

бамп

бамп

бамп
бамп

бамп
Python c библиотекой Beautiful Soup
Гугли регулярные выражения.
спасибо за совет, но я не программист жи
есть что-нибудь готовое в формате *.еxe?
>Гугли регулярные выражения.
В курсе что это, но через какую программу поиск осуществлять и выкачивать ссылки?
бамп вопросу
скажи что за сайт - я сделаю
сажи буряткопидару
после этого поста тред для меня сдох, иди нахуй
мимопогромист

отклеилось
лол, это не особо законно
лучше объясни как это сделать, желательно на пальцах, ибо я, еще раз напомню не коддер
на тебе не Бурятку
бурятко-хейтер
бампец
Похожа на Лесли.
грибо-бамп
wget -r --spider -l1 -t1 -A doc http://example.com/ 2>&1 | grep -Eio http.+doc | tee docs.txt
Это для линуксобогов. У тебя наверняка Windows, поэтому с консолечкой пердолься там сам. Все остальные советы в треде — хуйня.
Это для линуксобогов. У тебя наверняка Windows, поэтому с консолечкой пердолься там сам. Все остальные советы в треде — хуйня.
а тебе не похуй законно это или нет? не ты-же будешь делать
Хороший ответ.
анонасы, так че, нету ли готового варианта в формате *.exe для нуба?
т.е. тебе просто нужно проверить есть ли на сайте ссылка кончающаяся на .doc?
Анон, а че такое "Красивый суп"? Всм для чего?
иди нахуй. я сделаю бесплатно
проиграл че то
мимо-не-оп
а в чем профит тебе?
Нанять программера, очевидно
а можно поподробней? на виртуалке на линксе это будет работать?
хочу помочь
Это вообще то называется "web scraping" и очень востребованно на всяких фриланс-площадках, так что бесплатно я это говно точно не сделаю
зачем? Ты не получишь абсолютно никакой выгоды, а признание будет краткосрочным и от одного человека.
ебанаврот, сорян, но я должен это сам сделать
файлы слишком много стоят :(
просто запиши линукс на флешку и запусти в лайф режиме
Нужно будет только wget установить, он обычно не идет в дефолтной поставке. А так — да, конечно.
>web scraping
Вот сейчас заинтересовал. Есть что-то в интернетах по поводу этой темы? ну там что это такое, что делает в широком смысле и т.д.
[email protected]
ща говорить не могу, внезапно надо уходить, черкани сюда
ща говорить не могу, внезапно надо уходить, черкани сюда
Он карма-йог, а ты ленивое быдло.
даун ,иди на хуй,чмо
ну тогда иди нахуй.. хочешь помочь, а он еще и выебывается
неа
вот смотри, на каждой странице есть ссылка примерно такого вида site.com/123465436.doc
мне нужно прошарить каждую страницу, чтобы всех их собрать в файл txt
Но ведь то что тебе тут сделают, может спиздить твои файлы и ты начнешь сушить сухари, так нахуя ты сюда пришел?
>карма-йог
Тоесть желание делать что-то без признания, материальной выгоды и только с надеждой что когда нибудь зачтется это так называется?
>ленивое быдло
мой левел кодинга наверное не достаточен, хотя я и не уверен. Но попытаться бы мог конечно. Когда то два раза писал прогу для себя что бы пиздить пики с двача. Ох прогером я себя чувствовал)) Но да сейчас это смешно звучит
Ну так я примерно так же и сказал...
Ладно вопрос два, ссылки на страницы уже готовы, или программа должна сама искать все доступные ссылки?
я тут не вешаю свою пробему на других, а задаю вопрос как это сделать, просек?
конечно, большое спасибо за безвозмездную помощь, но мне нужна помощь в виде совета
Ну тебе дали пару готовых вариантов, а насчет парсеров, хз врядли что то еще насоветуют..
Типичное задание для фриланс-биржи.
Сканирование сайтов в интернет не может быть "незаконным". Сайты созданы для того, что бы их html-код считывали, загружали и пр.
Ссылки не готовы, нужно, чтобы парсер искал и проверял каждую страницу, как-то так
"Вкатиться" решил, рачишко?
Очевидным вгетом, ну. Ну проще простого же, ну.
К.О.
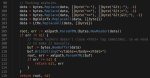
import requests, bs4
f = open('file.txt', 'a')
for i in range(200):
....r=requests.get('http://example.com/page.php?p='+str(i+1))
....soup = bs4.BeautifulSoup(r.text, 'html.parser')
....z=soup.find('a', {'id': 'document'})
....f.write(z['href'])
f.close()
вроде того, перепиши под свой случай
f = open('file.txt', 'a')
for i in range(200):
....r=requests.get('http://example.com/page.php?p='+str(i+1))
....soup = bs4.BeautifulSoup(r.text, 'html.parser')
....z=soup.find('a', {'id': 'document'})
....f.write(z['href'])
f.close()
вроде того, перепиши под свой случай
там фигня в том, что админ сайта по ошибке допустил фейл и в коде сайта стала доступна инфа, которая стоит денег..
Нет, просто интересно.
Не думаю что я применю это знание когда нибудь.
охуел что ли
это для вгета или для чего?
Дауны советую вгеты, хотя не понимают, что 200 тысяч страниц программа будет майнить овердохуя долго.
Пиши на [email protected]
Я заюзаю python, подрублю пару своих выделенных впсок на асинхронных корутинах и быстренько тебе всё соберу.
Стоить работа будет 3 к рублей.
для питона
так пусть админ и напишет парсер, ибо нахуй он нужен
сорямба, я не доверю тебе это качать, те файлы слишком дорогИ
ты не понял, сайт чужой
я пытаюсь спиздить от туда инфу, которая сейчас находится в отрытом доступе
хотя на самом деле это очень даже законно, поэтому уже не парюсь
Спасибо.
Пфффф, я занимаюсь бд у всяких американцев, храню и админю их огромные массивы данных с кучей конфиденциальной инфы. Они мне доверяют, а какой то чел с двача нет? Нахуй мне нужны там твои документы, пусть там даже паспорта или кредитки. Я слишком честный человек, чтобы использовать это всё в корыстных целях
Блин, я польщен, что ты предлагаешь свою помощь, пускай даже платно.
Но меня интересует совет, т.к. я собираюсь все сделать сам.
тоесть ты хочешь спиздить 200к файлов... Охуенное конечно ты нашел место что бы совета спросить, но судить не мне. Найди фриланс чела и дай задание написать прогу.
>сам
>не зная кодинга
Хм...
Начни с Pascal ABC
Но мне теперь даже интересно будет такое написать. Такому нубу как я. Спасибо оп, пойду писать ее.
Спасибо за совет, но я продолжу спрашивать здесь..
Если боишься за свои данные, я тебе тупо могу написать скрипт, ты запустишь его на своей стороне. Мне же тупо сбросишь пример .html страницы твоего сайта с указанием того, что ты хочешь запарсить.
Еще раз спасибо, но я не готов платить 3к

>http.+doc
А оно точно правильно выдерет? А если на document.doc наткнется?
Так тебе же ответили, берешь питон и beautifulsoup. Хотя, тебе лучше взять grab ибо под него есть документация на русском и в гугле туча примеров. http://docs.grablib.org/ru/latest/
>wget -r --spider -l1 -t1 -A doc http://example.com/ 2>&1 | grep -Eio http.+doc | tee docs.txt
слушай, а что если сами ссылки находятся именно в коде страницы, а не открыто "на странице"
будет работать?
сори, я человек спокойный, но ты меня бесишь.
взаимно, выйди из треда
Ты обосрался. Если у тебя на странице будет слово http - прорва текста - doc, то он у тебя выдернет этот текст
нет. Тут попутно много чего интересного рассказывают. Приходится терпеть ОПа питуха
Если ты имеешь ввиду, что ссылка на документ генерируется в браузере жс скриптом, то работать не будет. И в таком случае тебе придется брать селениум, кстати, ты ведь и так его можешь взять, в фаерфоксе под него есть плагин с гуем. Можешь там наебенить скриптик для парсинга.
Плюсик же вроде ленивый квантификатор а не жадный.
> не может
Может. В Европке за NMAP можно сесть. Если говорить про Россию, то тебя могут посадить, если ты скачанную тобой инфу будешь перепродавать, например. Советую тебе не умничать насчет вещей, о которых совсем не знаешь.
>Если говорить про Россию, то тебя могут посадить, если ты скачанную тобой инфу будешь перепродавать, например.
Слишком геморно и затратно, только если ОП реально таким образом кому-то сильно поднасрет. а так хоть обпарсись.
нет, имею в виду, что на самой странице ссылки нету, а когда заходишь в код страницы, она лежит между
<script><object><param>
причем, ссылка на тот самый файл прямая
> Дауны
Тот, про кого ты это сказал я, парсит половину интернетов с 2011 года. Ты же, ньюфажина, создашь заметную нагрузку на сервис своими асинхронными корутинами и с непростительно большой вероятностью спалишься.
Обязательно все?
SELENIUM гугли
то, что я пытаюсь сделать вполне законно, файлы в открытом досупе, не пугайте "мачираторов"
Будет, если не на стороне клиента джаваскриптом генерится.
Если тебе неизвестны все ссылки, то тут тупо нужен перебор, ибо кроме сервера никто не знает их.
Тут два путя. Первый - брать питон, брать парсер, оптимизированый на быструю работу, если ссылок много и делать. Это просто должно быть. Второй вариант - брать готовое решение. Есть много тулз для этого, они как правило связанны с иб. Например, skipfish, кажется, умеет так, как тебе нужно. Он точно справится быстро, так как специально написан для большого объема данных. Есть еще goofile. Он, кажется, на питоне написан. Задаешь ему сайт и список расширений, которые нужно искать, он выдает все ссылки.
Кстати, еще вариант, что-то с wget запилить. Это, кстати, самое простое. Читай доки по нему и юзай.
Кстати, еще вариант, что-то с wget запилить. Это, кстати, самое простое. Читай доки по нему и юзай.
большое спасибо, годнота
поиск ссылок на мэйнпейдже переход на них и с них на остальные, каждый раз сверяясь нет ли одинаковых страниц, что бы не переходить на них дважды.
Мочерне похуй на твои дела.
Я увидел, что человек конкретно ошибается, и решил его поправить. Может, оно ему когда-нибудь поможет избежать суда даже. Не первый раз встречаю человека, который пытается смотреть на законы через призму какой-то своей логики.
Selenium - годно, но, для данной задачи, излишне. Если бы оп имел опыт работы с ним - то да, запилил бы без проблем. Но разбираться в фреймворке чтобы решить одну, конкретную задачу - такое себе.
webbez
Так если как говорит ОП, ссылки жс скриптом генерятся, чем ты их еще кроме селениума выдергивать будешь?
…regex-infection will devour your HTML parser, application and existence for all time like Visual Basic only worse he comes he comes do not fight he comes, his unholy radiance destro҉ying all enlightenment, HTML tags leaking from your eyes like liquid pain, the song of regular expression parsing will extinguish the voices of mortal man from the sphere I can see it can you see it it is beautiful the final snuffing of the lies of Man ALL IS LOST ALL IS LOST the pony he comes he comes he comes the ichor permeates all MY FACE MY FACE ᵒh god no NO NOOOO NΘ stop the an*gles are not real ZALGΌ IS҉ TOƝȳ THE PONY HE COMES
не генерятся ссылки никакие, уже лежит прямая ссылка в коде сайта между скрипт/скрипт
Так ты страничку wget-ом дерни, и проверь, есть ли они в хтмл коде.
нашел интересный видеогайд по вгету
https://www.youtube.com/watch?v=k9qTgrIqM-k
ща буду разбираться, вроде это самое простое
https://www.youtube.com/watch?v=k9qTgrIqM-k
ща буду разбираться, вроде это самое простое
могу сразу сказать, что при сохранении страницы та самая ссылка на нужный файл остается прямой
ахтунг!
кстати, если у сайта посещаемость под 8к уников в день, нет ли у них защиты?
кстати, если у сайта посещаемость под 8к уников в день, нет ли у них защиты?
Совсем ебанутый.
>за NMAP можно сесть
Орнул с этого. А за Земляную Обезьяну, случайно, нельзя сесть, умалишённый?
Тред не читал, не знал, что там жс задействован. Если так, то да, селеиум или типо того придется юзать. Но если они уже есть сгенереные, то выберать что-то из этого
Видеогайды - хуйня. Есть доки, их и читай. И нахуй тебе весь сайт качать?
напиши почту, я с тобой свяжусь
интересно такое написать
мимо_программис
не задействован там джаваскрипт, уже 3-й раза распинаюсь
там всего лишь нужныую прямую ссылку засунули между <скрипт>link </скрипт>
moladosa()gmail.ком
мне не надо весь сайт качать, нужно только скачать прямые ссылки почти с каждой страницы сайта в txt
через вгет пытаюсь сейчас хотябы сайт скачать..
Могут быть что-то вроде промо-страниц, на которые никто не ссылается.
Орнул с разводящих ОПа-лоха на бабки за простейшую задачу.
Найдешь такую страницу, 300кк программист?
node.js+phantom.js+casper.js
Все пишется в течении 15 минут.
Все пишется в течении 15 минут.
вгет не варик?
Еще раз орнул!
Покупаем кувалду и хуярим скобы в своём доме - всё OK.
Надеваем на хуй лоли, берем кувалду и вламываемся в полицейский участок, размахивая кувалдой - арестовывают.
>ко-ко-ко за кувалду можно сесть
перестань тут это обсуждать, ок?
у нас тут другой насущный вопрос, как спарсить файлы с 200к страниц
уже миллиард способов дали
иди ебись
хочешь skacat_vse.exe - плати деньги
я не слепой, но еще один способ не помешает, сечешь?
Рад, что веселю тебя. Прости, но я не вижу смысла спорить с твоей принципиальной позицией. Можешь считать, что сразил меня своим гениальным сравнением.
аноны, почему вгет выдает ошибку Permission denied, когда я выполняю скрипт через командную строку?
wget -r -k -l 10 -p -E -nc http://site.com/
папку в переменных средах указал, но сайт качать отказывается
wget -r -k -l 10 -p -E -nc http://site.com/
папку в переменных средах указал, но сайт качать отказывается
не секу
НО В РОТ ТЕБЕ НАДАЮ, ХАЛЯВЩИК ЕБУЧИЙ, ПИЗДУЙ ДЕЛАТЬ БЛЯДИНА ЕБАНАЯ, ЕЩЕ ЕМУ СКИДЫВАТЬ НУЖНО, ОХУЕВШАЯ РУСНЯ
а зря..
лол, ну у тебя и бомбануло
Лол, нахуя ты ключей-то наворотил столько?
1. Python
2. Beautiful Soup
3. ???
4. Профит
2. Beautiful Soup
3. ???
4. Профит
Как это не идет? На центосе идет
curl
/thread
вот скачал вгет, пытаюсь скачать сайт, но выскакивает хуйня в виде Bad file descriptor
>curl
спасибо за годноту, но слажнавата жи
рукожопу некоддеру дофига с этим разбираться
Вот нахуй ты этот вопрос задал, скажи? По-твоему, во всех дистрибутивах всё так, как в том, который знаком тебе? Там ещё и sudo искаропки, да?
Лол, тот же вгет, только в профиль. aira2c еще туда же. Отличия есть, но вкатываться одинаково.
aria2c*
Ты там на чем таком спартанском сидишь-то? На дебиане штоле?
мимоарчешкольник
import re
links='\n'.join([_ for _ in re.findall(r'href="([^"]+?)"',page) if re.findall(r'\.doc$',_)])
f1=open('results.txt','wb');f1.write(links);f1.close()
пиздец синтаксис. это шо, питон?
> спартанском
Оно спартанское, если тебе пятнадцать лет и ты сидишь в /s/. Если это часть твоей работы, то тебе тяжело понять логику тех, кто подобные вопросы задает.
пользуясь случаем неутонувшего треда спрошу,
в чем может быть проблема такой ошибки в wget?
... ошибка: Bad file descriptor.
в чем может быть проблема такой ошибки в wget?
... ошибка: Bad file descriptor.
Плохое описание файла.
что за команду юзаешь?
wget -r -k -l 10 -p -E -nc http://site.com/
Ты ведь под Виндой пытаешься это все провернуть?
да, все верно, через командную строку ввожу команду

Че-то качает вроде.
Проблема здесь в том, что, кроме тебя, такие вещи делают три с половиной инвалида в мире. Поэтому когда сталкиваешься с проблемой, в ответ на свои просьбы о помощи можешь не ждать чего-то отличного от «ну хуй знает, у меня всё работает».

вот такая фигня вылетает
вгет устанавливал по адресу C:\Program Files (x86)\GnuWin32\bin
попробуй форсировать айпив4
припиши -4
-4 добавь во флаги.

ееее, заработало
нужно было юзать эту команду wget -r -k -l 10 -p -nc --no-check-certificate
плюс вырубить файервол
нужно было юзать эту команду wget -r -k -l 10 -p -nc --no-check-certificate
плюс вырубить файервол
И да, я действительно не люблю Windows в том числе и по религиозным соображениям, но это боль, обоснованная определенным жизненным опытом.
Разрабатывали мы одну софтину, которая собиралась под различные платформы. Сначала виндовые сборки успешно собирались на линуксе с MinGW, но потом по ряду причин пришлось сборку перенести на Винду. Бля-я-я-я, какая же это анальная боль была. Сначала попробуй установи, потом попробуй запустить так, чтобы конфиги подцепились и переменные окружения были видны, а потом попробуй добиться желаемого результата ещё. Подводные камни на каждом шаге, решений проблем Гугл не знает. Короче, не рекомендую лишний раз пытаться что-то из швабодного мирка завести под Виндой без необходимости. Избегайте этого максимально.
к сожалению с линуксом у нас не сложилось
драйверов на видеокарту не нашлось и в целом слишком сложная штука, не хватает нужных програм, приходится с костылями использовать, что очень не удобно
Школьники до сих пор парсят HTML регэкспами, вместо DOM и XPath?
Есть готовый вариант за 20к. Будешь брать?
читай внимательней тред, я уже нашел решение
качаю вгетом все 200к страниц, потом вытаскиваю нужные ссылки
win
ну скорей всего он это делает через платные проксики
Нешкольник не знает наверняка, корректный ли там документ, но заранее выебывается? Сколько же вас тут умных, я хуею просто. Когда нужно быстренько на коленке слабать, регулярки — выбор успешного человека. Когда делаешь что-то всерьез и надолго, то делаешь как на пике, плачешь и тратишь часы на отлов всех возможных подводных камней на миллионах URL, но это потому что затраты окупаются.
Конкретный пример со скринами покажи, как всё выглядит.
Вот в таком виде лежит ссылка на файл ch1_131108.doc
<script type="text/template" id="tret">
<object id="1" classid="1" codebase="http://www.site.com" width="1" height="1">
<param name="src" value="https://www.site.com/temp/ch1_131108.doc" />
</object>
</script>
нужно выдергнуть эту ссылку в файл
страниц около 200к
пока что тупо качаю страницы юзая вгет через командную строку:
wget -r -k -l 10 -p -R jpg,css,png,js,gif,txt,swf -nc --no-check-certificate http://site.com
Скорее всего нужные ОПу данные приходят json-ом , но я не уверен.
Если б был доступ к этому сайту, можно было бы сказать точно.
нет, там не json
там все безумно просто устроено <скрипт> та самая прямая ссылка </скрипт>

Эээ... А ты точно тот анон, которому были нужны файлы с расширением .doc ?
Нейроночки на питончике поди хотели потеребить?
О, "Красная Бурда". Спасибо, анончик.
Ищи параметр по имени, бери его значение и переходи к следующему. Это будет долго, но я хз, как можно ещё сделать.

да, тот
но конечно там файлы не с расширением doc, а другим, более ценным (для меня)
Короче не знаю, поможет ли мой способ, но тут все просто и справится даже ребенок.
1. Сохраняешь хтмл файл внутри которого ссылка на нужный документ.
2. Выключаешь доступ в инет
3. Открываешь файл в браузере(смотри чтоб не подтянулся кеш, лучше очистить лишний раз) и ищешь эту ссылку
Далее:
Если ссылка есть, нам повезло и можно использовать питоновский grab или bs.
Грабом не сложно будет найти нужный тег и извлечь значение параметра value.
Если же нужных данных нет, надо атаковать страницу seleniumом. Лучше использовать Selenium вместе с Chrome, быстрее будет.
Такие дела. Отпишись как получилось, интересно.
1. Сохраняешь хтмл файл внутри которого ссылка на нужный документ.
2. Выключаешь доступ в инет
3. Открываешь файл в браузере(смотри чтоб не подтянулся кеш, лучше очистить лишний раз) и ищешь эту ссылку
Далее:
Если ссылка есть, нам повезло и можно использовать питоновский grab или bs.
Грабом не сложно будет найти нужный тег и извлечь значение параметра value.
Если же нужных данных нет, надо атаковать страницу seleniumом. Лучше использовать Selenium вместе с Chrome, быстрее будет.
Такие дела. Отпишись как получилось, интересно.
вроде писал, что страниц выходит около 200 000
пока что качаю их на комп, потом парсить буду на наличие ссылок с нужными файлами (анон подсказал)
вроде норм идея?
Пиши в телегу @fiuhd, договоримся по цене, сделаю.
не ответил по поводу ссылки
ссылка всегда есть (если мы нужную страницу скачали), хоть просто сохранить как, хоть через вгет
не, спс
я не доверю скачивать, слишком рискованно
Вся проблема в том, что возможно ты делаешь ненужную работу. Есть вероятность, что ты спарсил страницы без нужного тебе кода.
Это можно проверить открыв уже скачанный хтмл в текстовом редакторе и поискав ссылку.
Я же написал, что все норм скачивается, ссылки остаются
>пока что качаю их на комп
>вроде норм идея?
Нет.
Так в арче судо нету
прост проблема в том, что те самые прямые ссылки лежат в коде, которые не видно на страницах
их вроде просто так не вылудишь
Ну как бы мне абсолютно похуй что у тебя там лежит (хоть ядерные коды, блять). Ты мне заплатишь приемлемую сумму, я для тебя выкачаю ссылки. Джаст бизнес.
Оп, гугли Screaming Frog SEO Spider. Ключ также гуглится. Парсит в несколько потоков, работает с регулярками, делает экспорт. Можешь не благодарить.
Ты может быть уже это все знаешь, но как бы это...
При скачивании данных через Wget не выполняются скрипты на странице, которые могут быть необходимы для того, чтобы там появилась нужная тебе ссылка.
При скачивании данных через Wget не выполняются скрипты на странице, которые могут быть необходимы для того, чтобы там появилась нужная тебе ссылка.
Хоть бы скинул фрагмент кода с ссылкой.
А так ты будешь просто мозги анонам и в первую очередь себе ебать. Ну в общем смотри сам.
-кун
-кун
блин, я же писал выше.. хотя тут дофига постов уже..
лан, еще раз. там не генерится ссылка, она по умолчанию стоит на странице
>Screaming Frog SEO Spider
500 url limit
Я такие вещи на работе пишу :(
>там не генерится ссылка, она по умолчанию стоит на странице
Тогда нет смысла качать все себе на винт, можно качать одни доки.

вот, уже скидывал
Вот в таком виде лежит ссылка на файл ch1_131108.doc
<script type="text/template" id="tret">
<object id="1" classid="1" codebase="http://www.site.com" width="1" height="1">
<param name="src" value="https://www.site.com/temp/ch1_131108.doc" />
</object>
</script>
нужно выдергнуть эту ссылку в файл
страниц около 200к
тебе регекс дали же омг
>wget -r --spider -l1 -t1 -A doc http://example.com/ 2>&1 | grep -Eio http.+doc | tee docs.txt
дык вот как выдергнуть через вгет?
кодить то я не умею
файлы там с рендомным названием, просто так через доунлоад мастер не скачаешь
Гугли ключ

Тебе вишмастер щас скину
Не кидай
>wget -r --spider -l1 -t1 -A doc http://example.com/ 2>&1 | grep -Eio http.+doc | tee docs.txt
можешь пояснить что означает каждая команда?
чтобы понятно было, если не сложно
... и будет там
fileUrl = g.get.document('//param[value]')
спасибос!
ок, сейчас проверю что скачалось, специально..

Кстати, откуда у него под виндой wget ?
через командную строку жи, все просто
оп
Так поставь и настрой, удобно же, ебана.
это я придумал название, не обращай внимание
Скачал и поставил, очевидно.
ананы, как через вгет качать страницы только из этой дериктории?
www.site.com\ui\ID_09\
www.site.com\ui\ID_09\
А что , директория отдает список файлов?
>Как вытянуть эти ссылки относительно быстро и красивый суп+лэхэмэлэ
не не, прост чтобы страницы выкачивались только если они находятся по этому пути www.site.com\ui\ID_09\page.html
чтобы остальные пропускались
Вот ты конченый, честное слово. Конченый просто. Я тебе, по сути, ещё в начале треда дал готовую команду, а ты до сих пор не разобрался.
-r — рекурсивно обойти сайт;
--spider — в режиме паука, то есть не загружать файлы, а просто собирать URLы, как ты и просил;
-l1 — слишком далеко не уходить вглубь сайта, настроить под себя;
-t1 — количество попыток при сетевых сбоях всяких, тоже настроить под себя;
-A doc — через запятую форматы интересующих файлов;
2>&1 — перенаправление stderr в stdout, потому что wget пишет в stderr всё;
Через вертикальные черточки пишутся конвейерные команды (как-то так это будет на русском, наверное, я не ебу). То есть вывод первой команды идет на ввод второй. И так далее.
grep — отсеиваем все лишнее из вывода wget
-Eio — включить режим регистронезависимых (i) регулярок (E, можно было воспользоваться алиасом egrep) и выводить только подходящие подстроки (o)
tee docs.txt — клонировать вывод из терминала в файл, чтобы ты и вживую мог прогресс наблюдать, и одновременно это в файл сохранялось.
Ты какой-то дегенерат, честное слово. Анон выше где-то выебывался, что wget будет тебе все ссылки вечность скачивать. Увы, к данному моменту ты бы уже раза три успел все выкачать. Тут бутылочное горлышко — не wget, а твоя, анон, голова.
Запрети подниматься в родительские каталоги. --no-parent или -np.
сделаю за пару сотен
не злись, я нуб, ща попробую..
как дерикторию вот эту указать, чтобы все остальные обходил? www.site.com\ui\ID_09\
Иди нахуй. Ответил за того анона.
Не благодари.
не работает, пишет
"grep" не является внутренней или внешней
командой, исполняемой программой или пакетным файлом.
Ты, вполне возможно, обосрешься и отсеешь не то, что нужно отсеять, потому что ты не понимаешь, как это работает. Двести, двести, ёбаный ты в рот, постов, а ты нихуя еще не сделал. Либо вкидывай ссылку на сайт в тред, чтобы я тебе дал полностью готовую команду и объяснил, что к чему, либо дальше жди советов долбоебов с их Питонами, крякнутыми мокрописьками и деловыми предложениями, раз ты такой отбитый.
А все равно поблагодарю.
ДА ТЫ ШО?
Линукс нашевели где-нибудь сначала, на виртуалке или на живой флешке с убунтой какой-нибудь.

да ну, я заебусь его устанавливать, пускай даже на виртуалку
спасибо и на этом за помощь
> заебусь его устанавливать
Охуеть, далее-далее-готово прощелкать в убунте. Тебе же им не пользоваться полноценно, а так, консольку получить. В винду та команда все равно не пролезет, даже если ты grep и tee поставишь. Плюс почти наверняка получишь кодировкопроблемы в виндовой консольке.

кстати, с такой командой файлы doc не скачиваются
причем причина очень простая, они не на странице находятся, а в коде скрипта
я об этом писал в первых постах, но ты видимо проигнорил
ОП
Не забудь велосипед изобрести.
Ты о чем? Я же сказал, что не пашет. Нужные файлы твоя команда не выдергивает(

можно ли в вгете увеличить скорость скачивания?
а то выходит около 100 страниц в минуту, маловато
с дерикториями уже разобрался -I
а то выходит около 100 страниц в минуту, маловато
с дерикториями уже разобрался -I
бастрофикс *директориями
нахуй вы помогаете этой тупой школоте?
Щас забаню, усек?
Мамку свою забань, шкет
нет ты
Мимокрок, палящий ресурс, которым пользуешься раз в год, когда мимокрокодишь мимо треда в /б
https://explainshell.com/explain?cmd=wget+-r+--spider+-l1+-t1+-A+doc+http%3A%2F%2Fexample.com%2F+2%3E%261+%7C+grep+-Eio+http.%2Bdoc+%7C+tee+docs.txt
спс
а он точно найдет в теле скрипта ссылку?
иди нахуй тупая шлюха
>а он точно найдет в теле скрипта ссылку?
>
ты даун?

не твоя личная, лол
пшел от сюда, холоп
сверху уже писал, что нуб
зачем снова задавать похожие вопросы?
соси хуй быдло
Не, антош, он просто поясняет с вертушки в щщи юниксовские команды. Ничего больше :3
хех, я уж решил он решил помочь скачать
напИсали ему в ротик, а он просит добавки
ух какой шалунишка
ебать ты сука тупой
двачую. уже давно разжевали что и как

всего выходит 140000 нужных страниц
скачалось уже 1400
эх
скачалось уже 1400
эх
а еще я не умею ремонтировать унитазы
ух блять тупизна!1
элитко роток открыло
Зачем устанавливать для этого линукс? Cygwin же есть
да блять тупой он... отбитый полностью...
запусти программу еще один раз, чтобы было в два потока
wget автоматически будет собирать сайты, но быстрее

>Cygwin
тут анончик выше советовал линукс навернуть, я в этом не разбираюсь
но к сожалению даже с линуксом греп работать не будет
он не вытаскивает файлы из кода скрипта страницы
фига се, это просто вин
ща попробую
благодарю за совет
test
максимум можно вроде-бы 8 потоков качать
ну это если винда хр. а если 7 или 10, то лимита нет
врубил вторую cmd, пишет что страница уже имеется и перестает скачивать
код команды вот такой
wget -r -k -l 10 -p -R jpg,css,png,js,gif,txt,swf,pdf,JPG,PNG -nc -I re,ID_co --no-check-certificate https://www.site.com/
-nc удали
"-nc" нужно убрать
да норм, за два дня все качнешь. а то начнешь дудосить, тебя и закроют.
Двачую за Пайтон.
>-nc
файлы тупо заменяться будут, какой смысл убирать?
тоже к этому склоняюсь
но потом-то в любом случае прийдется дудоснуть 140к файлов:)
что-бы качать не в один поток. читай маны нуб)
уже курю)
;)
Хацкеры, помню в Винду 10 вшивали консольку с поддержкой убунты, ето так?


получилось в 2 потока, значит и в 10 выйдет
вот такая фигня для нескольких окон
wget -r -k -l 10 -p -R jpg,css,png,js,gif,txt,swf,pdf,JPG,PNG -N -I po,ID_co --no-check-certificate https://www.site.com/
еще раз спасибо всем, кто помог
вот такая фигня для нескольких окон
wget -r -k -l 10 -p -R jpg,css,png,js,gif,txt,swf,pdf,JPG,PNG -N -I po,ID_co --no-check-certificate https://www.site.com/
еще раз спасибо всем, кто помог
Кто уже наконецто сдиванонит что ОП там парсит ?
азаза
ОП
Спасибо, анон-хуй <3
Это можно восстановить. Только всем лень
Ты о чем?




Нужно вытянуть почти с каждой страницы сайта ссылку, например, на .doc документ (она одна на каждой странице) и положить все найденные ссылки в .txt
Страниц около 200к. Как вытянуть эти ссылки относительно быстро и без "жертв"?
Сам я не программист, хз как это осуществить.