


Наконец выяснил, как миксовать SDXL с PonyXL.
Авторы мерджей применяют технику мерджа "DARE", чтобы соединять максимально непохожие модели одной архитектуры. Я сделал мердж comradexl, ponymagine, anythingxl и использовал его как прекурсор для дальнейшего мерджа, теперь идет как по маслу. Но фоны все равно мыльные. Интересно, встанет ли всё это поверх Pony7.
Авторы мерджей применяют технику мерджа "DARE", чтобы соединять максимально непохожие модели одной архитектуры. Я сделал мердж comradexl, ponymagine, anythingxl и использовал его как прекурсор для дальнейшего мерджа, теперь идет как по маслу. Но фоны все равно мыльные. Интересно, встанет ли всё это поверх Pony7.
>Pony7
До нее же еще далеко
На, сравнивай, хоть обгенерься.
https://huggingface.co/spaces/VikramSingh178/Kandinsky-3
Это кривой жопой обученное говно никому, кроме сбера не нужно.
Сколько они его пилили? Года полтора? За это время СД эволюционировал за счет энтузиастов анмимешников до вполне удобного и рабочего инструмента. Без бабла, без "команды продукта".
Гайд будет?
Ща погуглил и оказывается, есть ComfyUI нода для Dare, вроде ничего сложного.
Нихуя не понял как пользоваться
а хотя нет вроде понял, но лучше бы чтобы воркфлоу свой скинул для примера
Там еще дейр мержер лор есть, ток у меня он не работает лол ругается на разные дименшоны.
А вообще конкретно по дейру че за че там отвечает? Реально гайд бы.




Какой способ тренировки лор может найти эти мелкие отлчия между 2-мя практически одинаковыми картинками?
Перефразирую:
Как тренировать лору чтобы во время обучения сравнивались только пары пикч между собой? Например пик1 сравнивался только с пик2, а пик3 только с пик4 и т.д.
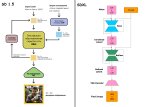
Block merge это мощный инструмент контроля над юнетами от разных SDXL моделей...
С ним я смогу добавить к этой новой модели https://civitai.com/models/480956/anime-reality-interweaving?modelVersionId=534884 верхний слой от фотореалистичной модели, чтобы сделать фон еще реалистичнее, и нижний слой от маня-чекпойнта - чтобы стиль персонажа был более выразительным.
Чем выше, тем больше воздействует на композицию целиком, не трогая детали. Чем ниже - тем больше меняет детали, не трогая общую композицию. Middle - это про поверхности, их материалы и текстуры. (В первой версии OrangeMix автор плавно заменил миддл у NovelAI, взяв реалистичную модель с голыми японками).
Значение 1 означает - полностью оставить первую подключенную модель, 0 - полностью сделать из второй. Из моего опыта, верхние 3-5 слоёв в input влияют в основном на детали фона и освещение, 6-7 сильнее всего влияют на фон и могут его сломать. Если заменить только input_blocks 0 - то поменяются некоторые детали фона, одежда персонажа и её цвет, а персонаж останется прежним. С середины middle начинает влиять на текстуру кожи и структуру волос (но не расположение прядей). В низу middle начинает менять позу (точнее, конечности - включая принципы их расположения) и всю анатомию. В output меняет лицо, а в последнем output_blocks 11 серьезно меняет даже такие детали, как пряди волос. Есть и отдельная нода для мерджа клипов. CLIP из PonyXL ухудшает фон, но в теории может улучшить понимание Booru-концептов.
Есть вариант прибегать к пресетам (поставив в комфи ноду с пресетами), про них показано здесь https://civitai.com/articles/2370/model-merging-management-how-to-merge-stable-diffusion-models-to-fit-your-style
С ним я смогу добавить к этой новой модели https://civitai.com/models/480956/anime-reality-interweaving?modelVersionId=534884 верхний слой от фотореалистичной модели, чтобы сделать фон еще реалистичнее, и нижний слой от маня-чекпойнта - чтобы стиль персонажа был более выразительным.
Чем выше, тем больше воздействует на композицию целиком, не трогая детали. Чем ниже - тем больше меняет детали, не трогая общую композицию. Middle - это про поверхности, их материалы и текстуры. (В первой версии OrangeMix автор плавно заменил миддл у NovelAI, взяв реалистичную модель с голыми японками).
Значение 1 означает - полностью оставить первую подключенную модель, 0 - полностью сделать из второй. Из моего опыта, верхние 3-5 слоёв в input влияют в основном на детали фона и освещение, 6-7 сильнее всего влияют на фон и могут его сломать. Если заменить только input_blocks 0 - то поменяются некоторые детали фона, одежда персонажа и её цвет, а персонаж останется прежним. С середины middle начинает влиять на текстуру кожи и структуру волос (но не расположение прядей). В низу middle начинает менять позу (точнее, конечности - включая принципы их расположения) и всю анатомию. В output меняет лицо, а в последнем output_blocks 11 серьезно меняет даже такие детали, как пряди волос. Есть и отдельная нода для мерджа клипов. CLIP из PonyXL ухудшает фон, но в теории может улучшить понимание Booru-концептов.
Есть вариант прибегать к пресетам (поставив в комфи ноду с пресетами), про них показано здесь https://civitai.com/articles/2370/model-merging-management-how-to-merge-stable-diffusion-models-to-fit-your-style
> Перефразирую:
> Как тренировать лору чтобы во время обучения сравнивались только пары пикч между собой? Например пик1 сравнивался только с пик2, а пик3 только с пик4 и т.д.
Разделить по концептам с уникальными стартовыми токенами?
Ты путешественник во времени? Как там в 2022?
> Block merge это мощный инструмент
дерьма
Стандартный, просто теги разные поставь у обычной и тонмапленной картинки, и оно само различит. Точнее попробует различить - у него не бесконечная способность к генерализации. Главное выставь как можно больше тегов для абсолютно всего что есть на пикчах помимо твоей разницы, включая предметы, оттенки, действия и т.п. И подбери пикчи так, чтобы они были максимально непохожими друг на друга, и отличались только тонмаппингом. Иначе он будет клепать похожее на твои пикчи.
Но вообще лоры для этого недостаточно мне кажется, надо файнтюнить полноценно, хотя бы на 10к+ пикч. Тем более что тонмаппинг кривую можно налепить автоматически.
>практически одинаковыми картинками
Это для тебя почти одинаковыми. А у шоггота собственные критерии похожести.
Но вообще, нахуя тебе тонмаппинг кривую зашивать в нейронку? Ебанутая идея изначально, как по мне. Это же чисто автоматическая операция.
>Например пик1 сравнивался только с пик2, а пик3 только с пик4 и т.д.
Теги пик1: интерьер, вестибюль, балкон, диван, камин, домашняя обстановка, столик
Теги пик2: интерьер, вестибюль, балкон, диван, камин, домашняя обстановка, столик, пиздатый тонмаппинг
И он автоматически выводит разницу при обучении. Но надо овердохуя тегов для всего остального, чтобы он смог тщательно отделить тонмаппинг от всего остального. И овердохуя пар, чтобы не сошёлся на каком-то паразитном признаке.
Утерянные знания https://rentry.co/Copier_LoRA вот это попробуй
Интересные наблюдения, анонче, пробовал уже лучшее таким образом из разных аутизмов там для аниме анатомии вытаскивать например из моделей?
Анон, это всё так не работает. Твои наблюдения не обобщаются, обычно одни отвечают за низкие частоты, другие за высокие, но не всегда, и обычно затрагивают совершенно несвязанные вещи. Протестировать вручную это невозможно, слишком большой объём.
По этой же причине невозможно было управлять FreeU, т.к. это шаманство. По этой же причине любые интуитивные ковыряния в отдельных весах или слоях или блоках - хуйня из коня.
>Утерянные знания
Интересное решение, кстати.
Еще, помню, были какие-то штуки для тренировки лор-слайдеров, основанные именно на парных картинках, а не регулировке весов, когда все делается без картинок вообще.
Колабы по ссылкам в шапке дохлые, нихуя там не работает тренировка и уже более года вроде на него как хуй забили.
А вот эта тема https://colab.research.google.com/github/hollowstrawberry/kohya-colab/blob/main/Lora_Trainer.ipynb по первой ссылке в гугле внезапно работает
А вот эта тема https://colab.research.google.com/github/hollowstrawberry/kohya-colab/blob/main/Lora_Trainer.ipynb по первой ссылке в гугле внезапно работает
RAM колабовского gpu не хватает для трейна XL
Я xl не юзаю, на 1.5 хватает и ладно



Dare с включенным attention - годнота, вот сэмплы 50/50 мерджа AutismMix с Helloworld. Надо экспериментировать, хочу сделать анимэ мердж со стилем как в цифровой живописи китайцев из Artstation. (чтобы не как в Pony 6 - а хорошую разностороннюю XL модель как Unstable, которая возьмет из пони только анатомию и концепты чуть-чуть). Видел где-то костыль для инжекта нойза в чекпойнты, он может помочь чтоб делать фон без мыла.
Ты отдаешь себе отчет в том, что занят проектом лепки из говна по мотивам лепнины, созданной альтернативно разумными индивидуумами ииз пластилина на уроке трудотерапии?
это почему у тебя так от пони печет?
Вопрос к знающим. Если веса Vpred модели можно присобачить к обычной, то как присобачить веса модели offset noise? Так же через train difference?
о живой полторашечник
плюсуешь офсет нойз лору к модели в нужном весе, трейн дифренсишь к изначальной полученную модель
на сдхл если интересно такой же эффект + полное управление динамическим диапазоном и цветами через мердж с CosXL, на пони не работает есличе
Надо бы тогда в шапке сменить на этот, раз он работает
А сколько там? С чекпоинтингом в фп8 и в 8 гигов умещать умудряются с XL
У меня не лоры, а обычные модели. Т.е. по сути, так же все как и с лорой? Я просто лоры никогда не мерджил с моделями, считаю это извращением.
>У меня не лоры, а обычные модели.
непонял, что за модели?
>Т.е. по сути, так же все как и с лорой?
да
>Я просто лоры никогда не мерджил с моделями, считаю это извращением.
ну и зря, это же просто замена весов в модельке на нужные, ничего криминального
>непонял, что за модели?
https://huggingface.co/lodestones/furryrock-model-safetensors/tree/main Шерстяные, тащемта. Хочу попробовать с них вытянуть впред, офсет нойз и в душе не ебу что за terminal-snr и minsnr-zsnr-vpred-ema - последнее что-то на колдунском, гугл молчит. Но если это можно вытянуть из модели и проверить, то хорошо. Ещё бы знать как правильно, потому что с СуперМерджером я на "вы" и никогда им не пользовался.
>ну и зря, это же просто замена весов в модельке на нужные, ничего криминального
Допустим.
Чел, это пердолинг loss при тренировке, что ты там из чекпоинта собрался тянуть, шиз?
Тредом ранее говорили, что vpred можно через трейнДиф перетянуть от одной модели к другой. то же самое говорит, но на примере лор. Плюс как бы я ясно выразился, что с мерджем я плохо знаком, поэтому и спрашиваю можно ли подобные особенности с одной модели перетянуть на другую. С чего ты взял, что я прям 100% уверен что это можно сделать?
>это пердолинг loss при тренировке
А поподробнее, где об этом можно почитать?
Заменил в шаблоне и попросил модератора обновить ОП-пост чтобы пару месяцев до ката не ждать.
Аноны, не знаю где ещё спросить, итт самый свет науки в области нейросетей сидит.
Нужен софт, который убирает цензуру "мазайку" с хентайных пиков и работает в гугл колабе.
1) DeepCreamPy не работает больше в колабе, разраб написал что проебал сурсы, то что есть не пашет и как пофиксить в интернете инструкций нет.
2) hentai-ai тоже не работает, пытается установить opencv устанавливает его час и потом хуй.
3) DeepMosaics это ваше маниме не понимает.
А больше ничего и не гуглится.
Как быть?
Нужен софт, который убирает цензуру "мазайку" с хентайных пиков и работает в гугл колабе.
1) DeepCreamPy не работает больше в колабе, разраб написал что проебал сурсы, то что есть не пашет и как пофиксить в интернете инструкций нет.
2) hentai-ai тоже не работает, пытается установить opencv устанавливает его час и потом хуй.
3) DeepMosaics это ваше маниме не понимает.
А больше ничего и не гуглится.
Как быть?
Купить видеокарту и демозаить локально.
Интересная тема, однако.
Исследователи из Техасского университета в Остине разработали инновационную схему обучения моделей на сильно поврежденных изображениях, метод получил название Ambient Diffusion
Последнее время то и дело возникают судебные иски — художники жалуются на незаконное использование их изображений.
И Ambient Diffusion как раз позволяет ИИ-моделям не копировать изображения, а скажем «черпать вдохновение» из них.
В ходе исследования команда исследователей обучила модель Stable Diffusion XL на наборе данных из 3 000 изображений знаменитостей. Изначально было замечено, что модели, обученные на чистых данных, откровенно копируют учебные примеры.
Однако когда обучающие данные были испорчены — случайным образом маскировалось до 90% пикселей, — модель все равно выдавала высококачественные уникальные изображения.
Статья : https://www.ifml.institute/node/450
Любителям шатат формулы: https://arxiv.org/pdf/2305.19256
Получается, что аксиома "Говно на входе - говно на выходе" пошатнулась? Надо попробовать на испорченном сете протренить лорку.
Исследователи из Техасского университета в Остине разработали инновационную схему обучения моделей на сильно поврежденных изображениях, метод получил название Ambient Diffusion
Последнее время то и дело возникают судебные иски — художники жалуются на незаконное использование их изображений.
И Ambient Diffusion как раз позволяет ИИ-моделям не копировать изображения, а скажем «черпать вдохновение» из них.
В ходе исследования команда исследователей обучила модель Stable Diffusion XL на наборе данных из 3 000 изображений знаменитостей. Изначально было замечено, что модели, обученные на чистых данных, откровенно копируют учебные примеры.
Однако когда обучающие данные были испорчены — случайным образом маскировалось до 90% пикселей, — модель все равно выдавала высококачественные уникальные изображения.
Статья : https://www.ifml.institute/node/450
Любителям шатат формулы: https://arxiv.org/pdf/2305.19256
Получается, что аксиома "Говно на входе - говно на выходе" пошатнулась? Надо попробовать на испорченном сете протренить лорку.
Это в говне моченые - ученые.
1. Учили на уже обученной модели (даже ванильная от ОА - уже обучена)
2. Открыли для себя сильные токены базовой модели. Даже если в качестве сета использовать ргб-шум, но учить на сильный токен, "man" например, то мужики все равно будут получаться. Откровение, блядь!
3. Попробуй на объект или стиль подсунуть "90% пикселей говна" на уникальный токен - получишь месиво из говна от Лоры.
Пиздец, конечно, позорище, техасцам.
Просто заюзай impaint со стейбл дифужна, только чекпоинт (на цивит.аи) предварительно найди под стиль твоей картинки. И даже так можно получить вполне приемлемый результат в 70% случаев, ну в остальных 30 что-то фото шепом придется поправлять руками.
> аксиома "Говно на входе - говно на выходе" пошатнулась
С чего бы вдруг? Там же loss считается из испорченных пикч. Если модель знает как выглядят испорченные пики, то всё будет как обычно, просто меньше информации будет из пика идти. Условно, части ебала он будет запоминать, а общая композиция сломана и он будет её игнорить, т.к. там рандом.
Добавьте инфу о сайтах по типу цивитай в которых есть возможность бесплатно тренировать.
Парни, такой вопрос, позволяет ли control net менять позу без изменения персонажа? Чтобы не добавлялись и не терялись мелкие детали, уебищно тени не скакали туда сюда, и можно ли довести уровень двух изображений с изменённой позой (с условным запрокидывание руки) до такого уровня чтобы из двух картинок можно было красивую анимацию сделать бесшовную?
Не позволяет.
По крайней мере, не позволял до сих пор.
Можешь это чекнуть, недавно видел, но сам не тестировал.
https://www.youtube.com/watch?v=hc5nF6rGa68
как же заебали эти недоблогеры с кликбейным говном изо всех щелей.
Да этот то чел нормальный.
Доступно объясняет, ссылки, все на месте.
Разве что актива у него нет последнее время.
технаряны, нубярский вопрос.
Есть модель на HF (ванильная SDXL файнтюненая методом SPO экперимента ради, но дающая очень хороши результаты по сравнению с оригом).
Она выложена как я понимаю в формате diffusors. Как ее сконвертить в savetensors для использования в гуях? Локально, коллаб, сам HF - пофиг.
Гугление этого вопроса зациклило меня рекурсивно, GPT несет дичь, Сlaude делает вид, что не понимает.
Репа: https://huggingface.co/SPO-Diffusion-Models/SPO-SDXL_4k-p_10ep/tree/main
Есть модель на HF (ванильная SDXL файнтюненая методом SPO экперимента ради, но дающая очень хороши результаты по сравнению с оригом).
Она выложена как я понимаю в формате diffusors. Как ее сконвертить в savetensors для использования в гуях? Локально, коллаб, сам HF - пофиг.
Гугление этого вопроса зациклило меня рекурсивно, GPT несет дичь, Сlaude делает вид, что не понимает.
Репа: https://huggingface.co/SPO-Diffusion-Models/SPO-SDXL_4k-p_10ep/tree/main
Ну нахуя вбрасывать если не собираешься объяснять, сука?
Не знаю насчёт конвертации, но пара гуёв вроде бы поддерживают формат diffusers. Лапша с кастомными нодами и СД некст.
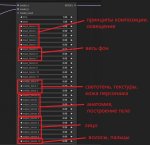
Собираюсь тренировать лору в civitai объясните пожалуста как работает bucketing? Он просто кропает пикчу до ближайшего рабочего разрешения например если пикча с соотношением сторон 17:9, то он кропает только до 16:9 или на все популярные соотношения сторон т.е. из 17: кропает до 9:16, 16:9, 1:1, 2:3, 3:2, 4:5 и т.д.?
Будет ли bucketing растягивать разрешение изначальной пикчи с 512х512 до выставленного 1024x1024? Хочу что бы более менее широкий спектр разрешений поддерживала лора.
> т.е. из 17: кропает до 9:16
* т.е. из 17:9 кропает до 9:16
-быстрофикс
* т.е. из 17:9 кропает до 9:16
-быстрофикс
пасиб, анон, но я уже залез в консольную трясину.
Решение прям совсем гдето-то рядом, но пока не хватает знаний понять какого хуя state_model_dict ловит ошибку без описания.
Если уж совсем мозг сломаю - пойду в Комфи
>Будет ли bucketing растягивать разрешение изначальной пикчи с 512х512
Для этого есть опция Don’t upscale bucket resolution
>как работает bucketing?
Buckets contain images with different aspect ratios than 1:1. Using bucketing, you don't need to crop your training data to 1:1 aspect ratios. Instead, you just throw the variously sized images at the script. It doesn't "randomly" resize images. It looks at them all and calculates appropriate buckets for them, that fit within your dictated resolution frame, then resizes them all and sets up the schedule for them.
The scheduling is the key part of the bucket script that makes it work. Batches have to be from all the aspect ratio so 1 batch can only train on 1 bucket at a time. So if you have a batch size of 10, and buckets have 2 images, 5 images, and 9 images in them, none of those bucket sizes fills a full 10 batch right? So the system will automatically do smaller batches and gradient accumulation them together to built an effective batch of 10.
In the case where you're already using gradient accumulation , it'll adjust the batch sizes accordingly. So by using bucketing, you're giving the script it's own dynamic control over batch size and gradient size, with your settings as a general target to aim for. If you have gradient accumulation turned off, then it'll fill the entire batch of 10 with one bucket's images. so if the current batch is working on the bucket with only 2 images, it'll do each of those 5x on that batch. Recommend you use gradient accumulation as this can lead to over representation of the training data.
None of this is "random". It is all very calculated and plotted across a very precise training schedule.
Cropping images to 1:1 ratios is still a super valid training approach too. Not everyone uses bucketing. I like it because i like rectangles better than squares and the models trained with buckets produce better rectangular images.
Веса слишком разнородные, хоть как извращайся, ничего кроме поломанного лоботомита не сделать. В теории, можно сделать гомункула, которого потом дообучить, и это будет быстрее и качественнее чем делать с чистой sdxl.
Двачую этого и остальных.
Мертвичина как и ожидалось.
Полностью готового софта нет. С помощью SD и аниме модели можно снимать цензуру инпеинтом, но придется вручную выделять область. Можешь воспользоваться yolo, там наверняка уже есть готовые для нужной области, или сам обучи, и уже из ее результата делай маску и посылай запросом по api. Или собери систему в комфи, такое более чем возможно, его же вроде на коллабе не банили, не?
> что аксиома "Говно на входе - говно на выходе" пошатнулась?
На вход всеравно подавались "хорошие" картинки, просто "ученые" просто сделали аугументацию, которую модель понимает. А насчет изначального копирования - ужасно подобраны параметры обучения, такого нет если делать нормально.
У кохи есть скрипт для конверсии форматов https://github.com/kohya-ss/sd-scripts/blob/main/tools/convert_diffusers20_original_sd.py и еще рядом смотри
> Он просто кропает пикчу до ближайшего рабочего разрешения
Сначала кропает до ближайшего соотношения сторон, потом ресайзит до заданного разрешения.
> Для этого есть опция Don’t upscale bucket resolution
Двачую, вот только делать так не стоит, в смысле что использовать 512 пикчи для обучения. Если нет возможности достать хайрез - берешь хороший dat апскейлер и прогоняешь картинки через него, чтобы превышали 1 мегапиксель. И их уже добавляешь в датасет, эффект будет гораздо лучше чем от тренировки лоурезами.
>У кохи есть скрипт для конверсии форматов
Спасибо тебе, анон! Это, похоже именно то, что нужно! Сейчас кофейку бахну и погружусь.
>вот только делать так не стоит, в смысле что использовать 512 пикчи для обучения
При трене на персонажа вообще бакеты отключаю, несколько десятков пикч руками подготовить (почистить, проапскейлить которые де дотягивают, протегать) аообще не проблема - занимает 15-20 минут. Зато на выходе качество субъекта горазло лучше.
Для больших стилевых датасетов, вероятно, полезно.
> При трене на персонажа вообще бакеты отключаю
А зачем? Честно, даже не интересовался что будет без них, просто кроп+рейсайз пикчи до квадрата/указанного в параметрах разрешения? Это может негативно повлиять на возможности генерации в других соотношений сторон, увы с лорами всякие байасы тоже любит хватать.
Включение бакетов не отменяет ручную подготовку, просто тренировка будет в разных ar.
>А зачем?
Потому что для вручную подготовленного сета они не нужны. Их задача - рассортировать по размеру изображения из сета.
https://github.com/bmaltais/kohya_ss/wiki/LoRA-training-parameters#enable-buckets
If your training images are all the same size, you can turn this option off, but leaving it on has no effect. (с) оттуда же
>что будет без них
если сет разного размера пикч и бакеты отключить - то неподходящие по размеру будут апскейлиться или даунскейлится до aspect ratio. Например, если базовый размер составляет 512x512 (соотношение сторон 1), а размер изображения - 1536x1024 (соотношение сторон 1,5), изображение будет уменьшено до 768x512 (соотношение сторон остается 1,5). (c) тоже из ссылки выше
> для вручную подготовленного сета
Имеешь ввиду еще и вручную кропнутного до квадратов разрешения тренировки?
Какая-то ерунда надомозговая написана, пусть и самим мейнтейнером.
> If your training images are all the same size
Случай простой и понятный, тут ок.
> будут апскейлиться или даунскейлится до aspect ratio. Например, если базовый размер составляет 512x512 (соотношение сторон 1), а размер изображения - 1536x1024 (соотношение сторон 1,5), изображение будет уменьшено до 768x512 (соотношение сторон остается 1,5).
И мы имеем как раз пикчи разного размера, которые не могут трениться вместе, где логика?
Там вообще есть 2 момента, первое - необходимо иметь тензоры одной и той же длины в батче, второе - соотношения сторон пикч могут быть разные и нужно подогнать их под единое количество пикселей, чтобы оно соответствовало заданному размеру для тренировки. Баккеты обеспечивали и то и другое, что будет без них если датасет типичный смешанный?
>Имеешь ввиду еще и вручную кропнутного до квадратов разрешения тренировки?
Я бы сказал не кропнутого, а приведенного к размерам 1024х1024 в соотношении 1:1. Потому что зачастую это не только кроп, когда пикчи больше, но и небольшой апсейл при необходимости, косметическая очистка от ненужных деталей, коррекция цвета, дешарп\деблюр в некоторых случаях.
>Какая-то ерунда надомозговая написана, пусть и самим мейнтейнером.
Так это же Kohya, все ок. Там исторически пиздец в логике неизбежен, скрипты пишет японец, а GUI и мануал к ним - bmaltais
> что будет без них если датасет типичный смешанный?
Не проверял, но как мне кажется, просто на выходе хуйня получится.
Использование исключительно квадратов чревато, без необходимости лучше не стоит.
> коррекция цвета, дешарп\деблюр в некоторых случаях
Можно примеры? Интересно в каких случаях и как такое делается.
> Так это же Kohya, все ок.
Не, это же вроде автор гуйни пишет. Чтобы Кохя написал описание и туториал - это хз даже что должно произойти.
>Интересно в каких случаях и как такое делается.
Ебался я недели 2 с тренировкой на одну мадам. Все перепробовал, даже сервак под тренировку на сутки взял, думал может у меня с компом беда.
При любом раскладе мадам на готовой лоре получалась (лицо) немного фиолетовым, близко вроде норм, а немного подальше отодвинуться - прям неестественно.
И только после того как отцветокорил сет первая же тренировка с стандартными(для меня) настройками - все стало заебись.
С тех пор - еще и на цвет чекаю сет.
Блюр помогает убрать ненужное за контуром головы, когда открывать ФШ и вырезать фон лень.
Шарпом тоже часто пользуюсь - им хорошо доводить черты лица на расфокусированных фотках из инета, когда датасет и так кислый.
>Не, это же вроде автор гуйни пишет
В том то и дело, скриплы прилит один, а ГУЙ и туториал - другой, и, судя по всему они меду собой вообще не общаются, то есть как гуеписец понял - так и написал, отсюда недоумение у пользователей.
>Использование исключительно квадратов чревато, без необходимости лучше не стоит.
Почему? всегда только 1:1 1024х1024 , кроме первых 2-3 трейнов, полет отличный

> Ебался я недели 2 с тренировкой на одну мадам.
Неправильно ты, дядя Федор, диффузию тренишь. Нужно чтобы компьютер неделями напрягался а не ты сам.
По поводу сути описанной проблемы вроде понятно, а можешь датасет показать? Интересно что там могло дать подобный эффект. Или хотябы опиши датасет (количество, содержимое) и дай свои предположения от чего могло быть.
Сам могу дать анимублядский пример - художник bartolomeobari на всех пикчах ограниченный диапазон, смещение гаммы и прочее, офк все это тоже усваивается. Можно починить нормализацией пикч.
> Блюр помогает убрать ненужное за контуром головы, когда открывать ФШ и вырезать фон лень.
Насколько потом модель может четкий не-заблюренный фон делать? И для чего вырезать фон, там что-то нехорошее?
> судя по всему они меду собой вообще не общаются
Общаются, он чуть ли не основную репу sd-scripts содержит. Просто год назад написал на отъебись, и с тех пор висит.
> Почему?
Могут ухудшиться генерации в соотношениях сторон не 1к1, особенно в определенных ракурсах/позах и т.д.
https://github.com/lllyasviel/stable-diffusion-webui-forge/discussions/801
Фордж, походу, всё. Ну, по большей части.
Можно перекатываться на дев-вебуя, судя по всему туда завезли оптимизон (не весь).
Фордж, походу, всё. Ну, по большей части.
Можно перекатываться на дев-вебуя, судя по всему туда завезли оптимизон (не весь).
>неделями напрягался а не ты сам
Ага, а вдруг он (компьютер) выгорит от перенапряга, тогда придется неиллюзорно мне напрячься, чтобы его в рехаб отправить и замену купить. 210к степов, конечно, мое почтение целеустремленности научить модель.
>а можешь датасет показать?
Могу, только его очень поискать надо, попробую завтра в выходной как раз же.
>могло дать подобный эффект
Моя теория - фотограф на постобработке не просто поигрался ползунками в Лайтруме, а жестко и решительно накинул LUT.
>Можно починить нормализацией пикч
Про графику тоже слышал, что годно помогает, а вот про реализм - не знаю, надо почитать, спасибо за наводку!
>Насколько потом модель может четкий не-заблюренный фон делать? И для чего вырезать фон, там что-то нехорошее?
Вообще не влияет, пробовал и с блюром и без, главное - на подблюренных пикчах в датасете более конкретно прокапитонить, описав только сабжа и ничего более.
Блюрить - не столько вырезать что-то нехорошее, сколько исключить фоновые объекты с пикчи, при тренировке, например, на пикче, где сабж стоит на фоне елок, велоятность получить потом от лоры генерацию с деревом выше, чем если эту сраную елку подблюрить чтобы явно очертания не считывались. Лучше конечно совсем вырезать фон, но. как я говорил выше иногда лениво, проще кистьб помазюкать.
>Могут ухудшиться генерации в соотношениях сторон не 1к1, особенно в определенных ракурсах/позах и т.д.
Хм, не замечал, надо практически проверить, интересная тема.
>Лучше конечно совсем вырезать фон
Рукалицо...
Лучше этот фон протэгать. Когда у тебя эта елка в кэпшонах - модель ее поймет (потому что уже знает), и будет вызывать только по запросу. Ну или случайно, что тоже лечится - негативным запросом или прописыванием определенного фона в промпте.
Если у тебя на заднике будет мазня, которую ты даже как "blury background" или "bokeh" в файле не запишешь - эта мазня у тебя с другими токенами ассоциироваться начнет, в том числе и с тем основным, на который ты тренируешь.
Ля, крутая штука. Которая изменение первого кадра распространяет на всё видео. Для "изменения" одежды самое то
Даже если всё окажется не так радужно, то благодаря изменений в цвете можно создать стабильную видео маску и пустить в animatediff inpainting
К сожалению весов и кода пока нет. Буду терпеть когда выложат
https://i2vedit.github.io/index.html
Даже если всё окажется не так радужно, то благодаря изменений в цвете можно создать стабильную видео маску и пустить в animatediff inpainting
К сожалению весов и кода пока нет. Буду терпеть когда выложат
https://i2vedit.github.io/index.html
> Ага, а вдруг он (компьютер) выгорит от перенапряга
Значит туда и дорога, хули.
> мое почтение целеустремленности научить модель.
Ее палкой вообще бить надо чтобы хоть что-то нормально запоминала.
> главное - на подблюренных пикчах в датасете более конкретно прокапитонить
Так ты опиши задник, правильно тебе говорят. А тут дополнительно заставляешь модель запоминать что задников несуществует или там одно мыло, захочешь что-то сложное запромтить и досвидули.

Это я. Зашел поблагодарить анона/анонов, которые тогда мне помогали делать лору под пони. Тогда сразу не отписал, потом всё руки не доходили что-то. В итоге получилось все более менее неплохо. Думаю я выжал практически всё что можно было сделать при моём датасете (60). На 48 эпохе генерирует неплохо, эталонные изображение вообще практически идеально, есть проблемы с деталями, думаю эт оследствие того что лора впитала не только персонажа, но и стиль. Может если сделать лору под 1.5, а потом нагенерить в других стилях, чтобы добить датасет, получилось бы лучше. Также, в отличие от 1.5, судя по гридам, лора стабильно работает только в очень узком диапазоне эпох
ии силе лоры. Вообще, пони конечно кривые спецефичные. Короче буду заниматься дальше как время подосвободится. Присмотрел пару авторов, думаю сделать лору под них, благо тут уже проблем с датасетом не будет. Но что там сейас по мете? Я так понял народ ждет сд3 и новых поней? Читал пост автора поней, он и сам сидит и ждет новый сд, там какие-то траблы с правилами комерческого использования. Говорит мол что чет стабилити мудаковато общаются.
ии силе лоры. Вообще, пони конечно кривые спецефичные. Короче буду заниматься дальше как время подосвободится. Присмотрел пару авторов, думаю сделать лору под них, благо тут уже проблем с датасетом не будет. Но что там сейас по мете? Я так понял народ ждет сд3 и новых поней? Читал пост автора поней, он и сам сидит и ждет новый сд, там какие-то траблы с правилами комерческого использования. Говорит мол что чет стабилити мудаковато общаются.
> Я так понял народ ждет сд3 и новых поней?
SD3 мертворождённая и пони не будет на ней. Следующая пони на XL, а потом на пиксарте или какой-то другой китайской сетке.
>Я так понял народ ждет сд3 и новых поней?
На не будет, автор нытик-омежка, который никак не может прочитать 3 абзаца на 2-х страницах сайта SAI и ссытся от того, "что ему непонятно как лицензироваться"
Rundiffusion - залицензировались и пилят файнтюн для сервиса
Леонардо - залиуензировалось
Мелкие онлыйн-помойки уже добавили в свои списки SD3
Pirate diffusion просто положили хуй на лицензирование (как неожиданнно) и высрали анонс что к 1 июля ждите pirate edition
А это ничтожество третий день бегает между реддитом, цивитаем и форчаном, ноя что ему непонятно и он так не может.
Сегодня аж на японский свой высер перевел на циве.
> никак не может прочитать 3 абзаца
А что там читать? Там не опенсорс лицензия, а коммерческую ему никто не продаст из принципа.
> непонятно
Там лицензирование в виде "звоните нам". А на том конце провода ссутся с пони.
> бегает
Не понятно только почему у SD-шизиков так пригорает от того факта, что он не будет дальше тренить на SD. Наоборот же хорошо, не будем больше жрать SAI-кал с поломанными архитектурами. Автор гуя для кохи уже сказал что SD3 кал для тренировки и надо просто считать это говно провалом как SD 2.0, а лицензия вообще большинство тюнов отсеит сразу. У кохи, кста, уже готова поддержка Сигмы.
Забавнее всего наблюдать как SAI изворачивается и опять пытается напиздеть что-то. Сегодня у них уже официальная методичка подъехала, что SD3-Medium это ранняя бета и вы не так поняли, хотя только вчера Ликон рассказывал что это лучшая модель и у вас руки кривые. А ещё вскрылось со слов SAI опять же что медиум тренили с нуля по-быстрому за два последних месяца с дико порезанным датасетом и в сырости виноваты нетерпеливые юзеры, а оригинальная 8В через API вообще другая модель и её даже не собирались релизить.


>Забавнее всего наблюдать как SAI изворачивается и опять пытается напиздеть что-то. Сегодня у них уже официальная методичка подъехала, что SD3-Medium это ранняя бета и вы не так поняли, хотя только вчера Ликон рассказывал что это лучшая модель и у вас руки кривые. А ещё вскрылось со слов SAI опять же что медиум тренили с нуля по-быстрому за два последних месяца с дико порезанным датасетом и в сырости виноваты нетерпеливые юзеры, а оригинальная 8В через API вообще другая модель и её даже не собирались релизить.
Уже новую завезли - все охуенно, все так и должно быть. Но если что - это CLIP, оттуда Рутковские лезут.
Это Эмад высрал в Х (пикрил):
https://x.com/EMostaque/status/1801686921967436056
https://twitter.com/EMostaque/status/1571634871084236801
>Там лицензирование в виде "звоните нам". А на том конце провода ссутся с пони.
Нихуя, 20$ и иди пили, пока у тебя 1 лям пользователей в месяц онлайн не набрерется или годовой оборот не дойдет до 1 млн $, вот тогда ЗВОНИТЕ ЭМАДУ.
>а коммерческую ему никто не продаст из принципа.
С хуяли не продаст? Ну ебаный в рот, у него пару косарей на Cоула местного нет? Все на пропердоливание score_9 ушло?
>Не понятно только почему у SD-шизиков так пригорает от того факта, что он не будет дальше тренить на SD
Потому что, посмотри на циву, 95% моделей\лор\пикч - 2-2.5D мультипликация. Аудитория у него такая, что поделать.
>Автор гуя для кохи уже сказал что SD3 кал для тренировки и надо просто считать это говно провалом как SD 2.0, а лицензия вообще большинство тюнов отсеит сразу. У кохи, кста, уже готова поддержка Сигмы.
Вот это отлично, альтернатива и конкуренция - всегда заебись для нас.
>что SD3 кал для тренировки
лол это потому что опубликованные в диффузерсах скрипты нихуя не работают, там в ишшуисах пожар выше крыши.
НО! вот тут : https://github.com/bghira/SimpleTuner/ обещает мало того что Лоры для сд3, но и главное : файтюн модели на 3090.
Хуй с ними с лорами, а вот представь, если каждый начнет себе пилить свою XL? Это же заебись.
Лично по мне, я понями никогда не пользовался, они мне нахуй не уперлись, к СД3 уже придрочился по сеттингу и промтам, если людей не генерить лол. Но,уверен, анатомия, позы - это первое что начнут тюнить.
В результате получится охуенный сетап: что-то в XL, что-то в Сигме, что-то в Далли, что-то в CД3 делать. Это же просто инструменты, и то что их несколько - это хорошо.
Меня чисто нытье понибати и его паствы бесит, везде блядь они, везде.

Подскажите пожалуйста как проверить орфографические ошибки в датасете (captions).
тхт открывай хромом, если правописание англ включено подсветит или сам себе в телегу кидай в чем сомневаешься, там тоже работает.
Ты руками что ли бил?
>тхт открывай хромом
Там ~100 штук, я охуею каждый файл проверять.
>Ты руками что ли бил?
Да. Clip interrogator разочаровал.
Ок, я нашел способ. Нужно просто в DatasetHelpers подсчитать частоту тэгов и скопировать этот текст в программу с проверкой правописания, например хром как подсказал анон.

> Эмад
А он тут при чём? Он уже почти никакого отношения к происходящему не имеет. Официальная позиция представителей SAI пикрилейтед, они переобуваются каждый день.
> 20$ и иди пили
Там ограничение на количество генераций с модели, лол. Ещё раз - лицензия не опенсорс, ты хоть усрись, но будешь башлять SAI даже без коммерческого использования. Под такими условиями никто не будет делать крупные файнтюны.
> это потому что опубликованные в диффузерсах скрипты нихуя не работают
Тот чел пояснял что концепты на SD3 тренируются очень плохо, даже очень простые, поэтому тренить лоры как с XL на 50 пиках не выйдет.
Напомните, что там надо скопировать, чтоб все настройки с одной копии ВебУЯ на другую перенести.
config.json, ui-config.json

как можно загрузить картинку в уже открытый и настроенный автоматик1111 в инпеинт?
я хочу следующее:
- нажимаю кнопку в блендере
- вьюпорт захватывается, сохраняется в папку
- картинка автоматически подхватывается и загружается в img2img inpaint
- я делаю инпеинт с нужным мне результатом и сохраняю пик на диск
- нажимаю кнопку в блендере, получаю на экране текстуру-стенсиль
меня интересует выделенное жирным, остальное я знаю как сделать
я хочу следующее:
- нажимаю кнопку в блендере
- вьюпорт захватывается, сохраняется в папку
- картинка автоматически подхватывается и загружается в img2img inpaint
- я делаю инпеинт с нужным мне результатом и сохраняю пик на диск
- нажимаю кнопку в блендере, получаю на экране текстуру-стенсиль
меня интересует выделенное жирным, остальное я знаю как сделать
Тебе так трудно картинку вручную вставить? Тут либо костылять либо костылять. В первом случае править автоматик, чтобы он сканил твою папку и подгружал файл, во втором случае какой-нибудь грисманки, чтобы он делал то же самое, но со стороны браузера (Насколько я помню там такие апи есть, а если нет - то только автоматик). Если я правильно понял что ты хочешь.

одну картинку вставить несложно. но в процессе работы это делается сотни, тысячи раз, зачастую буквально на 1 мазок кистью нужно инпеинт сделать. и на эту дрочь уходит половина времени

короче, все этапы кроме самого нужного реализовал
узнал про API: https://github.com/AUTOMATIC1111/stable-diffusion-webui/wiki/API
и даже получилось послать корректный POST запрос и сгенерить картиночку прямо из блендера, получив результат в виде пнгшки закодированной в респонсе. да вот мне не нужен бэкэнд автоматика. мне нужен фронтенд на соседнем монике, чтобы я в нем менял модели, лоры, перерисовывал маски, перегенерировал всё по сто раз и т.д. там быстрее всего работается
есть в том API что-то для управления фронтендом? менять вкладки в интерфейсе, загружать картинки и т.д. или таких вещей в принципе не бывает в API?
Сделать на комфи с захватом картинки из блендера - нет?
как этот процесс будет происходить в случае с комфи?
>- нажимаю кнопку в блендере
>- вьюпорт захватывается, сохраняется в папку
>- картинка автоматически подхватывается и загружается в img2img inpaint
>- я делаю инпеинт с нужным мне результатом и сохраняю пик на диск
Специальные ноды.
Будет окно для захвата картинки из блендера, из него картинка идет в ноду, в ней можно нарисовать или загрузить маску. Потом все вместе с маской идет в сэмплер, выхлоп сохраняется через ноду в нужное место
>- нажимаю кнопку в блендере, получаю на экране текстуру-стенсиль
А это руками
Хотя есть просто отдельные ноды для текстурированния

буквально - три слова в строке поиска ютуба:
blender+statble+diffusion
На любой вкус:
- и с Автоматиком и с Комфи
- и для созлания анимации
- и через хитропридуманные костыли
- и на русском и на английском
спасибо, попробую
Текстурируеш?

так баловаюсь
Не погано. Вот бы можно было позу с картинки в риг переносить.

Запрашиваю тактическую помощь, как это говно даунгрейднуть?
Я хз почему, но это вылечилось удалением файла ui-config, запуском каломатика, который успешно запустился, после чего я закинул обратно файл и всё заработало без ошибок. ЧЗХ с каломатиком?

я через junction вытащил модели наружу, и теперь перенакатываю вебуй начисто вместо апгрейда
когда у приложения в одной папке насрано файлами json, yaml, toml, понимаешь, что лучше перестраховаться
./models
./embeddings
./extensions/sd-webui-controlnet/annotator/downloads
только с outputs не прокатило, не подгружает картинки из junction
наверное ПО теперь ошибочно считает, что зависимость стоит правильной версии
Объясните нубу, как правильно обновлять что-то с гита, если он выдает такой текст:
>Please commit your changes or stash them before you switch branches.
Хочу на дев-ветку автоматика переключиться, и он мне список файлов выдает, в которых я сам явно ничего не менял.
Если reset hard сделать - вроде бы полетят и все настройки, а этого бы не хотелось.
>Please commit your changes or stash them before you switch branches.
Хочу на дев-ветку автоматика переключиться, и он мне список файлов выдает, в которых я сам явно ничего не менял.
Если reset hard сделать - вроде бы полетят и все настройки, а этого бы не хотелось.
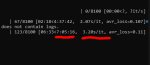
Оно так и должно медленно идти? Треню sdxl лору на 4060ti 16gb.
Да. СДХЛ лоры тренируются намного медленнее сравнительно с полторашками.
Плюс у тебя еще и шагов овердохрена, столько обычно не нужно.
Я в целом только вкатываюсь в тренировку лор. Такое количество шагов подобрал исходя из гайда в шапке.
От 8000 до 12000 для стилей. чек
От 400 до 600 итераций на эпоху. У меня всего 81 изображение. Как раз, чтобы было 8к шагов, сделал 10 повторений на 10 эпох на 81 картинку.
>От 8000 до 12000 для стилей.
Ужас какой. Где там вообще такое написано? Чем можно тренировать настолько долго?
Я когда своими старыми настройками тренировал - у меня стиль начинал ухватываться уже на 800-м шаге, и на 1600 закреплялся полностью.
Ну там буквально на строчку ниже другое значение для XL написано, но вообще странная скорость, ты сколько батч поставил? Есть чекпоинтинг?
> Я когда своими старыми настройками тренировал - у меня стиль начинал ухватываться уже на 800-м шаге, и на 1600 закреплялся полностью.
А что именно тренил и с каким батчем? Те цифры были выведены эксперементальным путём для бородатого наи, учитывая остальные дампенеры и не учитывая деления на батч
Батч сайз 1, потому что все 16гб заняты, если верить афтербернеру.
>чекпоинтинг
Что?
> Батч сайз 1, потому что все 16гб заняты, если верить афтербернеру.
У тебя полезло всё в системную память, ХЛ без --gradient_checkpointing жрёт слишком много, а более простой вариант кстати расписан https://rentry.org/2chAI_hard_LoRA_guide#easy-way-xl с готовыми конфигами




Получаются абсолютно рандомные, взорванные генерации, но иногда получается что-то похожее на космические пейзажи. Позже попробую еще, возможно сперва набью руку на полторашке.
Всем спасибо.
Всем спасибо.
Это с тем конфигом так? Если да, то интересно глянуть на датасет и пример генерации с метадатой, чтобы понять причину
Я думаю надо так же сделать. у меня гуй отказывается реагировать если F5 не нажать после запуска. Видимо пора.
Стили и концепты в основном.
Адам, косинус, батч 2. Конфиг как раз времен "бородатого НАИ", работает на поне практически без изменений, только памяти больше жрет, и в три раза дольше тренирует.
https://stackoverflow.com/questions/4157189/how-to-git-pull-while-ignoring-local-changes
Просто забекапь настройки.
В целом да, чекни чтобы видеокарта была загружена а не простаивала.
> От 8000 до 12000 для стилей. чек
Это борщ, только если делаешь большую лору на десяток стилей, и шаги в отрыве от батчсайза малоинформативны.
Пони? Она настолько убита гейпами что с наскоку подобное не сделать.

Нет, тот конфиг не ставил. Датасет пикрил, там все картинки такие.
кэтбокс даже с впном не открывается
Не просто пони, а аутизм.
Наверное дело в том, что я через анимешный микс поней делаю лору с датасетом из реалистичных картинок. При этом пытаюсь научить концепту, который поням вообще не известен.
> Не просто пони, а аутизм.
Еще хуже, оно более переломанное с точки зрения модели, работать в диапазоне задач это не мешает, но тренить на таком - плохое решение.
Капшнинг у них какой? Обычная XL или анимушные модели не-пони без проблем такому обучатся если будут нормально протеганы.
А какие остальные настройки? Просто я точно помню что в 512 разрешении там и не нужно было столько тренить
> Нет, тот конфиг не ставил. Датасет пикрил, там все картинки такие.
Лол, ты конечно нашёл высокохудожественный чекпоинт чтобы такое тренить, пони кумерский в первую очередь, так ты ещё и на аутизме тренил, что вдвойне плохо, для такого может какой то анимейджин бы лучше подошёл или даже вообще что нибудь дедовское
> кэтбокс даже с впном не открывается
Ну любой другой сайт/способ передать картинку с метадатой
> Не просто пони, а аутизм.
Тренить с аутизма стоит только в одном единственном случае, когда юзаешь только его и хочешь во что бы то ни стало вжарить какой нибудь стилевый датасет и чтобы он проявлялся вообще всегда с первого взгляда, на каждом промпте, перебивая даже саму модель. Но это такое себе занятие, которое сломает анатомию аутизма практически гарантированно
Посмотри в диспетчере задач, если памяти жрёт больше чем выделенная память видимокарты, то часть уходит в оперативку и получаешь дикие тормоза - тогда уменьшай батчсайз или включай градиент чекпоинт.
>Просто забекапь настройки.
Что-нибудь забуду, и потом придется заново настраивать...
Хотелось бы, чтоб он этот ресет как пулл делал - т.е. игнорируя те файлы, которые трогать не надо с точки зрения обновлений.
>А какие остальные настройки?
mixed_precision = "fp16"
max_data_loader_n_workers = 1
persistent_data_loader_workers = true
max_token_length = 225
prior_loss_weight = 1.0
sdxl = true
xformers = true
cache_latents = true
max_train_epochs = 8
gradient_checkpointing = true
resolution = [ 1024, 1024,]
batch_size = 2
network_dim = 32
network_alpha = 16.0
min_timestep = 0
max_timestep = 1000
optimizer_type = "AdamW8bit"
lr_scheduler = "cosine"
learning_rate = 0.0002
max_grad_norm = 1.0
unet_lr = 0.0002
text_encoder_lr = 0.0001
enable_bucket = true
min_bucket_reso = 512
max_bucket_reso = 2048
bucket_reso_steps = 64
bucket_no_upscale = true
weight_decay = "0.1"
betas = "0.9,0.99"
Как-то так, вроде ничего важного не забыл.
Разве что эпохи вместо шагов указаны, но я там все настраиваю так, чтоб полная тренировка на 2000-2400 шагов получалась. Хотя могу взять и 4, и 6 эпоху вместо финальной 8-й, если вижу, что там получше получилось.
Датасеты обычно крупные, от 100 картинок.
> sdxl = true
Да не, я про конфиг для наи имел ввиду, для хл то база, сам ведь почти таким же пользуюсь
> наи
Кто вообще полторахой пользуется в 2024?
А, ну так он такой же, за исключением этого флага и размера бакетов/картинок. Там либо 512, либо 768, если память позволяет.
Я ж говорил, что конфиг времен НАИ, в нем только это и поменялось, считай.
кто-то тренил в каггле sdxl лоры?
такое ощущение что те кто хочет обучать лоры уже имеют карточки для этого, а нищукам просто похуй и используют онлайн слоп-генераторы
такое ощущение что те кто хочет обучать лоры уже имеют карточки для этого, а нищукам просто похуй и используют онлайн слоп-генераторы
Хватит срать этим по тредам. Иди трейни на Civitai с мультиакка

Как в AD внедрить контролнет?
Список моделей не открывается
Не использовать AD для таких задач, а переключиться на и2и во вкладку ипнэинта.
>ипнэинт
Зачем ручками работать там, где можно автоматизировать?
По крайней мере, я хочу протестить эту тему
Затем, что творчество.
пиздец, вроде как 32гб vram, но есть нюанс, то что эти 32гб разделены на две видяхи
пытался обучать дефолтным скриптом кохи, и нихуя не получалось выше 1 батч сайза поставить с градиентом
видимо скрипт хуево параллелит нагрузку или модель sdxl большая слишком для таких задач
пытался обучать дефолтным скриптом кохи, и нихуя не получалось выше 1 батч сайза поставить с градиентом
видимо скрипт хуево параллелит нагрузку или модель sdxl большая слишком для таких задач
чел, ты видюхи хоть выбирал или просто на похуй запустил
>выбирал
я просто скрипт кохи запустил и все
с --multi-gpu эта хуйня выдаёт оом
без него не выдаёт, но при этом хавает память с 2 видях
> но есть нюанс
Это неебаться какой нюанс, в теоретической теории можно обойтись FSDP но на консумерских видюхах с кохой это, считай без шансов.
В гайдах в шапке есть настройки для лоры, они позволяют ужаться до 12гб для минимального обучения без серьезных импактов на качество. В 16 гигов будет влезать некоторый батч сайз. Вторая видюха будет просто ускорять обучение в 2 раза (если подключена по нормальной шине, меньше если всратая) но никак не прибавит тебе возможностей по памяти.
Можешь накатить dev ветку и использовать fused оптимайзер, адам8бит в них отсутствует, так что единственный полезный будет adafactor. Это прилично снизит требования к врам. Можешь обмазаться дипспидом, если не будет компилироваться - пропиши в энвах пути до либ новидео, но для него потребуется дохуя рам.
Если хочешь больше эффективный батчсайз - накати pr на добавление фьюзед оптимайзеров, там дополнительно есть функция, которая позволяет делать накопление градиента на фьюзед оптимайзерах и не тратить приличный кусок врам на это.
> видимо скрипт хуево параллелит нагрузку
Он отлично ее параллелит, объединение врам в сделку не входит никогда, если только явно не раскидывать части модели по разным девайсам.
Да, мультигпу и все это актуально для прыщей или wsl, удачи собрать все нужные либы под окнами.
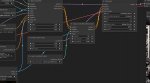
Выгнали с sd треда сюда, с таким вопросом
Юзаю такие настройки. Ставлю end_percent на canny повыше и получается мазня, а щас не соответствует референсу. Что крутить?
Юзаю такие настройки. Ставлю end_percent на canny повыше и получается мазня, а щас не соответствует референсу. Что крутить?
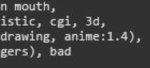
Делай плавное понижение веса и гони до самого конца, а не 0.4. И судя по пикрилу ты шиз, тебе только таблетки помогут. Особенно если ты для аниме canny используешь.
>Делай плавное понижение веса и гони до самого конца, а не 0.4.
Попробую
>И судя по пикрилу ты шиз, тебе только таблетки помогут. Особенно если ты для аниме canny используешь.
Это негативный промпт, как давно где-то скопировал так и юзаю, надо будет поправить. Использую для фотореала. Раньше использовал zoe depth, но оно тоже попердоливает цвета если большие веса и end_percent дать
> 1016
> sdxl
Уже с этим проебався, кратности 64 следует придерживаться.
> Ставлю end_percent на canny повыше и получается мазня
Препроцессор как работает и в каком разрешении? Канни в принципе не стоит держать на силе 1 с полном циклом, ибо она слишком агрессивная и "пиксель перфект". Используй лайн арт или аналоги, их можешь сколько угодно жарить. Как тебе сказали используй спадающую силу под конец. Проверь совместима ли вообще эта модель с чекпоинтом что используешь.
Ну и за трешанину в промте двачую.

Сап обновил кохины скрипты, там теперь торч 2.1.2. Где брать норм куду, чтобы ему вбросить? Старый вброс не подходит по именам файлов. Че он ее сам не вбрасывает, заебал, с каждым апдейтом скорость падает на 20%
Какие именно скрипты, какую куду, какой вброс? Распиши подробнее, ничего не понятно.
>с outputs не прокатило
В настройках есть папки куда сейвить выхлопы
Раньше советовалось скачивать свежий cudnn (11 или 12, не помню от чего зависит) и вбрасывать dll-ки в site-packages/torch-x.x.x/lib/, с заменой файлов. Это ускоряло мне тренинг с 1.7-1.8 до 2+ итсов.
Щас торч другой версии и куда там тоже другая, и это выдает на 1.6 итсов. Прошлый свежий cudnn туда не подходит. Вот я и спрашиваю где его правильно брать, ну или послать все нах и сделать даунгрейд.
Кто может посоветовать, тот и так в курсе этой ебатории.
Это было оче давно и уже неправда. Делаешь
> pip install torch==2.1.2 torchvision==0.16.2 torchaudio==2.1.2 --index-url https://download.pytorch.org/whl/cu121
> pip install xformers==0.0.23.post1
Потом реквайрменты и довольно урчишь. Про ту херь забудь как страшный сон.
Попробую, спасибо. /cu121 это как раз для 12 куды сборка?
> # CUDA 12.1

Нашел в итоге сам подходящие куднны. Проверил разные варианты на 300 итерациях (первый тест был холодный, но не думаю что здесь это важно).
Как видим, ку118 + свежая куда все еще тащит. Разница небольшая, но это из-за тупой реализации счетчика и малого колва шагов на тест. Через 1000 шагов оно сойдется к большему значению.
Если седня на ку118+8.9.7 выдаст около 2 итса, то меня устроит. Если не выдаст, то отпишу в тред.
Для ясности
1: оригинал, свежая копия кохи без модификаций, на 3000 шагах дает 1.6х итсов
2: как 1 + в site-packages/torch/lib закинуты дллки отсюда: https://developer.nvidia.com/rdp/cudnn-archive -> Download cuDNN v8.9.7 (December 5th, 2023), for CUDA 11.x
3: как 1 + рецепт анона
4: как 3 + в site-packages/torch/lib закинуты дллки отсюда: https://developer.nvidia.com/rdp/cudnn-archive -> Download cuDNN v8.9.7 (December 5th, 2023), for CUDA 12.x
Если кто будет существующий инсталл править:
> pip install torch==2.1.2 torchvision==0.16.2 torchaudio==2.1.2 --index-url https://download.pytorch.org/whl/cu121
Это работает само по себе
> pip install xformers==0.0.23.post1
Это работает только после pip uninstall xfromers, иначе пип считает, что +cu188 и так стоит, и не ставит версию без +cu118, которая на самом деле +cu121, но опубликованная без суффикса. ебанутее нет создания чем питонист блять
Как видим, ку118 + свежая куда все еще тащит. Разница небольшая, но это из-за тупой реализации счетчика и малого колва шагов на тест. Через 1000 шагов оно сойдется к большему значению.
Если седня на ку118+8.9.7 выдаст около 2 итса, то меня устроит. Если не выдаст, то отпишу в тред.
Для ясности
1: оригинал, свежая копия кохи без модификаций, на 3000 шагах дает 1.6х итсов
2: как 1 + в site-packages/torch/lib закинуты дллки отсюда: https://developer.nvidia.com/rdp/cudnn-archive -> Download cuDNN v8.9.7 (December 5th, 2023), for CUDA 11.x
3: как 1 + рецепт анона
4: как 3 + в site-packages/torch/lib закинуты дллки отсюда: https://developer.nvidia.com/rdp/cudnn-archive -> Download cuDNN v8.9.7 (December 5th, 2023), for CUDA 12.x
Если кто будет существующий инсталл править:
> pip install torch==2.1.2 torchvision==0.16.2 torchaudio==2.1.2 --index-url https://download.pytorch.org/whl/cu121
Это работает само по себе
> pip install xformers==0.0.23.post1
Это работает только после pip uninstall xfromers, иначе пип считает, что +cu188 и так стоит, и не ставит версию без +cu118, которая на самом деле +cu121, но опубликованная без суффикса. ебанутее нет создания чем питонист блять
У тебя там GTX 1660 что ли?
а что должно быть?
у меня
>[1:54:30<50:43, 3.30s/it, avr_loss=0.0372]
на двух теслах т4 для sdxl лоры
мимо нищук на каггле
Итсы зависят от параметров тренинга, у разных анонов они разные. Важны только относительные значения.
>xfromers, иначе пип считает, что +cu188 и так стоит
>xformers, иначе пип считает, что +cu118 и так стоит
самофикс
Что за видеокарта и система?
Просто ставишь версию для куды121 и забываешь, твой скрин это подтверждает. В фоне браузер чуть поскроль и будет аналогичного масштаба эффект.
> Это работает само по себе
Не всегда и не везде.
> Это работает только после pip uninstall xfromers
Чивоблять? У тебя там васян-обертка поверх кохи, или ставишь сразу рекварментсы в надежде что правильный торч скачается?
Нужно делать именно в таком порядке на свежем вэнве, а не ломать совместимость или качать неправильные версии на уже засранном.
> ебанутее нет создания чем питонист блять
Сам создаешь проблемы, а богоподобный пип всеравно их исправляет, подсовывая все совместимое.

Винда, 4070ти.
>Чивоблять? У тебя там васян-обертка поверх кохи, или ставишь сразу рекварментсы в надежде что правильный торч скачается?
Дефолтная коха после setup.bat (пункты install + download cuda).
>Нужно делать именно в таком порядке на свежем вэнве, а не ломать совместимость или качать неправильные версии на уже засранном.
Я знаю что делаю тащемта. Итсы берутся из торча и куды. Что там вокруг валяется и каких версий - никакого значения для процесса тренинга не имеет, т.к. это просто клей для овермайнд методов, зашитых в торчекуде.
По итогу заменены 4 пакета, торч, вижен, аудио, хформерсы.
>богоподобный пип всеравно их исправляет
Да, а потом "WARNING xfromers not loaded 118 vs 121". А если ставишь без версии, то качает торч 2.3.0.
Че ты так трясешься с этого, фанбой что-ли? У питонистов вечно проблемы на ровном месте. Я щас добью вопрос и поделюсь результатом и рецептом, какие бы ни были. Не на риторике, а на фактах.
---
Вариант cu118+свежий куднн на 3к шагов показал 1.89 (пик), против 1.6 стока.
Я щас проверю полный трен cu121 стока, ок, мне не жалко.
> Дефолтная коха после setup.bat
Это уже гуйня, дефолтная коха - https://github.com/kohya-ss/sd-scripts
В принципе с ней можешь просто нажать сетап, оно все само сделает. А готовый вэнв шатать с кучей взаимных зависимостей такое себе.
> Итсы берутся из торча и куды.
Расскажи это кохаку с поломанными версиями ликориса. А так в новом торче оно заведомо все быстрое.
> Я знаю что делаю тащемта
> Да, а потом "WARNING xfromers not loaded 118 vs 121"
Ну вот видишь. Важен порядок установки и конкретный синтаксис с указанными версиями, а не свободная интерпретация. По дефолту качается ластовая с 2.3 торчем, да, но коха на ней не сработает. Под 2.1.2 именно версия 0.0.23.post1 если полистать репу то там написано.
> Че ты так трясешься с этого
Чел, пока что трясешься только ты, бездумно тыкаешься а потом жалуешься, пытаясь повторять историческую херь, на которую даже те кто ее пропагандировал уже забили. И судя по надписям у тебя там мешанина из версий, которая такой эффект и дает.

Я протестил все варианты, только в этот раз включил версию драйвера. Твой, с абсолютно новым венвом, тоже протетсил.
В итоге:
- Без вброса свежих дллок cu118 тренит на 1.6-1.7 итсах
- Ты прав, в полном тренинге cu121 со вбросом и без вброса (1.86) несильно отличается от cu118+вброс (1.89). Видимо в cu121 просто по дефолту свежий куднн.
- При драйвере 551.52 cu121 достиг 1.94 итсов, а cu118 - 1.97 итсов
Новый драйвер я сдуру поставил, забыв что он нерфит тренинг.
Вывод:
- Ставишь 551.52
- Вбрасываешь дллки если сидишь на cu118 (ссылка выше)
- Сидеть на cu121 большого смысла нет
>Это уже гуйня
Да похер, пикрил
>Важен порядок установки и конкретный синтаксис с указанными
Ладно.жпг
>бездумно тыкаешься а потом жалуешься, пытаясь повторять историческую херь, на которую даже те кто ее пропагандировал уже забили
Если посмотреть выше, то я вроде как пришел к успеху. Правда я сам от него же и ушел, поставив ебучий новый драйвер и не записав в прошлый раз ссылку на хороший куднн. Зато обновил тесты, хуле, может кому пригодится.
>Уже с этим проебався, кратности 64 следует придерживаться.
Тут мимо, я InstantID еще предварительно использую, а там если 1024 ставить лютые ватермарки хуярит, поэтому только 1016
>Ну и за трешанину в промте двачую.
Промт уже поправил
Возможно, автор гуйни что-то там навертел в своем автоустановщике что он по дефолту ставит старые версии, от того и такой эффект. Это же у него раньше была опция прямо в инсталляторе "подкинуть библиотеки".
В твоем случае отличия в скорости могут быть еще из-за разных xformers, которые под шинду скомпилированы через одно место.
Собранный торч самодостаточен, и новая версия уже заведомо содержит последние библиотеки, то что надо было что-то подкидывать - костыль старых времен.
> - Сидеть на cu121 большого смысла нет
Наоборот, он дает полный перфоманс без странных манипуляций. Бонусом, если захочешь накатить новые пры и подобное - все будет работать без внезапных приколов. Разница что ты углядел - едва измерима, время записи на диск больше эффекта даст.
А здесь не ставит потому что края изображения идут по бороде, странно что оно без артефактов как-то декодится, возможно помогает тайлинг. Ну если работает то и норм.
Какова может быть причина пережарки? После 31 эпоха начало появляться мыло+контраст. По-спекулируйте пожалуйста. Настройки (civitai трейнер):
"resolution": 768,
"targetSteps": 2475,
"numRepeats": 5,
"maxTrainEpochs": 45,
"trainBatchSize": 6,
"unetLR": 0.00001,
"textEncoderLR": 0.00001,
"lrScheduler": "linear",
"networkDim": 128,
"networkAlpha": 64,
"noiseOffset": 0.1,
"lrSchedulerNumCycles": 3
"minSnrGamma": 5,
"optimizerType": "AdamW8Bit",
"flipAugmentation": false,
"loraType": "lora",
"clipSkip": 1,
"enableBucket": true,
"keepTokens": 0,
"shuffleCaption": true,
> "maxTrainEpochs": 45,
Пиздос.
> "numRepeats": 5,
> "maxTrainEpochs": 45,
Оче много если только там не датасет из десятка пикч. Но такой сам по себе может являться проблемой если не прибегать ко всякой черной магии.
> "unetLR": 0.00001,
> "textEncoderLR": 0.00001,
Но лр при этом относительно низкий для остальных параметров. Показывай в чем выражается твоя пережарка.



Там на самом деле 49 эпохов. 66 пикч. Tренировал стиль. Хотя вижу уже даже на 31 эпохе уже волосы слипаются и странных шарп на краях.
1 без лоры
2 31 эпох
3 49 эпох
Что получить пытаешься вообще? Показывай датасет, что в нем и как сделаны капшны.
Наблюдаемое может быть следствием и слишком низкого лр, и хуевого датасета, и много чего еще, но это не пережарка в классическом понимании.
Выстави нормальный LR, например раз в 5-10 больше для таких параметров, эпохи можешь смело в 2-3 раза снижать, шедулер можешь оставить, но лучше косинус воткнуть.
>Наблюдаемое может быть следствием и слишком низкого лр,
Спасибо, не знал что даже это может иметь негативные последствия.
Видео рил была предыдущая попытка, тот же датасет, те же настройки кроме noise offset, его я поднял с 0.1 до 0.12, но другой чекпоинт. Уже на 7 эпохе какая-то пережарка пошла по этому я и боялся выставлять высокий LR.
>не пережарка в классическом понимании
Не дожарка?
>эпохи можешь смело в 2-3 раза снижать
Да выставил максимальные эпохи чтобы базз за просто так не уходил.
>Показывай датасет
Не хочу диванонится, т.к. если лора получится хорошей то залью её на циви.
капшн1:
orange eyes, looking at viewer, fixing her glasses, big breasts, cleavage, black leather skirt, red lips, red tail, red choker, red gloves, from above, secretary outfit, red background, red light, photorealistic, realistic, имя художника на англюсике, glasses, solo, sfw
капшн2:
ada wong from resident evil, solo, nude, asian, nipples, breasts, brown eyes, belly button, pubes, red bikini, black choker, bob haircut, black hair, standing, holding guns, thick thighs, looking at viewer, low angle, indoors, realistic, by имя художника на англюсике, dominant
> кроме noise offset
Вот его лучше вообще убери. Если в чекпоинте уже есть, или применяется другая лора с ним - поломается капитально.
Ты только на циве семплинг в процессе обучения смотрел? То же самое только с хайрезфиксом хотябы попробуй, и гридом по разным эпохам как раз. Артефакты такие могут и из датасета лезть, и из-за косячного vae при кодировке, множество причин в общем. Еще, как вариант, снизить лр текстового энкодера не более трети-половины от лр юнета.
> ыставил максимальные эпохи чтобы базз за просто так не уходил
Тут просто нюанс в том как работает косинус, на максимальных эпохах он будет медленно снижаться и долго жарить в начале. Косинус с рестартами тогда уже поставь или лучше annealing чтобы один период приходился на сколько эпох.
Капшны нормальные если просто по тексту оценивать.
я правильно понимаю что альфа в параметрах обучения это тупо константный множитель и a=r/2 это тупо каргокульт?
если дотрейнить лору с альфой 1 одним шажком с параметрами альфа например 32 - она станет эквивалентом лоры которая обучалась с самого начала на альфа=32?
если дотрейнить лору с альфой 1 одним шажком с параметрами альфа например 32 - она станет эквивалентом лоры которая обучалась с самого начала на альфа=32?
> если дотрейнить лору с альфой 1 одним шажком с параметрами альфа например 32 - она станет эквивалентом лоры которая обучалась с самого начала на альфа=32?
сам спросил, сам потестил по-разному - не станет, но отличия от исходной всё меняют генерацию даже на одном шаге с околонулевым лр
> альфа в параметрах обучения это тупо константный множитель и a=r/2 это тупо каргокульт?
В целом да
> если дотрейнить лору с альфой 1 одним шажком с параметрами альфа например 32 - она станет эквивалентом лоры которая обучалась с самого начала на альфа=32?
Абсолютно нет. Но если тренить с кратно большим лр - будет нечто похожее, офк там оптимайзер свои коррективы вносит и конечный результат может отличаться.
> меняют генерацию
Даже слабое шатание весов лоры может заметно менять воспроизведение сидов. В интеграле работа при этом не изменится.
>Вот его лучше вообще убери. Если в чекпоинте уже есть, или применяется другая лора с ним - поломается капитально.
Ясно.
>Ты только на циве семплинг в процессе обучения смотрел?
Циви использую потому что больше нигде нет бесплатного тренинга лоры.
>То же самое только с хайрезфиксом хотябы попробуй, и гридом по разным эпохам как раз.
Ты имеешь ввиду сейчас посмотреть есть ли артефакты при генерации i2i?
>Еще, как вариант, снизить лр текстового энкодера не более трети-половины от лр юнета.
Попробую.
>annealing
Такого в циви нет.
Есть фото референс. Задача сгенерить свое по этому референсу с максимальной детализацией. Что использовать?
да буквально что угодно, можешь тупо имг ту имг, можешь инпейнтом, можешь контролнет канни/глубины/карты нормалей, можешь референс, можешь лору натрейнить, если ебало очень кривое - можешь даже лору со свёрткой
Ананасы, насколько актуален этот https://rentry.org/2chAI_hard_LoRA_guide
гайд? И как мне тренировать персонажа: хочу лору по девке из непопулярной вн, и поэтому всё, что у меня есть —это ~20 цг из игры, все с голландским кадром или другими персонажами (если замазывать в фотошопе, картину обрезать ровно по героиню, и убирать даже пересекающую её чужую руку?), одна нормальная цг в полнорост, куча спрайтов (все от одного художника, разница в стиле есть, но слабая), и десяток-другой скетчей и ещё несколько фанартов, где визуальное совпадение в деталях отсутствует/у персонажа неканоничная одежда/одежды нет.
гайд? И как мне тренировать персонажа: хочу лору по девке из непопулярной вн, и поэтому всё, что у меня есть —это ~20 цг из игры, все с голландским кадром или другими персонажами (если замазывать в фотошопе, картину обрезать ровно по героиню, и убирать даже пересекающую её чужую руку?), одна нормальная цг в полнорост, куча спрайтов (все от одного художника, разница в стиле есть, но слабая), и десяток-другой скетчей и ещё несколько фанартов, где визуальное совпадение в деталях отсутствует/у персонажа неканоничная одежда/одежды нет.
>куча спрайтов
Куча скетчей, самофикс
Хотя и спрайты (с разными лицами) тоже есть, их не стоит пихать ведь, а то он научится на ~100 эмоциях при одной позе ещё
Нужно расширить фотографию. Закидываю в img2img + outpainting mk2 скрипт или через inpaint и сверху, дорисовывает нормально, снизу, где сцена сложнее лепит хуйню вообще не в тему к основному изображению. Накидайте правильных настроек
Лучше в датасете оставить лишь эту твою тян, убрав остальное в фш, либо сделав маски и тренировать с ними.
Когда артов мало, можно даже сделать примерно так - сделать хоть какую то лору и нагенерить в разных стилях, поправив генерации, чтобы чар был консистентным, тем самым пополнив датасет и тренить снова.
Ну и ещё, когда все арты в одном стиле, то можно сначала натренить этот стиль, вмерджить в модель, или использовать соответствующий флаг в сд-скриптс, вторая тренировка с таким стилем поверх уже его не будет впитывать, но будет впитывать уникальные характеристики чара, так например с койкацу можно сделать тем же, надеюсь мысль понятна. Правда лучше набрать для такого стиля картинок не связанных с чаром, чтобы вторая тренировка проходила правильно.
Фоны тоже убирать?
Накропай чара откуда можно, убрав лишнее и отзеркаль пикчи для их размножения. Апскейли дат ганом чтобы превышали 1 мегапиксель. Хорошо протегай чара, как его имя, так и одежду. Совсем упарываться фанатизмом с очисткой не стоит, как и убирать фона. Дутчангл должен быть в капшнах есть он есть на пикче.
Это разбавляешь исходными артами где есть и окружение, и другие персонажи и прочее, главное чтобы все было хорошо описано. Из этого уже может получиться нормальный датасет для лоры на чара. Если уж совсем плохо будет - нагенери с имеющейся лорой, черрипикни удачные и добавь их в датасет.
Можешь попробовать, так чар может в итоге точнее натренится с маскед лоссом
Что такое маскед лосс и маски вообще?
В гайде как раз и расписано с примером
Первый вопрос:
Имеет ли смысл обучать ЛОРы для всех версий SD сразу?
Я надолго отвратился от SDXL, когда все говорили, что оттуда выкинули очень много картинок на обучении. Но я открываю сайт civitai и вижу как много лор выходит именно (и только) под SDXL.
А ведь уже какой SD 3 появился.
---------------------------------------
Второй вопрос: собираю новый комп. Хочу взять 4090 именно для обучения лор/генерации картинок. Так как 24 GB VRAM. Иначе бы взял 4070/4080 (где 16).
В принципе, могу себе позволить переплатить, если это имеет смысл. Имеет ли смысл переплачивать разницу между 4080 и 4090?
> Имеет ли смысл переплачивать разницу между 4080 и 4090?
Имеет

Пытаюсь повторить эту фотку (по позе) но выходит полная хуета, нейронка никак не может свести ноги вместе
Набрал такие теги
1 girl, legs up, holding legs, straightened legs, legs together, hamstrings, calves, thighs, hips, socks, feets, ass, short hair, red hair
Набрал такие теги
1 girl, legs up, holding legs, straightened legs, legs together, hamstrings, calves, thighs, hips, socks, feets, ass, short hair, red hair
> Имеет ли смысл обучать ЛОРы для всех версий SD сразу?
Странные вопросы задаешь, по что планируешь юзать под то и обучай.
> Имеет ли смысл переплачивать разницу между 4080 и 4090?
Абсолютно. Можешь подождать пол годика анонса блеквеллов.
Насколько существенно чтобы именно за носок держалась?
> анонса
не, я комп этим летом хочу.
>Насколько существенно чтобы именно за носок держалас
В целом, главное чтобы были подняты вверх ноги, показывая заднюю поверхность бедра и чтобы девушка именно сидела, а не лежала
Наверное самое реалистичное - это тренить Лора. Ну или ждать SD6, или когда там нейронки начнут такие сложные позы понимать
Тогда покупай, единственная альтернатива для ии - риг на бу 3090 что такое себе.
Анимублядское - легко.
Гоняю 4080. Для SDXL вполне хватает, но для чего-то большего уже маловато 16GB. Если есть возможность - бери 4090, не пожалеешь, оно того стоит.
Раз легко то не сложно будет рассказать как именно




Предыдущий тред:
➤ Софт для обучения
https://github.com/kohya-ss/sd-scripts
Набор скриптов для тренировки, используется под капотом в большей части готовых GUI и прочих скриптах.
Для удобства запуска можно использовать дополнительные скрипты в целях передачи параметров, например: https://rentry.org/simple_kohya_ss
➤ GUI-обёртки для sd-scripts
https://github.com/bmaltais/kohya_ss
https://github.com/derrian-distro/LoRA_Easy_Training_Scripts
https://github.com/anon-1337/LoRA-train-GUI
➤ Обучение SDXL
https://2ch-ai.gitgud.site/wiki/tech/sdxl/
➤ Гайды по обучению
Существующую модель можно обучить симулировать определенный стиль или рисовать конкретного персонажа.
✱ LoRA – "Low Rank Adaptation" – подойдет для любых задач. Отличается малыми требованиями к VRAM (6 Гб+) и быстрым обучением. https://github.com/cloneofsimo/lora - изначальная имплементация алгоритма, пришедшая из мира архитектуры transformers, тренирует лишь attention слои, гайды по тренировкам:
https://rentry.co/waavd - гайд по подготовке датасета и обучению LoRA для неофитов
https://rentry.org/2chAI_hard_LoRA_guide - ещё один гайд по использованию и обучению LoRA
https://rentry.org/59xed3 - более углубленный гайд по лорам, содержит много инфы для уже разбирающихся (англ.)
✱ LyCORIS (Lora beYond Conventional methods, Other Rank adaptation Implementations for Stable diffusion) - проект по созданию алгоритмов для обучения дополнительных частей модели. Ранее имел название LoCon и предлагал лишь тренировку дополнительных conv слоёв. В настоящий момент включает в себя алгоритмы LoCon, LoHa, LoKr, DyLoRA, IA3, а так же на последних dev ветках возможность тренировки всех (или не всех, в зависимости от конфига) частей сети на выбранном ранге:
https://github.com/KohakuBlueleaf/LyCORIS
Подробнее про алгоритмы в вики https://2ch-ai.gitgud.site/wiki/tech/lycoris/
✱ Dreambooth – для SD 1.5 обучение доступно начиная с 16 GB VRAM. Ни одна из потребительских карт не осилит тренировку будки для SDXL. Выдаёт отличные результаты. Генерирует полноразмерные модели:
https://rentry.co/lycoris-and-lora-from-dreambooth (англ.)
https://github.com/nitrosocke/dreambooth-training-guide (англ.)
✱ Текстуальная инверсия (Textual inversion), или же просто Embedding, может подойти, если сеть уже умеет рисовать что-то похожее, этот способ тренирует лишь текстовый энкодер модели, не затрагивая UNet:
https://rentry.org/textard (англ.)
➤ Тренировка YOLO-моделей для ADetailer:
YOLO-модели (You Only Look Once) могут быть обучены для поиска определённых объектов на изображении. В паре с ADetailer они могут быть использованы для автоматического инпеинта по найденной области.
Подробнее в вики: https://2ch-ai.gitgud.site/wiki/tech/yolo/
Не забываем про золотое правило GIGO ("Garbage in, garbage out"): какой датасет, такой и результат.
➤ Гугл колабы
﹡Текстуальная инверсия: https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb
﹡Dreambooth: https://colab.research.google.com/github/TheLastBen/fast-stable-diffusion/blob/main/fast-DreamBooth.ipynb
﹡LoRA: https://colab.research.google.com/github/hollowstrawberry/kohya-colab/blob/main/Lora_Trainer.ipynb
➤ Полезное
Расширение для фикса CLIP модели, изменения её точности в один клик и более продвинутых вещей, по типу замены клипа на кастомный: https://github.com/arenasys/stable-diffusion-webui-model-toolkit
Гайд по блок мерджингу: https://rentry.org/BlockMergeExplained (англ.)
Гайд по ControlNet: https://stable-diffusion-art.com/controlnet (англ.)
Подборка мокрописек для датасетов от анона: https://rentry.org/te3oh
Группы тегов для бур: https://danbooru.donmai.us/wiki_pages/tag_groups (англ.)
Гайды по апскейлу от анонов:
https://rentry.org/SD_upscale
https://rentry.org/sd__upscale
https://rentry.org/2ch_nai_guide#апскейл
https://rentry.org/UpscaleByControl
Коллекция лор от анонов: https://rentry.org/2chAI_LoRA
Гайды, эмбеды, хайпернетворки, лоры с форча:
https://rentry.org/sdgoldmine
https://rentry.org/sdg-link
https://rentry.org/hdgfaq
https://rentry.org/hdglorarepo
https://gitgud.io/badhands/makesomefuckingporn
https://rentry.org/ponyxl_loras_n_stuff
➤ Legacy ссылки на устаревшие технологии и гайды с дополнительной информацией
https://2ch-ai.gitgud.site/wiki/tech/legacy/
➤ Прошлые треды
https://2ch-ai.gitgud.site/wiki/tech/old_threads/
Шапка: https://2ch-ai.gitgud.site/wiki/tech/tech-shapka/