бамп
>кравлер
ты реально собрался обойти все страницы всех сайтов в интернете своей машиной? ты ебанутый?
а если десяток серверов двухпроцессорных?
допустим, памяти суммарно 5Тб, дисков 1Пб.
у меня есть пара свободных серверов с безлимитным трафиком и несколькими терабайтами места.
а это уже слишком дохуя будет стоить.
имхо весь текст в интернете весит не больше сотни гигабайт, а вот картинки - да, десятки и сотни терабайт.
А вот и свободный от оков цивилизации. Свободный от зондов, капчующий через интернет, провайдер которого видит весь трафик, хранит сообщения и звонки, который по первому требованию отдать это всё товарищу майору. Сидящий на мейлрушной борде, живущий в городе, где на каждом шагу камеры. И еще пытается выпукать свое говнище. Выйди на улицу, потрогай траву, а не дома сиди, шизик.
не путай тёплое с мягким. мне похуй, что провайдер и майор всё видят на самом деле почти ничего не видят, но это совсем другая история, но мне не похуй, что гугл сортирует результаты по собственному желанию, в первую очередь подсовывая проплаченное говно, и что он удаляет результаты поиска "по запросу правообладателей", "по закону о забвении", "по желанию левой пятки".
> имхо весь текст в интернете весит не больше сотни гигабайт, а вот картинки - да, десятки и сотни терабайт.
"A single copy of the Internet Archive library collection occupies 99+ Petabytes of server space" но это не только вебсайты, но и музыка, видео, софт, исо образы виндовса, "computer magazines and journals, books, shareware discs, FTP sites, video games, etc"
сколько весит чисто web.archive.org я не нагуглил, у интернет архива есть официальное API, можете поковыряться:
https://github.com/jjjake/internetarchive
https://archive.org/developers/items.html
не тонем
сам то, что-нибудь полезное нарыл?
только гигабласт. подумываю об установке 9го дебиана
Жидяра, спок
bump




репост из /zog/:
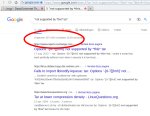
Простой эксперимент для всех сомневающихся. Вводите любое слово в поисковики и мотайте, просматривая выдачу. Там будет один-два десятка результатов со ссылками на вики, клоны вики, всякую правительственную парашу, ВК (если вы там зареганы), на объявления. ЗАТЕМ! Эти выданные сайты начнут тупо повторяться, меняя порядок, а иногда не меняя, т.е. мотаешь 100ую и 300ую страницу, а там просто они одинаковые по выдаче.
НО! Чаще всего вам просто выдадут пару десятков страниц с выдачей И ВСЁ!
Ещё недавно (месяц назад мб) гугл выдавал под 50-70 страниц, сейчас видимо заболел. Скрины прилагаю.
1. Я конечно понимаю, что Москва - это какая-то хуйня, но может она достойная больше двадцати с хуем страниц выдаче В ГУГЛЕ - царе поисковиков???
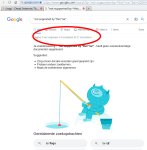
2. Дакдакго самый честный поисковик. Ты запросил слово автомобиль? Это чо? На нахуй тебе 6 страниц выдачи и иди нахуй, не мешай.
3. Я конечно понимаю, что слово "слово" и слово "Бюджетный федерализм" имеют разную частоту употребления в инете, но блядь, яндекс, какого хуя у этих двух запросов по 25 страниц выдачи?
4. Пока мотал яндекс до последней страницы, он спросил меня "А не бот ли ты, петушок?". Я -нет, а ты блядь?
Про свои "А вот в икс поисковике всё хорошо" - сходите нахуй, а перед этим почитайте какие запросы он выдаёт - всё после пары десятков страниц начинает повторяться.
Боты из треда не сочкуют.
А какого хуя так людей стало мало на дваче с 17 октября?
>Так это хохлов отрубили от инета.
Бляя складно.
>Да нет тут никакого заговора, просто копирайтеры пук, рекламщики среньк, капитализм пук.

репост из /zog/:
mda kek, пол миллиона результатов поиска даже на три страницы не уместились.
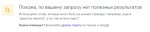
репост из /zog/:
Мне кажется хоть бы в Интернете осталось 10% того, чтобы было в 2010.
Я гуглом пользовался с середины нулевых. Я обожал сёрфить в интернете, это было как кладоискательство. Сотни страниц картинок от одного запроса. Я мог найти кино, просмотренное в глубоком детстве, по его смутному описанию. А сейчас что?
Любой специфический запрос приходится закрывать в ковычки, ибо алгоритмы усредняют всё под тупого юзера, чтобы подсунуть популярные "похожие" запросы. Наверное всех бесит это, когда Не найдено: N| Запрос должен включать: N при этом зачёркивая половину запроса в т.ч. суть.Последние месяцев 6 Гугл совсем скис и даже ковычки стали хуже помогать, я стал замечать, что всё чаще обращаюсь к Яндексу за специфическим запросом.
Написав длинный запрос и закрыв всё в ковычки как надо, с большей вероятностью тебе попадутся одни дорвеи.
99% форумов вымерло. Раньше в гугле вообще можно было помимо "карт" и "видео", выбирать "обсуждения", где подбирались различные форумы на всяких популярных движках типа XenForo.
Всё ушли в соцсети? Хорошо. Только вот соцсети окуклили. Те же группы вк плохо стали индексироваться, даже с site:vk.com не найдёт.
Даже не скрывают, что подбирают только "ПОЛЕЗНЫЕ" запросы
ну и сам тред в /zog/: https://2ch.hk/zog/arch/2023-04-28/res/620696.html
> Тебе гугл откровеено говорит, что доступ юзера к результатам поиска - атавизм, и много лет целенаправленно уничтожает поиск. Когда поиска совсем не станет - лишь вопрос времени.
репост из /zog/:
Теперь понятно зачем "Яндекс" и "Google" уничтожили поиск. Они так не только скрыли зачистку интернета, но и подготовили почву для поисковой надстройки в виде ботов.
Схема простая: доступ к полной базе данных будут иметь боты, а людям - демо-версия, имитирующая поиск.
В результате люди ищут и не могут найти, бот находит легко. Это уже реализовано.
Т.е. людей подталкивают, вынуждают использовать надстройку вместо самостоятельного поиска информации и её анализа.
Анон выше про "истину в последней инстанции" прав.
Помимо интернета, вывели и расплодили "потребителей", которые воспринимают ссылки на "авторитетов" (или просто ссылки) как нечто священное.
Старожили знают что такое нормальный поиск в интернете и нормальные сайты с нормальными статьями, а не сгенерированная дрянь. "Ньюфагам" банально не с чем сравнивать, они стали использовать интернет когда он уже стал барахлом и нейросетевые системы могут восприниматься ими как "шаг в будущее", потому что это стандартная схема "отобрать и вернуть", только возвращают с контролируемой посреднической системой.
Получается сразу пачка степеней цензуры информации:
- модерация;
- поисковые системы;
- нейросетевые системы.
На каждом уровне цензура. Плюс "теневые баны" и "информационная изоляция".
Дословные цитаты из "Библии" поисковики уже не всегда находят.
>провайдер и майор
они существуют только в твоем воображении, дебил
дебил - это твой отец, точнее сразу оба.
Не могу с тобой не согласиться, он действительно дебил. Я вот все время удивляюсь, хуле я такой умный?

всё так анон.
Но что делать?
Допустим запускаем какой то локальный индексатор, вопрос
1) сколько всего доменов в интернете?
2) как получить полный список?
3) как долго краулер будет обходить все сайты?
4) сколько полезных данных удастся индексировать на обычном HDD размера 4-10Тб ?
5) с какой скоростью потом будет работать поиск?
> 1, 2
под миллиард. иногда кибержулики сливают зоны целиком, у меня где-то валялись дампы.
можно посмотреть на веб архиве, раньше вот тут была зона ру: https://partner.r01.ru/ru_domains.gz
и вот тут ком нет орг http://www.domainresearchtool.com/lists/com.zone.gz
http://www.domainresearchtool.com/lists/net.zone.gz
http://www.domainresearchtool.com/lists/org.zone.gz
> 3, 5
долго) но у меня есть безлимитный гигабит.
> 4
мало, см. выше:
> можно посмотреть на веб архиве
пиздец, только сейчас заметил, что моя заметка с этими ссылками создана в 2011 году.
проверил веб архив:
.ru зона последний раз выкладывалась в сентябре 2013го
.com - первый и единственный раз в 2014ом (странно, что кравлер веб архива не знал про эту ссылку в 2011ом)
.net и .org - вообще не архивированы
> долго) но у меня есть безлимитный гигабит.
когда я баловался с массканом, весь мир на один порт сканировался 5-15 минут.
но это чисто connect и read 1024 байт баннера, скачивание всей страницы + всех её элементов (яваскрипты и css всякие (хотя хз, нужны ли они для архивирования)) займёт намного больше времени, но тоже терпимо.
имхо выкачать вообще весь интернет по 80 порту займёт максимум неделю, плюс ещё 443 порт и ради прикола 81, 8080, 8443
тут нужны пацаны из ИСКОПАЗИ, чтобы точнее соориентировали по времени.
> 1) сколько всего доменов в интернете?
нашёл базу 2022 года
...
...
...
.net.ua - 10113
.msk.ru - 10130
.men - 10148
.review - 10378
.bzh - 10439
.vision - 10472
.cards - 10475
.bz - 10481
.waw.pl - 10491
.ne.jp - 10518
.healthcare - 10592
.deals - 10624
.sa - 10656
.org.pl - 10722
.co.tz - 10723
.frl - 10752
.jetzt - 10810
.careers - 10896
.contact - 10897
.solar - 10917
.edu.au - 10922
.productions - 11043
.tax - 11050
.ly - 11161
.ooo - 11203
.web.id - 11259
.casino - 11265
.org.il - 11352
.vegas - 11468
.shopping - 11471
.estate - 11480
.co.rs - 11811
.moe - 11881
.edu.vn - 11944
.fashion - 11980
.skin - 11980
.kiwi - 12289
.clinic - 12365
.tours - 12511
.uy - 12525
.com.bd - 12616
.ren - 12657
.style - 12683
.day - 12832
.hair - 12876
.rentals - 12885
.clothing - 12916
.partners - 13015
.gold - 13040
.gov.cn - 13068
.management - 13075
.fitness - 13104
.jobs - 13143
.mn - 13213
.pet - 13327
.eus - 13392
.realty - 13417
.scot - 13475
.science - 13569
.direct - 13639
.net.in - 13640
.blue - 13650
.autos - 13754
.ar - 13784
.stream - 13796
.pp.ua - 13904
.com.ec - 13905
.golf - 13937
.mk - 13987
.al - 14003
.mom - 14015
.vc - 14074
.reviews - 14120
.boutique - 14232
.net.nz - 14279
.yoga - 14371
.wales - 14391
.im - 14566
.ind.br - 14694
.realestate - 14880
.gg - 15065
.beer - 15077
.net.pl - 15166
.ng - 15386
.com.py - 15450
.com.de - 15497
.wedding - 15543
.properties - 15552
.com.pt - 15558
.institute - 15585
.miami - 15684
.sale - 15792
.com.ru - 15850
.wien - 15983
.re - 16067
.band - 16086
.codes - 16097
.dog - 16294
.bike - 16306
.casa - 16407
.ba - 16566
.org.za - 16588
.gay - 17428
.photo - 17490
.legal - 17529
.directory - 17584
.wine - 17584
.guide - 17662
.press - 17663
.az - 17695
.xin - 17762
.md - 17848
.bid - 18025
.nrw - 18053
.help - 18089
.trade - 18091
.ua - 18205
.party - 18427
.show - 18564
.cash - 18789
.exchange - 18937
.swiss - 18960
.org.ua - 19111
.immo - 19166
.money - 19276
.am - 19299
.hamburg - 19328
.xn--io0a7i - 19425
.energy - 19600
.red - 19619
.to - 19774
.uno - 19858
.koeln - 20105
.tools - 20225
.law - 20328
.ltd.ua - 20337
.org.in - 20390
.org.nz - 20436
.paris - 20460
.chat - 20885
.ventures - 20933
.gallery - 20998
.xn--p1acf - 21343
.amsterdam - 21377
.cafe - 21407
.cm - 21816
.school - 22319
.fund - 22350
.pub - 22399
.photos - 22462
.travel - 22606
.training - 22715
.community - 22830
.pics - 22999
.software - 23145
.in.ua - 23196
.foundation - 23789
.market - 24245
.xn--czru2d - 24316
.tips - 24363
.video - 24363
.bio - 24502
.coach - 24643
.ge - 24727
.coffee - 24787
.cam - 24793
.house - 24969
.land - 25018
.tn - 25110
.run - 25513
.fm - 25526
.xn--3ds443g - 25734
.cool - 25824
.gmbh - 25855
.li - 26162
.xn--czr694b - 26379
.adv.br - 26489
.ru.com - 26634
.farm - 26747
.com.pe - 27019
.international - 27352
.capital - 27502
.us.com - 27827
.beauty - 27912
.co.at - 27930
.com.uy - 28062
.sch.id - 28206
.xn--55qx5d - 28226
.marketing - 28368
.best - 28844
.or.kr - 29023
.events - 29450
.spb.ru - 29557
.social - 29573
.com.pk - 29832
.church - 30015
.plus - 30076
.realtor - 30678
.la - 30708
.hk - 30730
.business - 31074
.education - 31312
.bayern - 31351
.works - 31420
.kiev.ua - 31616
.com.ph - 31964
.support - 31979
.ninja - 32303
.bond - 32380
.health - 32528
.city - 32676
.co.th - 32729
.expert - 32796
.wtf - 32825
.host - 32964
.uz - 33009
.za.net - 33507
.family - 34137
.technology - 34355
.care - 34730
.homes - 34768
.llc - 34846
.lk - 34894
.or.jp - 34981
.pe - 35140
.consulting - 35201
.com.np - 35460
.org.br - 35549
.earth - 35637
.cc.ua - 35832
.london - 35915
.wiki - 35989
.bet - 36044
.my.id - 36369
.systems - 37107
.com.ng - 39818
.com.es - 40160
.co.zw - 40569
.center - 41282
.photography - 42419
.zone - 42469
.pk - 42750
.team - 43196
.ink - 44348
.games - 45091
.tel - 45552
.fit - 45640
.ai - 45726
.co.ke - 46021
.rest - 46319
.xn--ses554g - 46780
.com.hk - 47391
.finance - 47525
.me.uk - 47703
.love - 47839
.net.br - 47881
.berlin - 48286
.lol - 48391
.wang - 48865
.fyi - 48867
.ph - 49367
.is - 50871
.uk.com - 51139
.academy - 51996
.global - 54196
.org.au - 54543
.pw - 55066
.bg - 55725
.guru - 56212
.sg - 56338
.page - 57383
.cn.com - 58887
.sbs - 60736
.ma - 61352
.ovh - 62487
.nyc - 62853
.services - 62925
.hk.com - 63184
.my - 64334
.co.id - 65353
.com.sg - 68609
.tw - 69003
.news - 69467
.network - 71059
.media - 71740
.lu - 72383
.ws - 73932
.win - 75109
.rs - 75462
.rocks - 76226
.company - 77223
.hr - 77996
.kred - 80141
.inf.ua - 81381
.nz - 85576
.lv - 85607
.quest - 85993
.org.cn - 86786
.com.vn - 91107
.solutions - 91279
.today - 91875
.agency - 92058
.id - 93389
.by - 94137
.kz - 94645
.su - 99374
.monster - 99550
.com.my - 99658
.studio - 101315
.com.co - 101404
.group - 103006
.si - 105330
.cat - 109930
.name - 110328
.email - 110901
.ae - 111965
.design - 116423
.ltd - 118951
.cfd - 123249
.digital - 124233
.net.cn - 131656
.bar - 139832
.lt - 139942
.net.au - 140809
.africa - 144391
.ee - 151592
.eu.org - 152833
.kr - 156233
.com.tw - 164755
.world - 166532
.tokyo - 174428
.one - 177459
.vn - 180193
.co.il - 187380
.link - 190640
.blog - 192174
.asia - 199063
.com.pl - 200225
.ie - 207497
.mx - 211309
.art - 212690
.work - 230687
.pt - 235808
.click - 237438
.cloud - 238435
.nu - 239361
.website - 240315
.co.in - 257749
.com.tr - 259850
.now.sh - 260086
.life - 276453
.com.ua - 278180
.mobi - 283816
.pro - 303935
.org.uk - 303943
.tv - 305396
.com.ar - 328890
.dev - 329046
.fun - 333063
.gr - 338676
.com.mx - 346278
.co.kr - 348675
.co.nz - 365315
.fi - 366723
.co.jp - 368430
.space - 370254
.cc - 380401
.cl - 401932
.tech - 406215
.ro - 412954
.io - 432735
.sk - 447628
.uk - 505206
.no - 560565
.hu - 573494
.buzz - 574459
.me - 588160
.ir - 597311
.app - 622585
.live - 633951
.vip - 634190
.xn--p1ai - 634854
.club - 660123
.cyou - 778853
.jp - 835637
.store - 850162
.co.za - 916310
.cz - 947983
.icu - 991013
.dk - 1036088
.at - 1047859
.site - 1065040
.com.cn - 1101790
.in - 1125272
.be - 1177099
.shop - 1200264
.es - 1245846
.biz - 1365735
.pl - 1373594
.se - 1428930
.co - 1472092
.tk - 1667831
.top - 1840704
.us - 1892992
.online - 1972363
.ca - 1977357
.com.au - 1979664
.it - 2235746
.gq - 2243329
.ch - 2410074
.eu - 2500571
.com.br - 2518138
.ml - 2579590
.fr - 2616353
.cf - 2737993
.ga - 3050915
.info - 3659291
.nl - 3724829
.xyz - 4120476
.cn - 4342564
.ru - 4814375
.co.uk - 5635601
.org - 10642621
.de - 12112593
.net - 13044441
.com - 159256705
сумма всех зон = 308901854
дохренищща. Имена доменов есть?
Кроме этого ещё и регистрации\обновления IP\освобождения надо отслеживать.
конечно есть.
зачем отслеживать изменения IP, если можно тупо заново резолвить все домены при следующем обходе?
да, не существенно. Даже можно пренебречь регистрирующимися, как содержащими инфу сомнительной ценности.
> )
Пиздец. Быдло. Пиздец.
сударь, проследуйте в /rf/))))
Дерьмо, не кривляйся.
дерьмо это твоя мамка
обоссав шизика, узнавшего про двач три года назад на лурочке и теперь делающего вид, что он ниибацца олдфаг и негодующего, что на его дваче кто-то ставит скобочки, вернёмся к конструктивному обсуждению.
основная проблема gigablast и прочих публичных кравлеров в том, что они тупо собирают HTML код со страницы, и не выполняют Javascript код, а вот гугл и прочие яндексы исполняют яваскрипт и получают больше информации, чем простой дамп HTML.
к сожалению, в современном уебанском вебе большинство сайтов работают исключительно на яваскрипте, и если какую-нибудь парашу типа инстаграма мы можем просто занести в блэклист кравлера - там всё равно ничего ценного нет - то форумы на движке Discourse и сайты на движке Wix как-то парсить надо.
то есть простой модификацией какого-нибудь masscan не обойтись, в кравлер придётся вкручивать v8 или какой-нибудь ducktape для выполнения яваскрипта.
основная проблема gigablast и прочих публичных кравлеров в том, что они тупо собирают HTML код со страницы, и не выполняют Javascript код, а вот гугл и прочие яндексы исполняют яваскрипт и получают больше информации, чем простой дамп HTML.
к сожалению, в современном уебанском вебе большинство сайтов работают исключительно на яваскрипте, и если какую-нибудь парашу типа инстаграма мы можем просто занести в блэклист кравлера - там всё равно ничего ценного нет - то форумы на движке Discourse и сайты на движке Wix как-то парсить надо.
то есть простой модификацией какого-нибудь masscan не обойтись, в кравлер придётся вкручивать v8 или какой-нибудь ducktape для выполнения яваскрипта.

Почему мелкобуквенные залетухи из /б/ так любят "обоссывать"?
потому что ваше место у параши. в очередной раз напоминаю, что в интернетах писать с маленькой буквы было принято задолго до того, как тебе купили первый компьютер.
Залётное срущее дерьмо, вернись в /б/. Тебе здесь не рады.

> Залётное срущее дерьмо, вернись в /б/. Тебе здесь не рады.
бамп
клоун
биджиджи
бамп
https://github.com/benbusby/whoogle-search
Попробуй это, шизик
Попробуй это, шизик
> прокси для гугла
ты тупой?
Кто я? Я ебаное дно
биджиджи
биджиджи
бамп
вообще тема интересная, я бы поэкспериментировал, но в до зимы свободного времени нет
бамп
о, похоже, что это именно то, что надо, спасибо!
Я вообще удивлен, как можно не знать платину этой отрасли, биджиджи
> как можно не знать платину
а сам-то знал её до 16/06/23 Птн 18:41:00?
бґґґ
класс, спасибо!
> Marginalia, the indie search engine that surfaced non-commercial content first, is currently on the front page of HN and handling the traffic load with one $5k commodity server with 128GB RAM/24 cores at 85% utilization with a single Java app
> The search engine now indexes 106,857,244 documents!
вообще шикарно. это намного меньшие затраты, чем я предполагал.
> mysql
фигасе. я ожидал какой-нибудь еластик
I was looking around the marginalia website and found this link:
https://seirdy.one/posts/2021/03/10/search-engines-with-own-indexes/
It has a detailed list of various independent search engines and seems very well researched.
Some might fit your criteria exactly such as: https://github.com/alexandria-org/alexandria
о, тут вообще гуй на пхп, восхитительно, спасибо.
не зря две недели бампал.
хотя нет, это не совсем то.
это поисковый движок типа еластик сёрч, а не кравлер. этот движок использует данные, собранные проектом https://commoncrawl.org/
с другой стороны, благодаря alexandria я узнал об этом commoncrawl, так что всё равно спасибо.
> commoncrawl
> about 250 TiB of uncompressed content
pizdos
а также неизвестно, фильтруется ли что-то в этом commoncrawl или нет. может, там тоже неудобные результаты были вырезаны жидомасонами.
я считаю, что для того, чтобы иметь unbiased данные, нужно сделать следующее:
1. натравить павука на весь диапазон IPv4 0.0.0.0/0 (нахуй IPv6)
2. натравить павука на все известные домены
3. совместить собранные данные с публичными данными от commoncrawl.
дискасс
я считаю, что для того, чтобы иметь unbiased данные, нужно сделать следующее:
1. натравить павука на весь диапазон IPv4 0.0.0.0/0 (нахуй IPv6)
2. натравить павука на все известные домены
3. совместить собранные данные с публичными данными от commoncrawl.
дискасс
травить по IP = уменьшать результаты.
У хостингов на одном IP висит по сотне доменов и простой запрос по IP выдаст дефолтную пустую страницу (или максимум первый домен из сотни).
дальше первого пункта прочитал?
бiмп
> Дословные цитаты из "Библии" поисковики уже не всегда находят.
Дословные цитаты из Библии "поисковики" уже не всегда находят.
Так вернее.
Бля это было бы охуенно если бы верунов оставили без их сказочек. Жаль, такого не произойдет.
Так почему не пользоваться непопулярным поисковиком, где нет такого говна как в Гугл и Яндекс?
Есть же какие-то нишевые, должны быть
Это проще, чем свой собирать
потому что завтра к этому непопулярному поисковику придут и попросят убрать из выдачи неприятные результаты, а свой паук со своей базой - это свой паук и своя база.
БАМПУЮ В ТЕМАТИКЕ
ХОБА!
ХОБА!
Как ты будешь размещать сервера под кроватью, если там всё место жиды заняли?
А есть ли смысл? Чат гопота/альпака и тд уже заархивировала ценные знания. Ну а бд яндекс еды и так не в белом интернете.
жиды под кроватью, а сервера в датацентре.
Хуй с ним с поисковиками. С порносайтов пропала порнуха, которая там всегда была. Все "вот те" заебавшие ролики по соответствующим запросам. Просто блядь нету, как корова языком слизала. Не говно, не процессоры, не расчленёнка, обычная. Заходя с VPN из разных стран часть этого старья иногда появляется обратно, но не всё и с разных VPN пояаляется разное. Нахуя так делать? Подписку я всё равно не куплю при наличии миллиона аналогичных сайтов в поиске.
> с разных VPN пояаляется разное
лол, я совсем забыл - гугол же тоже показывает разные результаты для разных стран.
и что, сука, характерно, он показывает разные результаты даже для запроса site:тут-какой-нибудь-сайт.ком в зависимости от того, из какой страны гуглишь. пиздец, короче.

Можно подчистить результаты гугла, плагин uBlacklist
это, конечно, клёвый аддон, но только он не имеет никакого отношения к тематике треда.
>Старожили знают что такое нормальный поиск в интернете и нормальные сайты с нормальными статьями, а не сгенерированная дрянь.
это ты щас про сайты типа wikiHOW ? или HOW-To-DO?
Как раздобыть свой датацентр? Отнять у пыни? Не варик, он не даст. Варианты?
>у меня есть пара свободных серверов с безлимитным трафиком и несколькими терабайтами места.
Нужно безлимитное количество ip с которых будешь сканить а не трафик.
>а это уже слишком дохуя будет стоить.
>имхо весь текст в интернете весит не больше сотни гигабайт
Вот это ты дурачок.
Один либрусек весит 300Гб и это в пожатом виде
https://rutracker.org/forum/viewtopic.php?t=5384939
А текст в интернете весит тысячи ТБ.
Тебя забанят везде на второй день или даже раньше, потом прилетит абуз твоему провайдеру/хостингу и тебя отключат. На этом гг.
Хочешь обойти цензуру поисковиков присоединяйся к тем кто ведет реестры удаленного из гугла говна.
Выдача 20 страниц это просто оптимизация, ты же не думаешь что ради одного дебила поисковик по слову москва выдаст все свои миллионы страниц?
Чел, а зачем хранить тексты, если сеть не собирается сегментироваться и удалять свободный доступ? Тогда достаточно просто создать дерево графов или облако тегов, раздать им цифробуквы и определения, а дальше просто весь текст пропускать через семантико-семиологию нейронетов, они циферки/цвет/звук выставят и определят/зададут направление/вектор поиска при запросе. А дальше будет просто запрос - телепорт к нужному хосту, вычитка, анализ, результат хранимой инфы. Пусть гугл и люди и дальше хранят архивы, фактически, у тебя будет каталог, реестр анализа, и ты будешь прыгать по данным, как блоха по слону. Как рисунок Матрицы на мониторе, с бегающими иероглифами оформить, и весьма символично будет, лол.
достаточно несколько проксей в нескольких странах, большинству хостеров похуй, что с них сканят, особенно если вставишь в юзерагент ссылку на страницу для "отписки" от скана.
> А текст в интернете весит тысячи ТБ.
commoncrawl - 250 TB
но всё это мне не нужно, имхо нескольких десятков терабайт хватит с головой.
домашним провайдерам на сканы глубоко похуй, хостерам иногда бывает не похуй, но если сделаешь форму отписки - станет похуй.
А если упорться децентрализацией?
Например, на компе добровольца запускается краулер, который сканит свой сегмент сети. Краулеры общаются между собой через тот же Yggdrassil.
Работать может примерно так: реализовать на уровне приложения и краулер, и интерфейс поисковой системы, плюс приложение будет иметь библиотеку всех ipv6 адресов, на которых оно хостится. Таким образом, пользователь, чтобы получить доступ к поисковику, также хостит у себя и краулер. Задавая вопрос поисковой системе, приложение опрашивает себя и остальных, получант ответ, формирует форму предоставления для пользователя.
Основных затыков вижу два:
1. Сегментация Интернета между краулерами, чтобы ответ из сети не имел дублирующихся значений (но несколько краулеров могут по общему алгоритму шерстить один и тот же сегмент для отказоустойчивости)
2. "Слепота" поисковой системы на ранних этапах развития.
> но несколько краулеров могут по общему алгоритму шерстить один и тот же сегмент для отказоустойчивости
не "могут", а должны шерстить один и тот же сегмент, потому что огромное количество сайтов и CDN используют геоблокировки и я в том числе, ибо нахуй мне паразитный трафик из какой-нибудь африки
Я правильно понял. что нужно иметь свой сервер чтобы найти информацию?
зависит от каждого конкретного движка. маргиналия например даёт искать по своей базе.
хозяйке на заметку: https://github.com/webrecorder/browsertrix-crawler
> Browsertrix Crawler is a simplified (Chrome) browser-based high-fidelity crawling system, designed to run a complex, customizable browser-based crawl in a single Docker container.
> Browsertrix Crawler is a simplified (Chrome) browser-based high-fidelity crawling system, designed to run a complex, customizable browser-based crawl in a single Docker container.
>А если упорться децентрализацией?
>Например, на компе добровольца запускается краулер, который сканит свой сегмент сети.
Это единственное потенциально рабочее решение. Если людей наберется тысячи то еще и работать лучше гугла будет.
Начинайте разрабатывать.
Yacy же есть. Он как раз на 100% попадает под тебя
test
Сап. Есть ли какая OSINT вундервафля для сталкинга? И на себя в прошлом посмотреть, и за ЕОТ пошпионить?
Вообще сейчас хочу сделать децентрализованную борду в игдрассиле, основная задумка -- локальные копии тредов по умолчанию сохраняются на устройствах тех, кто в них заходит, и могут быть загружены у них же новыми посетителями вместе с ipv6 адресами всех держателей треда, по которым будут пробегаться, обновляя тред. В планах отказаться от разделения на доски, но ввести хештеговую систему тредов с возможностью включения и исключения тегов.
Проблема только в том, что последний раз что-то кодил в универе, что было 4 года назад. Сейчас вот думаю, как синхронизировать бд, хранящиеся у всех отдельно.
Кстати, вопрос знатокам: PWA может фоном гонять данные по сети, и на каких осях?
Ну и, если получится, может и до краулера доберусь, да.
- кун
>Кстати, вопрос знатокам: PWA может фоном гонять данные по сети, и на каких осях?
В шинде PWA на хромиум могут обращаться с API фоновой выборки, периодической и постоянной фоновой синхрой. Как ты понимаешь, должны быть запущены службы поддержки фоновой работы приложений формата UWP\PWA.
Лучше сделай меш-чат, вместо борды. Туда (в бордель) никто не придет, да и не оценят, а чятик - постоянное общение и новые мысли.
бамп
звучит интересно.
полазайте по нижнему Интернету, думаю там помогут.
дам одну ссылку, дальше по вебрингам куда угодно доберётесь.
https://m.13f0.net/shadow_wiki/index.xhtml

Подписался на годнотищу.




существуют ли готовые опенсорцные поисковые движки, "пауки" или "кравлеры", которые можно запустить на своём компьютере?
в гугле находится только всякая фигня типа Searx и Mojeek, которая или не является реальным поисковым движком, или которую невозможно запустить на собственном железе.
ну и миллион не поисковых движков, а просто кравлеров, которые ещё нужно допиливать, чтобы они стали поисковой системой.
единственный реальный поисковый движок, что я нагуглил - Gigablast, заброшенный проект, который не собирается даже на протухшем Debian 10 и Ubuntu 18: https://github.com/gigablast/open-source-search-engine
https://web.archive.org/web/20210126124653/http://www.gigablast.com/about.html