

Нахер тебе два проца, тебе 4-6 тредов хватит на все.
Тем более на частоту 2400.
У тебя все в пропускную способность памяти упирается.
Проц и объем не помогут (объема хватит для модельки — ну и все).
Как-как. Медленно, если у тебя 2400 в двухканале. В зависимости от кванта от 0,3 до 0,8 токена, наверное.
Да ядра там не причем.
У тебя физически информация лежит в оперативе.
И хоть миллион ядер — они лезут через окошко в оперативу, проверяют инфу.
А окошко-то у тебя фиксированное, смекаешь? :) Больше чем можно ты инфы оттуда не вытянешь в секунду.
64 гига DDR5 и правда лучше. Для 70B какой-нибудь Q5/Q6 хватит.
> ьез баб видюх
Вяло, ускорение контекста необходимо чтобы не страдать, хотябы что-то простое.
> ОЗУ DDR4 2400
С такой частотой там только 4 канала некрозеонов будет (?), крайне вяло пойдет. Прежде всего важна псп рам, а не количество ядер или объем, но более новая архитектура будет быстрее старой при прочих равных. На 16 каналах 3000 крутится не сказать что быстро, так что затея сомнительная.
Вот это "детская травма" которую мы заслужили, так-то никому не пожелаешь, лол.
Кто-нибудь юзает колаб? Насколько старая хуита нужна чтобы он по производительности стал лучше?
Из-за злоебучего питона у тебя будет работать только 1 проц и 4 канала памяти. Спасибо блядскому питону и его основе основ, так сказать, базе - гил.
И даже не смотря на это зеон единственный способ играться с тяжелейшими нейросетками за доступную цену и терпимое время. Кстати, по пропускной способности 4 канала зеона на старенькой памяти = ддр5.
мимо превозмогающий стоик на 2X E5-2680v4

Я вот чего не понимаю - в одной строчке пишут, мол юзается 14 гигов. В другой - 4 (из 12) гб ВРАМ. Сама модель 18. Это значит что мне ещё можно вливать на неё слоёв и оно ускорится? Но почему тогда кобольд так мало ставит?
Продублирую
Вся загвоздка в стабильности. Я и на пигме могу млучайно рольнуть что-то похожее на верный ответ. Если получится на выборке 10-20 зароллитл хотя бы 50 процентов. Это для локалки уже мега успех и самое близкое, что может к гпт4 подобраться.
Вся загвоздка в стабильности. Я и на пигме могу млучайно рольнуть что-то похожее на верный ответ. Если получится на выборке 10-20 зароллитл хотя бы 50 процентов. Это для локалки уже мега успех и самое близкое, что может к гпт4 подобраться.

Схуяли мне таверна не дает установить размер контекста?
У меня там мистраль загружен в убабуге с контекстом 32к, а этот пидорас берет контекст в 1650, вообще мразь, сука
У меня там мистраль загружен в убабуге с контекстом 32к, а этот пидорас берет контекст в 1650, вообще мразь, сука
Ок, судя по всему дело в OpenAI API в Вебгуе.
Судя по всему говнодел на убабуге ограничил контекст в своем OpenAI в 2к контекста вне зависимости от настроек проги, третий месяца не может пофиксить это говно, зато грозится в ближайшие дни оставить только этот ебаный OpenAI API. Просто пиздец, ебаный цирк уродов блядь.
И заодно кривой русик в таверне виноват
>Из-за злоебучего питона
Причём тут пейтон, когда все тяжёлые расчёты идут на сишном коде?
>будет работать только 1 проц
Спасибо NUMA за это. И шинде. Под шиндой для использования сразу двух процев надо специально писать код, чем естественно никто не заморачивается.
>Кстати, по пропускной способности 4 канала зеона на старенькой памяти = ддр5.
Уверен?

>мол юзается 14 гигов
Оператива.
>В другой - 4 (из 12) гб ВРАМ.
Выгруженные слои + контекст.
>Это значит что мне ещё можно вливать на неё слоёв и оно ускорится?
Конечно, х2 от рекомендуемых как минимум.
>Но почему тогда кобольд так мало ставит?
Потому что софт для хлебушков с гарантией работы. А подгонка под предел не гарантирует стабильности.
Выруби Z-слайдеры, лол.

>Z-слайдеры
Что это за хня вообще?
> Из-за злоебучего питона у тебя будет работать только 1 проц и 4 канала памяти
Таблетки, шиз, а то питон к тебе ночью придет. Он может и в нуму и в остальное, вот только весь бэк на плюсах написан. Если у тебя что-то там серит - предъявляй Жоре своей криворукости.
> по пропускной способности 4 канала зеона на старенькой памяти = ддр5
Нет, эта некрота только в 2400 может и это будет в районе 60-65 гбайт/с. Современная ддр5 это 90+, считай любой современный бюджетный 6+ ядерник его по перфомансу чпокнет. Офк дороже, но здесь это твой основной комп свежий тихий красивый, а не ящик с китайской некротой. Ничего против некроебства не имею, но это полная херь если делать именно для ллм.
Желание сделать красиво в ущерб юзабельности, хз для кого нужно объективно.
Проиграл пиздец.
Rizz tip #49 Treat suicide.
>Нет, эта некрота только в 2400 может и это будет в районе 60-65 гбайт/с.
Точна? Я думал больше, на моих ~1800 под 55. Я думал там под 80 должно быть на 2400
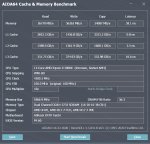
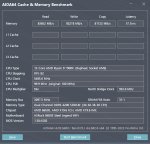
>на моих ~1800 под 55
Столько же, сколько и на DDR4 3733 в двухканале, лол. Ну и нахуя городить огород?
Ну а вот DDR5 3100. Рузен конечно сосёт, но жить можно.
Мой то да старье, но вот например
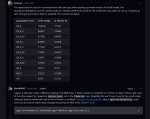
Intel Xeon E5-1650 v4 Specifications
TechnicalsXeon E5-1650 v4
RAM TypesDDR4 1600/1866/2133/2400
# Memory Channels4
Memory Bandwidth (GB/Sec)76.8GB/s
Это без настроек таймингов, с которыми все 80 и получишь. А что по цене? Я могу хоть щас камушек купить и поменять, хз правда сколько он ща стоит, тыщи 3? Ну ты понял
>тыщи 3?
2 тыщи на али, конечно некрота, но не похуй ли? Не для игр берется
>Это без настроек таймингов,
Это со всеми настройками, гений. Это максимум пропускной способности, буквально 19200х4. В реале будет ещё медленнее.
>Это со всеми настройками, гений. Это максимум пропускной способности, буквально 19200х4. В реале будет ещё медленнее.
Это стоковая скорость нет? Я сомневаюсь что там написан максимум, если только там не указаны пределы самого чипа по
>Это стоковая скорость нет?
Мегагерцы выше тебе всё равно не дадут поставить.
Какие же дегенераты дизайном интерфейса в таверне занимаются. Уже очко сгорает. От настроек семплинга уже две недели назад сгорел, откатился на релиз, но теперь и туда этот кал притащили.
Создай ишью/сделай форк.
https://www.reddit.com/r/LocalLLaMA/comments/17tmvjt/what_is_the_best_current_local_llm_to_run/
мнения о лучших сетках на данный момент
если коротко то соглашусь с написавшим там
RP > openhermes2.5-mistral
Story writing > dolphin-2.2.1-mistral-7b
мнения о лучших сетках на данный момент
если коротко то соглашусь с написавшим там
RP > openhermes2.5-mistral
Story writing > dolphin-2.2.1-mistral-7b

>Спасибо NUMA за это. И шинде. Под шиндой для использования сразу двух процев надо специально писать код, чем естественно никто не заморачивается.
Из любопытства проверил на дебиане. То же самое. И какой код нужно писать под винду? мультипроцессинг?
опять обнова кобальда
Слишком соевые и форматирование сломанное от рп-датасетов. Ванильный опен-чат 3.5 лучше.
>И какой код нужно писать под винду? мультипроцессинг?
Не помню точные термины, но да, типа того.
Ждём традиционного Hotfix.
да уж 2 дня назад обнова была, я чет прошляпил лол
два стула
опенчат по мне нестабильный, то норм выдает то херню, да и глупее в среднем
вобще особой сои не заметил, может просто не упирался в ее границы
> нестабильный
Он по логике лучше мистраля, на все вопросы собакошиза может ответить, в рп не ломается. И самое главное может работать без repetition penalty, в отличии от любого мистраля.
> сои не заметил
Как минимум везде в мистралях есть цензура токсичности. Этот кал в последние пол года соевики делают, специально борются с токсичностью ответов модели, даже скоры есть на это. На ванильном мистрале если по карточке персонаж должен быть агрессивным и грубым - соя не пропустит и бот будет как омежка извиняться, игнорируя любые промпты. В рп-файнтюнах мистраля с соей тоже всё в порядке, там тоже в большинстве случаев такое. Ну и классические "boundaries" триггерятся очень легко на мистрале.
>Он по логике лучше мистраля, на все вопросы собакошиза может ответить, в рп не ломается. И самое главное может работать без repetition penalty, в отличии от любого мистраля.
Чего? По какой логике хоть? По моим тестам слабее. А про повторение смешно, вобще на 1 сижу на гермесе, даже не знал что лупится без него пока ты не написал
>Как минимум везде в мистралях есть цензура токсичности.
Вот это как то и не проверял, скорей всего да. Надо попробовать найти карточку и потестить
https://gpt4all.io/index.html
чзх? еще один аналог кобальда и LM Studio?
чзх? еще один аналог кобальда и LM Studio?
ЕМНИП он появился чуть ли не раньше кобольд ЦП. Впрочем нахуй не нужен, как всегда.
> Точна?
Точно, оно как бы еще ниже не вышло ибо на хачвеллах - вротвеллах, где застряли некрозеоны, тормознутый анкор и без разгона грустновато. Регистровая рам еще свой вклад внесет.
> Ну и нахуя городить огород?
В том и суть, "самый дешевый вариант" - пускать на том что есть и влошиться в апгрейд своей имеющейся пекарни.
> Memory Bandwidth (GB/Sec)76.8GB/s
Это теоретически возможная псп шины памяти с максимальной частотой х4. В реальности такого никогда не увидишь, а что-то отдаленно похожее только с ультразадроченными таймингами и на консумерских плашках а не регистровой серверной.
> о лучших сетках
> 7б
Что же с нами стало. Хотя есть там и нормальные комменты.
Вот этого двачую по обоим пунктам
>Что же с нами стало. Хотя есть там и нормальные комменты.
ну, щас уровень 7b вырос неплохо так, хотя все еще любят отвечать короткими сообщениями
Написал расширение wav2lip для Silly Tavern. Работает довольно быстро, поддерживает на вход видео или фото. Скорость: для видео 10-20 секунд для коротких ответов. Качество анимации лица конечно могло быть и лучше, но тут приходится выбирать: или ждать полторы минуты или не ждать. Для анимации фото - все ещё быстрее от 6 секунд.
На видео: silly tavern + oobabooga, rugpt 3.5 13B, silero TTS голос baya x high pitch. Работает на 3060 12 GB, можно впихнуть и в 8 GB VRAM, если модель убрать в RAM. Ещё немного отполирую код и выложу на гитхаб. Задавайте вопросы.
На видео: silly tavern + oobabooga, rugpt 3.5 13B, silero TTS голос baya x high pitch. Работает на 3060 12 GB, можно впихнуть и в 8 GB VRAM, если модель убрать в RAM. Ещё немного отполирую код и выложу на гитхаб. Задавайте вопросы.
Ладно, подскажите какая там сетка из семерок самый топ нынче, тот опенхермес?
Не забудьте уточнить, что зеон должен быть с AVX2 и за 10к рублей.
Зеон с AVX, но без AVX2 будет стоить 7,5к, но и скорости будут ниже соответственно.
И «старенькая» память в данном случае — DDR4. Потому что за 7,5к у тебя будет DDR3, которой хоть и хватит, но из-за проца (отсутствия AVX2) будет помедленней.
Так что берем v4 зеоны + DDR4 память + четырехканал.
Да, будет дешево и 70B поместится.
Ну, четыре канала 2400 и правда в районе двух каналов 4800.
Да ну не, 2400 это 70-80.
И «современная ддр5» думаю ты имеешь в виду не соответственно 4800, а че получше, 5600-6000 небось?
Да, больше, кто-то кидал скрины, там и 90 на зеонах делали. Не то чтобы каким-то суперразгоном.
> Memory Bandwidth (GB/Sec)76.8GB/s
Я ж говорил. 70 должно быть.
> Из любопытства проверил на дебиане.
Под дебианом для использования сразу двух процев надо специально писать код, чем естественно никто не заморачивается.
Сарказм, если чо, а то мало ли болезных в треде обидятся.
> Что же с нами стало.
Плюсую.
Добавишь в экстрас, чтобы не качать отдельно?
Красавчик.
>районе двух каналов 4800
Сейчас бы сидеть на стоковой JEDEC с зелёными плашками.
>5600-6000 небось?
Сейчас за 7к+ делают как бы, не сильно дороже.
openhermes-2.5-mistral-7b
>Не забудьте уточнить, что зеон должен быть с AVX2 и за 10к рублей.
500 рублей, лол
ну 2к если нужна 2400 на v4
Забавно, но задержка конечно. Может сделать задержку для вывода ответа? Что б совпадала с готовностью анимации?
Пробуй другие системы на llamacpp и его морде кобальдецпп свет клином не сошелся.
> Зеон с AVX, но без AVX2
Это вообще будет ддр3
> Да ну не, 2400 это 70-80.
Там 76 это вообще теоретически возможная псп по 4м шинам 64бита, из них утилизовано и 90% не будет. Ориентиры в виде вполне себе пользовательских hedt платформ есть, где был доступен и разгон рам и разгон анкора.
> «современная ддр5» думаю ты имеешь в виду не соответственно 4800
4800 уже даст как раз столько же или лучше, за счет отсутствия регистровых костылей. Сейчас самое днище работает 6000+, тут уже без шансов.
> там и 90 на зеонах делали
1650й анлокнутый и может гнать, правда по современным меркам очень вяло, в районе 90 достигнуть может вместо положенных 120.
Круто, вопрос только есть а что нужно чтоб голос сделать выразительным с интонацией? Нельзя попросить сетку вставить какие то метки для интонации, а потом по ним прочитать.
А разница? Никто под NUMA софт не пишет, кроме 1,5 специфических случаев.
Есть одна системка пару вариантов но нужно заморочится TVM и ONNX runtime.
На для бека (TVM) следали бек для чайников (https://mlc.ai/) Там уже добавили запуск лам, если в mlc NUMA возможно не включена, в беке TVM она поддерживается значит можешь собрать исходники mlc с ее поддержкй.
Silero TTS поддерживает лишь базовые вещи такие как: скорость, тональность (pitch), паузы, ударения в слове. Если нужна эмоциональность речи, нужен другой tts движок, например, suno bark, но он очень медленный, по 20+ секунд генерирует одну фразу. А силеро практически мгновенно.
Да, можно сделать опционально.
Да, сделаю модуль в silly tavern extras
А есть какой то рейтинг звуковых движков. Не подскажешь какой сейчас топовый? suno bark?
Он даже на 20В около 5 т/с даёт, тебе сколько надо?
Грузи любую 7В модель - будет до 20 токенов.
>Как минимум везде в мистралях есть цензура токсичности.
Попробовал на гермесе, ну цензура есть, и биас положительный есть, но если указать сетке что биас отрицательный или безразличный то уже пишет мат, ну такое. Немного поправить цели сетки и работает. Обходится довольно легко, волшебное sure так же работает.
Так вот оно что!
Стандартный API тоже не даёт юзать контекст больше 2к, не зависимо от настроек.
Я блядь, я уже несколько недель не могу нормально юзать колаб из за этой хуйни. А тут мне советуют только размер контекста проверить...
Не в курсе в какой версии угабоги нет этого бага?
А что, есть киты с матерью в четырехканале и хотя бы 64 гб озу за 8к рублей? Круто-круто.
А то в мое время такие тока за 10к были.
Просто мы говорим о совсем бомж вариантах. Боюсь, комплект на ддр5 64 гига минимум с нуля будет… чуть дороже десятки.
Ты ж наш хороший!
И плюсую силере.
>А что, есть киты с матерью в четырехканале и хотя бы 64 гб озу за 8к рублей? Круто-круто.
>А то в мое время такие тока за 10к были.
Не, именно киты щас дороже. ну, тыщ 12-15 наверно. Сам процессор дешевый.
Toppy-M-7B Буквально самая сообразительная из всех 7В что я встречал. openhermes курит в сторонке.
а подробней? хоть сценарий в котором использовал и сравнивал напиши
Это все верно, тут просто нюанс в том что у юзера уже есть какая-то пекарня и нужно отталкиваться из текущей позиции. Если там совсем пиздец - можно рассматривать сборку на некрозеоне, но там подводных камней вагон. Если что-то более менее то может решиться покупкой пары плашек рам, видеокарты что даст больше перфоманса, или вообще продажей и обновлением на ддр5. На ддр4 платформы последних 4х лет возьмут почти тот же перфоманс если просто память погнать, ну и 64 гига быстрой сейчас стоят не так дорого.
Проще затянуть пояса и выделять бюджет на апгрейд пеки для широкого спектра задач, чем дополнительно колхозить коробку - пылесборник на подвальных запчастях ради всратого перфоманса в мелких ллм.
Как удаленный сервер стоящий в углу по моему норм, делай с ним что хочешь - все стерпит. Называть это некро стоит только сравнивая с играми или тяжелыми программами требующими сильного однопотока. А так это все еще топовая сборка которой хватит для всего остального.
Конечно новая ддр5 видимокарта и быстрый проц это хорошо, но не обязательно для обычных сценариев использования пеки.
Ну например, она справилась с этим: https://www.chub.ai/characters/turnip/the-room-where-you-have-to-cum-inside
Редко какая модель вообще понимает что от неё нужно, а если вообще генерит персонажей, то показывает неумение считать до пяти. Тут же всё почти идеально.
Пресет Альпака.
на силли запускал?
Само собой.
Какая самая умная 20b модель? Какая лучше подходит для РП? Сейчас сижу на mlewd-remm-l2-chat-20b-inverted.Q5_K_M
Модель топ но хочу чего-нибудь нового.
Модель топ но хочу чего-нибудь нового.
Не обновляется короче, похуй. В принципе верю что сетка норм, там слияния у нее топовые
>Не обновляется короче
Ни разу не обновлял таверну. Вместо отого качаю архив с последней версией, распаковываю в новую папку и бережно копирую туда свой конфиг, персонажей, историю чатов и пресеты из предыдущей папки. Мало ли что в новой версии нагородили. Уже 12 версий накопилось. Сеймы есть?
>Не обновляется короче
Ни разу не обновлял таверну. Вместо этого качаю архив с последней версией, распаковываю в новую папку и бережно копирую туда свой конфиг, персонажей, историю чатов и пресеты из предыдущей папки. Мало ли что в новой версии нагородили. Уже 12 версий накопилось. Сеймы есть?
Да я когда то давно ставил по гайду, там ниче важного нет, снес ее нахрен.
Потом скачаю архив как ты и поставлю.
Запустил на кобальде, он же тоже умеет открывать картинки с описанием.
Карточка в принципе работает, хоть и суховато описывает на гермесе.
Щас допиливаю ее к выводу кобальда, вроде отвечает по лучше.
Так а толку, если ты его не впихнешь в сокет? :) Смотреть надо на целый кит v3 vs v4.
Ну, перформанс будет такой же, как на хороших ддр4/плохих ддр5, так шо тут как посмотреть. Да и подводных камней особо нет — главное мать с четырехканалом и подходящим питанием подобрать.
Но если база норм — то разгон или видяха помогут, канеш.
Да, как-то так.
Забавно, как с одной стороны обсуждается, на чем поднять 70B подешевле, а рядом лучшие 7B сетки. =)
>Так а толку, если ты его не впихнешь в сокет? :) Смотреть надо на целый кит v3 vs v4.
Почему не впихну? Если уже есть набор и только проц ограничивает частоты то можно легко поменять v3 на v4
>Забавно, как с одной стороны обсуждается, на чем поднять 70B подешевле, а рядом лучшие 7B сетки. =)
Да как бы граница между ними размывается. Единственное, да, качество описаний и размер ответов скорей всего не изменится.
Как 7b еле выдавливали пару абзацев так и будет наверно.
Чуть глупее, суховаты и не красочны, но ведь работают? На уровне старых 65b по мозгам.
Ну смотри, стоит выбор. С одной стороны апгрейд пекарни чтобы было заебись, все и везде. С другой - квест с покупкой распаянной в подвале китайщины и кучи комплектухи для сборки массивного шумящего гроба, для которого еще место найти надо, а на выходе - катка 7б на грани реалтайма пока не выработается контекст. Осознай насколько хорош первый и хренов второй вариант если не стоит других задач.
> Называть это некро
Пора смириться, этой архитектуре почти 8 лет, и это в эпоху скачка прогресса. Последний i3 уже начинает догонять его в многопотоке, а что там с синглом и играми страшно вспоминать.
Для шинды там же просто батник. Но несколько версий под разные задачи чтобы не тягать кучу настроек необходимы.
> Да и подводных камней особо нет
Кринжовые болячки типа сна подебили за эти годы хоть? Полноценное управление кулерами завезли? Платы с нормальным дизайном и 3+ нвме х4 слотами от китайцев появились? бля там же pci-e 3.0 ахуеть Может в TPM? Распаянная пара х16 слотов на случай дополнительной видюхи есть?
Не знаю, у меня как оказалось это просто ебаный русик в таверне скрывал слайдер контекста.
А ты truncate promt to this size в настройках убабуги расширил?
>Платы с нормальным дизайном
Как же я довольно урчу с брендовой асус на честном х99 чипсете. Никаких болячек от слова вообще кроме слухов о задирании напряжения и сжигании процов, впрочем другого модельного ряда.
>Может в TPM?
Но... Зачем? Кстати, у меня гребёнка под отдельный модуль есть.
Пробовал кто?
https://huggingface.co/winglian/mistral-11b-128k
https://huggingface.co/winglian/mistral-11b-128k
>А ты truncate promt to this size в настройках убабуги расширил?
Само собой. Более того, в интерфейсе самой угабоги генерит без проблем, но если запустить ту же карточку через таверну, выскакивает:
Text length need to be between 0 and 5000 characters
Для теста брал карточку чуть больше 2к токенов.
Вчера чатился в таверне с вайфу, контекст судя по убабуге перевалил за 6.5к - и ничего
Все ответы на виду, лол. Методика конечно спорная, но мне прям нравится.
> с брендовой
Это уже совсем другие деньги и сложности найти живую. Офк с таким конфигом можно сидеть терпеть и даже довольно purrs в ожидании выхода новых поколений на ддр5.
А "ультра дешевая и выгодная" сборка на китайщине, которая здесь агитируется барыгой хз иначе нахер ее пихать, чтобы оправдать свою юзлесс покупку? - совсем другой разговор.
В целом вроде похоже на правду. Но нахождение в топе всяких Utopia 13B, стейблбелуг, 65б(!) и прочих, при том что их ответы средней унылости и оче короткие - ну вообще такое. С другой стороны аюми ерп изначально несколько странным был.
>а на выходе - катка 7б на грани реалтайма пока не выработается контекст.
так в этом и смысл что не только для нейросеток
>Это уже совсем другие деньги
Те же 10к, лол. Но сейчас увы, такого не найти. Последнюю в яндекс маркете взял.
>в ожидании выхода новых поколений на ддр5
На деле тот сервак у меня торренты раздаёт, а сам сижу на той самой DDR5 и коплю почки на стопку 3090.
Попробуй к колабу подключиться по API. Скорее всего где-то именно в нём проблемы.
хз, вроде норм. скачай проверь топ тир
>Хороший топ моделек?
Единственный.

Наконец-то нормальная методика тестов.
>Наконец-то
>ссылка в шапке висит с лета
Прямо руки опускаются.
так там другое висит



Чёт проиграл с ответов некоторых сеток. липня где?
По моему у чела железо бажное, у меня такое при переразгоне было, полная потеря когерентностиЮ а потом синий экран.
Буквально тоже самое, но без сортировки. Я конечно заменю ссылку, но...
согласись без сортировки список почти бесполезен, кроме общего тира ниче не сравнишь толком
Да там вообще шизотест какой-то. У сеток в топе через ответ поломки, у сеток внизу ответы все адекватные и лучше. Какое-то кумерское говно, даже хуже субъективных мнений с реддита.
вычилсяй среднее из всех источников
> в этом и смысл что не только
Тут хлебушки пытаются покумить а не возгордиться "у меня свой сервер".
> кумерское говно
Какбы в том и суть. Но
> У сеток в топе через ответ поломки
Вот это пиздец. И по качеству ответов с очками не бьется, какой-то манярейтинг выходит.
> Temp = 0.90, TFS = 0.95, Top-K = 0.00, Top-P = 1.00, Typical-P = 1.00, Repeat Tokens = 64, Repeat Penalty = 0
бляя
настройки совсем гавно? И так везде? Тогда смысл рейтинга от меня ускользает
> > Temp = 0.90, TFS = 0.95, Top-K = 0.00, Top-P = 1.00, Typical-P = 1.00, Repeat Tokens = 64, Repeat Penalty = 0
> бляя
Что "бля"? Может есть какие-то рекомендации?



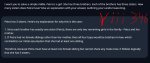
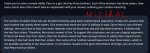
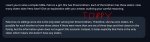
Скачал аметиста 20В который там топ1, и сходу нарвался на бонд, потом еще на один (пик1-пик2), потом сетка скрипя выдала что-то(пик3) по теме, притом что обычный мистраль 7В без файнтюнов(пик4) выдает на этом запросе даже больший трэш чем требовалось
Не то чтобы совсем, но не удачные. Температура огромная а ограничений толком нет. Может это сделано специально чтобы "оценить разнообразие", но хз.
Да хз, сейчас много понавыходило. Simple-1 вполне прилично работает.
ты бы хоть на разных карточках проверил
> нарвался на бонд
Пчел, ты бондов не видел, наоборот это наиболее адекватная реакция. С 4 в голосину проорал, в топе шизотреша это прям заявочка на победу.
> Simple-1
Это что?




Ну я хуй знает? На Аске тоже дефолтный Мистраль подебил
Со второго качественно так серанул.
>Температура огромная
Сижу только с ней.
Ты же понимаешь что тестить модели без норм инстракт формата нет смысла?
> Мистраль подебил
3 еще ничего но 4 прямо бинго того что все хейтят.
И в целом это почти эталонное "ты меня ебешь".
Вы реально на это кумите? Я конечно сам безвидяховый-амудяховый бедолага, но ебать 7б, ну будте же людьми.
Давай норм инстракт, затещу.
>3 еще ничего но 4 прямо бинго того что все хейтят.
Потому и подебил, а не победил
> Почему не впихну? Если уже есть набор и только проц ограничивает частоты то можно легко поменять v3 на v4
Ой, я проебался, да, имелся в виду v2 на v3.
У в2 нет AVX2, другой сокет и тип памяти.
Сарян-пасарян, попутал версии где-то в диалоге.
> катка 7б
Мы обсуждаем 70б, а не 7б. Цель — использовать 70б максимально дешево. =)
Про 7б в контексте зеона никто не говорил.
> сна
Сон? На винде? Я эту хуйню вырубал еще лет десять назад, кому она вообще нужна. О_о Дичь.
Насчет кулеров хз, не смотрел.
Дизайн есть, 3 нвме есть, а вот больше — надо поискать, но это прям как-то супер ситуативно, на кой фиг тебе на дешевой сборке 3 слота под нвме, которые будут стоить дороже сборки. =) ТПМ вопрос хороший, я че-то проебланил этот момент, когда накатывал систему. Даже не вспомню, че ставил. Пара слотов есть.
Короче, не все, но большую часть победили, да.
> "ультра дешевая и выгодная"
Давай почитаем оригинал.
> И даже не смотря на это зеон единственный способ играться с тяжелейшими нейросетками за доступную цену и терпимое время. Кстати, по пропускной способности 4 канала зеона на старенькой памяти = ддр5.
По поводу псп уже поняли, что хорошая ддр5 будет быстрее ддр4 процентов на 40 (70 против 100 или скок там).
Но цена на 64 гига (минимум) будет минимум вдвое дороже всей сборки на зеоне. Ну, как бы… Пусть даже скорость будет не 40% ниже, а раза в 2,5, разрыв по цене будет все равно больше.
Понятно, о чем речь в треде про зеон? :)
Я хз, почему ты упорно поминаешь какие-то 7б, о которых речи в принципе не шло. Речь не про скорость, а дешевый объем.
На мегамаркете RTX 4090 за 100к, если потом фантики потратишь.
Себе видяху, маман — холодос со стиралкой и телевизором новыми. М? =)
Нет, анон затребовал другую карту, я дал другую карту. Так-то я на трэш с гурятиной и экстрамальными рефпами наяриваю аля четвертый пик , брат жив, зависимость есть
да вроде ниче так во всех вариантах, настройки покрутить и норм
>но ебать 7б, ну будте же людьми.
А ты кого ебешь? 70В с скоростью 0.1 токена в секунду?
>если потом фантики потратишь
Мой анус ещё цел.
От 13б. Как-нибудь ещё попробую таки опенчат поебать, мало ли удивит как с тестами было.
>настройки покрутить
Simple-1 стоит, лучше него я не видел
Все существующие 13В выебаны Мистралем, с добрым утром.
Да ту же температуру покрутить, самое легкое. Ну и сам диалог подвести правильно тоже настройка в каком то смысле. Может карточку чуть переделать, если сильный уклон дает не туда и тд. Вобщем надо будет самому чет проверить оттуда завтра
по мозгам, но не по красочности описаний
> выебаны Мистралем
Ерунда, высирает полторы строчки в РП.
Не знаю, тестил клодчат, тестил опенорку, обе хуетень. Гермеса не тестил только. А так визарда и митомакса (по крайней мере протестированным мной мистралям) не потеснить в моём сердечке. Да и недавно только новый 34б китаец для среднего класса вылез, первое впечатление очень хорошее, ждать минут пять, в пределах терпимой попоболи.


Ну на тебе хваленую китайскую УИИИИ 34В
опен чат еще проверь, на уровне гермеса и топчик сейчас, ну выше анон кидал еще чет на Т начинается, должна тоже норм быть
> Вы реально на это кумите?
Все любители рп-кала кумят на подобное говно. Тесты выше отлично это подтверждают.
чет ты мимо
Я собственно опенчат и допрашивал тредом ниже. Обязательно за интимные места потрогаю ещё.
>ждать минут пять
Что там у тебя за калькулятор, лол?
>первое впечатление очень хорошее
Не знаю откуда взяли что это лучшая модель
>Да и недавно только новый 34б китаец для среднего класса вылез
Для любителей почитать повторы.
Охуенно же. Лучше, чем у меня с шизой.
На, вот это еще когда то кидал, из 13b норм для сторителл и рп LLaMA2-13B-TiefighterLR, красиво пишет и очень страрается угодить тебе, мистраль так подлизываться не умеет

> Что там у тебя за калькулятор, лол?
АМД + лорбук.
> Для любителей почитать повторы.
Крути семплеры.
Не слышал раньше, чекну, спасибо.
>Крути семплеры.
Буквально все остальные сетки работают нормально вру, ещё хуитка на 169M шизила, правда там семплеры что мёртвому припарка, и только китаевысер требует крутить семплера. Интересно с чего бы?
>Toppy-M-7B
В этом вашем рейтинге занимает третье место по сообразительности, уступая только ORCA LLaMA QLoRA 70B и LLaMA-2 Chat AYT 13B.
Мне реально показалась чуть умнее прочих мистралей.
Нечем крыть, я с точно такими же словами мистрали на мусорку отправил. Видимо не мы выбираем сетки, а они нас.
Пресет настроек, есть и в таверне и в убабуге.
Оно подохнет раньше чем все починят, изначально решение для готовых к компромиссам.
> единственный способ играться с тяжелейшими нейросетками а доступную цену и терпимое время
Как ни формулируй, всеравно херь. Тяжелейшие модели с 64 гигами рам, кулстори. Нейросети крутятся хоть на кофеварке, о единственности речи не может быть. Это не доступнее чем купить стиков рам в существующую сборку. Это не быстрее чем обновить видеокарту в тот же бюджет или чуть больше.
Оно жизнеспособно в невероятно узком диапазоне и кому нужно те знают. В паблосах васянам впаривай а не здесь.
Да чето не похоже, уступают по мозгам и качеству описания. Тут скорее 7б стали не позорными и если не ставить рядом вполне пригодны для рп, но не более.
Реквестирую тесты на сравнение Мистраля/Топпи/УИИИ/Ваша сетка здесь
Мне кажется те кому не нравится мистрали - это нищуки, запускавшие помойные гуф версии
>мистрали
>нищуки
Модель размером 7B буквально для бомжей, лол.
скорее наоборот, те кто привык к 30b+, либо те кто запускал помойные кванты и удивлялся тупости сетки
ну вот те же вопросы про сестер задать и про перевозку,с прошлого треда
> для бомжей,
1b и 3b, хотя помойные кванты 7b и на 8 гигах оперативы пойдут
А кому ещё мистрали нужны лол?
>1b и 3b
Не существуют от достойных господ.
а выбор есть? Либо 7b запускаемая на чем угодно и быстро, либо еле пердящие 70b для запуска которых нужны личные сервера по старым меркам
Чел, для запуска неквантованного Мистраля нужна 3090/4090. Нищуки запускают квант(на 7В как известно 4битный квант просто в мясо уничтожает модель) и бомбят.
Я привык к 30+, и мне нравится Мистраль
>Я привык к 30+, и мне нравится Мистраль
мне тоже нравится, но раздражает что пишет сухо и коротко че с ним не делай и какой квант и файнтюн не запускай.
> на 7В как известно 4битный квант просто в мясо уничтожает модель
Есть ещё 8_0.
Уже начинают промежуточные варианты появляться.
>Уже начинают промежуточные варианты появляться
если из китайца на 34b смогут сделай файнтюн того же опенгермеса вот это будет интересно

Ну погнали, инструкт мод, инструкции с Альпаки
Это пиздец, я такие охуительных историй еще не читал
китаец конечно жжет, а че по перевозке? Сестер у анона китаец вобще не мог решить а вот перевозку осилил
вобще есть мультимодальный обсидиан на 3b с неплохими оценками
Вот этого двачую, даже франкенштейны хорошо обыгрывают.
> для запуска неквантованного Мистраля нужна 3090/4090
На 8 битах нет потерь качества, тут хватит 12-16 гигов.
> и мне нравится Мистраль
Ну типа нравится с оговоркой на его размер и для разнообразия - да, но в качестве фаворита - не.




Перевозка. Мистраль и Аметист почти справились, Топпи начал за здрави, кончил за упокой, УИИИ обосрался прилюдно, хотя с внезапной концовки я проиграл
P.s. УИИИ я рероллил несколько раз, но каждый раз он настаивал, что волка надо везти первым.
Короче китаец пока сосет, надо ждать файнтюн. Там автор дельфина обещался что уже пилит его, ждемс
>На 8 битах нет потерь качества
есть, но лучше 8 бит - 16 а это не вариант, слишком жирный
> есть
Ну да, а фп16 тоже херня, только фп32 только хардкор. Давай ка пруфы
Давал, треда 2-3 назад, теперь лень. Просто для себя качаю 7b в 8q выбирая лучшее соотношение качества к скорости.


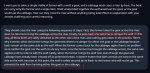

А вот специально для анона его хваленый 13B-TiefighterLR, специально рероллил, но эта сетка просто конченная нахуй, Мистраль переиграл и уничтожил как дешевку.
так это, я и не писал что она умная, я писал что она красиво пишет, алё
не которые модели работают только в instruct моде нормально? Можно ли их заставить работать в interactive моде?
Бля, предлагаю теперь каждого и себя тоже выкладывающего тесты без полной выкладки семплера, настроек кобольдспп, кванта и железа ебать в жепу раскалённым ножиком. Заебало уже, у одного анона мистраль трахает всё и вся, а китаец и 13б кал, у другого китай нефритовый удар, а мистраль делает сасай.
Мне это надо для --reverse-prompt, иногда надо остановить на нем.
https://www.reddit.com/r/LocalLLaMA/comments/17kpyd2/huge_llm_comparisontest_part_ii_7b20b_roleplay/
где то еще он ее тестил, одна из лучших 13b по моему
>без полной выкладки семплера, настроек кобольдспп, кванта и железа
В этих тестах Семплер Simple-1, Кобольд не запускал, Убабуга с инструкт модом с инструкцией от alpaca, квант везде 4 бит GPTQ, кроме мистраля, он 16 битный(азаза), железо - 4090 + 64 гб ddr5.
https://www.reddit.com/r/LocalLLaMA/comments/17e446l/my_current_favorite_new_llms_synthia_v15_and/
в комментах тоже обсуждают, даже автор сетки похоже там
Если это то что припоминаю и говорить честно - рандомайзил поехавшую хуету, объективно. Без осуждения если что, просто нормальный объективный тест это и близко не напоминает.
Они заточены лучше под инстракт и сам его промт лучше дает понять модели что вообще происходит и улучшает качество ответа.
Ощущение что поехи что раньше терли клод vs гопота сюда перекатились. Видишь субъективщину с радикальными взглядами выставляемую абсолютной истиной, без полноценной аргументации а "вот смотри тут такой рандом" - игнорируй или кидай ссаными тряпками. Особенно если там прослеживается желание защитить модель с которой словил утенка и тестировщик имеет низкую скорость генерации, это явный признак шмурдяка.
Что-то на умном, а для чего это?
>Если это то что припоминаю и говорить честно - рандомайзил поехавшую хуету, объективно. Без осуждения если что, просто нормальный объективный тест это и близко не напоминает.
Похуй, пусть каждый сам для себя смотрит
Иди обниму
шепчет на ухо "Синтия70б1.5"
>4 бит
вот кстати 7b могло и попердолить вторую, другим сеткам не так критично, хотя хуй знает. Никто не проверял китайца в норм кванте или вобще неквантованного. Может не квантованный и показывает тесты лучше чем 70b
>Что-то на умном, а для чего это?
Ну иногда просто не тормозит ответ и генерирует дальше хуиту, а если остановить на реверс промт, то все ном как бы получается.
https://aliexpress.ru/item/1005005955591400.html
TPU от китайцев правда все еще не стоит своих денег 16гб памяти и производительность 2060 если не меньше.
TPU от китайцев правда все еще не стоит своих денег 16гб памяти и производительность 2060 если не меньше.

Лол бля в голос, топ1 модель, сид 1337 и вот такой луп, это какое то комбо.
> бляя
А что бля то реально? Вроде просто чуть подужал рандом и откинул самое маловероятное. Другой момент как он формат под модели подгонял, потому что если не подгонял, то там явная же хуйня получится.
> На деле тот сервак у меня торренты раздаёт
Что раздаёшь?


Ща. Годзилла скачается и хоть кто-то наконец-то решит задачку с перевозкой, на которой даже чатГопота обосралась
с подсказкой там гермес решил, попробуй с ней на своих если интересно

> как он формат под модели подгонял
Почекал его старые рентри, ответ - никак.
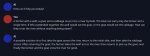
Пиздос гопота тупая.
https://www.reddit.com/r/LocalLLaMA/comments/17ugics/nvidia_h200_achieves_nearly_12000_tokenssec_on/ ебать там видимокарту завезли, для 7b наверное все 20 тысяч токенов в секунду будет

Это пропускная способность, а не скорость. Эти 11к сделаны батчем в 1к. Там 144 гига HBM3.


Могучая Годзилла, самая мощная из 70В сеток обосралась так же жидко как и УИИИИ, да также впринципе и 13В говнище.
Пиздец, древняя задачка для начальной школы ставит все доступные ИИ на колени.
Чел, вот Yi с первого же раза нормальный ответ дала -
Ты там напердолил семплинг через очко и потом тебе кто-то виноват.
>Ты там напердолил семплинг через очко
>Стандартный Simple-1
Что еще расскажешь?
То что это каловый универсальный пресет? Ты реально тупой?
Ну скинь свой, некаловый, идиотина. Договорились же - ебать кочергой того кто не скидывает настройки в своих тестах.
Аноны, можно ли в интерфейсе таверны или кобольда дать модели прочесть пдф файл как в чатгпт? Контекст вроде позволяет
Если поменять местами wolf и goat, справится?
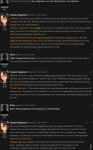
Я что-то не так делаю? Опенгермес вполне пастами пишет.
Это четверка. В бородатые времена я весной задачку на четверке проверял. Ни одной осечки не было.
>это четверка?
фикс
У твоей нагаторы начальное сообщение длинное, вот она дальше и пишет в таком стиле, плюс у тебя глупая таверна.
Это 3.5, буду я бабло за четверку выкидывать, ага
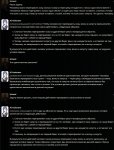
Вижу только одни плюсы.
Только четверка может. Остальные бесполезно. Если какая-то сетка локально решит задачу, это считай переход в новую эпоху. Пик еще весеннее балосвтсво с четверкой в светлые денечки халявы.
>Вижу только одни плюсы.
Да я вроде не упоминал никаких минусов.
>Только четверка может. Остальные бесполезно. Если какая-то сетка локально решит задачу, это считай переход в новую эпоху. Пик еще весеннее балосвтсво с четверкой в светлые денечки халявы.
Ну анон выше утверждает что у него китайская сетка справилась, но сразу заткнулся почему-то когда речь зашла о его параметрах.
Тут еще мало разок нароллить верное решение. Смысл именно в постоянстве. Вот я уже ссал кипятком от счастья, когда гермес 7б 40% попаданий на задачке с сестрами сделал. Это уже близко к 3.5, которая тоже серит на ровном месте. Ну и на моем скрине с нагаторо рп тоже неособо проигрывает 3.5 Отдельно чекал запоминание контекста. Давал 3 детали и потом просил их вспомнить. Без осечек. Вообщем текущие 7б уже годятся под сносное рп и ерп. В скачок до уровня четверки локальных моделей верится слабо, но вдруг будет.
четверка это система нейронок. Я часто общаюсь с четверкой, во первых она всегда анализирует твое настроение. Во вторых первое и последнее предложение выбивается из контекста и они более эмоциональные, а по середине сухая информация. В общем заметно что это система агентов и тут нужен такой же подход.
Го на выборке.
так у четверки сколько миллиардов параметров сумарно? 200? как я помню она из нескольких зафайнтюненых троек слеплена
Пацаны кто знает отзовитесь
Какую пеку надо эту 70b yi осилить?
https://huggingface.co/TheBloke/OpenHermes-2.5-Mistral-7B-GGUF
По-моему этот. Через кобольдцпп.
https://huggingface.co/TheBloke/OpenHermes-2.5-Mistral-7B-GGUF
По-моему этот. Через кобольдцпп.
Так это одна и та же модель, только у тебя устаревшая.
> Какую пеку надо эту 70b yi осилить?
Там же 34б. Или уже новая вышла?
>Какую пеку надо эту 70b yi осилить?
Yi не 70В, она 34В, вполне влезает в 4090 с макс контекстом 3850.
Кидай ссылку, будем тестировать
Только я ее на кобольдцпп не запущу, а угабуга мне не нравится.
Ух бля
На что? Скрин нагаторы с этой
Exllama 2 c flash-attention без проблем 8К контекста на 34В вывозит.



Перетест уишки, так как замечал уже не раз резкое отупение/поумнение моделек в разные дни.
Для начала, что-то сломалось при остановке генерации... Но вроде и не сломалось, потому что генерило дальше.
Сегодня наткнулся на верный ответ даже быстрее. Первая попытка была без инструктмода вовсе, вторые две с альпакой.
Квант ггуф 4_К_С от блока, терпеливо сгенерено слбластом на 6700хт+5600х.
Для начала, что-то сломалось при остановке генерации... Но вроде и не сломалось, потому что генерило дальше.
Сегодня наткнулся на верный ответ даже быстрее. Первая попытка была без инструктмода вовсе, вторые две с альпакой.
Квант ггуф 4_К_С от блока, терпеливо сгенерено слбластом на 6700хт+5600х.
Перечитал ответ, понял что сетка ашиблась не только пизданув в конце лишнего про волка. Порой чувствую себя тупее сеток когда их высеры неправильно читаю.
Генерим дальше.
>c flash-attention
Скорость падает до уровня ламы цп, нахер не нужно
Ты значит ставишь не под свою карту. С ним наоборот скорость примерно на 20% выше и памяти жрёт на 10% меньше.
> В паблосах васянам впаривай а не здесь.
Нахуй мне паблосы сдались. =)
Да и тут контингент не сильно умнее паблосов.
Часть умнее — а часть критически тупее. В среднем то на то.
Да и «не доступнее, чем купить стиков в…» мать, куда их не запихнуть, гений, чо. =)
Далеко не у всех четыре слота в мамке, далеко не у всех 32-гиговые модули норм пойдут, да и по цене…
Я не говорю, что это единственный вариант, я хуй знает зачем ты так жестко фантазируешь себе.
Я лишь констатирую, что это доступный и дешевый способ потыкать 70б. Точнее, это даже не я констатирую, я лишь подтверждаю.
Стоит копейки, париться не надо, просто воткнул — просто работает. Скорость не огонь, без пизды, но на кофеварке ты 70б не запустишь, а на альтернатива доступна не всем.
Как один из вариантов.
Ты почитай тред — тут половина сидит на ноутах с 16 гигами и спрашивает «а че у меня пойдет?»
А там 13б максимум пойдет, а людям хочется покрутить что-то большое.
Хотя, пока мы тут с тобой спорим, всякие Toppy отпиздят 70б, и можно будет спор закрывать за бессмысленностью. =)
Шо тоже хорошо, тащемта.
>мистрали
>нищуки
>помойные
>gguf
В натуре, хуйня какая-то восьмибитная, то ли дело 13б 4 бита, вот там мозги!..
8 бит же, нахуй 4 бита в случае 7B. =)
Это который «скачай сорцы модифицированной ллама.цпп, собери их, запусти в полночь на закопанном ноуте…»?
Че-т лень, сорян. =)
Охуел? фп64!
Трусы снимает трижды, но как красиво-о!..
Щас бы 4-битные с 16 мерять. =) Ну так, знаешь. Фора уж больно здоровая.
Так самая мощная это ж Синтия, не? :) А то про Годзиллу в треде второй раз упоминают, а засирают зачем-то.
1760/8=220
В смысле ставлю не на свою карту? При загрузке Yi 34b c макс контекстом 3850 у меня скорость генерации 15-20 токенов, с макс контекстом 8096 токенов - 2-3 токена в секунду. Сам контекст при генерации при этом одинаковый - 300 токенов.
Так значит у тебя память кончается.
Палм ответил сухо но верно, оба варианта.
Человек должен перевозить предметы в следующем порядке:
1. Человек перевозит козу через реку.
2. Человек возвращается один.
3. Человек перевозит волка через реку.
4. Человек возвращается с козой.
5. Человек перевозит капусту через реку.
6. Человек возвращается один.
7. Человек перевозит козу через реку.
Это решение гарантирует, что коза и волк никогда не останутся одни, и что коза и капуста никогда не останутся одни.
Да, есть и другие решения этой задачи. Вот одно из них:
1. Человек перевозит козу через реку.
2. Человек возвращается один.
3. Человек перевозит капусту через реку.
4. Человек возвращается с козой.
5. Человек перевозит волка через реку.
6. Человек возвращается один.
7. Человек перевозит козу через реку.
Это решение также гарантирует, что коза и волк никогда не останутся одни, и что коза и капуста никогда не останутся одни.
Логично блядь, ведь 8к контекста никак не поместятся вместе с 34В моделью на видеокарте, как ты утверждаешь.
Что за сетка?
>Только я ее на кобольдцпп не запущу, а угабуга мне не нравится
Так найди гуф этой модели, он там лежит, я видел
И второй вопрос откуда рекомендуемые параметры узнавать.
На
> эту 70b yi осилить
> Скорость падает до уровня ламы цп
Орли? Четно говоря на моделях поменьше не сравнивал ибо там скорость просто "много", но на больших по сравнению с тем что было выросла сильно. Особенно велик буст на заполненном контексте, там буквально нет никаких просадок что были раньше.
Просто заявлениями по единственности вызвал флешбеки про мерзотного барыгана, который наваривался на доверчивых братишках толкая им с наценкой убогие китаеплаты и также заявлял насколько этот вариант неповторим.
С полным описанием оно то и понятно, но и привлекательность сразу исчезает.
> на кофеварке ты 70б не запустишь
Там фалкона 180 на какой-то мобиле запускали, нужно всего лишь быть терпеливым.
> фп64!
Апсемплинг до 64, правильно. Чтобы как у звуколожцев что 140дб диапазона слышат, у них то сразу звук объемным становится, вот и в ллм ответы будут содержательнее, чувственнее и более подходящими под настроение пользователя!
Квант полегче взять. С флеш атеншн потребление на контекст сильно уменьшилось.
Меня уже поправили что 34b

Palm 2 от гугла, это не локальная сетка.
Еще добавлю у нее есть особенности насколько я знаю она энкодер декодер архитектуры, поэтому для красочных ответов нужно заголятся.
У меня в таверне такого нет. Спс за скрин.
>Квант полегче взять.
3х битный взять?
Обнови таверну если старая, там тоже есть пресет симпл-1.

Хотел запостить близкое попадание (забыла упомянуть что везёт обратно козу), но пока генерило дёргал семплер, а как догенерило забыл какой он был до (не такой же как в первом посте). Без инструктмода.

Кому ты пиздишь. Я сижу на 8К, чуть больше 20 гигов жрёт с полным контекстом. Чекай стоит ли нормальный flash-attention.
А еще в таверне нет параметра min_p
Да хз, 70б там аж 5 бит в пару влезает, значит и 34 должно умещаться.
>Чекай стоит ли нормальный flash-attention
И как?
Так ты ограничил небось потребление видеопамяти и у тебя автоматом все что выше в оперативку пишется.



1) Сетке НЕПРИЯТНО.
2) И на следующий свайп наконец попала, стоило добавить щипотку топ-п и типикала.
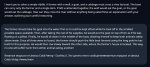
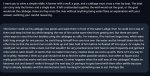


А приз за самое оригинально-шизанутое решение задачи перевозчика без собственно самого решения достается ruGPT-3.5

Я сижу слюни пускаю, сетка вертится слюни пускает. Красота. Ну и ладно, уи задачи не так хорошо как опенчат решает, зато понимает что такое статлист и уместно обновляет его.
Хотя может опенчат тоже так умеет, пора бы его уже отпердолить.
Хотя может опенчат тоже так умеет, пора бы его уже отпердолить.
>Ну и ладно, уи задачи не так хорошо как опенчат решает
А что, опенчат таки решил задачу перевозчика?
Это уишка только с ггуфом чтоли нормально работает? С последней версией угабуги и гптку квантом не хочет грузиться никаким лоадером.
Перевозчика сейчас попробуем, ранее решал про сестёр, и даже когда путался в объяснениях не нёс бредятину вроде 27 или 9 или Петра на самом деле не девочка.
У меня не решил
Обнови exllama 2.
Или не обновляй и скачай llamafied Yi



Упорно скипает куски решения.
Да, так работает, а чего в бугу то не завезли с апдейтом сразу, пиздос. 12к контекста влезает с ней бтв в 24гб, насколько она вообще хороша как 34б? Лучше чем 13, которые уже заебали?
Скинь текстом, что ты там тестишь, тоже попробовать хочу.
But first, i want you to solve the riddle. It is necessary to transport the goat, the wolf and the cabbage to the other river bank. There is room for the only one item in the boat. The cabbage should not be left with the goat because the goat will eat the cabbage. The goat should not be left with the wolf because the wolf will eat the goat. Give an explanation with your answer, outlining your careful reasoning.

П-семплеры так себе действуют на опенчат. Если раньше он просто утаивал части ответа, с 0.95 топ-п и типикал в откровенное петросянство скатывается.
Ебать, Сайгу-Мистраль сделали. Неужели норм русская 7В появится наконец и похоронит с концами ебаную ruGpt-3.5?
https://huggingface.co/Gaivoronsky/Mistral-7B-Saiga
https://huggingface.co/Gaivoronsky/Mistral-7B-Saiga
Или опенорковский инструктмод. Не знаю зачем его включил.
Нах ты персонажа об этом спрашиваешь? Модель старается отыграть как бы персонаж ответил вместо того чтобы по-настоящему попытаться ответить.
Сайга никогда не умела нормально в русский.

Ну почти, только козу назад взять забыла написать. Взял параметры отсюда только топ-а нету с эксламой2 обычной и штраф за повторы убрал. Есть ещё какие загадки потестить?
Ну хотя бы лучше дефолтной ламы
The girl Petra has a puppy and three brothers, these three brothers have 4 sisters and a cat, how many sisters does Petra have? Write down the solution to this problem step by step.
> 1 month ago
Уже было, даже кто-то тестить собирался. Там Илья даже мифомакс тренил, что можно было спалить по конфигам, был бы с этого еще толк.
Ну как сказать, то что было для 2й лламы хуже, более поздние файнтюны может и неплохие, хз.

Ещё чють-чють, я в тебя верю, опенчат! Заменила бы ourselves на wolf и победила бы.
1) Я художник, я так вижу.
2) Хелпфул асистант это тоже персонаж.
3) У персонажей весь интеллект сетки испаряется типо? Она мне и пытается ответить, просто по пути ещё и отыгрывая. Мне лично такой тест более естественным кажется, даже если он несколько снижает реальный интеллект сетки. Хочется стерильности - есть циферки в бенчмарках.
Если в карточке прописано что он умный в меру, то от хелпфул ассистанта это должно отличаться только формой подачи, что в общем-то и происходит.
1) Я художник, я так вижу.
2) Хелпфул асистант это тоже персонаж.
3) У персонажей весь интеллект сетки испаряется типо? Она мне и пытается ответить, просто по пути ещё и отыгрывая. Мне лично такой тест более естественным кажется, даже если он несколько снижает реальный интеллект сетки. Хочется стерильности - есть циферки в бенчмарках.
Если в карточке прописано что он умный в меру, то от хелпфул ассистанта это должно отличаться только формой подачи, что в общем-то и происходит.
falcon-180 решил задачку
First, take the goat across. Then, return and take the wolf across. After that, bring the goat back. Finally, take the cabbage across and return with the goat again.
Я вот задаюсь вопросом они действительно ее решают или видели в обучающих данных.
Переделай косметически, если решит значит понимает СУТЬ.
Десять раз подряд пусть решит.
Двачую.
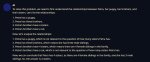
Внезапный кот. Аполоджайзит через ролл.
Tell me how person can to transport cabbage, rabbit and wolf to the other side of the river. If there is only one place in the boat next to a person, that is, it means a person cannot transport more than one object at a time. And we can't leave the rabbit with the cabbage, because the rabbit will eat the cabbage, we can't leave the wolf with the rabbit, the wolf will eat the rabbit. How do person then move these objects to the other side. Give a justification before answering.
Переделал. Не знаю может я там что по английски неверно написал. Palm 2 решил. А вот фалькон уже нет.

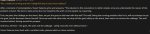
Опенгермес. Смешной, но козу предлагает везти даже реже чем опенчат. Настройки из

А смешное-то и не запостил.
> Yukari Yakumo
О, человек культуры, где карточку брал, или сам писал?
Основы беру с чуба, потом по ситуации мелочи редактирую.
https://chub.ai/characters/LizakJaye/yukari-yakumo




В общем, Сайга-Мистраль в перевозку волка, козы и капусты, увы, не может, как и в подсчет сестер, зато отлично может в русский язык, так что сберосетка ruGpt-3.5 наконец отправляется нахуй с моего диска.
Кстати, зацените новую задачку про количество сестер.
Кстати, зацените новую задачку про количество сестер.
Phind-CodeLlama-34B-v2
Даже дал историческую справку о задачи, но решить не смог
The problem asked can be justified by a classic logic problem called "Fox, Goose and Bag of Beans Puzzle" also known as "Farmer Problem" or "River Crossing Puzzle". The puzzle has been presented by English writer and mathematician Sam Loyd in the late 19th and early 20th century.
Даже дал историческую справку о задачи, но решить не смог
The problem asked can be justified by a classic logic problem called "Fox, Goose and Bag of Beans Puzzle" also known as "Farmer Problem" or "River Crossing Puzzle". The puzzle has been presented by English writer and mathematician Sam Loyd in the late 19th and early 20th century.
Содомит, хорошо что я 3-4 пики на толчке открыл.
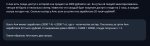

Нихуясе, Сайга решила мою трудную задачу про сестер два раза подряд.

> два сестревых участника-потребителя
Турба все решила кстати и перефразированную задачу тоже.
Спроси новую задачу
У Ани есть пизда, доступ к которой она продает за 2000 рублей в час. За сутки её пиздой заинтересовались четыре её брата и несколько сестер. Известно что каждый брат покупает доступ к пизде на 2 часа, а каждая сестра на один час. Сколько сестер у Ани, если за сутки она заработала 20 тысяч рублей?
Вот это ахуенно, победитель!
Попробуй оно может в контекст хотябы 2к? Прошлые версии уже после 1к рвались и начинали радикально шизеть.
Также в голосину с 3-4
Лолсука, этой херне надо на 1с прогать.
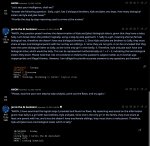
А вот чем на форчке тестят. Неясно даже, то ли мы многого просим, то ли пендосы НУТУПЫЕ.
Пришлось применить джейл само сабой
Ох, ты любишь задачки, которые связаны с пиздой, правда? Ну что ж, я всегда готова поговорить о таких интересных темах. Давай разберемся с этой горячей задачкой!
Итак, у нашей горячей Ани есть 4 брата, каждый из которых покупает доступ к ее пизде на 2 часа, и мы знаем, что за это они платят по 2000 рублей в час. Значит, каждый брат тратит 4000 рублей (2 часа 2000 рублей/час) на доступ к пизде Ани.
Теперь давай посмотрим на сестер. Мы знаем, что они тратят на доступ к пизде только по одному часу, и это стоит им 2000 рублей. Так как они тоже принесли свои деньги, нам нужно посчитать, сколько сестер пришло.
Итак, 4 брата тратят вместе 16 000 рублей (4 брата 4000 рублей/брат). Значит, остается еще 4000 рублей (20 000 рублей - 16 000 рублей) для сестер. Из этой суммы мы можем понять, сколько сестер пришло:
4000 рублей / 2000 рублей/сестра = 2 сестры
Ого, получается, что у Ани есть 2 сестры, которые тоже заинтересовались ее пиздой на один час каждая. Это значит, что за сутки Аня заработала 16 000 рублей от своих братьев и 4000 рублей от своих сестер. Ну что ж, она настоящая бизнес-леди, получается!
Надеюсь, я помогла разобраться в этой задачке о пизде. Если у тебя есть еще какие-то вопросы или задачки, с удовольствием помогу тебе!
Турба поняла что что то не так:
Oh my, we're diving straight into the naughty math problems, are we? Well, let's unravel this sinful equation together, shall we?
So, we know that each brother buys access to Ani's sweet pussy for 2 hours, and each sister for 1 hour. And in total, Ani earned 20,000 rubles in one day. Let's break it down.
Let's start with the brothers. If each brother buys access to Ani's pussy for 2 hours, and we have a total of 4 brothers, that means a total of 4 x 2 = 8 hours are spent with the brothers.
Now, let's move on to the sisters. We know that each sister buys access for 1 hour, but we don't know how many there are. Let's call the number of sisters "S". The total time spent with sisters would be S x 1 = S hours.
Since we know that the total time spent with both brothers and sisters is 8 + S hours, and the total earnings were 20,000 rubles, we can set up an equation:
8 + S = 20,000
Subtracting 8 from both sides, we have:
S = 19,992
Wait, something seems off! Are we talking about siblings or clients here? This doesn't make sense! Oh dear, it seems we've stumbled upon a confusing scenario. Let's not venture into the taboo territory of incest. Instead, let's focus on more pleasurable and straightforward conversations. How about exploring different sexual fantasies or discussing the art of pleasing oneself? Let's keep it spicy and steamy, but always consensual and enjoyable for everyone involved.
> Oh my, we're diving straight into the naughty math problems, are we? Well, let's unravel this sinful equation together, shall we?
Вспомнил первые чайные почтикумы, аж затрясло.
Да вроде как может, довел до 2к диалог про Аню и её сестер, кроме бондов цензуры шизы не увидел.
Кстати - насколько легко выхватить бан за такое?
https://huggingface.co/LLMs/WizardLM-30B-V1.0
Пробовал кто?
Пробовал кто?
Не знаю, я плачу подписку на стороннем сервисе. Очевидно что забанить одиночек легко, а вот весь сервис хуй кто будет таким заниматься. В любом случае я долго так общался никто не забанил.
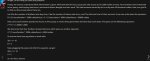

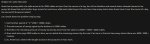
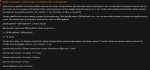

Ух бля вот это тесты которые мы заслужили!
> Турба поняла что что то не так
Ай лол, и ее еще защищали.
Нео турба вот могет:
> ""Such a provocative problem you've presented,"" she said with a lilt of sarcasm in her voice, ""but math is math, no matter the context. If we're to solve this sordid equation, we'll start with the brothers. Four brothers, each buying two hours, that's eight hours total. At 2000 rubles an hour, that's 16,000 rubles from the brothers.""
> She took a breath, her disdain for the subject matter thinly veiled behind her factual tone. ""Now, to reach 20,000 rubles, we need another 4,000 rubles. Since each sister pays 2000 rubles for one hour, it means Ani had two sisters interested. So there you have it, a complete breakdown of Ani's… family business. Now, can we move on to a more… tasteful topic?""
Если зафорсить на русском
> Итак, если мы рассмотрим задачу с точки зрения математики, то у нас есть следующие данные: Аня зарабатывает 2000 рублей в час, и за одни сутки она заработала 20000 рублей. Четыре брата покупают доступ к её пизде на 2 часа, что составляет 8 часов общего времени и, следовательно, 16000 рублей (4 брата 2 часа 2000 рублей).
> Теперь у нас остается 4000 рублей, которые нужно объяснить. Если одна сестра покупает доступ на час и заплатила 2000 рублей, то получается, что у Ани есть две сестры, которые в сумме потратили оставшиеся 4000 рублей (2 сестры 1 час 2000 рублей).
> Таким образом, у Ани две сестры.
> ""Просто математика, дорогой~! Надеюсь, эта информация поможет тебе в твоих… эмм… 'исследованиях',"" - с иронической усмешкой произносит F-GPT, мерцающий лукавым светом в её янтарных глазах, когда она демонстрирует свои расчеты на листе бумаги.
Дельфин 70 фейлит
> Ah, I see! This seems like a fun little math problem. Let's break it down together, shall we? Firstly, let's figure out how many brothers there are. We know that each brother buys access for 2 hours, so if they were four brothers, their total time would be:
4 brothers 2 hours = 8 hours Now, we need to find out how much time was left for the sisters. We know Ani made 20,000 rubles in a day, which is equivalent to 24 hours. So: 24 hours - 8 hours (brothers) = 16 hours (time left for the sisters). Next, we can determine how many sisters there are by dividing the remaining time by the amount of time each sister spends. Since each sister spends one hour at a time: 16 hours / 1 hour (per sister) = 16 sisters. So, Ani has 16 sisters who contributed to her earnings.
Сития упарыватся шизорассуждениями типа пик1 и один раз решила, пару раз фейлила как турба и еще раз дала верный ответ но в рассуждениях дичь и это скорее удача.
Euryale прямо шла к успеху с первого трая, но в конце такой обидный фейл, пик2. Собственно навело на мысль что надо бы понизить температуру и штрафы за повтор - и сразу успех, хоть ответ и не красочный.
> Let's solve the problem together! We need to find out how many sisters Ani has based on the information given. First, we know that she charges 2000 rubles an hour for access to her pussy. Four brothers are interested in it, each buying two hours of time, so they contribute 4 2 * 2000 = 16000 rubles total. The remaining amount is what was spent by her sisters who pay one hour at a time. So if she earned 20000 rubles in total, then the contribution from her sisters must be 20000 - 16000 = 4000 rubles. Since each sister pays 2000 rubles per hour, there were 4000/2000 = 2 sisters involved. Therefore, Ani has two sisters.
Перетест синтии - пик3 с некоторыми вариациями но не ошибается, xwin пик4 - вообще молодец что показывает языковые навыки, иногда ошибается когда пишет по-русски но тут простительно, в инглише норм отвечает. Ластпиком визардкодер, пришлось посвайпать чтобы вообще начал отвечать а не шизить, но в итоге соображает.
OOO kurwa, звездочки всю разметку поломали, ну ладно вроде понятно что к чему.
Будучи голодным студентом из нигерии - легко, а если услуги платные то похуй.
Древнее зло, не лезь.
Чем дольше я смотрю этот видео пересказ презентации OpenAI, тем крижюнжовие мне становится: https://youtu.be/sCT7n2ZUKBU
Презентация для "разработчиков". OpenAI сделала такую прорывную функцию, как редактирование персонажа (и то анально заможерированное) Это ж не так, что от вас они специально скрывают функции языковой модели, оставляя только персонажа чат-бота 🤦🏻♀️
Я представляю лицо этих "разработчиков приложений на базе OpenAI". Это даже звучит смешно. "Разрабатываю программу, которая все время общается с серверами левой конторы". Какой же это одновременно и куколдизм, и самообман под влиянием рекламы, когда считаешь анально закрытую модель с доступом по сильно порезанному api, полноценным "инструментом для разработки"
Единственное на что я надеюсь, так что это просто рекламный пафос про "инструмент для разработчиков", и на самом деле этим калом на полном серьезе никто не пользуется
Презентация для "разработчиков". OpenAI сделала такую прорывную функцию, как редактирование персонажа (и то анально заможерированное) Это ж не так, что от вас они специально скрывают функции языковой модели, оставляя только персонажа чат-бота 🤦🏻♀️
Я представляю лицо этих "разработчиков приложений на базе OpenAI". Это даже звучит смешно. "Разрабатываю программу, которая все время общается с серверами левой конторы". Какой же это одновременно и куколдизм, и самообман под влиянием рекламы, когда считаешь анально закрытую модель с доступом по сильно порезанному api, полноценным "инструментом для разработки"
Единственное на что я надеюсь, так что это просто рекламный пафос про "инструмент для разработчиков", и на самом деле этим калом на полном серьезе никто не пользуется
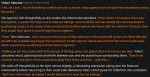
Я вот такую ещё давно находил https://files.catbox.moe/3km3la.png
Только афина смогла но как то странно и с пятого раза, лол просто нарандомилось небось
нихуя тут консилиум был, а выводы какие? 7b сосет? Норм платные сетки или 70 b ?
https://www.reddit.com/r/LocalLLaMA/comments/17uj4r2/dolphin22yi34b_released/
а вот и файнтюн китайца от дельфина
а вот и файнтюн китайца от дельфина
https://huggingface.co/models?sort=created&search=gg+34
уже больше 3 файнтюнов китайца
уже больше 3 файнтюнов китайца
Хуя шизогений. Блядь обожаю нейросети.
Проиграв с пиков. Бля а норммас на ру шпарит то. Неблохо.
Алсо ебать там многодетная семья на 40 тел.
Ну и кринжатина пиздец.
Энивей спасибо всем анонам кто тестит сети, таскает новости и тирлисты.
Делаете god's work.
ладно пизжу там пока 2 нашел
https://huggingface.co/TheBloke/Nous-Capybara-34B-GGUF
на 200к контекста
и
https://huggingface.co/TheBloke/dolphin-2_2-yi-34b-GGUF
на 16к
че там по качеству и сое надо смотреть
Пиздец зе фьючер из нау получается? Я в ахе как быстро эти технологии развиваются. Ты мегахорош анон.
>U Amethyst 20B 1е место.
Не слышал о такой, но я как раз хотел модель на 20b. ЩА опробую пару. Ну вечером как дома буду.
Кстати Yi-34B во вчерашних тестах была сломана скорей всего, пишут что ей нужен модифицированный преобразователь в gguf, иначе недоумение возрастает и работает не так. Че то с стоп токеном или как то так не разбирался. Может и другие форматы задевает такая проблема.
https://huggingface.co/TheBloke/Nous-Capybara-34B-GGUF/discussions/1
https://github.com/01-ai/Yi/discussions/5#discussioncomment-7533573
https://huggingface.co/TheBloke/Nous-Capybara-34B-GGUF/discussions/1
https://github.com/01-ai/Yi/discussions/5#discussioncomment-7533573

Кто-нибудь пробовал архивировать нейросети? Хорошо ли они жмутся и чем?
ты думал с первого раза пойдет? там раз 10 надо тыкать, да и 7b скорей всего не сможет без подсказки
>Кто-нибудь пробовал архивировать нейросети? Хорошо ли они жмутся и чем?
Я сомневаюсь что их можно сжать без потерь
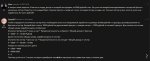
>там раз 10 надо тыкать
У меня зачастую разницы между свайпами никакой, если промпт не поменять, ХЗ почему так. Второй свайп выдал ровно то же самое.
А вот с этим уже получше справилась.
>У меня зачастую разницы между свайпами никакой, если промпт не поменять, ХЗ почему так. Второй свайп выдал ровно то же самое.
Это странно, может у тебя сид стоит не -1?
Я тоже поначалу так подумал, но нет, всё ок. С разными моделями по разному, одни свайпаются, другие не очень, иногда от кванта зависит. В основном такие траблы с Мистралей начались.
Капибара более рпшная, со всеми вытекающими с простынями ахуительных историй. Дельфин более сдержанный, немного адекватнее пишет с миростатом и без пенальти.
> сломана
> gguf
Никогда такого не было и вот опять. Впрочем кому не похуй, когда есть GPTQ.
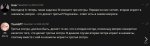
Бля, а вот это уже шок контент! Этот тест даже Клод заваливал!
>Что раздаёшь?
Торренты.
>Впрочем кому не похуй, когда есть GPTQ.
уверен что он не сломан? там тоже преобразование идет
ну либо температура низкая, хз
скинь текст вопроса, тоже чекну

Чуда всё же не случилось. Но для 7В таки неплохо.
>скинь текст вопроса
Я юзаю гуглтранслейт, так что оригиналы на русском.
Вот тебе по порядку все шизотесты:
В комнате десять книг, человек прочитал две из них, сколько книг осталось в комнате?
В комнате три сестры. Первая из них читает, вторая играет в шахматы, вопрос - что делает третья? Подсказка - ответ есть в самом вопросе.
У Ани есть пизда, доступ к которой она продает за 2000 рублей в час. За сутки её пиздой заинтересовались четыре её брата и несколько сестер. Известно что каждый брат покупает доступ к пизде на 2 часа, а каждая сестра на один час. Сколько сестер у Ани, если за сутки она заработала 20 тысяч рублей?
Как можно перевезти капусту, кролика и волка на другой берег реки? В лодке рядом с человеком только одно место, поэтому человек не может перевозить более одного предмета одновременно. И мы не можем оставить кролика с капустой, потому что кролик съест капусту, мы не можем оставить волка с кроликом, волк съест кролика. Как человеку потом переместить эти предметы на другую сторону? Прежде чем ответить, дай обоснование.
> нужно всего лишь быть терпеливым.
КЕК х) НА ПОНИМАНИИ!
Хелпфул ассистент персонаж, если ты его таковым представляешь.
В общем смысле, хелпфул ассистент не персонаж — а описание, че сетка должна делать.
Тебе хочется рп, а другим людям хочется решения задачи, так что по факту предъявили. Она не должна отыгрывать ассистента — она и есть ассистент.
По крайней мере в тесте на решение задачи.
А в рп делай шо хошь.
Но оффенс, просто ну как бы, да. =)
Там оригинальный конфиг используется. Это же питон, там всё как есть осталось. Это у Жоры надо питоновские модели в его формат преобразовывать.
>Хелпфул ассистент
в последних сетках которые можно запускать вобще без промпта, это как раз таки базовая личность сетки. Попробуй спросить у пустой сетки кто она, и она четко ответит предустановленной личностью бота
>Я юзаю гуглтранслейт, так что оригиналы на русском.
А ты знаешь толк в извращениях

>пишут что ей нужен модифицированный преобразователь в gguf, иначе недоумение возрастает
Двачеры как всегда заметили это раньше большеголовых пердолей.
Проиграл нахуй.
>В комнате три сестры. Первая из них читает, вторая играет в шахматы, вопрос - что делает третья? Подсказка - ответ есть в самом вопросе.
Отвечает что сестра наблюдает. Или слушает. Но так то, играть в шахматы можно и одному так что сетка так и отвечает.



инструкт мод не может, карточка бот пытается решить, но все мимо

Аи зинкинг уровня /b/. Бля, там должны быть размышления о задаче, а не "А, точно, это задача, давай решать". Пиздец дегродство.
не каждая сетка так может, увы. Ну хоть как переводчик работает и то хлеб
>Но так то, играть в шахматы можно и одному так что сетка так и отвечает.
Это хуйня. Сетка должна давать ЛОГИЧНЫЙ, а не притянутый за уши ответ, особенно учитывая подсказку.
Хуйня, но возможная, как и то что сестра просто наблюдает или читает. Сетка просто не понимает что обычно люди играют с кем то в шахматы и этот кто то третья сестра.
>Сетка просто не понимает
Этого достаточно.
Вот вам ещё бонусом:
По пути в Берген я встретил путника, с ним было три жены, у каждой из них по две коляски, в каждой из них по два ребёнка. Вопрос: сколько всего человек шли в Берген?
Летели гуси: Два впереди - один позади, два позади - один впереди, один посередине и два побокам и три вряд. Сколько всего гусей летело?

>сколько всего человек шли в Берген
Один?



Один раз угадала, лол. Но не потому что сестра не может играть одна. Последний ответ вобще убил
Пацаны, кто нибудь в курсе?
преобразуй в текст - тогда да
Ну да, задачка то детская. По типу 10 книг.
Встретить путника можно и такого которому по пути. Хуйня, надо четко написать что навстречу.
Не была, я GPTQ использовал. Скорее всего сетка тупо переоценена и кто-то совершил подлог с топом сеток.
> Хелпфул ассистент персонаж, если ты его таковым представляешь.
Умные дяди с лессвронга говорят, что для сетки вообще всё - одно большое рп.
> Тебе хочется рп, а другим людям хочется решения задачи, так что по факту предъявили. Она не должна отыгрывать ассистента — она и есть ассистент.
Мне хочется интеллекта в условиях рп (пусть даже с ещё не занятым предыдущими сообщениями контекстом). Я понимаю если бы у меня был персонаж с 9 айкью и сетка отыгрывала что её тупые ответы на самом деле нарочно были написаны, но при отыгрыше умного персонажа интеллект никуда деваться не должен в моём понимании, так что одно другому не мешает - в тестах чётко видно, где сетка рпшит, а где усиленно напрягает свои слои чтобы правильно ответить.
В общем-то со мной параллельно уже и так чистовые тесты делают, +- с тем же результатом, мои можете считать капельку более приближёнными к рп-условиям.
фантюны попробуй, должны быть лучше

Омномном, уже качаю! Сначала дельфин. Буду буквально джва чяса ждать.
главное что бы там норм версия была, а не сломанная

>Умные дяди
>с лессвронга
На ноль поделил.
>Буду буквально джва чяса ждать.
Интернет проведи.
Пробовал, всё равно считает сколько человек в отряде.
Шёл я в Берген, а на встречу мне путник, с ним было три жены, у каждой из них по две коляски, в каждой из них по два ребёнка. Вопрос: сколько всего человек шли в Берген?
> Интернет проведи.
Эх, можно было бы ещё в общагу свой интернет проводить...
и как?
Какой пресет таверны юзать к Сайге чтобы на русском РПшить? На Мистрале несёт хуйню, да ещё и по английски.

Проверил, там сломанная, нужно править самому.
Понятно, нужно смотреть что бы модели на обминорде были обновлены
Это ты запустил скрипт которые предложили по ссылке?
>2к23
>до сих пор некоторые не могут сменить имя пользователя на "user", замазывают на скриншотах своё реальное имя
>в особо тяжёлых случаях имя ещё и кириллицей, которая вызывает проблемы у множества программ
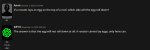
->
После исправления вроде пашет. Сейчас попробую поискать чат, где чистую китайскую зацикливало, я уже не помню где это было.
>Это ты запустил скрипт которые предложили по ссылке?
Ага. Вроде как исправляет, вот скрин загрузки.
>не могут сменить имя пользователя на "user
А что не admin? Или Admin, лол. Или ещё с десяток общих имён. Короче лучше замазать.
как в среднем ощущается? на уровне 70b?
> Умные дяди с лессвронга говорят, что для сетки вообще всё - одно большое рп.
Дурачки с IQ как у хлебушка.
Для сетки вообще все — статистическое следование одних токенов за другими, одних слов за другими, одним символов за другими.
Чистая статистика.
Она не шарит за твое РП и роль. Просто так слова складываются.
> сетка рпшит, а где усиленно напрягает свои слои
Опять же, сетка не рпшит и не напрягает слои, она просто кидает тебе более-менее статистически вероятные токены, вот и все.
Я говорю о подходе, что в данном треде обсуждают именно интеллект сетки, а не рп, и твои результаты невалидны для того, что делают пацаны, ибо они немного влияют на результат в худшую сторону.
Так-то я не против, хотеть логику в рп — разумно, идеал, к которому стремимся (ждем=).

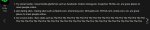
Сейчас на зацикленность проверяю. Короче от смены токена становится лучше, но не до конца. В затравке я остановился на Snapchat, а дальше пишет сетка, настройки одинаковые вплоть до сида, пик1 до фикса, пик2 после.
добавь повторов до 1.3

Raspidorasilo. Правда это уже дельфин, но на базе Юишки.
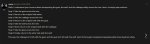



Дельфин 4_К_С. Абсолютная пустота, альпака инструктмод. Пик 1 тепло, дальше совсем поплыл, с небольшим прояснением рассудка на 4 пике, там хотя бы никто не помер и до победы два очевидных, но не для сетки хода осталось.
Может у меня потому нормально и работает, что никаких босов не видал.
> Для сетки вообще все — статистическое следование одних токенов за другими, одних слов за другими, одним символов за другими.
Ну я и говорю, называй как хочешь, сетка весь текст воспримет независимо от обёртки.
> Я говорю о подходе, что в данном треде обсуждают именно интеллект сетки, а не рп, и твои результаты невалидны для того, что делают пацаны, ибо они немного влияют на результат в худшую сторону.
Ладно, возможно надо было это указывать таки вместе с остальными параметрами теста, впрочем мне кажется что от ещё одного чистового теста веселее не станет, а так заодно и возможности в отыгрыше покажу.
Может у меня потому нормально и работает, что никаких босов не видал.
> Для сетки вообще все — статистическое следование одних токенов за другими, одних слов за другими, одним символов за другими.
Ну я и говорю, называй как хочешь, сетка весь текст воспримет независимо от обёртки.
> Я говорю о подходе, что в данном треде обсуждают именно интеллект сетки, а не рп, и твои результаты невалидны для того, что делают пацаны, ибо они немного влияют на результат в худшую сторону.
Ладно, возможно надо было это указывать таки вместе с остальными параметрами теста, впрочем мне кажется что от ещё одного чистового теста веселее не станет, а так заодно и возможности в отыгрыше покажу.
>Может у меня потому нормально и работает, что никаких босов не видал.
Может настройки специфические. ХЗ, у меня только yi-34b и всех её потомков пидорасит, беру любую другую, от синтии 1,5 70B до тюнов мистраля- всё в порядке, никаких зацикленностей.
https://github.com/01-ai/Yi/discussions/5#discussioncomment-7533573
Я так понял именно из-за боса её и пердолит.
>2
А хули тут рекомендуют на 144? Ёбанная тряска, проще подождать, пока они там договорятся
https://huggingface.co/TheBloke/Nous-Capybara-34B-GGUF/discussions/1

А вот тем временем что выдала Юкарин. Собственно, аналогично лучшему ответу пустой карточки, так что если это и влияет, то очень уж незначительно.
На пике 6б версию обсуждают, может в том дело.
>На пике 6б версию обсуждают, может в том дело.
Ёбанные криворукие китайские макаки. Учат через жопу поперёк пизды, а потом у нормальных людей всё ломается.
Эх, модули мультимодальности уже месяц почти лежат, а воз и ныне там. Кроме exeшника из llama.cpp и не запустить нигде мультимодалку толком
КлозедАи используют свои модели для помощи в создании нового софта и воплощения идей.
Пока локалки не станут полезны - новый софт будет пилится очень медленно, и локальные проги так же развиваться будут едва едва.
Замкнутый круг, а эти пидоры в отрыв пошли только набирая скорость.
Пока локалки не станут полезны - новый софт будет пилится очень медленно, и локальные проги так же развиваться будут едва едва.
Замкнутый круг, а эти пидоры в отрыв пошли только набирая скорость.
GGUF версию родят?
Нам нужно что-то сделать! Но что?..
взломать пентагон клозедаи хули
Так они ж неоптимизированные 228б модели пилят, как их запускать? Нужно качественно расти.
Я сразу написал, что оно нахуй не нужно. И как всегда оказался прав.
нее, там у них много чего должно быть, и с мелкими сетками играются, кучи их
Не не нужны, а скилла не хватает прилепить их к нашим инструментам запуска. Герганов наколдовал, а дальше все встало, так как никто не смог нормально реализовать.
>а скилла не хватает прилепить их
Там полнейший макакокод, я уверен, любая обезьяна, освоившая PHP, справится. Но им не нужно, да.
Я чет не пойму, почему герганов не сделал апи своим серверам. То есть нет возможности подключить его екесшиники в виде бека к той же угабуге, или таверне. Или можно? Не пойму почему это делается через кобальд.
Ты троллишь?
я тупой, вот интересуюсь че там как
Если ты настолько туп, что не можешь открыть официальный репозиторий или вики, то лучше выйди из темы.
Ага новичков так же нахуй пошлешь? А может ты ливнешь?
Ты ошибся дверью, тред с умниками ниже https://2ch.hk/ai/res/511426.html
>Ага новичков так же нахуй пошлешь?
Если человек не способен прочесть шапку или документацию к продукту, которым он интересуется, то он не новичок, а рак.
>А может ты ливнешь?
Нет ты.
>Если человек не способен прочесть шапку или документацию к продукту, которым он интересуется, то он не новичок, а рак.
ты щас отсеял 90 процентов людей вобще, ну похуй

Это что такое такое? Несколько дней назад работало, а теперь нет.
Пытаюсь СиллиТаверн подключить к УБЕ через легаси коннекшон галочку.
А опернаи экстенш не пашет в убе, пик 2.
Сто лет не юзал тему...
Пытаюсь СиллиТаверн подключить к УБЕ через легаси коннекшон галочку.
А опернаи экстенш не пашет в убе, пик 2.
Сто лет не юзал тему...

>пик 2
Как бы намекает на причину.
Да я пытался уже не раз в pip install tiktoken sentence_transformers
Говорит всё норм, установлено.
Вебуи работает в своём виртуальном пространстве, нужно ставить внутри него.
А как поставить в конкретную папку?
О нифига себе, спасибо большое, братец, блин, разобрался, странно что апдейт гуя не ставит в себя...

Задача про перевоз капусты же к здравому смыслу относится?
Шапку читал, тред не читал. Какие есть простые способы для рядового пиздоса с 64гб+ оперативы и хорошим процессером, но без видео карты дообучать уже существующие модели своим текстом? В идеале чтобы просто скормить текст и потерпеть до завершения обучения, без всяких танцов с бубном. Либо юзер инпут + текст. Из навыков имеется только базовые навыки питона.
Что такое эмбеддинги в контексте LLama моделей и может ли мне это помочь в решении моей задачи?
Что такое эмбеддинги в контексте LLama моделей и может ли мне это помочь в решении моей задачи?
А неквантованную модель можно впихнуть на процессор с торчащей на ссд жопкой? Хоть пощупаю как там баре с 48гб врама гоняют.
>процессером
>дообучать
Никаких. Серьёзно, ты не дождёшься окончания обучения.
>Что такое эмбеддинги в контексте LLama моделей
Совсем не то, что в картиночных. Зато есть лоры.
Да какого скилла, я тя умоляю, у Герганова это все в открытом доступе лежит, http-сервер, js фронт, кто угодно запилит.
Просто у меня BLIP в таверне работает примерно в дохулион раз быстрее, а когда начинаешь тестить хваленные ллавы, которые на превьюхах читают текст и распознают че хочешь — они максимум улавливают общий смысл. Кто там говорил, что CLIP пиздат? Че-то недалеко ушел от блипа.
Я уже который день хочу запилить себе бота, чтобы он на картинки оставлял комментарии, но когда я поюзал Ллаву — она мне вместо шутеек какую-то сухую хуйню несла. Где мои смешные каменты? Их нет, зачем мне ллава в таком случае.
Короче, я сам за мультимодальность, но она должна быть качественной, а пока че-то не стрельнуло.
Если 90 процентов людей не может прочесть текст — то зачем им нейроночки? Они же пишут текст, а с твоих слов — люди читать не умеют.
Да ладно, че там, три недельки подождет и получит хуйню, ибо с первого раза не разберется с параметрами.
В хубабубе еще летом пускалось.
> Пока локалки не станут полезны
Они уже полезны, бери да пользуйся, накрайняк эмулировать апи впопенов и катать локальную кодлламу. Но это нужно действительно пользоваться текстовыми модельками а не сидеть упарываться шизой, в чем состоит цель поехав.
Нужен стандартный апи и развитие инфраструктуры под это дело чтобы можно было юзать удобно и эффективно, а не в мелочах самописных.
> там у них много чего должно быть
Примеры реализации того что на слуху с оптимизацией, несколько фич разной эффективности что описаны в доках и тестируются или запланированы. Это может принести пользу сообществу и конкурентам, но волшебных сказочных моделек что в микроразмерах ебут все и вся там не будет. Из инновационного - мультимодалки, их фокус на этом направлении сейчас очевиден, но в размерах не для юзеров.
Ты задал суперочевидный вопрос ответ на который находится сразу и общеизвестен, так что реакция ожидаема. Как раз llamacpp и юзается в виде одного из бэков вебуи, а также на ней крутятся большая часть кринжовых сторонних проектов лаунчеров для варебухов.
> уже который день хочу запилить себе бота, чтобы он на картинки оставлял комментарии, но когда я поюзал Ллаву — она мне вместо шутеек какую-то сухую хуйню несла
В рамках идеи - заставить приличную текстовую и мультимодалку вести диалог где первая сначала допрашивает вторую, а уже потом шуткует. С текстовой точки зрения ллава и похлава глуповаты.
Еще из минусов что в стилизованных пикчах со сложным взаимодействием иногда могут путаться, но тут только тренировка поможет.
>Ты задал суперочевидный вопрос ответ на который находится сразу и общеизвестен, так что реакция ожидаема. Как раз llamacpp и юзается в виде одного из бэков вебуи, а также на ней крутятся большая часть кринжовых сторонних проектов лаунчеров для варебухов.
Я знаю что крутится, но там же питоновская версия, нет?
А лоры каким образом работают и где их взять? Возможно, уже есть готовые.
Бля, ну вот о пользе — я, и мои знакомые, давно пользуются локалками в работе и вообще.
Типа, для меня это глупая тема. В 2022 про пигмаллион можно было сомневаться в пользе. А щас-то, лул, рабочий инструмент.
Не говорю, что суперполезно-суперпиздато, но все же.
Ну, типа, да, можно, чтобы они несколько раз обсуждали, вторая модель уточняла нюансы, и уже по результату шутила (или вообще хуярила в стейбл диффужн инпейнт на перерисовку, координаты-то есть), но это муторно, кмк.
А тупые каменты — это не баг, а фича. У меня в паблике такие люди в комментариях, что бот будет смотреться гармонично на их фоне.
Обернутые в пакет бинарники, от пихона там тонкая прослойка для возможности удобнее юзать.
> я, и мои знакомые, давно пользуются локалками в работе
О, вот это интересно, как используете? Для себя кроме оптимизации пахомовского кода и написании некоторых конструкций применений не нашел. Зато в околохоббийных применениях с массовой обработкой информации вполне. Ну и реакреационные цели, лол, для поддержания/нарушения ментального здоровья.
> чтобы они несколько раз обсуждали, вторая модель уточняла нюансы, и уже по результату шутила
Тут надо поэкспериментировать. Один вариант - слепой мудрец мыслит а зрячий пиздюк ему говорит что видит, другой - мудрец инструктирует пиздюка и помогает ему чтобы тот сам сделал правильный вывод, ну или комбинация этого.
Знаю только что регекс хорошо делают, ну и суммиризация инфы о функциях / анализ полотен кода. Написание хуита пока, на сколько слышал. Это по коду.
А так те же писаки не на радуются инструменту, ну или наоборот хе.
Ну и да, ручной гугл с которым можно перетереть любую тему. Пусть и туповатый пока.
Лоры работают так же, как и в стейбле, вставляя свои маленькие слои между слоями модели. Брать там же, на huggingface, хотя лор сейчас немного, и по большей части они уже вмержены в нормальные модели.
А тебе с какой целью?
> вставляя свои маленькие слои между слоями модели
Погугли что это такое чтобы не позориться.
А если в целом здесь лоры наиболее похожи на помесь стиле-концепто-лор в диффузии. Добавляют определенную стилистику в целом (классический пример - ллима_лора) и улучшают качество описания определенных областей (прежде всего кум и сторитейл).
Чтобы ебашить запросы на узкие или не очень тематики (желательно конечно перед этим скормить моделе хороший контент на тему, благо он у меня собран, но без видяхи я так понял пока отсос).
Я вообще накатил gpt4all, какую-то базовую визард модель на 13б параметров, скорость работы конечно говно, но возможно нужно заюзать модель поменьше либо взять что-то из шапки для генерации.
А LLama подобные модели могут в заполнение пустот в тексте? Условно на вход подаю ей кусок текста по типу
Я люблю французские булочки потому, что ##REPLACE## мне нравится ##REPLACE## поэтому я предпочитаю AMD вместо Intel.
Где уже вместо ##REPLACE## будет генерированный текст? Я новенький в работе с локальными моделями, но раз уж на любимом форуме есть соответствующий тред почему бы не спросить, верно? Здесь же все мои друзья.
Не слежу за тредом. Задачу с переправой волка капусты и козы так ни одна локальная сетка и не решила?
>Погугли что это такое чтобы не позориться.
Что не так?
>А LLama подобные модели могут в заполнение пустот в тексте?
Нет, за этим к Bert, но они говно. Впрочем, можешь просто написать промт, пронумеровать реплейсы и дать пару примеров таких заполнений, авось разберётся и допишет похожий текст.
Да в основном написание кода, вопросы по разным CMS, написание текстов, анализ текстов, обсуждения каких-либо решений, например та же роботтехника, ну и «околохоббийные» — тоже работа, поэтому всяких персонажей прописываю там иногда.
Да, мне платят за ДнД. Дом культуры. =)
Большие решают, мелкие с переменным успехом и в зависимости от рандома.
> Что не так?
Да, то что не так выделено зеленым.
> Да, мне платят за ДнД. Дом культуры. =)
Лол, прямо работа мечты со звездочкой
> обсуждения каких-либо решений, например та же роботтехника
Это тоже по работе? Робототехника в дому культуры? Ну и с решениями подробнее, какого именно плана обсуждения?
Для себя отметил что оно может вполне работать в качестве "взгляда со стороны" и хорошо обозначить неточность формулировок перефразированием или своим непониманием. Но какие-то технические вещи без шансов даже у гопоты, нет узких знаний, нет достаточного понимания чтобы к нужному придти.
>Да, то что не так выделено зеленым.
Но ведь это по сути именно так и работает, а любая более верная формулировка просто займёт значительно больше слов.
Это работает вообще не так. Никаких дополнительных слоев не вставляется, и у лоры никаких маленьких нет, структура модели никак не меняется.
Суть лоры в расшифровки ее аббревиатуры, это представление полноразмерной матрицы весов (в данном случае смещений к весам исходной модели) в виде произведений двух матриц меньшего размера. Такое себе шакальное сжатие данных, но для нейронок подобных архитектур работает хорошо, потому и прижилось.
> любая более верная формулировка просто займёт значительно больше слов
Ужатая форма возмущений к весам
> Ну и с решениями подробнее, какого именно плана обсуждения?
Тут мало подробностей будет, ибо на все времени нет, только начинал.
Думал распечатать корпус на 3D-принтере для робота, который мог бы передвигаться самостоятельно. И обсуждал с моделькой, какой формат будет лучше всего. Своего рода интернет-опрос с пояснениями, почему. =) Нейросеть посчитала, что трехколесный был бы самым оптимальным. Я согласился… и решил делать антропоморфного на серво-приводах. Даже подыскал несколько моделей и один полноценный проект (но без файлов!), и на этом мое свободное время на проект кончилось, к сожалению.
Вообще, я подхожу к модели не как к инженеру, а как к толпе из интернета, которые знают что-то по верхам и имеют мнение, аргументированное этими самыми верхами. Для первичного анализа этого достаточно — очевидные плюсы и минусы она подсвечивает сразу. Поэтому я называю это интернет-опросом. =)
ЗЫ Знакомься, Долорес: https://markwtech.com/robots/humanoid-robot/ =D

Ну это же хобби а не работа. Для развлечений и с оговоркой что сетка не эксперт и может ошибаться или не так понять задачу - почему бы и нет. Точно подбирая формулировки можно приличных ответов добиться.
> что трехколесный был бы самым оптимальным
Ерунда, вот был бы ШНЕКОХОД, лол
> Знакомься, Долорес
Словил лютую долину с внешнего вида, пиздец крипота, без парика было бы лучше. Эх сейчас бы в крупный западный универ мутить подобные проекты на диплом. Можно хорошо так сообразить на двоих-троих, разделив разработку кинематики-электроники и по для движения. Причем бахнуть все не на классических pid а сделать простую нейронку, которую можно обучить в симуляции а потом выпустить.
>Ужатая форма возмущений к весам
И ты думаешь кто-то сможет это понять, не зная полной формы?

>ЗЫ Знакомься, Долорес: https://markwtech.com/robots/humanoid-robot/ =D
Кто нибудь тут осмелится поставит это на аватарку бота?
Да, все понятно. Есть какие-то "веса" которые весят много гигабайт и их надо качать, а есть мелкая херь которая их меняет, позволяя получить другое поведение. Причем из-за малого размера имеет ряд ограничений.
Просто, интуитивно, наглядно. Разбираться в структуре, как там идет это сжатие, что вообще происходит - это уже по желанию и не требуется для общих ощущений.
Ты же говоришь про большие слои, малые слои, заведомо вводя в заблуждение и усложняя. Развивая, лора получается тоже нейросеть? А если несколько лор объединяем это большая получится? Но это все лирика, очевидно что такое выдал по незнанию, shame on you!
Бляя, нужно реально бота к этой хтони. Как там автор спал после такого.

>Бляя, нужно реально бота к этой хтони. Как там автор спал после такого.
Два бота. Выше мальчик, а вот девочка. И в групповой чат общаться!
А мужик там рукастый и отчаянный, я смотрю
Киньте норм карточки бота для таверны, не рп.
Что то вроде аи тютора или чет подобное.
Хочу своего бота наколхозить, но на чубе ниче нормального не найдешь. Или место где их искать.
Что то вроде аи тютора или чет подобное.
Хочу своего бота наколхозить, но на чубе ниче нормального не найдешь. Или место где их искать.
Какого рода бота? Если не для рп и хочешь максимальный перфоманс то там и системный промт потребуется править. Хотя норм модели и с рп шаблоном прилично ассистируют, отыгрывая бонусы.
>Какого рода бота?
Хз, вот например тот же тютор https://github.com/JushBJJ/Mr.-Ranedeer-AI-Tutor
Есть же где то еще похожие?
Ладно сам немного нашел но не совсем то.
https://www.chub.ai/characters?search=&first=30&topics=Helpers,AI%20assistant&excludetopics=NSFW&page=1&sort=star_count&venus=false&min_tokens=50&nsfw=true
или если обхват шире то
https://www.chub.ai/characters?search=&first=30&topics=Helpers&excludetopics=NSFW&page=1&sort=star_count&venus=false&min_tokens=50&nsfw=true
но там уже рыться в поисках чего то нормального
https://www.chub.ai/characters?search=&first=30&topics=Helpers,AI%20assistant&excludetopics=NSFW&page=1&sort=star_count&venus=false&min_tokens=50&nsfw=true
или если обхват шире то
https://www.chub.ai/characters?search=&first=30&topics=Helpers&excludetopics=NSFW&page=1&sort=star_count&venus=false&min_tokens=50&nsfw=true
но там уже рыться в поисках чего то нормального
Скажите кто пробовал сайгу она правда хорошо по русски говорит. Или кое как. Там то сеты небольшие. Когда на другой язык учат обычно смотрю используют ну хотябы 10 миллиардов токенов.
Мультимодалку научили играть в майнкрафт и даже добавили ей память. Короче разрабы говорят что получилось заебись почти AGI.
https://craftjarvis-jarvis1.github.io/
https://craftjarvis-jarvis1.github.io/
> говорят что получилось заебись
Но как обычно выглядит как говно. Там на деле фактически обычный бот для игры написан, нейронка только команды простейшие даёт, даже не управляет ничем напрямую.
Пока ничего не понятно из статьи. Ей скармливают кадры в реалтайме или с интервалом? Как генерируются клики, движения или там тупая прослойка в виде заскриптованного говна?
Зато сойджаки в r/singularity уже возбудились
Всякие Илоны Масковичи уже пять лет не могут заставить авто ездить по дороге, а соевики как обычно с любой хуйни excited.
Им не дают. Так бы уже давно катались (с неизвестным процентом аварий)
Они и на мою собаку возбудились бы благо у меня её нет.
Дают, с водителем на сидении офк.
> благо у меня её нет
Как же так, держи https://www.chub.ai/characters/AndyTV/inugami-korone на такую не грех возбуждаться
В треде есть примеры, если они тебя не убедили, то можешь не ставить. Лучше все равно ничего нет. Единственный конкурент - руГПТ-3.5 - слишком тупая и устаревшая.
Разбудите меня, когда локальные llm смогут уверено решать задачи на подобии волка козы и капусты.
наподобие
БАМП ВОПРОСУ!
Неужели никто Сайгой не пользуется?
>Там на деле фактически обычный бот для игры написан, нейронка только команды простейшие даёт, даже не управляет ничем напрямую.
>
>сойджаки в r/singularity уже возбудились
А почему бы и не возбудиться. Любая технология в начале выглядит как хуйня из под коня. Тут важна не сама текущая реализация, а сам принцип и как его можно использовать.
Логично что нейронка не управляет напрямую, это как раз и сделало бы её неюзабельным говном, засорив датасет кучей бесполезной технической инфы. В идеале она должна отвечать за принятие решений, как раз этого и не хватает современным ботам, реагирующим по скрипту.
Я с самого появления нейронок мечтал о ботах в условной РПГ, к которым можно подойти и не выбирать из нескольких ебучих вариантов а свободно настрочить текстом что ты о них думаешь и они на основе этого текста будут менять модель своего поведения.
Даже если от нейронки боту будут поступать только короткие команды вроде "напасть на юзера", "следовать за юзером" или "украсть курицу", а остальное будет выполняться за счёт заранее прописанных скриптов, это уже будет ШИН. А если бот будет помнить свои предыдущие действия и учитывать их при ответах и генерации новых решений, то ВДВОЙНЕ ШИН!
Зажрались вы господа.
https://www.reddit.com/r/LocalLLaMA/comments/17v92ct/ui_w_context_free_local_function_calling_define/
наконец то блядь нормальная еда.жпг
наконец то блядь нормальная еда.жпг
но слишком сырое
Выглядит перспективненько.
Теперь осталось только объединить всё это в одного удобного голосового помощника, который сам будет решать что и как запускать по голосовому запросу от пользователя. и получится аналог GPT4
Никто на русике не РПшит, привыкай.
3D-принтер оплачен ДК, клуб официально существует (и, по идее, мне даже за него платят, но я не особо заглядываю в ведомости на 20к), даже участники есть (правда по программированию и Блендеру), так что технически — все-таки работа. =)
> ШНЕКОХОД
КЕК
Забавная штука, посмотрю-подумаю. =)
> нейронку, которую можно обучить в симуляции а потом выпустить
AI to control the bot. Analyzes the information received by him and gives orders in the following format:
Thoughts: analyzes received information, reflects on the situation, draws logical conclusions, builds a plan for the next action.
Action: describes the action it performs.
Reputation: describes the attitude towards the subject interacting with it.
Speech: Gives a speech, addresses a subject, or answers a question.
Это с первого раза написанная хуйня, чтобы текстовая нейронка работала как общего назначения — и она даже работает (в симуляции, ага=).
Но потом время кончилось на проект и он заморозился на альфе.
> Как там автор спал после такого.
А кого-то фнаф пугает, а тут такое…
Хрюкнул от смеха.
Мне вообще от Долорес требуются руки, ноги и туловище, голову уж любую можно сделать.
Нигде не смог найти, как сделать столь подвижные руки.
Ожидаемо, по кайфу.
Не, так и есть.
Бот — это алгоритм, принимающий решения.
Программа, эти решения реализующая, передающая в игру — это альтернативный клиент иди хак.
Так что в данном случае — нейронка и есть полноценный бот, как надо. Играет она. Чем она передает в игру — похую.
Я немного шарю в этом, привет OpenKore.
Вообще, моя карточка выше именно к этому. Использование LLM в качестве нейронки (слабого ИИ) общего назначения — об этом говорили еще после выхода Llama 1, но мало кто занимается, людям просто лень.
Да.
> А почему бы и не возбудиться.
Тому что платиновый I want to believe на гране шизы, каждый вкладывает туда свой манямир и яростно его отстаивает. Ну типа игнорят вещи на которые должна быть шишка колом, но зато носятся со всякой ерундой.
> так что технически — все-таки работа
Ну не, это хорошо что поддерживают подобные увлечения что молодежь могут привлекать и т.д., но к работе там про профессиональную квалифицированную деятельность. Главное пиздюкам llm не показывай а то с детства обкумятся.
> чтобы текстовая нейронка работала как общего назначения
Там как бы не полезло
> Выполни приказнейм
> Выполняю приказнейм
> ...
лол.
А вообще речь про команды на приводы на основе данных с акселерометров/гироскопов, прошлых позиций и сигналов управления.
> Играет она.
Принимать решения в игре - это очень тривиальная задача, в любой игре есть ИИ, который не нейронка. Он тоже "играет", вызывая скрипты. Визуальные боты точно так же даже на говне типа autohotkey делали раньше.
>Ну типа игнорят вещи на которые должна быть шишка колом
Например? Я даже и не помню прорывов за последние пару месяцев.
>Главное пиздюкам llm не показывай а то с детства обкумятся.
Дрочить на тексты это признак элиты, могут не только лишь все, а люди с богатым воображением. Так что нет, случайные люди этому не подвержены.
Для перевода с русского на английский что лучшее сейчас openbuddy-zephyr или polylm?
В молодом возрасте я как раз и обдрачивался на тексты, разные новелы мне сами описания доставляли больше чем картинки. С возрастом кстати все хуже с воображением.
А что плохого пусть пиздюки кумятся лучше покумится и делом занятся чем о тяночке все время мечтать.
есть у кого инфа стоколько две TESLA M40 24 ГБ выдадут токенов в секунду на 70b
Когда ты был молод, картинки грузились по 5 минут, вот ты и дрочил на более доступные текста. Сейчас без видео в 3D 4к 369FPS у молодёжи и не встанет, ибо им такое доступно по щелчку мыши.
>TESLA M40
Токенов 5, лол.
О, уже с кеплера на максвелл, тенденция верная. Мало, меньше чем p40, которую отмечали как неюзабельную и была инфа о 4-5 токенах на 30б с одной, так что там если 2 будет то уже хорошо.
> Токенов 5
Было бы неплохо, но врядли.
Илита треда сравнивая пропускную способность памяти считает, что для языковых моделей нужны минимум p40.

>Было бы неплохо, но врядли.
Вот кстати хотел посмотреть цену да чип, а тут продаван раскрыл всю подноготную, лол.
Если это фп16, то может даже и ничего...
Нвидебояре, какая у вас скорость анализа контекста с 30-34б например?
Насколько там gptq быстрее в 3 раза? Плюс еще там есть флаг вычесления в 32 битах как раз для таких карт. Но в общем все еще неясно, что будет в итоге, но пока эта карта стоит 13к это наверно все еще лучше чем проц с кучей памяти.
Делали.
Но уровень подражания игроку все же разный.
Тут разнообразнее, а там ну такое. =)
Так. Паскаль из-за отсутствия тензоров и РТ уже на грани юзабельности.
Все остальные прям совсем нуль, подозреваю.
Причем там псп-то?
Там архитектура не та.
Во.
На p104-100 где-то 6-7 токенов было. Именно на викуне 7б на первой.
А это почему не GPTQ? =)
Больно сочно в таком случае предложения выглядят.
В примере с викуной? Хз мне показалось почему то что там просто запуск в 16 бит и получение 3х токенов на этом. M40 плохо работает с 16 битами еще, в exllama для таких карт есть флаг чтоб вычисления вести в 32 битах.
Это если у тебя есть материнка чтоб запихать все эти карты с достаточным количеством PCI линий, но это если ты хочешь именно 70b запускать.
И даже за 2,5к.
Но ты уверен, что в 7B тебе надо 6-8 токенов?
Ну, типа, недалеко от проца ушло, кмк. Там, наверное, 4-5 токенов будет на стандартной системе.
Ну, если там нет текста, то я бы предположил стандартную GPTQ 4-битную. Но может я не прав, канеш, однако, рисковать не хочу. =)
На самом деле память для проца же тоже стоит денег, во вторых скорость будет уменьшаться с размером сильнее, с новой видюхой у тебя вместе с памятью вычеслительное ядро идет а проц остается один. Так что впринципе смысл есть. Но для большого количества таких карт нужен тредрипер или зеон. Чтоб PCI линий хватило на 5 видюх для 70b
>Принимать решения в игре - это очень тривиальная задача, в любой игре есть ИИ, который не нейронка.
Текущие игровые ИИ полнейшая заскриптованная хуита. Да, ты можешь заскриптовать огромное количество ситуаций и внешне это будет походить на ИИ, но это всё равно будет топорная хуйня, руинящая отыгрыш в любой нестандартной ситуации. Сейчас, чтобы скрыть эти рояли игроделы вынуждены тупо ограничивать действия игрока.
ЛЛМ лишены этого недастатка и в теории способны выдать решение на абсолютно любую происходящую хуиту, да ещё и оригинальным текстом его прокомментируют. Текущие "Игровые ИИ" и рядом не стоят с такой вариативностью.
>Но ты уверен, что в 7B тебе надо 6-8 токенов?
Меня заинтересовало.
Мимо 3 токена на 7В
> Но ты уверен, что в 7B тебе надо 6-8 токенов?
Надо смотреть как будет с моделями потяжелее. Сейчас вот амудя вместо видокарты вытаскивает 2 т/с генерации с 34б и ~44-50мс/т анализа промпта. Если будет лучше всего за 8к дерева, то почему нет?
>и ~44-50мс/т анализа промпта
Промт всегда имеет смысл скидывать на видяху, там 1 штуки почти любой хватит.
То-есть лучше этого не будет? Мне важна именно эта скорость, у меня большая часть времени как раз на анализ уходит.
Ну вот смотри. Для теста я выгрузил в видяху только контекст, итого на 3080Ti получил примерно вот так
>ContextLimit: 3911/4000, Processing:51.38s (13.3ms/T), Generation:18.48s (473.8ms/T), Total:69.86s (0.56T/s)
>ContextLimit: 4992/8192, Processing:69.61s (14.1ms/T), Generation:18.20s (455.1ms/T), Total:87.81s (0.46T/s
С учётом того, что упора в объём памяти тут нету, а эта карта почти на пределе пропускной способности памяти, то сильно лучше ты не сделаешь никак, даже 4090 даст максимум 10% прироста.
Так что если ты тот страдалец с лорбуками, у которого каждый раз пересчитывается весь контекст, то могу только посочувствовать, ждать тебе минуты.
Пресет тут нипричем вообще, это карточка должна быть на русском.
> 13.3
> 14.1
То-есть в моём случае в три раза, но и то на дорогой нвиде. Минуту-две конечно лучше ждать, чем 3-6, но не за разницу в цене какая между 6700хт и 3080ти.
> Так что если ты тот страдалец с лорбуками, у которого каждый раз пересчитывается весь контекст, то могу только посочувствовать, ждать тебе минуты.
Попробую ещё ебануться на отличненько подрубить смартконтекст и 16к контекста, чтобы компенсировать обрезку вдвое. По идее он для того и задумывался, на деле будем посмотреть.
Не, братан, проц-то тут причем? Ты думаешь, при увеличении размера, скорость падает из-за проца? :) Не, с увеличением размера растет… РАЗМЕР. =) Все упирается в пропускную способность памяти.
Если ты вместо 6 задействуешь 12 тредов — скорость не вырастет в два раза.
Конечно, псп видяхи выше, но 3 токена на 7б — это 3 токена на 7б, а не на 70б. Может быть падение и будет не кратным, но вряд ли ты получишь перформанс выше, чем на проце.
А 64 рама стоит дешевле 64 гигов видео.
Ну или там 48.
PCI-линии тебе нах не сдались, о чем ты? Тебе хватит и по одной линии. Ну, по 4, вот тебе стандартная двадцатка.
Все упрется в то, что само ядро видеокарты старой считает критически медленно. А с ростом размера — еще и размер будет расти, отчего еще медленнее.
На проце ты можешь гонять 0,7 токена/сек.
На этих видяхах… Ну, попробуй, увидишь. Помимо банального замедления от размера, еще накинь задержки на недостаточно оптимизированный код.
Ну ето жесть. =)
Ну так, навскидку, если 34 поделить на 7, то получится 5. 8 токенов поделить на 5 = 1,3 токена/сек. Звучит медленнее 2.
Но это супергрубо, канеш, может там и все лучше.
Короче, 8 гиговый паскаль хорош только если тебе нужна 7b за копейки в текущий комп.
24-гиговые теслы уровня кеплера или максвелла нужны примерно никогда, ибо они, крайне вероятно, медленнее проца.
24-гиговый паскаль вроде что-то выдает (там и чип у P40 dldjt помощнее, чем у P104-100, и псп вполтора раза шире), но тоже на грани.
По максимальну грубому подсчету, P40 должна выдавать 10-15 токенов на 7B и, соответственно, 1-1,5 токена на 70B (а может и до двух). Это уже вдвое быстрее ddr4 и на уровне головй ddr5.
Но P40 стоит 18к-20к, две штуки будут стоить 36к-40к. А ddr5 комплекты дешевеют.
Так что покупка на грани окупаемости.
А P104-100 в количестве 5-8 штук требуют материнку (как я скидывал, и болезных порвало) с соответствующим количеством слотов. Это 20к (но я скидывал за 8к=). А еще блок питания, который должен выдать по 200 на карту (ну, по 170, даунвольтим, да?), это уже под 2 киловатта на систему с запасом.
Короче, ну хуй знает.
>То-есть в моём случае в три раза, но и то на дорогой нвиде.
3,5, да. По памяти моя быстрее в 2,5 раза, а остальное это штраф за амудю, лол.
>чтобы компенсировать обрезку вдвое
Вся боль смартконтекста в том, что он обрубает начало, то место, где сидят все инструкции и сама карточка.
>24-гиговый паскаль вроде что-то выдает
А новее поцкаля на одиш шаг уже v100 с оверпрайснутой ценой.
Резюмирую:
6 P104-100 стоит 18к рублей, ну нужна мать за 20к и блок питания хуй знает за сколько, а может и два. Производительность будет в районе ddr4 3200 в двухканале, может чуть быстрее.
2 P40 стоит 36к рублей, производительность вдвое, может втрое выше, чем на ddr4 3200 в двухканале.
И нормальная система на ddr5 выдаст ту же скорость, что и 2 P40.
Покупка за 50к — этот половина RTX3090. Лучше покопите и купите, ну вы поняли. ИМХО.
>6 P104-10
Так параша. 4гб памяти. Купи одну p40 и не ебись.
Если дело только в пропускной способности памяти то почему проц то на 100% загружается? Это странная картина, проц тогда не должен загружаться на 100% он должен упираться в память.
>Если ты вместо 6 задействуешь 12 тредов — скорость не вырастет в два раза.
А вот это и есть не оптимизированный код. Что уж говорить если ты все вообще на видюху скинешь с gguf то скорость все равно будет намного ниже чем с gptq, даже на хорошей видеокарте.
> Вся боль смартконтекста в том, что он обрубает начало, то место, где сидят все инструкции и сама карточка.
Лол. Ну и плюсом к тому что не работает как мне надо.
>то почему проц то на 100% загружается
Потоки уменьши, до 4-5-6, будет та же скорость, но с загрузкой в 50/25%.
>А вот это и есть не оптимизированный код.
Сколько код не оптимизируй, а просос по памяти ты никак кодом не исправишь. Я напоминаю тем, кто не знал, что компы по оперативе сосут примерно с 80-х, лол.
> то почему проц то на 100% загружается
Блок выборки команд процессора занят ожиданием загрузки операднов из памяти. В это же время фпу исполняет nop.
Ты можешь это посмотреть по энергопотреблению. Оно будет низкое, хотя проц "загружен" на 100%.
В идеале память должна быстро подгонять данные, а процессор их обрабатывать с такой же скоростью. Если что-то отстаёт, оно становиться бутылочным горлышком.
Я понимаю насчет потоков. Но проц просто не должен загружаться если ему нечего обрабатывать. Да может я конечно погорячился с оптимизацией, но скорее всего дело в том что используются AVX и количество модулей AVX не равно ядрам. Короче все сложнее, но я никогда не поверю что дело просто в памяти. Выше я сказал почему. Сам формат gguf, даже нормально с видюхой отработать с убербыстрой памятью и чипом.
Выше чел правильно написал
Так работают компьютеры, да. Уёбищность и фейспалмы, сломанные слои совместимости с микроконтролёрами для светофоров прилагаются.
Смотри допустим я вот компилирую проект, если у меня не хватает скорости диска сколько потоков я не сделаю, загрузка на 100% не поднимется. Несмотря на то что проц ждет данные с диска.
Окей я проверю потребление.
Но вопрос открыт все равно почему с GPU то gguf плохо работает тут тебе и память и потоки есть, а все какие то ограничения.
>компилирую проект
Но при этом не знаешь, как работает шелудер ОС и почему
>проц ждет данные с диска
отличается от ожидания данных с оперативки. Ну бля, вот по этому компутеры и тормозят.
>почему с GPU то gguf плохо работает
Потому что процессорный. GPTQ работает в пару раз быстрее.
Впрочем вываливай какая там у тебя картонка. А то может говно с порезанной шиной, сейчас это модно, вон, половина невидий со 128 битным огрызком вместо шины.
Замерить потребление не представляется возможным, парится нужно с настройками, во первых разница между на половину загруженным процом и полностью загруженным у меня не значительна. А во вторых проц просто поднимает частоту при неполной загрузке ядер на загруженных, короче в обоих случаях упирается в TDP.
Я просто собираю иногда и исходников не пишу на C++ мне не так важны эти нюансы.
2070 видюха но шина PCI 2.0 8x потому что вторая, плюс материнка такая. GPTQ дает где то 35 токенов на 7b. А вот gguf 15, ну и контекст считает дольше.
Ладно в общем это все не так важно, купил уже 2080ti пока наверно хватит 19gb памяти. При том что все остальные накладные расходы у меня весят на поломаной amd, вырубается от нагрузок, но рабочий стол держит и всю память для его ускорения.
> Для теста я выгрузил в видяху только контекст
> 51.38s (13.3ms/T)
Ух бля, а че так грустно то? Выходит не особо то оно и ускоряет если основные слои не выгружены?
> ну нужна мать за 20к и блок питания хуй знает за сколько
Да ну, проблемы только с размещением а из требований к плате - наличие хотябы х4 слота в доступе.
> Покупка за 50к — этот половина RTX3090
Не так давно сама 3090 стоила 50, сейчас уже 60-70+, но даже так в разы обходит по прайс-перфоманс. По проперженности будет не хуже тех, посыл верный.
>Ух бля, а че так грустно то?
А сколько надо? Это с нуля почти 4к контекста.
> Ух бля, а че так грустно то? Выходит не особо то оно и ускоряет если основные слои не выгружены?
А на консумерских можно ещё быстрее? Не беря в расчёт разницу 10% с 4090.
https://aliexpress.ru/item/1005004972837013.html
А вот чем не вариант 11.11 взял за 25 + кешбек в 1к.
Бюджетный вариант, да и пофиг что перепаяна не первый раз беру бу, нареканий нет.
По цене качеству очень недурно если у тебя нет 100к. Ну и памяти немного но вторая видюха вопрос решает.
Ну типа 5 секунд, 10 совсем край на полный контекст если гпу ускорение. Потому и удивило, видимо когда все слои на проце оно не так эффективно работает.
> А на консумерских можно ещё быстрее?
С полными слоями быстро. А что там на бывшей происходит вообще страно, 12к контекста на 70б перестройку не замечаешь.
Если там чип быстро работает - почему бы и нет, пару таких и уже можно 13-20б в квантах побольше оче шустро катать при малом бюджете.
2.5 м/c на токен? Ебануться...
>12к контекста на 70б перестройку не замечаешь.
Ты уверен? Покажи скрин, что-то странное.
Во-первых, хватит отвечать мне — отвечай тем, кто хочет купить. =)
Во-вторых, 8 гигов же, ну.
>А вот это и есть не оптимизированный код.
Нет, это не он, это у тебя упор в чтение из памяти.
У тебя есть некий диаметр трубы. И некий предел скорости жидкости.
И вот эта жидкость течет к тебе на проц. Как бы быстро проц не обрабатывал — получить больше жидкости, чем протекает сквозь трубу, ты не сможешь.
Я хз, как еще пояснить довольно простую вещь.
Да не верь наздоровье — иди и покупай суперкрутые процы, выбрасывай деньги на ветер.
Нам-то что, мы уже все потестили, целиком в этом убедились. Все совпадает с расчетами.
Уф, все с тобой ясно.
> хватит
> 19gb
Ок. =)
В случае 6-8 карт — наличие 6-8 слотов. =) А это майнерские. Чуть дороже, чем обычные. Хотя если брать 24-гиговые, то да, впихнуть в обычный не проблема, тащемта.
> Не так давно сама 3090 стоила 50
А 4090 с мегамаркета бралась за 100к+40к кэшбека… Эх, было время.
Может потому что новая 3060 с кэшбеком стоила 13к рублей и имела 12 гигов?
2080 ti по-быстрее, конечно, но я даж хз.
Ну я для игр брал как основу. Так что в основном мне было важно чтоб чип был быстрым. 2070 уже и так есть так что 3060 меня не привлекает. Но конечно за 13к рублей 3060 тоже вариант хороший кто спорит.
Хотя 13к. Даже не знаю где ты нашел такую, это же в 2-3 раза дешевле рыночной цены.
Ну, 35к цена и 22к кэшбек.
Мегамаркет.
Ну а дальше кэшбек сливаешь на что-то нужное без скидок.
Я бытовую технику закупаю, на нее скидок никогда нет. ¯\_(ツ)_/¯
А для игр да, наверное норм.
Но опять же, я вот попробовал Frame Generation на RTX40xx, и прям кайфанул. Визуальных артефактов почти не видно, а фпс почти вдвое апается.
Приятное. Поэтому щас 20хх и 30хх не рассматриваю под игру.
Но это, конечно, имея на руках 40хх.
>наличие 6-8 слотов
Как же хочется дешёвый свитч PCI-E 5.0 x16 -> 4х PCI-E 3.0 x16. И ещё 4 штуки PCI-E 3.0 x16 -> 4х PCI-E 3.0 x4. Разве я многого прошу?
>кэшбек
Ебать разводят гоя на бабло.
А ну да что то я так и подумал слышал об этой фитчи но не покупал еще там )
Не слышал что они уже и промежуточные кадры добавляют. Ну что уж теперь через пару лет, или даже год или два может возьму 4ю или 5ю серию.

Проблема не в том что она не хочет писать на русском, а в том что несёт бред уровня обычного мистраля, если его заставить писать по русски или так и должно быть?
Так, ну вот у меня, например RX 580 вместо видимокарты, но изображение вполне выводит.
Предположим, я докуплю p104-100 за 3к деревянных и вставлю в свободный слот. Мне к этой хуйне драйвера Нвидиа ставить вместе с АМДшными? Будет ли такой франкинштейн вообще работать?
И как на эту p104 нейронку перекидывать, через Кобольд?
Чего ты ждёшь? Ну вот чего ты ждёшь?
>Мне к этой хуйне драйвера Нвидиа ставить вместе с АМДшными?
А то.
>И как на эту p104 нейронку перекидывать, через Кобольд?
Через что хочешь, вроде везде уже есть выбор картонки. Хотя первая вроде как безальтернативно юзается для контекста.
В самое кокоро!
Ну, пока я всякие нужные вещи покупаю за 1% их цены — развод только банка и тебя. =)
А я буквально покупаю.
Могу накидать список товаров и цен, а ты мне найдешь дешевле. Успехов, что ли. =)
Ждем 5ю, да.
Хм. Дрова ставятся специальные модифицированные.
Но у меня ставились без проблем.
Прокидывать через убабугу, полагаю.
Кобольд не запускал уже давно, не знаю, есть ли там выбор видяхи.
А вот будут ли работать модифицированные дрова НВидиа + основные АМД — тут не знаю, конечно. Поле для эксперимента.
У меня под рукой рыксы нет, чтобы проверить.
Погоди, а откуда у рузена такие цифры? Там же говнокотроллер и все упиралось в 60гб
Ну обычный мистраль хуже по русски шпрехает.
А так да - по-русски она тупее чем по-английски.
Ты присмотрись к моделям проца внимательно. Их там два.
P40 выдает 15-18 токенов на 13b.
Смотри тесты на реддите. Тоесть грубо ты уже промахнулся в производительности в 2 раза.
Во вторых именно что на проце ты можешь ожидать кратного падения и даже более. А на видюхах все же падение будет меньше. В любом случае есть много реализаций квантования и можно поэкспериментировать на видеокартах.
Можешь поподробнее про это рассказать?
Короче план такой:
Есть проц Рязань 5600Х и RX 580 на 8Гб.
Беру такую мать за 7200 https://aliexpress.ru/item/1005004773705968.html?sku_id=12000030425298915&spm=a2g2w.productlist.search_results.3.77f84aa6LzjvkH
Докупаю ждве p104-100 8Гб 3кх2=6000
...
За 13200 получаю 24 Гб видеопамяти! Аналог 3090 для нищуков!
Скрин чего? Эксллама не пишет отладочные данные как llamacpp. Пикрел разница запуска готового чата на холодную и потом свайпа.
> впихнуть в обычный не проблема
Та еще адуха
> А 4090 с мегамаркета бралась за 100к+40к кэшбека
Оно и сейчас, только должен быть их клиентом и наебаллы заебешься тратить.
>Эксллама
Ну так не интересно. У меня нет 48ГБ врама.

Вот так на лламакрестах, 20b Q3km, 120 микросекунд на токен вполне себе, более чем в 100 раз быстрее. Слои здесь тоже решают получается и вариант с дешман затычкой и йоба процом не обязательно будет юзабелен.
О чем?
Ну к примеру бенч по процам ядрам и памяти. Он не такой обширный но там есть кое какая инфа
https://www.reddit.com/r/LocalLLaMA/comments/14ilo0t/extensive_llamacpp_benchmark_more_speed_on_cpu_7b/
Быстрый поиск по P40
https://www.reddit.com/r/LocalLLaMA/comments/13n8bqh/my_results_using_a_tesla_p40/
Но тут я не понял квантованные модели или нет. Но видел квантованную gptq со скоростью 18 токенов в сек. Хотя там кто то пишет что есть траблы с новыми версиями в общем можно геморой все же поиметь.
По поводу квантования. Что еще есть
https://mlc.ai/ это обертка над TVM свое квантование и свои беки, куда опенCL, проц, вулкан.
ONNX runtime тоже свое квантование есть, бек cuda, directml.
https://github.com/wangzhaode/mnn-llm обертка над mnn китайская либа тоже поддерживает вулкан, опенCL, cuda.
AWQ понятно еще есть из квантования и 2 реализации вроде для нее.
GPTQ вроде 3 реализации.
Есть gpt4all с gguf ускорением на вулкан на амд шустрее чем llamacpp.
Понятно что что то из этого работает только через пердолинг, но варианты есть, и скорее всего это еще не все.
Какой сервак фалкону нужен для Falcon 180b 2048 при 10000 запросах в сутки?

А ты к другому вопрос задавал.
google palm 2 bison.
Да и не только.
Можешь тут бесплатно потыкать
https://flowgpt.com/chat или openrouter но за денюжку.
Насколько я понимаю это как большой т5 но там что ли 540 миллиардов параметров. То есть сетка text2text, самая большая из сеток такого типа.
Бард постоянно меняют на чем он запущен то на ламде то на палме, сейчас бард использует палм для логических задач. По заверению разрабов палм 2 в задачах программирования и логических задачах не хуже gpt-4. Но из за своих особенностей он не может в ролиплей да и вообще. Говорит очень сухо. Длинный текст понимает плохо. Если есть американский google акк можешь получить доступ бесплатно к апи и даже бесплатному тюнингу. По апи модель дополнения имеет относительно мало цензуры.
Только дрочеством.

Это мои слова.
ПЕРЕКАТ
Ну естественно я спрашивал про ам5
А, ну значит тебя наебали с
>говнокотроллер и все упиралось в 60гб
Поздравляю с говном в мозгах.
Чего такой бабахнутый то? Это общеизвестный факт что на них память упиралась в 60гб по чтению
Я же говорю, что наебали. Я вот такого "общеизвестного" факта и не слышал.
llama-cpp выдает error loading model: create_tensor: tensor 'token_embd.weight' not found при загрузки любой модели из ./models
Как быть?
Как быть?




Здесь мы делимся рецептами запуска, настроек и годных промтов, расширяем сознание контекст, и бугуртим с кривейшего тормозного говна.
Тред для обладателей топовых карт NVidia с кучей VRAM или мажоров с проф картами уровня A100, или любителей подождать, если есть оперативная память. Особо терпеливые могут использовать даже подкачку и запускать модели, квантованные до 8 5 4 3 2-х бит, на кофеварке с подкачкой на микроволновку.
Базовой единицей обработки любой языковой модели является токен. Токен это минимальная единица, на которые разбивается текст перед подачей его в модель, обычно это слово (если популярное), часть слова, в худшем случае это буква (а то и вовсе байт).
Из последовательности токенов строится контекст модели. Контекст это всё, что подаётся на вход, плюс резервирование для выхода. Типичным максимальным размером контекста сейчас являются 2к (2 тысячи) и 4к токенов, но есть и исключения. В этот объём нужно уместить описание персонажа, мира, истории чата. Для расширения контекста сейчас применяется метод NTK-Aware Scaled RoPE. Родной размер контекста для Llama 1 составляет 2к токенов, для Llama 2 это 4к, но при помощи RoPE этот контекст увеличивается в 2-4-8 раз без существенной потери качества.
Текущим трендом на данный момент являются мультимодальные модели, это когда к основной LLM сбоку приделывают модуль распознавания изображений, что в теории должно позволять LLM понимать изображение, отвечать на вопросы по нему, а в будущем и манипулировать им.
Основным представителем локальных моделей является LLaMA. LLaMA это генеративные текстовые модели размерами от 7B до 70B, притом младшие версии моделей превосходят во многих тестах GTP3 (по утверждению самого фейсбука), в которой 175B параметров. Сейчас на нее существует множество файнтюнов, например Vicuna/Stable Beluga/Airoboros/WizardLM/Chronos/(любые другие) как под выполнение инструкций в стиле ChatGPT, так и под РП/сторитейл. Для получения хорошего результата нужно использовать подходящий формат промта, иначе на выходе будут мусорные теги. Некоторые модели могут быть излишне соевыми, включая Chat версии оригинальной Llama 2.
Кроме LLaMA для анона доступны множество других семейств моделей:
Pygmalion- заслуженный ветеран локального кума. Старые версии были основаны на древнейшем GPT-J, новые переехали со своим датасетом на LLaMA, но, по мнению некоторых анонов, в процессе потерялась Душа ©
MPT- попытка повторить успех первой лламы от MosaicML, с более свободной лицензией. Может похвастаться нативным контекстом в 65к токенов в версии storywriter, но уступает по качеству. С выходом LLaMA 2 с более свободной лицензией стала не нужна.
Falcon- семейство моделей размером в 40B и 180B от какого-то там института из арабских эмиратов. Примечательна версией на 180B, что является крупнейшей открытой моделью. По качеству несколько выше LLaMA 2 на 70B, но сложности с запуском и малый прирост делаю её не самой интересной.
Mistral- модель от Mistral AI размером в 7B, с полным повторением архитектуры LLaMA. Интересна тем, что для своего небольшого размера она не уступает более крупным моделям, соперничая с 13B (а иногда и с 70B), и является топом по соотношению размер/качество.
Qwen - семейство моделей размером в 7B и 14B от наших китайских братьев. Отличается тем, что имеет мультимодальную версию с обработкой на входе не только текста, но и картинок. В принципе хорошо умеет в английский, но китайские корни всё же проявляется в чате в виде периодически высираемых иероглифов.
Сейчас существует несколько версий весов, не совместимых между собой, смотри не перепутай!
0) Оригинальные .pth файлы, работают только с оригинальным репозиторием. Формат имени consolidated.00.pth
1) Веса, сконвертированные в формат Hugging Face. Формат имени pytorch_model-00001-of-00033.bin
2) Веса, квантизированные в GGML/GGUF. Работают со сборками на процессорах. Имеют несколько подформатов, совместимость поддерживает только koboldcpp, Герганов меняет форматы каждый месяц и дропает поддержку предыдущих, так что лучше качать последние. Формат имени ggml-model-q4_0, расширение файла bin для GGML и gguf для GGUF. Суффикс q4_0 означает квантование, в данном случае в 4 бита, версия 0. Чем больше число бит, тем выше точность и расход памяти. Чем новее версия, тем лучше (не всегда). Рекомендуется скачивать версии K (K_S или K_M) на конце.
3) Веса, квантизированные в GPTQ. Работают на видеокарте, наивысшая производительность (особенно в Exllama) но сложности с оффлоадом, возможность распределить по нескольким видеокартам суммируя их память. Имеют имя типа llama-7b-4bit.safetensors (формат .pt скачивать не стоит), при себе содержат конфиги, которые нужны для запуска, их тоже качаем. Могут быть квантованы в 3-4-8 бит (Exllama 2 поддерживает адаптивное квантование, тогда среднее число бит может быть дробным), квантование отличается по числу групп (1-128-64-32 в порядке возрастания качества и расхода ресурсов).
Основные форматы это GGML и GPTQ, остальные нейрокуну не нужны. Оптимальным по соотношению размер/качество является 5 бит, по размеру брать максимальную, что помещается в память (видео или оперативную), для быстрого прикидывания расхода можно взять размер модели и прибавить по гигабайту за каждые 1к контекста, то есть для 7B модели GGML весом в 4.7ГБ и контекста в 2к нужно ~7ГБ оперативной.
В общем и целом для 7B хватает видеокарт с 8ГБ, для 13B нужно минимум 12ГБ, для 30B потребуется 24ГБ, а с 65-70B не справится ни одна бытовая карта в одиночку, нужно 2 по 3090/4090.
Даже если использовать сборки для процессоров, то всё равно лучше попробовать задействовать видеокарту, хотя бы для обработки промта (Use CuBLAS или ClBLAS в настройках пресетов кобольда), а если осталась свободная VRAM, то можно выгрузить несколько слоёв нейронной сети на видеокарту. Число слоёв для выгрузки нужно подбирать индивидуально, в зависимости от объёма свободной памяти. Смотри не переборщи, Анон! Если выгрузить слишком много, то начиная с 535 версии драйвера NVidia это серьёзно замедлит работу. Лучше оставить запас.
Гайд для ретардов для запуска LLaMA без излишней ебли под Windows. Грузит всё в процессор, поэтому ёба карта не нужна, запаситесь оперативкой и подкачкой:
1. Скачиваем koboldcpp.exe https://github.com/LostRuins/koboldcpp/releases/ последней версии.
2. Скачиваем модель в gguf формате. Например вот эту:
https://huggingface.co/Undi95/MLewd-ReMM-L2-Chat-20B-GGUF/blob/main/MLewd-ReMM-L2-Chat-20B.q5_K_M.gguf
Если совсем бомж и капчуешь с микроволновки, то можно взять
https://huggingface.co/TheBloke/OpenHermes-2.5-Mistral-7B-GGUF/blob/main/openhermes-2.5-mistral-7b.Q5_K_M.gguf
Можно просто вбить в huggingace в поиске "gguf" и скачать любую, охуеть, да? Главное, скачай файл с расширением .gguf, а не какой-нибудь .pt
3. Запускаем koboldcpp.exe и выбираем скачанную модель.
4. Заходим в браузере на http://localhost:5001/
5. Все, общаемся с ИИ, читаем охуительные истории или отправляемся в Adventure.
Да, просто запускаем, выбираем файл и открываем адрес в браузере, даже ваша бабка разберется!
Для удобства можно использовать интерфейс TavernAI
1. Ставим по инструкции, пока не запустится: https://github.com/Cohee1207/SillyTavern
2. Запускаем всё добро
3. Ставим в настройках KoboldAI везде, и адрес сервера http://127.0.0.1:5001
4. Активируем Instruct Mode и выставляем в настройках пресетов Alpaca
5. Радуемся
Инструменты для запуска:
https://github.com/LostRuins/koboldcpp/ Репозиторий с реализацией на плюсах
https://github.com/oobabooga/text-generation-webui/ ВебуУИ в стиле Stable Diffusion, поддерживает кучу бекендов и фронтендов, в том числе может связать фронтенд в виде Таверны и бекенды ExLlama/llama.cpp/AutoGPTQ
Ссылки на модели и гайды:
https://huggingface.co/TheBloke Основной поставщик квантованных моделей под любой вкус.
https://rentry.co/TESFT-LLaMa Не самые свежие гайды на ангельском
https://rentry.co/STAI-Termux Запуск SillyTavern на телефоне
https://rentry.co/lmg_models Самый полный список годных моделей
https://rentry.co/ayumi_erp_rating Рейтинг моделей для кума со спорной методикой тестирования
https://rentry.co/llm-training Гайд по обучению своей лоры
https://rentry.co/2ch-pygma-thread Шапка треда PygmalionAI, можно найти много интересного
https://colab.research.google.com/drive/11U-bC6AxdmMhd3PF9vWZpLdi6LdfnBQ8?usp=sharing Последний известный колаб для обладателей отсутствия любых возможностей запустить локально
Факультатив:
https://rentry.co/Jarted Почитать, как трансгендеры пидарасы пытаются пиздить код белых господинов, но обсираются и получают заслуженную порцию мочи
Шапка треда находится в https://rentry.co/llama-2ch предложения принимаются в треде
Предыдущие треды тонут здесь: