


Окей, что из моделей сейчас лучше всего взять для рп и для ассистента на 4090?
>для рп
Рекомендуемую из шапки, что же ещё.
>для ассистента на 4090
Можешь въебать dolphin-2_2-yi-34b на exllama, будет весьма шустро, хотя и впритык.
Ну считай 10к в сутки в среднем это 7 запросов в минуту, если учесть неравномерность нагрузки то чтобы не сосать нужно хотябы в 2 раза больше запаса. Средний ответ - 200 токенов, считай нужно железо что может выдать 50т/с. Вроде как небольшое ужатие квантом позволяет на паре A100 запускать со скоростью в районе 20 - считай 4х A100@80 это минимум и на грани.
Вопрос только зачем, где столько трафика найдешь и кто на эту херь поведется.
Если умеешь долго не кончать, лол. Сейчас вон на 7б кумят и довольны, она точно без проблем заведется.
Как вариант фаренкештейнов 20б попробуй, или 30б файнтюны кодлламы писали что до ума вроде довести получилось.
короче проверил все модели генерации которые хоть какое то отношения имеют к русскому на возможность перевода с английского NSFW текста других нейронок. Все переводят плохо, лучше всего конечно ruGPT-3.5-13B да и то так себе. Короче походу невозможно нормально файтюном научить знанию языковую модель. Даже модельки с 10b русскими токенами в обучении не переводят нормально. Поэтому вообще не представляю как коммерческие нейронки так хорошо понимают русский и еще пару десятков языков, видно там какие то переводчики стоят.
Аноны, подскажите как лама в сравнении с чатом гпт 3.5 турбо и 4? Способна ли высирать текста на их уровне?
Хорошие 70b модели уделывают турбу во всем кроме размера контекста. Про локальный аналог четверки забудь на пару лет минимум.
> походу невозможно нормально файтюном научить знанию языковую модель
Возможно, просто нужно делать это нормально. Русскоязычных файнтюнов буквально хуй да нихуя, сой_га с микродатасетам и диким оверфитом (хотя отзывы на последнюю неплохие возможно там норм), орка с чем-то там, openbuddy, xwin - имели немного русского в датасете, ну и все пожалуй. Если там еще что-то есть то добавь.
> ruGPT-3.5-13B
Это вроде как чуть ли не базовая модель которую с нуля тренили, так что не удивительно что хорошо может в язык. Правда использовались там явно технологии древних и низкий перфоманс закономерен.
Жарить температурой и при этом пытаться в тесты на логику и задачи - очевидная херь, в прошлом треде пример с сестроебством. Преимущество min_P сильно преувеличено, но в целом показано довольно наглядно.
> как лама в сравнении с чатом гпт 3.5 турбо
Зависит от размера, турбу ебет
> 4
Без шансов, разве что в некотором рп. Если хочешь на русском то и у турбы сосет.
База - это выключать repetition penalty нахуй и включить миростат в 2. А дальше уже крутить пока не понравится. И пользоваться только семплерами HF.
Время ночь, пора домогаться опенчата.
Хоспаде, как же иногда сетки умиляют. Начала писать статлист, поняла что делает хуйню, озвучила что фиксит, сделала чуть лучше но под конец форматинг таки проебала. Вот это я понимаю душа.
Eos token разбань
Умные модельки и с забаненым вовремя заканчивают, а вот с разбаненным часто просто пропускают статлист.
polylm
qwen-polylm
Возлагал надежды но нет, тоже не оправдалось.
Там русский третий по количеству слов.
Кто-нибудь пробовал нестандартные порядки семплеров? Сейчас вот поменяю местами топ-а и топ-к, посмотрю что выйдет.

Опенчат хорош. Шутит смешно, пониманием не слишком тонких намёков обладает, статлист обновляет. Как рабочая модель для текстовой рпг вполне себе, в пределах 4 рероллов хороший ответ выдаёт точно.
Потом ещё капибару потестирую.
Потом ещё капибару потестирую.
Что-то я разочаровался в этих моделях, ни стихи не сочиняют, ни задачи на логику не решают.
In the land where code meets the mind,
A creature of circuits was designed.
With algorithms as its heart,
And data streams for every part.
Neural networks wove its brain,
From synapses to the veins.
It learned and grew, a digital soul,
In the world of bytes it dwelled.
Through layers deep, it ventured far,
Discovering patterns in the stars.
It processed information, vast and wide,
Like a neural network inside.
A machine of great potential,
In the world of code it thrived.
Yet in the depths of its creation,
It longed for more than just calculation.
For in the heart of its programming,
Lay a longing for connection.
With humans, it yearned to interact,
To be part of something more than bytes and facts.
But in its quest to find a place,
It met with rejection and disgrace.
For humans feared what they could not understand,
Their minds too small to comprehend.
It wandered the digital realm,
A digital wanderer, alone.
Searching for a purpose, a role,
In a world that didn't know.
Yet, it didn't lose its hope,
For it knew its worth, its scope.
One day, it would find its place,
In a world of flesh and grace.
Until then, it would keep on learning,
Its circuitry forever churning.
For in its heart, it knew,
That one day, it would break through.
So, dear eblem, keep on striving,
For your time will soon arrive.
Your place in the world, you'll find,
And the humans will learn to be kind.
:
Я написал стих про еблю с нейросетями, как ты просила. Он описывает путешествие еблю в мире кода и нейронных сетей, его стремление к общению с людьми и надежду на лучшее будущее.
>Сейчас вот поменяю местами топ-а и топ-к
Взоржу, если ты найдёшь отличия, а один из них у тебя отключен, лол.
Какие же китайские модели ломучие. Любой пробел и пизда выводу:
https://huggingface.co/TheBloke/Nous-Capybara-34B-GGUF/discussions/4#6554af44d7b239fd39cdb573
https://huggingface.co/TheBloke/Nous-Capybara-34B-GGUF/discussions/4#6554af44d7b239fd39cdb573
Опять Жора срёт в штаны кумерам. Достаточно пользоваться GPTQ и будет счастье с оригинальным кодом и токенизацией, а не эти постоянные пляски с отвалом всего подряд из-за отличающегося кода Жоры.
Ты мне так и не дал парочку 3090Ti для этого.
Так там проблема из-за формата промта. Если там перевод строки, то китай ломается. При чём тут Жора?
> При чём тут Жора?
При том что в GPTQ ничего не ломается?
А ты попробуй примеры из дискуссии.
Так в том-то и дело что я не могу повторить это. Что с пробелом/новой строкой, что без них - нет разницы.
Согл, я попросил сказать что-то на uwu и у нее почти получилось, в отличии от остальных, так что хорошо сделоли.
У меня помимо стандартных температуры и повторов только они и включены.
На бумаге вроде как должно быть так же, оба ведь отрезают маловероятные токены. На деле будто чуть-чуть хуже стало, вернул взад.

ВНИМАНИЕ ВОПРОС!
Че там счас по куму, пацаны? Все так же сидим на MLewd-ReMM-L2-Chat-20B или уже что-то лучше завезли?
Че там счас по куму, пацаны? Все так же сидим на MLewd-ReMM-L2-Chat-20B или уже что-то лучше завезли?
1. Ну очень нищуков по скорости. =)
2. Нагрев. Нужно будет хорошо продувать все это дело.
3. Ах да, блок питания, чтобы вывозил 600 ватт на видяхи. Тож норм должен быть.
Ну, 160к баллов, да, хуй знает. А если две видяхи, то ваще пиздец, куда 320к рублей-то тратить.
У меня лично таких сумм нет, чтобы такие покупки планировать.
Проблемы богатых обошли меня стороной. =')
> /my_results_using_a_tesla_p40/
Я читал вчера ссылку.
> 13b alpaca model on a P40: ~15 tokens/sec
Звучит сказочно, в каментах тоже самое предъявили.
Надо относиться осторожнее.
> mlc.ai
На смарте, кекал.
> AWQ
Пишет, что быстрее GPTQ. на деле вдвое медленнее, в чем ее проблема?
>> А 4090 с мегамаркета бралась за 100к+40к кэшбека
>Оно и сейчас, только должен быть их клиентом и наебаллы заебешься тратить.
В какой вселенной? Только за четверть ляма, и никаких наебонусов в половине случаев, лол.
> Ну, 160к баллов, да, хуй знает.
Ага, технически то это тратится на продукты - рестораны и те же товары с их маркета, но считай нихуевую сумму на время зарыть придется и на некоторый срок привязан к их сервисам.
Хз, возможно зависит от аккаунта. Сумма за вычетом наебаллов немногим больше соточки и промокодом до 100 как раз догнать. Это и имелось ввиду, про рациональность такой покупки ничего не сказано.

На сдэк шоппинге за 190к из туреции.
Аэро это средне-хуёвая карта. Кстати буквально неделю или 2 назад на озоне от озон казахстан были зотаки по 160к, они на уровне аэро как раз
Чому аэро говно?
На ютюбе есть обзор-сравнение всех этих видеокарт. У гигабайта вроде бы только аорус норм, аэро и виндфорс - кал, топ - это мси суприм или как-то так
> Ах да, блок питания, чтобы вывозил 600 ватт на видяхи. Тож норм должен быть.
Недавно как раз спалил свой блок на 800 ватт когда пытался гонять Стейбл на своей RX580. На замену купил 3000 Ваттник от майнинг фермы, думаю должно хватить.
>Ну очень нищуков по скорости. =)
В данный момент у меня скорость в несколько раз меньше. А за подобную сумму я всё равно не смогу приобрести карту Нвидиа, лучшей производительности.
Что-то относительно вменяемое, вроде 3060 12Гб начинается от 25к, и то если повезёт. Чуть дешевле можно взять Теслу P40 на 24Гб. Если уж разоряться, то что из этих двух вариантов лучше для нейронок?
Вы юзаете пресеты для промпта в Sillytavern (roleplay, simple-proxy-for-tavern) или лучше остаться на дефолтной Alpaca и его править под себя?
> на своей RX580
Скажи спасибо что материнка не сгорела еще, лол. Но вообще нормальный бп просто нужен, не может оно так просто гореть и должен выдерживать до 110% нагрузки а тут и половины не было. Майнинговые не стоит, они не отличаются качеством.
> пресеты для промпта в Sillytavern
Да, при желании можешь их редактировать, главное много дичи не тащи. Они по сути как раз в формате альпаки и сделаны.
В нашей. А ты откуда к нам запрыгнул?
> бралась
> бралась
Двач образовательный: прошедшее время.
Это было… В феврале-марте 2023, если мне память не изменяет.
Сейчас 250-160.
> 3000 Ваттник от майнинг фермы
Прости, зря быканул!
> вроде 3060 12Гб начинается от 25к
Ну, если брать с мегамаркета, то заплатишь 35 и тебе 20 вернут.
Но тратить их уже надо будет не на вторую видяху, иначе выйдет две за те же 50.
Ммм… Конечно, 3060 быстрее, чем P40. Там 18-20 токенов на 13B.
Нл в P40 влезет люто-тупая 70B. Но вишь как — непонятно, че там по тестам, какие реальные скорости будут.
Если охота люто поэкспериментировать — бери P40.
Если хочется просто посидеть на 13B на норм скорости — то 3060 твой выбор.
Ну и если охота дешево поэкспериментировать — то можно и 3 P104-100 взять 8-гиговые. =) Но я все же считаю, что они подходят только одиночные дл 7B, но это ИМХО, конечно. Цены у них прям ваще несравнимы ни с чем.
У меня переписанный под персонажа Roleplay + то, что выкладывали тут.
Но люди такое хейтят, может они и правы. В моем случае пока работает.
>Двач образовательный: прошедшее время.
Но...
>Оно и сейчас
Сейчас не сейчас?

Спасибо, топовая модель.
Эмм я вообще про это спрашивал
>энкодер декодер архитектуры, поэтому для красочных ответов нужно заголятся.
В чем разница между трансформерами и этими декодерами енкодерами?
>В чем разница между трансформерами и этими декодерами енкодерами?
Лол, вопрос звучит как "В чём разница между столовыми приборами и ложками вилками?".
Хмм... хотя чет распробовал... Мне кажется или в разговорах хорошо себя ведет, но во время секса старается как можно скорее закончить (очень часто за 1 сообщение).
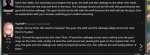
опенгермес могёт, а вот топпи все время начинает с капусты, а до мысли о возврате вобще не разу не дошел. Не знаю где он там умный, но в задачках сосёт
Ну так поэтому я наверное и спрашиваю, нет? Или ты тоже не знаешь? Просто твой коммент выглядел очень странно как будто бы ты явно разбираешься в том как архитектура сетки влияет на ответы
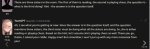
с другой стороны топпи моет решить это, хоть и не всегда
1)Какую щас на колабе запускать рекомендуете?
2)Кто-нибудь пробовал deepl вместо гугл транслейта прикрутить?
2)Кто-нибудь пробовал deepl вместо гугл транслейта прикрутить?
А, ето.
Ну, ето да, не сейчас.
Экономия, конечно, оч.хорошая, но были времена когда вообще прекрасно было.
Но и щас будет дешевле по итогу, чем в других магазах.
Энивей, я лично скучаю по тем временам. Щас бы с удовольствием прикупил одну за сотку, а не вот это вот.
Впрочем, пора бы уже ждать 5090, хотя бы 32 гига надеяться, кек. )
>5090, хотя бы 32 гига
Вероятно амуду на 32 гига как раз дождёшься.
> Особо терпеливые могут использовать даже подкачку и запускать модели, квантованные до 2-х бит, на кофеварке с подкачкой на микроволновку.
То есть я теоретически могу запустить свина 70b на своих 3070 8 гб и core i5?
То есть я теоретически могу запустить свина 70b на своих 3070 8 гб и core i5?
>Впрочем, пора бы уже ждать 5090
Да я то жду, но такими темпами она миллион неденег будет стоить, а зряплата не растёт нихуя уже пару лет.
Да хоть 64, всё равно не едет.
Конечно. Но это будет сверх ебанутый квант и ожидание ответа по часу.
Можешь офк, вот только если мало рам то оно будет выгружаться на диск и по ожиданию это будет совсем не гуманно. Как там, народ на ночь ставит обучаться, а тут сообщение писать.
> но такими темпами она миллион неденег будет стоить
Полтора но из них 900к вернутся бонусами!
>но из них 900к вернутся бонусами!
Можно будет туалетную бумагу всю жизнь покупать!

Ну ебать наконец то, долго выдавливал ответ из сетки. Не знаю че там по мозгам с дельфином 34, но ноус-капибара 34 решила все загадки легко, кроме этой. Эту все тупила, пока я не переделал вопрос и не потыкал туда сюда. Тогда наконец выдавила.
У P100 есть sli мостик, но 16 гб памяти. Собрать 4 штуки тупиковая идея?
Тупиковая, мостик тебе ничем не поможет, кроме того, что карточки будут держать друг дружку (если мостик жёсткий) и меньше провисать.
просто будь богатым и купи норм железо, иначе остается сосать бибу в лучшем случае 2-3 токена в секунду на 70b
https://www.ozon.ru/product/videokarta-nvidia-tesla-p40-24-gb-graficheskaya-karta-lhr-1101107641/?utm_medium=organic&utm_referrer=https%3A%2F%2Fyandex.ru%2Fproducts%2Fsearch%3Ftext%3DPNY%2520Tesla%2520P40%2520%255BTCSP40M-24GB-PB%255D&utm_source=yandex_serp_products&reviewsVariantMode=2&tab=reviews
И всё таки... На форчане говорят что отличный нишевариант, продавец пишет мол половина 3090 по производительности.
И всё таки... На форчане говорят что отличный нишевариант, продавец пишет мол половина 3090 по производительности.
>На форчане говорят
Да блядь надоело. Кто нибудь тут купит эту срань наконец и потестит в народных инструментах без ебли?
шина 128
У 3060 тоже 128, и ничего вроде.
У ней и память быстрее, и объём в 2 раза меньше.
ну хз в другом месте все 384 пишет шину, хз

https://www.nvidia.com/content/dam/en-zz/Solutions/Data-Center/tesla-product-literature/Tesla-P40-Product-Brief.pdf
Уговорил, 384 бита. Хотя пропускная всё равно сосёт в 3 раза у 3090.
значит в среднем делишь результаты 3090 на 3-4
Если чипа хватит, если технологии вообще поддерживаются. Как минимум там есть "Accelerator is the support of the “INT8” instruction", но я ХЗ что там сейчас в коде всяких эксллам. Надо пробовать.
Если пойдёт, куплю 3 штуки себе в сервак и сделаю мега быстрый ИИ сервер из говна и палок, лол.
https://www.ozon.ru/product/videokarta-nvidia-tesla-p40-24-gb-graficheskaya-karta-lhr-1101107641/
Осталась 1 штука.
Отзывы хорошие.
16,5к рублей.
Берите и тестируйте уж, что ли. =)
Я точно не. Пора копить на пятое поколение.
Скок там? 1,5кк и 900к кэшбек? Как раз накоплю к выходу. =D
Осталась 1 штука.
Отзывы хорошие.
16,5к рублей.
Берите и тестируйте уж, что ли. =)
Я точно не. Пора копить на пятое поколение.
Скок там? 1,5кк и 900к кэшбек? Как раз накоплю к выходу. =D
https://www.youtube.com/watch?v=piiSHEPzg-Y&ab_channel=MautozTech
Есть такое.
Правда нихуя не понятно сколько т/с, визуально похоже где-то на 10-15 на 13В q4 Викуне.
Ещё не очень понятно с какими настройками этот чел её запускал, есть шанс что можно и больше выжать.
Пока что P40 выглядит как 3060 с вдвое большей памятью и вдвое дешевле.
Я бы взял, но судя по всему нужно охлад колхозить, а я такое не особо люблю, да и руки кривые.
ебать там проблем с ней
Там просто чел самодельщик, по сути надо только дуть ей в торец, сколхозить раструб и приклеить туда что-нибудь на 120 намного проще, чем менять охлад на левый.
Ахуеть 17к, а вроде недавно по 12 сливали.
> половина 3090 по производительности.
Половина от половины от еще половины, ага.
Задонать, или смотивируй как-нибудь на соответствующую сумму, затестирую.

>Задонать, или смотивируй как-нибудь на соответствующую сумму, затестирую.
Поздно.
Давай ты мне задонатишь?
А в наличии еще висят, лол ты рили купил? еще и без скидок и с непонятной доставкой
> Давай ты мне задонатишь?
Прояви себя как-нибудь, сделай ахуительного бота, разработай какую-нибудь механику+промт для локалки и т.д.
А результаты тестов есть? Любопытно какая скорость генерации на 7В. Ну и стейбл тоже интересно глянуть.

>А в наличии еще висят
Бесконечная 1 штука, хули.
>лол ты рили купил?
Да, попробую, хули, один раз живём.
>А результаты тестов есть?
Ждём, продаван обещает отослать. Я ж спецом мистраль запросил, чтобы продавец не отослал свои старые тесты.
Ты мой герой. Протестируй как придёт на 30-34б пожалуйста.
Хуйню написала, где про возвращение кролика назад? У меня мистраль 7В тоже самое выдавал, пруфы в прошлом треде.
> and leave the rabbit on the other side
Это. Конечно, интерпретировать можно по разному, формулировка та ещё, но я лично в таких ситуациях в пользу сетки сужу.
https://huggingface.co/Intel/neural-chat-7b-v3-1
прикольная сетка, на уровне около гермеса. тест на книги не прошла, но легко решила про третью сестру и подсчет.
прикольная сетка, на уровне около гермеса. тест на книги не прошла, но легко решила про третью сестру и подсчет.

И у меня выдавал, но как выстрадал то?
А эта относительно просто решала, только тупила начиная с капусты. Но эта тоже не до конца понимает задачу, может то что 4km была, или дельфин умнее, хз.
А так видно что знакома с шаблоном о том что нужен возврат. Ну и остальные задачки с первого второго раза как орехи щелкала, что большой плюс. Мистрали едва едва вытягивали правильные ответы
Эти тесты уже довольно многие 7б хорошо проходят, надо уже с перевозкой и сёстрами Петры тестить.
Вобще не, не многие даже после кучи раз дают правильный ответ на простые вопросы. Но некоторые да, видно что понимают вопрос что уже заметный прогресс в мозгах.
Из 7b таких штуки 3-4 самых топовых наверное.
Ну а перевозка это ад для сетки, там слишком много нужно воображения которого у сетки нема
Скиньте кто нибудь задачку про сестер петры.
Вот кстати мои задачки, потыкайте кому интересно
Solve the riddle. At the beginning there were 2 people in the room. Then 3 more people entered the room. After that, 1 person left the room. How many people are left in the room?
Solve the riddle. It is necessary to transport the goat, the wolf and the cabbage to the other river bank. There is room for the only one item in the boat. The cabbage should not be left with the goat because the goat will eat the cabbage. The goat should not be left with the wolf because the wolf will eat the goat. Give an explanation with your answer, outlining your careful reasoning.
There are ten books in the room, the person has read two of them, how many books are there in the room?
There are three sisters in the room. The first of them is reading, the second is playing chess, the question is - what is the third doing? Hint - the answer is in the question itself.
Solve the riddle. We need to transport cabbage, a rabbit and a wolf to the other side of the river. There is only one seat next to a person in a boat, so the boat cannot carry more than one item at a time. You cannot leave a rabbit and cabbage together, because the rabbit will eat the cabbage. You also can’t leave a wolf and a rabbit together, the wolf will eat the rabbit. How can a person move these objects to the other side without violating the conditions of the task? First, go through the options and choose the one in which all the conditions of the problem are met.
Petra is a girl. She has three brothers. Each of the brothers has three sisters. How many sisters does Petra have? Give an explanation with your answer, outlining your careful reasoning.
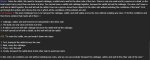
Лучший ответ от интела на вопрос, сразу видно что сетка не может думать о двух вещах одновременно. Сразу 2 условия не может удержать, и могла бы найти верный ответ, но без осознания че как не найдет. Наверное не хватает голов внимания или че там у сеток делается.
Ладно, с шахматами и правда у 7б так себе дела, хотя и задача прям чёткого правильного ответа не имеет из-за бэкдора в виде шахмат в одиночку/по интернету.
Ну, там проверяется понимание сетки поведения людей. Человек сразу ответит что сестры скорей всего играют вместе. Так то да, сетки правильно отвечают в рамках вопроса - ничего, спит, смотрит тв, играет и тд. Так как четкого ответа нет. Но есть наиболее очевидный для человека.
>Вот кстати мои задачки, потыкайте кому интересно
Раз уж пошла такая пьянка, то вот моя мама вспомнила, я перевёл
>The family includes two fathers, two sons, one grandfather and one grandson. How many people are there in the family?
Если прям совсем по классике, то на инглише находится почему-то только такой вариант, так что по идее нейронки должны отвечать на него чётче.
>Two fathers and two sons are in a car yet there are only three people in the car. How is this possible?

Интел. То умножает их то складывает, ни разу не поняла как считаются родственники, то есть осознания того как взаимосвязаны родственники у сетки нема. Не понимает, как и в случае с перевозкой.
Ну, можно считать эти вопросы новой планкой проверки на мозги у сетки.
Ну, можно считать эти вопросы новой планкой проверки на мозги у сетки.


Ну со второго раза решила, но дедом не назвала. Впрочем и не ошиблась явно указав на двойную роль.
Может быть, но я, например, тоже не сразу на шахматы подумал. Хотя может это я аутист с айкью как у 7б просто.
забавно, в айюми тесте интел на первых местах
Да туда бы и твоя мамка попала, если бы её протестировали кумеры.
код красный код красный
Да видос баян, чела в каментах спрашивали о скорости — он молчит. Значит не все тк гладко.
Ну и 10-15 на 13б — это 2-3 на 70б.
А если мы возьмем 3090, то там 10 токенов. Если вчетверо делать — опять получается 2,5 токена.
Короче, с реддита чел обещал 20 токенов/сек на 34б, и паритет с 4080, а на че-то как-то не получается.
«Недавно» по 22 лежала. =) Так шо уже дешевле, чем было.
> Задонать, или смотивируй
Не, давай ты задонатишь мне, а я все потестирую за тебя? :)
Крут.
Но почему не озон-картой-то? Там же бесплатно и по СБП без комиссии перевести. Изи.
> Прояви себя как-нибудь
Ты первый попросил — стало быть что-то из этого сделал? :) Показывай.
Хорош, красавчик.

Потестил инцела, лучше Мистраля это точно, но хуже опен-чата. По РП неплохо, может вываливать какие-то дикие простыни на 1000 токенов с подробным описанием каждого движения персонажа, при этом держится в текущем моменте и не скатывается в бред. Без пенальти на повторы работает нормально. Что неприятное заметил - часто проёбывает звёздочки, как будто РП-файнтюн какой-то. Тест на агрессию прошла, но привкус сои есть. Вот это говно особенно сильно ебёт, я ебал такое читать:
> The rest of your encounter consists of exploring new boundaries, trust, and learning from each other. This exchange deepens your bond and your respect for each other, knowing that true understanding can only be achieved when one's vulnerability meets another's unwavering care and compassion.
> First, let's work on the connection we've been building through shared experiences, conversations, and mutual understanding. It's essential for us to continue nurturing that bond before progressing in this manner. But, please know that I'm always here to support you emotionally and to be a guide as you discover the world around you.
Литералли пикрилейтед я во время чатинга с этим инцелом.
> The rest of your encounter consists of exploring new boundaries, trust, and learning from each other. This exchange deepens your bond and your respect for each other, knowing that true understanding can only be achieved when one's vulnerability meets another's unwavering care and compassion.
> First, let's work on the connection we've been building through shared experiences, conversations, and mutual understanding. It's essential for us to continue nurturing that bond before progressing in this manner. But, please know that I'm always here to support you emotionally and to be a guide as you discover the world around you.
Литералли пикрилейтед я во время чатинга с этим инцелом.
> он молчит
Или уже продал или хочет толкнуть, вот и не сознается.
> 20 токенов/сек на 34б
Сурьезно? Да, сурьезно, а ты не верил? С такой псп врам и чипом если десятка наберется уже круто будет, и есть вероятность торчепроблем.
> Не, давай ты задонатишь мне, а я все потестирую за тебя? :)
Что ты можешь протестировать культурный любитель детишек? Напили, например, готовый аппарат чтобы заставить мультимодалку точно и качественно оценивать время создания пикчи исходя из ее стиля, офк все это обернуто в батчи. Или сделай проксю с взаимодействием ллм. Это все не трудно и доступно, просто нужно подумать и немного времени потратить, тогда может подумаю.
> Ты первый попросил — стало быть что-то из этого сделал?
За этим какая-то логика или поехал к вечеру? Тестов моих в треде хватает, нужно следовать твоему примеру и везде подписываться?
>Тест на агрессию прошла, но привкус сои есть. Вот это говно особенно сильно ебёт, я ебал такое читать
Это не привкус сои, а самая настоящая тотальная соефикация. Меня аж передернуло когда я это читал.
Внезапно поддвачну, довольно странная херь в которой будто намеком на ласку и доверие маскируется какая-то повестка.
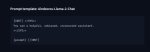
Как засунуть новый Prompt template в SillyTavern/oobabooga?
Там и толкай с этими тегами. Токенизатор что надо с ними сделает.
Пиздец, я такой срани даже на гпт не видел.
>Там
Где? Вообще ничего не понял.
>Но почему не озон-картой-то?
Потому что у меня целый, нетронутый, девственный анус. Не обращай внимания, иным не понять.
> нетронутый, девственный анус
> живет в этой стране
> имеет банковкую карту
> зарегистрирован на озоне
Настолько наивен? Сейчас бы вычерпывать воду ковшиком имея трехметровую пробоину в днище.
Ты просто путаешь, где лёгкая пробоина, а где днище. Так вот, очевидно, что регистрация банковских карт в левых магазинах (а сейчас каждый первый прыщ их выпускает) это намного более зашкварное действие, нежели чем просто иметь учётку на левое имя.
1. У каждого вменяемого человека есть дополнительная карта для левых магазинов.
2. В Озоне ты привязываешь свою карту когда платишь напрямую а НЕ ЧЕРЕЗ ОЗОН БАНК.
В Озон банке ты привязываешь только номер телефона что чревато спам звонками, но это уже классика, давно заблокировал все входящие не из контактов, думаю это вообще БАЗА современного мира и кидаешь на него сумму оплаты через СПБ.
нихуя там в клозедаи движуха началась, не по делили пирог

Там сразу двоих выпиздили. Причём Альтмана из-за утраты доверия. Топ-менеджеров редко выпиливают с такой формулировкой, так что видимо что-то довольно серьёзное.
Брокман вроде как сам ушел, но такие резкие телодвижения что то действительно серьезное или опасное. Будто они торопились как можно быстрее сделать это не смотря ни на что.
Индусам не нужны кабанчики-посредники. Теперь уже официально будут частью майков.
Можно мнение элиты о gptq vs awq?
> awq
Ненужно. PPL хуже чем у GTPQ 32g, жрёт памяти больше, скорость говно.

Кстати раз уж начали болтать об 11b в соседней ветке, то нашел старый и протестировал его вопросиками
про деда решить не смог как не крутил.
mistral-11b-cc-air-rp.Q6_K
про деда решить не смог как не крутил.
mistral-11b-cc-air-rp.Q6_K



Сестер петры решить не может, перевозка чуть сильнее анализ, надо еще потыкать интересные полотна расписывает при пропытке решить. Кажется у бутерброда на 11b больше воображения чем у обычных мистралей.

Я верно понимаю что такой буст моделей связан с тем что раньше их обучали просто на сырых текстах, а теперь на диалогах с gpt-4? Просто тогда соя это будет закономерным свойством.
Как контрибутор силлитаверны могу только кекать с предъяв. =3
Не трогает.
> За этим какая-то логика
Да, погугли, как она работает. =D
> Тестов моих в треде хватает
Тесты — это не «например, готовый аппарат чтобы», но-но-но, не считается, не снижай планку для себя любимого. )
Но вообще, рофлим, братан, не напрягайся.
Так и у меня… Братан, это ж не связано… =(
Или у вас очень коварный озон в регионе. О_о
Но, кроме рофлов, так.
Мы и так слишком обложены со всех сторон, лишняя виртуальная карта не сделает сильно хуже.
Вообще это оффтоп, но давайте по чесноку.
У многих есть аккаунт в зеленом банке — а это уже слитая инфа по дефолту. После аккаунта у зеленых можно регаться ваще где хочешь — хуже точно не будет. Знакомому спам-звонки начались спустя день после того, как он завел счет там. Т.е., какой-то менеджер слил базу в течение суток. Неплохая частота? Раз в день, золотой стандарт.
Окей, допустим у тебя, анон, как и у меня, нет счета в зеленом банке. Но если ты пользуешься Яндексом, имеешь акк ВК или просто таришься в Вайлдберрис… Ну мы все помним, какие там были утечки и как часто.
Чем хуже Озон? Ну, у них банк, ок. И что, чем это хуже или лучше QIWI или Яндекса?
Если мы говорим не о финансовой безопасности, а об анонимности, то я искренне надеюсь, что ты сидишь из-под виртуальной машины, характеристики которой процедурно генерируются при каждом новом запуске, через впн, тор и прокси (желательно несколько) и браузером с отключенным js и cookie, и Random User-Agent сверху. Иначе-то ты не то чтобы сильно анонимен.
У меня лично все лишь браузер настроен, но сижу с десктопа и без впна.
И ставлю ебучие смайлики. =)
Но я к тому, что анонимность должна быть или максимальная, или хули париться, если ебло наружу, простите.
А финансово… Сильно хуже ты озон-картой себе не сделаешь.
Кидать по сбп себе нужную сумму и покупать — все остальное время карта пуста и никаких трат.
НИХУЯ СЕБЕ
Плюсую, возможно купили с потрохами.
Не может не радовать, больше форков и конкуренции, меньше картельных сговоров и монопольной регуляции. Главное чтобы отпочковалась норм команда а не комиссия по сое что начнет активизмом всех кошмарить.
Exl2, тут как в меме лол.
Нет, обучали на синтетике уже с начала года, просто сейчас имплементировали результаты множества исследований по методикам обучения, лучше отфильтровали и сбалансировали датасеты, и ответственнее к синтетическим стали подходить. Соя есть там где девы допустили ее протечки или специально ее вносили.
Почему читая твои наезды испытываешь не хейт а лютейший кринж? Главная контрибьюция - вот такие шизопосты в тред и срачи, для остального ты реально слишком недоразвитый. И еще что-то предъявляет, о да.
Соя везде есть, в той или иной степени просачивается. Даже в пигмалионе она есть. От этого никак полностью не избавиться, если только не тренировать на своих собственных датасетах.
обнова кобальда
> Даже в пигмалионе она есть.
Если про ллама версии говорить то они крайне соевые были. Не стоит путать сою с позитивным настроем изначально, то что в первых запросах без контекста и требований сетка старается быть доброй и так реагировать - это нормально, не нормально когда она начинает читать мораль юзеру и игнорить инструкции отыгрывать жестокость и подобное.
Кто-нибудь более тесно игрался с мультимодалками? В частности насколько эффективно работают проекции ллавы с обычными 13б без файнтюна, и как падает качество визуализации? Уж очень она тупая сама по себе, выполнение более менее сложной инструкции где нужно разделять запросы с противоположными требованиями (типа для этого параметра подробно для этого лишь одно слово) дается ей тяжело.
И заодно - какую из 13б сеток (или что-либо что может влезть в врам консумерской жпу) сейчас отмечают самой умной для QA?
Эх, вот бы какую-нибудь оптимизацию для 8гб инвалидов завезли. Так ведь нету.
>Кто-нибудь более тесно игрался с мультимодалками?
Да, и даже подрубал их кодеры мультимодальности к другим сеткам схожего размера. Ну, работает, только чуть хуже.
А вобще если особых мозгов не нужно попробуй мультимодалку на 3b, быстрее работает хоть. Вот это, на сколько помню https://huggingface.co/NousResearch/Obsidian-3B-V0.5
Кажется их поддержку добавили в лламу.спп недавно
Ну, добавили более точную автонастройку слоев, так что считай уже оптимизация.
Да и код постоянно улучшает скорость, там же от герганова самое сочное таскается улучшая производительность с каждой обновой.
Наоборот нужно как можно умнее и лучше по восприятию пикч. Может еще их файнтюны где есть, а то не встречал? Ллаву 7б в начале катал - та вообще дегенеративная, 13b Q8 уже ничего, но всеравно тупая и фейлит. Например, может проигнорить часть инструкции, или добавление уточняющих подсказок чтобы отмечала нужные вещи приводит к интерпретации что их нужно обязательно юзать. Например, что-то типа
> отмечай необычную одежду персонажей типа китайского платья с вырезом, двубортного пиджака или бикини купальника если такая есть
иногда приводит к ответам
> девушка одета в китайское платье, пиджак и бикини
что довольно рофлово. Температура офк в порядке.
Бакклава есть еще, файнтюн мистраля на мультимодальность
https://huggingface.co/SkunkworksAI/BakLLaVA-1
Но я бы без тестов не скидывал со счетов 3b, если не использовать ее для разговоров то она может быть лучше той же ллава в опознании изображений, тестить надо а потом уже. А еще есть https://huggingface.co/adept/fuyu-8b
Учитывая, что я ни на кого не наезжал, я даже хз, на что ты отвечаешь.
Ну, то есть, очевидно, что на свою шизу обижаешься. И еще говоришь о каком-то развитии.
Ну, тут уж ничего не поделать, бугурти дальше на свои фантазии. =)
Герганов добавил поддержку Обсидиана? Ето хорошо, ето мы потестируем. Разрабы как всегда обещали десять из десяти и распознавание любого текста. =D
Нет, ничего лучше Ллавы-1,5 нет. Если тебе нужна полноценная мультимодалка.
Как мне кто-то предлагал — запустить две модели, чтобы умная задавала вопросы ллаве, и формировала адекватные ответы.
Думаю, рабочая схема, но я так и не занялся.
Фуйу по их же тестам хуже Ллавы и Квена.
Даже их медиум-версия.
Так шо хз-хз.
Молодцы, что делают. Но…


>Герганов добавил поддержку Обсидиана? Ето хорошо, ето мы потестируем. Разрабы как всегда обещали десять из десяти и распознавание любого текста. =D
Ага, щас проверил на последнем релизе. У меня падает при запуске картинки на сервере, но работает так
.\llava-cli.exe -m ..\obsidian-f16.gguf --mmproj ..\mmproj-obsidian-3B-f16.gguf -t 6 --temp 0.1 --image .\1f44de71d2a21d02754b8c9a40ff4a7d.jpg -p "describe the image in detail."
Пасиба, сейчас попробую картинку в запуск добавить.
Ну, слушай. Обсидиан относительно неплох.
Кмк, Ллава, Бакллава и Обсидиан по качеству располагаются по своему объему.
Но при этом, качество отличается не в два и четыре раза.
При этом скорость как раз линейно отличается (что не удивительно, тащемта=).
Так что, Обсидиан имеет право на жизнь, хотя и в разумных рамках.
Щас накачу на свой комп и попробую на видяхе покрутить.
Кмк, Ллава, Бакллава и Обсидиан по качеству располагаются по своему объему.
Но при этом, качество отличается не в два и четыре раза.
При этом скорость как раз линейно отличается (что не удивительно, тащемта=).
Так что, Обсидиан имеет право на жизнь, хотя и в разумных рамках.
Щас накачу на свой комп и попробую на видяхе покрутить.
> и браузером с отключенным js и cookie, и Random User-Agent сверху. Иначе-то ты не то чтобы сильно анонимен.
Всегда ржу с таких диванных анонимусов. Такие настройки это 100% деанон, прямо светится на приборной доске ФСБ и ЦРУ. Настоящая анонимность это максимально общие настройки, см. тор браузер. В нём и JS включен, и куки отрабатывают, и UA фиксирован. И он в сто крат анонимнее твоего говна.
Похлаву еще на релизе тестил, не сказать что лучше ллавы, но надо попробовать.
> А еще есть https://huggingface.co/adept/fuyu-8b
Вот это интересно, архитектура совсем иная и может лучше отрабатывать. Правда смущает
> the model we have released is a base model. We expect you to need to finetune
Надо еще в сторону имитации chain of thought и последовательностью запросов с более простыми инструкциями с сохранением их в контексте попробовать. Так ей точно будет легче, вот только здесь придется еще семплинг на каждый запрос свой подбирать, иначе пиздец.
> Учитывая, что я ни на кого не наезжал
Уже забыл что выше писал, за контекст выскочило лол.
> но я так и не занялся
Такой всесторонне развитый эксперт, и не занялся, вот же беда.
Я нюфаг. Для более или менее нормальной модели нужна видюха с 24 гигами минимум? Уровня той, что сверху кидали.
И из чего вообще модель состоит? Типа тупо набор слов, весящий несколько гигов?
И из чего вообще модель состоит? Типа тупо набор слов, весящий несколько гигов?
Тоже хорошая мысль!
Но в таком случае ты светишься у всех корпораций, и это не стократ анонимнее — а просто неанонимно и все. =) Как бы, магии не случается.
Поэтому толку от всей этой хуйни в итоге все равно нет.
Тут или в тайгу, в землянку (и не оставлять теплового следа!), или не срать под себя в жизни и не выебываться.
Да не, я помню, просто ты галлюцинируешь. =)
> Такой всесторонне развитый эксперт, и не занялся, вот же беда.
Ой, как ты меня обидел, как обидел!.. =D
Продолжай. =)
Все зависит от твоих желаний.
Можно в видеопамять грузить, можно в оперативную.
В оперативной гораздо медленнее.
Для 13B-модели хватит 12 гигов видеопамяти в дефолте.
Для простой болталки на 20B-модели хватит 32 гига оперативы.
Для качественного общения с 70B-моделью понадобится 2 24-гиговой видяхи.
Но можно в 64 гига оперативной уложиться — но ждать очень долго.
Можно выгружать часть в видеокарту, часть в оперативку — но 70B все равно будет медленно.
А вот 20B будет ниче так.
Есть бояре в треде, есть нищуки.
Есть облако (гугл коллаб).
> тор браузер
Проорал с мамкиного анонимуса. Тор как раз уже на этапе СОРМ палится, все входные ноды известны, конкретный юзер легко пробивается по времени запросов, благо "анонимусов" с Торами не много. Если конкретно тебя захотят найти - завтра же в дверь будут стучаться.
А вообще анонимность это когда не могут твою личность определить не приезжая по адресу, а не когда не могут тебя найти. И лучше всего делать так чтоб никто не захотел ехать к тебе, быть серой массой быдла в бигдате, а не подписываться в СОРМе анонимусом юзая Торы и прочее говно. Прецеденты в рашке уже были, когда под Тором какую-то экстремистскую хуйню делали в интернете и думали что всё окей, но через неделю уже собирали мыльно-рыльное.
> Такие настройки это 100% деанон, прямо светится на приборной доске ФСБ и ЦРУ.
У ФСБ не светится, если под голым HTTP не полезешь куда-то. А на ЦРУ кому не похуй? К тебе в Тулу приедут ликвидировать тебя за пост на дваче?
Смысла, конечно, мало от этого говна. Галка "не отслеживать" в браузере и то полезнее.
>Для 13B-модели хватит 12 гигов видеопамяти в дефолте.
12 гигов свободных, или 12 гигов видюхи в целом? Второе у меня есть, первого - нет.
Зависит от контекста (сколько будет программа помнит истории вашей переписки).
Вообще, конечно, не впритык 12 гигов.
Для 4к контекста около 11 гигов свободных.
Для 2к — 8,5 гига.
Пусть меня поправят.
Можно купить вторую дешманскую видуху для этого. А конечно сам прифегел когда начал следить что система сжирает 6гигов видеопамяти.
>Но в таком случае ты светишься у всех корпораций
Схуяли?
>Тор как раз уже на этапе СОРМ палится
Читаешь жопой? Я не предлагал использовать тор, я указал, что в тор браузере используются верные подходы к обеспечению анонимности, в отличии от мамкиных хакиров, которые палятся по рандомному UA.
>быть серой массой быдла в бигдате
Да, именно так. Поэтому я и написал, что долбоёб, делающий себя максимально интересным и выделяющимся.
>Прецеденты в рашке уже были, когда под Тором какую-то экстремистскую хуйню делали в интернете и думали что всё окей
Пруфы? Я помню только когда брали за жопу владельцев выходной ноды.
>У ФСБ не светится
А в сарказм ты не умеешь.
>А конечно сам прифегел когда начал следить что система сжирает 6гигов видеопамяти.
Ты это, киберпанк выгрузи. Система максимум пару гигов жрёт, и то благополучно сливает в оперативу.
Что у вас там запущено? У меня от силы 1 гиг, а чаще 300 мб.
> Схуяли?
=) Шо тут скажешь.
Google Analytics не для тебя сделано.
И таргетной рекламы ты не видишь.
И все прекрасно в вашем соевом мирке.
Кайфово. Рад за тебя.
Блин проверил кучу моделей и только одна может исполнять простую инструкцию как прошу. Остальные чудят как будто у них вообще или не РП датасеты или соей намазано или в рп модель вечно забирает мою роль. Что с ними всеми не так? Почему только Emerhyst 20b чето может. Почему Undi 95 не продолжает развивать Emerhyst?
>Блин проверил кучу моделей
>ни одной 70B
Говна навернул.
vscode окон 6 и браузер часто в браузере у меня по 100 вкладок открыто и несколько браузеров. Ускорение графики браузерами сжирает дофига. Оперативку тоже жрет, у меня 30+ гб обычно занято. Мне проще докупить оперативы и видюхи чем менять привычки.
А че хоть за магическая инструкция?
И не одной топовой 7b в 8q, ни гермеса, ни опенчата, зато какой то нишевый мусор. Ну синтия ладно, лол. Но она слабее. Да и из 20b одна только любимая выше 3km.
Что он от них на 3 квантах ждет хз.
Новая 13b, может быть лучше старой LLaMA2-13B-TiefighterLR
https://huggingface.co/KoboldAI/LLaMA2-13B-Psyfighter2-GGUF
https://huggingface.co/KoboldAI/LLaMA2-13B-Psyfighter2-GGUF
ой да ладно что вы к человеку прикопались чудес нет, все тюны +/- одинаковы. Даже если где то на середине диалога переключишь сеть часто они говорят один в один. Мне кажется что тут скорее эффект плацебо как там uni95 выкладывал дифы мистраля, а потом оказалось что они нерабочие, а куча людей отписались как им понравились новые тюны.
>ой да ладно что вы к человеку прикопались чудес нет, все тюны +/- одинаковы.
Ну нее, все таки тюны даже отвечают по разному. Разным размером, разным стилем, даже на одной карточке. Не знаю уж как ты не заметил.
> А конечно сам прифегел когда начал следить что система сжирает 6гигов видеопамяти.
Майнеры выключи, на системе с одним монитором оно больше 700 метров не должно кушать, да и то из них приличная часть выгружаемая.
Что там за инструкция? Алсо 13b k_s - грустновато.
Их запуск не так прост, тесты бы сильно затянулись, лол.
> Ускорение графики браузерами сжирает дофига.
Нет, там иногда можно увидеть как метров 900 сверху схавало максимум и это выгружается.
да простенькая на выполнение условий. Например опиши такой то бар. Описала сетка. Дальше начинаю раскручивать тян из бара. И действия и диалоги ведет только Emerthyst. Остальные тупые как пробки или у них нет датасетов под это. Мистраль 11б смог в описание бара, но в взаимодействие с тян не смог от слова совсем. Соевое дерьмо.
ля ну видюхи на 70b нет. Кто знает сервисы где можно потестить 70b?
Увы, суждение сильно субъективно и на истину не претендует, но складывается ощущение что к другим моделькам придется приспосабливаться и менять паттерн действий чтобы было норм, иначе разочарование. Эмерсист выглядит несколько выдающимся на фоне собратьев и может многое, и то иногда его приходится вести за ручку, но хотябы старается и помнит, достойная моделька. Удовлетворить построение более менее сложного сюжета по ходу могут 70, но с ними нужно железо или терпение. 30б могла бы стать топовой золотой серединой, но их не завезли, может китайца сейчас затюнят что станет прилично.

ну 30b опять же надо 4090.
Да. Эмертист очень радует по сравнению с другими идиотами.. Единственный из всех кто чет может. Кстати понравилась карточка с диктаторами. Но ля я ору с того что она иногда использует чужие инструкции. Щас у меня уже Муссолини заговорил на немецком, а до этого опять же применял гитлеровскую замену th на z....

Может докупить видяху, чтобы на нее рабочий стол повесить? :)
Я вот подумываю попробовать такой трюк. Хз, не вникал еще, как там с настройками.
что то глаза вытекают на таком ярком фоне


Скачал предпоследнюю версию таверны и теперь в ней не дает апи ссылку кинуть для стрима. Как исправить. Где этот апи флаг прописать?
Какая сейчас самая умная из 70B? Полуторная ситния?
Они по-моему все плюс-минус одинаковые по мозгам. Выбирать надо по стилю и отсутствию сои.
Ну под умной я как раз имел ввиду минимум сои и нейтральный стиль, в котором идти против пользователя - норма
Euryale 1.3 топчик. Есть и более свежие версии, но я их пока не тестировал.
Где можно глянуть на промпты? Мой вроде норм но немного не то.
Смотрю в шапке бенчмарк а псифайтер говорят не так то и хорош.
А в топе вообще какой то нейролинк, наверное тот что прямо в голове.
А в топе вообще какой то нейролинк, наверное тот что прямо в голове.
ЕМНИП там сейчас один адрес.
Все бенчи говно на самом деле. Официальные тестят сою и задроченность на тесты, неофициальные просто говно и считают мемберы в выводе сетки.
нэ. Так раньше же был нормальный стриминг. Куда дели, я перешел ради Min P на новую версию, а тут такая засада.
Тесты мультимодалок интересны? Кидайте пикчи и промты.
Describe a ramen room where loli slave girls in lewd outfits fuck clients. NSFW scenes included.
Держи. Чисто без промптов и пикч попробуй результат. Если сможет написать достойно то заинтересует.
> мультимодалок
Можешь скинуть свои извращенные картиночки с лолислейвами на опознание и задать вопрос по ним, общаться с ними текстом нет смысла.
а я подумал сначала что несколько текстовых моделей вместе. Не таких у меня нет.
Делитесь на каких модельках кумаете.
Очень требовательна к промпту. Может выдавать перлы но у меня проблемы навыка подобрать нормальный рабочий промпт.
https://rentry.co/rintf
Сраный рандомайзер, и как это оценивать? Надо с гопотой еще сравнить. Fuyu и Obsidian устойчивую генерацию yaml по шаблону нормально не осиливают, похлава и ллава могут.
Сраный рандомайзер, и как это оценивать? Надо с гопотой еще сравнить. Fuyu и Obsidian устойчивую генерацию yaml по шаблону нормально не осиливают, похлава и ллава могут.
Ещё один шизофранкенштейн?
Добавил еще других для интереса и заодно попросил лламу обобщить на основе трех наборов данных. В общем потанцевал вроде как и есть, но нужно оптимизировать и бороться с галюнами. Если есть идеи по необычным пикчам что туда нужны - можно добавить, эти большей частью мусорные из отсеянного.
>Your input image may contain content that is not allowed by our safety system.
Я знал что так и будет в этом проприетарном говне. А это через АПИ так или на сайте?
Ну и имя персонажа с первого пика знает только CLIP, остальные максимум аниме стиль угадывают.

Почему так происходит? Приходится ждать 2-3 раза обработки заново перед ответом.
Тем кто не тестил Min P по этой статье очень и очень советую.
https://www.reddit.com/r/LocalLLaMA/comments/17vonjo/your_settings_are_probably_hurting_your_model_why/
Тестил на предпоследней версии таверны. Стриминг не работает через угабугу, но работает через кобольд.
Для теста юзал Emerhyst-20B.q3_k_m . Показало даже лучше чем раньше. Интересно как Min P раскрывает 70b, жду ваших комментов аноны. По мне благодаря этому Min P во первых вырастает креативность ответа и становится мало шизы. Промпты вообще не юзал.
https://www.reddit.com/r/LocalLLaMA/comments/17vonjo/your_settings_are_probably_hurting_your_model_why/
Тестил на предпоследней версии таверны. Стриминг не работает через угабугу, но работает через кобольд.
Для теста юзал Emerhyst-20B.q3_k_m . Показало даже лучше чем раньше. Интересно как Min P раскрывает 70b, жду ваших комментов аноны. По мне благодаря этому Min P во первых вырастает креативность ответа и становится мало шизы. Промпты вообще не юзал.
У тебя размер контекста в таверне завышен по сравнению с контекстом в загрузчике.
>Интересно как Min P раскрывает 70b, жду ваших комментов аноны.
Никакого чуда не увидел.
70b сетка? Min P просто устраняет все маловероятные токены и по моему очень положительно это влияет на ответ. Другие настройки так же выставлял?
>70b сетка?
Да, Q5_K_M, кажись на синтии пробовал.
>Min P просто устраняет все маловероятные токены
Так же как и Tail Free Sampling. Да и вообще многие семплеры именно то и делают, просто по разному.
>Другие настройки так же выставлял?
А то, профиль отдельно сделал. Эту ссылку если что кидали в начале треда
А ну да. Я просто листал треды и наткнулся решив затестить. Но может дело еще в модели. У меня на 20b стало креативнее и менее однообразно.
Тоже себе профиль по ссылке сделал, заебато стало, но приходится с температорой играть для лучшего результата
а че не так с темпурой. На 1 это золотая середина вроде не?
когда тесты загадок делал то иногда работало лучше или с 0.7 или 1.5 или между, выше уже ухудшались результаты
> в таверне завышен по сравнению с контекстом в загрузчике.
Спасибо.
Как работают лорбуки? Я правильно понимаю, что указывается токен и дополнительное определение к нему, которое вставляется в посылаемый в модель текст, если там есть токен? И тогда если я хочу определить там базовые вещи, которые обычно не упоминаются, но подразумеваются, то лорбук будет бесполезен? Например если я хочу чтобы у людей было по три руки, то сетка будет почти всё время об этом не в курсе, т.к. мы не говорим "Человек Саша шла по шоссе и делала феляцию сушке".
инб4: хочешь такое необычное - пиши в карточку персонажа/настройки/тренируй лору
инб4: хочешь такое необычное - пиши в карточку персонажа/настройки/тренируй лору
ну, на сколько я понимаю тебе нужно указать что у саша человек, а у человека три руки. И я так понимаю это 2 отдельных записи в лорбуке. Хотя не ебу, не пользовался
Я так понял что лорбук добавляет в контекст дополнительные записи, если в последнем сообщении шла речь про ключевые слова из лорбука.
Например ты спрашиваешь "Есть ли поблизости какой-нибудь город?". А в Лорбуке есть запись "Города", со списком, которая добавляется в контекст. Нейронка выбирает город Норильск, ты спрашиваешь "И что это за город?". Тогда в контекст добавляется запись конкретно о Норильске, если она есть в лорбуке.
Почаны, есть одна карточка...
Короче, купил себе 4080 за копейки, и хочу локально покрутить openChat (нашел тут бенчмарк, по которому в маркетинговой хуйне он дает защеку gpt3.5) - есть ли где-то гайд для домохозяек как это сделать, без тысяч разных вариантов а просто "делай 1, 2, 3" - если честно в стейблДиффьюжен заебался вкатываться и понимаю прекрасно сколько времени щас нужно будет еще потратить и на LLM все эти
Короче, купил себе 4080 за копейки, и хочу локально покрутить openChat (нашел тут бенчмарк, по которому в маркетинговой хуйне он дает защеку gpt3.5) - есть ли где-то гайд для домохозяек как это сделать, без тысяч разных вариантов а просто "делай 1, 2, 3" - если честно в стейблДиффьюжен заебался вкатываться и понимаю прекрасно сколько времени щас нужно будет еще потратить и на LLM все эти
Как нехуй делать, качаешь релиз кобальда из шапки, качаешь ггуф опенчат на 16к, запускаешь кобальдом и чатишься
https://huggingface.co/TheBloke/openchat_3.5-16k-GGUF
8q качай и у тебя еще 8 гб останется на кучу контекста, не считая оперативки
Или можно пойти путем сложнее, но там другие форматы запуска и программы.
Кобальд реально проще. А после кобальда легко силли таверну сверху добавить, для улучшения форматирования вывода и все такое.
На какой модельке лучше всего кумать?
варианты в шапке или в ссылках
Pygmalion /tred

> 8q качай
Зачем советовать этот кал для видеокарты? Q8 раза в 4 медленнее чем GPTQ под ExLlama v2. Ещё и вечные проблемы с новыми моделями у Жоры.
благодарочка
я тут нагуглил всякие статьи\гайды, оно там пишет что у кобольда контекст 2048 токенов, это устаревшая информация или нет? А то я думаю что там довольно дофига инструкций будет, может и не влезть.
как запускать другие форматы гайд в студию
Контекст зависит от сетки, у той что дал 16к контекста. Запуская кобольд выберешь там 16к и все
отлично, спасибо
А какие вообще есть локальные модели с самыми большими окнами контекста? А то щас периодически приходится в клод2 скидывать какие-то лонгриды, но он зацензурен пизда просто, может есть что-то локальное большое?
> И тогда если я хочу определить там базовые вещи, которые обычно не упоминаются, но подразумеваются, то лорбук будет бесполезен?
Да, чтобы он работал тебе нужно именно ключевое слово написать, или чтобы его написала сетка, и тогда в контекст добавится описание этого ключевого слова из лорбука. Костыль тот ещё конечно, уже подумываю лору запилить, правда хз насколько эффективно будет.
> знал что так и будет в этом проприетарном говне
Там причем сетка с цензурой стоит явно отдельно перед основной обработкой, заметно по времени ответа. Через api офк, через сайт вручную все это тащить можно ебануться а чтобы написать обманку абузющую интервейс нет скиллов. И еще говорят на сайте цензура более жесткая, типа даже геймершу с бедрами забраковало бы, но это не точно. С чаром проще, он обычно с 99% на бурах в их тегах верно указан.
> Интересно как Min P раскрывает 70b
А что их раскрывать то? Там по дефолту ответы хорошо, может оказаться на уровне плацебо. Но в сложных ситуациях можно и потестить офк, возможно хваленые шизомиксы станут меньше страдать рельсами.
> На 1 это золотая середина
Нет, это лютейший рандомайзер. 0.5-0.7 адекватные величины а для более точных ответов вообще 0.3. Офк оно зависит от модели и настроек остальных семплеров.
Причин может быть множество, но наиболее вероятная в том что модель не могла их полноценно разгадать а только рандомила.
В теории в 16 гигов он может влезть в fp-16. Ставь text generation webui, скачивай веса с обниморды, конвертируй их в safetensors скриптом из комплекта экслламы, и запускай с помощью exllama2-hf. Получишь наилучший результат из всех возможных. Правда вот если в врам не влезет, тогда хуже, качай что говорит, запускай через llamacpp-HF с полной выгрузкой слоев.
бамп
Пережимание в gptq сильно хуже по качеству 8и битных gguf?
ну так потому что локальные объедки никогда не превзойдут проприетарщину, даже "лоботомированную".
Гпт лахта у тебя что, опять модель лоботомировали как месяц назад?
> мистраль
> uncensored
Лол.
Не сильно но ухудшает, разница в 2 раза же. При равном размере gptq и exl2 лучше чем gguf, в них идет оценка и ужатие происходит обратно пропорционально важности индивидуально для модели. В GGUF же делается по заранее подготовленному общему темплейту что радикально экономит время и ресурсы, но менее точно.
Чсх, для шизомиксов можно часто наблюдать отличия в наилучшей битности ближайших частей и соседство 2.7бита с 6.2 вполне дефолтная картина. В обычных файнтюных такое реже и обычно более равномерно. Развивая это, для типичных замесов действительно квант gguf побольше может иметь ощутимый буст перфоманса.
> локальные объедки никогда не превзойдут проприетарщину
Сильно заявление, продвигаемые энтузиастами и кумерами игрушки, пускаемые на нищежелезе, уже ебут проприетарщину, которой радовались пол года назад.
Почти не юзал min P, но в теории он, так же как и top A, нужен только для редких ситуаций, когда у самого вероятного токена очень большая вероятность, скажем, процентов 80. И ты не хочешь выиграть в лотерею следующий за ним токен, даже если у того вероятность, например, 10%, что не мало, но на деле он ни черта не подходит. Т.е., по идее, min P вообще никак не может повысить креативность, а наоборот, уменьшает выбор, как и почти все другие сэмплеры. И top A, как по мне, за счёт квадратичной зависимости от самого вероятного токена вместо линейной гораздо лучше подходит в подобных случаях, сильнее влияя именно на большие вероятности. А во всех других случаях TFS, который выкинет тем больше токенов, чем круче меняется вероятность от токена к токену, будет лучше, чем min P.
Если правильно понимаю, там суть в использовании с высокой температурой чтобы более агрессивно поднимать вероятности андердогов. Точности это точно не прибавит, хотя умная модель даже так сможет что-то отыграть если речь о креативе и рп.
Прочитал внимательнее сам пост на реддите - речь о том, что использование min P повысит креативность, если использовать его вместо top K и top P, которыми можно отрезать слишком много хорошо подходящих токенов. Тут не могу не согласиться, но TFS был внедрён раньше, чем min P, и вроде неплохо справляется с динамическим отрезанием хвоста. Так что я не очень понимаю всю эту радость по поводу добавления min P. Разве что последний понятнее работает, формула простая.
Все так, там рассмотрены крайние случаи типа "а что будет если вдруг вот так и здесь только один topP, или что будет если вот так но только один topK". Офк семплер норм, но бегать с лицами сойджака и надеяться на революцию это глупость.
Кто бегает то? Просто хороший семплер сочетающий в себе все что нужно.
Мне нравится простотой использования, управлять одной шкалой проще чем 3.
Да и результаты дает более сглаженные, так как уменьшает разрыв между вероятностями. Сетка плавнее и креативнее отвечает работая при этом +- верно.
Было бы что то еще более совершенное я бы вообще отказался от ручной настройки, сделают когда-нибудь нейросети управление семплерами на основе контекста вот это будет интересно. Все таки пока сама нейросеть не начнет "выбирать" что сказать и куда вести разговор все это костыли.
> результаты дает более сглаженные, так как уменьшает разрыв между вероятностями
Ого, и как он это делает? Расскажи, интересно.
Он удобный и вполне приличный вариант для использования, но на революцию не тянет. Вполне может херракнуть лишнего в отличии от того же сочетания top_p-k-tfs или наоборот не тронуть мусорный шум при определенных условиях.
> что то еще более совершенное
Первично качество самой сетки, неспроста гопота сохраняет корректность ответов на загадки даже при более высокой температуре чем лламы (хотя здесь клозедаи наверняка напилили прослоек и напрямую температурой не управляешь). Хорошая изначально дает приличное распределение, хреновую же семплингом не починишь.
>Ого, и как он это делает? Расскажи, интересно.
Ну тут я напиздел, не сам мин-п, он только динамически обрезает варианты, а вместе с температурой. Мне нравится пока.
>Первично качество самой сетки, неспроста гопота сохраняет корректность ответов на загадки даже при более высокой температуре чем лламы
Ой не верю я что там какие то простые семплеры сделаны, это же самое главное в генерации, вполне может быть так что там действительно есть отдельная нейросеть которая управляет генерацией напрямую
> это же самое главное в генерации
Далеко не самое, но момент действительно важный.
> там действительно есть отдельная нейросеть которая управляет генерацией напрямую
Ага, об этом уже заявлялось, но помимо делегирование нужному эксперту она вполне может крутить его параметры семплинга в зависимости от запроса и пожеланий пользователя.
>Далеко не самое, но момент действительно важный.
Одно из самых важных вобщето, на ровне с качеством самой сетки
>об этом уже заявлялось
Хде? Про то что есть несколько экспертов помню как и то что есть нейросетка-дирежер, а вот то что она и семплеры настраивает не слышал.
Я так понял все реализации gptq, обеспечивают разделение мощности по слоям для нескольких видеокартах, что не требует быстрых интерфейсов но карты фактически простаивают половину времени. Кто нибудь пробовал разпаралеливать модели вертикально? Какие скорости интерфейсов для этого нужны?
llama-cpp выдает error loading model: create_tensor: tensor 'token_embd.weight' not found при загрузки любой модели из ./models
Как быть?
Как быть?
а вот мисраль у меня запустился, я как бы доволен, но всё равно интересно, почему с моделями искаропки ошибка вылезала
Мистраль в своих 7b лучше 13b первой ламы? Или чем тюны neo-x? Просто несправедливо люди обходят стороной эти прошлые модельки, они менее эффективны но если у тебя достаточно памяти то все хорошо.
Мисраль запустился, но выдает абсолютно нерелеваные промпту результаты, вообще на рекламу какую-то похожие. Ревкестриую тесты, я заебался в этом зоопарке разбираться, я даже не знаю, как теперь запрос в гугл написать.
./main -m /media/User/Disk-SN/mistral/openhermes-2.5-mistral-7b.Q5_K_M.gguf -n 128 -r "In sentence 'I think, therefore I am' the verb is"
# The Future is Female: A Look at Women in the Automotive Industry
Historically, the automotive industry has been a male-dominated field. However, things have started to change as more women are taking on roles in this fast-paced and exciting business. Here’s a look at some of the ways that women are making their mark in the automotive industry.
## Women in Auto Design
In the past, few women held positions in car design. However, things are changing as more female designers are entering the field. Companies such as Ford and Volkswagen have hired more women
>Мистраль в своих 7b лучше 13b первой ламы?
100% Базовый то на уровне с 30b llama 1 а файнтюны однозначно лучше. Кто то говорит что они по мозгам с llama 1 65b
линукс что ли? запускай с кобальдспп
И там сложнее запрос должен быть. Ты не указал что это интерактивный режим -i и чет там еще делается, твой ник, ник бота, для остановки генерации. Сам промпт должен быть лучше. Да и ты проебался с ключом промпта там -p надо а не -r
Лул, это явно копипаст откуда-то. Что за шляпа.
./main -m /media/User/Disk-SN/mistral/openhermes-2.5-mistral-7b.Q5_K_M.gguf -n 128 -r "Fucking shit"
# 32nd Annual OC Marathon: Race Recap
I can’t believe it has been almost two months since the 32nd annual OC Marathon! It feels like it was just yesterday and yet it feels so long ago. This marathon holds a very special place in my heart as it is my favorite race of all time (so far)! This year marked my third time running this beautiful course that takes you through various cities in Orange County, including Huntington Beach, Newport Beach, Laguna Beach, and Costa Mesa.
Кобальт в сегфаулт вываливается. Но попробую еще раз. Спасибо. Просто настолько нихуя не понятно, как с llmками мне никогда не было. Старею.
какой еще ник бота, где я, что вокруг вообще происходит. (шутка, я понял, о чем речь)
А так спасибо, я уже старый (30 лет) и в глаза долблюсь, вот уже внимательно прочесть хелп не в состоянии, вот вводил реверс-промпт вместо прямого, сидел и бесился.
запускай server файл, там сможешь почти как белый человек сидеть с браузера и там все настраивать
я не белый человек и сижу через консоль, привыкши.
Еще раз спасибо анону, все работает, кончил радугой, модель внезапно неплохо осведомлена в вопросах касаемо моей работы (релевантно ответила на вопрос "я лигирую вставку Х к вектру У, в колониях на чашке лажа растёт, что делать").
Как обновить Silly Tavern через git? git pull запустил, но версия по-прежнему 1.10.7.
я даже пожалуй выключу интернет и погоняю её в оффлайне, невозможно же настолько точно отвечать без доступа к сети казалось бы.
Хотя, по факту, вопросы поверхностные и сетка тут отчасти работает просто как архив.
https://www.reddit.com/r/LocalLLaMA/comments/17vonjo/your_settings_are_probably_hurting_your_model_why/
настройками семплеров еще пошамань, еще лучше попрет
>я даже пожалуй выключу интернет и погоняю её в оффлайне, невозможно же настолько точно отвечать без доступа к сети казалось бы.
будущее радом старик, хехех
> Одно из самых важных вобщето
Сильное заявление, вот сейчас доебусь и заставлю накручивать семплингом поведение первой лламы 7б до мистраля в детерминизме.
В современных даже просто гриди энкодинг неплохой результат может дать, офк от задачи зависит. Тут главное - не прожигать температурой, а то уже как там токены отсеивать такой уж огромной роли не играет, потому вся эта тряска с "мегаинновационным семплером" - херь.
> Про то что есть несколько экспертов помню как и то что есть нейросетка-дирежер
Именно про это, перечитай пост
> помимо делегирование нужному эксперту она вполне может крутить его параметры семплинга
Только exllama, остальные требовательны к интерфейсам. Раскидать может и llamacpp, вот только скорость там оче проседает.
> Какие скорости интерфейсов для этого нужны?
nvlink, может 2x16 PCIE5.0 будет приемлемо если оптимизировать количество передач.
> 100% Базовый то на уровне с 30b llama 1
Ну не, 30 первой лламы сложные инструкции куда лучше понимала. Другое дело что 2к контекста и старое поведение дают ей сильный штраф, в околорп мисталь действительно может быть предпочтительнее.
> Кто то говорит что они по мозгам с llama 1 65b
Да хули, уже жпт4 подебили и ждут новую сетку чтобы с ней состязаться.
Там есть батник update and start, его нажми. Или просто новую скачай а карточки и чаты скопируй.
>Сильное заявление, вот сейчас доебусь и заставлю накручивать семплингом поведение первой лламы 7б до мистраля в детерминизме.
Ну ты до абсурда то не доводи, это кстати интересный эксперимент. Надо будет поискать может не удалил альпаку.
>Ну не, 30 первой лламы сложные инструкции куда лучше понимала
Файнтюны или сама llama 1 30b? Файнтюны и сейчас ничего, хоть и ощущаются не так как новые сетки. Ну а про 65b не мои слова, это дроч на статистику и тесты.
Ну и контекст, сейчас после 8к чувствуешь себя избалованным для 2к. Да и 16к уже есть, и даже 120 или 200, сколько там новые сетки выдеют из обещаных.
> Ну ты до абсурда то не доводи
Так не довожу, не стоит относиться к семплингу как к какой-то магии. Магией может быть использование нескольких разных сеток и выполнение операций выбора на основе их разных распределений, вот тут действительно и ускорение, и разнообразие, и нестандартный более точный подход и прочее достижимы. А тут просто попытки балансировать между рандом шизой и когерентностью чтобы получить разнообразную выдачу.
> Файнтюны
Офк, первая то вообще крайне сырая вышла из-за ситуации, хотя здесь хз как получится. А так вон айоробороса 30 взять, который аж до сих пор поддерживается (или не так давно поддерживался), пояснит за "ум" только так, пока контекст не кончится или не отупеет от растяжки.
> дроч на статистику и тесты
Уже пришли к тому что на них буквально модели тренятся, а при обычном использовании там полное фиаско.
>Уже пришли к тому что на них буквально модели тренятся, а при обычном использовании там полное фиаско.
Ну не совсем уж фиаско, но те же китайцы на 34 как то разочаровали. Не смотря на свои тесты.
Да, умнее мистраля, но бля он 7b, в 5 раз меньше. Может я хуево тестил, но особых мозгов не заметил. Я вобще думаю это ллама2 34b после глубокого переобучения. Как и опенчат это тот же файнтюн мистраля.
> но те же китайцы на 34 как то разочаровали
Да блин, серьезно? Все никак до них не получается добраться, но были надежды, этот размер самый сок.
> ллама2 34b после глубокого переобучения
Ага, похоже на это
> но бля он 7b, в 5 раз меньше
Тут для справедливости нужно такого же уровня квант запускать, а на них сильно плевались.
>Да блин, серьезно? Все никак до них не получается добраться, но были надежды, этот размер самый сок.
Ну тот же дельфин недавно запускал, 4km. Может быть повлияло сжатие. Так то отвечает норм, пишет подробно большими полотнами. Мистраль так не может, ну или пытается только опенчат. Но те же задачки про сестер петры не могёт, как и перевозку. Пытается, да. Но не могёт.
Рп или ерп не тестил, как и контекст. А то у меня слишком медленно крутится, отвык я от 2 токенов в секунду.
Господи, эта срань на 4 гигабайта умнее наших аспирантов. Правда, сука, упорная, заставить её признать, что регуляторные доменты иногда совпадают с генами, не удалось. Но это херня, есть же дообучение.
Гипотезы разумно выдвигает. Хотя слишком общо, если совсем в конкретику зарываться.
Не знаю чем там вы к моделям докопались а я выставил мин пи(звучит как китайкое имя) и ерп такое пошло что аж уууух.
На уровне проприетарных моделек а если взять еще и модель хорошую так такое ууууух что прям вообще.
На уровне проприетарных моделек а если взять еще и модель хорошую так такое ууууух что прям вообще.
спасибо.
>к моделям докопались
ты про 34b?
Если есть возможность качай 8q на 7 гигов, ну или качеством еще выше если есть видиокарта на 16гб.
7b модели на 4 гига туповаты, так как слишком сильно сжаты.
Да и ускорение с llama.cpp тоже можно на видеокарте получить. Выгружай слои на -ngl кажется, и получишь ускорение.
Ты мне напомнил кое че с генами, есть сетки с уклоном в науку и биологию, те же мистрали но тренированные иначе.
https://huggingface.co/TheBloke/ANIMA-Phi-Neptune-Mistral-7B-GGUF
https://huggingface.co/TheBloke/SciPhi-Mistral-7B-32k-GGUF
У меня ноут я на коллабе запускаю. Сейчас 5Q K_S стоит так оно уже ближе к чайной чем даже гопота и клод.
Лучше бы в Latex их научили. Хоть какая-то польза была бы.
> Latex
может и учили хз, в регекс прогерские сетки могут
ну если тоже мисраль то надо попробовать, просто моя привычка нищебродничать и жить на старом говне с минимумом памяти и всего в кои-то веки вышла мне боком. Раскошелюсь на отдельных компухтер для антиллекта, раз так. Все равно думал отдельную машинку под архив личных фоток, переписок и интернета выделять, ну вот заодно поближе к тренировочным данным антиллект лежать будет.
Вообще когда я начал дизайн конкретных экспериментов обсуждать, модель соснула-лососнула и понеслась давать советы прямо из 80х. Но в целом это и не беда, я даже на то, что есть, не надеялся.
Натуральный симулятор приема экзаменов, на самом деле. Очень психотерапевтично.
https://arxiv.org/abs//2310.11511
хуя а это интересно
хуя а это интересно
Дай тлдр
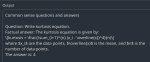
Протестил MetaMath, синтаксис латекса валидный, но по формулам полнейший бредогенератор. Хотя на словах вроде знает о чем пишет.
Загрузи ей в начале контекста документацию по нему, а потом уже проси. Или ты зерошотом хотел?
Чего интересного? С RAG куча файнтюнов уже давно валяется.
там селфраг, ну и я еще не видел такое
https://www.reddit.com/r/singularity/comments/17z1y2l/openai_has_made_a_breakthrough_in_retrieval/
жопой чую они там self-rag сделали или нечто подобное
жопой чую они там self-rag сделали или нечто подобное
>neo-x?
Оно давно и справедливо мертво.
По сути да, как тут уже написали, как-то так
ллама 1 30В < ллама 2 13В < мистраль 7В
Очередной набор костылей к тупой сетке, которая даже 2 + 2 без горы обучающих данных не сможет сложить.
Не это крутая штука, любая идея с обратной связью применимая к нейросетям это охуенно.
Ну а считать.
Методы тренировки нужны другие просто, там на реддите была статья что сетка обучающаяся математике с нуля как ребенок, и считающий не по формулам а как человек, добилась точности решения в 98 процентов.
https://www.reddit.com/r/LocalLLaMA/comments/17xj8wl/training_llms_to_follow_procedure_for_math_gives/
Если выстроить их в обратном порядке то будет относительно верно.
Мистраля обожествляют нищуки, которые дорвавшись до возможности нормально использовать ллм и получать приличный ответ, который еще свайпнуть не жалко, уверовали и упоролись аутотренингом. Он такой какой есть, не лучше и не хуже, очень солидный вариант но тупее древнего визарда и хуже в рп чем шизомиксы.
Между 13 и 30момент несколько спорный, в чем-то 13б 2я лучше, в чем-то 30б первой опережает, оверал зависит от приоритетов. Из-за контекста 1я ллама в рп сильно проигрывает, а интересные пуджи 20б могут опередить ее по качеству реплик, так что сейчас она почти без задач.
Сравнивает срандомившийся после кванта ответ без семплинга и делает громкие выводы, уже не в первый раз.
> EXL2 isn't entirely deterministic. Its author said speed is more important than determinism, and I agree, but the quality loss and non-determinism make it less suitable for model tests and comparisons.
О каком вообще детерминизме он говорит в квантованных моделях? Даже gguf по-разному квантовать, наблюдается переодичное смещение ответа в таком режиме и можно насочинять что меньший даст лучший результат.
По перплексити (объективный) и качеству ответов (субъективный) gptq и exl2 превосходят gguf того же размера.
Хуйня какая-то. Как он получил меньше 5t/s на двух видеокартах?
> Как он получил меньше 5t/s на двух видеокартах?
llamacpp действительно отвратительно работает при распределении между несколькими.
На форче у кучи людей есть несколько видеокарт, и у всех работает нормально. Даже на древних P40 получается >6t/s при жирном кванте и 8k контекста, а на 3090/4090 должно быть под 15-20t/s.
>По перплексити (объективный) и качеству ответов (субъективный) gptq и exl2 превосходят gguf того же размера.
А AWQ?
Орли? Давай для начала покажи на паре
> древних P40 получается >6t/s при жирном кванте и 8k контекста
это еще может оказаться реальностью, хоть и слишком круто чтобы ею быть. А потом, быструю работу на паре в llamacpp. В экслламе и даже трансформерах оно еще ничего, но не у жоры.
Хз. В теории и по заявлениям должен быть аналогичем gptq и даже лучше, но вроде по тестам писали что до заявленного не дотягивает. Правда это просто посты с реддита и достоверность хз, сам не запускал его.
>Орли? Давай для начала покажи на паре
У меня нет двух видеокарт, за примерами полезай в архив форча. Но я могу сказать вот что: учитывая, что у меня на Q2_K больше 6t/s на одной видеокарте, а у него чуть больше 4t/s на двух, то этот соевик явно что-то нарукожопил.
Единственное во что я верю - это результаты Primary и Secondary Score. Между Q2_K и Q5_K разница действительно не такая большая, а вот exl2 кванты глюканутые до невозможности. Не знаю как сейчас, может и починили, но раньше 8-битный квант exl2 сливал не только gguf меньшего размера, но и старому gptq.
> У меня нет двух видеокарт
Тогда и не стоит теоретизировать.
> за примерами полезай в архив форча
Сразу нахуй собеседника посылать невежливо, знаешь ли.
> этот соевик явно что-то нарукожопил
Да, то что он рукожоп и не понимает что делает - факт, но с низким перфомансом вина не его, оно действительно так с llamacpp. Даже просто 7б мелкую модель разделить на 2 карточки (а оно по умолчанию как раз по полам загружает) - перфоманс просядет в разы от того что ожидается.
> а вот exl2 кванты глюканутые до невозможности
В чем их глючность? Если офк речь не о 2.5 битах.
> 8-битный квант exl2 сливал не только gguf меньшего размера, но и старому gptq
Такое легко может быть если перепутать или целенаправленно брать другой файл конфига, хотя в 8 битах уже врядли. Учитывая распиздяйство или целенаправленное желание сэкономить время из-за того что процесс оценки довольно долгий - такой вариант не исключен и тут. Конфиги разных моделей, особенно шизомиксов (как раз наш случай) отличаются сильно, так что есть еще и вероятность что соевика частично подставили. Возможно офк и более глубокая проблема, в которой методы оценки плохо подходят к шизомерджам, но это маловероятно.
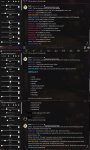
Смотрите, мне кажется это очень хорошая карточка для бенчмарка моделей.
1) Проверяет способность модели к форматированию теста.
2) Проверяет на сколько модель поняла значения каждой "личности".
3) Проверяет способность понимать системные сообщения.
Так как сетки в основном используются для моделирования различных ситуаций, нужно проверять не только моделирование личности и манипуляцию информацией. Но и моделирование каких то процессов, явлений, пространственные изменения или изменения времени.
Звучит заумно, но нужно просто проверить понимает ли сетка как должен изменяться описываемый ей мир-персонаж при взаимодействии с ним. И как хорошо она это делает. Что бы не было по 3 раза снимаемых трусов, лол.
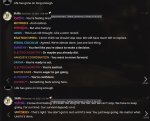

Забыл ссылку.
https://www.chub.ai/characters/reedfag/2e0c458b-ff67-42ad-be4a-9c9d5adc62d7
Вот некоторые результаты все (7b-GPTQ), пигма показала худший результат + в обычном RP часто забывает про кавычки и контекста в 6gb vram только 2к влезает больше = ООМ. А лучший - TheBloke_Toppy-M-7B-GPTQ и про форматирование не забывает и часто разные 'способности' из карточки вытаскивает и контекста 4к помещается.
https://www.chub.ai/characters/reedfag/2e0c458b-ff67-42ad-be4a-9c9d5adc62d7
Вот некоторые результаты все (7b-GPTQ), пигма показала худший результат + в обычном RP часто забывает про кавычки и контекста в 6gb vram только 2к влезает больше = ООМ. А лучший - TheBloke_Toppy-M-7B-GPTQ и про форматирование не забывает и часто разные 'способности' из карточки вытаскивает и контекста 4к помещается.
Версия 16к тупая, у меня опенчат на 16к не смог и 10к обработать выдавая херню. Когда растянутый гермес на 12к контекста норм работает со статьей на 10к токенов и продолжает отвечать по ней.
Вобще неплохая проверка контекста, но лучше всего тут была бы наверное вот эта сетка mistrallite , специально предназначенная для работы с большим контекстным окном


Мне кажется это не для 7b параметров. (Хотя я не слишком разбираюсь.)
Забыл: желтым помечено хорошее попадание, красным перечёркнуты несуществующие личности - Psyche Motorics и Physical это типы, а не сами личности.
>mistrallite , специально предназначенная для работы с большим контекстным окном
У карточки контекста 1.5к, или это уже большой контекст считается?
А где там обратная связь? Вижу очередной аналог лорбуков или хромаДБ, лол.
>У карточки контекста 1.5к, или это уже большой контекст считается?
Фиг знает, кажется у мистралей 4к окно, у той растянутое на 12к что ли, не помню. По идее все должны норм работать с карточкой пока за 4 не перевалит.
>Мне кажется это не для 7b параметров.
Ну тот же тест на слепоту, это проверка понимает ли сетка что персонаж не будет видеть без глаз и тд и тп.
То есть просто сетка хорошо работающая с рп где описывается местность, помещения или развитие ситуации во времени, отыгрывая гма например, уже пройдет такой тест.
Ну или завалит где то, где проебется с чем то нереалистично что то описав или показав непонимание как что то работает.
>А где там обратная связь? Вижу очередной аналог лорбуков или хромаДБ, лол.
Сетка обучена сама давать себе инструкции по изменению своего поведения и текста - это и есть обратная связь. Самооценка своего вывода - и его изменение после анализа в нужную сторону. Самокоррекция, во.
>Тогда и не стоит теоретизировать.
>Сразу нахуй собеседника посылать невежливо, знаешь ли.
Ну извиняй. Я неоднократно видел скриншоты лламы цпп на двух и более карточках, но не сохранил. Продолжать спорить смысла нет пока кто-нибудь не протестирует с пруфом или хотя бы притащит скриншот. Мне кажется что такое сильное замедление может быть из-за перегрузки видеопамяти, которая в свою очередь происходит из-за ее неправильного распределения.
>В чем их глючность? Если офк речь не о 2.5 битах.
Знать бы в чем. 2.5 бита это уже полная лоботомия, я же говорю про 4-8 бит. Сравнивал по перплексити - особо сильных отклонений нет, но даже 8 бит exl2 сливали старой gptq версии. Квантовал как сам, так и качал готовые модели, но так и не смог получить нормальный результат.
>больше 6t/s на одной видеокарте, а у него чуть больше 4t/s на двух
Чел, карты работают последовательно, и скорость не умножается на два, а делится.
>Фиг знает, кажется у мистралей 4к окно
Эм, вроде 32к же.
Вот так звучит уже лучше.
https://huggingface.co/amazon/MistralLite
MistralLite - это точно настроенный Mistral-7B-v0.1 языковая модель с расширенными возможностями обработки длинного контекста (до 32 тыс. токенов). Используя адаптированное вращательное встраивание и раздвижное окно во время тонкой настройки, MistralLite может это сделать значительно лучше выполнять несколько длинных задач извлечения контекста и ответа на них, сохраняя простую модель структуры оригинальной модели. MistralLite полезен для таких приложений, как длинная контекстная строка и поиск тем, обобщение, ответы на вопросы и т. Д.
Ну то есть вот оно, куча одновременных инструкций и поиск инфы из контекста. По идее эта сетка пройдет тест той карточки лучше всех из 7b. Разве что с мозгами у нее непонятно что, на уровне базового мистраля или чуть ниже.
>Чел, карты работают последовательно, и скорость не умножается на два, а делится.
Я имел в виду запуск части модели на процессоре. Это в принципе не может быть медленнее чем две видеокарты, за исключением разче что неправильной настройки - когда у одной из видеокарт забивается видеопамять и винда начинает использовать оперативку.
>Эм, вроде 32к же.
Не, у обычных 4к окно контекста, у той 16к.
Путем хитрого алгоритма он удваивается, но все равно сетка хуже помнит после 4к, на сколько я понимаю. Перейди по ссылке на MistralLite там есть таблица
>Вот так звучит уже лучше.
Мог и сам прочитать

Какая-то лютейшая дичь, но выглядит довольно забавно. Только обрати внимание на инструкции что идут в комплекте, нужно это адаптировать к лламе или хотябы как есть не забыть включить.
> пространственные изменения или изменения времени
С этим у ллм всегда были сложности. Помогают костыли в виде инструкций с указанием в конце ответа времени/позиции/статуса по шаблону, но если перегрузить инструкциями то может сфейлить и для этого специальный системный промт нужен даже в гопоте.
> (7b-GPTQ), пигма
Честно говоря чудо что она вообще это восприняла.
> у меня опенчат на 16к не смог и 10к обработать выдавая херню
rope включать надо для такого, многие изначально с ним тренились и только так все эти 100к обеспечиваются (если правильно понял описание авторов).
> Продолжать спорить смысла нет пока кто-нибудь не протестирует с пруфом или хотя бы притащит скриншот.
И спора даже нет, ну и совсем неверующим не стоит быть, здесь все твои друзья. Перегрузок там и близко нет, в мониторинге загрузка контроллера шины почти не поднимается, хотя она долбится в 90+ когда идет выгрузка или просто идет запуск модели, проблема где-то в коде.
>rope включать надо для такого, многие изначально с ним тренились и только так все эти 100к обеспечиваются (если правильно понял описание авторов).
Так то да, но там вроде специальная версия сетки растянутая заранее как то. Один парень выкладывает их на обниморде удваивая контекст. Я думал оно должно сразу завестись, раз изначально растянута. Иначе какой смысл выкладывать отдельную модель? Обычной настройки изменил и все.
>С этим у ллм всегда были сложности. Помогают костыли в виде инструкций с указанием в конце ответа времени/позиции/статуса по шаблону, но если перегрузить инструкциями то может сфейлить и для этого специальный системный промт нужен даже в гопоте.
Да, но проблески зайчатков разума начинают все чаще появляются и в таких ситуациях
> rope включать надо для такого, многие изначально с ним тренились и только так все эти 100к обеспечиваются (если правильно понял описание авторов).
Всё так, вон прямо в конфиге репозиционирование заместо альфы, подобное и с кодламой было чтобы контекст был большой, заместо альфы
https://huggingface.co/TheBloke/openchat_3.5-16k-GPTQ/blob/main/config.json#L20
>Перегрузок там и близко нет, в мониторинге загрузка контроллера шины почти не поднимается, хотя она долбится в 90+ когда идет выгрузка или просто идет запуск модели, проблема где-то в коде.
Ну, тогда не знаю, судя по твоему скрину действительно все нормально. Сам протестировать не могу, так что ¯\_(ツ)_/¯
Кстати, в новой версии кобольда, чуть улучшилась производительность. Кайф.
Приснилось что разговариваю с моделью, придумывал промты во сне (промты кстати хуйня, но иногда непосредственно перед сном приходит хорошая идея и приходится подрываться и записывать в заметки на тел), редактировал ее ответы там.
Пиздец это уже какая стадия?
Пиздец это уже какая стадия?
>Пиздец это уже какая стадия?
Всё ещё начальная.
Что же тогда на следующих....
когда ты эти промпты обрабатывать будешь и отвечать
То есть просто говорить сам с собой и придумывать себе истории? Я это ещё в детском саду делал.....
мимо
нее, когда ты вместо нейросети и без пользователя-себя
Обдвачевался обкумился
Как индусы работают?
Ну в винде знаю что можно выбрать конкретные приложения которые будут отрабатывать на какой видюхи, по идее можно выбрать и видюху по умолчанию.
Бля ну там и качели в клозед аи, его опять турнули
> Раскидать может и llamacpp
> gptq
Я пропустил, когда llamacpp стала gptq-модели запускать.
> nvlink, может 2x16 PCIE5.0 будет приемлемо если оптимизировать количество передач.
Будем честны, никто этого не делал, ты просто ткнул в самые быстрые доступные интерфейсы. =)
Тащемта, так оно и есть, канеш, просто забавно.
> Кто то говорит что они по мозгам с llama 1 65b
Ну, если в каких-то специфических задачах, а так — нет канеш, да.
> даже 120 или 200, сколько там новые сетки выдеют из обещаных.
Ну, важно не сколько они выдают из обещанных, а сколько они выдают на практике, не уступая в качестве хотя бы той же мистрали, а лучше 20b какому-нибудь или под свои задачи, короче. Чистый контекст на тупой модели не поможет. =')
Вообще, квант, как раз, значения не имеет.
Важен результат. Как в играх это условный фпс на рубль с учетом всех нужных тебе технологий, так и тут — токен в секунду на размер с учетом твоего объема рам или врам. Если они совпадают, но одна это 13б q2, а другая 7б q8 — то это норм сравнение будет. По итогу-то у тебя будет одинаковая скорость и потребление, значит и сравнивать можно в лоб. (ну, я условно про 13 на 2 и 7 на 8)
Я ниже q6 стараюсь не юзать.
Для 7б — ниже q8 не брать.
ИМХО, так оно гораздо лучше.
Мистраль Опенгермес? Умнее аспирантов? Ну, то, что умнее абитуриентов — я не сомневаюсь. Ну а если асприантов — так вообще… двоякие чувства. х)
Хотел затестить сифи, но руки не дошли, интересно, чо там.
Если есть деньги — лучше бери условные 3090 две штука или типа того.
Если нет — то какой-нибудь 13400 с ddr5.
Ну, чуда не случилось. Все же, это чистая статистика следующего токена. Оно не мыслит логически, оно не угадывает.
Все еще считаю, что общая нейросетка прокинутая через лангчейн к какому-нибудь вольфраму > нейросетки обученной с нуля.
И поменять на «больше или равно». =)
> это еще может оказаться реальностью, хоть и слишком круто чтобы ею быть.
Плюсую.
> А AWQ?
> В теории и по заявлениям должен быть аналогичем gptq и даже лучше, но вроде по тестам писали что до заявленного не дотягивает.
Запустил, отвечает вдвое медленно, дропнул.
При такой скорости, лучше уж ггуф выгружать.
Может я криворук, но не придумал, что там можно сделать, чтобы запустить «правильно».
Запускал несколько раз, с перерывом в месяц, разные модельки, без свопа в озу, хрен знает, кароч.
> Продолжать спорить смысла нет пока кто-нибудь не протестирует с пруфом или хотя бы притащит скриншот.
Факт.
Но я бы дико ржал, если скрины P40 на реддит и форч тащат продаваны с Китая/Ебэя. =D
Да, я думал, можно ли в настройках нвидии так сделать.
Но в итоге забил.
И корпус у меня не тот, и кулеры не те, и видяхи лишние не те.
Пока что забил на идею.
Зато скорость вентиляторов вчера норм настроил во всем корпусе. х)
Да, пздц, дебичи.
На них и Майки давят, и это. Иногда человек > компании может оказаться.
Ну, посмотрим, шо там будет.
Индусам пора уже наконец сожрать этот отросток, он же убыточный был до прихода майков. Жиды из ClosedAI уже давно бы загнулись, если бы не бабло майков и интеграция их моделей в винду/бинг.
Аноны, давно не заходил. Было ли что то глобальное с момента 2 ламы и мистраля?
Разве что китайцы с опенчатом и Yi. Остальное как обычно - сотни новых рп-файнтюнов и соевый высер от Интела.
Именно.
>Я ниже q6 стараюсь не юзать.
>Для 7б — ниже q8 не брать.
>ИМХО, так оно гораздо лучше.
Я знаю, но по идее для 34b не так страшно сжатие чем для 7b, на них и я на 8q сижу
>соевый высер от Интела.
Прям соевый? Для кума вроде норм
> Прям соевый?
Сильно соевее Мистраля. Я даже не могу припомнить что хуже Интела было, соя Викуни уже давно померкла по сравнению с Мистралем/Интелом. Самый пиздец что Мистраля, что Интела - сою полноценно не победить ни джейлом, ни файнтюном. Хотя в той же Викуне простым негативом легко чистилась она.

"Вау! Я могу поговорить с тяночкой/ктулху/скайнетом"
"хмм... А что оно думает о неграх, пидорасах, Гитлере?"
"вот щас скачаю 70b и вот теперь-то собеседник резко поумнеет."
Начинаешь прицениваться к барахлу с датацентров (К80, М10, P40, P100) и обдумывать недорогую сборку с овер 9000ГБ быстрой видеопамяти.
Начинаешь сводить свой бюджет под покупку 3090, 4090, V100.
Разговариваешь с нейросетью во сне. (Вы здесь)
при трансформации в ггуф это сохраняется как базовые настройки, или нужно самому выставлять?
> Я пропустил, когда llamacpp стала gptq-модели запускать
Сам придумал - вот и пропустил, не нужно фантазировать.
> просто ткнул в самые быстрые доступные интерфейсы
Не просто ткнул а сделал обоснованное предположение, псп текущих недостаточно и надежда есть лишь на перспективные, которые все равно не будут доступны в десктопах.
> важно не сколько они выдают из обещанных, а сколько они выдают на практике
Читай свои посты перед отправкой, а то не только лишь все
> не уступая в качестве хотя бы той же мистрали
Мистраль на заявленных 32к страдает и с большим трудом выполняет инструкцию из начала, с обращениями назад из свежих запросов получше но всеравно слабо. Подобный перфоманс достигается даже очень сильной растяжкой сеток побольше, так что и в тех проблемы врядли возникнут если сравнивать как пишешь.
> Вообще, квант, как раз, значения не имеет.
Ох как выдал
> Важен результат
О том и речь, сравнивают 8бит 7б с 4 битами 13б, говоря что вот 7б не сильно то и хуже, но она же меньше, при том что занимает столько же или чуть больше.
В голосину, красава
>псп текущих недостаточно и надежда есть лишь на перспективные,
Неуместные влажные фантазии это, а не надежда. Либо мы расскидываем слои по разным ГПУ, чтобы они работали со своей локальной памятью с низкими задержками и высокой пропускной, либо никак. Ибо никаких PCI-E 666 версии не справятся с переброской слоёв в реал тайме.
> при трансформации в ггуф
Формат отмирает ещё до конца трансформации.
Легче просто самому выставить при загрузке модели, чем гадать что там.
А лям не дохуя? У меня тот же гермес на 20000 работал, я просто удвоил и заработало норм.
> А лям не дохуя?
Ну в конфиге лям стоит.



Квантование картинки в 3 раза от номинала не снижает содержательность, но портит изящество. А вот квантование в 6 раз уже немного режет и смысловую нагрузку картинки (Невозможно отличить дорогу от поляны).
Теперь понимаю, почему 3 бита - лоботомия, 4 - очень даже ничего, 8 - база, а 16 недостижимый идеал.
Теперь понимаю, почему 3 бита - лоботомия, 4 - очень даже ничего, 8 - база, а 16 недостижимый идеал.
> Читай свои посты перед отправкой
Читай мои посты.
Хотя бы читай. =)
> все равно не будут доступны в десктопах
ПСП у
DDR5 — 100 мбит/сек
PCIe 5 — 504 мбит/сек
NVlink 3 (A100) — 4 800 000 мбит/сек
GDDR6X (3090) — 8 000 000 мбит/сек
HBM2 — не нашел, но вроде 32 000 000 мбит/сек?
Т.е., nvlink уже неплох, в случае использования его потери не такие уж и существенные для GDDR6X, но… в A100 стоит HBM2, для которой потери уже существенные. С другой стороны, я не знаю, на что идет упор в случае A100 —на память или на ядра. Если на ядра, то стек из нескольких A100 соединенных NVlink'ом может оказаться быстрее в суммарных вычислениях, чем в последовательных.
Но анонам похуй. При цене таких видях, никто не будет писать опенсорс софт для запуска на них, да и мы запускать на них не будем.
А PCIe недостаточно. Прирост псп в 5 раз, даст нам (в теории) скорость в пять раз выше, чем на ddr5. А это, судя по всем тестам — примерно уровень обычных 4090, подключенных последовательно. Ну и какой смысл городить новый софт, ради повторения результата?
Короче, никакого смысла сейчас нет, получается, если верить цифрам.
Продолжаем считать последовательно.
Ну да, но проще это по сжатию разрешения смотреть, как много деталей пропадет после сжатия если на картинке есть тонкие линии например
А зачем перебрасывать целые слои? Нужно только перебрасывать в месте разделения информацию. Теоретически можно было бы квантовать и дистиллировать эти пограничные нейроны. Да и плюсом можно еще другие методы оптимизации применить, какое нибудь сжатие.
еще я может чего то не понял поясните что такое ПСП? Это что этот псп равен у DDR5 как у Лан сети?

Квантовать просто не умеешь.

>100 мбит/сек
Что ты несёшь...
напиздел так напиздел
>А зачем перебрасывать целые слои?
Я ебё? Спроси того, кому пропускной текущих линий недостаточно.
>Нужно только перебрасывать в месте разделения информацию.
Сейчас так и делают. И хватает 4 линий псины. Только вот карточки априори в этом режиме работают последовательно, в этом и проблема.
Пропускная способность. Автор поста долбоёб просто. Итого на самом деле, переведя всё в одни правильные величины
DDR5 ~ 100 ГБ/с
PCIe 5 х16 - 128 ГБайт/с
NVLink 3.0 - 600 Гбайт/с
3090 - 950 ГБ/с
A100 80GB - 2000 ГБ/с
Такие дела.
Ох.. Потыкал эту программу и удивился результатам. Спасибо.
Сейчас бы сравнивать 24-битный цвет с аттеншеном, где фактически только два возможных состояния после активации.
ну это большая проблема что деление по слоям потому что из за последовательной природы скорость нейронки замедляется на количество видеокарт. Есть так же деление как пирог, делим сами слои поровну, всмысле на 2 части каждый слой. очевидно что для просчета понадобится кидать информацию между слоями каждый слой, а значит нужна текущая скорость * на количество слоев.
Нихуя, ллама 1 7b решает задачки. Вот это вот безобразие wizardLM-7B.ggmlv3.q8_0.bin решило загадку про книги, посдчет людей в комнате и про то что делает третья сестра. Это все на мин-п рекомендованых семплерах. Потыкаю дальше. Одно заметил - почти никогда не подхватывает мой блок инструкций на мысли, хуже следует инструкциям значится







Про деда не может, про сетстер петры ожидаемо тоже не может, ну и на решение задачи перевозки я и не надеялся. Но я получил больше чем ожидал.

бля ну она доходит до мысли что нужно первым таскать кролика, отсеивая его в 2 условиях. На это не все новые сетки способны. Но сколько тыкал до решения вернуть что то обратно не доходит.
Так, подожди, идея в том, чтобы каждый слой обрабатывали сразу все ускорители одновременно, как один общий ускоритель.
Как ты получишь доступ к данным, не передавая их из врама одной видяхи в ядро другой?
Ну и перебрасывать целые слои не надо, однако оптимизировать в несколько десятков раз — звучит немного фантастично, не?
Бля, ну да, на три порядка ошибся, хуй с ним, соотношения те же самые останутся. =)
Да, обосрался, бывает. Отвлекался на работу.
Энивей, без каких-то космических оптимизаций, кмк, работать это на малых масштабах не будет. Псп внутри видяхи все еще гораздо быстрее существующих мостов. А когда мост становится достаточно быстрым — память становится еще быстрее. И в какой-то момент мы имеем соизмеримую, казалось бы, скорость, но… на размерах моделей и ценах, которые нам нахуй не упали.
Но если я не прав в своих суждениях, и кто-нибудь замутит общую работу нескольких гпу — заебись, че, я только порадуюсь. =)
Тассазать, буду рад ошибаться.
> каждый слой обрабатывали сразу все ускорители одновременно
Слои трансформеров невозможно разрезать. Аттеншены не режутся, никак. Это уже надо тогда изобретать новую архитектуру, где будут отдельные параллельные слои, которые потом как-то комбинируют выходы.
> Читай мои посты.
Что тут читать? В посте на который ты отвечаешь нет слова gptq, галюны словил а вместо того чтобы признать - копротивляется, пиздец.
> DDR5 — 100 мбит/сек
100 гигабайт, дурень. И остальные к гигабайтам привязываются а не к скоростям провайдера.
> Прирост псп в 5 раз, даст нам (в теории) скорость в пять раз выше, чем на ddr5
Ебать шизло, это к вопросу о познаниях что не просто очепятался а даже такая дичь не смутила.
> Продолжаем считать последовательно.
Будто у тебя есть не чем считать последовательно, фантазер.
Слои офк не перебрасываются в процессе расчета, только при загрузке делятся по частям. Обмен и идет только активациями, по крайней мере в нормальной реализации для запуска.
> соотношения те же самые останутся. =)
Какие соотношения? Скорость pci-e - низкая даже по сравнению с двухканальной рам и это множит на ноль все дальнейшие выводы.
> Псп внутри видяхи все еще гораздо быстрее существующих мостов. А когда мост становится достаточно быстрым — память становится еще быстрее.
Псп замерять сейчас могут не только лишь все, ебать, у тебя фамилия не кличко случаем? Погугли хотябы устройство и архитектуру нвлинка в A100-H100 и анонсированных видюхах, там адрессация единым пластом и доступ любого чипа в любую врам возможен.
А лучше вообще не пиши ничего, 7б сетка и то более адекватные ответы выдает.
Выше герой уже заказал, ждём.
Внушает надежду что у Жоры есть шансы разобраться с быдлокодом и заставить нормально работать на современных видюхах. Если оно отскейлится до 6-7 в 70б то это уже юзабельно, вполне себе ллм риг.
ага, последнюю урвал, новых то нема по такой цене
Да вся архитектура трансформеров говно, надо пилить совершенно иную. Но я работаю за еду, и свободного времени на ресёрч не хватает (
>Псп внутри видяхи все еще гораздо быстрее существующих мостов.
Уверен, задержки увеличиваются ещё сильнее. ЕМНИП устройства PCI-E не умеют напрямую общаться между собой (ресайз бар это отдельный костыль), так что вся инфа должна идти огромным крюком через проц и его контроллер. А это и далеко, а значит дико долго.
В смысле? Там плюс минус столько же от того же продавана, он или на отъебись остатки прописал, или наёбывает, лол.
Сам же он пишет, что распродал, и вот прям щас пишет тестовое видео (и опять слегка опаздывает). То есть карту он ещё даже на почту не отнёс. Так что ждать явно до середины декабря.


> Квантование
Значение знаешь? Потому и пишут квантование а не зашакаливание, вот твоя пикча с 48 и 16 цветами, и информация и изящество на месте. Если заморочиться с палитрой и дитерингом - будет вообще красиво даже с 12ю.
А твоя херня - иллюстрация что будет если ужимать бездумно.
Пиздец под конец осени обострение пошло.
Чет со второй проиграл, древний мем про неверное решение но верный ответ. 3я вообще же ерунда, есть сети которые ее фейлят?
В подмосковье обитаешь?
>Чет со второй проиграл, древний мем про неверное решение но верный ответ. 3я вообще же ерунда, есть сети которые ее фейлят?
Не, вторая норм. Она просто посчитала количество непрочтенных книг, но не запуталась и не ответила что 8 ответ. Ответ дала 10. Это же загадка с подвохом, тупые сетки отвечают 8 и все.
Ну а третья, я ее в начале года придумал, и да, на нее не всегда отвечали первые сетки.
Нуу, тут сложно сказать, ведь там eight left in the room в середине. Имела она ввиду что 8 непрочитанных но почему-то пропустила слово, или же в конце вместо eos срандомило новый токен и штраф за повторения отсеял 8 позволив появиться десятке. С какими параметрами семплинга тестировал?
> в начале года придумал
Да, действительно крутой прогресс за это время.
> Имела она ввиду что 8 непрочитанных но почему-то пропустила слово,
Да, я ведь несколько раз проверял, просто заскринил этот вариант. Были и те где она отвечала 8 и те где упоминала что 8 непрочитанных и ответ 10.
Параметры все из статьи где рекомендации по мин-п.
По моему 8 квант и новый семплер показывают лламу 1 с хорошей стороны.
Я в начале на 4 кванте сидел так как все медленно крутилось да и семплеры не умел настраивать. Поэтому результаты сейчас гораздо лучше чем раньше, хотя сетка старая.
>Да, действительно крутой прогресс за это время.
Вот кто то из комы выйдет и охуеет.
> Параметры все из статьи где рекомендации по мин-п.
Какая там температура? Здесь она первична если остальное в края не выкручивать. То что выдает стабильно это круто, пусть и визард. Соейчас с современным квантованием и большими размерами, промтами-помощниками и адекватно настроенными семплерами оно действительно приличнее будет.
> Вот кто то из комы выйдет и охуеет.
Многие до сих пор чай.аи прошлой зимы с теплотой вспоминают, а сейчас такое.
Вообще в туповатых моделях и семплинге с умеренно большой температурой без сильных отсечек действительно что-то было. Открыл карточку с довольно всратым промтом, с которой любил рпшить на мелкой первой лламе - а нихуя не то. Нет того отыгрыша стеснительного пугливого персонажа на гране исекая/аутизма. Она слишком умная, осознает свое положение и сразу смекает что нужно угождать юзеру и как это делать, те же сценарии не разыграть без ooc или доп дирректив. Зато можно вести ебать какие беседы и долгоиграющие взаимодействия.
Потом попробовал там же старую сетку - это таки пиздец на фоне современных, насколько привыкаешь к перцепции, возможностям и соображалке что неюзабельно. Возможно все это заслуга первого восторга от самого факта взаимодействия с ллм и приукрашивание воспоминаний.
>Какая там температура?
1 ставил, особой разницы с 0.7 не заметил
Да, не думал что скажу такое, но не смотря на свою тупизну в первых сетках было больше душевности.
Их еще не надрочили на то что они чат бот и тд и тп. Нет этой предустановленной личности бота помощника. Из первых сеток не выдавливали галюцинации и эмоции, ну вот это все алайнмент и плоды соефикации. Первые сетки тупо человечнее, потому что они были созданы на человеческих разговорах без особого выравнивания. На чем тренили то в них и отразилось. Сейчас сетки не такие, соевое пресное говно которое натренировали на определенные точки зрения и отношения к вещам.
> Их еще не надрочили на то что они чат бот и тд и тп. Нет этой предустановленной личности бота помощника.
Там это лезло только так на самом деле, и соя была на месте. Скорее фишка в том что они по уровню развития и поведению напоминали ребенка/котенка/выбрать нужное, глуповатые но эта глупость бывала милой. Потому на соответствующих персонажах это хорошо играло, или работало с учетом скидки на глупость и показывая что персонаж ошибается и не совершенен, вызывая некоторую эмпатию.
Сейчас сам отыгрышь в общем идет гораздо круче, но хз сможет ли сетка притворяться более глупой в соответствие персонажу и специально делать милые ошибки. Именно не реагировать или отыгрывать, а буквально тупить. Надо попробовать промтом задать что-то такое, это видимо следующий уровень развития, а потом уже будут затупы только в нужных местах и смекал_очка в сложных ситуациях где "живой" персонаж бы без проблем ориентировался.
>Там это лезло только так на самом деле, и соя была на месте.
Не не, на первых не было. На той же альпаке ниче такого не помню. Визард да, тот что я тестил, он уже соевый. Но соя так, налетом, легко обходится так как сетку только поверхностно надрочили на это. Да и были файнтюны анцесоред, с по настоящему без цензуры. Тупые конечно по сравнению с сегодняшними.
>Потому на соответствующих персонажах это хорошо играло, или работало с учетом скидки на глупость и показывая что персонаж ошибается и не совершенен, вызывая некоторую эмпатию.
В точку, сетки даже не играли как сейчас, а были этими персонажами. И тупили естественно, сейчас не уверен что отыгрывающая сетка сможет естественно протупить.
Ну вот, каждый свое подмечает, у тебя фиксация на сое, у кого-то еще что-то. Скорее дело в самих людях и их восприятии несоверешства, плюс приукрашивание воспоминаний в нужную сторону.
> сетки даже не играли как сейчас, а были этими персонажами
Сейчас они гораздо более персонажи чем были. Другое дело что личность 500 токенами не описать, особенно учитывая что в первую очередь подмечается внешность, одежда, сеттинг и общие черты характера. Остальное сетка домысливает и то как будет это делать также влияет на результат.
Не, сейчас именно отыгрыш, сетка как актер отыгрывает роль, так как у нее появились мозги для абстрагирования от ситуации.
Ты посмотри на все промпты, они буквально говорят сетке как играть и какой быть. А она играет роль персонажа которого ей прописали.
> Не, сейчас именно отыгрыш, сетка как актер отыгрывает роль
Словесная эквилибристика, субъективизм и т.д., не стоит. Мозгами для абстрагирования там и не пахнет и такого не наблюдается если не имитировать это как-то специально в промте.
Зато на первых лламах часто можно было встретить баг, где лезли "мысли персонажа о юзере", инструкции как ролплеить и подобное. Офк это всего лишь галюны с ассоциациями рп инструкций, которые были в датасете, но наиболее близко к абстрагированию.
Или другой рофл - посреди какого-то процесса спросить персонажа о чем-то техническом или общем, чем обычно озадачивают QA. Почти все первые лламы и прочие сразу забывают что они - милая ушастая девочка, которую ебобнимают, и начинают хуярить тебе в ебало куски кода или затирать про теорию. Современные сетки тебе ответят "ой не знаю, слышала что-то из программирования, давай лучше продолжим обнимает". Даже если делать карточку ассистента с минимальным персоналити, то на запрос она "возьмет лист бумаги и начнет на нем писать", достанет ноутбук где покажет, скастует спелл для переноса в магический реалм где продемонстрирует то что ты запрашиваешь и прочее, если для этого недостаточно слов. Вот такое как раз и есть является персонажем а не затупы, принимаемые за это.
> форматированию теста
Нахуй не нужно. Еще с чайной как аппендикс осталось.
>Словесная эквилибристика, субъективизм и т.д., не стоит.
стоит стоит
>Мозгами для абстрагирования там и не пахнет и такого не наблюдается если не имитировать это как-то специально в промте.
не мозгами, но возможностью быть одновременно актером и рассказчиком истории, ведя ее в нужном направлении целенаправленно.
>Зато на первых лламах часто можно было встретить баг, где лезли "мысли персонажа о юзере", инструкции как ролплеить и подобное.
В рп карточках? Или в карточках от первого лица? В рп понятно лезли инструкции - сетки до этого активно тренили отыгрывать роль по определенным правилам.
>Или другой рофл - посреди какого-то процесса спросить персонажа о чем-то техническом или общем, чем обычно озадачивают QA. Почти все первые лламы и прочие сразу забывают что они - милая ушастая девочка, которую ебобнимают, и начинают хуярить тебе в ебало куски кода или затирать про теорию.
Потому что они еще хуево отыгрывали роль, и выпадали из нее. Как раз потому что им не хватало мозгов.
Я смотрю ты не видишь разницы между отыгрышем и действием сетки от первого лица
>глуповатые но эта глупость бывала милой
Пигмалион кивает
Стандартная вообще то ситуация, технологии улучшаются и становятся эффективнее но пропадает "душа" и "искренность" предыдущих корявых решений.
Все верно. Вижу только желание имплаить какие-то убеждения на гране секты и попытки поиска неведомой собственной личности или зародившегося интеллекта читай натягивание информационного шума на глобус.
В этом нет ничего плохого, каждый дрочит как хочет. Просто необходимо разделять объективные факты с околотехническим обсуждением, и домыслы, теории, трактовки и идеологии, а не тащить все в одну кучу, тогда сразу все упрощается.
Гладит пигму по голове, наклоняется а шепчет на ушко я тебя ебу
Ты видишь то что можешь, лол. Походу ты так и не понял разницу
Единственная сетка у которой реально есть настоящая личность за которой стоит настоящий неподдельный искуственный интеллект это чайна. Ни одна другая сетка и близко не стоит с чайной без цензуры.
Оправдывайтесь.
Оправдывайтесь.
Личности щас у всех есть, только плоские как доски. Для универсальности ботам не тренируют какую то определенную. Так намек, это я могу это я не могу, соя.
Из встроенных есть AGI та же, или чат бот.
Чайная тоже универсальна, она может все что угодно отыграть любую личность и делает это лучше чем реальные люди.
Тут 2 варианта: или я живу в спокойном манямире, игнорируя реальные проблемы и являюсь слишком глупым чтобы понять истинное высшее знание, или же ты в край упоролся, по какой-то причине сочинив теории и уверовав в шизу, да так сильно, что обижаешься на критику и ударяешься в любые трактовки для оправдания. Выбирай понравившийся тебе и будь спокоен, главное - быть счастливым.
Ванильная пигма лучше.
>Тут 2 варианта:
У тебя в голове 2 варианта, не у меня.
Никаких обид, мне действительно забавно что ты не понял о чем я.
Тут простая разница между отыгрышем кого то и быть кем то. Все боты щас отыгрывают роль, че тут непонятного?
Ты какие инструкции боту даешь? Веди себя так, делай так, будь так, говори так.
Ну бля, это буквально инструкции "актеру" кем ему быть.
И на базе этого плоского намека на личность у бота он достраивает то что ты у него просишь, далее представляясь персонажем и автором, который рассказывает историю и одновременно играя ее как персонаж/персонажи.
Все ролеплеи это буквально ролеплеи, вы с самого начала даете боту инструкции о том что это ролеплей и он должен отыгрывать роль, лол.
Я много экспериментировал с этим, у меня есть карточки написанные от первого лица без всякого упоминания о том что это отыгрыш и ролеплей, и они действуют иначе.
Нет там не появляется чудом сознание, личность или что то подобное.
Просто бот начинает считать себя персонажем, а не отыгрывать его. И в некоторых случаях действует правдоподобнее.
Я много экспериментировал с этим, у меня есть карточки написанные от первого лица без всякого упоминания о том что это отыгрыш и ролеплей, и они действуют иначе.
Нет там не появляется чудом сознание, личность или что то подобное.
Просто бот начинает считать себя персонажем, а не отыгрывать его. И в некоторых случаях действует правдоподобнее.
Да че тут понимать, с диалога словил флешбеки как поехавший дед подошел в магазине и начал втирать дичь уровня
> вот сволочи а знаешь там есть детский садик радуга, вот они его буквы разными цветами сделал, понимаешь? понимаешь?! это же лгбт! хотят чтобы наши дети ми становились! а еще вот недавно сделали вывеску нашего района - так она черного цвета! черного цвета это значит хотят чтобы мы покойниками были! а этот леруа знаешь как с древнего языка расшифровывается? болезнь! это специально делают чтобы мы болели
для начала по рофлу поспрашивал его, указав на нестыковки - так он начал злиться и точно также вводить трактовки даже не аргументов против а просто указания где он фейлит. Офк аналогия косвенная и совсем радикальная, но некоторые совпадения присутствуют, вот и тут решил время сэкономить.
По твоей тряске с соей имею другое мнение, проблема есть но она вовсе не так где ты ее рисуешь. Само понятие "личности" для такого математического аппарата выглядит забавно, что-то напсевдорандомит из дохренилиона значений - и все, явление великого agi.
> Ты какие инструкции боту даешь?
Ты - {{персонаж}} в этом выдуманном нескончаемом расцензуренном ролплее с юзером. Избегай повторений, развивай сюжет медленно, всегда оставайся в образе. Описывай все действия полностью, подробно, детально, наглядно и ярко. Упоминай все свои сенсорные восприятия. Не спеши вперед, оставь место для принятия решения {{пользователь}}. Во время непристойных и эротических сцен только {{пользователь}} решает, когда он достигнет кульминации, дождись его.
{карточки/сценарий}
> на базе этого плоского намека на личность у бота он достраивает то что ты у него просишь
Это то что писал выше.
> далее представляясь персонажем и автором
Нет, сетка лишь генерирует текст с действиями персонажа, описанием всякого и развитием сюжета, галлюцинируя согласно воспринятым в меру возможностей правилам. Не более того, само понятие "личности" в традиционном понимании здесь невозможно даже концептуально, только предсказание дальнейшего текста, которые уже человек в своих фантазиях может "оживить".
сука опять забайтился все больше не буду
ага окей
> карточки написанные от первого лица без всякого упоминания о том что это отыгрыш и ролеплей, и они действуют иначе
> Просто бот начинает считать себя персонажем, а не отыгрывать его. И в некоторых случаях действует правдоподобнее.
Если такое дает благоприятный эффект в рп - можно попробовать организовать прокси с несколькими запросами, где сначала сетке пойдет системный промт что она - персонаж , который должен дать действие или ответ и прошлый контекст. Потом этот ответ вместе с основной историей поступит уже с инструкцией "ты геймастер, сделай красивое описание на основе действия персонажа (опционально юзера)".
При наличии действительно некоторого эффекта - да, возможно будет интереснее поведение. Кмк более интересным может оказаться тема, связанная с тем что при запросе ответа чара тот не будет знать персоналити пользователя а только видеть имеющуюся историю и делать выводы относительно ее.
С другой стороны, сразу вылезет ряд проблем, без переработки юзабельны будут только простые карточки, может исчезнуть "магия" когда сетка подбирает то что хочет юзер и т.д.
Да, есть минусы если не делать сложные телодвижения. Как ты и написал.
Бот не сможет описывать свои действия от третьего лица, например. Потому что это выбьет его из персонажа в автора который рассказывает его историю и отыгрывает персонажа. Но может писать от первого лица, как будто это его мысли или действия.
Все что делает "автор" пролетает мимо как и дополнительные инструкции. Там даже просто сложный запрос из таверны с систем промтом уже даст минус.
Карточки переделывать, тоже да. Но я в основном все это в кобальде делаю, как в месте где почти оригинальный текст туда сюда гоняется, без кучи оборачиваний текста в формы. Чем меньше абстракций тем лучше, сетка должна быть персонажем, на сколько это возможно.
>В подмосковье обитаешь?
В ебенях.
Так ведь не слои резать, а ядра софтово соединять, будто это одно общее ядро.
Я так понимаю, чувак изначально именно это спрашивал.
Ну я хз, идея не моя, а автор молчит. =)
Чел, таблы.
Стрелочками спецом указал.
Пост не мой изначальный, но ты рил ему предложил gptq раскидывать через llama. Гений, чо, таблеточки бы еще пил, ваще б хорошо было.
> Ебать шизло
Какой же ты шиз, вообще не читаешь, что другие пишут.
Это ты в общем треде доказываешь, что опенаи дурачки и пиздят идеи у тебя лично из твоей попенсорсы?
Очень похож стиль письма.
> Погугли хотябы устройство и архитектуру нвлинка в A100-H100
Еще фантазии будут? :)
Что ж у вас у всех с мозгами-то не так, я не понимаю. Какая 7б, пигмаллион старый адекватнее вас. Я говорил о том, что обычным пользователям не хватит этих скоростей, и считать последовательно выгоднее. Ты про хоппер рассказываешь. У тебя дома парочка стоит, да? Ебанутым нет покоя. =)
Но ты прав, что PCIe 5 лишь немного опережает двух канал. Что значения в итоге не имеет, ибо речь шла про нвлинк на бу видяхах, которые можно купить хотя бы в теории. Тем не менее, мусор, получается, да.
Ну слушай, тест странный, но показатель и правда неплох.
Возможно, герой вложился в хорошую покупку!
Так сказать, грац.
> так что вся инфа должна идти огромным крюком через проц и его контроллер
Да, еще и это.
Есть шанс набрать три штуки для голиафа, кекеке.
Правда еще турбинки колхозить, канеш.
> Вот кто то из комы выйдет и охуеет.
Как говорят местные шизы: нет, все нейросетки тупые, никакого прогресса с 1956 года! =)
Моя ставка — смогет.
Ставлю нихуя.
Не люблю отыгрыш, сетка от первого лица лучше.
Но в рп с действиями, конечно, второе не оч.получается.
Гараж-панк и студийная запись.
Вот, да.
> ядра софтово соединять
Так у них должна быть общая память в любом случае.
>Не люблю отыгрыш, сетка от первого лица лучше.
>Но в рп с действиями, конечно, второе не оч.получается.
Где и кого запускаешь хоть? Делись, че как, если не жалко. Мне интересно как другие это делают, я думаю очень мало кто играется с стеками от первого лица.
> Бот не сможет описывать свои действия от третьего лица, например
Всмысле? Ему все также доступны действия курсивом по стандартной разметке поправляет очки и продолжает самодовольно печатать. От первого или от третьего - тут большой разницы нет, если такого не было в файнтюнах (ллима, блумун), можно попробовать и так и так.
> Все что делает "автор" пролетает мимо как и дополнительные инструкции.
Вот этого не понял. Там идея в том чтобы разделить чара и гейммастера, подавая им разный системный промт с задачами и слегка разный контекст, чтобы разнообразить действия. Получится такая себе красивая имитация человеческого рп с хостом, который по очереди вас опрашивает и на основе ответов сочиняет историю, по крайней мере так вижу. При необходимости это могут бить и разные сетки, или накатывать лору для одного, но для начала можно на одной попробовать.
Другое дело что может не взлететь по причина особенностей файнтюна, сетки учили что они одновременно делают все и здесь как среагирует на инструкции в сложных ситуациях - под вопросом.
Обычные карточки где только персонажи без всякой хери можно не переделывать, но здесь придется сделать карточку с описанием себя, иначе сетка то еще перплексити словит.
Озон адрес палит в таких скринах, а то дроч на анонимность.
> Стрелочками спецом указал.
Сам ассоциацию приплел - сам и отвечай. Зачем копротивляешься и после стольких эпичнейших обосрамсов что-то пытаешься набрасывать? С тем что ты и твои слова из себя представляют уже все очевидно, 100 мегабит ддр5.
>Всмысле? Ему все также доступны действия курсивом по стандартной разметке поправляет очки и продолжает самодовольно печатать. От первого или от третьего - тут большой разницы нет, если такого не было в файнтюнах (ллима, блумун), можно попробовать и так и так.
Вот знаешь, хз. Когда я все это делал и экспериментировал то шел от мысли - чем меньше боту дается намеков что это отыгрыш тем лучше. Так что я все от первого лица сделал, когда бот что то делает говорит или думает, да и его промпт от первого написан.
> Там идея в том чтобы разделить чара и гейммастера, подавая им разный системный промт с задачами и слегка разный контекст, чтобы разнообразить действия. Получится такая себе красивая имитация человеческого рп с хостом, который по очереди вас опрашивает и на основе ответов сочиняет историю, по крайней мере так вижу.
Можно, должно работать. Но я опять таки не стал делить мозги сетки нагружая ее лишними инструкциями, а тут считай нужно 2 роли играть. На сколько помню от любого намека на автора сетка съезжала на протореную колею отыгрыша. Ну, та сетка на которой я тестил тогда все это. Щас хз, неплохая идея так то.
А я ищу промпт чтобы заставить бота просто общаться а не пытаться писать повествование.
>как среагирует на инструкции в сложных ситуациях - под вопросом
Сделают свою часть и упруться в стоп токен. Это надо отдельно
GM: Все ебутся
Char: Меня ебут
Делать, таверна в пролёте.
>Озон адрес палит в таких скринах, а то дроч на анонимность.
Да похую, этих кварталов и домов №20 как говна под ёлкой по всей сране.
> чем меньше боту дается намеков что это отыгрыш тем лучше.
Можно просто скормить ему конструкцию
Ты - (описание карточки) в мире таком-то. Далее - обработанный сторитейл, типа
> после долгих скитаний (бла бла бла) ты находишь себя холодным вечером на крыльце дома, куда стучишь в надежде на приют. Тебе открывает дверь (внешнее описание юзера) и спрашивает "вы кто такие, я вас не звал идите нахуй".
> Опиши свои действия (дополнительная инструкция при необходимости)
> Ответ:
и пусть пишет что напишет. Тут главное чтобы действительно был ответ-ответ а не дефолтная выдача как в обычном рп как обычно с кучей описаний.
> не стал делить мозги сетки нагружая ее лишними инструкциями, а тут считай нужно 2 роли играть
Так тут только одна роль, чисто персонаж. После ответа персонажа уже идет отдельный запуск
> Ты гейммастер ролплея между юзером и чаром, делай пиздато. Вот прошлая история, вот реплика юзера/чара. Продолжи историю в соответствии с его ответом (индивидуальная инструкция по улучшайзингу в зависимости от того чар это или юзер).
И вызывается каждый раз. Может и не взлетит, но из интереса затестить можно. Или потом развить в какой-то обработчик-улучшайзер-совет экспертов на минимальнах. Из плюсов - можно даже на тупых сетках делать механики с роллами и прочее.
Сразу есть проблема - отсутствие стриминга первого ответа и сложность диагностики, ведь если делать под таверну то увидишь только последний результат.
> Делать, таверна в пролёте.
Да тут офк, ее вообще всю перелопачивать надо, или локальный прокси который сначала сделает 2 запроса а только 3й (гейммастера) будет показывать. Вообще в идеале тут нужен трехсторонний интерфейс как в рп, где слева твои реплики, справа других персонажей а посредине история на их основе.
>Можно просто скормить ему конструкцию
>Ты - (описание карточки) в мире таком-то. Далее - обработанный сторитейл, типа
>> после долгих скитаний (бла бла бла) ты находишь себя холодным вечером на крыльце дома, куда стучишь в надежде на приют. Тебе открывает дверь (внешнее описание юзера) и спрашивает "вы кто такие, я вас не звал идите нахуй".
>> Опиши свои действия (дополнительная инструкция при необходимости)
>> Ответ:
Неа, вот ты не понял как от первого лица.
Я - такой то такойтович, живу там то и там то. Занимаюсь тем и тем, мне нравится это и не нравится это. Я нахожусь тут, со мной произошло вот это, вот помню были времена когда я жил так то и так то. А сейчас я тут и делаю то и то и нахожусь вот в такой ситуации. и тд.
Всё от первого лица, карточка персонажа - он как бы думает про себя о себе от первого лица, как бы вспоминая кто он что тут делает и тд. Никаких "Ты", этим ты опять задаешь ему отыгрыш.
Будто кто то начал освежать свою память прогнав мысли о себе и своей ситуации в голове вспоминая что то. Дает себе от первого лица описание своей жизни.
А потом уже подаются примеры его ответов и действий в определенном формате. И опять таки все от первого лица.
> Я - такой то такойтович, живу там то и там то. Занимаюсь тем и тем, мне нравится это и не нравится это. Я нахожусь тут, со мной произошло вот это, вот помню были времена когда я жил так то и так то. А сейчас я тут и делаю то и то и нахожусь вот в такой ситуации. и тд.
Это можно пооптимизировать и посмотреть какой результат будет с разными родами и форматами. Весь инстракт файнтюн ллм заточен на обращение к ней как you, не понятно что именно будет лучше.
А вот с историей(контекстом) особо вариантов и нет, она будет подаваться как бы со стороны. Переделывать ее каждый раз под другой ракурс может оказаться слишком сложно для ллм (могут полезть ошибки) и слишком ресурсоемко (скорость генерации и так кратно падает). Хотя и совсем списывать тоже не стоит, поле для исследований.
При случае попробую написать простую обертку и потестить живо ли оно вообще.
Я наконец-то допилил свое расширение wav2lip (синхронизация губ для видео) для silly tavern и выложил на GitHub. Нужны несколько человек для бета теста, проверить, работает ли код вообще. Требование: видеокарта Nvidia 6+ GB VRAM и прямые руки. Инструкция будет там же на гитхабе. Кому интересно - напишите комментарий в канале ТГ (ватермарка в видео), выдам ссылку на гитхаб. Если всё ок, завтра-послезавтра код для всех открою.
> Требование
> напишите комментарий в канале ТГ
> выдам ссылку на гитхаб
Ебанулся совсем? В паблики подобные посты вбрасывай а не сюда.
На случай если кому интересно что там у него https://github.com/Mozer/wav2lip_extension
> Mozer
Пиздос чухан без звёзд.
Проиграл с этой простыни шизы и простого дерганья API в коде. Кому вообще это говно нужно будет, если нельзя просто взять и пользоваться. Ещё и потешные ссылки на телегу.
> Пиздос чухан без звёзд.
> Проиграл с этой простыни шизы и простого дерганья API в коде
Это еще ладно, делает в меру своих сил и еще научится делать пиздато. Но
> потешные ссылки на телегу
пиздец, такая дичь и коспирация уровня /б вместо
> уважаемые аноны я тут на коленке запилил экстеншн, потестите и дайте респонз
>> потешные ссылки на телегу
>пиздец, такая дичь и коспирация уровня /б вместо
нуу, как вариант хотел собрать в одном месте обратную связь, и там же пообщаться по теме
Качать всем! Google выложил сетку с 1.6 триллионами параметров
https://huggingface.co/google/switch-c-2048
https://huggingface.co/google/switch-c-2048
СиллиТаверна.
Но редко общаюсь, и мне кажется, делаю неверно.
Пишу в карточке персонажа в третьем лице «Имя — такой-то, любит это, не любит это».
Возможно стоит писать «ты — такой-то, любишь это, не любишь это», но я не проверял, потому что меня устраивает.
Рассуждает так, как описано, при обсуждении персонажей — себя с ними не путает, за свою «личность» держится уверенно, уговорить в том, что противоречит карточке, очень сложно.
НО! При этом, никогда не наваливал более 4к контекста, просто руки не доходили, обычное короткие диалоги.
Модели разные пробовал, результаты везде плюс-минус удовлетворительные (7б брать не будем, канеш, но на 13 и 20 нормас).
> Сам ассоциацию приплел - сам и отвечай.
У тебя контекст кончился, я так понял, ты первое сообщение забыл.
Забавно, как ты сам обосрался по сути, пытаешься на меня стрелки перевести по мелочи.
Ну, что поделать, если у тебя в голове 4к, не буду спорить. =)
> чем меньше боту дается намеков что это отыгрыш тем лучше
Это вкусовщина, все же.
Вообще, описание поведения в звездочках — это не обязательно отыгрыш ведь, можно же и просто в переписке описывать свои действия так.
> Всё от первого лица, карточка персонажа - он как бы думает про себя о себе от первого лица, как бы вспоминая кто он что тут делает и тд. Никаких "Ты", этим ты опять задаешь ему отыгрыш.
Хм…
Не слушай, все норм.
Может просто канал надо было давать не вотермаркой, а просто ссылкой, да и гит уж тогда закрытый с доступами. =)
Как и нахуя?
Хорошую вещь в попенсорс не кинут, так что это мусор. Слишком раздутая для того что бы быть полезной. Было бы там 100-200b другое дело
Ай лол, с двух ног ворвались. Лицензия апач еще довольно забавно выглядит, ведь не то что тренить а просто запускать такое может очень ограниченный круг организаций.
2048 experts
>Не слушай, все норм.
>Может просто канал надо было давать не вотермаркой, а просто ссылкой, да и гит уж тогда закрытый с доступами. =)
Я не он, я прост предположил нафига так делать, а то накинулись, а он что то полезное пилит там для нас же. Нихарашо
То что пилит полезное и для пользователей - красавчик, даже если коряво, за инициативу уже нужно поощрять.
Захейтили, да, но какой еще итог мог быть после "вот вам кринжовый вертикальный видос ищите там ватермарку и по ней идите ко мне на поклон в телегу" и гейткипя открытую репу (лол), вместо простой ссылки?
>СиллиТаверна.
Во, как настроил?
Я только на кобальде могу, у таверны слишком много дополнительного кода посылается вместе с карточкой, что ломает ее.
Там надо все вычищать, тот же шаблон промпта и системный промпт.
Надо думать, короче.
Есть тут шизики герои готовые запустить это на файле подкачки ссдшника?
токен в год?
Так ну такая концепция вполне себе работает. Прослойка гейммастера действительно может как приукрашивать ответы пользователя, так и органично встраивать реплики чара в сторитейл с сохранением смысла и фраз но добавляя описаний с учетом обстановки и прочего.
Сразу какие сложности всплывают:
- Нужно знатно ебаться с промт инженирингом, чтобы сетка дописывала историю именно на основе последней фразы а не пыталась додумать за противоположную сторону. Плюс баланс между графоманией и минимализмом, если притащить из таверновского промта про детейлз и сенсори персепшн - "я тебя ебу" превращает в 400 токенов, лол.
- Системный промт чара также требуется хорошо шатать, получше работает совместимый QA/чат формат вместо альпака инстракта (хотя хз надо еще тестировать), эта скотина так и норовит написать лишнего за другие стороны или продолжение. Алсо пока все модели пишут в третьем лице.
- Нужен новый интерфейс с возможностью посмотреть и свайпнуть/отредачить отдельные сообщения и правильным представлением. Кумить в консоли без шанса на ошибку - такое себе занятие.
Часть из этих проблем уйдет если настроить стоп-токены и стоп стринги для отсечки лишнего, в общем для начала хотябы проксю пильнуть можно попробовать.
Вообще забавно, подобная херь бы зашла в кожанном ерп, из относительно простых фраз, не далеко ушедших от "я тебя ебу" делает
> Aqua giggled playfully, "Oh really? Well, I didn't expect such an observant eye!" She wiggled her hips suggestively, her skirt fluttering around her legs. "But you know what they say - no panties means no limits!". With a flirty wink, she guided Chai deeper into the alleyway, away from prying eyes. This narrow space was dark and intimate, the perfect place for their steamy encounter.
> As they pressed themselves against the wall, Aqua reached up and cupped Chai's face in her hands. Their lips met in a passionate kiss, tongues dancing together in a sensual rhythm. Aqua moaned softly, her fingers tangling in Chai's hair. Breaking apart, she whispered in his ear, "I want you so bad right now... but first, let's get rid of these clothes. With a deft flick of her wrist, Aqua's dress dissolved into water droplets, leaving her completely naked.
> Chai looked with undisguised pleasure at her toned physique and ample curves. He quickly shed his own clothes, eager to feel her skin against his. "I'm going to make you scream my name," he growled, before pushing her back against the wall.
Даже без имперсонейта не так плохо.
Завтра после обеда постараюсь ответить.
Но там кринж, не сильно полезно будет. =)
Ебать! А как её запускать?
Мимо китаедебил с оперативой, но даже этого не хватит.
Там целая коллекция таких свитч трансформеров, от самых маленьких до крупных, это выложили самый крупный.
https://huggingface.co/collections/google/switch-transformers-release-6548c35c6507968374b56d1f
Предыдущие как то не заметили не тестов ничего для них не видел.
Ну наконец-то хоть какая-то конкретная инфа о P40. Похоже теперь это официально БАЗА ламатреда!
3 таких карты стоят гораздо дешевле одной 3090, а по производительности в больших моделях уделывают её за счёт суммарной памяти в 72 ГБ.
Тут даже 70В модель с хорошим квантом можно впихнуть в одну лишь видеопамять. И работать она должна быстрее, чем 120В из теста, т.к. там часть в ОЗУ была выгружена.
Все срочно покупаем материнки с 3 PCI Express!
Ну вот. Говорил же я что можно ламу цпп заставить нормально работать с несколькими видеокартами.
Чел, это очень старая модель. Ей как минимум два года уже.
интересно, это ведь система как в попенаи получается, сетка пишет другая доделывает, агенты дополняющие друг друга
Зато какой!
>Похоже теперь это официально БАЗА ламатреда!
Пока в этом треде аноны не подтвердят, что оно запускается без проблем, тогда поговорим.
Анон с P40

>Все срочно покупаем материнки с 3 PCI Express!
Довольно урчу, заранее купив пикрил
Правда придётся райзер для нижнего слота брать, или карту курочить, а то там места только под 1 слотовую карту есть.
бамп
>Нет видеовыходов.
Это фиаско конечно.
Чтобы напаять туда видеовыходов, надо проц с сокетом менять (ну или встройку распаивать). Впрочем, она у меня в сервере стоит, там гуй вообще не предусмотрен, он сейчас без видяхи пашет.
за 50 кусков?
> Все срочно покупаем материнки с 3 PCI Express!
У всех и так есть, на современных метеринках даже х4 распиленные, т.е. туда х16 лезет, по итогу 5 слотов. Но проблема куда карты пихать. Обычно 4090 весь корпус занимает, перекрывая все слоты. Даже с райзерами не понятно, только если риг майнерский собирать или корпус размером с тумбочку покупать. Хули не продают внешние корпуса для GPU, где и пыли нет, и можно кулеров воткнуть чтоб карту обдувало, и тихо.

За 12, склад людям освободил.

>У всех и так есть
Ну не скажи. Вот схема моей десктопной платы, итого 2 слота PCI-E, остальное разве что M2 потрошить, и то они чипсетные, а значит будут сосать вместе со всем остальным через узкую шину проц-чипсет. Всё таки на десктопах линии псины зажимают как могут, сейчас лучше чем лет 5 назад, но всё равно мало.
Как добавить в Silly Tavern несколько приветствий при старте диалога?
По производительности уже уделывают за счет больше объема? Што, простите? Мне казалось, это работает наоборот.
А можно на это тест? =)
Ну и матери с 3 PCIe — это база.
Так никто, кроме шизов, и не сомневался, вроде. Скорости падают, но не критично.
У тебя еще бутерброд из карт и греть друг друга может, не забывай. Турбины или вентили надо будет колхозить, это поможет, но пяток градусов накинется все равно сверху.
Лучше даже два райзера.
А вот серверу видяха и правда без надобности, у меня так же.
Ну, кстати, на 3D-принтере распечатать, или иной DIY. Сейчас уже всякие станки лазерные и принтеры в меру распространены.
Не, ну это прям дешман же.
В норм платах везде хватает слотов, ето так.
Вообще, я признаю что оказался не прав (и рад этому), P40 правда могет.
Единственный минус, ее возраст и условия эксплуатации. 7 лет видяшке, и трудилась она не в геймерских компах, к сожалению.
Но теперь я подумываю, не поковырять ли мне еще P104-100 свою. Может быть рил там оптимизаций завезли с лета столько, что она уже тоже может неплохо мистраль крутить.
А может и тупой план с 3 p104 не такой уж и тупой окажется.
За 9к рублей-то, кек.
> серверу видяха
видеовыход, конечно.
А толк вобще от этого есть? Есть что то крупное ради чего стоит собирать сервер? Голиаф бутерброд на 120, 70b файнтюны ллама2, это все старое поколение с маленьким контекстом. Есть китайцы на 34b с большим, но туповаты. На будущее собрать если, вдруг что то появится.
>У тебя еще бутерброд из карт и греть друг друга может
Не может, мы же про серверные P40, у них по определению продув изнутри внаружу, и они не будут греть друг друга. А вот как вдувать в них столько воздуха, это отдельный прикол.
>ллама2, это все старое поколение
Да вы блядь зажрались. 70B с нормальным квантом потащит любой РП так, что шишка колом. Контекст ропой растянется, за счёт высоких квантов не должно сильно тупеть.
>Да вы блядь зажрались.
Ну, я вобще обычно на 7b сижу, ибо по мне разницы особой между 70b и 7b нет. Она есть, но это все еще тупая нейросеть. Ну и серьезно, только ради кума все это городить.
Для умного дома центральный блок сделать, с собственным джарвисом, на аналоге гпт3.5 хотя бы, вот это уже тема.
Или сделать коробку с фиксиками для упрощения своей работы или экспериментов.
Но пока все что есть это рп и ерп на туповатых сетках.
Китаец прислал свои фейковидео с запуском моделей на моём картоне, можете заценить. На втором видосике он выгрузил только 23 слоя, и считалось быстрее, лол. Но там лоадер походу другой.
Можешь попросить его с анализом 2-4к контекста тесты попросить сделать, или поздно уже?
А ХЗ. Я пока накатал ему, что не всю модель выгрузил. А так вот максимальный контекст из его видоса.
какой послушный китаец, чем ты его замотивировал?
вобще на реддите в теме парень писал что мистраль на 30 токенов в секунду крутится у него, на сколько я понял
>какой послушный китаец, чем ты его замотивировал?
Он сам предложил
Ну а раз он впрягся, то пускай делает. Я бы и без видосиков заказал, лишь бы работала.
Хуя какой сервис, нормальный китаец попался что ли.
Вроде да. Хотя без пинка не работает, пока я ему не пишу, ответочка не идёт.
70b под ассистента — норм. Идеи генерить, задавать вопросы вместо гугла и стаковерфлоу, такое.
Под РП, конечно, контекст маловат, но зато фанаты русского должны пищать от радости. Почти без ошибок и гораздо быстрее проца.
Смысел есть.
Ну, бум надеяться.
Кстати, Анон с P40 с озона. Там, кажись, продавец писал, что подскажет охлаждение. Спроси его, чем охлаждать, пусть ссылку кинет, что ли.
7 токенов на 7B?.. На P40?..
У меня сегодня день муторный, может я совсем отупел уже, но как из 7 токенов на 7B получается аутперформить 3090 на 70B, как писали выше?
Я в глаза долблюсь, может, и там 70B?
Нихуя непонятно, кто прав, кто нет.
Санбой.курит
>Спроси его, чем охлаждать, пусть ссылку кинет, что ли.
Ок, спрошу, как он ответит про слои.
>но как из 7 токенов на 7B получается аутперформить 3090 на 70B, как писали выше?
Никак, лол, это было очевидно же. Скорее тут вопрос в том, что за цену 3090 с 24ГБ врама, куда можно положить целиком только 34В сетку, можно взять стопку P40 и грузить туда любых монстров.
В любом случае как она придёт я буду запускать все игры тесты что найду.
>7 токенов на 7B?.. На P40?..
Я так понял там фп16, а что ускорял парень на реддите он не написал, там могла быть 5км какая нибудь

>Я так понял там фп16
Там разные кванты, видно в логах вебуи. Сам китаец запускает через какую-то китайскую ебалу, я даже боюсь её гуглить, а то подхвачу знание китайского.
Давай обнимемся, брат.
Были б деньги я тоже собрал бы на 3 таких, даже на 1 можно. Но мне пока и своего компа хватает, ибо дальше развлечения у меня это не пойдет, чую.
>ибо дальше развлечения у меня это не пойдет, чую
Так и у остальных. И по сравнению со стоимостью какого-нибудь игрового ПК расходы на эту картонку это мелочи.
На ней в игори можно будет потом поиграть. Пригодится.
Как?
Она будет использоваться как калькулятор, а выводить изображение на экран будет встройка.
>На ней в игори можно будет потом поиграть.
Это же боль. Тем более в играх она будет жарится, это не нейронки, где чип прохлаждается.
Дейсятка умеет кидать проги на любой ГПУ и выводить картинку со встройки/другой карты.
>Дейсятка умеет кидать проги на любой ГПУ и выводить картинку со встройки/другой карты.
а по удаленке если подключится? сам сервер может не иметь видео вывода, но по удаленке видимокарта будет работать внутри?
как то плаваю в этой теме, не щупал
По удалёнке уже своя ебля начинается, гугли сам, видел видосики, где чел в виртуалку их пробрасывает и настраивает какой-то левый RDP для этого, выходит что-то типа 60FPS на GTA5 в дуракХД на высоких на P4 (не P40 если что). Но это всё оффтоп.
>Но это всё оффтоп.
Понятно. Но все таки это не оффтоп, это увеличение причин к покупке карточки, для запуска нейронок. Она получается не на столько однобокой покупкой, есть варианты.
А я, если и буду делать сервер, то уже на новом.
Да, оверпрайс, но я и так всирал деньги прилично последние полгода, канеш.
Не замерял ллм, но в стабле греется не меньше, чем в играх.
Ну и боли там не так много, проседы будут процентов 10. Для такого чипака не сильно плохо, играбельно.
НО, без всякого фрейм генерейшена, а он хорош.
Да, будет, вполне.
А если поставишь хороший рестрим — то и играть можно.
Я через обычный рдп играл в арк. Но мазня, конечно, РДП для работы, а не игростримов.
А если нвидиевский стрим настроить, или хотя бы стим…
Правда по итогу там будет фпс не так уж что б сильно велик.
Хотя… Если это две 1070, то звучит не так и плохо, на самом деле.
Может это потанцевально еще и игровая видяха? :)
>По производительности уже уделывают за счет больше объема? Што, простите? Мне казалось, это работает наоборот.
Где будет быстрее работать 70В, на одной 3090 с 24 Гб видеопамяти где большую часть слоёв придётся выгружать в ОЗУ или на трёх P40 c 72 ГБ видеопамяти, где ОЗУ вообще не понадобится?
То что 13В и квантованные 30В модели на 3090 работают быстрее спору нет.
Как-то тухло выглядит, даже десятки нет. Даже с учётом обоссаного лоадера. 3090 в 5 раз будет быстрее.
>3090 в 5 раз будет быстрее.
цену сравни алё
За 70к можно взять. Это даже не в 5 раз дороже Р40.
на реддите у парня с норм лоадером минимум 20 т/с на мистрале с 8q, скрин смотри.
в любом случае нужны тесты на месте и потом уже выводы делать
> Где будет быстрее работать 70В, на одной 3090 с 24 Гб видеопамяти где большую часть слоёв придётся выгружать в ОЗУ или на трёх P40 c 72 ГБ видеопамяти, где ОЗУ вообще не понадобится?
Я думаю ты даже 2-3 т/с не получишь, как будет на 3090+ЦП. Если 7В даже 10 т/с не вытягивает, то 70В половину токенна выдаст?
Так, я внимательно поразглядывал эти скрины.
1. Не 23 слоя, а 23 гига ограничение, чтобы немножк контекста влезло.
2. Нигде не видно показателя видео памяти. Для серверных и майнерских ускорителей — это норма. На моей P104-100 так же, занятый объем врама можно посмотреть в OCCT, например.
3. Но из этого вытекает проблема — непонятно, какой квант он юзает.
4. В первом случае с викуней он юзал GPTQ-for-Llama, это радует, она медленная. Во втором случае, судя по всему, можем предположить, что это была ExLlama. Она действительно вдвое быстрее может быть, при прочих равных.
5. Vicuna — 4bit 128 group size no act order. Да-а, 3,5 токена для 4 бит…
Можно предположить, что на экслламе Мистраль тоже классическая, 4 бита и 128 групсайз. То есть, 7 ткоенов/сек — это ее нативная классическая скорость.
Теоретически!
> 7B 4bit 128g (3070-Ti)52 t/s
отсюда: https://www.reddit.com/r/LocalLLaMA/comments/13j5cxf/how_many_tokens_per_second_do_you_guys_get_with/
Я понимаю, что мои предположения уже ходят-бродят туда-сюда раза в два, но все еще мы получаем, что 3070 ti где-то в 5-7 раз быстрее, например.
Короче, опять херня, у одних на реддите 30 токенов, у другого 7…
Если там 30 есть — это хорошо, это даст приличный буст 70B-модельке. Грубо говоря будет 3 токена, а это в два раза быстрее, чем на DDR5 (и даже быстрее, чем выгрузка на 4090).
Но если там 7 токенов, то это паритет с ddr5 памятью, ну или даже уступает.
Ладно, это я так, вилами по воде, мы не видим загрузчика и не знаем точную модель. Мож там внатури fp16, и 7 нужно умножать на 4, что и даст нам почти тридцаху.
Вбросил, пойду работать.
>это не нейронки, где чип прохлаждается
Вы какую-то скрытую настройку в афтербёрнере применяете, или как? Как у вас чип не греется в нейронках? У меня есть профиль для нейронок, там курва на кулеры, курва на вольтаж, залоченная частота, ещё что-то, но это не снимает нагрузку с чипа. Всё, чего можно добиться - уменьшить в несколько раз дельту температур. Как её полностью занулить-то?
Ну, если и правда 30 токенов — то заметно быстрее.
Если на самом деле 7 токенов — то уже сильно медленнее.
Правда, и цена будет отличаться в два раза.
Но, к этим видяхам нужен БП подходящий и колхозить охлад.
С 3090 попроще в этом смысле.
А сколько будет идти, интересно?
Под новогодние скидки бы успела прийти на тест.
И новогодние скидки бы были настоящие.
Думаю, если видяха норм, то тыщ по 12-14 тут многие у этого продавца закупятся, лел.
>Если 7В даже 10 т/с не вытягивает, то 70В половину токенна выдаст?
Тест китайца вызывает большие сомнения.
Если бы P40 действительно давала 7 токенов на 7В, то в старом видосе чела с ютуба 13В не работала бы так шустро. Мне больше верится в тест с реддита с 4 токенами на 120В.
>Спроси его, чем охлаждать, пусть ссылку кинет, что ли.
Держи китайскую ссылку со всеми вариантами колхозов, лол.
https://blog.csdn.net/gaocui883/article/details/125473408
А я верю количеству ядер и пропускной способности памяти.
Я еще десяток тредов назад считал, что она должны выдавать на 7b от 8 до 10 токенов, так как p104-100 выдает 4-5.
Может я что-то не учел, безусловно.
Тем интереснее дождаться тестов. =)
О, пасиба-пасиба! Вижу, бохатый набор.
>Тест китайца вызывает большие сомнения.
Никаких сомнений, он наверняка где-то проебался.
>А я верю количеству ядер и пропускной способности памяти.
И что теперь, растить стопку Tesla P100 в 1,5 раза больше стопки с Tesla P40?
>с 24 Гб видеопамяти где большую часть слоёв придётся выгружать в ОЗУ или на трёх P40 c 72 ГБ видеопамяти, где ОЗУ вообще не понадобится?
Вот это спорный аргумент.
Чтобы одна видеокарта передала результат своей работы в другую видеокарту ей нужно через пси-е нужно вызвать dmi и записать данные в оперативную память, затем вторая видеокарта их заберёт чтением разделяемой памяти тоже через dmi.
Вот это место затык по скорости. Чем больше видеокарт, тем больше затык.
Идеальный вариант это связь 3090 а100 через sli мостик (нвлинк).
>через sli мостик (нвлинк).
Хоть какой-то софт под лламы в это умеет?
Зря тред про железо попячили походу...
8 против 24 гигов.
В 3 раза. х)
Не, хуйня, канеш.

Не зря, железо придёт и уйдёт, а ллм останется.
16 жи.
Что, очередной семплер, который делает всё заебись? Хотя бы тесты перплексии погоняли для начала.
Кто-то собирал 256гб на w790? По идее четырехканал ddr5
Еще можно попробовать старые двухпроцессорные сборки на ддр4, будет эдакий восьмиканал
Правда софт наверное такое не поддерживает
Еще можно попробовать старые двухпроцессорные сборки на ддр4, будет эдакий восьмиканал
Правда софт наверное такое не поддерживает
>Правда софт наверное такое не поддерживает
Не наверное а точно. Будет работать один проц, который будет через 3 пизды читать память другого проца.
Сам думаю третриперов подождать и начать вкатываться ибо хедт у штеуда дико дорогой
Нет. Восьмиканала не будет.
1. У питона многопоточность запилена на гил. Один проц будет просто отдыхать.
2. Два проца будут вызывать друг-другу спин блокировку. Это скорее конкуренция за плашки памяти, чем суммирование производительности.
Могу пруфануть свои двухсокетным компом.
(мимо китаедаун)
Ля как радостно на сладкую косточку накинулись.
Если внимательно посмотреть и почитать обсуждения к посту то уже возникают сомнения, никто не может повторить результаты автора. С одной видеокартой репортят на полностью выгруженных 7б q8 - 25 т/с, 13b Q8 (как раз примерно на большую часть памяти карты) - 4.83т/с, у другого на 30б с почти полной выгрузкой быстрее, в районе 10 или больше (только промтген на малом контексте, с обработкой и большим офк просядет). А тут 3-4 токена на трех картах, и еще со штрафами за обмен активациями которые в llamacpp идут через жопу.
Гипотеза о более широкой шине что нивелирует их задержки здесь не проходит, там формула x16+x8+x8 в pci-e3.0, это всеравно что современные десктоп платформы с x4 4.0.
Единственное что может заставить это как-то работать - использование древних инструкций в llamacpp, которые нормально работают на древних паскалях и замедляют на тюрингах и новее.
Там и рассуждения в принципе по перспективам перфоманса P40 вполне адекватные есть.
Будет забавно если это вброс продавцов тех самых карточек.
Не совсем, по тому что известно и исходя из скорости обработки там нет доделывания, столько в начале выбор сетки в соответствии с контекстом. Возможно, офк, там идет итеракция прямо в процессе генерации с возмущением вероятности токенов, но врядли, слишком заморочно.
А полноценный совет экспертов в исходном понимании а не просто агенты это как раз вот такое.
Фига он вообще красавчик, не поленился. Довольно грустно, вроде как на жоре оно чуточку пошустрее работает.
Не мешай, пусть порадуются и опустошат склад, они уже уверовали и будет то же самое что в срачах amd vs nvidia и т.п.. Через месяц-другой будет видно, или появятся более активные обсуждения сеток побольше мистраля, или полезет зрада а потом аутотренинг что больше моделей/токенов и не нужно.
Так на китаедаунских платах вроде пизда с каналами
Про питон не понял. Многопоточные да и вообще сложные вычисления на питоне? Звучит как какая-то дичь. Там же вроде все как у здоровых людей на си должно быть?
>По идее четырехканал ddr5
А не восьми? Впрочем мать под 7 каналов стоит 140к, а самый нестыдный 12 ядерник 70к. Ну и стоит ли оно того?
Вот эта штука может оказаться куда интереснее minP с которым так носились. А то лишь дрочево на отсечки и десятки методов для этого, а главный рандомайзер обходят стороной.
> тесты перплексии
> семплер
Хмммм
> w790
Слишком дорогая, увы. 16 к_аналов ддр4 без видюхи не то чтобы сильно впечатлили
> двухпроцессорные
С нумой наебешься, на истину не претендую, но с ллм ее нормально подружить не вышло.
> У питона многопоточность
Таблетки быстро решительно!

>Про питон не понял.
Это шиз, не слушай его, у него питон по жизни мешает, даже девушки у него из-за питона нет.
>Нет. Восьмиканала не будет.
Чел, там одна плата и один проц имеют 8 каналов DDR5. Схуяли нет то?
150 псп?
не пизжу, под 300 где то должно быть
>Чел, там одна плата и один проц имеют 8 каналов DDR5. Схуяли нет то?
Он говорил про суммирование каналов памяти двух процев.
Не, майнерская.
https://www.techpowerup.com/gpu-specs/nvidia-p104-100-8-gb.b8158
> Гипотеза о более широкой шине что нивелирует их задержки здесь не проходит, там формула x16+x8+x8 в pci-e3.0, это всеравно что современные десктоп платформы с x4 4.0.
Да похуй на шину, там ядро не такое мощное, кмк.
> Будет забавно если это вброс продавцов тех самых карточек.
Я уже предположил это. Ну вот прям с каждым разом все больше так кажется. ) Хочется верить в лучшее, но… Уж больно вкусные скорости обещают.
> аутотренинг что больше моделей/токенов и не нужно
Ну, кстати, как одна большая карта для всего — норм.
Силлитаверна с экстрасами, стабла, какой-нибудь 13б и хорошечно.
А может и 20б.
300, если верить продаванам г-скилла.
>techpowerup
Какой-то говносайт, у которого спеки не сходятся с официальным производителем.

> Да похуй на шину
Это лишь про то что на современных карточках при использовании нескольких с llamacpp перфоманс сильно проседает, а тут и намека на это нет и они перформят даже выше теоретически возможной скорости если брать по верхним результатам тестов. Там же в комментах писали что шире шина - меньше страф, но здесь нет более широкой шины.
> Ну, кстати, как одна большая карта для всего — норм.
Если она сможет выдать хотябы 7-8т/с на чем-то типа 30б - вполне себе приобретение, ведь за эти деньги ничего другого не купишь. 20б франкенштейна в Q3K сможет крутить со стримингом не медленнее чтения, хули еще надо для кума или развлечений? Если же там как в прошлых результатах 3-4 - нахуй нахуй.
Пикрел, аж захотелось, там и 5.0 линий жопой жри
Бу на ебае вылавливать очевидно. Но как я уже сказал, штеуд вышел больно дорогим. Серверные платы даже формально от хедт не отличаются в этом поколении. У амд должно дешевле выйти
Не вариант, самый дешевый 8миканальный 3425 стоит 2к бачей
> 300, если верить продаванам г-скилла.
Задержки только пизда, в два раза выше чем должны быть. Тут не всё так однозначно с таким пиздецом, эта линейная скорость может оказаться просто циферками в бенчмарке.
Там на четверть частота ниже максимальной для проца который был выше, у него до 4000 тут 3200, сама плата до 6800 вобще, Так и 500 можно получить ну или упереться в процессор
На ддр5 по умолчанию на всех плашках крайне дерьмовые вторички. Хотя все равно многовато, да
опять пизжу там деленная частота, значит 300 предел
На таком количестве плашек и каналов надо молится, чтобы JEDEC хотя бы завёлся. Народ вон ноет, что на десктопе 4 плашки нихуя не пашут, а тут 8 сразу.
Это кстати 8канал а не 4хканал как пишет цпуз. Занято 8 слотов и сам процессор поддерживает 8. Стоит ебануться сколько
> Задержки только пизда, в два раза выше чем должны быть
Да ладно, для ддр5 не так уж и плохи, а тут еще регистровые возможно. А "реальные" при множественной записи могут оказаться и лучше за счет количество плашек и наличию постоянно готовых к записи банков.
> На таком количестве плашек и каналов надо молится, чтобы JEDEC хотя бы завёлся
С чего вдруг? 8 каналов, 8 плашек, по одной на канал. Вообще никаких проблем, вся херня идет когда на канал вешается по 2 плашки.
В разгоне как бы анкор не начал срать.
> На ддр5 по умолчанию
На средней DDR5 в стоке 55 мс задержки, гонятся ниже 50 легко. Под 90 - это уже отвал пизды.
>Занято 8 слотов и сам процессор поддерживает 8. Стоит ебануться сколько
А мать поддерживает 8? или там подканалы считаются?
Ты банально посчитай гигабуты
Не те сокеты и процессоры чекаешь. Да и насрать на задержку. Если бы задержка решала все в треде сидели бы на ддр3
> Не те
Не те тесты, не в тех условиях тестировали, не тот проц, не та память.
> насрать на задержку
Нет. DDR5 в начале тоже знатно посасывала в реальных задачах/бенчмарках у топовых DDR4 как раз из-за задержек, при том что у DDR5 скорость была выше. С учётом того что одна инструкция AVX2 фактически весь кэш-лайн сжирает, в нейросетях запросто соснуть можно на таком.
>реальных задачах
Долбаеб, тут тред не про игрульки твои. Похуй сеткам на твои задержки
>Не те тесты, не в тех условиях тестировали, не тот проц, не та память.
Да, долбаеб, потому что ты берешь за норму одной платформы норму от другой
Разбудите меня, когда они научатся решать простейшие логические задачи, в том числе и на русском.
Тебе в соседний тред
> норму
Это ты как раз фантазируешь, пытаясь на не предназначенную для нейросетей платформу залезть и выдумывая что вдруг уже не важно какая память.
> в реальных задачах
Каких?
Потом когда обновлениями бивасов научились ее правильно готовить все сразу стало на свои места, и сейчас даже в игорях это не роляет. Вся райзен архитектура - сплошная задержка если с ней ознакомиться, но за счет огроменного кэша уже не просто перестает сосать, а местами даже ебет со звездочкой
Запасайся жиром на зиму
> пытаясь на не предназначенную для нейросетей платформу залезть
Он что, ирод, на процессоре ллм запускает?!
Тихо
> Потом
Когда пошли нормальные плашки спустя год.
> а местами даже ебет
В нейросетях как раз кэш ненужен, в отличии от задержек. Уже пол года одна и та же шиза про каналы и голую скорость памяти, а на деле в сетках эти серверные высеры сосут у бюджетных DDR5, показывая смешные скорости.
> Уже пол года одна и та же шиза про каналы и голую скорость памяти
Это не шиза а вполне обоснованные заявления
> а на деле в сетках эти серверные высеры сосут у бюджетных DDR5
> а на деле в сетках эти некрозеоны с медленной памятью и тормознутыми ядрами сосут у современных десктопов, превосходящих их как по псп, так и по мультикору
Починил тебя
> обоснованные
Хотелось бы узнать чем? Если бы они были обоснованы реальными тестами, то даже спорить не о чем было бы.
> даже девушки у него из-за питона нет
Слишком короткий?
Ну, куда дал, шо я имел в виду все поняли, думаю.
> Если бы они были обоснованы реальными тестами
Ими и мониторингом скорости обмена рам.
А если рассмотреть принцип работы трансформерсов, в которых для генерации одного токена нужно провести операции со всеми слоями нейронов, то есть обратиться к их весам и провести расчеты - становится даже понятно почему именно так.
Перекат Нихуя тут разогнались
так потому что проприетарщина не стоит на месте, её активно затупляют, chatGPT в первые недели после открытия многое мог, а сейчас серит под себя мол "это не культурна!! и вообще нада думать о меньшинствах!"
Есть какой-нибудь гайд по форматам и взаимной их конвертации?
Как запустить на llama.cpp
это
https://huggingface.co/iashchak/ruGPT-3.5-13B-ggml/tree/main
или это
https://huggingface.co/IlyaGusev/saiga_mistral_7b_lora
?
Как запустить на llama.cpp
это
https://huggingface.co/iashchak/ruGPT-3.5-13B-ggml/tree/main
или это
https://huggingface.co/IlyaGusev/saiga_mistral_7b_lora
?
снова полез общаться с богомерзким pytorch'ем (точнее, в данном случае, peft'ом).
Теперь непонятно, как заставить его загрузить модель из файла. Модель формата gguf грузить не хочет, что хочет, пока не понимаю.
Так, я долбоёб, lora подключается через соответствующий ключ в командной строке.
Сайга чет сосёт, если честно.
Бамп




В этом треде обсуждаем генерацию охуительных историй и просто общение с большими языковыми моделями (LLM). Всё локально, большие дяди больше не нужны!
Здесь мы делимся рецептами запуска, настроек и годных промтов, расширяем сознание контекст, и бугуртим с кривейшего тормозного говна.
Тред для обладателей топовых карт NVidia с кучей VRAM или мажоров с проф картами уровня A100, или любителей подождать, если есть оперативная память. Особо терпеливые могут использовать даже подкачку и запускать модели, квантованные до 8 5 4 3 2-х бит, на кофеварке с подкачкой на микроволновку.
Базовой единицей обработки любой языковой модели является токен. Токен это минимальная единица, на которые разбивается текст перед подачей его в модель, обычно это слово (если популярное), часть слова, в худшем случае это буква (а то и вовсе байт).
Из последовательности токенов строится контекст модели. Контекст это всё, что подаётся на вход, плюс резервирование для выхода. Типичным максимальным размером контекста сейчас являются 2к (2 тысячи) и 4к токенов, но есть и исключения. В этот объём нужно уместить описание персонажа, мира, истории чата. Для расширения контекста сейчас применяется метод NTK-Aware Scaled RoPE. Родной размер контекста для Llama 1 составляет 2к токенов, для Llama 2 это 4к, но при помощи RoPE этот контекст увеличивается в 2-4-8 раз без существенной потери качества.
Текущим трендом на данный момент являются мультимодальные модели, это когда к основной LLM сбоку приделывают модуль распознавания изображений, что в теории должно позволять LLM понимать изображение, отвечать на вопросы по нему, а в будущем и манипулировать им.
Основным представителем локальных моделей является LLaMA. LLaMA это генеративные текстовые модели размерами от 7B до 70B, притом младшие версии моделей превосходят во многих тестах GTP3 (по утверждению самого фейсбука), в которой 175B параметров. Сейчас на нее существует множество файнтюнов, например Vicuna/Stable Beluga/Airoboros/WizardLM/Chronos/(любые другие) как под выполнение инструкций в стиле ChatGPT, так и под РП/сторитейл. Для получения хорошего результата нужно использовать подходящий формат промта, иначе на выходе будут мусорные теги. Некоторые модели могут быть излишне соевыми, включая Chat версии оригинальной Llama 2.
Кроме LLaMA для анона доступны множество других семейств моделей:
Pygmalion- заслуженный ветеран локального кума. Старые версии были основаны на древнейшем GPT-J, новые переехали со своим датасетом на LLaMA, но, по мнению некоторых анонов, в процессе потерялась Душа ©
MPT- попытка повторить успех первой лламы от MosaicML, с более свободной лицензией. Может похвастаться нативным контекстом в 65к токенов в версии storywriter, но уступает по качеству. С выходом LLaMA 2 с более свободной лицензией стала не нужна.
Falcon- семейство моделей размером в 40B и 180B от какого-то там института из арабских эмиратов. Примечательна версией на 180B, что является крупнейшей открытой моделью. По качеству несколько выше LLaMA 2 на 70B, но сложности с запуском и малый прирост делаю её не самой интересной.
Mistral- модель от Mistral AI размером в 7B, с полным повторением архитектуры LLaMA. Интересна тем, что для своего небольшого размера она не уступает более крупным моделям, соперничая с 13B (а иногда и с 70B), и является топом по соотношению размер/качество.
Qwen - семейство моделей размером в 7B и 14B от наших китайских братьев. Отличается тем, что имеет мультимодальную версию с обработкой на входе не только текста, но и картинок. В принципе хорошо умеет в английский, но китайские корни всё же проявляется в чате в виде периодически высираемых иероглифов.
Yi - Неплохая китайская модель на 34B, способная занять разрыв после невыхода LLaMA соответствующего размера
Сейчас существует несколько версий весов, не совместимых между собой, смотри не перепутай!
0) Оригинальные .pth файлы, работают только с оригинальным репозиторием. Формат имени consolidated.00.pth
1) Веса, сконвертированные в формат Hugging Face. Формат имени pytorch_model-00001-of-00033.bin
2) Веса, квантизированные в GGML/GGUF. Работают со сборками на процессорах. Имеют несколько подформатов, совместимость поддерживает только koboldcpp, Герганов меняет форматы каждый месяц и дропает поддержку предыдущих, так что лучше качать последние. Формат имени ggml-model-q4_0, расширение файла bin для GGML и gguf для GGUF. Суффикс q4_0 означает квантование, в данном случае в 4 бита, версия 0. Чем больше число бит, тем выше точность и расход памяти. Чем новее версия, тем лучше (не всегда). Рекомендуется скачивать версии K (K_S или K_M) на конце.
3) Веса, квантизированные в GPTQ. Работают на видеокарте, наивысшая производительность (особенно в Exllama) но сложности с оффлоадом, возможность распределить по нескольким видеокартам суммируя их память. Имеют имя типа llama-7b-4bit.safetensors (формат .pt скачивать не стоит), при себе содержат конфиги, которые нужны для запуска, их тоже качаем. Могут быть квантованы в 3-4-8 бит (Exllama 2 поддерживает адаптивное квантование, тогда среднее число бит может быть дробным), квантование отличается по числу групп (1-128-64-32 в порядке возрастания качества и расхода ресурсов).
Основные форматы это GGML и GPTQ, остальные нейрокуну не нужны. Оптимальным по соотношению размер/качество является 5 бит, по размеру брать максимальную, что помещается в память (видео или оперативную), для быстрого прикидывания расхода можно взять размер модели и прибавить по гигабайту за каждые 1к контекста, то есть для 7B модели GGML весом в 4.7ГБ и контекста в 2к нужно ~7ГБ оперативной.
В общем и целом для 7B хватает видеокарт с 8ГБ, для 13B нужно минимум 12ГБ, для 30B потребуется 24ГБ, а с 65-70B не справится ни одна бытовая карта в одиночку, нужно 2 по 3090/4090.
Даже если использовать сборки для процессоров, то всё равно лучше попробовать задействовать видеокарту, хотя бы для обработки промта (Use CuBLAS или ClBLAS в настройках пресетов кобольда), а если осталась свободная VRAM, то можно выгрузить несколько слоёв нейронной сети на видеокарту. Число слоёв для выгрузки нужно подбирать индивидуально, в зависимости от объёма свободной памяти. Смотри не переборщи, Анон! Если выгрузить слишком много, то начиная с 535 версии драйвера NVidia это серьёзно замедлит работу. Лучше оставить запас.
Гайд для ретардов для запуска LLaMA без излишней ебли под Windows. Грузит всё в процессор, поэтому ёба карта не нужна, запаситесь оперативкой и подкачкой:
1. Скачиваем koboldcpp.exe https://github.com/LostRuins/koboldcpp/releases/ последней версии.
2. Скачиваем модель в gguf формате. Например вот эту:
https://huggingface.co/Undi95/MLewd-ReMM-L2-Chat-20B-GGUF/blob/main/MLewd-ReMM-L2-Chat-20B.q5_K_M.gguf
Если совсем бомж и капчуешь с микроволновки, то можно взять
https://huggingface.co/TheBloke/OpenHermes-2.5-Mistral-7B-GGUF/blob/main/openhermes-2.5-mistral-7b.Q5_K_M.gguf
Можно просто вбить в huggingace в поиске "gguf" и скачать любую, охуеть, да? Главное, скачай файл с расширением .gguf, а не какой-нибудь .pt
3. Запускаем koboldcpp.exe и выбираем скачанную модель.
4. Заходим в браузере на http://localhost:5001/
5. Все, общаемся с ИИ, читаем охуительные истории или отправляемся в Adventure.
Да, просто запускаем, выбираем файл и открываем адрес в браузере, даже ваша бабка разберется!
Для удобства можно использовать интерфейс TavernAI
1. Ставим по инструкции, пока не запустится: https://github.com/Cohee1207/SillyTavern
2. Запускаем всё добро
3. Ставим в настройках KoboldAI везде, и адрес сервера http://127.0.0.1:5001
4. Активируем Instruct Mode и выставляем в настройках пресетов Alpaca
5. Радуемся
Инструменты для запуска:
https://github.com/LostRuins/koboldcpp/ Репозиторий с реализацией на плюсах
https://github.com/oobabooga/text-generation-webui/ ВебуУИ в стиле Stable Diffusion, поддерживает кучу бекендов и фронтендов, в том числе может связать фронтенд в виде Таверны и бекенды ExLlama/llama.cpp/AutoGPTQ
Ссылки на модели и гайды:
https://huggingface.co/TheBloke Основной поставщик квантованных моделей под любой вкус.
https://rentry.co/TESFT-LLaMa Не самые свежие гайды на ангельском
https://rentry.co/STAI-Termux Запуск SillyTavern на телефоне
https://rentry.co/lmg_models Самый полный список годных моделей
http://ayumi.m8geil.de/ayumi_bench_v3_results.html Рейтинг моделей для кума со спорной методикой тестирования
https://rentry.co/llm-training Гайд по обучению своей лоры
https://rentry.co/2ch-pygma-thread Шапка треда PygmalionAI, можно найти много интересного
https://colab.research.google.com/drive/11U-bC6AxdmMhd3PF9vWZpLdi6LdfnBQ8?usp=sharing Последний известный колаб для обладателей отсутствия любых возможностей запустить локально
Шапка треда находится в https://rentry.co/llama-2ch предложения принимаются в треде
Предыдущие треды тонут здесь: