Иногда проскакивает электронный звук/артефакт в букве Ц например. Это из за некачественного исходника? или из за некачественно обученой модели? Кто как с этим борется?
Годные ттски
https://github.com/hinaichigo-fox/rus-silero-webui - русская силероТТС
https://github.com/hinaichigo-fox/rus-edge-tts-webui - русская ЕджТТС. Лучше всего подходит для следующей перегонки через рвс
https://github.com/hinaichigo-fox/rus-silero-webui - русская силероТТС
https://github.com/hinaichigo-fox/rus-edge-tts-webui - русская ЕджТТС. Лучше всего подходит для следующей перегонки через рвс
По интонации все равно понятно что робот озвучивает а не человек
у меня на силеровский голос бая встает. Кажется что реальная девушка говорит
Анон, как справляться с хором? Например у меня такой трек: везде обычно, а на 1:09 начинается часть с хором, на которой модель ахуевает
Вокал оригинала: https://voca.ro/19M1lMTqz676
Мой кавер: https://voca.ro/1itbIvewKIm8
Вокал оригинала: https://voca.ro/19M1lMTqz676
Мой кавер: https://voca.ro/1itbIvewKIm8
Никак, вырезай его, он не поддаётся трансформации.
>Retrieval-based-Voice-Conversion-WebUI (RVC)
Пиздец, все на китайском.
А есть гайд, как ей пользоваться, на русском или английском?

Пытаюсь вкатиться в нейронки, но, кажется, в несколько архаичном порядке. Сначала задрочил математику перцептрона и еще пару алгоритмов и их голые реализации, затем tensorflow, затем pandas.
Прямо сейчас мне нужно воспользоваться Silero из шапки треда.
Я пытаюсь запустить пример, но не пойму, как в этом ебаном формате юпитера, которым я пользуюсь в первый раз, вскормить питону ввод, которого данная ячейка, очевидно, требует.
Заодно скажите, какая там команда позволяет узнать, с каким именно питоном мы имеем дело.
Прямо сейчас мне нужно воспользоваться Silero из шапки треда.
Я пытаюсь запустить пример, но не пойму, как в этом ебаном формате юпитера, которым я пользуюсь в первый раз, вскормить питону ввод, которого данная ячейка, очевидно, требует.
Заодно скажите, какая там команда позволяет узнать, с каким именно питоном мы имеем дело.
Пытаюсь вкатиться в нейронки, но, кажется, в несколько архаичном порядке. Сначала задрочил математику перцептрона и еще пару алгоритмов и их голые реализации, затем tensorflow, затем pandas.
Прямо сейчас мне нужно воспользоваться Silero из шапки треда.
Я пытаюсь запустить пример, но не пойму, как в этом ебаном формате юпитера, которым я пользуюсь в первый раз, вскормить питону ввод, которого данная ячейка, очевидно, требует.
Заодно скажите, какая там команда позволяет узнать, с каким именно питоном мы имеем дело.
Прямо сейчас мне нужно воспользоваться Silero из шапки треда.
Я пытаюсь запустить пример, но не пойму, как в этом ебаном формате юпитера, которым я пользуюсь в первый раз, вскормить питону ввод, которого данная ячейка, очевидно, требует.
Заодно скажите, какая там команда позволяет узнать, с каким именно питоном мы имеем дело.
А, проехали, я наконец поднял глаза на 20 сантиметров наверх
чем пользоваться? Тебе обучение или создание аи каверов описать?
под шапкой треда я кидал ссылку на хорошее вебуи для силеро
Чел Сенко музыка ты охуенный
4 языка - один народ
Не работает чет, пишет try again
надо зайти на сайт через почту
Бля, на самом интересном месте!
Какая-то гачи-версия Мстителей

https://disk.yandex.ru/i/yrSqvLJOuy0jNA
ElevenLabs это какой-то рандом с низким шансом сделать годноту, полдня перебирал реплики одной сцены чтоб было более менее. Голоса прям актёров, но шопот плохо разбирает прога и ударения ставит в разнобой. Эх, была бы возможность текст редактировать - можно актёров дубляжа сразу на улицу выбрасывать, но пока сыро.
ElevenLabs это какой-то рандом с низким шансом сделать годноту, полдня перебирал реплики одной сцены чтоб было более менее. Голоса прям актёров, но шопот плохо разбирает прога и ударения ставит в разнобой. Эх, была бы возможность текст редактировать - можно актёров дубляжа сразу на улицу выбрасывать, но пока сыро.
пытался для немытой ваты сделать перевод этой годной реплики, но нихуя, получается мусор цифровой.
Говно этот АИ, актеры озвучки пока будут в порядке.
Говно этот АИ, актеры озвучки пока будут в порядке.
>so-vits-svc-fork
Аноны, не появилась там возможность учить на фонемах русского языка?
Аноны, не появилась там возможность учить на фонемах русского языка?
> мелкобуква что-то пискнула
Meh...
)
как легко задеть чувства немытой ваты и заставить ее ответить на свой пост
>актеры озвучки пока будут в порядке.
>Активная движуха с нейронками около года.
>Уже ГПТ4 высрали, уже почти точные копии голосов делают школьники на коленке, рисовач. За один ебаный год.
>Говно этот АИ, актеры озвучки пока будут в порядке.
Рвись попка.
А где можно скачать голос санбоя pth+index для Mangio-RVC?
сори, пиздоглаз - https://huggingface.co/models?search=sunboy
Чет стремно мне на ютуб лить озвучку чьим-то голосом. А ну как страйк кинут? Есть какая-нибудь синтетическая безкопирастная модель с хорошим английским?
>А ну как страйк кинут?
Кинут, не переживай, повода для этого не нужно. Заливая что-то на чужую площадку, нужно сразу понимать, что оно заведомо пропало, и не беспокоиться по этому поводу.
>3
Умора, просто уписиваюсь

Бля пиздец аноны. Вот с svc надо сначала тонну времени угрохать модель натренить, потом накладывать её на речь. И после этого она будет кортавить как иностранец. А тут всё на лету делается за секунды.
Это как вообще? Это с помощью чего такое? Ссылочку на репозиторий можно? Или это какие-то секретные разработки госдепа которых нет в открытом доступе?
Судя по твоему комменту, ты с ютубом знаком чисто теоретически, а я спрашивал совета практиков.
> Ссылочку на репозиторий
Попенсурсоманьки совсем ебанулись.

>Или это какие-то секретные разработки госдепа которых нет в открытом доступе?
Ты логотипа не видишь? Конечно же проприетарщина. Впрочем, они примерно вторые после меты.
Кто пробовал обучать модельку на шакальных записях телефонного разговора?
Выходит аутентично типа как запись с диктофона, или совсем пиздец?
Выходит аутентично типа как запись с диктофона, или совсем пиздец?
>Кто пробовал обучать модельку на шакальных записях телефонного разговора?
На сайте есть демо записи Кейва из игры Portal 2, где его голос в игре обработан под запись. Модель звучит точно также.
А то здесь все ебутся, шумы вычищают, я вот думаю, может быть не обязательно запариваться в таком кейсе если нужен не чистый результат.
Поделитесь опытом очистки шум и выделения вокала из аудиозаписей с шумом? Пользуетесь ли вы UVR для изоляции вокала?
>Пользуетесь ли вы UVR для изоляции вокала?
А чем собственно ещё?
а какие модели используешь для очистки аудио от звука? kim vocal? Поделись как ты изолируешь голос. Желательно не с трека а с реального шумного аудио.
Stability выпустили свои инструменты для тренироки аудио моделей https://github.com/Stability-AI/stable-audio-tools
почти везде сетки голос-голос требуют предварительно заготовленные модели голоса, а как же elevenlabs справляется без всего этого? опять гоев греют поди
Чем можно нагенерить голос из текста чтобы нагенеренное уже подогнать под .pth модель из rvc?
А какие там лимиты, гайс?
Heygen всё же лучше озвучивает.
Ну так у них модель может сама зафайнтюнится от одного сэмпла голоса.
Это как IP-adapter в SD, который копирует стиль с одного фото.
Или roop который накладывает лицо с одного фото.
Аноны пытаюсь вкатиться в SoftVC VITS Singing Voice Conversion Fork (SVC). Как я понял там специальные модели нужны? И где конфиг к моделям искать, а то зачастую модели вижу,а конфига к ним нет? И да есть ли тут жесткая зависимость модели от языка на котором она сделана. Для tts как я понял она есть например.
Охуенно
Чем делал? Это sts?
Анончеки, вот есть обученный в колабе рвц голос. Так как теперь колаб агрессивно банит нейронки, я не знаю на чем мне использовать этот голос, так как есть только ноутбук без всяких там нвидиакарточек. Что делать, помогите
Разверни рвц локально, если не запускать тренировку то просто для работы с моделями готовыми говорят хватит и ноута
Аноны для RVC исходный файл надо как-то по особому подготавливать? А то взял для примера файл без музыки с просто монотонной начиткой голосом. И при наложении голосов почему-то получается вообще даже отдаленно не похоже на оригинал, а голос смещается ближе к писклявому. Может еще какие настройки покрутить? А то я попробовал только понижение октавы и вообще не особо помогло. Модели взял русских голосов и исходник так же на русском.


Помогите нюфане, поясните почему оно нихуя не видит?
Ты пытаешься использовать RVC-модель для SVC - они несовместимы между собой.
А понял, спасибо
а кто автор ?
Сука, орууу!
серебряная свадьба хз


Анон, выручай.
Совместными с камрадом усилиями запустил RVC на камне (Жду, когда видеокарта придёт) и наткнулся на такую проблему.
В EasyRVC (Который был на колабе) есть крутилка "Mangio-Crepe Hop Length.", в других версиях RVC её я не нашёл. Но, почему-то, там отсутствует метод rmvpe, который точно был, когда оно висело на колабе.
https://github.com/AKhilRaghav0/EasyGUI-RVC-Fork?ysclid=lnr6u9ryy344916232
Ещё у меня лежит RVC, в которой есть rmvpe, но нет этой крутилки, а она нужна шопиздец.
https://huggingface.co/datasets/Ba1yya/RVC_rmvpe/tree/main
Как забороть проблему? Пытался прикрутить rmvpe, но там больно дохуя файлов, которые приходится переделывать, да и я тут не то что бы сильно понимаю. Или, может, у кого-то есть версия с обоими этими хуйнями?
Совместными с камрадом усилиями запустил RVC на камне (Жду, когда видеокарта придёт) и наткнулся на такую проблему.
В EasyRVC (Который был на колабе) есть крутилка "Mangio-Crepe Hop Length.", в других версиях RVC её я не нашёл. Но, почему-то, там отсутствует метод rmvpe, который точно был, когда оно висело на колабе.
https://github.com/AKhilRaghav0/EasyGUI-RVC-Fork?ysclid=lnr6u9ryy344916232
Ещё у меня лежит RVC, в которой есть rmvpe, но нет этой крутилки, а она нужна шопиздец.
https://huggingface.co/datasets/Ba1yya/RVC_rmvpe/tree/main
Как забороть проблему? Пытался прикрутить rmvpe, но там больно дохуя файлов, которые приходится переделывать, да и я тут не то что бы сильно понимаю. Или, может, у кого-то есть версия с обоими этими хуйнями?
Отбой.
Как обычно, сначала хуйню спросил, потом подумал. Эта крутилка и нинужна там.
Аноны, кто-нибудь может перевести это на инглиш?
Это она озвучивает?
Это же сперва человек пропевает а уже потом накладывается нейрота. Я правильно понял?
Да, суёшь в RVC или SVC модель, обрабатываемую дорожку (вокал нужно отделить от музыки), достаёшь оттуда такой же вокал, но с другим голосом.
блять анон, замени лицо гитлера на зеленского на 1 видео, это будет вообще 10/10
анончики, пожалуйста, не поленитесь, наставьте на путь истинный, я уже изъебался осилять в пустоту
я хочу из своего скрипта отправлять нейронке текст и чтобы она выдавала мне его нужным голосом
как понял я, таков путь: отправляем текст в ттс, полученный файл отправляем в рвс, других вариантов нет?
тогда вопрос, какую ттс использовать лучше всего чтобы из неё делало охуенные результаты рвс?
текст будет только русский и мужской
и пожалуйста, подскажите такую ттс чтобы всё было в 1 папке и ненужно было ебаться с зависимостями, виртуальными средами и прочей хуйнёй
и анончики, поясните пожалуйста для тупых:
- если в форке есть файл install, он качает всё что есть в requirements, всё это говно ставится в эту папку или срёт по всей системе?
- в форке RVC-Project например в папке runtime\Lib\site-packages есть просто куча говн например google, это же всё мусор потому что нахуй ненужно и китаец который собирал этот форс просто пидор?
- все эти файлы в папке runtime в папке Lib и Scripts это же и есть те самые модули которые можно подключить к питону и тем самым расширять его функционал, то есть то что пишется после import?
я хочу из своего скрипта отправлять нейронке текст и чтобы она выдавала мне его нужным голосом
как понял я, таков путь: отправляем текст в ттс, полученный файл отправляем в рвс, других вариантов нет?
тогда вопрос, какую ттс использовать лучше всего чтобы из неё делало охуенные результаты рвс?
текст будет только русский и мужской
и пожалуйста, подскажите такую ттс чтобы всё было в 1 папке и ненужно было ебаться с зависимостями, виртуальными средами и прочей хуйнёй
и анончики, поясните пожалуйста для тупых:
- если в форке есть файл install, он качает всё что есть в requirements, всё это говно ставится в эту папку или срёт по всей системе?
- в форке RVC-Project например в папке runtime\Lib\site-packages есть просто куча говн например google, это же всё мусор потому что нахуй ненужно и китаец который собирал этот форс просто пидор?
- все эти файлы в папке runtime в папке Lib и Scripts это же и есть те самые модули которые можно подключить к питону и тем самым расширять его функционал, то есть то что пишется после import?
Путь действительно один. Отправить текст в ттс и потом в рвс.
Лучшая ттска для отправки в рвс это еджттс https://github.com/hinaichigo-fox/rus-edge-tts-webui это гуи от меня могу подсказать если что надо. Установка простая. Скачиваешь 3 библиотеки
pip install edge-tts
pip install gradio
pip install asyncio
и запускаешь python app.py. Далее в консоли будет ссылка
>- если в форке есть файл install, он качает всё что есть в requirements, всё это говно ставится в эту папку или срёт по всей системе?
Без виртуального окружения тебе всегда будет срать по всей системе.
>- в форке RVC-Project например в папке runtime\Lib\site-packages есть просто куча говн например google, это же всё мусор потому что нахуй ненужно и китаец который собирал этот форс просто пидор?
Это не засорит тебе в системе. И плюсом можешь поискать по коду. Эта библиотека найдется. Там нет ничего ненужного.
>- все эти файлы в папке runtime в папке Lib и Scripts это же и есть те самые модули которые можно подключить к питону и тем самым расширять его функционал, то есть то что пишется после import?
это библиотеки. Библиотеки нужны для сокращения кода. Например вместо того чтобы писать кучу кода ты просто обращаешься к библиотеке и код сокращается в разы
>Лучшая ттска это еджттс
это тебе ты скозал?
>это гуи от меня
вишмастер там установлен или надо кочать?
>pip install
вот из-за него и не хочу, это пиздец какой-то, в наше время такой хуйни небыло чтобы всё само ставилось, только ручками или портабл
у тебя это просто ттс получается, из него потом нужно в рвс отправлять?
а что насчёт https://github.com/litagin02/rvc-tts-webui скажешь? мне руки не позволяют его поставить из-за всех этих git clone curl venv pip install, у меня какая-то встроенная ненависть к ним, а хочется такую штуку, как блять её наебать чтобы она как рвс без всех этих свистоперделок работало просто из папки просто по батнику
>это библиотеки
точно, они самые, просто я жабаскрипт червь без фреймворков и без опыта в питоне у меня эти ваши библиотеки сложна СЛОЖНА
>Без виртуального окружения тебе всегда будет срать
но ведь рвс работает без всех этих говн просто из папки по батнику, почему ттс не может?

Отправил ПР для твоей репы, чтобы настраивать venv и ставить зависимости через запуск одного батника. Инструкцию по установке можно будет сократить до пикрелейтед (только имя своей репы подставь).
Развернул твой проект на HF здесь:
https://huggingface.co/spaces/NeuroSenko/rus-edge-tts-webui
TTS нетребователен, так что даже на бесплатном спейсе от HF работает быстро. Предлагаю тебе самому спейс на HF развернуть, если будешь дальше правки вносить.
говоришь не на русском. Расскажи что такое ПР.

а. все. разобрался
Спасибо. Я переделал репу
ПР - PR - Pull Request - Запрос на слияние
Процедура, когда кто-либо предлагает внести правки из одной гит-ветки в другую. Если говорить простым языком про основной сценарий - это когда другой человек предлагает внести свои правки в твой код. Пока ты не добавил правки вручную, на экране с тем ПР должна была быть доступна кнопка вида "Merge pull request", которая в пару кликов добавила бы правки в репу. Сейчас тебе пришлось это делать вручную.
Обычно ПРы используют, когда над проектом работает больше одного человека, чтобы они могли проверять изменения друг-друга перед тем, как слить правки в общую кодовую базу. В случае опенсорса это помогает владельцу репы удобно принимать правки от мимокроков.
Подробнее здесь можешь почитать, если будет желание:
https://git-scm.com/book/ru/v2/GitHub-Внесение-собственного-вклада-в-проекты
спасибо
Есть пайплайн для обработки чего-то сложнее чем цоевское завывание под гитарку? Желательно для безопытных в обработке аудио.
Анон, привет, ворвусь в тред не читая шапки, с набором конкретных вопросов.
У меня есть задача озвучить несколько реплик, для некоммерческих целей, типо как бы для мемеса, желательно на английском, можно и на русском.
Есть актер забугорный, голос которого хотелось бы использовать, есть кино-фильмы с его участием.
Что мне понадобится чтобы выполнить мою задачу? Буду благодарен если разъясните прямо по пунктам
У меня есть задача озвучить несколько реплик, для некоммерческих целей, типо как бы для мемеса, желательно на английском, можно и на русском.
Есть актер забугорный, голос которого хотелось бы использовать, есть кино-фильмы с его участием.
Что мне понадобится чтобы выполнить мою задачу? Буду благодарен если разъясните прямо по пунктам
1.Обучить голосовую модель этого актера.
1.1. Для этого нужно собрать датасет. Лучше всего как минимум 1 час чистой речи.
1.2. Запихнуть в рвс и обучить модель
2. Открыть любой ттс из шапки треда. Например этот https://huggingface.co/spaces/NeuroSenko/rus-edge-tts-webui . Там на русском озвучить нужный текст.
3.Получить мп3 файл с текстом и переделать его в вав.
4. Запихнуть в рвс с нужной моделью.
Профит
1 час речи или около того, есть. С музыкой правда и прочим дерьмом.
Где достать РВС и как конкретно туда запихнуть аудидорожку для обучения модели?
https://www.youtube.com/watch?v=l5ZsZgEwivU
https://www.youtube.com/watch?v=0bG8boJZ9j4
Чекни этот пост только аудиодорожку для RVC можно не нарезать на кусочки, если в датасете нет голосов других персонажей - RVC сам всё нарежет. Музыку уберёшь из датасета через https://github.com/Anjok07/ultimatevocalremovergui (UVR).
На ютабе полным-полно гайдов по сведению и мастерингу вокала. Пайплайн в большинстве случаев примерно одинаковый и никакой рокетсаенса там нет. Освоишь — и сможешь делать из говна что-то более-менее похожее на студийную запись. Полезешь в эти дебри чуть дальше — и сможешь вручную корректировать картавость, шипящие и твердые согласные.
Да я хочу тупо голос Трауна в английской версии оторвать и использовать для пары тройки реплик, на случай важных переговоров
Может кто подсказать где откапать голос славы кпсс для рвц? Чет нихуя не могу найти
Обучи сам. Он же стример ебучий, у него месяцы чистой речи без музла и прочих фонов нарезать можно.
Я в своё время продал душу дьяволу и купил карточку интел за "цена/качество", с коей как мы знаем нейронки не хотят дружить. А на коллабах соединение разрывается через минуту.
Аноны может кто подсказать приятные женские русские голоса, а то я хз как такое гуглить, а прослушивать все модели подряд такое себе. Напишите пару субъективных примеров если кто использует.
в siletoTTS есть бая голос. Офигенный голос. Ну а так хз
>в siletoTTS есть бая голос. Офигенный голос
Знаю такой, да неплохой голос. Но или у меня сборка косячная, или голос еще не доработан, но при записи какие-то левые звуковые эффекты образуются типо вздохов что-ли и слушать такое тяжело причем именно с этим голосом в другом же от них который использую все нормально.
вздохи классные. я подрочил один раз даже
Есть ли нейросеть, которая копирует русский голос на качество похуй бесплатно? Нужно одно предложение озвучить, пара секунд. Не для коммерческих целей, а так, мем запилить.
посоны, хочу из текста делать озвучку нужным мне голосом, я как понял нужно сперва ттс озвучить текст, потом через рвс переозвучить нужным голосом, вот этот форк норм будет? вишмастер не разъебут меня? https://github.com/rsxdalv/tts-generation-webui
Это фигня полная. Бери простые ттски и потом через рвс простой прогоняй. Например возьми еджТТС. Он и для русского и украинского есть. Вот чтобы на пк скать https://github.com/hinaichigo-fox/rus-edge-tts-webui и вот чтобы онлайн https://huggingface.co/spaces/NeuroSenko/rus-edge-tts-webui . Потом полученный файл прогоняешь через рвс и все
блять аноны объясните тупому, я уже горю нахуй
например https://github.com/rsxdalv/tts-generation-webui написано что надо сделать кучу ебаных инсталов, например pip install -r requirements.txt
я правильно понимаю что pip это какойто ебаный файловый менеджер в котором хранится куча урл для скачивания всего того говна что написано в requirements.txt?
а этот пидор не ставит всё это говно сам в свой гит чтобы у меня типа была последняя версия того говна что там написано и которое необходимо для работы его программы и чтобы его программа много не весила до скачивания?
как всё это называется и какое видео можно посмотреть чтобы понять что блять происходит и в чём их логика, в моём понимании это актуальность версий софта который они использовали и малый размер при скачивании с гитхаба
сука хочешь просто скачать ебучую нейронку и запустить из папки, а тут сука куча какихто непонятных ебаных установок, виртуальных сред и хуй пойми ещё чего, а главное хуй пойми куда вся эта блядина ставится, или весь этот мусор ставится в ту же папку откуда я запускаю нейронку?
я просто пишу хуйню для озвучки текста на автомате, и у меня уже получается 5 нейронок надо запускать, сука 5 ебаных консолей говна которое ставит неведомое говно в мою систему и висит срёт в памяти поднимая ебаные сервера, я в ахуе, помогите разобраться просмотром видео от человека который объяснит весь процесс и наъуй так делают, я думаю всё это можно вообще обьеденить в 1 проект и запускать с 1 файла из сосноли
например https://github.com/rsxdalv/tts-generation-webui написано что надо сделать кучу ебаных инсталов, например pip install -r requirements.txt
я правильно понимаю что pip это какойто ебаный файловый менеджер в котором хранится куча урл для скачивания всего того говна что написано в requirements.txt?
а этот пидор не ставит всё это говно сам в свой гит чтобы у меня типа была последняя версия того говна что там написано и которое необходимо для работы его программы и чтобы его программа много не весила до скачивания?
как всё это называется и какое видео можно посмотреть чтобы понять что блять происходит и в чём их логика, в моём понимании это актуальность версий софта который они использовали и малый размер при скачивании с гитхаба
сука хочешь просто скачать ебучую нейронку и запустить из папки, а тут сука куча какихто непонятных ебаных установок, виртуальных сред и хуй пойми ещё чего, а главное хуй пойми куда вся эта блядина ставится, или весь этот мусор ставится в ту же папку откуда я запускаю нейронку?
я просто пишу хуйню для озвучки текста на автомате, и у меня уже получается 5 нейронок надо запускать, сука 5 ебаных консолей говна которое ставит неведомое говно в мою систему и висит срёт в памяти поднимая ебаные сервера, я в ахуе, помогите разобраться просмотром видео от человека который объяснит весь процесс и наъуй так делают, я думаю всё это можно вообще обьеденить в 1 проект и запускать с 1 файла из сосноли

One-click installer пробовал? Правда, там миниконда нужна.
Вообще, если тебе нужно просто несколько фраз переозвучить, то проще делать как этот анон предлагает Я лично вообще хз что ты там за комбайн смотришь, хотя может и годное что-то - за все эти форки не шарю.
TTS можно делать в облаке (по ссылке выше), либо скачать его и через bat-скрипты подтянуть зависимости в папку с проектом. RVC качается сразу со всеми зависимостями, там не нужно лезть в консоль.
>кучу ебаных инсталов,
>например pip install -r requirements.txt
Для тебя прописать пип инсталл реквестст это много?
>я правильно понимаю что pip это какойто ебаный файловый менеджер в котором хранится куча урл для скачивания всего того говна что написано в requirements.txt?
Нет. Пип это не файловый менеджер. Это модуль для установки пакетов. Пакеты нужны для простоты. Вот представь. Что легче? Нести продукты в руках или взять пакет и положить туда продукты? Вот и тут так же чтобы не писать 10000+ строк проггер импортирует библиотеку и код сжимается до 10 строк
зависимости это типа весь необходимый софт чтобы его скрипты запустились? например тот же gradio?
анон у меня боль когда программа ставит непонятно что непонятно куда, у меня зависимость от портабл софта
и всё же получается pip менеджер в котром хранятся все ссылки на нужные версии софта, как ты говоришь пакетов который нужен чтобы скрипт автора нейронки смог стартовать?
>анон у меня боль когда программа ставит непонятно что непонятно куда, у меня зависимость от портабл софта
Переходи на линукс ставь виртуальные среды!
>и всё же получается pip менеджер в котром хранятся все ссылки на нужные версии софта
Ну не совсем. Через него пакеты нужные можно установить. Ты не идешь на какой нить сайт с исходниками библиотеки и сам ее компилишь а просто пишешь pip install либа и все.
Лучший совет, анон, не ешь месяц и усердно работай. Заработай себе на 1тб ссд и вставь в комп. и больше не парься по поводу памяти
лол, если бы в этом была проблема, я не хочу чтобы винда была засрана и биллиард телеметрий собирал записи каждого моего пука


> зависимости это типа весь необходимый софт чтобы его скрипты запустились? например тот же gradio?
Всё верно. Зависимости - это либы, которые требуются для запуска проекта. В большинстве случаев они прописаны в файле requrements.txt.
В случае pip зависимости могут ставиться глобально (насрать в систему) или локально.
Для проекта, который анон выше кинул, написаны скрипты, чтобы зависимости ставились в папку venv, которая будет болтаться в корне проекта. То есть оно не будет никуда срать в систему. Для RVC ещё проще - при скачивании стандартной версии (не какого-то непонятного форка) всё зависимости идут сразу в комплекте, то есть оно не будет расползаться по системе и ты всегда можешь снести всю директорию с проектом целиком, точно зная, что не останется каких-то следов в системе.
вот и я о том, почему нельзя делать 2 версии, одна как они любят дрочить с пипкой, а другая всё говно 1 папке чтобы не ебаться, скачать - запустить, не нравится - удалть нахуй и забыть, нет блять надо всю систему пипками ебать и потом вилкой говно чистить
норм TTS? https://github.com/Tera2Space/TeraTTS
Ну, в том же Stable Diffusion WebUI зависимости автоматически ставятся в папку с проектом при первом запуске. Тут уже зависит от того, насколько сильно разработчик запарился над тем, чтобы его тулзу было легко поставить. Просто в TTS/STS куча форков и мелких проектов - не вышло какой-то стандарт де-факто сделать, как получилось в случае со Stable Diffusion. Так что сотни людей вместо того, чтобы коллективно один проект до ума доводить, пилят каждый свой велосипед, не имея времени/возможности его до ума довести.
аноны в папке RVC\runtime\Lib\site-packages очень дохуя всяких файлов, это и есть те пакеты которая ставятся pip и прочей гадостью? это и есть зависимости? то есть то без чего остальной код RVC не заведётся?
тогда непонятно почему их так много, например там есть пакеты гугл и гидра, нахуя в рвс нужно какоето говно для работы с гул? или гидра, насколько я помню это брутфорсер паролей
тогда непонятно почему их так много, например там есть пакеты гугл и гидра, нахуя в рвс нужно какоето говно для работы с гул? или гидра, насколько я помню это брутфорсер паролей

> это и есть те пакеты которая ставятся pip и прочей гадостью? это и есть зависимости? то есть то без чего остальной код RVC не заведётся?
Всё верно.
> тогда непонятно почему их так много, например там есть пакеты гугл и гидра, нахуя в рвс нужно какоето говно для работы с гул? или гидра, насколько я помню это брутфорсер паролей
Список всех прямых зависимостей для RVC на скрине. Можно погуглить по каждой либе, что она конкретно делает, если хочешь с этим разбираться. При этом каждая либа может тащить за собой другие либы. Вот и получается, что в папке site-packages у тебя больше 300 разных папок, в которых чёрт ногу сломит.
В TTS-проекте, который анон ранее скидывал, подключаются всего три библиотеки, но, тем не менее, в site-packages там 150 директорий, так как либы друг-друга по цепочке тянутся.
Это другая гидра, там что-то про конфигурирование приложений: https://github.com/facebookresearch/hydra
Про гугл не подскажу, допускаю, он тянется другой либой, но не используется по факту. Добро пожаловать в мир современной разработки.
Челы пилят опенсорсный русскоязычный TTS. Заявляют, что решили проблему с автоматической расстановкой ударений.
https://habr.com/ru/articles/767560/
В комментах срутся с разрабами Silero, лол.
https://huggingface.co/spaces/TeraTTS/TTS
https://t.me/teratts_bot
Вот тут глянуть можно в онлайне.
>Добро пожаловать в мир современной разработки
пиздец анон, сильнее меня подбрасывает только с ООП и MVC
это как с памятью когда браузер 10гб жрёт или с играми когда пустая локация грузит гпу на 100%, пидоры одним словом а не разработчики
получается я могу просто скачать нужные все пакеты и закинуть в папку с питоном в папку с скачанным проектом и всё должно завестись если я правильно пути проставлю? и ненужно будет виртуальные среды создавать и инстолы запускать?
а в чём минус дохуя пакетов в системном питоне? начинает тормозить? потому что виртуализацию насколько я понял используют чтобы в основной питон не ставить нужные для гита пакеты
уже тыкал онлайн версию, мне показалось без хуйни с ударениями озвучка человечнее, ещё скорости надо поддать а то слишком медленно читает, короче можно использовать как основу для RVC?
Ну да, юзеры уплатят за доп. плашку RAM. Такова цена кроссплатформенности и быстрой разработки.
> получается я могу просто скачать нужные все пакеты и закинуть в папку с питоном в папку с скачанным проектом и всё должно завестись если я правильно пути проставлю? и ненужно будет виртуальные среды создавать и инстолы запускать?
"Прописывание путей" по сути и есть задание виртуальной среды. Просто ты говоришь питону, что "либы качай/ищи не в стандартной системной помойке, а вот в этой папке".
> а в чём минус дохуя пакетов в системном питоне? начинает тормозить? потому что виртуализацию насколько я понял используют чтобы в основной питон не ставить нужные для гита пакеты
Во-первых, это засирает систему. Ты потыкал тулзу, удалил её, а зависимости мог забыть удалить из системы. В результате, у тебя на системном диске лежит ненужный кал, который никто потом не удалит, и его объём может быть существенным.
Во-вторых, могут быть конфликты версий, когда одна тулза работает только с одной версией либы, а другая тулза только с другой. Разбив это на виртуальные среды ты можешь скачать две разных версии либы и подсунуть то, что каждой из утилит нужно.
Ну вот быстро затестил Silero vs Edge vs Tera с последующим изменением голосом в RVC. Имхо, Terra хуже всего себя показала на этом отрывке.
Почему, мистер Андерсон, почему? Во имя чего?.. Что вы делаете? Зачем? Зачем встаёте? Зачем продолжаете драться?.. Неужели вы верите в какую-то миссию — или вам просто страшно погибнуть? Так в чем же миссия, может быть, вы откроете?!.. Это свобода? Правда? Может быть, мир?! Или вы боретесь за любовь?! Иллюзии, мистер Андерсон, причуды восприятия! Хрупкие логические теории слабого человека, который отчаянно пытающегося оправдать своё существование, бесцельное и бессмысленное! Но они, мистер Андерсон, как и Матрица, столь же искусственны!!! Только человек может выдумать скучное и безжизненное понятие — любовь!.. Вам пора увидеть это, мистер Андерсон, увидеть и понять! Вы не можете победить! Продолжать борьбу бессмысленно!!! ПОЧЕМУ, МИСТЕР АНДЕРСОН, ПОЧЕМУ ВЫ УПОРСТВУЕТЕ?!
Ещё такой момент. У Edge плюс по сравнению с Silero в том, что Edge английские слова озвучивает посреди текста, а Silero такое просто пропускает.
> и биллиард телеметрий собирал записи каждого моего пука
Господи. Скажи, о тебе собирает информацию лист бумаги? Пакеты в питоне за тобой следить не будут
ну как бы тебе сказать. Сам процесс обработки текста хороший. Я его возьму. А голос не очень
>Edge английские слова озвучивает посреди текста, а Silero такое просто пропускает.
Так и с числами. Силеро не озвучивает числа. Но от этой фигни можно избавиться.
https://github.com/oobabooga/text-generation-webui/blob/main/extensions/silero_tts/tts_preprocessor.py Вот пример обработчика текста который меняет текст как надо.
https://github.com/Em1tSan/silerotts-webui/blob/main/tts.py
Вот тут уже на русском
блджад, матрица сбоит, откуда ты знаешь что я только что смотрел пранк про мистера андерсона? https://www.youtube.com/watch?v=YWWdtow0cZ0
анон как это выглядит, ты поставил все эти 3 нейронки, установил кучу говна что они просят для запуска, запустил 3, ТРИ СУКА ебаных локальных сервера с гуем, сохранил результаты, запустил ещё ОДИН ЕБАНЫЙ сервер с гуем для рвс, прогнал через него, сохранил, потом взял ЕБАННЫЙ ффмпег, картинку и через ещё одну ебанную сосноль по очереди склеивал картинку с сохранённой аудиодорожкой?
пиздец нахуй ну и страдания блять, 2024 год
>это засирает систему. Ты потыкал тулзу, удалил её, а зависимости мог забыть удалить из системы. В результате, у тебя на системном диске лежит ненужный кал, который никто потом не удалит
а зачем пакетам, насколько я понял таким же питон скриптам загружаться кудато в системные папки? а нельзя просто скопировать питон в папку с нейронкой которую хочешь поставить, закинуть в неё в папку либ необходимые пакеты из реквайрементс и запустить всё это говно не устаналивая питон себе в систему вообще? ведь рвс работает без всего этого, у него там свой питон и библиотеки, он просто запускаются и всё работает ничего не засирая, как мне показалось, возможно конечно он срёт в кучу временных папок и локальные папки пользователя
а что насчёт https://github.com/suno-ai/bark
https://github.com/rsxdalv/tts-generation-webui тоже на bark работает?

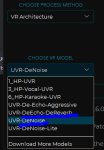
Может кто посоветовать чем выдирать вокал, что бы чище всего было и инструментал? Я пользуюсь вот фт, вроде как...нормально?
И чем еще чистить сверху? Я пользуюсь этими двумя, нойс и удаления эха и реварба.
И чем еще чистить сверху? Я пользуюсь этими двумя, нойс и удаления эха и реварба.
Ну а как ты хотел? Сначала открываешь ттску прогоняешь текст. Потом сохраняешь его и в рвс. Потом с помощью видеоредактора соединяешь картинку и аудио.
Вопрос 1. А че ж ты сам то не сделаешь штуку которая будет все в одном?
аноны, а что за кеш в нейронках и почему его надо чистить и почему это не происходит автоматом? и как убедиться что после использования нейронки нигде не осталось говно и всё вычистилось? и что за кучи файлов в папках __pycache__? хули всё так засрано и так много непонятных файлов с непонятными расширениями
пайкэш можешь удалить нахрен. Оно каждый раз создается при запуске. В любом даже простецком проекте если юзается какая либо либа запоминающая что то то появляется кэш.
п почему оно само за собой не подтирает? и при использовании рвс там тоже есть кнопка очистить память гпу, что это значит в техническом плане? питон срёт в видеопамять как в эти __pycache__ и не убирает за собой? да что он за мразь такая
я так понимаю ты и в браузере куки каждый час чистишь?
сперва ты узнал что я смотрю пранк про мистера андерсона, теперь узнал про куки, я в матрице?
посоны, по сути, чтобы не запускать виртуальную среду и не ставить себе всякое говно для её запуска, можно просто кинуть папку с пайтоном в папку с нейронкой и установить в неё все необходимые библиотеки и запускать просто стартовый файл через батник?
а пайтон можно например скопировать с рвс из папки runtime?
я другой анон. тот пост с сенко не мой
Нет. Это так не сработает
Нет. Твой пароль 123456 не украдут от того что ты запустишь нейросеть. Нет. За тобой не приедут майкрософты и не заберут тебя в анальное рабство. Нет. За тобой не приедет фсб потому что ты сделал кавер на песню про адольфа гитлера.
Вот эта тема вин. Нейронки для рисования говно безе задач, а вот это действительно нужно. Кучу контента малоизвестного можно выкатить ан международную арену. Зеленый слоник на японский перевести например.
но почему же анон? инфа сотка? смотрит я даже в ту же папку нейронки что просит запустить виртуальную среду прямо в неё закидываю питон с его файлами, запускаю его через терминал и пипкой ставлю всё что прописано в реквайремент от этой нейронки и запускаю основной файл нейронки через батник прямо из этой папки, почему не должно сработать? ведь путь до питона указан, все библиотеки установлены в папку либ
батник это не основной файл. В батнике простые команды типа старт смд и в ней прописывается старт файл нужный. Ты батник открой в блокноте и увидишь что там. И все поймешь.
Питон не будет работать локально как и другой яп. он должен быть установлен в системе
я щас на линуксе. И я не особо устаю от того что вместо нажатия на старт.бат я пишу в консоли python start.py
ты меня наверно не понял, я говорю что делаю то что описал ранее, потом пишу в батник python.exe tts.py и вуаля, основной файл .py запущен, а там уже подтягиваются прописанные библиотеки из либс, почему же нет? виртуализация насколько я понял это же просто создание временной папки для питона установленного в систему чтобы в него сыпалось всё говно из реквайремент, а тут я просто в ттс добавлю свой питон и установлю всё говно в него, то есть должно же стартовать без виртуализации и сранья в основной птон, хотя мне и на основной питон похуй
Что анон думает про https://github.com/suno-ai/bark ?
https://github.com/rany2/edge-tts vs. https://github.com/suno-ai/bark куда сам сядешь, куда мать посадишь?
https://github.com/rany2/edge-tts vs. https://github.com/suno-ai/bark куда сам сядешь, куда мать посадишь?
>https://github.com/rany2/edge-tts
>Microsoft Edge's online text-to-speech service
>online
Сразу нахуй.
оно работает и без тырнета
Во первых. Если и юзать еджТТС то с гуи https://github.com/hinaichigo-fox/rus-edge-tts-webui https://huggingface.co/spaces/NeuroSenko/rus-edge-tts-webui
Ну определенно на еджттс. Из плюсов: скорость, большой словарь с правильными ударениями(в барке как по мне не особо правильные ударения да и говорит с акцентом). В еджттс голос более менее не роботизированный и чистый. В барке появляются дефекты.
Ну а ты сам выбирай. Для чего тебе?
1. Для последующей обработки в рвс это тебе едж ттс
2. Для озвучки текста это тебе в барк
https://youtu.be/lvM9ayZOxoo?feature=shared вот те гайд. Устанавливай питон на флешку и там все делай
Анон. Пробуй. Все в твоих руках!
Тебе платят за рекламу этого твоего гуя?
нет не платят. Полностью бесплатно. Опенсорс лол
ну вот анон, получается виртуальное окружение нахуй ненужно? просто закидываем нужную версию питона в папку с нейронкой, ставим все необходимые библиотеки в этот питон, настраиваем пути и готово? хоть убейте не понимаю нахуй нужна эта виртуальная среда, если можно просто закинуть свой питон в нейронку с нужными библиотеками
Сука заорал с кореянки.
почему все эти нейронки работают на gradio? питон не может в интерфейс?
может конечно. Только не такой будет как в гардио.
снеси питон но перед этим скопируй питон.ехе и потом запихай в папку. ну и проверь че у тя работает
запусти виртуалку и там тесть лол
у меня нет питона, но рвс работает же без всей этой ебалы из своего локального питона в папке runtime без этих ваших виртуальных сред, отсюда у меня и непонимание нахуй всё это говно, если можно просто закинуть питон с нужными библиотеками в папку с нейронкой и запустить главный срипт через этот питон просто указав до них путь в батнике
а. рвс работает без питона? Нифига себе.
ну так перенеси из рвс файлы в другую нейронку
бля ты жопой читаешь
не могу понять че ты хочешь и почему не хочешь устанавливать питон
не хочу ставить его в систему, зачем если его можно поставить портативно прямо в папку с нейронкой для каждой свой без установки в систему и без предвариельного запуска всяких виртуальных сред, рвс же работает без всего этого говна, значит и остальные должны смоч, как руки доберутся попробую на твой же руттсэджгуй поставить свой питон без установки в систему просто копированием и запустить всё это дело и без виртуальной стреды
что происходит на первом вебм? уколотый шеневмерный навозец через силу поет новый гимн?
Я соло исполнение российских гимн на скорую руку не нашел
пробуй тогда. если в рвс работает то везде должно

Аноны, очень хочу трейнить модельки на RVC, но у меня AMD вместо видяхи, помогите, что делать?
на каггле тренить. Вот гайд https://youtu.be/uA92FDw_Xfw?feature=shared
добра тебе, анонче!

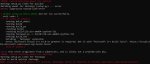
что эта мразь от меня хочет? чтобы я установил очередное дерьмо https://visualstudio.microsoft.com/ru/visual-cpp-build-tools/ ?

как же я ненавижу современных разработчиков, инвалиды сука ебаные, скачай то что нахуй недоступно иначе я не буду работать, заебись блять

блять у меня и так в системе стоит версия выше 14.0, почему это говно просит его установить?
Не путай простой с++ и буилд тулс. это разные вещи
Хочу нейронку чтобы песню писало по промпту одного предложения и стилистике и само пело.
Типо: предоставить песню про то и то, длина 3 минуты, стиль такой-то, тональность мажорная минорная, настроение веселое, стилистика годов выпуска и тп..
Типо: предоставить песню про то и то, длина 3 минуты, стиль такой-то, тональность мажорная минорная, настроение веселое, стилистика годов выпуска и тп..



> а что насчёт https://github.com/suno-ai/bark
Чёт у них похоже пример на коллабе поломанный, с русским языком совсем какая-то шиза выходит:
https://vocaroo.com/1dizRoE1qYsw
> Вот пример обработчика текста который меняет текст как надо.
И вправду, просто перед отдачей в нейронку меняет несколько различных подстрок, которые нейронка не распознаёт. Занятно, что такое не включили в Silero изначально, идея то тривиальная...
> анон как это выглядит, ты поставил все эти 3 нейронки, установил кучу говна что они просят для запуска, запустил 3, ТРИ СУКА ебаных локальных сервера с гуем
Для всех трёх TTS развёрнуты спейсы в hf, так что локально при желании можно его не запускать.
> запустил ещё ОДИН ЕБАНЫЙ сервер с гуем для рвс, прогнал через него, сохранил результаты
Да.
> потом взял ЕБАННЫЙ ффмпег, картинку и через ещё одну ебанную сосноль по очереди склеивал картинку с сохранённой аудиодорожкой?
Я для этого такую фигню в онлайне запаблишил, чтобы проще было объединить аудио с картинкой:
https://huggingface.co/spaces/NeuroSenko/audio-processing-utils
Оно, правда, тоже кривое, но мне хватает. Если делать в онлайне, то добавляется 3 секунды тишины в конце т.к. там качается не та версия ffmpeg, что на винде, и команда ведёт себя иначе; и число пикселей по ширине/высоте должно быть чётным по какой-то причине...
Можно, если ты убедишь разработчика пакета так заморочиться.
Ну хоть что то...
Да это оно, но еще недоразвитое, через 3 года подрастет, чат гпт внедрят 5ю версию и будут песни одной левой писать и петь.
Типа колонке говоришь, а ну-ка спой мне песню как я хорошо посрал в стиле джаз, оно само генерирует и исполняет..
Я просто хочу на чтоб мне прожка на английском читала текст женским человеческим голосом(бесплатно). Есть такое? Все что я нахожу платное или пару строк только может, я хочу прям текст закинуть
конечно можно. Берешь модель нормальной бабы, потом прогоняешь через edgeTTS и затем через рвс
Реально что ли для озвучки нейросетью, нужно пердолиться с указанием ручками как читается "г.", "%" и т.п.? Оно ж еще по контексту может меняться: год, грам, гривны, просто буква г, да еще и миллион разных форм слова, и точку не всегда пишут
Этот уже не нейронка в таком случае, это старый перебор всех возможных случаев руками
это не чатжпт тебе чтобы понимать что там за г сокращено. Это синтезаторы речи. Они просто по тексту синтезируют. если есть г они будут читать это как г если есть рандомное сочитание букв то они его прочитают так как написано. Это машина, у нее нет мозга
у Edge хорошее понимание произношения букв исходи из используемых слов и их контекста. Не совсем хорошо, но в большинстве случает читает лучше среднего гражданина этой страны.
Я вот тут ничего не перебирал.
>suno bark
Не читал и возможно не в тему скажу: у них в дискорде можно быстро потестить. Время от времени генерит хуйню, да, зато очень эмоционально.
аноны я дурак, установил нейронку через пипы, виртуалки и прочую хуйню, как теперь это запускать с батника? пишу вот это, а у меня просто открывается и закрывается консоль
C:\AI\venv\Scripts\activate
pause
Если открываю консоль с этой папки venv и пишу Scripts\activate то работает, а если с батника то нет, моментально закрывается и даже pause не помогает
C:\AI\venv\Scripts\activate
pause
Если открываю консоль с этой папки venv и пишу Scripts\activate то работает, а если с батника то нет, моментально закрывается и даже pause не помогает
короче как сделать батник чтобы он активировал виртуальное оружение уже созданного проекста и запускал нужный файл из окружения? если писать просто пайтон и ссылку на исполняемый файл то он пытается найти нужные библиотеки в глобальном пайтоне и обсирается, а если перед запуском написать активацию виртуальной среды то она активируется и тут же закрывается сосноль, чё за пиздец

Первой строкой. Дальше что хочешь. В конце
PAUSE
ставь.
анон спасибо, изза этого КАЛА весь мозг уже изъебал, а ебаный ChatGOVNOTA про этот call ни слова не сказал
> ChatGOVNOTA
Ебало имажинируйте. Подтереться-то после сранья без помощи этой хуйни еще в состоянии?
с каканием всё хорошо если не затягивать на 3 дня, потом может случиться запор доктор
а у кого ещё мне спросить чтобы меня не обосрали? только у него
Пользователям TTS. А какое применение вы видите вообще в этом? Мой кейс был такой - выдернул текст из файла субтитров для того чтобы прогнать через ТТС и затем прогнать через РВЦ для дубляжа. Итог такой что все эти ТТС начитывают максимально механически и для +- нормальной озвучки не подходят вообще. Есть какая ТТС которая как то играет голосом немного? И почему при прогоне через РВЦ в готовом оутпуте как будто не применяется файл черт голосовой модели, потому что на выходе звучит так же механически только другим голосом
>Есть какая ТТС которая как то играет голосом немного?
Нормальная технология пока только у корпов под замком, у мордокниги полностью закрытая, у Elevenlabs можно потрогать руками, роликов в треде вагон.
>А какое применение вы видите вообще в этом?
Озвучка видео. Не нужно париться с записью своего или чьего-то голоса - загенерил речь, добавил звуковой дорожкой к видеоряду и актеры озвучки уже не нужны.
Получается ттс движок годный пока только у elvenlabs но он не опенсорс и никогда им не будет, так?
Но ведь это озвучка то такая себе, для передачи смысла пойдет но актеры озвучки то получаются могут расслабить булки назад так как ттски хоть сейчас и могут озвучить, но актерской игры там ноль. Единственный вариант который вижу, это самому наговаривать текст и затем прогонять через рвц под понравившуюся модель. Но тогда ебли то получается не меньше если просто самому озвучивать
>Получается ттс движок годный пока только у elvenlabs но он не опенсорс и никогда им не будет, так?
Там не ТТС, там хитрее, типа сразу зеро-шот перевод с языка на язык. Внутре скорее всего есть ТТС, но он явно использует данные предоставленного звука, все эти интонации и прочие акценты, помимо самого собственно голоса.
Локально у нас только либо озвучивание текста с весьма дубовыми интонациями, либо сравнительно качественный голос-в-голос, тут ты прав.
Благодарю за разъяснение
подскажите ТТС которой можно по АПИ отправить текст и она вернет ссылку на полученный аудиофайл?
локальную, не онлайн
>https://github.com/hinaichigo-fox/rus-edge-tts-webui
после каждой конвертации срёт в AppData\Local\Temp\gradio файлами и не чистит за собой, как это фиксить

анон, не поклади хуя своего, я уже сума схожу, в оригинальном RVC в самом низу есть кнопка Use via API, я думал это API чтобы пользоваться нейронкой через JS, но если посмотреть его, там пиздец со скрина, я не понимаю как ему отправить ссылку на аудио и модель чтобы он сделал преозвучку и вернул мне ссылку на результат?

> я не понимаю как ему отправить ссылку на аудио
Ты блядь в бейс64 не можешь файл закодировать?
>Ты блядь в бейс64 не можешь файл закодировать?
я че мудак что-ли, нахуй оно мне надо

маму ебал этих ваших requirements, блядская хуйня просто не устаналивается, нахуй блять такое говно делать и нахуй я там должен разбираться что этот пидорас от меня хочет, нахуй такое говно выкладывать в сеть, это ебаный https://github.com/Mangio621/Mangio-RVC-Fork такую хуйню высирает, пошли-ка они нахуй со своим манго
>A very experimental fork of
Ебало непредставимо.

>я там должен разбираться что этот пидорас от меня хочет
Зачем тебе вообще этот форк? Чем оригинал с его "скочал zip, распаковал, запустил" не нравится?

выше пчелы ноют что это некомельфо, чо поцоны только так делают
это понятно анон, но если зайти на https://visualstudio.microsoft.com/ru/downloads/ и выбрать там Инструменты для Visual Studioа потом ебаный Инструменты сборки для Visual Studio 2022 и нажать СКОЧАТЬ БУИЛУД ТУЛЗ тебе тут же по ебалу скрин АДРЕС_ИНВАЛИЛД_ПОШЕЛ_НАХУЙ
>АДРЕС_ИНВАЛИЛД_ПОШЕЛ_НАХУЙ
Страной не вышел.

Остановись, пощади, человек-анекдот.
адрес дай
> выше пчелы ноют что это некомельфо, чо поцоны только так делают
Чел, там просто объясняли, что мейнтейнерам, как правило, просто лень оформлять нормальные инсталлеры, но в случае RVC с этим как раз проблем нет.
Просто качни zip для своей платформы здесь и не сношай себе и треду мозг:
https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI/releases
Сам себе выдумал проблему, и начал героически её решать.

нравится, так уже пол часа стоит не россия хотел просто по красоте сделать, а тут как всегда хуем по нод носом провели
а чё делать если я вот это хочу попробовать https://github.com/litagin02/rvc-tts-webui там нет полного архива, а ошибка точно такая же
Тогда остаётся только возиться с зависимостями. Тут хотя бы EdgeTTS+RVC а не просто форк RVC, сделанный хер значет зачем, так что здесь это имеет какой-то смысл.

ошибку установки Microsoft C++ Build Tools высирает https://github.com/facebookresearch/fairseq смотрим описание, понятно, пидоры, пидоры говноеды, вот и не работает
Причина тряски?
какое нормальное приложение/раширение/сайт будет собирать деньги на войну в стране воров, только пидорское
это кэш. чисти руками
Кто может объяснить почему установка библиотек для https://github.com/litagin02/rvc-tts-webui вызывает ошибку требующую установки Visual Studio? Что за бред? Это же просто куча .py файлов
> Это же просто куча .py файлов
Нет, там ещё куча бинарников
> вызывает ошибку требующую установки Visual Studio
Потому что некоторые библиотеки при установке собираются из исходников
качай и все.
Не понимаю, нафига люди качают какую то хрень если есть простой едж ттс и рвс отдельно. Нервы скажут спасибо, да и место на диске
может быть чтобы сразу из текста получить озвучку нужным голосом, как думаешь?
>Потому что некоторые библиотеки при установке собираются из исходников
Спасибо не знал, а нельзя никак наебать систему скопировав эти библиотеки из оригинального RVC?
Не качается
пипец. там качество плохое выходит
Скинь пример?
сам попробуй
=>
>Не качается
Что в RVC делают вкладки Обработка ckpt и Экспорт ONNX?
какая ошибка?
АНОНЫ!
Подскажите есть какой-то способ переводить порнушку ? Пиздец так хочется понимать о чем они там говорят, подскажите идеи как можно хотя бы англ субтитры прикрутить к видосам локальным?
Подскажите есть какой-то способ переводить порнушку ? Пиздец так хочется понимать о чем они там говорят, подскажите идеи как можно хотя бы англ субтитры прикрутить к видосам локальным?
Перевод из аудио/видео в текст: https://github.com/openai/whisper
Вызови команду --help, там была возможность сохранять в формате субтитров. У меня он сейчас не настроен, точную команду не подскажу.
ну и что это за хуйня, пропустил текст через edge-tts, потом через rvc с моделью ленина, последняя в aihub, а на выходе вот это дерьмо, кто там пиздел что edge-tts идеально для rvc
Пипец сжв обиженка. Закенсили их, не пользуйся их софтом, тогда они поймут
членин не матюкался. поэтому не похоже
А где то можно послушать примеры голосов которые доступны в бесплатной Silero которая у себя на компе юзается?
русские голоса
а ты на каком режиме делал? Лучше там делать в рвс в режиме crepe
=> (You)
>Не качается
> 'rmvpe': лучшее качество и минимальная нагрузка на GPU
ну вот. бери crepe
почему не качается? Там должна быть какая то ошибка. Сними на видео процесс установки или покопайся в тырнете
нет доступа из страны, не вошёл в список избранных у пидорасов
че ж у тебя за страна? Я месяц назад скачивал и все норм. Живу в России
ну я хз. мб модель плохая
а эт где делал
Какой нейронкой можно скачать аудиодорожку из видео с ютуба? Желательно чтобы обращаться к ней можно было по API
Тебе вот в этот тред
> скачать аудиодорожку из видео с ютуба
> нейронкой
Зачем?.. Для загрузки видео с ютуба есть браузерные плагины и онлайн-сервисы. Нейросетки-то тут причём.
вы совсем там? Я за 5 минут в том году накидал бота для вк который простым ттс обрабатывает текст и потом загружает как голосовое смс в вк. Один хочет скачать аудиодорожку, другой хочет по апи к ттс обращаться. Ну совсем уже. Совсем уже мозги поехали с нейронками.
Для анона тут логика простая. Скачиваешь с ютуба видос либо сразу аудио скачиваешь либо потом преобразовываешь через модуль os.
Для анона
Че тут думать? Это силеро или эдж ттс. Там апи легкие. простое обращение и потом конвертация в файл. Загружать его можно в питоне либы есть реквест та же
Openai Whisper.
А ты хотел там увидеть САППОРТ ПЫНЕСТАН? Лол, не удивительно, что у тебя нихуя не получается
Посоны, какой нейронкой делают локализацию киберпука? Хули такой хороший звук?
https://youtu.be/OtbMc1dx2gs?si=tc5qpyEc8JIObKC7
https://youtu.be/OtbMc1dx2gs?si=tc5qpyEc8JIObKC7
ищу чтобы загрузил известную композицию и оно само ремикс сделало, есть вот статья с подборкой програм, но примеры в ней не работают или не разобрался
https://filme.imyfone.com/cover-song/ai-music-remixer/
https://filme.imyfone.com/cover-song/ai-music-remixer/
вот эта херня работает, но попробовать дает мало, дальше плати
https://covers.ai/
https://covers.ai/
Аноны. А как удалить то говно чем насрала нейронка?
Нужно скачать и установить другую нейронку, которая чистить все после других нейронок.
мудро
Здесь есть пользователи ControlNet?
Это тебе в треды с стейбл диффюшн. Тут все про аудио
Мда, я совсем уже обдвачевался.
пипец

Привет, анон. Хочу переозвучить некоторые моменты в фильме. Нарежу фраз одного персонажа, сделаю голосовую модель в RVC. На Линухе этим методом можно воспользоваться? Подводных камней нет? Не хочу несколько часов трахаться с тем, что в итоге не получится.
Я слышал, что ему нужно 8ГБ VRAM, верно? У меня Steam Deck, вроде в описании написано что оперативная и видеопамять в нём как бы объединены (пикрил), хотя я впервые об этом слышу.
Я слышал, что ему нужно 8ГБ VRAM, верно? У меня Steam Deck, вроде в описании написано что оперативная и видеопамять в нём как бы объединены (пикрил), хотя я впервые об этом слышу.
конечно можно. запускать рвс можно через infer-web.py
Ебать, ты собрался это на стимдэке делать? И этот человек ещё будет говорить что-то про беспощадное трахание
На стим деке видеопамять lpddr, и это амд Какие нахрен нейронки?
Ух ля охено, рвс спокойно переозвучивает с обученным ранее на колабе голосом на моем говноноуте без жпу. Как же я счастлив анончики. Правда если переделать долгую запись, начинает какую-то ошибку выдавать до перезапуска
Сравнение обработки в рвс голоса от еджттс и трех силероттс
всё звучит как хуйня
Вообще то я кадырку назвал ослоебом и сыном шакала. А вот тебе нужно немножко лучше разбираться в ситуации. А по поводу чурки, в зерколо посомотрись)) Это слово пошло от имени языческого бога Чура. Раньше до христианства русские были язычниками. "Чур меня" это выражение до сих пор используется на территории рф. Вот поэтому и называли русских чурками.
сразу видно неуча. Впервые, именно, монголо-татары во времена вторжения на Россию называли русских чурками, потому что русские прятались от них в русских печах.
МОНГОЛО-ТАТАРСКОЕ ИГО на Руси (1243-1480) В этот период времени, когда татары собирали дань, и забирали (Русских) мужчин и молодых людей в свою армию, мужики прятались в русской печи. Татары приходя за данью, спрашивали- мужики есть? получив ответ НЕТ, они открывали печь (зная про хитрость) и зазывая из печи чумазого сажей русского мужика "ЧУРКА ВЫХОДИ" И так продолжался 237 лет (почти десятки поколений) и это выражение ЧУРКА "чумазый сажей (ЧЕРНЫЙ) и из печки остался в сознании Русского народа.
Мимоариец
Неучь как раз ты. Начитался в тырнете разного)))
До принятия христианства русские были язычниками и верили в нескольких богов. Так был бог ЧУР – оберегатель, хранитель границ. Русские делали деревянные истуканы с изображением бога ЧУРа и вкапывали их в качестве пограничных столбов. И когда кочевники во время набегов на русских видели эти столбы и зная о имени бога ЧУРа, стали называть тех, кто живет за этими столбами ЧУРками. Вот так и появилось это слово. Кочевники уже и позабыли, что когда-то называли русских ЧУРками, но русские помнили, как их называли, и на манер "сам дурак" всех неруских чурками стали обзывать. Вот так вот мои маленькие русские друзья, знайте этимологию этого слова!
P.S. Русские до сих пор говорят, когда случается что-то страшное "Чур меня", что означает "Убереги меня ЧУР".

анон, можешь переделать скрипт app.py чтобы он сохранял в папке temp озвученные файлы не как gradio/рандомназваниепапки/output.mp3, а рандомное gradio/рандомназваниефайла.mp3, чтобы видеть все файлы в 1 папке, а не блять по 1 файлу в тонне папок, я пытался переделать то что на пике, но пиздец обосрался, не получается, нет знаний работы с глобальными переменными типа __file__
когда были ЧУРы на Русь не набегали. Это после крещение стали набегать. Когда русских дурили в храмах!

Сап аноны.
Можно ли перетренить модель в so-vits-svc-fork? Я пока не спешу и включаю обучение на несколько часиков каждый день. Так может и до бесконечности продолжаться. Не будет ли хуже от этого, или в определенный момент модель просто не будет меняться т.к. "научится всему" образно говоря и дальше уже не будет развиваться?
Или тут может быть ситуация, что модель будет становиться хуже если передержать?
Ещё вопрос, просто давно не заходил к вам, появилось ли что-нибудь новенькое и более продвинутое в области копирования голоса в попенсорсе? Вроде SVC\RVC, а то всё-таки с русской речью эта модель не очень справляется сколько её не мучай - фонемы другие.
Можно ли перетренить модель в so-vits-svc-fork? Я пока не спешу и включаю обучение на несколько часиков каждый день. Так может и до бесконечности продолжаться. Не будет ли хуже от этого, или в определенный момент модель просто не будет меняться т.к. "научится всему" образно говоря и дальше уже не будет развиваться?
Или тут может быть ситуация, что модель будет становиться хуже если передержать?
Ещё вопрос, просто давно не заходил к вам, появилось ли что-нибудь новенькое и более продвинутое в области копирования голоса в попенсорсе? Вроде SVC\RVC, а то всё-таки с русской речью эта модель не очень справляется сколько её не мучай - фонемы другие.
а нафига те вообще сохранять в папки? Там есть кнопка скачать. Жмешь и скачиваешь куда надо
Сцдя по твоему скрину файл сохраняется не в этом куске кода, а в классе comunicate, в методе save.
В куске кода со скрина только проверяется наличие файла, чтобы ссылочку отобразить. А в методе clearSpeech файл удаляется.
Что думаешь, после крещения не было тех, кто остался язычником? А кто по твоему в Сибирь откочевывал, воюя там с местными?
вот код кста https://github.com/hinaichigo-fox/rus-edge-tts-webui/blob/main/app.py
бля походу сохранение происходит гдето в кишках модуля gradio, короче хуй найти
анон, надо, было бы заебись если вообще можно было указать папку куда сохранять все результаты

я те по секрету скажу, но выходной файл появляется в папке нейросети.... Вон от. оутпут мп3

аноны, объясните зачем нужно указывать файл .index? мне показалось что без него нет разницы, он обязательно нужен?
и какие настройки кроме тона от -12 до +12 можно покрутить? я просто нихуя не понимаю что делают остальные крутилки в rvc
и какие настройки кроме тона от -12 до +12 можно покрутить? я просто нихуя не понимаю что делают остальные крутилки в rvc
там только последний файл, а хочется все, которые в папке gradio появляются в рандомпапках
а че там появляется? Покажи

типа того, в каждой папке 1 файл output.mp3, а хочется чтобы вместо папок сами файлы были с этим рандомназванием
дружище. это кэщ. Его переодически чистить надо если он сам не очищается.....
вот я хочу чтобы этот кеш не выводился по 1 файлу в папке, а чтобы все сгенерированные мной файлы были в 1 папке, чтобы видеть их размер и продолжительность, кстати почему он сам не чистится, это же пиздец засрать диск можно
>вот я хочу чтобы этот кеш не выводился по 1 файлу в папке,
иди к создателям градио. пусть кэш переделывают
Похоже скрипт просто затирает файл оутпут. не влезая в подкапот можно просто на выходе каждый раз результат переименовывать. Без лишних импортов и нарушений скрипта, встроенными средствами питона это может выглядеть вот так.
Учти, я просто мимокрок и тот скрипт который ты используешь в глаза не видел, так что если что-то не заработает сам уже ковыряй.
Строка 38
if (os.path.exists(audio_file)):
....return audio_file
Замени на
if (os.path.exists(audio_file)):
....new_name, pe, i = audio_file, audio_file.rsplit(".",1), 2
....while os.path.exists(new_name):
........print('in loop')
........new_name, i = f"{pe[0]}_{i}.{pe[1]}", i+1
....if i != 2:
........os.rename(audio_file, new_name)
........audio_file = new_name
....return audio_file
>........print('in loop')
Это можно удалить
у rvc кстати с этим нормально, он сохраняет просто в папку temp с рандомназванием
да оно похоже так и есть, но они охуели дополнительно срать в папку temp, зачем это делать если просто заменяют файл в папке с нейронкой, с твоим вариантом получается срать будет и в temp и в саму нейронку
это ж каким нужно быть чтобы жаловаться на кэш? Эта папка удалится в худшем случае через неделю лол. А в лучшем случае после перезапуска пк..
Ну а как ты хотел? Лезть в подкапот и искать где там насрано никто не будет. Удаляй временные файлы сам.
И вообще наверняка этого требует технический процесс и где-то в дебрях скрипта есть функция удаления кэша, которая отключена в релизе, потому что по какой-то причине комьюнити решило кэш оставлять. Такой софт не школьники пишут а студенты, которые прекрасно ЗНАЮТ что делаю. Не зная что ты делаешь и для чего ты ничего и не напишешь тащемта.
На сивитае дохуя анимаций вижу. На чем их делают?
а как ты склонировал голос Лукашенко в ElevenLabs?
разве они не требуют подтверждения, что это реально твой голос?

>разве они не требуют подтверждения, что это реально твой голос?
Требуют, но подтверждение нужно тому, что ты не будешь использовать функцию клонирования голоса в злоумышленных целях.
Ну я и подтвердил. Больше ничего не нужно.

анон скачал rus-silero-webui, в папке с питоном создал виртуальную среду, закинул туда содержимое гитхаба, запустил пип инстал requirements, запускаю app_aud.py, открываю выданный айпи, ввожу текст, жму генерация а мне выводит эрор, а в сосноли пишет то что на пике, как лечить? на всякий скопировал папку силеро в виртуальную среду к другим файлам, закинул туда файл hubconf и отредактировал его как в примере, не помогло, нихуя не озвучивает

ах да скачал ffmpeg-master-latest-win64-gpl отсюда https://github.com/BtbN/FFmpeg-Builds/releases и скипировал 3 файла с пика и указал в path пусть до этой папки

>скопировал папку силеро в виртуальную среду к другим файлам, закинул туда файл hubconf и отредактировал его как в примере, не помогло
а блин. Так. Попробуй еще раз запустить.
Бля, натренируйте Сюткина гайз. Почему ББПЕ никто не сделал с ним?
Я так понимаю сейчас это сделать бесплатно невозможно? Только платно, а заплатить из РФ нельзя
я конечо это делал, не помогает, уже ffmpeg скорировал во все папки и папку selero, нихуя, никак не подцепляется
хмммм. щас разберемся
питон 3.10?
поставил эту силеру https://github.com/GhostNaN/silero-webui тоже самое
у тебя кодеки установлены?

были, обновил сейчас на эти https://codecguide.com/download_k-lite_codec_pack_full.htm не помогло
скинь полный текст ошибки. Просто из консоли скопируй
Running on local URL: http://127.0.0.1:7860
To create a public link, set `share=True` in `launch()`.
[nltk_data] Downloading package punkt to C:\Python\silero...
[nltk_data] Package punkt is already up-to-date!
Using cache found in C:\Users\2ch/.cache\torch\hub\snakers4_silero-models_master
Traceback (most recent call last):
File "C:\Python\silero\lib\site-packages\gradio\queueing.py", line 407, in call_prediction
output = await route_utils.call_process_api(
File "C:\Python\silero\lib\site-packages\gradio\route_utils.py", line 226, in call_process_api
output = await app.get_blocks().process_api(
File "C:\Python\silero\lib\site-packages\gradio\blocks.py", line 1550, in process_api
result = await self.call_function(
File "C:\Python\silero\lib\site-packages\gradio\blocks.py", line 1185, in call_function
prediction = await anyio.to_thread.run_sync(
File "C:\Python\silero\lib\site-packages\anyio\to_thread.py", line 33, in run_sync
return await get_asynclib().run_sync_in_worker_thread(
File "C:\Python\silero\lib\site-packages\anyio\_backends\_asyncio.py", line 877, in run_sync_in_worker_thread
return await future
File "C:\Python\silero\lib\site-packages\anyio\_backends\_asyncio.py", line 807, in run
result = context.run(func, args)
File "C:\Python\silero\lib\site-packages\gradio\utils.py", line 661, in wrapper
response = f(args, kwargs)
File "C:\Python\silero\app_aud.py", line 79, in generate
torchaudio.save(output_file, audio, params['sample_rate'])
File "C:\Python\silero\lib\site-packages\torchaudio\_backend\utils.py", line 287, in save
backend = dispatcher(uri, format, backend)
File "C:\Python\silero\lib\site-packages\torchaudio\_backend\utils.py", line 220, in dispatcher
raise RuntimeError(f"Couldn't find appropriate backend to handle uri {uri} and format {format}.")
RuntimeError: Couldn't find appropriate backend to handle uri output.wav and format None.
Это просто при запуске?
попробуй кэш очистить

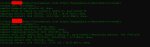
нет при запуске только Running on local URL: http://127.0.0.1:7860, а когда пишу текст и нажимаю генерировать - снизу пишет эрор с 1 пика, а в консоли эту хуйню
кеш это папка темп? чистил, сейчас удалил папку .cache и запустил, появилось чтото новое но тоже не завелось, пик 2
C:\Python\silero\lib\site-packages\torch\hub.py:294: UserWarning: You are about to download and run code from an untrusted repository. In a future release, this won't be allowed. To add the repository to your trusted list, change the command to {calling_fn}(..., trust_repo=False) and a command prompt will appear asking for an explicit confirmation of trust, or load(..., trust_repo=True), which will assume that the prompt is to be answered with 'yes'. You can also use load(..., trust_repo='check') which will only prompt for confirmation if the repo is not already trusted. This will eventually be the default behaviour
warnings.warn(
а нук попробуй закинуть любой файл .wav с названием output в папку с проектом
тоже самое
тогда хз. гугли по ошибке
а я правильно установил? мой порядок действий - из папки питона запустил cmd, создал окружение python - m venv silero, скачал https://github.com/hinaichigo-fox/rus-silero-webui/archive/refs/heads/main.zip и распоковал в папку silero, перейдя к ней через cd silero сделал активацию среды scripts\activate и запустил pip install -r requirements.txt, потом скачал https://github.com/BtbN/FFmpeg-Builds/releases/download/latest/ffmpeg-master-latest-win64-gpl-shared.zip распоковал в папку ffmpeg 3 файла из папки bin и указал путь в ней в path, потом в консоли прописал python app_aud.py, и вот тут начинает проблема, пишу русский текст и жму сгенерировать и вылетает error а в консоли это дерьмо
ааааа. Ты не так сделал все.


анон, вот такую хуйню выдало при установке pip install fairseq нужной для работы проекта, какую из хуйнь качать отсюда? https://visualstudio.microsoft.com/ru/vs/older-downloads/
я скачал Microsoft Build Tools 2015 в самом конце, при запуске меня просит выбрать что установить со 2 пика, что выбирать? пиздец, какого хуя вообще для установки модуля для работы нейронки нужно устанавливать хуйню занимающую 3гб места с отключенными всеми компонентами, пиздец
я скачал Microsoft Build Tools 2015 в самом конце, при запуске меня просит выбрать что установить со 2 пика, что выбирать? пиздец, какого хуя вообще для установки модуля для работы нейронки нужно устанавливать хуйню занимающую 3гб места с отключенными всеми компонентами, пиздец
Короче. Сначала скачиваешь проект. Распаковываешь его, потом переходишь в папку эту и создаешь окружение. Активируешь и запускаешь пип инсталл. Так должно сработать

блять, это говно без VPN даже не качается, заебись
пипец. Качал в августе норм все было
не понимаю разницы, edge-tts работал и по моему способу установки, а в самом проекте как назвать папку виртуальной среды в таком случае? venv? я думал виртуальная среда и должна содержать файлы проекта, а не проект содержать папку с виртуальной средой
виртуальная среда это папка венв и проект. Они должны находится в одной общей папке
как я и думал это не помогло анон, ладно хуй с ним, а что есть кроме edge и silero? edge слишком деревянный, silero сам понимаешь
Обидно что не помогло. Ну смотри. Едж ттс после обработки в rvc нормальный. А так ттс больше не знаю
ладно спасибо анон, может кто-то подскажет что-то подобное
в гитхабе набери tts
Ну кидайте свои озвучки! Я что на тред подписался чтобы на ваши черные скриншоты смотреть?
https://huggingface.co/NeuroSenko/rvc-models/tree/main
https://huggingface.co/NeuroSenko/svc-models/tree/main
Буду вынужден выпилить эти репы через сутки по определённым обстоятельствам. За это время можете скачать с хг, если кому надо.
Модели всё ещё можно будет скачать в боте телеги: https://t.me/AINetSD_bot
https://huggingface.co/NeuroSenko/svc-models/tree/main
Буду вынужден выпилить эти репы через сутки по определённым обстоятельствам. За это время можете скачать с хг, если кому надо.
Модели всё ещё можно будет скачать в боте телеги: https://t.me/AINetSD_bot
можно ли как нить их перенести на свой хг?
Все. Скачал
>Буду вынужден выпилить эти репы через сутки по определённым обстоятельствам
За модель гитлера посадить хотят?
За Зеленского
одно и тоже
потом вернешь же?
Нет, дело в копирайте. По сути, от меня требуют следующее:
1. У всех публичных моделей должны быть проставлены ссылки на их оригинальный хг-репозиторий (так что можно будет проследить авторство)
2. В репе не должно быть приватных моделей, которые продают на бусти и т.п.
Сама репа, по факту, должна быть пустым каталогом русскоязычных моделей. В rvc-репе суммарно 200+ моделей, так что провести такое займёт много времени.
Предъяву мне выкатили русскоязычные мочухи AI Hub'а (он недавно снова ожил), которые сами пытаются заработать на продаже своих моделей. Немного подумав, я решил, что мне нет смысла цепляться за эту репу, поскольку эти модели, в настоящий момент, и так доступны публично, просто чуть менее удобно.
https://github.com/MaHivka/ultimate-voice-models-FAQ/wiki
Кроме того, они пилят русскоязычный справочник по голосовым моделям, поэтому у меня нет желания идти на конфликт, т.к. на русском языке инфы очень мало и я ценю их вклад, хотя сама концепция "платных" моделей для меня какой-то сюр. Иди попробуй чекпоинты с лорами для SD/ламы продавать - тебя только на смех поднимут. Сам факт наличия огромной бесплатной базы моделей и лор для того же SD - это один из основных факторов, почему SD 1.5 ещё может потягаться с DALLE 3, несмотря на своё техническое отставание. Если бы в SD-комьюнити сложилась подобная традиция создания платных чекпоинтов/лор (просто представьте, что у вас нет ничего, кроме базовых SD1.5/2/XL и NAI), то он был бы никому не интересен и все пошли бы сдаваться в рабство облачных решений в виде Midjourney/DALLE.
Кроме того, на площадках рода YouTube/Pixiv/DeviantArt сложилась традиция дискриминации AI-generated контента - на нём либо прямо запрещено зарабатывать (YouTube), либо его показ режется алгоритмами (DA/Pixiv). Понятное дело, что, в подобной ситуации, есть и вина самого AI-комьюнити, а именно тех, кто бездумно дампал условный DeviantArt тысячами однотипных картинок. Я клоню к тому, что AI-модели, в настоящий момент, не являются средствами заработка, и, поэтому, надо искать очень странных людей, которые будут выкладывать свои кровные, просто что бы делать переозвучку мемчиков/песенок, на которых нельзя заработать. Особенно если мы говорим про страны пост-СНГ, где за десятилетия отсутствия доступного простым людям платного контента сложилась традиция пиратства, что снова обострилось после начала сами знаете каких событий.
Нет, я, конечно, могу устроить клоунаду в репе на хг, когда прилетит жалоба, заставляя их как-то пруфать авторство моделей. Можно поступить в стиле Хачатура - поменять веса моделей на уровне погрешности и выложить под видом своих моделей. Как ультимативное решение, я мог бы просто арендовать сидбокс и выложить магнет-ссылку на торрент.
Но есть причины, по которым я не хочу так поступать:
Во-первых, модели всё ещё будут доступны публично через тг, так что смысла устраивать драку за зеркало не вижу.
Во-вторых, русскоязычное комьюнити по звуковым моделям и так довольно слабое, не хочу в открытую противостоять тем, кто что-то пытается сделать.
В третьих, то, что попало в интернет, остаётся там навсегда. Попытки нападок на держателей зеркал приведут лишь к тому, что зеркал станет ещё больше. Эффект Стрейзанд никто не отменял.
Насчёт срача - возможно стоило бы немного повонять, может быть это привлекло немного внимания к ру комьюнити с последующим вкатом мимокроков. Как я замети, даже после мизерного инфоповода залетают по паре человек в этот мёртвый тред на мёртвой доске.
Но как знаешь. В последнее время и так говна расплодилось что-бы ещё самому набрасывать...
Не, твоё право конечно, но пидоров с идеями брать за что-то там деньги нужно давить как гнойные прыщи.
Пиздец пориджи пошли, без гуя в браузере уже репу залить не могут.
>Можно поступить в стиле Хачатура - поменять веса моделей на уровне погрешности и выложить под видом своих моделей.
Лол, такой рофл я пропустил. Есть ссылки с инфой?
> Пиздец пориджи пошли, без гуя в браузере уже репу залить не могут.
Покажи мне как форкнуть репу с LFS при помощи git не скачивая несколько стотен гигабайт моделей.
>не скачивая несколько стотен гигабайт моделей.
А может обойдёмся без камазов под водой? Берёшь и качаешь. Иначе зачем оптику в квартиру проводить?
Да и там всего лишь гиг 50 в сумме.
57,7ГБ
Кто свои модели делал, подскажите сколько по времени занимает и сколько эпох надо?
У меня дохуя материала для обучения, пробовал по разному:
1. Разбил 8 чаасовую запись на 8 штук по часу - понял что хуйня
2. Взял часовую, её наслайсил на 3000 кусков, понял что тоже хуйня
3. В итоге сейчас взял 20 минут, насэмплил через саму сетку и сижу жду обучения.
Но тоже думаю будет полная хуйня и занимает это 5+ часов.
У меня дохуя материала для обучения, пробовал по разному:
1. Разбил 8 чаасовую запись на 8 штук по часу - понял что хуйня
2. Взял часовую, её наслайсил на 3000 кусков, понял что тоже хуйня
3. В итоге сейчас взял 20 минут, насэмплил через саму сетку и сижу жду обучения.
Но тоже думаю будет полная хуйня и занимает это 5+ часов.
8 часов записи чистого голоса?????
Да это ж офигенная модель будет. Берешь и режешь на записи по 10 сек(в тырнетах полно прог для этого на питоне) Потом это все закидываешь в рвс. Ну тут в зависимости от карточки. Если карточка норм то быстро часа 3-4 будет. Эпох ставь 200-250.
да я бы не против, но у меня 1660Ti и как я уже говорил даже 400 сэмплов по 10 секунд у меня одна эпоха занимает 4-6 минут, получается в час штук 10. Чтобы сделать 200-250 эпох - придётся сутки обучать.
На время так то похуй, но во время обучения ПК становится почти кирпичом, игори на фоне не поиграть, ютубы и твичи в фулхд тоже начинают через пол часа- час тормозить
Меня инетерсут это адекватное время для обучения или нет?
Тренируй в каггле. Там все можно фоном. Если твоя карта меньше 2060 то лучше не браться за обучение локально. https://www.kaggle.com/varaslaw/rvc-tg-aisingers-by-rus-no-gradio тут делать
https://youtu.be/uA92FDw_Xfw тут обучалка
ебанул 2 часа речи (1300 сэмплов) на 500 эпох, посмотрим как быстро закончит и что на выходе будет
сам давно пробовал по этому гайду?
у меня за 20 минут 500 эпох пролетает, но в папке аутпут ничего нет, в комментах на ютубе так же пишут, похоже на сегодняшний день не работает

https://docs.aihub.wtf/guide-to-create-a-model/tensorboard-rvc
У AI Hub'а есть статьи по обучению, в них советуют по тензорборду оверфит отслеживать. График лосса должен дойти до минимума и дальше будет болтаться на месте. В этот момент и начинается оверфит, если им верить.
у меня тенсор по вертикальной оси не показывал значения, только количество шагов на горизонтальной
вроде видел как зафиксить, но не накатыва
пробовал. И 3 модели сделал. Все на высоком уровне
я те скажу. 1 минута на эпоху это уже пипец
Может я че то не так делаю просто?
У меня есть голос на 8 часов. Я его вручную порезал на 8 кусков по одному часу. Сохранил в wav. Через svc (когда он у меня был) я его насемплил на дохуя мелких кусков, порядка 5 тысяч. Каждый кусок 3-10 секунд и там чистый голос. Всё это в формате wav. Как бы с этим и работаю.
Последний раз оставил 1000 сэмплов и этот архив на https://www.kaggle.com/varaslaw/rvc-tg-aisingers-by-rus-no-gradio загнал.
Только я потом заметил что у этого чела из гайда выбирается акселиратор - для этого надо телефон подтвердить.
В остальном у меня всё так же как у него.
Ну и когда 500 эпох проходят - в разделе аутпут у меня только одна папка, в ней пара других но кроме 2 файлов 0Кб ничего в них нет.
а в чем проблема телефон подтвердить? Я не парился и подтвердил своим. Все работает
500 эпох для 8 часов это дофига. ставь 200-250
только что подтвердил через сервис на тайландский номер, рашку нельзя. да я заметил что у него есть выбор ГПУ, а у меня нет. но в этом гайде он про это не говорит, случайно наткнулся на ютубе на другой его видос, где он показывает как регаться на каггле и там как раз было про верификацию телефона. сейчас еще раз запустил трейн
рашку нельзя? Я своим подтвердил лол.

1300 сэмплов почти на час закинул на 500 эпох
какой же уродский лог, как будто ничего не работает

может у каких то операторов пропускает. я заплатил за это 3 рубля 90 копеек
оно не завершило работу лол
когда вместо ранинг будет написано сексесфулл тогда и смотри файлы


гайд смотреть внимательней надо. Логи и не будут двигаться. там все по тихому. Эпохи не отображаются. Завтра приходи на сайт и там будет уже все завершено


лол, внатуре из-за отустствия гпу не обучалось
вытаскивай по гайду.

но нету индекс файла, который начинается с "added", а сами модели в weights есть. он кажись не не нужен, rvc без него модель скушала и даже высрала что-то. короче работает, разобрался. пойду все 8 часов заебашу, лол
так. Там смотри. В файлы переходишь(в меню сверху) и там жмешь лоад мор. Будет папка нужная

не, по папкам всё ок но вот этого файла как в гайде я не нашёл. сразу взял модели из weights - локально прогнал, вроде работают. я хз зачем этот файл .index нужен
лучше скачай и закинь куда надо.
файл нужен чтоб настраивать акцент
да я бы рад, но его нету.
Короче запустил на 2000 эпочей с шагом сохранения 200 сэмплов на 2 часа (вышло 3000 штук).
Так вопрос, а если хуевая модель получится - че делать? Поиграть длиной семплов или что можно сделать?
какие 2000 эпох????? Тут не работает чем больше тем лучше. Чем больше тем лучше это про количество аудио. Грузи 5 часов и ставь 200 эпох. лучше всего будет
Я так понял просто скачал/онлайн ввел текст и получил норм записи сейчас нет? По крайней мере бесплатно нет?
да

чет нихуя не понимаю, скачал для проверки какую то анимешную модель, прогнал через неё тестовый сэмпл, нихуя не поменялось.
ЧЯДНТ?
ЧЯДНТ?
питч поставь на 12
да, просто перезапустил - вроде сработало
Для инфы:
В RVC v2 NO GRADIO сэмплы общей длительностью 2 часа выполнились на 125 эпох, дальше отключилось, т.к. лимит по времени 12 часов (43200 секунд).
Если там линейная зависимость, получается максимум можно 50-60 минут пронать на 200-250 эпох
В RVC v2 NO GRADIO сэмплы общей длительностью 2 часа выполнились на 125 эпох, дальше отключилось, т.к. лимит по времени 12 часов (43200 секунд).
Если там линейная зависимость, получается максимум можно 50-60 минут пронать на 200-250 эпох
UPD оказалось это не так, похоже овердохуя файлов в любом случае отваливаются по лимтиу. Закинул 1000 сэмплов на 650 эпох - обработалось за 15 минут.
upd2 оказалось всё хуйня - просто ебучий каггле завис у меня на 12 часов.
Если он через 20 минут не выдаёт 200 эпох - надо перезапускать проект
Чет бухтите что-то, а песенки забавные перестали выкладывать, а прошлых тредах так классно было, что случилось?
скиньте отделенные воис и инструментал какой нибудь, на котором нормально получаются каверы.
сделал свою модель, но какой-то всратый звук получается, как у робота.
хочу на нормальных записях проверить.
сделал свою модель, но какой-то всратый звук получается, как у робота.
хочу на нормальных записях проверить.
Всем привте, тоько залетел, один вопрос - может доставить кто модель Бориса Репертура? Кто-тож уж точно должен был сделать, с меня как обычно

а все ненад, почитал шапку и нашол
Хотел уже я написать, пока нашел чето в шапке, а там блять, мудак какой-то шутканул, вот и че это?
Короче вопрос актуален.

впервые вижу ваще такую шнягу, погуглил метод, понял что это сдеано было при помощи py7zr, нет, это не дает возможности им открыть архива, но если типа захотите такую же хуйню забабахать то вы пидор
Короче я понял примерно че там не работает, осталось понять как фиксить.
У меня G_.pth файлы с конфигом в жсоне нормально работают, а .pth (без конфига, как этот например) дают мегадлинную ошибку где последние строчки такие:
"C:\Users\user_name\AppData\Local\Programs\Python\Python310\lib\concurrent\futures\_base.py",
line 403, in __get_result
raise self._exception
PermissionError: [Errno 13] Permission denied: '.'
Как фиксить?
баляя, полуркал, это оказуется для другой проги, то есть для so-vits-svc-fork не работает большая часть из шапки в том числе та, с Репертуром :с , ну, попробую чето еще, но походу придется свою делать блин...
Баляяя, в телеге тоже один файл и он, удивительно, не работает.
Короче нашел на данный момент 2 модели и все, сука. одним pth файлом.
1.
2. С бота с телеги
траль-пидарас-уебок-мать-его-ебал не считается
Выручайте, котаны
Ты бы сразу уточнил, что на SVC модель ищешь. Для неё модели несовместимы с моделями для RVC.
Вообще советую сразу RVC поставить, SVC со второй половины лета уже мало кто использует и моделей для RVC на порядок больше.
А нахуя кстати нужны D_ и G_ файлы?
G_*.pth это типа формат для одной проги конкретной другой формат короче я сам хуй знает D_ тоже хуй знает че реально
Бля ок сяп учту
Да как нормально натренить модель. Я уже заебался, у меня безлимитное количество записей для тренировки, но что бы я не делал - выходит хуйня.
И 10 минут закидывал без сэмплов и с сэмплами
И 2 часа без сэмплов и с сэмплами
И в wav и в мп3
И 1000 и 200 эпох
Всегда одинаково выходит - хуйня 3/10 качество.
Может датасет сперва как то обработать?
И 10 минут закидывал без сэмплов и с сэмплами
И 2 часа без сэмплов и с сэмплами
И в wav и в мп3
И 1000 и 200 эпох
Всегда одинаково выходит - хуйня 3/10 качество.
Может датасет сперва как то обработать?
Качество датасета важнее длительности. Сами разрабы RVC говорят, что хватит датасета длительностью менее 10 минут голоса в разных диапазонах.
Если используешь UVR, то выбери нормальные модели, а не те, что идут в комплекте. Самая пиздатая это похоже MDX23C-InstVoc HQ, но она очень медленно работает и сильно грузит GPU. После неё мне больше всего нравится htdemucs_ft, но она более агрессивно режет эхо, судя по моим небольшим тестам. Хотя может это и плюс.
Если на датасете есть монотонные шумы, можешь их выпилить через Audacity: https://blog.selfpub.ru/not-noise-with-audacity
Здравствуйте аноны. С помощью какой локально нейронки можно сделать звуковую дорожку для видео без звука? Я слышал такое существует, но не понятно локально ли это
Ну я так понимаю порядок такой:
1. Через UVR выдернуть и почистить голос
2. Через RVС засэмплить его, тут же тишина удалится
3. Обучать на сэмплах.
Формат файла как-то влияет? И можно ли в каггле дообучать имеющуся модель?
> песенки забавные
)0
Назрел вопрос, вот у меня есть модель натрененная на японском голосе, можно ли как-нибудь научить ее говорить по русски без дичайшего акцента?
SoftVC VITS Singing Voice Conversion Fork (SVC) модели этой хуиты можно заставить читать какой нибудь текст или они только для замены голоса?
Аноны, а шо за хуйня с этим llElevenLabs? Переводил короткие ролики с инглиша на русский, первые 3 заебись перевелись, все последующие просто нихера не происходит, только звук заглушается. Это мне так сообщают о том, что у меня попытки закончились чи шо

Анон, можешь посоветовать сетку, где я смогу озвучить свой текст торжественнымголосом на русском и эхом? Будто речь в огромном зале перед сотнями тысяч людей.
И ещё вопрос первая предложенная в шапке русская сетка - она как вам? Можно рассказики озвучивать? Там можно выбирать только голоса?
А если мне хочется особого голоса или атмосферы, придётся в секвенсорах играться?
И ещё вопрос первая предложенная в шапке русская сетка - она как вам? Можно рассказики озвучивать? Там можно выбирать только голоса?
А если мне хочется особого голоса или атмосферы, придётся в секвенсорах играться?
Лан, вопрос неактуальный, понял, что прост работает через жопу зачастую
что такое голосовая модель? Это просто голос. На любом языке говорит. Ей пофиг
Есть способ делать батч для еджи ТТС? В интерфейсе только вставление куска текста.
овощевоз vs. говновоз
че такое батч
Аноны я вот видел войс ченеджер на голоса известных стримеров, известных людей, название не могу найти, но он работал в реалтайме с микрофона, а есть ли какой-то софт для изменения голоса с файла? помогите пож
> SoftVC VITS Singing Voice Conversion Fork (SVC) модели этой хуиты можно заставить читать какой нибудь текст или они только для замены голоса?
Нет, придётся сначала генерить через TTS и потом прогонять через SVC или RVC. Были какие-то проекты, которые автоматизируют процесс TTS -> STS, но я их не смотрел, не могу чего-то конкретного посоветовать.
> Анон, можешь посоветовать сетку, где я смогу озвучить свой текст торжественнымголосом на русском и эхом? Будто речь в огромном зале перед сотнями тысяч людей.
Про торжественность хз, русскоязычные опенсорсные TTS довольно монотонны, а при конвертации в RVC стилистику не поменяешь. Хотя тот же EdgeTTS, на мой взгляд, звучит гораздо более пафосно, по сравнению с Silero. Если в EdgeTTS никакие голоса не не заходят, то не знаю, что предложить можно. Эхо можно через Audacity добавить с плагином
FabFilter https://rutracker.org/forum/viewtopic.php?t=6198392
RVC твой выбор. Там есть как realtime замена голоса, так и замена голоса в файле (или сразу в множестве файлов).
Насчет дичайшего не знаю, но акцент всё равно будет, звуки различаются. То же самое "р", "ш" и т.д.
бамп
Олсо, а этот пак записей голоса подойдет для обучения голоса?
https://nnmclub.to/forum/viewtopic.php?t=154903
Голос брутальный альфачовский


Хочу сделать оффлайн windows приложуху с качественным (относительно майкрософтной говорилки) tts синтеза для курсача.
Какие есть открытые для скачивания ai-модели? Может не такие крутые как в шапке, но хотя бы быстрые
Какие есть открытые для скачивания ai-модели? Может не такие крутые как в шапке, но хотя бы быстрые

Помогите найти голосовую модель для so-vits-svc Путина
Звуковую дорожку для видео без звука, чиво? Картинки в (слушабельный) звук еще пока вроде даже без нейронок не научились превращать, мне кажется ты хочешь сделать озвучку сам записать и потом прогнать под желаемый голос.
RVC лучше и на каждом углу
Куда вы все эти модели устанавливаете?
Софт есть какой то или только сайты?
Софт есть какой то или только сайты?
RVC для нейрокаверов и преобразования голоса локально ставится, глянь ссылки в шапке.
TTS из шапки и отсюда тоже локально ставится при желании.
Умерла девушка, сколько нужно записей что бы синтезировать голос?
Помогите, не хочу сам искать
От пяти минут до одного часа для обучения RVC модели. Опытные челы писали, что лучшим датасетом будет датасет небольшой длины (~10 минут), но что бы голос в нём был представлен в разных диапазонах.
Делал из 15мин голосовых в тг, 300 эпох, после тюнинга получилось 1 в 1, звонил мамке ее, говорил ее голосом, она ничего не поняла.
Под Windows 7 есть какой то софт?

зачем мне твой сгенерированный шлак с отслеживанием мышки и отправкой скриншотов рабочего стола?
есть нормальный STS преобразователь чтобы песенки со спанчбобом делать, который будет работать на windows 7?
Нету. Только шлак, ссылка выше.
Правда? хуево вам там наверное с платными сайтиками и 2умя высерами с гитхаба написанными в глубинах тайваньских катакомб
Кому вам? На сперме осталось 1,5 аксакала, все нормальные люди на дристянке.
> все нормальные люди на
Линуксе.
есть понт обновлять rvc?
Нормальные на десятке, красноглазые на линуксе, бородатые старцы на семёрке, соевые криэйторы на макоси, зумеры на андроиде/иос - зачем этим эти ваши громоздкие ящики на столе?
Нормальные — это ретрограды-реакционеры?
Дочитать до третьего куплета было нелегко
> Нормальные на десятке
Быть кретином это не нормально, чел.
Нормальная ось это линукс, остальное от лукавого.
На мобилка андроид офкос.
Нормальная ось - Линукс.
Нормальный софт - опенсорс.
Всё остальное - от глюкавого.
https://www.youtube.com/watch?v=VF3yM7q1hJc
Аноны, хочу также свой голос заебашить, где это можно сделать?
Аноны, хочу также свой голос заебашить, где это можно сделать?
модель?
spittin' fax
блять я подумал тесак допрашивает Дмитрия Комарова
бля rvc (релиз из шапки прям) не хочет хавать мп3 56кбпс на 49 минут пмргите
>модель?
элевенпролапс даббинг с английского
Я заебался обучать модель в RVC, уже 3 недели ебусь с ней. Делал и локально и на Каггле. И дата сет брал 4 минуты и 15 и 30 и несколько часов. Сам дата сет чистил от тишин, убирал ревёрб, хотя его там нихуя нет. Пробовал и 30 эпох и 500 ( в приницпе на 40-50 уже максимальное качество получается, дальше перетрен идёт). Пробовал и продолжать тренировку. Пробовал даже выдёргивать голос через UVR, хотя в дата сете чистый голос без музыки и посторонних шумов.
Одна хуйня выходит модель, которая хуево похожа на соус. Думаю надо предварительно датасет как то отредактировать что ли хз.
Может есть кто шарит в подготовке дата сета или уже полученном на выходе файле? Искал советы по этой теме - нигде ничего нет, челы тупо берут 5 минут записи и у них нормально получается.
Одна хуйня выходит модель, которая хуево похожа на соус. Думаю надо предварительно датасет как то отредактировать что ли хз.
Может есть кто шарит в подготовке дата сета или уже полученном на выходе файле? Искал советы по этой теме - нигде ничего нет, челы тупо берут 5 минут записи и у них нормально получается.
Бля, чел, там же в названии видео и описании указано.

https://2ch-ai.gitgud.site/wiki/speech/
Всю инфу из шапки структурировал и вынес по разделам сюда. Так же добавил инфу о нескольких других TTS'ках и ещё нескольких проектах, которые не упомянуты в шапке, включая UI, которые скидывали вначале треда.
Из ссылок убрал только китайский видеогайд для MoeTTS, т.к. нашёл для него английские доки на гитхабе.
Вики хранится в виде кучи md-файлов в git-репе, которые потом проливаются на статичный сайт. Из особенностей выбранного движка вики то, что все текстовые документы с вики прогружаются в момент загрузки любой страницы. Благорадя этому, поиск работает сразу по всей вики, несмотря на отсутствие какого-либо бекенда (пик).
Вики можно форкнуть и запустить локально, при желании. Я написал небольшие скрипты, которые облегчат этот процесс на винде - вам нужно лишь стянуть проект через git и запустить нужные батники, инфа здесь:
https://2ch-ai.gitgud.site/wiki/
Из требований только наличие python + pip в системе.
Приветствуются предложения по внесению правок посредством цитирования ОП-поста и запросом изменений в треде. Так же приветствуется участие посредством отправки Pull Requests.
Текущая версия шапки и так перегружена, что до сих пор спрашивают платину - в связи с этим, хочу переработать структуру шапки таким образом, что бы на ней была ссылка на вики и небольшой FAQ с разбором платины. А всю инфу о конкретных системах упрятать в вики.
Мнение, пчелы.
Всю инфу из шапки структурировал и вынес по разделам сюда. Так же добавил инфу о нескольких других TTS'ках и ещё нескольких проектах, которые не упомянуты в шапке, включая UI, которые скидывали вначале треда.
Из ссылок убрал только китайский видеогайд для MoeTTS, т.к. нашёл для него английские доки на гитхабе.
Вики хранится в виде кучи md-файлов в git-репе, которые потом проливаются на статичный сайт. Из особенностей выбранного движка вики то, что все текстовые документы с вики прогружаются в момент загрузки любой страницы. Благорадя этому, поиск работает сразу по всей вики, несмотря на отсутствие какого-либо бекенда (пик).
Вики можно форкнуть и запустить локально, при желании. Я написал небольшие скрипты, которые облегчат этот процесс на винде - вам нужно лишь стянуть проект через git и запустить нужные батники, инфа здесь:
https://2ch-ai.gitgud.site/wiki/
Из требований только наличие python + pip в системе.
Приветствуются предложения по внесению правок посредством цитирования ОП-поста и запросом изменений в треде. Так же приветствуется участие посредством отправки Pull Requests.
Текущая версия шапки и так перегружена, что до сих пор спрашивают платину - в связи с этим, хочу переработать структуру шапки таким образом, что бы на ней была ссылка на вики и небольшой FAQ с разбором платины. А всю инфу о конкретных системах упрятать в вики.
Мнение, пчелы.
Так там платно, не охота платить деньгу за это.
> Всю инфу из шапки структурировал и вынес по разделам сюда.
Охуенно структурировал, прямо нравится.
> небольшой FAQ с разбором платины
Вот да, этого конечно действительно не хватает. Просто во всей этой инфе платиновый пайплайн ну для тех же нейрокаверов на песенки как то затерялся кмк.
Я бы ещё добавил теги:
портабл
работает в облаке
только локально (ручная установка с гита)

Привет аноны.
Я один из тех людей, которые внезапно возгораются энтузиазмом что-то делать, а потом энтузиазм спадает на неопределённый срок. Но пока волна энтузиазма есть, прёт энергия и можно свернуть горы.
Сейчас меня нахлынула такая волна, когда наткнулся на нейронный кавер на ДДТ голосом НекоАрк.
И хочу я перезаписать нейронную кавер-версию %песня-нейм% в исполнении %группа-нейм% так, чтобы голосом %группа-нейм% поверх минуса %песня-нейм% в мотив оригинальной %песни-нейм% другой текст, похожий интонационно и по рифмам
Вопросы от меня интеллекту тотального нуба в теме нейронок:
1) Эти ваши сети онлайн в бравузере или нужно будет что-то качать?
2) Там как двач - ввёл капчу и вперёд, или там анальный цирк с кармой, СМС и регистрацией
3) Правильно ли я понимаю, мне нужно сперва скормить оригинальную кучу песен %группа-нейм%, чтобы нейронка переняла интонации, затем скормить именно нужную мне песню несколько раз (разные студийки и лайвы), а потом как-то подключить текстовую нейронку к музыкальной, чтобы написанный мной текст нейронка наложила на минус %песня-нейм%, и только тогда я смогу получть в одной из сотен генераций песню, в которой поверх минуса/инструментальной версии %песня-нейм% будет наложен найросеточный голос, имитирующий голос, интонации и манеру исполнения оригинального исполнителя но с моим текстом?
Типа как в видриле Путину наложили арабскую речь изначально написанным текстом https://www.youtube.com/watch?v=kY6s1RRdktY
Какой в пизду обход бана? Я первый раз в разделе
Я один из тех людей, которые внезапно возгораются энтузиазмом что-то делать, а потом энтузиазм спадает на неопределённый срок. Но пока волна энтузиазма есть, прёт энергия и можно свернуть горы.
Сейчас меня нахлынула такая волна, когда наткнулся на нейронный кавер на ДДТ голосом НекоАрк.
И хочу я перезаписать нейронную кавер-версию %песня-нейм% в исполнении %группа-нейм% так, чтобы голосом %группа-нейм% поверх минуса %песня-нейм% в мотив оригинальной %песни-нейм% другой текст, похожий интонационно и по рифмам
Вопросы от меня интеллекту тотального нуба в теме нейронок:
1) Эти ваши сети онлайн в бравузере или нужно будет что-то качать?
2) Там как двач - ввёл капчу и вперёд, или там анальный цирк с кармой, СМС и регистрацией
3) Правильно ли я понимаю, мне нужно сперва скормить оригинальную кучу песен %группа-нейм%, чтобы нейронка переняла интонации, затем скормить именно нужную мне песню несколько раз (разные студийки и лайвы), а потом как-то подключить текстовую нейронку к музыкальной, чтобы написанный мной текст нейронка наложила на минус %песня-нейм%, и только тогда я смогу получть в одной из сотен генераций песню, в которой поверх минуса/инструментальной версии %песня-нейм% будет наложен найросеточный голос, имитирующий голос, интонации и манеру исполнения оригинального исполнителя но с моим текстом?
Типа как в видриле Путину наложили арабскую речь изначально написанным текстом https://www.youtube.com/watch?v=kY6s1RRdktY
Какой в пизду обход бана? Я первый раз в разделе
Что качать стейбл дифижн скачал
Я слушаю ваши нейронки на Ютубе, но мне этого нехватает
эт называется мэшап. Выходит нейромэшап

>эт называется мэшап. Выходит нейромэшап
Ну что ж, с терминами мы разобрались.
Это хорошо.
Теперь вопросы по существу:
1) Эти ваши мешап-мейкеры онлайн в бравузере или нужно будет что-то качать?
2) Там как двач - ввёл капчу и вперёд, или там анальный цирк с кармой, СМС и регистрацией?
3) 2) Там как двач - ввёл капчу и вперёд, или там анальный цирк с кармой, СМС и регистрацией....
и т.д.
В чём делать, короче, и как?
1. Берёшь голос/вокал будущего исполнителя. Если нету нормальной дорожки с голосом, то делаешь с трека через Ultimate Vocal Remover (разделяет музыку и голос).
2. Чистишь от тишины, шумов (ну или не чисти, при тренеровке само подчистится, но может хуево). Этот чистый голос называется датасет
3. Обучаешь модель под этот голос. Для этого качаешь Mangio-RVC или идёшь сюда https://www.kaggle.com/code/varaslaw/rvc-v2-no-gradio-https-t-me-aisingers-ru (загугли телегу его, там есть гайд).
4. Кормишь свой дата сет. Обучаешь до 100-150 эпох, с сохраненим каждой 10-20. На выходе получаешь разной степени обученности модели. Они могут "перетренироваться", поэтому надо будет потестить какая лучше
5. Потом делаешь то же самое что в п.1 но с целевой песней, которую будут перепевать. У тебя получится несколько файлов, один с вокалом, остальные (или 1) с музыкой.
6. Берёшь вокал из п.5 и накладываешь на него модель из п4. На выходе получаешь перепетый голос.
7. Склеиваешь это в аудио редакторе по дорожкам с музыкой из п.4.
Но у меня говно получается, 3 недели ебался, так и не сделал нормально. Думаю надо уметь работать со звуком чтобы все это подправлять и выравнитьвать
мимо
> качаешь Mangio-RVC
А в чём профит по сравнению с https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI ?
Одна хуйня. То что ты скинул - это китайский первоисточник. Может там при установке все на китайском, хз. Так что ставь Мангио.
># Установка необходимых зависимостей
>!apt-get -y install build-essential python3-dev ffmpeg
Но Это Же на линукс. У меня-то шинда10
это на облаке делается
читай гайд внимательно, поди, смотришь в раздел для красноглазых. все для винды есть.
Анон, нет времени вникать во все самому, поэтому прошу у тебя помощи с такой задачей: нужно украсть голос, сделать его идентичным или хотя бы похожим на оригинал, озвучивать с ним тексты, либо в идеале изменение голоса в реальном времени, через дискорд, скайп, тг. Готов заплатить за труды.
чей голос? Сколько минут есть этого голоса. Насколько чистый
Голос знакомых, они в курсе, есть возможность записать этот голос столько, сколько нужно, ну и под определенные требования.
моя тг @Almironc
там голоса минимум час нужно в хорошем качестве. сможешь?
Смогу, конечно.
тогда делай. как будет напишешь
Прошлый тред: >>
Вики треда: https://2ch-ai.gitgud.site/wiki/speech/
FAQ
Q: Хочу озвучивать пасты с двача голосом Путина/Неко-Арк/и т.п.
1. Используешь любой инструмент для синтеза голоса из текста - есть локальные, есть онлайн через huggingface или в виде ботов в телеге:
https://2ch-ai.gitgud.site/wiki/speech/#синтез-голоса-из-текста-tts
Спейс без лимитов для EdgeTTS:
https://huggingface.co/spaces/NeuroSenko/rus-edge-tts-webui
Так же можно использовать проприетарный комбайн Soundworks (часть фич платная):
https://dmkilab.com/soundworks
2. Перегоняешь голос в нужный тебе через RVC. Для него есть огромное число готовых голосов, можно обучать свои модели:
https://2ch-ai.gitgud.site/wiki/speech/sts/rvc/rvc/
Q: Как делать нейрокаверы?
1. Делишь оригинальную дорожку на вокал и музыку при помощи Ultimate Vocal Remover:
https://github.com/MaHivka/ultimate-voice-models-FAQ/wiki/UVR
2. Преобразуешь дорожку с вокалом к нужному тебе голосу через RVC
3. Объединяешь дорожки при помощи Audacity или любой другой тулзы для работы с аудио
Опционально: на промежуточных этапах обрабатываешь дорожку - удаляешь шумы и прочую кривоту. Кто-то сам перепевает проблемные участки.
Качество нейрокаверов определяется в первую очередь тем, насколько качественно выйдет разделить дорожку на составляющие в виде вокальной части и инструменталки. Если в треке есть хор или беквокал, то земля пухом в попытке преобразовать это.
Нейрокаверы проще всего делаются на песни с небольшим числом инструментов - песня под соло гитару или пианино почти наверняка выйдет без серьёзных артефактов.
Q: Хочу говорить в дискорде/телеге голосом определённого персонажа.
Используй RVC (запуск через go-realtime-gui.bat) либо Voice Changer:
https://github.com/w-okada/voice-changer/blob/master/README_en.md
Гайд по Voice Changer, там же рассказывается, как настроить виртуальный микрофон:
https://github.com/MaHivka/ultimate-voice-models-FAQ/wiki/Voice‐Changer (часть ссылок похоже сдохла)
Q: Как обучить свою RVC-модель?
Гайд на русском: https://github.com/MaHivka/ultimate-voice-models-FAQ/wiki/RVC#создание-собственной-модели
Гайд на английском: https://docs.aihub.wtf/guide-to-create-a-model/model-training-rvc
Определить переобучение через TensorBoard: https://docs.aihub.wtf/guide-to-create-a-model/tensorboard-rvc
Q: Надо распознать текст с аудио/видео файла
Используй Whisper от OpenAI: https://github.com/openai/whisper
Так же есть платные решения от Сбера/Яндекса/Тинькофф.
Шаблон для переката: http://
Вики треда: https://2ch-ai.gitgud.site/wiki/speech/
FAQ
Q: Хочу озвучивать пасты с двача голосом Путина/Неко-Арк/и т.п.
1. Используешь любой инструмент для синтеза голоса из текста - есть локальные, есть онлайн через huggingface или в виде ботов в телеге:
https://2ch-ai.gitgud.site/wiki/speech/#синтез-голоса-из-текста-tts
Спейс без лимитов для EdgeTTS:
https://huggingface.co/spaces/NeuroSenko/rus-edge-tts-webui
Так же можно использовать проприетарный комбайн Soundworks (часть фич платная):
https://dmkilab.com/soundworks
2. Перегоняешь голос в нужный тебе через RVC. Для него есть огромное число готовых голосов, можно обучать свои модели:
https://2ch-ai.gitgud.site/wiki/speech/sts/rvc/rvc/
Q: Как делать нейрокаверы?
1. Делишь оригинальную дорожку на вокал и музыку при помощи Ultimate Vocal Remover:
https://github.com/MaHivka/ultimate-voice-models-FAQ/wiki/UVR
2. Преобразуешь дорожку с вокалом к нужному тебе голосу через RVC
3. Объединяешь дорожки при помощи Audacity или любой другой тулзы для работы с аудио
Опционально: на промежуточных этапах обрабатываешь дорожку - удаляешь шумы и прочую кривоту. Кто-то сам перепевает проблемные участки.
Качество нейрокаверов определяется в первую очередь тем, насколько качественно выйдет разделить дорожку на составляющие в виде вокальной части и инструменталки. Если в треке есть хор или беквокал, то земля пухом в попытке преобразовать это.
Нейрокаверы проще всего делаются на песни с небольшим числом инструментов - песня под соло гитару или пианино почти наверняка выйдет без серьёзных артефактов.
Q: Хочу говорить в дискорде/телеге голосом определённого персонажа.
Используй RVC (запуск через go-realtime-gui.bat) либо Voice Changer:
https://github.com/w-okada/voice-changer/blob/master/README_en.md
Гайд по Voice Changer, там же рассказывается, как настроить виртуальный микрофон:
https://github.com/MaHivka/ultimate-voice-models-FAQ/wiki/Voice‐Changer (часть ссылок похоже сдохла)
Q: Как обучить свою RVC-модель?
Гайд на русском: https://github.com/MaHivka/ultimate-voice-models-FAQ/wiki/RVC#создание-собственной-модели
Гайд на английском: https://docs.aihub.wtf/guide-to-create-a-model/model-training-rvc
Определить переобучение через TensorBoard: https://docs.aihub.wtf/guide-to-create-a-model/tensorboard-rvc
Q: Надо распознать текст с аудио/видео файла
Используй Whisper от OpenAI: https://github.com/openai/whisper
Так же есть платные решения от Сбера/Яндекса/Тинькофф.
Шаблон для переката: http://
Мнение по такому варианту шапки? Может ещё есть мысли, что добавить/поправить надо?
Так норм?
Хорошая идея, тоже думаю, что стоит добавить. В ближайшие пару дней сделаю.
Так норм?
Хорошая идея, тоже думаю, что стоит добавить. В ближайшие пару дней сделаю.
Бамп




Text To Speech (TTS) 📝 👉 🎤
Silero
Российская разработка, легковесный, быстрый, относительно качественный. Поддерживает много языков, включая русский.
https://github.com/snakers4/silero-models
Есть 2 GUI:
Для всех систем: https://huggingface.co/spaces/NeuroSenko/tts-silero
Для винды, более продвинутый проект формата "всё в одном" (TTS/STS/TTS), часть функционала платная: SoundWorks, https://dmkilab.com/soundworks
Официальный бот в телеге. Требуется подписка на новостной канал. На бесплатном тарифе есть лимиты на число запросов в сутки: https://t.me/silero_voice_bot
Данная нейронка не обладает высокими системными требованиями. Если хотите запустить на своём компьютере, то, придётся накачать около 5 гигов + питон + гит, но всё будет установленно в одну папку поэтому будет легко удалить если надоест. Если используете несколько нейросетей - используйте Anaconda / Miniconda!
Гайд: https://textbin.net/kfylbjdmz9
Нет возможности тренировки своих голосов, но возможно сделать генерацию с одним из имеющихся голосов, и потом преобразовать получившийся файл через STS (смотри ниже).
Elevenlabs
Онлайн-сервис синтеза и преобразования английского голоса. На бесплатном тарифе ограничения по числу символов в месяц.
Сайт: https://elevenlabs.io/speech-synthesis
Гайд по использованию и общие советы: https://rentry.org/AIVoiceStuff
VITS-Umamusume-voice-synthesizer
Только на японском, 87 голосов.
ХагингФейс: https://huggingface.co/spaces/Plachta/VITS-Umamusume-voice-synthesizer
Гугл-Калаб: https://colab.research.google.com/drive/1J2Vm5dczTF99ckyNLXV0K-hQTxLwEaj5?usp=sharing
MoeGoe и MoeTTS
Гайд на китайском: https://colab.research.google.com/drive/1HDV84t3N-yUEBXN8dDIDSv6CzEJykCLw#scrollTo=EuqAdkaS1BKl
Кажется можно тренировать свои голосовые модели, но это не точно
Гугл-Калаб: https://www.bilibili.com/video/BV16G4y1B7Ey/?share_source=copy_web&vd_source=630b87174c967a898cae3765fba3bfa8
Speech To Speech (STS) 🎤 👉 🎤
Оба проекта SVC и RVC позволяют обучать модели на любой голос, в том числе свой, любимой матушки, обожаемого политика и других представителей социального дна. Для обучения своих моделей нужен датасет от 10 минут до 1 часа. Разработчики софта рекомендуют для обучения использовать видеокарту с объёмом памяти 10 GB VRAM, но возможно обучение и на видеокартах с меньшим объёмом памяти.
Преобразование голоса можно осуществлять как на видеокарте, так и на процессоре с меньшей скоростью.
SoftVC VITS Singing Voice Conversion Fork (SVC)
Репозиторий: https://github.com/voicepaw/so-vits-svc-fork
Гайд по установке и использованию: https://rentry.org/tts_so_vits_svc_fork_for_beginners
Готовые модели:
https://discord .gg/aihub (канал voice-models) UPD: сервер выпилили, бекапы здесь: https://www.weights.gg | https://voice-models.com
https://huggingface.co/models?search=so-vits-svc
https://civitai.com/models?query=so-vits-svc
https://t.me/AINetSD_bot (зеркало https://huggingface.co/NeuroSenko/svc-models/tree/main )
Для изменения голоса в песнях вам дополнительно необходимо установить софт для отделения вокала от инструменталки: https://github.com/Anjok07/ultimatevocalremovergui
Не поддерживает AMD GPU на Windows.
Retrieval-based-Voice-Conversion-WebUI (RVC)
Репозиторий: https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI
Где взять последнюю версию: https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI/releases
Готовые модели:
https://discord .gg/aihub (канал voice-models) UPD: сервер выпилили, бекапы здесь: https://www.weights.gg | https://voice-models.com
https://huggingface.co/juuxn/RVCModels/tree/main
https://t.me/AINetSD_bot (зеркало https://huggingface.co/NeuroSenko/rvc-models/tree/main )
Утилиты для отделения вокала от инструменталки идут в комплекте.
Speech To Text (STT) 🎤 👉 📝
Консольная тулза от OpenAI, поддерживает множество языков, включая русский: https://github.com/openai/whisper
Прочее 🛠️
Утилита для нарезки длинных аудиотреков (пригодится для составления датасетов): https://github.com/flutydeer/audio-slicer
Чтобы создать видео из аудио, можно использовать FFMPEG, но если лень - есть GUI, SoundWorks (ссылку см. выше) - Tools \ Video \ Produce still video
Загрузить аудиофайл, чтобы поделиться в треде: https://vocaroo.com/upload
Ссылки на эти проекты мелькали в прошлых тредах, но не похоже на то, чтобы их активно использовали итт:
https://github.com/w-okada/voice-changer/blob/master/README_en.md
https://themetavoice.xyz/
https://github.com/coqui-ai/TTS
Шаблон для переката: https://rentry.co/byv2s
Предыдущий тред: