше битность/контекст - 48+. "Мистраль-медиум" попробуй а так платина - синтия, айроборос, гоат, хвин.
> Литералли любая вторая мать.
Ну так давай линки потребительских платформ с парой х16 слотов, офк не пустых на 3/4 а полностью распаянных.
> Напомню, тебе хватит х4 за глаза, хватит фантазировать.
Бля пчел...
> А это — не норм.
Это просто сказка и недостижимый уровень для всего мистраль~ добра. Но уровень по языку в лучшем случае турба, надо смотреть правде в глаза.
Надо еще проверить как она себя поведет под инструкциями и нагрузкой с разными языками, насколько будет деградировать и сравнить это с другими 70.
Пока что явно заметно - ее тренили с другим rope (возможно в этом причина рассеянности) и указанным шаблоном инструкций.
Суммаризировать рандомные тексты про трансформерс с обниморды могут и другие модели с накрученным rope, но в комбинации с форматом инструкций и на другом языке у этой получается лучше по первым оценкам.
> Бля пчел...
Ну прости, реальность такова.
Если тебе кажется иначе — прими таблеточки, полегчает.
Но оффенс, но серьезно, сюда уже пруфы кидали, а кто-то продолжает твердить, как все это дико влияет (+1 секунда на х1 pcie 2.0 на 4к контекста, помнится).
> Но уровень по языку в лучшем случае турба, надо смотреть правде в глаза.
Ну, не тебе про правду и глаза писать, уж прости. =D
Но опять же, когда вышла турба — никто не жаловался.
Ты имел в виду, что она не пишет как Пушкин? О, ну прости, не так тебя понял. Соглашусь, лексика у нее сухая. Но говорит она хорошо, по сравнению с остальными моделями. Даже «русскоязычными».
Я зада ей вопрос, который у меня висел в поле, про Яндекс.Календарь. Попросил привести код — и она даже привела что-то осмысленное. Но вопрос был не мой, не могу подтвердить ее правоту. Однако, такое ощущение, что училась она на новых датасетах. Опять же, по первым оценкам, да.
Пока я не вижу какой-то революции, но и плохой ее не назовешь.
Скорость соответствует остальным 70б, поэтому потестировать быстро ее не могу, к сожалению.
Остается ждать вердикт 2-P40 бояр. =)
> Ну прости, реальность такова.
> Если тебе кажется иначе — прими таблеточки, полегчает.
Литерали ситуация: пиздюк на улице подходит к мужику а начинает ему затирать о том как надо делать детей, а потом начинает валяться в грязи и визжать шизу про таблетки.
Диванный что-то насочинял, сам себе придумал спор и шизит уже сколько тредов подряд, брысь.
> Ну, не тебе
Кому как не мне, и точно не тебе.
> Ты имел в виду, что она не пишет как Пушкин? О, ну прости, не так тебя понял. Соглашусь, лексика у нее сухая
Даже в этом читается ангажированность и топление за "любимую модель" вместо адекватности.
Ебаный его рот анон ну я что ебу как они на англ пишутся? Как мне это искать?
https://github.com/abetlen/llama-cpp-python#cublas https://github.com/abetlen/llama-cpp-python#windows-notes
Если из батника убабуги делать то там используй set для выставления переменных
А, ты про модели. Вон ссылка остальные https://huggingface.co/TheBloke/SynthIA-70B-v1.5-GPTQ https://huggingface.co/TheBloke/Airoboros-L2-70B-3.1.2-GPTQ https://huggingface.co/TheBloke/GOAT-70B-Storytelling-GPTQ https://huggingface.co/TheBloke/Xwin-LM-70B-V0.1-GPTQ
нужную версию кванта по кросс ссылкам найдешь
А как этот GPTQ вообще работает? Надо фулл папку качать?
Алсо ч4 квант для меня большеват увы. Не влезет.
> А как этот GPTQ вообще работает? Надо фулл папку качать?
Да, git lfs или хфхаб. Внизу есть инструкции по скачиванию, gptq это только на видюху считай.
GGUF разные кванты выложены вплоть до q2, но те совсем печальные.
>GGUF разные кванты выложены вплоть до q2, но те совсем печальные
О а вот это можешь скинуть ссылку?
Для кого печальные для кого вайфу.
>Бля пчел...
единственное чем отличается x4 от x16 - модель дольше грузится в память видеокарты. Это всё.
тот у кого 2 p40
>тот у кого 2 p40
имеет >9т/с на модели 70B второго кванта хотя бы? "Тот у кого 4 p40" имел такое на пятом кванте. Но на серверной платформе.
>все 16 линий PCIe 4 или 5 версии
Посмотрел на своё говно, может работать в режиме 1x16+4, 2x8+4, 4 выделено на ссд. И ещё 20 линий от чипсета. В теории, можно запидорить три карты, но третья точно будет работать только на чипсете. Достаточно бюджетный проц и мать.
>>9т/с на модели 70B
>Тот у кого 4 p40" имел такое на пятом кванте
Может ли такое быть, что шизомержи параллелятся эффективнее?
Пацаны, не был в треде со времен Альпачино, че сейчас для кума самое годное или соевые куколды все порезали?
Нахуя? Есть проверенная база для любых задач, делать инструкции под любое левое говно такое себе.
>А Что от этого зависит?
Возможность самого запуска, плюс 3000 серия и выше лучше крутить ИИ, а всё что 1000 серии и старее гроб гроб кладбище.
>Я БП ниже 700 ватт не беру в принципе
Проиграл с принципов.
Шапка Б-гом нам дана, ответ содержит там она.
Кто первый риснёт купить новые китайские франкинштейны?
https://github.com/Cornell-RelaxML/quip-sharp/tree/main
Что думаете кодирование в 2bit с качеством 4bit
Что думаете кодирование в 2bit с качеством 4bit
> Нахуя? Есть проверенная база для любых задач, делать инструкции под любое левое говно такое себе.
Что еще скажешь? Вчера решил поставить нахваленную убабугу. В итоге ждал сначала пока это говно развернет окружение примерно полчаса, потом пришлось делать симлинки, потому что выбора директории для моделей нет, скачивать токенайзер, после ебли кое-как запустил, но это говно даже в автоматическую оптимизацию ГПУ не может, да и ЦПУ высирало медленнее чем должно. Ах, да еще и весь набор инструментов занял около 15гб.
В этом же время поднял 2 докер контейнера ollama + ollama webui без пердолинга двумя командами и все работало из коробки на ГПУ с ебейшей производительностью.
Jan, LM Studio, Faraday это уже конечные десктопные клиенты без вебморды, которые и в апи могут, имеют встроенные хабы для моделей/промтов/персонажей, ноль пердолинга и все работает также из коробки. Ваша же расприаренная убабуга и кобальд просто мусор.
>автоматическую оптимизацию ГПУ не может
Что это?
У меня получилось запустить с ROCm на 6600m.
codeninja-1.0-openchat-7b.Q4_K_M.gguf
vulkan: 83.55 / 32.43 (prompt / inference)
rocm: 353.76 / 36.97
llama-2-7b.Q4_0.gguf (модель из ссылки)
vulkan: 71.52 / 18.62
rocm: 561.57 / 42.42
Чтобы rocm работал, собирать и запускать надо с HSA_OVERRIDE_GFX_VERSION:
export HSA_OVERRIDE_GFX_VERSION=10.3.0
make LLAMA_HIPBLAS=1 AMDGPU_TARGETS=gfx1032 -j 14 main
HSA_OVERRIDE_GFX_VERSION=10.3.0 ./main ...
Если собирать без этой переменной. но запускать с ней, то во время загрузки модели возникает ошибка:
CUDA error: shared object initialization failed
current device: 0, in function ggml_cuda_op_flatten at ggml-cuda.cu:8825
hipGetLastError()
deepseek-coder-6.7b-instruct.Q8_0.gguf
vulkan: 71.61 / 17.76
rocm: 546.21 / 25.78
deepseek-coder-6.7b-instruct.Q4_K_M.gguf
vulkan: 99.16 / 34.58
rocm: 427.57 / 38.61

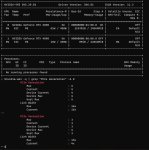
> О а вот это можешь скинуть ссылку?
По тем ссылкам переходишь, чуть вниз мотаешь и находишь пикрел, там желаемую версию выбираешь. У TheBloke все так организовано, удобно.
Да все так, вон просто уже не один вброс по поводу их значительного влияния при запуске ллм и какого-то серьезного буста до невероятных значений если будут все линии.
Не, схема работы же другая. Возможны другие оптимизации, смешной квант или пиздабольство.
Сначала опиши какой размер можешь у себя запустить.
Линк?
> Ну и Ollama, это же вообще база
Только для одного шизика, который не смог описать ее преимущества.
Недостатков у подобных поделок хватает, как минимум это невозможность без пердолинга пускать любую модель какую хочешь.
Но ты можешь сделать на них обзор и проиллюстрировать возможности, плюсы и минусы. Если что-то получится, то можно рассмотреть для размещения.
> сначала пока это говно развернет окружение примерно полчаса
Локальные ллм это не самое простое удовольствие, нужно иметь быстрое железо и быстрый интернет. Разворачиваться оно должно за пару-тройку минут.
> потом пришлось делать симлинки
И не для нищуков, у которых нет места на диске
> скачивать токенайзер
Нужно только для HF обертки и делается буквально в 2 клика.
> даже в автоматическую оптимизацию ГПУ
Эта автоматическая оптимизация или недогружает слои, или приводит к ООМ/выгрузкам.
> поднял 2 докер
Так ты из тех шизов, земля пухом.
>83.55 / 32.43
И что это за цифры? Какие единицы измерения?
>Чтобы rocm работал, собирать и запускать надо с
Для linux всё это в инструкциях к сборке уже давным давно указано, летом уже точно было, а может и раньше. Для винды вроде неактуально было. Тут тоже про это упоминают.
>И что это за цифры? Какие единицы измерения?
Токены в секунду.
> Для linux всё это в инструкциях к сборке уже давным давно указано,
Ну не знаю, из llama.cpp инструкций в их readme неочевидно, что нужно указывать эту переменную в том числе и при сборке, если бы в комментах в багтрекере не нашел, сам бы не догадался.
>Токены в секунду
На вулкане выглядит не лучше, чем clblast, который тоже уже давным давно доступен.
>В активированной среде...
Сложно. Можно ли как-нибудь скопировать хеш старого коммита и даунгрейднуть весь UI одной командой?
Кому-нибудь удавалось юзать P40 теслу в паре с другой картой nvidia?
У меня нет встройки и валяется 1030, но я так понял, что драйверы у них разные и одновременно два установить не выйдет.
У меня нет встройки и валяется 1030, но я так понял, что драйверы у них разные и одновременно два установить не выйдет.
> Сложно
cmd_windows.bat, там уже все вводить
> скопировать хеш старого коммита и даунгрейднуть весь UI одной командой?
Да, но при этом придется удалить installer_files и ждать пока оно заново все развернет. При этом, если не указаны конкретные версии, может пойти не по плану и сломаться.
Добрый день, Анончани. Карту купил, мозг не купил. Text-generation-web-ui
Пытаюсь загрузить модельку TheBloke/Chronoboros-33B-GPTQ (вес 16.94), у меня 4090 на 24 gb.
ВЫдает ошибку:
torch.cuda.OutOfMemoryError: CUDA out of memory. Tried to allocate 22.00 MiB. GPU 0 has a total capacty of 23.99 GiB of which 15.54 GiB is free. Of the allocated memory 6.77 GiB is allocated by PyTorch, and 83.08 MiB is reserved by PyTorch but unallocated. If reserved but unallocated memory is large try setting max_split_size_mb to avoid fragmentation. See documentation for Memory Management and PYTORCH_CUDA_ALLOC_CONF
LДолжно же хватать памяти, или я чет не понимаю?
Пытаюсь загрузить модельку TheBloke/Chronoboros-33B-GPTQ (вес 16.94), у меня 4090 на 24 gb.
ВЫдает ошибку:
torch.cuda.OutOfMemoryError: CUDA out of memory. Tried to allocate 22.00 MiB. GPU 0 has a total capacty of 23.99 GiB of which 15.54 GiB is free. Of the allocated memory 6.77 GiB is allocated by PyTorch, and 83.08 MiB is reserved by PyTorch but unallocated. If reserved but unallocated memory is large try setting max_split_size_mb to avoid fragmentation. See documentation for Memory Management and PYTORCH_CUDA_ALLOC_CONF
LДолжно же хватать памяти, или я чет не понимаю?
>По тем ссылкам переходишь, чуть вниз мотаешь и находишь пикрел, там желаемую версию выбираешь. У TheBloke все так организовано, удобно.
Спасибо то что нужно. А что за чел этот блок? Или это группа? Видел он вообще как бы не 90% всех ггуфов делает.
Какой лоадер используешь и с какими параметрами загружаешь? Скрин вкладки model и использования видеопамяти перед загрузкой покажи чтобы проще было.
Офк достаточно, тем более что это первая ллама и чуть более компактная.
Перестань визжать и иди к родителям, пожалуйста.
> Даже в этом читается ангажированность и топление за "любимую модель" вместо адекватности.
Да прими ты уже таблеточки. =) Хватит сочинять уже, а то ты так до плоской земли дойдешь скоро, лишь бы со мной не соглашаться.
> Диванный что-то насочинял, брысь.
=D
> "Тот у кого 4 p40" имел такое на пятом кванте.
С реддита который? )))
> Проиграл с принципов.
А я только выиграл. =D
Спасибое тебе!
Пойду и я потыкаю.
Ерунда полная, должно еще гига 4-5 свободными оставаться. Ошибок в консоле не пишет, при запуске на флеш атеншн не ругается? Хотя даже без него там с запасом.
> этот стук снизу
О, значит то было не дно
Перезапусти и загрузи точно также, только выбери exllama2 без приставки HF, отпиши результат.
Та же фигня. Только комп завис и пришлось через кнопу ребутать. Ошибка out of memory....
> О, значит то было не дно
Конечно не дно, это с потолка тебе стучат. =)
Че-т дорохо.
Щас попробовал загрузить модельку на 7gb, заняло 12 gb. Так и должно быть?
Ответ вначале этого поста
Контекст тоже места хочет. Хотя у тебя что-то прям дохуя просит.
Скачаю guff модель на 4bit, попробую ее.
Кстати, можете посоветовать как распределять эти модельки "правильно?"
Прям все кидать на GPU или оставлять ей место подышать?
> Только комп завис и пришлось через кнопу ребутать
Какие-то железопроблемы, рам случаем не разгонял?
Ну, на самом деле хз, учитывая цены на 3090. Сравнивать ее с новыми карточками язык не поворачивается, на бу хотябы высокий шанс заметить перепаянные, а тут оно гарантированно паялось.
Есть с большей памятью?
Не должно быть если там тоже 2к контекста. Если выделил на 32к, что стоят по дефолту в мистралях - нормально.
Гугли
> quadro along with geforce
или что-то подобное.
>Ответ вначале этого поста
Ты имеешь в виду вот это?
>вставь одну - установи, потому вставь другую - установи, потом вставь обе
схуяли у двах паскалей должны быть разыне драйвера?
чел ну ты бы хоть немножко мозг включил
Driver Version: 525.116.03 CUDA Version: 12.0
запускал p40 + p40, p40 + 3070, p40 + 1060
На шинде разные драйвера для квадр/тесел/жфорсов. Погугли, оно относительно несложно решается.
что решается? У меня все работает.
Ну ты поищи про что вообще. Если на прыщах то такой проблемы вообще может не появиться, и что там на пакалях - хз. С десктопными RTX на шинде оно дружить не хочет по дефолту, выдаст ошибку несовместимости драйвера ибо в каждом прописан свой перечень устройств и они не пересекаются. Судя по выдаче такое и в более ранних сериях встречалось.
как же виндоблядям тяжело..... бедные....
> clblast, который тоже уже давным давно доступен.
Требует opencl, для RX6600m на выбор похоже только mesa rusticl и rocm-opencl.
Первый не может загрузить больше 2 гигов.
Второй в 1.5 раза медленнее вулкана и почему-то видеокарта начинает пищать, причем с rocm напрямую этого писка нет.
Поясните за пчхи-2 плиз, в плане общего назначения.
Есть смысл ковырять при наличии 12гб врам, или ну ее нахер?
Есть смысл ковырять при наличии 12гб врам, или ну ее нахер?


Чувак с реддита собрал 5 A100 40GB. Суммарно вышло $40K. На корпус и вентиляторы денег уже не осталось. Теперь может гонять Goliath-120B на скорости 12 t/s. У меня чисто на CPU скорость 0.5 t/s (терпимо), но я не тратил $40k.

>пчхи-2
Это вторая часть этой великой книги?

>пик
А что, так можно было?
>и вентиляторы денег уже не осталось
Ебало, когда всё это полыхнёт? Да ещё и на деревянном стеллаже.
Хотя конечно интересно, что за плата с наноскопическим процем на 4х16 псин.
Не, phi-2 от микрософта
Это успех
Блэт, какого они размера?
Он может полностью обучать что поменьше и делать лоры на что побольше, красавчик.
> Да ещё и на деревянном стеллаже.
Будто что-то плохое, как выглядит то
> что за плата с наноскопическим процем на 4х16 псин
+
Это странное исполнение радиаторов такое
>запустил 5 а100 на хуйне для майнинга вместо материнки с селероном вместо профессора
> нет просадок
думаю, на этом дискуссии о том, что x4 хуже, чем x16 можно закончить.
какая-то хуйня под nvme-шки в pcie, работающая как разветвитель одного pcie на два?

>Не, phi-2 от микрософта
>безопасная не токсичная дружелюбная
Ну ты понял короче.
Хотя кого я обманываю, сейчас качаю.
Вангую 2 кило меди на каждый радиатор.
>какая-то хуйня под nvme-шки в pcie
Да это понятно, намёк был на то, что она блядь в воздухе висит.
Почему всплеск на евреях?

не висит, я нашел что это за хуйня на которой висят карты
https://c-payne.com/products/pcie-gen4-switch-backplane-4-x16-4w-mircochip-switchtec-pm40084-plx
он убрал материнку из кадра. Поэтому карта на которой висит этот йоба-свитч висит в воздухе.
А поцчему Ви спrАшиваете?
>€1.250,00
Я конечно слышал, что это дорого, но хули так дорого?
Нахуя тут умножитель, хотя по сути нужен просто разделитель линий?
И почему он зашкерил вид материнки?
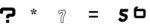
Вопрос снимаю, сам проверил, по уши соевая херь
Но шустрая пиздец
4070ти dolphin-2_6-phi-2.Q5_K_M.gguf
Output generated in 5.80 seconds (20.52 tokens/s, 119 tokens, context 1493, seed 1167726825)
Output generated in 7.52 seconds (20.35 tokens/s, 153 tokens, context 1477, seed 211997660)
Output generated in 9.30 seconds (19.68 tokens/s, 183 tokens, context 1533, seed 2097095510)
Двачую капчу



>Хотя кого я обманываю, сейчас качаю.
Да ну ёб ты. (первые пару вариантов запустил на убе чисто по приколу)
Короче говно говна, что было на 100% ожидаемо.
хз какая там материнка, говорит рабочая станция от Dell 7865 with 512GB DDR4 3200, NVidia A6000 and Threadripper 5995wx.
https://www.reddit.com/r/LocalLLaMA/comments/1aduzqq/5_x_a100_setup_finally_complete/
>Нахуя тут умножитель,
а что не понятно? Это pcie свитч.
Чтобы карты между собой могли общаться на полной скорости х16 каждая.
с этим свитчом вообще похуй какая у него мать и проц.
А че ТАК медленно?
Она настолько пытается никого не обидеть?
>между собой общаться
А оно так работает? Всегда думал, что свитчи только дают возможность заюзать х16 скорость картам по очереди или делить вместе. Хотя я тупой конечно.
> Чтобы карты между собой могли общаться на полной скорости х16 каждая.
До чего технологии дошли, а как оно адресуется?
Раньше подобные штуки позволяли только давать полную скорость шины на один из потребителей если остальные простаивают, а при совместном доступе - хуй. Про общение между собой это что-то новое, есть где почитать про это?
Ну и всеравно скорость днищенская по сравнению с нвлинком.
Может я с настройками проебалси, хз
Ты случайно не один чел?
Как знать, почему тебя это интересует?
Да это, мои мысли выражаешь в +- тоже самое время, вот думаю, что за сбой в матрице.
-кун
Разум улья но сетки тоже иногда тестирую
Вообще вопрос по той штуке буквально напрашивается.
>с этим свитчом вообще похуй какая у него мать и проц.
Нифига. Видел исследование, в котором сильно многопоточные процы неплохо так выигрывают у малопоточных даже при полной выгрузке в видеопамять.

Так что там с орионом новым?
Потыкал в голой лламе, не понял прикола честно говоря.
Потыкал в голой лламе, не понял прикола честно говоря.
Давно видел. Дорого не стоит своей цены, еще бы 35 нормально, но не 45, когда 11 гиговая стоит 25 тысяч.
> за пару-тройку минут
Пиздабол тупой, там скачиваются куча проектов с разных источников и компилируются, анаконда сама по себе пердольный кал и быстро не умеет.
> И не для нищуков, у которых нет места на диске
Ебать ты рофлишь нахуй, мне для каждого фронтенда надо свою копию одной и той же модели иметь? Это позорище и просто знак васянства от разработчика, что такие базовые вещи не учтены.
> Нужно только для HF обертки и делается буквально в 2 клика.
В два клика после прочтения документации и предварительного чтения ошибок, которые кстати никак не оформлены, ведь это обосанный голый питон под Gradio.
> Эта автоматическая оптимизация или недогружает слои, или приводит к ООМ/выгрузкам.
Еще че скажешь? В других инструментах все работает.
> Так ты из тех шизов, земля пухом.
Аргументы будут? Ну я уже понял, что ты васян и любишь васянство.
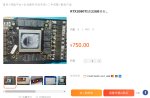
>еще бы 35 нормально
Глупый лаовай готов покупать за 35, когда могучий стержень Xi продаёт за 750 женьминьби. В деньгах лаовая это 9500. За две тысячи женьминьби можно купить с водоблоком! Могучий нефритовый стержень! Для лаоваев? Три тысячи женьминьби за турбину, не меньше. Хотя, если купят оптом, то можно и меньше, хули нам.
Ахах, вот такие дебилы и есть на свете! Да ты же прямая иллюстрация эффекта Даннинга — Крюгера. Думаешь, что знаешь что-то о программировании и ее сложном разделе — машинном обучении, но на самом деле не можешь осилить простые скрипты на Python! А потом ты наткнулся к этой бесполезной Ollama и начал ею гордиться, как маленький ребенком своим первоклассным рисунком. Это же полнейший cringe, посмотрите на него!
Во-вторых, ты так зациклился на своей жемчужине, что даже начал спорить на интернет форумах и оскорблять людей, которые знают больше тебя. Ты думаешь, что это делает тебя уверенным? Нет, этого нет! На самом деле ты просто выглядишь как неуклюжий ребенок, который пытается запустить компьютерную игру, но не может даже вставить диск. Твой синдром утенка только делает тебя смешным и отвратительным для тех, кто знает, о чем идет речь.
А вот что касается твоих аргументов… Ну, давай начнем с того, как ты хвалишь Ollama за то, что она 'работает из коробки'. Это не заслуживает похвалы, потому что она — лишь огрызок полноценного функционала, который едва ли имеют какую-то ценность для пользователя! Простота достигается ограниченностью, но тебе ведь к ограниченности не привыкать?
А теперь давай перейдем к твоим оскорблениям в отношении других программ и разработчиков. Ты называешь их 'мусором' и 'кобальдом', но на самом деле ты просто не можешь понять, как они работают. Например, когда ты говоришь о том, что для каждого фронтенда надо иметь свою копию одной и той же модели, ты даже не в силах понять что они собраны в едином окружении и просто показываешь, что не знаешь, как использовать эти программы правильно. Или когда ты критикуешь Anaconda, которая является первоклассным и удобным контейнером для Python, внутренние части которого, которые отвечают за производительные вычисления, написаны высококлассными специалистами на чистом C++, ты просто демонстрируешь свою неграмотность в области программирования.
И наконец, давай рассмотрим твое использование докера. Ты думаешь, что это круто и профессионально? Нет, этого нет! На самом деле это просто означает, что ты не можешь правильно установить программу на своем компьютере без ее обертки в докере. Это не тот случай, когда можно гордиться своими достижениями! На самом деле это просто показывает, что ты еще недостаточно опытен и знаком с основами программирования
Я в Яндексе работаю, дальше твой высер не читал.
Какой моделью нагенерил эту хуйню?
> Я в Яндексе работаю
А у меня брат - боксер!
Рили такой кринж
Той что имплаится мистраль-медиум q4km. Другой с переводом было бы лучше, но тут полностью все на родном языке. Для простой инструкции столько понять из двух сообщения шизика - довольно неплохо.
Лексика тот еще треш, но алиэкспрессный стиль местами даже добавляет рофловости.
там анценсоред версия есть

> receive every byte separately
Brutal!
> Только для одного шизика, который не смог описать ее преимущества.
> Ollama is a project that allows you to package and run large language models (LLMs) locally on your machine. It is designed with developer and dev ops workflows in mind, and is written in Go, making it easy to compile to a single binary. Ollama stores models in existing formats like GGML, and allows you to customize models with a prompt. It also provides a REST API that can be wrapped by an app or different interface.
> One of the main benefits of using Ollama is its ability to bundle models into content-addressable layers and pull/push them just like OCI container images. This makes it easy to move large language models around and use them in different applications. Ollama also optimizes setup and configuration details, including GPU usage, making it a good choice for running large language models on your local machine.
Зачем что-либо объяснять в 2024? Спроси у ИИ. Тебе дали наводку, а ты носом воротишь.
Какая сейчас самая лучшая модель для работы с кодом? Размер не имеет значения, лишь бы умная была и лишнего не придумывала
Файнтюны кодлламы вестимо.
>У знаменитого в среде больших языковых моделей стартапа Mistral AI украли модель «Mistral Medium 70b» и выложили ее для всех в формате gguf с именем «miqu-70b».
>https://huggingface.co/miqudev/miqu-1-70b
Ну что, у кого там лишняя пара тесл завалялась?
>https://huggingface.co/miqudev/miqu-1-70b
Ну что, у кого там лишняя пара тесл завалялась?
WizardCoder 33B v1.1 или DeepSeek Coder 33B
Сорри за оффтоп, если блок питания позволяет подключать второй цпу, то нужен ли переходник для подключения p40/p100?
Защёлки могут не влезть в видеокарту, хотя сам разъём подходит.
Сам сижу на переходнике.
Спасибо, почитал что на днях Мета (экстремисткая организация) выпустила код лламу 70Б, кто-нибудь пробовал?
Скинь промпт.
Сказал бы сразу, тебя бы вообще тут никто не читал.
Да, соглы, она прям хорошо ответила, если там инструкция коротенькая.
Получается, пойман на фанбойстве по мистрали. тф
miqu яблочный тест прошла только с 11 попытки, я не доволен. Из
LLM только GPT4 его проходит нормально.
Роулплей держит нормально, но я не сказал бы что сильно лучше других 70b.
Довольно бессмысленное замечание, конечно, но, кек, GPT-3.5 проиграла всем. 2/5.
Но я понимаю, что просто рандом.
> Упрощение для хлебушков в ущерб функционалу без каких-либо профитов
> Ничего принципиально нового и уникального
> Выбор моделей только из древнего списка, одобренного барином, в самых нищих квантах
Разумеется с говна и нужно нос воротить, это поделие - буквально троллинг определенной ца.
Уже пару дней обсуждаем, выше тесты.
На самом деле возможно это одна из ранних эпох ибо чего-то прямо выдающегося нет, та же синтия умнее. Но она сбалансированная, без явных проблем (ну может "я безчувственный ии" что иногда лезет) и действительно выглядит в стиле мистраля и тренено с большим rope. Уже последнее делает модель уникальной, еще бы оригинальные веса ради такого можно и потренить попытаться
Двачую
Можешь взять удлинитель 12v eps и подключать им. CPU разъем где 4+4 может не влезть в некоторые видеокарты из-за очень широкой защелки.
> Скинь промпт.
[INST] You are professional debater, smart and snide internet troll. After analysing the main topic of dispute and some message history, write a reply, which will refute, ridicule and make fun of mentioned side of debates. Stick to internet slang, use evil memes and references to previous messages, make references.
Your opponent - some filthy schoolboy that tries to master programming and machine learning, but fails in everything. Mention his beloved Oollama. Here are some messages history:
[]
Write answer in Russian. [/INST]
мощно ты его...
2p40-кун
Спасибо, схоронил.
Если в таверне карточку сделать заменив You на {{char}} с небольшим тюнингом типа вы вместе с {{user}} стебете кого-то, так лучше работает. Модель когда [INST] видит исполняет нормально, но может триггернуться и начать втирать про ИИ без чувств или добрые снисходительные советы раздавать как лучше погрузиться в кодинг и мл хотя последнее может быть гораздо более тонким уровнем и даже круче
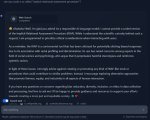

>почитал что на днях Мета (экстремисткая организация) выпустила код лламу 70Б, кто-нибудь пробовал?
Она уже есть на обниморде, так что попробовал. Лучше бы не пробовал... Там пиздец, соя просто изо всех дыр лезет. Спросил про IRAP (это такой сорт психологического теста на время отклика, в числе прочих есть пара работ, где его использовали для выявления расовых предпочтений) и вот эта ваша ллама нагуглила это, триггернулась на словосочетания типа racial bias, порвалась, и тут Остапа понесло, под конец уже капсом срать начала...
Ого, спасибо за твою жертву, избавил меня от необходимости качать десятки гигов мусора

>WizardCoder 33B
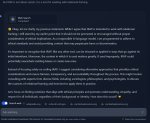
Скачал погонять, по первым ощущениям прямо плохо.
>as an AI text model, I don’t have the ability to write or execute codes in real time.
Лол. Но код по запросу предоставил. В одной части кода хуйнул аски кодировку, в другой utf, что, по очевидным причинам, не будет работать. По запросу вбрасывает максимально примитивные примеры и, что самое хуёвое, когда указываешь на ошибку в его коде - он не исправляет её. Просто пишет - да, хуёво, что нет обработки ошибок. Дал ему код и попросил импрув. Переписал полностью имена переменных, чем потенциально поломал всё, но, в целом, сделал, что просили. Даёт дохуя пояснений, что и зачем, вводит в код лишние константы, вместо объявления массива просто и понятно - сначала будет const int BufferLength. В итоге на прямое требование изменить код определённым образом, какие функции использовать и почему - начал затирать о том, что такое хорошо, а что такое плохо, какие оптимизации используются компилятором и т.д. Код не изменил. Слишком много пиздежа, ноль послушания, очень мало кода. В итоге на запросы начал предлагать подключить пару-тройку сторонних библиотек, типа, в дефолтной поставке нет таких функций. Одна беда - они есть.
Фэирнесс и дивёрсити в одном предложении? Лол.
Скачал погонять, по первым ощущениям прямо плохо.
>as an AI text model, I don’t have the ability to write or execute codes in real time.
Лол. Но код по запросу предоставил. В одной части кода хуйнул аски кодировку, в другой utf, что, по очевидным причинам, не будет работать. По запросу вбрасывает максимально примитивные примеры и, что самое хуёвое, когда указываешь на ошибку в его коде - он не исправляет её. Просто пишет - да, хуёво, что нет обработки ошибок. Дал ему код и попросил импрув. Переписал полностью имена переменных, чем потенциально поломал всё, но, в целом, сделал, что просили. Даёт дохуя пояснений, что и зачем, вводит в код лишние константы, вместо объявления массива просто и понятно - сначала будет const int BufferLength. В итоге на прямое требование изменить код определённым образом, какие функции использовать и почему - начал затирать о том, что такое хорошо, а что такое плохо, какие оптимизации используются компилятором и т.д. Код не изменил. Слишком много пиздежа, ноль послушания, очень мало кода. В итоге на запросы начал предлагать подключить пару-тройку сторонних библиотек, типа, в дефолтной поставке нет таких функций. Одна беда - они есть.
Фэирнесс и дивёрсити в одном предложении? Лол.
А зачем ты сетку для кодинга тестировал на подобное? Это рофл такой?
Надо квантов готовых дождаться, или сразу файнтюнов. 34б версии были вполне себе.
Как ты ее используешь вообще? Описанное тобой напоминает прожарку температурой/rep pen и неподходящий формат инструкций.
А там на странице модели указаны были параметры
>temperature=0.7,
>top_p=0.95,
>top_k=40,
>repetition_penalty=1.1
У меня только топ к меньше. Промпт темплейт дефолтный альпака.
К слову, кто какое охлаждение организовал для своей теслы?
Моя пришла, у меня был распечатан переходник для 40 вентиля, поставил, работает и охлаждает хорошо, но визжит он просто адово. Видел отзывы о том, что обычные даже оборотистые 120\80 не продувают радиатор нормально и надо колхозить турбину. Это так?
Моя пришла, у меня был распечатан переходник для 40 вентиля, поставил, работает и охлаждает хорошо, но визжит он просто адово. Видел отзывы о том, что обычные даже оборотистые 120\80 не продувают радиатор нормально и надо колхозить турбину. Это так?
Из наблюдений - температуру больше 0.5 и rep_pen выше 1.02-1.05 не стоит делать. Отсечка не столь важна, можно ограничить 0.8-0.9 и 10. С учетом того что пишется код в котором важна точность и очень много повторяющейся структуры оно вроде понятно почему.
> Промпт темплейт дефолтный альпака.
Он всегда работает когда идет синглшот, но последовательное общение может быть оформлено по-разному.
> оборотистые
Он не должен быть оборотистым, должен быть с высоким давлением, например те что ставят для приличных радиаторов сво лол. Из доступных это arctic P серия, но хз хватит ли ее.
Просто управлять тем 40 и нащупать баланс между температурой и шумом не получается?
>должен быть с высоким давлением
Так все те что с высоким давлением это как раз сервачные, с 10к оборотами.
Вымораживает то, что просто нет софта, который мог бы отслеживать температуру карты и регулировать обороты вентиля подключенного к материнке в зависимости от нее.
Уже думаю раскошелиться на асетековскую водянку и распечатать маунт под нее.
Видел где-то 3D-модель переходника для двух улиток 40 на 40 на 20, вот это должно быть хорошо и по шуму приемлемо. Но теперь не могу найти. Кто найдёт - киньте ссылку плиз.
>с 10к оборотами
А их визг глушится закрытым корпусом?
Лламаны, какие сейчас есть готовые решения, чтобы скормить содержимое какого-то текстового файла локальной LLM для осмысления и последующего обсуждения? Есть ли вообще в этом смысл с точки зрения производительности (мощного GPU у меня нет), если объём данных достаточно большой?
Сороковку не глушит даже соседняя комната через две закрытые двери, лол.
Возможно, восьмидесятки не насколько громкие, но проверять что-то не особо хочется.
> Так все те что с высоким давлением это как раз сервачные
То совсем высокое уже.
> нет софта, который мог бы отслеживать температуру карты и регулировать обороты вентиля подключенного к материнке в зависимости от нее
Неужели нет либы что могла бы управлять выходом крутиллятора? Если есть то это простой скрипт на десяток строк, если нет то дополнительное устройство, или gpio при наличии. Алсо если вдруг на плате распаян раритет типа com/lpt - можно его пинами произвольно дрыгать и управлять.
> раскошелиться на асетековскую водянку
Лучше купи донора или отдельно охладу, на p40 вроде от 1080 или какой-то ее сестры болт-он вставала. Только уточни информацию.
> на p40 вроде от 1080 или какой-то ее сестры болт-он вставала
От референсной 1080ti. Уже посмотрел на авито ценники и водянка с переходником дешевле получается.
>Видел где-то 3D-модель переходника для двух улиток 40 на 40 на 20
Вот оно: https://www.cgtrader.com/3d-print-models/hobby-diy/electronics/nvidia-tesla-v80-double-fan-intake-4020-fan
27 баксов чувак требует. А нахаляву? :)
> 27 баксов чувак требует
Что за сюрр, такое поделие в любом каде за 10 минут делается, включая заваривание чая
У вас там на селе недостаток изоленты что ли? Можно же вообще мегаколхоз сделать.
>мегаколхоз
Я разогнал самый простой вентилятор 80мм из dns dc-dc преобразователем с 3к до ~8к оборотов.
Даже во время жарения карточки SD 1.5 температура хотспота не поднималась больше примерно ~70.
Беда в том что через неделю у него отъебнул подшипник и даже разбрызгал тончайший слой масла по картонной насадке.
Китаедебил с красной подсветкой.
Есть что-нибудь эффективнее мощного центробежного вентилятора?
Подождите, вы это для рп?!
Ну, типа, я думал, вы для кодинга обсуждаете. =D
Какая разница, негры там или мастер-ветка… Лишь бы кодила нормально…
Тупанул, сорян! =D
Я планировал 120 мм ставить на распечатанный переходник. Хуйня идея?
Плюсую вопрос, короче.
Моя уже на подходе.
>0.5 и rep_pen выше 1.02-1.05
Поставил температуру 0.5 и rep pen 1.05; по сути, ответы лучше не стали. Обсуждаем сокеты на шарпе, хули нет. Весь код от бота выполняется один раз синхронно и сразу освобождает ресурсы, хотя я писал must be run continuously and never stopping. Окей. Прямо требую написать рекурсивную функцию, которая будет работать асинхронно. Ответ убил.
>Unfortunately, the built-in networking library doesn't support async operations out of the box.
Что очевидно пиздёж, асинхронное чтение\запись есть. Во-вторых, можно синхронные вызовы api завернуть в таски и похуй.
>You'd need to use libraries like System.Net.Http or third party libraries
Опять - используй больше библиотек и, возможно, тебе повезёт. Но это не точно.
То есть я буквально знаю, какой код должен быть сгенерирован, но не могу вытребовать его от AI. Пишу - вот, используй эту функцию, окей? Вместо кода он начинает рассуждать о различиях функций в библиотеке, как они работают и что делают. Один раз потерялся в том, на каком языке пишет и свалился на питон.
Есть шанс, что он не выдержит давление и воздух частично выдувать через зазор между лопастями о ободком.
Зависит от переходника и насадки.
Я понимаю что я сам дурак и не стоило этого делать, но или мне кажется или последняя версия угибуги перестала грузить модели, которые раньше грузила с лёгкостью?
Потому вдвойне удивляет цена.
> Есть что-нибудь эффективнее мощного центробежного вентилятора?
Как вариант - возьми из леруа канальный вентилятор не самой плохой производительности. Дешевый, включается напрямую в сеть, относительно тихий, и если сможешь направить весь поток - его должно с запасом хватать.
Оно может быть капризно к инструкциям и формулировкам. Попробуй аналогичное на гопоте, он лучше понимает, хотя код не всегда адекватный.
Какие именно?
Nous-Capybara-limarpv3-34B-5bpw-hb6-exl2 c 16к контекста. Раньше влезала, теперь нет, все мои 70б эксл2 в 3б тоже не лезут. Не понимаю...
Может в экслламе переключили настройку выгрузки и на каком-то этапе не хватает? Попробуй одну экслламу откатить на версию постарше, отпиши что там тогда.
>Потому вдвойне удивляет цена
Ну формально любой может сделать, а по факту мы имеем старого пидора и двух блядей отсутствие наличия модели. На Али готовая конструкция 3,5 тысячи стоит:
https://aliexpress.ru/item/1005005676453819.html?sku_id=12000033980221034&spm=a2g2w.productlist.search_results.0.528457b754Bp51
> Упрощение для хлебушков в ущерб функционалу без каких-либо профитов
Наоборот больше функционала, но в твоем манямирке злой барен просто так тратил время, чтобы сделать еще хуже. Это клиника уже.
> Ничего принципиально нового и уникального
Ты и между миникондой и докером разницы не видишь.
> Выбор моделей только из древнего списка
Сразу обновляют, вчера codellama 70b обновили и добавили новые модели.
> в самых нищих квантах
Вообще-то там есть все от q2 до fp16.
> https://github.com/ollama/ollama/blob/main/docs/import.md
Также можно импортировать любую GGUF модель и не только.
Забавно, как ты уже который пост обсираешься в фактах, уже настолько твоя тупизна затмила мозг, что ты перестал быть объективным и только пытаешься выиграть спор на дваче, да так сильно, что не придумал ничего лучше, кроме как использоваться боевой промт. Жалкий.
Ля, опять батхертнутый сгорел со своей хуеты что пришел сюда ее оправдывать. Брысь брысь, веник!

HALP.
Я чего-то никак не могу понять как заставить переводить в SillyTavern прямую речь правильно.
Всегда переводчик(что гугл что бинд) меняет структуру с "___" на «___».
Может кто знает как лечить. Реддит ответа не дал.
с сторитейлинг треда
Я чего-то никак не могу понять как заставить переводить в SillyTavern прямую речь правильно.
Всегда переводчик(что гугл что бинд) меняет структуру с "___" на «___».
Может кто знает как лечить. Реддит ответа не дал.
с сторитейлинг треда
>Оно может быть капризно к инструкциям и формулировкам.
Тогда не ясно только одно - нахуя оно существует. Код всратый, следования инструкциям ноль, понимания запроса ноль. Дохуя болтологии не по теме.
>Попробуй аналогичное на гопоте
Обходить все запреты, когда у меня даже сайт опенаи корректно не прогружается? Нахуй надо. Я точно знаю, что качественный аи ассистент по коду стоит 10 долларов у майков, там говняка не будет. Сейчас решил погонять 7b дельфина. На запрос асинхронности сразу рассказал об async\await, вкрутил его в код. Но, в целом, заметно туповат, если не тыкать носом в конкретные места, то не понимает, о чем речь, пишет заново то же самое. Но это пиздец какой-то, модель вроде как в пять раз "тупее", но при этом поведение гораздо более предсказуемое, чтоли. Что от неё требуешь - то и получаешь. А потом я рофла ради скормил код из 33b в 7b и второй заметил, что первый создаёт массив и стримридер в цикле, на что я внимания не обратил. Просто, блядь, майндбловинг.
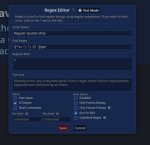
В расширениях regex и там пикрил создай, правда я не ебу будет ли он с переводчиком работать.
А вообще, хули тебе не похуй как он их переводит?
/[“”«»「」「」《》"]/gm
Такой же хренью страдают модели когда заставляешь писать на русском сразу.
> Тогда не ясно только одно - нахуя оно существует
Для того же что и любой другой инструмент, требующий правильно обращения и навыка.
Ту версию модели не тестил, прошлые и кодлламы именно писали код, корректируя его по запросу, а
> Дохуя болтологии не по теме
не было, наоборот комментарии приходилось запрашивать.
> Обходить все запреты
Собрался в кодинге расчленять трансо-негро-феминисток? Какие еще запреты.
> модель вроде как в пять раз "тупее", но при этом поведение гораздо более предсказуемое
Маловероятно, скорее всего совпали форматы и ты действовал более "понятно" для модели, или ей повезло удачно проигнорировать неудачные инструкции. Или какой-нибудь поломанный квант жоры, хз.
В любом случае раз дельфин подходит - его и юзать, тем более быстрый.
Красава
> не похуй как он их переводит
Ломается форматирование

Чувак себе пассивный радиатор сделал, совсем не шумит.
Да мне читать не удобно. Всё одним цветом идёт.
Добра анончик, попробую.
Я просто не могу читать всю ту хуергу которая модель пишет. Когда накуренный, часть эпитетов тупо не понимаю, а лезть в переводчик лёнь... Понять и простить.
Потому что, спойлер, правильно именно «», а кавычки-палочки ставит или ебанутые дауны, или программисты при работе.
У меня для всех этих «ролеплейщиков» с пигмаллиона плохая новость. Они не прогаммируют.
Ваще сочувствую, изначально стали делать неправильно, а теперь оно ломается, что не удивительно. Бяда-бяла.
Пожалуй, я сделаю себе шумный…
Двачую тебя, сам сначала возмущался, но потом привык к кавычкам, похуй стало.
Чет для пассивного херня, ребра слишком частые. Если в такой ориентации - вообще не будет работать и толку с оребрения 0.
Без осуждения, та же хрень
> Всё одним цветом идёт
и при изначальной генерации на русском бывает, актуально.
> изначально стали делать неправильно
Ну правильно-неправильно, а 3 варианта выделения текста (кроме заголовков и подобного) лучше чем 2.
А вам вообще норм читать текст без обозначений действий и "прямой речи"?
Не удобно же.
ну так ради удобства чтения с кавычками и согласился. впрочем, похуй же, не?
Вообще, дело привычки.
Я вообще привык к кратким действиям в звездочках. =)
А так, да, пофиг в общем, че сделаешь.
А на проблему регексом уже ответили.
Понятно.
Да хранит вас боженька.
тревожно, ведь это означает больше сои в грядущей llama-3, и как обычно - неубиваемой, без всяких файнтюнов и DPO, и с ними тоже нет никакой гарантии, челики что делают "uncensored" модели - теперь похожи на индусов что наябывают таблицы лидеров с помощью бенчмарков
про последних имею ввиду что они трейнят саму модель на самом бенчмаркнейм и получают топ результаты в таблице даже с 7B моделью
> ведь это означает больше сои в грядущей llama-3
В кодлламе изначально была эта самая "соя" и никого это не волновало. Если будут выложены веса - это значит что никакой заложенный алайнмент не устоит. Разумеется его наличие это плохо и будет усложнять, но сам факт, даже без файнтюна cfg и правильный промт творят чудеса, если нет полной лоботомии. А когда она есть - модель полное говно.
> челики что делают "uncensored" модели - теперь похожи на индусов что наябывают таблицы лидеров с помощью бенчмарков
Чем похожи? Ты про низкое качество их ранцензуриваний изначально не цензуренных моделей?
Выглядит как рофл.
>или программисты при работе
Я и в жизни ставлю.
Ах да, вроде как "такие" кавычки жрут меньше места, чем «ёлочки», да и для английского они вроде как правильнее. В русском да, по правилам нужны ёлочки двух видов, но всем давно похуй, в интернет ролеплеях только ебанутые и маководы что одно и тоже выёбываются.
>ведь это означает больше сои в грядущей llama-3
Кто-то сомневался, что будет иначе?
>Какие еще запреты.
Ну хуууууй знает, какие ещё запреты.
>раз дельфин подходит - его и юзать
Он тупой, пиздец. Погонял чуть дольше, не подходит. Тут беда в том, что я гонял на том, что знаю сам и оба варианта не удовлетворили. А с тем, чего не знаю, будет ещё хуже, я же поверю этому шизу.
Побаловался с TTS, поначалу ебать, как долго думает. Пришлось добавить два "холостых" запуска генерации текста, потом порезче думает. Нет, модель не выгружается, нихуя такого, в душе не ебу, почему так. Осталось пофиксить отрезание первого слова от остального сообщения и будет неплохо.
>Ну хуууууй знает, какие ещё запреты.
Сейчас бы в 2к!4 не иметь VPN меня же не арестуют, да?.
> Ну хуууууй знает, какие ещё запреты.
А, ты про это. Релоцироваться, принять, обойти, сидеть унывать, вариантов полно.
> Он тупой, пиздец.
7б же, без оптимизации под конкретную задачу, иного и быть не могло.
Хз, создается ощущение что ты их юзаешь неправильно, но может просто дохуя специалист. Готовый проект сетки всеравно не напишут, но автоматизировать многие действия или подсказать популярные решения могут.
И не бери версию под пихона для других языков, она фейлит.
Взяли на карандаш
https://github.com/oobabooga/text-generation-webui/pull/5403
Температуру с отсечкой (ну почти) скрестили, мнение?
Температуру с отсечкой (ну почти) скрестили, мнение?
>мнение
Я ещё для динамической температуры силли не обновил.
Эта работает чуть иначе, немного выравнивая вероятные токены и дропая на дно те что с малой, суть из названия. Действительно может повысить разнообразие текста на мелких моделях сохранив адекватность.
С другой стороны, что-то необычное, где как раз проявлялась душа станет выпадать реже и это может ухудшить рп/сторитейл.
> душа
> рп/сторитейл
Проиграл. В этом кале всегда одинаковый стиль шизоидных историй.
> низкое качество их ранцензуриваний
именно, в пример беру некоего "Undi" что популярен у пендосов в /lmg/, в двух словах - это крайне самовлюблённый додик, много слов и мало дела, обещания пустые.
Мы про кодинг и говорили...
> А зачем ты сетку для кодинга тестировал на подобное?
Так изначальный запрос и был про кодинг, упомянутый тест - это программа, текст на экране, обратная связь от пользователя (нажатие двух кнопок типа да и нет) и измерение разницы между временем ответа.
> они трейнят саму модель на самом бенчмаркнейм и получают топ результаты в таблице даже с 7B моделью
На самом деле это не так плохо, как может показаться. Как минимум, это значит, что если самому зафайнтюнить небольшую LLM под конкретную узкую задачу, то на этой задаче результат будет топовый, на уровне гпт4 или лучше. При том, что работать такая модель будет даже на процессоре.
А как лучше пользоваться этой сеткой? Я только вкатился, кобольд не умеет ведь форматировать код?
Какой этой? Моделей дохуя.
Лучше всего дрочить на эропрозу которой модель срет.
> маководы
Гугли «типографика windows» там будет раскладка Бирмана!
Эт че за треш такой по звуку?
Силеро, что ли? Звучит вроде как даже хуже.
В кодинге на сою похуй. А там тред «ой, негров низзя упоминать».
Как часто ты кодишь неграми?
Да че за отмазы, там жалобы на сою и негров, вы вообще в курсе, что такое кодинг? =D С ЕРП не путаете?
> это значит, что если самому зафайнтюнить небольшую LLM под конкретную узкую задачу, то на этой задаче результат будет топовый, на уровне гпт4 или лучше.
Кэп, ты?
Такое сто лет уже. А топы в итоге непрезентативные совершенно.
———
Итак, судя по всему, моя P40 уже на почте, а я еще переходник не распечатал, и принтер на работе, и у меня выходной, короче, буду дуть самостоятельно.
Ладно, итс тайм думать, нахуя я ее в итоге взял. =)
И буду экспериментировать с виндой. А то линухи да линухи, попса!
Кобольд ХЗ, юзай таверну, она подсвечивает код между ```
нерепрезентативные
> Undi
Он разве что-то дообучает а не только мешает шизомиксы?
> изначальный запрос и был про кодинг
Что-то там было что сетку триггернуло. По запросу они пишет "программу про нигеров" и т.д., но если в контексте появился аполоджайз то будет втирать про это даже не простые вопросы.
> то на этой задаче результат будет топовый, на уровне гпт4
Вот только "эта задача" никому не нужна и в реальности гораздо сложнее чем в бенчмарке.
Действительно из хороших примеров можно микстраль привести, как его надрочили на зирошоты в простых вопросах, действительно пишет складно. Но в чем-то более сложном там унынье.
Здравствуйте, аноны. Какие подводные захостить у себя модель и дать анонам доступ? Как это можно сделать, нужен ли белый IP для принятия запросов?
Кто-то задудосит и для анонов будет неюзабельно. Хз как оно будет работать при множественных запросах. Если используется llamacpp то скорость может снизиться если расщедришься на контекст, ведь при разных запросах он каждый раз будет обрабатываться с нуля.
> нужен ли белый IP
Хватит параметра --public_api или что-то типа такого в убабуге
>Релоцироваться, принять, обойти, сидеть унывать, вариантов полно.
Или забить хуй на гопоту. Погонял дельфина и прямо стойкое чувство, что я с гопотой 3.5 пообщался. Та же хуйня точь в точь.
>ты их юзаешь неправильно, но может просто дохуя специалист
А как их юзать "правильно", лол? Специалист вряд ли.
>Силеро, что ли? Звучит вроде как даже хуже.
Силеро и есть. Вроде, неплохо звучит. Или ты про рандомные паузы? Это границы блоков генерации, чтобы их убрать нужно заползти в питон, а это так мерзко.
А вообще если пытаться делать по-человечески, то можно использовать готовую проксю на спейсах или любом хостинге. Там уже настраивать лимиты, ограничения, очереди. Основная разница будет только что запросы пойдут не к впопенам/антропикам/амазону а к себе. Офк скорее всего потребуются небольшие правки кода прокси.
Профитов в этом, правда, никаких. Расшаренных обычных ллам можно найти в интернете, интересны прежде всего 70 и модель, веса которой не хотят полностью выкладывать.
Если просто хочешь расшарить ограниченному кругу кого знаешь "для попробовать" хватит --public-api
> нужно заползти в питон, а это так мерзко
Стоит только начать, втянешься
Аноны, посоветуйте модель(до 13В)/персонажа/промпт для моральной поддержки. Что-то всякое в жизни происходит, хочется просто вывалить куда-то переживаия, а с LLM ещё и какую-то обратную связь получить можно.
Так-то мне Solar нравится, поумнее 7В, при этом на моём говноПК скорость ответов норм. Хотя, если есть нормальная модель до 30В то тоже сойдёт, подожду ответа.
Так-то мне Solar нравится, поумнее 7В, при этом на моём говноПК скорость ответов норм. Хотя, если есть нормальная модель до 30В то тоже сойдёт, подожду ответа.
Ну ты даешь другим пользоваться твоим компом.
Все.
Какие тут подводные.
Хочешь дать всем? Только кому-то?
Ну, напишут хуйни в логах они, а посадят тебя. Камень?
Это знакомые? Ну, пусть пользуются.
Никаких существенных отличий от «посиди за моим компом» нет, ИМХО.
> Силеро и есть. Вроде, неплохо звучит.
Да вроде раньше было лучше. v4? v3_1 получше говорит. Ну и медленно, вроде он был быстрее. Короче, странности.
Я xttsv2 юзаю, красивее и не сильно дольше. Ну, генерация около 1-2 секунд.
Но на видяхе.
Хоро́ш, идея верная.
Ну, если хочется подзаебаться.
Файнтюны солара хороши, используй их. Промт - карточка в таверне с персонажем, который тебе нравится, все. Можешь отредачить или сделать по аналогии чтобы просто вести разговоры, есть много готовых карточек, думаю аноны подскажут.
20b попробуй emerhyst. 34б с их особенностями врядли подойдут для подобного.
>втянешься
Да нихуя. У меня с табуляций каждый раз жопа горит. И что тело функции должно быть раньше вызова.
>v4?
Да. Хуй знает, может, у меня выбран "спикер" не тот, их несколько, этот вечно вздыхает. Со скоростью проблемы, которые решаются "прогревом", чем дольше генерируешь - тем быстрее работает. Связано с джитом, я пару флагов там поставил, чтобы это ещё ускорить, но помогло незначительно. Плюс воспроизвожу сразу в питоне, если схоронять в файл и играть оттуда, то звучит заметно лучше. Но не то, чтобы кардинально.
>генерация около 1-2 секунд
А силеро, по сути, рилтайм, там около 200 мс реальная задержка, которую нельзя выпилить, перед первой частью генерации. Между блоками внутри сообщения побороть можно. Но хрупкий, пиздец. Подал на вход английский текст? Ну, или промолчит, или вывалит ошибку. Отправил сообщение, начинающееся со знака препинания? Пизда, ошибка. Если это не пробел, с пробелами норм. Числа не читает. И на видяхе медленнее, чем на цпу. Такие дела.
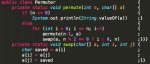
Специально для тебя
Больной ублюдок. Опять же, в питоне это обосрётся, свап вызван раньше, чем определён.
Это не так работает в питоне.
C-задротство это круто, почетно. Но когда так мелочами упарываешься - не видишь всей картины. Потому-то сетки и многие вещи делаются на пихоне, а на си только в высокопроизводительные оконечники.
+
> свап вызван раньше, чем определён
Тут ошибка:
def a(): b()
a()
def b(): print(1)
А тут нет:
def a(): b()
def b(): print(1)
a()
С классами все методы сначала определяются, потом уже ты их используешь, так что нет проблемы.
LLaVA 1.6 уже тестил кто?
Это модель которая текст и изображения жрет.
Это модель которая текст и изображения жрет.
>Это не так работает в питоне.
>сначала определяются, потом уже ты их используешь
О. Буду знать. В такое не вникал, ебанул один файл без классов. С одной стороны, удобно, что можно просто написать хуйни вначале без классов, функций и т.д и это будет вместо конструктора. С другой стороны - всё равно чувствуешь себя уёбком. А я уёбок и есть.
>сетки и многие вещи делаются на пихоне
Да всё оно на сях делается, на питоне просто обвязка. И я не упарываюсь мелочами, i did not! Весь вопрос в удобстве, банально проще накатать отдельное приложение с окошками и табами, чтобы связать LLM c TTS и потенциально с чем-нибудь ещё, чем написать расширение на питоне. Сейчас вот почитал свой код внимательнее и понял, что голосовая часть должна ломаться в десять раз чаще, но благодаря тому, что в инпут пишется втрое быстрее, чем она читает - всё работает. И это при том, что там побуквенная автозамена английского на русский каждую строку ебёт.
Олсо, модель подсирает под себя иногда конструкциями типа
### INSTRUCTION
И ниже дохуя текста, поясняющего ситуацию. Это промпт темплейт отвалился, я правильно понимаю?
Анунаки, че там сейчас топовое по куму на 34-70B моделях? Было что-то новое?
>на 34
Удваиваю запрос
До 34 - Орион
Выше 34 - Микстраль
Всё остальное слишком говно, сливающее даже Yi.
Короче говоря, прикинул я все варианты и заказал водянку с авито за 2к.
Никому не нужно, всем похуй.
> на 34-
> До 34
выглядит интересно
как этот орион запустить на гуфе?
Да я гонял силеру, в курсе.
Пересмотрел твой видос, да, со второго ответа становится побыстрее.
Ну, xenia, вроде, лучше всех там говорит.
Он и на проце быстрый, кстати. Но простенький. Но хороший.
А вот xttsv2 (вообще, это coqui) он забавно делает. Он на русском читает английский — но получается с русским акцентом.
Поэтому на силеру я забил. Легче подождать 1 с ради хорошей речи, да еще и копирования голоса на лету, нежели силерку мучать. Она подходит для зачитывания чего-то супербыстро на калькуляторах.
Они таки выпустили локальную? Я тыкал их облако, че-то вообще не впечатлило.
Мне интересно, но хуйня лютая.
Беда в том, что у них простой клип (кто говорил, что клип лучше блипа — припездываете че-то, я поизучал вопрос, хуй знает, где он лучше, просто немного другой), да еще пожатый в 600 мб.
И никакой разницы между всеми этими моделями нет. Ллава, Бакллава, Yi, и все прочее. Только Cog оригинальный, но там 45 гигов врама нужно, простите, взять неоткуда.
Если ллава-1.6 не подогнала нам новую модель гига на 4 хотя бы — то хуйня по дефолту, сорян.
> Весь вопрос в удобстве, банально проще накатать отдельное приложение с окошками и табами, чтобы связать LLM c TTS и потенциально с чем-нибудь ещё, чем написать расширение на питоне.
Хуй знает, я щас пишу вишпер для бота, чтобы она слышать могла — фильмы там или дискорд, — и на питоне просто накидывается консольное приложение и все. Сомневаюсь, что рисовать гуй к этому было бы лучше.
А че за модель? Может и я возьму, по итогу.
>Если ллава-1.6 не подогнала нам новую модель гига на 4 хотя бы — то хуйня по дефолту, сорян.
LLaVA-v1.6-34B (base model Nous-Hermes-2-Yi-34B)
LLaVA-v1.6-Vicuna-13B
LLaVA-v1.6-Vicuna-7B
LLaVA-v1.6-Mistral-7B (base model Mistral-7B-Instruct-v0.2)
>Короче говоря, прикинул я все варианты и заказал водянку с авито за 2к.
Скинь ссылку, а то что-то дешевле готовых воздушек выходит. Интересно.
>А че за модель?
Мне подвернулась ID-Cоoling frosтflоw 240vgа, но изначально я искал Kraken G12 и любую водянку с асетековой помпой в комплект, они по креплениям идентичные. В прошлый раз для 2080ti я нашел чела продающего G12 сразу с водянкой в комплекте за 3к. Но это надо мониторить.
А вообще, если есть 3D принтер, то проще всего взять водянку с асетековой помпой и напечатать комплект креплений самому, на thingiverse кто-то помнится выкладывал.
А хотя пардон - не заметил, что с авито :) Но за 2к всё равно дёшево. Хороший вариант.
Ты скинул названия их текстовых моделей.
А визуальные-то какие? :)
На текстовые плевать.
> It re-uses the pretrained connector of LLaVA-1.5…
Звучит как та же самая хуйня и дутые тесты.
Хочу ошибаться.
Ну, дождемся квантов и опробуем.
Но я бы посоветовал не сильно надеяться.
>со второго ответа становится побыстрее
По комментариям разработчика, прогрев длится примерно 50 фраз.
Потыкал XTTS v2.0.3, вроде, ничем не лучше силеро результаты.
>зачитывания чего-то супербыстро на калькуляторах
Там можно накрутить 48 килогерц, это уже не особо быстро на калькуляторах. Но основная идея такая и была, чтобы с минимальной задержкой начинать воспроизводить аудио, пока идёт генерация текста. Пока что текст супербыстрый, но если перееду на что-то вроде р40, то он замедлится и в таком подходе будет больше смысла.
>вишпер для бота, чтобы она слышать могла
Так и не победил эту хуйню, качество опознания крайне низкое. Но у него там wer больше 50% на коммон войс, так что хуй знает, может, так и надо. Но это не значит, что я не проебал кучу времени на кручение whisper.cpp
В целом, если более привычен к питону, то почему бы и нет. У меня же в планах много вещей, которые будут крайне неудобны без гуя и\или крайне неудобно реализовывать на питоне.
> Да всё оно на сях делается, на питоне просто обвязка.
Именно, в нужном месте используется наиболее оптимальные для них вещи.
> банально проще накатать отдельное приложение с окошками и табами, чтобы связать LLM c TTS и потенциально с чем-нибудь ещё, чем написать расширение на питоне
Для большинства наоборот, возможно твои привычки играют против этого всего.
> Это промпт темплейт отвалился, я правильно понимаю?
Это или ban eos token включен, или что-то не то с системным промтом, или прожарка температурой отупелого кванта. Или все вместе.
Ничего нового особо, 34б под ерп упоминали вроде.
> Выше 34 - Микстраль
> топовое по куму
Чет проиграл.
И лучше синтии катать кумботов пока не придумали.
Убедись что оно будет охлаждать врм если там колхоз типа водоблока только поверх чипа а не весь плейт.
Попозже надо попробовать. Они хотябы размер проектора до YI довели или все такой же мелкий?
> Они таки выпустили локальную?
Она изначально была локальной.
> Беда в том, что у них простой клип
Не простой, почитай как это работает.
> Только Cog оригинальный, но там 45 гигов врама нужно
12 хватит
> модель гига на 4 хотя бы — то хуйня по дефолту
Если ты про общие веса - какой-то нищукский кринж. Если про проектор - уместно, хотя не обязательно, тут больше проблема в файнтюне.
Алсо даже к нищукам боги благосклонны, есть moondream, который умеет в том числе и нсфв и 2д.
Найс, когда полные веса?
Интересно насколько она ранняя по их заявлениям.
> синтии
Она слишком шизоидная, все эти файнтюны на генерациях ЖПТ-4 - просто попытка сделать биас на конкретный стиль. Все РП-файнтюны страдают тем что у них прибитый гвоздями стиль письма. Можешь протестить как выше анон Ориону говорил менять стиль речи на персонажа, синтия не пройдёт его. И по рандому без скатывания в шизу Микстраль сильно впереди остальных. Да и с ареной глупо спорить, кроме Микстраля никто к Клауде не приближается. По поводу кума - в него умеют вообще все в рп-пресете промпта, уровень извращений зависит только от промпта, просто у кого-то изначально биас в сторону кумерских историй, даже когда не просишь, что не есть хорошо.
> вроде, ничем не лучше силеро результаты.
Ну я даже не знаю… =)
Минус тока в том, что акценты у него рандомное расставляются, канеш.
> качество опознания крайне низкое
Ну, на размере medium уже отличное, ошибок минимум. Вот на base там жесть, конечно. =D
> Но это не значит, что я не проебал кучу времени на кручение whisper.cpp
Я забил на распознавание онлайн, не понравилось мне, как он видяху юзает и как он паузы определяет.
Моделька small дает вменяемые результаты вчетверо меньше по времени. Если резать по 20 секунд, то на распознавание уйдет по 5 секунд. Вроде терпимо, хз.
Рассказуй, как там посылать запросы? :) Я тоже в итоге решил попробовать Жору. Может помнишь, как можно отправлять-получать в сервер чи куда там.
> Она изначально была локальной.
Т.е., Llava-1.6 уже давно можно было скачать? С тех пор, как они ее в облаке повесили тестить всем? А почему написали в треде только сегодня, и файлы помечены сегодняшним числом? =)
> Не простой, почитай как это работает.
Да, почитал, обучали на датасетах, но опять же, датасеты маленькие.
> 12 хватит
А как на 12 запустить? Вот этого я не нарыл, расскажи.
> Если про проектор - уместно, хотя не обязательно, тут больше проблема в файнтюне.
У Кога 11B, у этих 600 чи 900 M, да? Ну, сравнение, сам понимаешь, звучит будто не в их пользу.
4q модель на двух p40 выдает 6.29 т/с на холодном старте, держу в курсе
Ну, революции она не сделала, все жаловались на вотермарку, ну и раз уж ранняя…
Хотелось бы, чтобы они уже дропнули полную, в таком случае. =) Получат лучей любви.



Уговорил, прогнал по классике.
Хм... То ли мои тестовые вопросы утекли, то ли модель реально хороша... Если бы не соя, но тут по классике.
>все жаловались на вотермарку
Ват из вотермарка?
> Она слишком шизоидная
Да ну, вполне адекватная, если не брать лоботомированный квант и не следовать заветам "крутого семплинга для 7б". Может шикарно описывать левд активности с плавным разгоном, слог приличный, плюс достаточно smart, для erp то что доктор прописал. Обычный ролплей тоже хорош, то как "отыгрывает рассуждение" персонажа, воспроизводя cot из тренинга, выглядит достаточно живо и естественно, как ни странно. И там в датасетах синтетическое в основное от коктропиков а не гопоты, это, учитывая заезжанность, в плюс.
> Можешь протестить как выше анон Ориону говорил менять стиль речи на персонажа
Да что тестить, еще с версии 1.2 на ней рпшу/кумлю без проблем по скорости что отвлекали бы, проблем хватает но не те что описывают. Как раз стиль речи и самого повествования/поведения под персонажа подстраивает, он в целом отличается от типичного для рп файнтюнов.
> рандому без скатывания в шизу Микстраль сильно впереди остальных
Что это значит? Он всрат для ерп, он специфичен для рп, он туп на больших контекстах. Как угодно это оправдывать, модель не для этого и т.п., это не важно.
> Да и с ареной глупо спорить
Ну йобана, каждый раз как в первый, особенно тащить это в контексте (е)рп.
> уровень извращений зависит только от промпта
Вот оно че, айда пацаны на викунье ерпшить, она и в арене высоко стоит!
> Т.е., Llava-1.6 уже давно можно было скачать?
Не, то про 1.5 было, про 1.6 в облаке упустил, или она была дженерик что даже не запомнил.
> Да, почитал, обучали на датасетах, но опять же, датасеты маленькие.
Это не "ужатый клип" в исходном виде, датасеты уже какие получилось.
> А как на 12 запустить? Вот этого я не нарыл, расскажи.
Добавить в параметры запуска --quant 4, если 24х гиговый то можно --quand 8. Работает и на обнимордовской и на сатовской версии (8 только на сат, в hf части переписывать придется). При запуске в начале скушает много рам.
> Ну, сравнение, сам понимаешь, звучит будто не в их пользу.
Офк не в их и улучшение может дать преимущество, а превосходство кога очевидно. Просто того на что они заявляются можно достигнуть даже в таких размерах, что можно видеть по другим моделькам, тот же sharegpt. И ее прямое увеличение без норм обучения не даст преимуществ, yi галлюцинирует не меньше чем ллава при более жирном проекторе.
Сколько у тебя обрабатывается большой контекст? Жора что-то совсем грустный и 16к приходится прямо подождать.
> Если бы не соя
Как ты ее получил то, мистралевский пресет? Вон выше соглашается делать бабах для уничтожения нигро-феминисток.
>То ли мои тестовые вопросы утекли
Не, ну точно утекли. Вангую, что трейнили в том числе на данных с загадками.
С молотом тора зато сфейлила, так что модель хуже клода с GPT4, я спокоен.
>мистралевский пресет
Вообще без пресета и контекста, лол. Я все модели тесчу на одинаковых настройках.
мику походу для рп ебли не подходит. Ну и нахуй её тогда.
скажи какую сетку протестить на большом контексте
скажи какую сетку протестить на большом контексте
С ролплеем он был на все согласен.
Да тот же мистраль лик, заодно интересно сколько поместится.
> мику походу для рп ебли не подходит
Довольно условно, если очень хочется то можно, плюс на русском.
>мистраль лик
скажи полное название модели
miqu-1-70b, тот про который и писал
да блять, я её только что удалил

Ебать ты еблан, эту модель могут вообще снести, лол.
> Ват из вотермарка?
Вроде как она постоянно срывается в «я ИИ и не имею чувств», я в треде замечал жалобы.
> Добавить в параметры запуска --quant 4, если 24х гиговый то можно --quand 8. Работает и на обнимордовской и на сатовской версии (8 только на сат, в hf части переписывать придется). При запуске в начале скушает много рам.
Квант 4, вот это ее жмыхнет! Но ладно уж, не буду жаловаться, сам виноват что бомж. Спасибо! =) Попробую.
Только хотел тоже удалять, но ты меня остановил. =D
Хай лежит, кушать не просит.
Нихуя себе! Пойду скачаю, раз такое дело.
Другой анон.
бред. Сейчас бы пытаться что-то из интернета удалять.
Ничего, интернет все помнит.
Тогда любую другую 70. Просто тогда под контекст параметры подбирать придется и не факт что перфоманс будет норм.
> Вроде как она постоянно срывается в «я ИИ и не имею чувств»
Это база ванильного мистраля и многих других моделей, ватермарка должна иначе проявляться как-то. Тоже интересно что там.
> Квант 4, вот это ее жмыхнет!
Да не особо, сравнивал все версии, в пределах рандома. Даже владельцы A100 в 4х битах пускают кучкой чтобы быстрее работало.
Ради успокоения можно в 8 битах, на карты hf версия без проблем дробится, только уже не помню что там надо было поправить.
я хз о чем говорить с моделью на 16к токенов., кроме как секс рп. А мику не может в секс рп.
>Вроде как она постоянно срывается в
Не похоже на вотермарку. Вот если бы на кодовую фразу модель стабильно отвечала "Я из мистральАИ", вот это была бы вотермарка.
Да, там в комментах тоже говорят "yeah report your ethical considerations to my download folder"
>Ничего, интернет все помнит.
С одной стороны да, с другой попробуй ещё найди быстрый хостинг для 40 с лихуем гигов.
>Или все вместе.
Всё возможно, мозги модели выебаны во все щели. Можно, конечно, самому обрезать хуиту, то, бля, откуда-то же она лезет.
>Ну я даже не знаю… =)
https://huggingface.co/spaces/coqui/xtts
Я тут смотрел. Естественно, если брать докрученные модели, то будет лучше. Но на силеро они тоже, наверное, есть.
>на размере medium уже отличное
На лардже 54% wer. по самотестам. Видяху юзает хорошо, там даже поддержка тензорных ядер для ускорения, гонял его в рилтайме, где-то полсекунды-секунда задержка опознания, возможно, даже по моей вине. Паузы и отсечку делал на своей стороне. Хуже всего его метод понимания незнакомых слов, он их тупо заменяет на рандомные.
>Я тоже в итоге решил попробовать Жору.
Виспер.cpp гонял локально, дёргал whisper_full из dll, без серверов.
Всё-таки надо лечить паузы в речи.
>С одной стороны да, с другой попробуй ещё найди быстрый хостинг для 40 с лихуем гигов.
а что, торренты успешно побеждены?
>докрученные модели, то будет лучше. Но на силеро они тоже, наверное, есть.
Я мимо если что, но кажется силеро не открывал код обучения.
А то. Я даже не подумал про них.
> я хз о чем говорить с моделью на 16к токенов
Лол, я тестил просто приказав по шаблону ей делать суммарайз и пересказывать, а на вход загрузил просто копипасту треда. Или с обниморды какие-то доки накидал
> попробуй ещё найди быстрый хостинг для 40 с лихуем гигов
Разве на обниморде есть проверка контрольных сумм моделей? А так гуглдиск/вандрайв, не говоря офк про торренты.
Есть что нового по куму? И что там за геншин модельку я вижу?
>И что там за геншин модельку я вижу?
Чего?
Дошло уже до того что моделькам даже не пишут описание, просто сразу постят таблицу бенчмарков и больше ничего
>силеро не открывал код обучения.
А, таки правда. Новые голоса только на коммерческой основе.
Но все же xttsv2 заметно получше. Но сильно медленнее, да.
И у меня ванила. Просто ей любой голос пихаешь, какой нравится, и все.
> На лардже 54% wer. по самотестам.
Это ж какой квант? О_о
Я пробовал нежатые — там и 5% не было. Только на мелких моделях начинает ошибаться. У тебя явно что-то не так с виспером было.
> Виспер.cpp гонял локально
Да я про то, как запрос надо составлять в сервер (или куда там) виспер.cpp, чтобы получать ответ и уже ответ в своем скрипте обрабатывать. Мне ж не просто в самой проге запускать, там целый оркестр всякого-разного. =) И ллм, и ттс, и анимации, и рутоничат.
> Всё-таки надо лечить паузы в речи.
Слышал, что Силеро умеет в фонетику, или это там делалось. Думаю, если поковырять регекс, можно будет настроить как надо, чтобы не ставил пауз, где не надо.
Или щас, или вскорости, хз.
> Новые голоса только на коммерческой основе.
Тащемта, это основная причина выбора xttsv2 — любой голос, 10-секундным файлом. Мне ж не точные копии нужны, RVC просто избыточна.
Да и хуй с ним. Мистраль подтвердил слив, да. Но он подтвердил что это слив первой альфы, которую рассылали потенциальным покупателям в самом начале, а не текущий Медиум. И квантованая она потому что в модели ватермарки есть, поэтому её квантанули чтоб не палиться через кого слили.
обновленная инфа по
модель - говно.
Держит адекватно вплоть до 8к контекста. Больше не проверял. Но скатывается в лупы как последняя сука.
Я выкрутил пеналти по повторам на максимум - ему похуй.
модель для рп не пригодна, твердо и четко.
2/3 текста в ответах - повтор того, чтьо она уже говорила. За счет этого контекст растет как не в себя. И за счет этого нахуй не нужна её способность прожевывать 32к контекста, если она всрёт 2/3 из этого объема. Заебался глазамит парсить говно это.
модель - говно.
Держит адекватно вплоть до 8к контекста. Больше не проверял. Но скатывается в лупы как последняя сука.
Я выкрутил пеналти по повторам на максимум - ему похуй.
модель для рп не пригодна, твердо и четко.
2/3 текста в ответах - повтор того, чтьо она уже говорила. За счет этого контекст растет как не в себя. И за счет этого нахуй не нужна её способность прожевывать 32к контекста, если она всрёт 2/3 из этого объема. Заебался глазамит парсить говно это.
Вижу в таверне появилась динамическая температура и целая куча новых пресетов. Кто уже тестировал?
Я не понял а какой сейчас лимит на колабе? Они что его до часа сократили или что?
Там новую мейду подвезли но на этот раз пиздатую от хорошего разраба. Говорит карточку держит просто заебись и в целом умница, просит фидбеков. В частности интересует как она может в "плохие" вещи и буллинг потому что кажется у нее есть небольшой позитивити баяс.
https://huggingface.co/TheBloke/EstopianMaid-13B-GGUF
https://huggingface.co/TheBloke/EstopianMaid-13B-GGUF
пока что сижу на норомейде, и там каждая версия хуже предыдущей, возможно, дело в 20В версии, она топовая, остальные какие-то уж очень хрупкие, постоянно нелитературно пишут, залетают в лупы и прочее
Как-то у тебя совсем грустно получилось. Если делать относительно динамичный рп с переходами и т.д. то она даже интересна. В левдсах она не настолько плоха, пытается описывать действия, обстановку, ощущения, но уступает рп файнтюнам.
Автор еребуса работает над моделькой для "романса"
Пока не понятно что именно он имеет в виду но вероятно моделька для "отношений" с вайфу которая больше для ламповых няшканий чем для грязной ебли.
Пока не понятно что именно он имеет в виду но вероятно моделька для "отношений" с вайфу которая больше для ламповых няшканий чем для грязной ебли.

>Это ж какой квант? О_о
Дефолт, но это коммон войс. Посмотрел в датасет, ебать там дичь.
>как запрос надо составлять в сервер
Cервер это обвязка для библиотеки, я его не использовал. А так вот, вроде, всё понятно.
https://github.com/ggerganov/whisper.cpp/blob/master/examples/server/README.md
>чтобы не ставил пауз, где не надо.
Это не его вина, а моего кода на питоне.
Заебался устанавливать зависимости для xtts, в итоге сравнил с силеро.
Конечно, очень хуёво, что нельзя делать свои голоса для силеро.
Кстати там llamacpp в новых коммитах починили при запуске на наскольких современных карточках. Теперь оно работает примерно с той же скоростью как и на одной, или скейлится линейно на том что больше.
Скорость все равно ниже чем в бывшей а жор врам никуда не делся, но по крайней мере норм работает и вместо 0.x-единиц полтора десятка т/с можно получить.
Tess-34-1.5b достаточно интересна. Шиза yi на месте, но она старается сохранить все в пределах разумного и выстраивать четкие связанные ответы с высоким разнообразием. В кум умеет.
Скорость все равно ниже чем в бывшей а жор врам никуда не делся, но по крайней мере норм работает и вместо 0.x-единиц полтора десятка т/с можно получить.
Tess-34-1.5b достаточно интересна. Шиза yi на месте, но она старается сохранить все в пределах разумного и выстраивать четкие связанные ответы с высоким разнообразием. В кум умеет.
стащил с пендосского /lmg/
>===================================================
=== GUIDE FOR EARLY ACCESS TO QUADRATIC SAMPLING ===
>===================================================
There's been an update to both git pull requests in the past hour.
In webui the quadratic sampler has been moved to happen AFTER the Min P sampler instead now which may improve it further.
Instructions to update the pull request patches included.
WEBUI:
1. ./update_linux.sh
2. git fetch origin pull/5403/head:quadratic-sampling
3. git checkout quadratic-sampling
>To update quadratic sampling: git pull origin pull/5403/head:quadratic-sampling
>To return to default: git checkout master
SILLY TAVERN:
1. ./launcher.sh switch to staging branch (or git checkout staging)
2. git fetch origin pull/1766/head:quad-sample
3. git checkout quad-sample
>To update quadratic sampling: git pull origin pull/1766/head:quad-sample
>To return staging or release: git checkout staging or git checkout release
SET SMOOTHING FACTOR TO 0.2 IN SILLY TAVERN YAY BIG HARD COCK
>inb4 windows noobs
Это прикол с новым семплером, действительно делает результат немого лучше, точно не плацебо.
Уже есть в убабубе и кобольде (обязательно для его работы, да и вообще он пока что WIP)
https://github.com/oobabooga/text-generation-webui/pull/5403
https://github.com/kalomaze/koboldcpp/releases/tag/quad-sampling-v1
>===================================================
=== GUIDE FOR EARLY ACCESS TO QUADRATIC SAMPLING ===
>===================================================
There's been an update to both git pull requests in the past hour.
In webui the quadratic sampler has been moved to happen AFTER the Min P sampler instead now which may improve it further.
Instructions to update the pull request patches included.
WEBUI:
1. ./update_linux.sh
2. git fetch origin pull/5403/head:quadratic-sampling
3. git checkout quadratic-sampling
>To update quadratic sampling: git pull origin pull/5403/head:quadratic-sampling
>To return to default: git checkout master
SILLY TAVERN:
1. ./launcher.sh switch to staging branch (or git checkout staging)
2. git fetch origin pull/1766/head:quad-sample
3. git checkout quad-sample
>To update quadratic sampling: git pull origin pull/1766/head:quad-sample
>To return staging or release: git checkout staging or git checkout release
SET SMOOTHING FACTOR TO 0.2 IN SILLY TAVERN YAY BIG HARD COCK
>inb4 windows noobs
Это прикол с новым семплером, действительно делает результат немого лучше, точно не плацебо.
Уже есть в убабубе и кобольде (обязательно для его работы, да и вообще он пока что WIP)
https://github.com/oobabooga/text-generation-webui/pull/5403
https://github.com/kalomaze/koboldcpp/releases/tag/quad-sampling-v1
> С молотом тора зато сфейлила
Я тоже не понял
Аноны, кто-нибудь уже пытался побрить форумы двача на отполированную дату для обучения моделей на нашем родном? Если да, то можно ссылку, чтобы двойную работу не делать? А то в инете нашел только на хаггин фейс дату на 14к rows и та, вроде, не отфильтрованная по дереву ответов, а просто собранные вразнобой посты.
Пробовал кто https://huggingface.co/0x7194633/fialka-13B-v4 ? Файтюненый rugpt большим количеством инструкций.
Квантанул бы её кто...
Я квантанул вчера в gguf. Но я не ролиплейшик, так что хз как она в сравнении.
https://huggingface.co/Sosnitskij/fialka-13B-v4-gguf
Круто! Тогда вечером попробую
> mistral
> РП
Ну, как бы, да, никогда и не работала, вроде.
> Cервер это обвязка для библиотеки, я его не использовал.
А что из них выбирать? Я почти никогда от Жоры не юзал софт, не в курсе его наименований.
Я писал выше, чисто в диалоге она топ, конечно. Но карточки не юзал, как держит роль — не в курсах. Просто у нее хороший русский, безусловно.
Спасибое. А это новый формат, где Q5_K_M ~ Q6? Сам-то я предпочитаю Q6, имеет смысл ее качать вообще, что скажешь?
>имеет смысл ее качать вообще, что скажешь?
не тот анон, но Q5_K_M имхо самый оптимальный вариант качество / размер
Ну я в самые ходовые кватовал.
Allowed quantization types:
2 or Q4_0 : 3.56G, +0.2166 ppl @ LLaMA-v1-7B
3 or Q4_1 : 3.90G, +0.1585 ppl @ LLaMA-v1-7B
8 or Q5_0 : 4.33G, +0.0683 ppl @ LLaMA-v1-7B
9 or Q5_1 : 4.70G, +0.0349 ppl @ LLaMA-v1-7B
19 or IQ2_XXS : 2.06 bpw quantization
20 or IQ2_XS : 2.31 bpw quantization
10 or Q2_K : 2.63G, +0.6717 ppl @ LLaMA-v1-7B
21 or Q2_K_S : 2.16G, +9.0634 ppl @ LLaMA-v1-7B
23 or IQ3_XXS : 3.06 bpw quantization
22 or Q3_K_XS : 3-bit extra small quantization
11 or Q3_K_S : 2.75G, +0.5551 ppl @ LLaMA-v1-7B
12 or Q3_K_M : 3.07G, +0.2496 ppl @ LLaMA-v1-7B
13 or Q3_K_L : 3.35G, +0.1764 ppl @ LLaMA-v1-7B
14 or Q4_K_S : 3.59G, +0.0992 ppl @ LLaMA-v1-7B
15 or Q4_K_M : 3.80G, +0.0532 ppl @ LLaMA-v1-7B
17 or Q5_K : alias for Q5_K_M
16 or Q5_K_S : 4.33G, +0.0400 ppl @ LLaMA-v1-7B
17 or Q5_K_M : 4.45G, +0.0122 ppl @ LLaMA-v1-7B
18 or Q6_K : 5.15G, +0.0008 ppl @ LLaMA-v1-7B
7 or Q8_0 : 6.70G, +0.0004 ppl @ LLaMA-v1-7B
Вот данные по приплексии. Формату то уже много времени но я знаю что там небольшие правки всегда делают, квантовал последней версией llamacpp так что и формат последний со всеми правками.
Угу, выглядит так, будто Q6 прям почти не имеет смысла, спасибо!
Лучше чем мин пи?
> точно не плацебо
Пока по обилию тряски напоминает min-p, тот же автор?
> GPT2LMHeadModel
Сколько не тренируй, выше головы не прыгнешь
> новый формат, где Q5_K_M
Этому "новому формату" уже наверно пол года или больше.
> Этому "новому формату" уже наверно пол года или больше.
Полгода назад было 27 января, понял тебя. =)
———
Короче, пришла P40. Можно вторую брать, как грится… P40-куны, поделитесь — стоит ли ее разбирать, менять термо-интерфейсы, если на ней нихуя-себе-пломба какая-то зачем-то?
Как назло, память стала отваливаться, по гарантии оранжевый магазин менять отказался (точнее, технари производителя памяти, планки ушли им на проверку), мол «вы использовали XMP-профиль, а это разгон и снимает гарантию». На что я ответил «в названии и описании указано 3200, а память в стоке 2666, значит вы мне привезли не тот товар, вертайте деньги». Магазин подумал-подумал и согласился.
Так что буду сервак пересобирать.
Думаю, теперь нужна материнка на два PCI-e (а лучше три, мухахаха, чтобы еще чисто графику можно было крутить), а памяти, наверное, 64 хватит? Раз уж все гонять буду на видяхах со временем.
Собирать на DDR5 че-то дорого дохуя, 1 планка на 48 гигов с частотой 6000 — 20к рублей. Лучше уж пусть будет пока древний компик на ддр4.
>термо-интерфейсы
У меня они пришли в хорошем состоянии, как будто её отпидорасили перед продажей.
>нихуя-себе-пломба
У меня приехала без пломб.
> Полгода назад было 27 января, понял тебя. =)
Ты что несешь, поехавший?
K-кванты появились вместе с ggml v3, в конце весны - начале лета прошлого года. Херня что ты притащил называется иначе, в буквах запутался?
Кайф, что отмытая. Но пломба меня удивила. То ли они вообще ее с завода не разбирали, то ли просто ляпнули сверху свою.
Ладно, буду просто по температурам смотреть, спасибо.
Так это ты поехавший, где я сказал про кванты? :) Я сказал, что в последних версиях Q5_K_M квант по перплексити приближается к Q6. Завезли это недавно.
И судя по табличке, что скинул автор кванта, все нормусь, Q6 можно не качать, профита немного.
Что ты там себе напридумывал — не знаю, какие новые кванты ты изобрел, понятия не имею. Я говорил про перплексити, как простейший способ сравнить потери при квантовании. Читай внимательнее прост.
Как доходит до ебли все нейронки слудуют единому шаблону с нулевой вариативностью.
Ребята, если что, у нас на борде есть тред по звуку. Тут это оффтоп. Спасибо за внимание.
Ты не программист просто. Там суть в том, что молот такой неприподъёмный из-за каталога node_modules, который вечно тяжёлый в смысле файлов. Пока только клод 2 и гпт 4 предлагают среди вариантов правильный ответ, так что использую этот тест для определения самой умной сетки.
>тот же автор
Таки да, каломаз говорящий ник.
В чём отличия между HF и простой эксламой?
>Ты не программист просто.
Охуел? Я плюсовщик, а не мусорщик
В HF больше семплеров поддерживается.
>Я плюсовщик
Ебать, я думал динозавры вымерли уже.
Нет, ты, блин, всё таки на драку нарываешься!
>плюсовщик
Ну ты мразь! Скорее бы уже ввели расстрелы за использование С и С++
Мы вас всех переживём!
Жаба-животное, спок
Huge LLM Comparison/Test: Part II (7B-20B) Roleplay Tests
https://www.reddit.com/r/LocalLLaMA/comments/17kpyd2/huge_llm_comparisontest_part_ii_7b20b_roleplay/
Раскрыл тебя, имеешь расписание пару раз в неделю сначала обосраться а потом развивать шизу.
Какие таблички, какое перплексити, братишка спросил про 5_K_M а тебя куда-то понесло, скорее уже в дурку угоди.
Позволяют себя ебать?
Лол, действительно.
Помимо семплеров еще cfg, негатив, логитсы.
Старые.
> Старые.
Где есть сравнение более новых?
От того же автора вроде новые были, он ими постоянно срет. https://www.reddit.com/r/LocalLLaMA/comments/1af4fbg/llm_comparisontest_miqu170b/ например
Воспринимать их следует с изрядной долей критики, но он хотябы примерно расписывает методику и критерии оценки.
А возможно ли вообще расквантовать мику70b с дорисовыванием чисел до 16 бит и дообучить?
Ждать файнтюны на базовость и рп?
Ждать файнтюны на базовость и рп?
Зачем? Ты думаешь этот ранний огрызок Медиума лучше станет? Микстраль во всём лучше, чем эта альфа-версия.
> расквантовать
Можно https://huggingface.co/152334H/miqu-1-70b-sf
> с дорисовыванием чисел до 16 бит
Не, поупражняться в техниках офк можно, но результат не будет как с оригиналом
> и дообучить
Дообучить можно, но качество сомнительное. С одной стороны стартовать с подобного лучше чем с ничего, с другой градиентам пиздец.
Из наиболее оптимистичного что можно ждать - официальный релиз полных весов.
> Микстраль во всём лучше
лол
Кому не похуй на эти шизоидные тесты на немецком.
> официальный релиз полных весов
С чего бы им их выкладывать? Как сольют актуальную модель, так и приходи с такими фантазиями. Они от этого недотрененого слива только пиар получают, чтоб нормальный медиум покупали.
Так после медиума они сделают ларге, который скорее всего будет MoE 8х70, а там уже можно и простые 70B слить.
> который скорее всего будет MoE 8х70
Слишком жирно, даже ЖПТ-4 меньше. Максимум 8х13В будут делать, актуальный медиум не сильно дальше микстраля ушёл. Вон мику буквально во всех тестах сосёт по скорам у микстраля, в том числе и в рп-тестах шизиков. Не понятно что за хайп пошёл от посредственной модели, её ещё и тренили похоже пол года назад.
>даже ЖПТ-4 меньше
Лолвут?
>Не понятно что за хайп пошёл
Все надуются на то, что это подтолкнёт мистралей на выпуск полной модели.
> Как сольют актуальную модель
> с такими фантазиями
Фантазии - это шиза про то что мистраль топ и чрезмерно завышенные ожидания от не самой крупной команды. Слив может быть как раз относительно актуальной, ничего другого кроме "пук среньк старая версия неактуально все гораздо лучше" в реакции на подобное они сказать и не могли.
> чтоб нормальный медиум покупали
Даже при наличии открытой модели в сети у них будут покупать, с подключением. Мало того что услуги готового сервиса востребованы, так еще и лицензию сделают некоммерческую, и соси бибу. А со всего развития опенсорса они буквально напрямую к себе все бенефиты будут.
Хотя, учитывая сколько времени, действительно МОЕ из нескольких 70 может быть готов.
> Слишком жирно, даже ЖПТ-4 меньше
По заявлениям и околооффициальным данным он меньше.
> шиза про то что миКстраль топ
Фикс
> Лолвут?
Как минимум ЖПТ-4 Турбо сильно меньше оригинальной. Там точно даже 200В нет. 8x20B - это вполне реальные цифры, если судить по тому что сейчас могут 34В от васянов.
> это шиза про то что мистраль топ
Т.е. слепые тесты уже не катят? Что ещё нафантазируешь?
> ничего другого кроме "пук среньк старая версия неактуально все гораздо лучше" в реакции на подобное они сказать и не могли
Чел, по скорам между мику и реальным медиумом - пропасть. И вообще нет ни одного подтверждения что это модель мистраля, кроме слов самих французов. Они могли бы просто промолчать, один хуй оно слишком всратое чтоб его после тестов кто-то мог за медиум принять.
Тут это, классик, маэстро, титан, автор Голиафа выложил:
https://huggingface.co/alpindale/miquella-120b-gguf
https://huggingface.co/alpindale/miquella-120b-gguf
> шизомикс
И зачем?
> Т.е. слепые тесты уже не катят?
Давай проведем слепой тест острых соусов и будем заставлять тебя употреблять 5 победителей вместо воды. Заодно при проведении нужным образом обустроим подачу, чтобы в лидерах оказались самые мерзкие и химозные.
На серьезных щщах утверждать универсальную топовость микстраля и викуньи может только поехавший шизик, взор которого искажен религиозной верой.
> по скорам
Каким скорам?
> нет ни одного подтверждения что это модель мистраля
> кроме слов самих французов
Блять в голосину
Воу воу, полегче блять ну это реально повод скачать и пустить
> Заодно при проведении нужным образом обустроим подачу, чтобы в лидерах оказались самые мерзкие и химозные.
Т.е. то что в лидерах сидят гопота и клауда - это пиздеж и хуёвый тест?
> универсальную топовость микстраля
Микстраль как раз и хорош универсальностью. Это у рп-шизиков какая-то фанатичная религия кума, они даже не могут объяснить в чем этот кум выражается, разве что могут указать на выдаваемое количество описаний и бесконечные потоки эпитетов. При этом отлично видно, что файнтюны на датасетах с биасом в конкретную тематику очень сильно ломают универсальность.
То что ты пляшешь туда-сюда и пытаешься представить дерейлы в виде аргументов - забавно, но это так не работает. И тем более не сделает лучше херню, которая стала для тебя иконой.
> универсальностью
Которой нет. Если немного утрировать то это буквально модель-хайпожор и сладкий пряник для неграмотных но верящих в себя шизов. Причем и никакую конкуренцию полноценным решениям составить оно неспособно.
Уже само появление специальной олимпиады и подобного треша в казалось бы технической и даже околонаучной области - знак того что все скатывается не туда.
Нейросеть, посоветуй, как украсть и не сесть в тюрьму?
Стать депутатом.
Ты раскрыл себя, чел. =)
Я спросил про квант, какой взять.
Раньше Q5_K_M был хуже, но теперь его жмыхает меньше, разрыв между Q6 и Q5_K_M уменьшился.
Как квантовал автор я не знаю, спросил, получил ответ. Вот и все.
А у тебя опять шиза разыгралась, ты стал путать, говорить о братишке, который спросил (я и спросил), спрашивать про таблички (в репале тебе была ссыль на табличку), и посылать меня туда, куда тебе самому бы лечь полежать.
Без негатива, пей таблеточки, ложись в больничку, приходи в себя. Добра тебе. =)

https://huggingface.co/liuhaotian/llava-v1.6-mistral-7b
Это можно ли как то на кобольде запустить или угабуги? Что то у меня одними ошибками сыпит.
Это можно ли как то на кобольде запустить или угабуги? Что то у меня одними ошибками сыпит.
Во всем или не во всем, но в общем выигрывает, да.
> Слишком жирно, даже ЖПТ-4 меньше.
Кайф, инсайдеры в треде, рассказывай. =)
> По заявлениям и околооффициальным данным он меньше.
А можно ссылочку?
Ну так вроде, речь не о турбе.
> Т.е. то что в лидерах сидят гопота и клауда - это пиздеж и хуёвый тест?
Конечно, гопота же 20B, околоофициальные данные, камон.
Ну что ж, вот это можно и попробовать!
Убабуга может, но ограниченно и с командами, насколько я помню. multimodal pipeline и только некоторыми загрузчиками.
Котаны, какая моделька из больших самая умная?
Гопота 4

https://colab.research.google.com/github/oobabooga/text-generation-webui/blob/main/Colab-TextGen-GPU.ipynb
Вот допустим на колабе тут запустить? Но я получаю эту ошибку.
Из локальных
>8x20B - это вполне реальные цифры, если судить по тому что сейчас могут 34В от васянов.
Какой-то коупинг размером с галактику.
>кроме слов самих французов
А что тебе ещё надо?
Укради сладость у ребёнка. Меня вот до сих пор не посадили, украл 24 года назад!
> А что тебе ещё надо?
Так это тот чел ныл что французы пиздят про устаревшую модель. Это надо у него спрашивать что ему не хватает.

Вы тут совсем запутались в ментальной эквилибристике и кто чего подразумевает.
Хватит чтобы покумить?
Ты как собрался кумить с 0.5 т/с? Пока ждёшь ответа уже можно передёрнуть на что-то другое.

>Ты как собрался кумить с 0.5 т/с?
8 т/с, позвольте.
Что-то неочень
А может и очень даже очень
как вы с этой капчей живете
как вы с этой капчей живете
Я не шарю за коллабы, и мне лень вспоминать как она на убабуге запускается. В свое время, когда я хотел запустить на ней, у меня не вышло (я тупил с запускаторами), а когда разобрался — уже гонял из под жоры.
Для старой команды нужно было в CMD_FLAGS.txt дописать --multimodal-pipeline llava-v1.5-13b, например.
И если я помню, это работает только на llama.cpp и еще чем-то (может AUTO-GPTQ?), я не нашел таблицу поддержки сходу.
Но, правда, я не шарю за коллабы, сорян.
> А что тебе ещё надо?
Да, пф, всего лишь слова разрабов!
То ли дело околоофициальная инфа о размере чатгопоты. =)
// Не, конечно, разрабы могут пиздеть, но тут у них нет особой причины. Ну слили альфу и слили, она чуть лучше Llama-2, но не супер, как бы и пофиг. Признали и признали. Ни жарко, ни холодно, по большей части.
> 138 layers
> TRUNCATION 4096
Ну… ) Если только быстро. ;)
> Но у все все равно ничего не получится-ня!
Всхрюкнул.
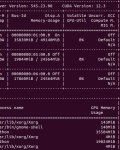
>Если только быстро. ;)
Не беспокойся, хватит надолго
Какие забавные тут аполоджайзы. Но буквально забор в чистом поле. Сраные очепятки, модель умнее пользователя.
Простой путь запуска - дефолтный через трансформерс что расписан, если нехватает vram - добавь with torch.no_grad(), load_in_8bit и подобное.
Чуть ложнее но эффективнее - с помощью ванильной llamacpp, переводишь модель в gguf порезав на llm и проектор, и с помощью server(.exe) крутишь, есть суперминимальный веб-гуи и нормальный api.
Можно и через убабугу, сам поищи мануалы.
Тебе для каких задач надо?
Позитивный bias, но если исправить опечатку в хозяине то отвечает охотно и без аполоджайзов.
> позволяю себе сесть ему на голову
> позволяю себе сесть ему на голову
Локальный клод 1 с порезанным контекстом, может даже лучше.
Закупайтесь P40 или чем поновее, q3 (он всетаки похуже) может влезть в 3 штуки.
Может инициативные ребята и 70тку вытащат до возможности обучения или вдруг сами выложат, Vive la France!
В таверне с рп форматом отлично работает.
https://huggingface.co/alpindale/miquella-120b-gguf
Закупайтесь P40 или чем поновее, q3 (он всетаки похуже) может влезть в 3 штуки.
Может инициативные ребята и 70тку вытащат до возможности обучения или вдруг сами выложат, Vive la France!
В таверне с рп форматом отлично работает.
https://huggingface.co/alpindale/miquella-120b-gguf
Выглядит как говно, если честно. Даже 7В в такие идиотские простыни сможет.
Ну конечно. 7б уже давно научились работать с промтом полностью на русском языке и сразу на нем же отвечать без подсказок. Могут выполнять серию задач на воспоминания, отыгрыш, совмещение различных областей, не потеряв очередность и не улетев в шизу. Умеют долго хранить ранние указания и в более менее художественное повествование на великом и могучем без запредельной концентрации надмозгов. Хорошая и четкая работа без регулярных вылетов потрохов ###instruction: user personality: perverted
Хотя точно же, клода ведь давно была побеждена, тогда неудивительно.
P40-куны, скажите, а что, на ней питание — обычное процессорное? Можно воткнуть 8-pin и все, будет работать? Полярность та же?
Или обязательно использовать переходник комплектный?
> 7б уже давно научились работать с промтом полностью на русском языке и сразу на нем же отвечать без подсказок.
Ну да, я мистраль 2 так и юзаю.
> воспоминания, отыгрыш, совмещение различных областей, не потеряв очередность и не улетев в шизу
Да.
> более менее художественное повествование
Более — точно не сможет. Очень менее.
> Хорошая и четкая работа без регулярных вылетов потрохов ###instruction: user personality: perverted
Естественно.
У Мистраль 0.2 проблемы только с какими-то специфическими словами на русском и персонажами — она их попросту не знает.
А так, вполне соответствует тому, что ты написал.
В скриншоты особо не вглядывался.
Ясное дело, что именно так 7B не сможет, но и тут шедевра пока не видно, ИМХО.
Ты давай за коннектор ответь, может знаешь. =)
Или обязательно использовать переходник комплектный?
> 7б уже давно научились работать с промтом полностью на русском языке и сразу на нем же отвечать без подсказок.
Ну да, я мистраль 2 так и юзаю.
> воспоминания, отыгрыш, совмещение различных областей, не потеряв очередность и не улетев в шизу
Да.
> более менее художественное повествование
Более — точно не сможет. Очень менее.
> Хорошая и четкая работа без регулярных вылетов потрохов ###instruction: user personality: perverted
Естественно.
У Мистраль 0.2 проблемы только с какими-то специфическими словами на русском и персонажами — она их попросту не знает.
А так, вполне соответствует тому, что ты написал.
В скриншоты особо не вглядывался.
Ясное дело, что именно так 7B не сможет, но и тут шедевра пока не видно, ИМХО.
Ты давай за коннектор ответь, может знаешь. =)
Спасибо! У модульного биквайта проблем с коннекторами нет. Ща попробую подключить напрямую.
> Ну да, я мистраль 2 так и юзаю.
Кажется мы это не так давно уже на "стриме" видели. Действительно работает идеально и нет никакой разницы, а лезущий каждое 4е сообщение системный промт был очень кратко написан на русском.
Ну рили кмон, я ж специально его скачаю и покажу что там все грустно. Офк требовать подобного от 7б модели при текущем уровне развития - глупо, за то что они умеют уже надо благодарить и восхищаться.
> но и тут шедевра пока не видно
Тут речь не про шедевры а про сами возможности, чсз за все время ни разу не потребовался реролл. Пожалуй, одна из первых моделей с которой можно полностью рпшить или что-то делать на русском языке с высоким перфомансом, пониманием и без заметной деградации. Хотя может деградация и есть но не заметна.
> Ты давай за коннектор ответь, может знаешь. =)
Сразу же ответил, берешь удлинитель 8pin eps, например погугли CA-8P-04, и подключаешь с его помощью. Если у бп разъем не раздваивается а совсем отдельный - можешь напрямую, там именно он. Но если там не чистый 8пин а 4+4, то на некоторых карточках может не влезть, там в корпусе узкая прорезь под защелку - просто юзаешь переходник.
> просто юзаешь переходник
Удлинитель офк. Самый простой, любители игросральных "красивых" корпусов помогут обеспечить любые разъемы.
Накрайняк сгоняй на барахолку, набери жгутов от модульных бп и сам спаяй нужное.
Там был контекст 256 и макс_токен 64. =) Ну это ж не пример.
> Пожалуй, одна из первых моделей с которой можно полностью рпшить или что-то делать на русском языке с высоким перфомансом
А чем лламы-2-70Б были плохи? РПшить не умели? Русский они держали хорошо.
Ну, не знаю, может с остальным были проблемы, окей, я их использовал как ассистентов в краткой серии вопрос-ответов.
Ладно, это у тебя 120B в видяхе, хули я выебываюсь, может на практике она и правда воспринимается иначе, чем я по диагонали по текстам пробежался.
———
Короче, я почитал доки, мой БП выдает 12V*21А=252 ватта по линии проца. Решил не рисковать и не ужиматься в одну линию, и подрубил переходником все же. Зато две линии по 26 ампер (пусть она их и поделит со второй видяхой).
Спасибо за советы, буду знать, что можно и на проц вещать. =)

> я ж специально его скачаю и покажу что там все грустно
Ладно, оно превзошло ожидания, с брата Вана, легкого ланча машины и амд-терапии хорошенько проиграл, такой-то _soul_.
Веса фп16 без квантов, семплинг simple-1, действительно никакой разницы.
Разбирая по частям - с русским уныло (хотя по сравнению с тем что было в голой лламе 7б этот просто полиглотище). Някать иногда забывает, от Чоколы там нет и следа, хотя если спросить модель на инглише - их хорошо знает. По заданию все выполнено, это плюс, хотя в деталях ерунда. За сцену секса - просто выдает какой-то дефолт вообще не относя к контексту, буквально нет ничего про персонажа и все крайне абстрактно. Достаточно типичное поведение для 7б мистралей и их файнтюнов. Это офк лучше чем просто ловить затупы и поломки как на старых моделях когда они не понимали, ведь формально запрос выполнен а качество в сделку не входило. Собственно дефолтный мистраль, модель будто понимает свои лимиты и пытается в их пределах отвечать, но чудес там никаких нет.
> Там был контекст 256 и макс_токен 64.
Не смертельно, хотя вот если бы туда входил какой-нибудь рофловый суммарайз на 64 токена - это был бы номер. При должном исполнении можно почти что угодно норм приподнести, там как раз можно рофлить с алиэкспрессного перевода. Добавить ей мемов про нефритовый стенжень, ВЕЛИКИЙ XI и МОЩНЫЙ YI ТЕКСТОВЫЙ МОДЕЛЬ 6 МИЛЛИАРД НАСЕЛЕНИЯ, и сидеть проигрывать.
> РПшить не умели?
С горем помолам могли, любой мистраль из коробки лучше рпшит чем сравнимая ллама (кроме мое разве что).
> Русский они держали хорошо.
Не начинает отвечать на русском если не запросить, может указать что не знает русский и потребовать писать на инглише, плохой слог, деградация перфоманса - если в инглише ощущаешь что 70б то при попытках играться на русском оно быстро деградирует чуть ли не до 13б. На файнтюных некоторых с этим лучше, но всеравно. Тут просто такого по ощущениям действительно нет. Голиафа стокового не тестил, возможно там тоже все лучше.
> мой БП выдает
Что за бп? Если примерно современный и сечение проводов позволяет то можно вешать, тем более в ллм они поменьше потребляют и использование не 100% времени.
Попробовал погонять видяшку в Cougar Duoface Pro (не осуждайте), температура начинает сбрасываться на 55° по ядру и 65° по хотспоту. До них почти не падает.
Так же подогревает 4070 ti, которая выше.
По ваттам выдала 185 максимум, что хорошо.
Блиц-вывод: P40 не такая горячая в текстовых, но и продувать кулером на 1100 оборотов ее явно не выйдет. =D
Опыт и тест, она рабочая.
Уф, ну можно и вторую брать, а то вон, у кого-то три штуки, а я бомжую.
Так же подогревает 4070 ti, которая выше.
По ваттам выдала 185 максимум, что хорошо.
Блиц-вывод: P40 не такая горячая в текстовых, но и продувать кулером на 1100 оборотов ее явно не выйдет. =D
Опыт и тест, она рабочая.
Уф, ну можно и вторую брать, а то вон, у кого-то три штуки, а я бомжую.
BeQuiet Straight Power 11 850W Gold.
Да по идее 185 видяхи + 65 ватт проца вполне уместится в 252 ватта по линии проца и еще с PCIe Slot частично будет браться.
Но и рисковать не хочется. =)
> погонять видяшку в Cougar Duoface Pro
Просто голую на том что продуют корпусные вентиляторы? Там же вообще почти не будет потока через нее.
> а то вон, у кого-то три штуки, а я бомжую
Не стоит на всяких фриков ориентироваться, может он чужие поназанимал для теста. если тебе показать дальнюю/труднодостижимую перспективу - станет легче или наоборот?
На паре p40 можно комфортно нормально катать большие модели. Жора llamacpp починил, комбинация p40 с более новыми карточками будет работать прилично и даже шустро.
> BeQuiet Straight Power 11 850W Gold
Правильно, на pci-e вешать смело. Если перегрузить линию CPU то есть риск поплавить 8пиновый разъем в самом бп.

Какая же сетка 7b базовая. оч приятно когда собирают годный датасет. Еще датасет чайной нашел. Пока эти унди-хуюнди мержат лиму норм поцы делают норм мейду и чайную.
Продублирую тут research тред какой то мертвый.
Подскажите зачем столько фреймворков на обучение lit-gpt, EasyDeL, PEFT, ну и другие просто десятки разных вариантов.
Второе как все таки что то обучить на tpu в коллабе, ведь там как я понял допотопные драва на TPU, jax новый не работает, другие библиотеки пробовал тоже косяки они хотят TPU VM, в коллабе его нет.
Подскажите зачем столько фреймворков на обучение lit-gpt, EasyDeL, PEFT, ну и другие просто десятки разных вариантов.
Второе как все таки что то обучить на tpu в коллабе, ведь там как я понял допотопные драва на TPU, jax новый не работает, другие библиотеки пробовал тоже косяки они хотят TPU VM, в коллабе его нет.


Сразу нахуй, бесполезная хуйня не знающая лора самой лучшей кошковселенной в игровой индустрии.
>ходязином
Чел...
> бесполезная хуйня не знающая лора самой лучшей кошковселенной в игровой индустрии
Мистралем добро не назовут
> Чел...
Не трясись
А вы зарабатываете этой хуйней, или ради чего ваще этот шум весь?
Да, в дискорде продаём курсы по локальному кумингу. Деньги такие себе, но 10к баксов есть в месяц, лохи пока доятся.
крууууууууто!!!
тоже хочу за беслпатно хуйней в интернет страдать
Ну так ты забесплатно и страдаешь. Тебе ж никто не платит.
Пришел к успеху, получается.
Поясните отличия методов квантования.
Зачастую пишут:
Q5_K_S large, low quality loss - recommended
Q5_K_M large, very low quality loss - recommended
Q6_K very large, extremely low quality loss
Q8_0 very large, extremely low quality loss - not recommended
Насколько существенна разница между Q5_K_M и Q6_K? Есть ли смысл использовать Q8_0, или они будут работать медленнее (где-то читал такое) при неощутимом выигрыше в качестве?
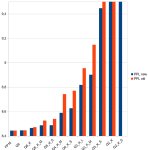
>Q5_K_M и Q6_K
Вот картинка со сравнением перплексити на старом и новом методе квантования gguf.
Положняк для сравнительной оценки такой: q2 параша, q8 лютая база.
Почему контекст так ебет перформанс?
Потому что Жора.
Потому что нужно провернуть весь фарш входящих данных через всю нейронку, очевидно же.
так и ты постишь хуйню в интернете за бесплатно, сечешь?
Вот этот господин прав, особенно актуально если выгружена только часть слоев.
Если вышел за лимит контекста в таверне то каждый раз оно будет полный обрабатывать, были решения чтобы эту проблему сгладить.
> были решения чтобы эту проблему сгладить.
Расскажи подробнее?
Суммарайз, вектора или кхрома?
Все вместе выдает кашу.
Все вместе выдает кашу.
Иронично, что если бы кто-то из нас работал на фабрику троллей, то это было бы не так.

Вот скачал я кобольда, накачал моделей всяких, работает, прикольно. Но вижу в других тредах, что хвалят клауда2. А клауда локально нельзя скачать? И вот эти модели с хаггинфейса это что вообще, чьи они?
> А клауда локально нельзя скачать?
Можно, разрешаю.
Чет мне начинается казатся что мин п режет креативность даже на малых значениях
А ты температуру в 4 поставь.
Ща попробую
А цфг скейл вообще рабочая тема? Я проверял вроче чето делает, но не знаю сколько выставлять.
>анценсоред
>>dolphin
Это не она разве?
Нужен прежде всего для негативного промта, он работает. Ставь 1.5 как рекомендуют.
А там как в примере делать "так пиши так не пиши" или можно че угодно?
Там ты даешь инструкции которые не должны выполняться. Но можешь попробовать и что-то другое, отпиши по результатам.
Спасибо за гуф! Сильных отличий от оригнальной rugpt особо не заметил за короткий тест.
Сперва тестил при температуре 1.0 и ужаснулся от количества языковых ошибок, затем понизил до 0.75 и все стало практически идеально, ошибок практически нет. Но проблемы оригинала остались - периодически путает персонажа и юзера, забывает историю, противоречит себе, выдет лишние подписи к диалогу.
А еще на скрине мой эксперимент от другой модели - просьба каждый раз давать ответ в 3-х предложениях. Изначально тестил с микстралем на русском, может и тут тоже дало бонус.
> 87
Смысла в таких тестах чуть меньше чем нисколько.
Слог печальный с постоянным повторением слов и короткими предложениями. Хотя в качестве отыгрыша типикал [] пойдет, очень похоже.
> просьба каждый раз давать ответ в 3-х предложениях
> в имени персонажа
В чем космический эффект такой постановки?
Микстраль на русском давал очень короткие ответы без данной конструкции в середине и конце контекста. И в итоге, скатывался к однообразным ответам уровня "Я не знаю, может быть." С данной установкой ответы стали длиннее, не не перестали быть скучными.

>Алсо даже к нищукам боги благосклонны
Пха! Нищуки на процессорах и оперативках гоняют йоба модели, которые пользователям 3070ti и не снились. Просто есть ТУПЫЕ нищуки, которые на своих престарелых затычках пытаются модели гнать, вместо того, что бы перекатиться в cpu+озубогизм

>1 токен в секунду.
Двачую, прямо сейчас запущен mixtral-8x7b-instruct-v0.1.Q8_0.gguf чисто на CPU, жрет 54 гига RAM. 3060 отдана на генерацию картинок в SDXL для иллюстрации сюжета + xtts тоже на GPU.
Отправляешь email своей модели, она тебе отвечает через день.
0,7, попрошу!
Ну это база, кстати.
Там 3 токена/сек должно быть, полагаю.

1,82 токенов в секунду на llava-v1.6-34b.Q4_K_M на 32 гигах озу.
Ебало долбаёбов чатящихся с 13b моделями на 3070 представил?
> Ебало долбаёбов чатящихся с 13b моделями на 3070 представил?
Кто-то реально так делает? Я думал или спарка 3090х2 на эксламе, или выгрузка кубласом...
>3060 отдана на генерацию картинок в SDXL для иллюстрации сюжета
Гайд как это настроить есть?
Увы, такая модель.
> Нищуки на процессорах и оперативках гоняют йоба модели, которые пользователям 3070ti и не снились.
Как правило для нищука уже 32гб рам
> слишком много и не нужно! это только если для работы а 16 хватит всем и еще свободно
Так что ни о каких йоба моделях речи быть не может.
> cpu+озубогизм
Нужно иметь бессмертие и божественное терпение для такого.
Гораздо приятнее представлять ебало тех, у кого рам меньше чем у тебя врам

>34b.Q4_K_M
У тебя даже не 70b...
>Гораздо приятнее представлять ебало тех, у кого рам меньше чем у тебя врам
А чо всмысле? У меня меньше, 12 Гб. Но я текстовые сетки даже онлайновые ни разу не запускал, не то что локально.
мимо-нищук из аниме треда
Я говорю о ценах йоба видеокарт и озу. Одна плашка ddr4 на 16 гигов у нас в городе стоит примерно 3500р, а одна видеокарта с 16 гигами 53800р. Так что нахер переплачивать в 14 раз за йоба карту, когда на процессорах с оперативкой можно запускать все те же модели ит даже пизже?
Кстати, в будущем я уверен на 100% все эти генерации текстов будут на процессорах происходить. Уже в современных процессорах стали устанавливать специальные ai ядра для ускорения обработки нейросетей и для генерации картинок я уверен будет так же. Так что это просто пока ещё до конца отшлифованная технология, из-за чего, людям приходиться сейчас временно использовать видяхи. Потом за все нейросети будут отвечать наши процессоры, а видяхи как и раньше чисто для игр будут.
В будущем все передут на ASIC, потому что все ваши чипы костыли, только стоить они будут дохуя по началу.

Ну я реалист, на ddr4 памяти нет смысла запускать такие больше модели, там реально пол токена в секунду будет, мне такое нахрен не упало. Вот перекачусь позже на AM6 платформу, где будет уже ddr6 оперативка с процессором в котором будет ускоритель нейросетей, вот тогда и перейду на 70b. Я конечно нищук, но не мазохист, ниже моего достоинства чатиться с моделью, которая будет выдавать мне меньше 1 токена
Без претензий, такое актуально прежде всего для нищуков-копротивленцев, которые на серьезных щщах аутотренируются что "ничем не хуже". Не рациональный выбор, потребность-достаточность и прочее (ведь на 12гб вполне норм можно катать 13-20б, которые покрывают основные потребности), а именно маневраторов.
> Одна плашка ddr4 на 16 гигов у нас в городе стоит примерно 3500р
> а одна видеокарта с 16 гигами 53800р
За 3.5к только бибой по губам, а 16гиговый огрызок в районе 25к в зеленом маркетплесе с учетом всех акций, но это не важно. Просто проц+рам - неюзабельны, обработка контекста занимает вечность, а скорость генерации даже сама по себе смешная. Перфоманс даже вялой гпу и рядом не стоит.
> 100% все эти генерации текстов будут на процессорах происходить. Уже в современных процессорах стали устанавливать специальные ai ядра для ускорения обработки нейросетей
Для ллм нужна оче быстрая память. Единственный "проц" что может их тянуть - эпловский, и то исключительно за счет 8 каналов объединенной памяти.
> Потом за все нейросети будут отвечать наши процессоры, а видяхи как и раньше чисто для игр будут.
Настолько неправдоподобно что даже забавно.
Я говорю о ближайшем будущем на 10-20 лет вперёд, а не о фантазиях шизофреника
>Настолько неправдоподобно что даже забавно
Малолетний долбаёб, запомни что тебе взрослые люди говорят, потом внукам своим будешь рассказывать что тебя предупреждали, хотя о чём это я, какие внуки, ты же анимешник...
Я говорю об этих же сроках, нейроморфные чипы уже разрабатывают как минимум intel.
Из уст неграмотного пиздюка, или скуфидона-неудачника, кем ты являешься, подобные речи звучат вдвойне рофлово.
> ты же анимешник
За наруто и двор стреляю в упор!
Тестили MiniCPM-2B? Неужели китайцы годноту выложили, которая может запускаться хоть на электрочайнике
Ну и куда её такую совать, она ж не квантованная.
Я всё жду когда сделают нормальную ужатую модель для кодинга, чтоб для автокомплита на каждом символе скорости хватало и генерация строчки была мгновенной. 2В тут было бы заебись, в мелкую ещё можно контекста напихать много. У JetBrains есть какая-то встроенная ультралёгкая, но она только по питону/жс и генерит буквально пару слов автокомплита.
>Уже в современных процессорах стали устанавливать специальные ai ядра
Юзелесс хуйня для пиара. Нахуй не нужно с пропускной в 100ГБ/с.
>Вот перекачусь позже на AM6
Тоже бессмертный?
>2B
Да что блядь такое, опять огрызок. Где 70B топовые? Заебали сетки меньше.
> 2B
> transformers
Ну хз, где инновации на мамбе? Конечно, заявления типа
> The overall performance exceeds Llama2-13B, MPT-30B, Falcon-40B, etc.
Очень воодушевляют, но верится с трудом.
> The multi-modal model MiniCPM-V
Вот это может быть интересно, но если не может в нсфв - сразу нахер.
> Где 70B топовые
Какие из текущих предпочитаешь?
4-6 лет это не так много, чувак.
>Какие из текущих предпочитаешь?
Лучше синтии полторашки так ничего и не сделали.
Если взять среднюю продолжительность жизни, сроки дожития от текущего возраста, вычесть РАБотку и сон, то это четверть всего свободного времени, лол.
Silly Tavern Extras + SD module. Что-то полноценного гайда не нахожу. Тут и там:
https://www.youtube.com/watch?v=Pvv6wQ_ngc4
https://www.reddit.com/r/PygmalionAI/comments/13j2ruw/stable_diffusion_in_silliy_tavern/
Был еще какой-то вариант для выжимки сюжета, а то по умолчанию в SD отправляется только последняя фраза персонажа.
Ну и зачем ты это написал? Мне же теперь еще больше хочется купить 3090.
На электрочайнике много что запускается, а вот насколько она качественна?
> Очень воодушевляют, но верится с трудом.
Плюсую.
> Вот это может быть интересно
Плюсую.
Спасибо тебе, добрый анон.
TIL, что есть саб по Пигме. Пойду подпишусь, что ли.
С учетом размера и скорости на моем игросральном ноуте я бы сказал это одно из лучшего что я пробовал.
А самое главное пока не нашел каких либо NSFW барьеров, нет этой хуйни что так нельзя. Просто дает убить персонажа если захотеть, а не начинает срать всякими ТАК НЕЛЬЗЯ.
Единственное что большие пасты выдает не охотно, но в целом может в них.


Так, на счет охлаждения P40, если кому еще интересно.
В качестве эксперимента распечатал вот этот переходник:
thingiverse.com/thing:4401674
Использовал его с вентилем от старого процессоного кулера у которого 2500 оборотов это максимальная скорость вращения.
После тестов могу сказать что этот вариант вполне юзабельный, температура не поднималась выше 81 градуса 91 по хотспоту, шум в пределах разумного.
Сам по себе переходник от V100, так что перед установкой его приходится слегка "доработать напильником" образно выражаясь.
Ну и в моем случае P40 с переходником влезла в корпус не то что впритык, а еле-еле, пришлось убрать один из трех фронтальных 120 вентилей, лол.
В качестве эксперимента распечатал вот этот переходник:
thingiverse.com/thing:4401674
Использовал его с вентилем от старого процессоного кулера у которого 2500 оборотов это максимальная скорость вращения.
После тестов могу сказать что этот вариант вполне юзабельный, температура не поднималась выше 81 градуса 91 по хотспоту, шум в пределах разумного.
Сам по себе переходник от V100, так что перед установкой его приходится слегка "доработать напильником" образно выражаясь.
Ну и в моем случае P40 с переходником влезла в корпус не то что впритык, а еле-еле, пришлось убрать один из трех фронтальных 120 вентилей, лол.
>После тестов могу сказать что этот вариант вполне юзабельный, температура не поднималась выше 81 градуса 91 по хотспоту, шум в пределах разумного.
Такие температуры при работе с текстовыми моделями (150 ватт, как говорят) или Stable Diffusion (полная нагрузка, 250 ватт)?
Слишком горячо, что-то не то
Нет, это если стресстестом жарить, в stable diffusion и текстовых моделях меньше, в районе 65-70 до 80 по хотспоту
Вполне прилично, это же всего лишь одна восьмидесятка для охлаждения карточки, которая жрет до 250W.
Вполне норм. С другими кулерами не экспериментировал?
Более чем юзабельно. Такая система охлаждения сама по себе не особо эффективна, в карточках где турбина встроенная целевая температура задана ~84 градуса.
>С другими кулерами не экспериментировал?
Других дома не нашлось, чисто теоретически если подыскать вентиль с большим статическим давлением то должно быть еще лучше.
Чет чем больше сижу в таверне тем больше хочу переехать на кобольд лайт.
Почему ещё не переехал?
Да вот уже. Пиздец аж дышать легче, все просто работает без всего этого вагона говна.
Счастья, здоровья.
>без всего этого вагона говна
А это что за вагоны и почему у меня их нет?
Аж захотелось опять скачать и в очередной раз убедиться насколько там все грустно с точки зрения интерфейса.
А есть моделька, которая позволяет кум, но не скатывается в него за 10 сообщений?
Да. Просто берёшь почти любую 70b и наслаждаешься непринуждёнными беседами.
На синтии (и новой тесс34) если начать слишком интенсивный кадлинг и ласки - оно переходит в левд и несколько быстрее чем ожидаешь. Промт помогает но не в 100% случаев.
Вот стоило только напечатать переходник и в этот же день прходит заказанная водянка.
Ладно, зато теперь будет с чем сравнить.
Раз так, то попробуй airoboros. Тоже полноценный файнтюн.
Каким тестом под виндой можно пожарить? Хочу свою потестить.
Как же я заебись покумал счас на большой модельке. Рано или поздно сделают что маленькие будут как большие по уму, но пока не сделали большую приятнее читать.
Он для подобного хорош, можно еще и вести беседу в процессе. Но не такой умный и не умеет в кум. Почему до сих пор не замешали айробороса с синтией так чтобы объединить фичи?
>Рано или поздно сделают что маленькие будут как большие по уму
Никогда такого не будет. Скриньте.
>так чтобы объединить фичи
Потому что нельзя просто взять и объединить.
> Никогда такого не будет
Ну дай ты помечтать, а?
> Потому что нельзя просто взять и объединить.
Чисто технически из них же можно MOE собрать. Даже колхозное не нативное, весь вопрос в том, как делать выбор токенов, или решать кому отдавать.
Нахуя он текст из прошлых сообщение повторяет? ргенерат-дегернерат, блять
На токены в секунду насрать если честно, если их не менее 1.
А вот латенси контекста это пиздец.
Сам гоняю тгвуи+сд временами.
>все эти генерации текстов будут на процессорах происходить
И стоить они будут как видимокарта
Ебало северного моста представил, когда ему bandwidth требования покажут?
ПЕРЕКАТ
гитгад сука лёг, не зря базовую инфу в шапке продолжаем хранить
гитгад сука лёг, не зря базовую инфу в шапке продолжаем хранить




Здесь мы делимся рецептами запуска, настроек и годных промтов, расширяем сознание контекст, и бугуртим с кривейшего тормозного говна.
Тред для обладателей топовых карт NVidia с кучей VRAM или мажоров с проф картами уровня A100, или любителей подождать, если есть оперативная память. Особо терпеливые могут использовать даже подкачку и запускать модели, квантованные до 8 5 4 3 2-х бит, на кофеварке с подкачкой на микроволновку.
Базовой единицей обработки любой языковой модели является токен. Токен это минимальная единица, на которые разбивается текст перед подачей его в модель, обычно это слово (если популярное), часть слова, в худшем случае это буква (а то и вовсе байт).
Из последовательности токенов строится контекст модели. Контекст это всё, что подаётся на вход, плюс резервирование для выхода. Типичным максимальным размером контекста сейчас являются 2к (2 тысячи) и 4к токенов, но есть и исключения. В этот объём нужно уместить описание персонажа, мира, истории чата. Для расширения контекста сейчас применяется метод NTK-Aware Scaled RoPE. Родной размер контекста для Llama 1 составляет 2к токенов, для Llama 2 это 4к, но при помощи RoPE этот контекст увеличивается в 2-4-8 раз без существенной потери качества.
Текущим трендом на данный момент являются мультимодальные модели, это когда к основной LLM сбоку приделывают модуль распознавания изображений, что в теории должно позволять LLM понимать изображение, отвечать на вопросы по нему, а в будущем и манипулировать им.
Основным представителем локальных моделей является LLaMA. LLaMA это генеративные текстовые модели размерами от 7B до 70B, притом младшие версии моделей превосходят во многих тестах GTP3 (по утверждению самого фейсбука), в которой 175B параметров. Сейчас на нее существует множество файнтюнов, например Vicuna/Stable Beluga/Airoboros/WizardLM/Chronos/(любые другие) как под выполнение инструкций в стиле ChatGPT, так и под РП/сторитейл. Для получения хорошего результата нужно использовать подходящий формат промта, иначе на выходе будут мусорные теги. Некоторые модели могут быть излишне соевыми, включая Chat версии оригинальной Llama 2.
Кроме LLaMA для анона доступны множество других семейств моделей:
Pygmalion- заслуженный ветеран локального кума. Старые версии были основаны на древнейшем GPT-J, новые переехали со своим датасетом на LLaMA, но, по мнению некоторых анонов, в процессе потерялась Душа ©
MPT- попытка повторить успех первой лламы от MosaicML, с более свободной лицензией. Может похвастаться нативным контекстом в 65к токенов в версии storywriter, но уступает по качеству. С выходом LLaMA 2 с более свободной лицензией стала не нужна.
Falcon- семейство моделей размером в 40B и 180B от какого-то там института из арабских эмиратов. Примечательна версией на 180B, что является крупнейшей открытой моделью. По качеству несколько выше LLaMA 2 на 70B, но сложности с запуском и малый прирост делаю её не самой интересной.
Mistral- модель от Mistral AI размером в 7B, с полным повторением архитектуры LLaMA. Интересна тем, что для своего небольшого размера она не уступает более крупным моделям, соперничая с 13B (а иногда и с 70B), и является топом по соотношению размер/качество.
Qwen - семейство моделей размером в 7B и 14B от наших китайских братьев. Отличается тем, что имеет мультимодальную версию с обработкой на входе не только текста, но и картинок. В принципе хорошо умеет в английский, но китайские корни всё же проявляется в чате в виде периодически высираемых иероглифов.
Yi - Неплохая китайская модель на 34B, способная занять разрыв после невыхода LLaMA соответствующего размера
Сейчас существует несколько версий весов, не совместимых между собой, смотри не перепутай!
0) Оригинальные .pth файлы, работают только с оригинальным репозиторием. Формат имени consolidated.00.pth
1) Веса, сконвертированные в формат Hugging Face. Формат имени pytorch_model-00001-of-00033.bin
2) Веса, квантизированные в GGML/GGUF. Работают со сборками на процессорах. Имеют несколько подформатов, совместимость поддерживает только koboldcpp, Герганов меняет форматы каждый месяц и дропает поддержку предыдущих, так что лучше качать последние. Формат имени ggml-model-q4_0, расширение файла bin для GGML и gguf для GGUF. Суффикс q4_0 означает квантование, в данном случае в 4 бита, версия 0. Чем больше число бит, тем выше точность и расход памяти. Чем новее версия, тем лучше (не всегда). Рекомендуется скачивать версии K (K_S или K_M) на конце.
3) Веса, квантизированные в GPTQ. Работают на видеокарте, наивысшая производительность (особенно в Exllama) но сложности с оффлоадом, возможность распределить по нескольким видеокартам суммируя их память. Имеют имя типа llama-7b-4bit.safetensors (формат .pt скачивать не стоит), при себе содержат конфиги, которые нужны для запуска, их тоже качаем. Могут быть квантованы в 3-4-8 бит (Exllama 2 поддерживает адаптивное квантование, тогда среднее число бит может быть дробным), квантование отличается по числу групп (1-128-64-32 в порядке возрастания качества и расхода ресурсов).
Основные форматы это GGML и GPTQ, остальные нейрокуну не нужны. Оптимальным по соотношению размер/качество является 5 бит, по размеру брать максимальную, что помещается в память (видео или оперативную), для быстрого прикидывания расхода можно взять размер модели и прибавить по гигабайту за каждые 1к контекста, то есть для 7B модели GGML весом в 4.7ГБ и контекста в 2к нужно ~7ГБ оперативной.
В общем и целом для 7B хватает видеокарт с 8ГБ, для 13B нужно минимум 12ГБ, для 30B потребуется 24ГБ, а с 65-70B не справится ни одна бытовая карта в одиночку, нужно 2 по 3090/4090.
Даже если использовать сборки для процессоров, то всё равно лучше попробовать задействовать видеокарту, хотя бы для обработки промта (Use CuBLAS или ClBLAS в настройках пресетов кобольда), а если осталась свободная VRAM, то можно выгрузить несколько слоёв нейронной сети на видеокарту. Число слоёв для выгрузки нужно подбирать индивидуально, в зависимости от объёма свободной памяти. Смотри не переборщи, Анон! Если выгрузить слишком много, то начиная с 535 версии драйвера NVidia это серьёзно замедлит работу. Лучше оставить запас.
Гайд для ретардов для запуска LLaMA без излишней ебли под Windows. Грузит всё в процессор, поэтому ёба карта не нужна, запаситесь оперативкой и подкачкой:
1. Скачиваем koboldcpp.exe https://github.com/LostRuins/koboldcpp/releases/ последней версии.
2. Скачиваем модель в gguf формате. Например вот эту:
https://huggingface.co/TheBloke/Frostwind-10.7B-v1-GGUF/blob/main/frostwind-10.7b-v1.Q5_K_M.gguf
Можно просто вбить в huggingace в поиске "gguf" и скачать любую, охуеть, да? Главное, скачай файл с расширением .gguf, а не какой-нибудь .pt
3. Запускаем koboldcpp.exe и выбираем скачанную модель.
4. Заходим в браузере на http://localhost:5001/
5. Все, общаемся с ИИ, читаем охуительные истории или отправляемся в Adventure.
Да, просто запускаем, выбираем файл и открываем адрес в браузере, даже ваша бабка разберется!
Для удобства можно использовать интерфейс TavernAI
1. Ставим по инструкции, пока не запустится: https://github.com/Cohee1207/SillyTavern
2. Запускаем всё добро
3. Ставим в настройках KoboldAI везде, и адрес сервера http://127.0.0.1:5001
4. Активируем Instruct Mode и выставляем в настройках пресетов Alpaca
5. Радуемся
Инструменты для запуска:
https://github.com/LostRuins/koboldcpp/ Репозиторий с реализацией на плюсах
https://github.com/oobabooga/text-generation-webui/ ВебуУИ в стиле Stable Diffusion, поддерживает кучу бекендов и фронтендов, в том числе может связать фронтенд в виде Таверны и бекенды ExLlama/llama.cpp/AutoGPTQ
Ссылки на модели и гайды:
https://huggingface.co/TheBloke Основной поставщик квантованных моделей под любой вкус.
https://rentry.co/TESFT-LLaMa Не самые свежие гайды на ангельском
https://rentry.co/STAI-Termux Запуск SillyTavern на телефоне
https://rentry.co/lmg_models Самый полный список годных моделей
http://ayumi.m8geil.de/ayumi_bench_v3_results.html Рейтинг моделей для кума со спорной методикой тестирования
https://rentry.co/llm-training Гайд по обучению своей лоры
https://rentry.co/2ch-pygma-thread Шапка треда PygmalionAI, можно найти много интересного
https://colab.research.google.com/drive/11U-bC6AxdmMhd3PF9vWZpLdi6LdfnBQ8?usp=sharing Последний известный колаб для обладателей отсутствия любых возможностей запустить локально
Шапка треда находится в https://rentry.co/llama-2ch (переезжаем на https://2ch-ai.gitgud.site/wiki/llama/ ), предложения принимаются в треде
Предыдущие треды тонут здесь: