














Документо тред?

молоденькая, ах ах
https://vk.com/id93692868
https://vk.com/id93692868







Вроде того
https://vk.com/doc93692868_437025676
это ссыль на фотку.
Судя по аккаунту, телка любит фотать своё тело. По-любому у нее есть фоты ню. Как можно найти остальные ее фото?
скрипт делающий вместо списка галерею https://pastebin.com/xgd0ca8y
пробовал вручную перебирать адрес. Получается, но очень уж долго












увы, аккаунт владельца заблочен
Добра тебе анончик ! что бы я сегодня делал если бы не ты
>IMG_####.jpg
а как понять с чей страницы фото вылажено?

вот тебе скрипт
вот как ты их нашел?
Я три нашел, они рядом были, а четвертую нашел перебирая последние две цифры в ссылке
как его запустить?
Бля, я цп нашел, звонить в полицию?
не, кидай сюда, сами разберемся
А как им пользоваться?

ну вот 1 фотка , которую думаю можно

скрипт ищет, и создает в папке где лежит ссылки если что то есть








Название фото на gallery начинается?
IMG

понятно. А чем его запускать. Вот скачал я txt файл в папку, дальше что?
алсо, чекните дату типа 22 февраля
или 23 февраля (наверняка пёзды дарят свои фотки)
или 23 февраля (наверняка пёзды дарят свои фотки)

Эм, там вобще хватает этого добра. моча, не тупи. у меня всё замазано








галка ёбанамать
более точное название
Обычно моча за такие фотки сразу трет
как вы сука такое находитЕ?

да, что-то есть
я установил расширение pastebin, как теперь его заюзать?
Качаем curl: http://www.paehl.com/open_source/?download=curl_752_1_ssl.zip (ссыль битая, просто скачайй курл с ссл из загрузок)
Создаем на диске D, папку vk, закидываем туда curl.exe, создаем go.bat, редактируем
@echo off
goto start
rem начало жи есть :start
:start
setlocal EnableDelayedExpansion
rem переход в текущую директорию
cd %CD%
rem курлом пытаемся скачать диапазон ссылок на доки, с ограничением в 4000 байт (было замечено что пустые страницы весят 15кб)
curl --max-filesize 4000 -k https://vk.com/doc80031892_328432[000-999] -o #1.html
rem ищем все скачанные файлы с расширением .html, ищем там ссылку на фото и качаем по этой ссылке, выписываем ссылку в файл лога с датой
for /f f in ('dir /b .html') do FOR /f skip^=109^ tokens^=2^ delims^=^" a in (f) do curl -k a -O | echo a >>log.txt
rem избавляем файл от мусора в расширении
for A IN (.jpg*) DO ren "A" "~nA%.jpg"
rem удаляем хтмл файлы
Я только отсос прыщавого куна куну находил

Лол, бабы думают что сиськи на 23 февраля это лучший подарок, дабллол
все равно тема сисек не раскрыта
https://gist.github.com/dr4g0n/9d8318c5cdfcd1cda61b05fa83ff2c6e корче, тут куча вариантов как эт проворачивать, на мой взгляд курл был наименее геморным тут

лол
Лол, какая счастливая девочка
установить надо какой нить tamper monkey и туда добавить скрипт этот








Моча в бредаче, анончик.
Анонче, не приложи толику усердия и разума, по жа луй ста
просто надо по годам прошарить
мне на работе не оч удобно

Объясните тупому как с помощью букв из блаконта попадать к владельцам документов на старницу

Фу


Q

ЕТоже их нашел)




Если пользователь заблочен можно котырть картинки?
IMG-20170223-WA0006.jpg не могу открыть, а там что то интересное
IMG-20170223-WA0006.jpg не могу открыть, а там что то интересное
При поиске результатов больше, а показывают ограниченное количество

Как с помошью кода зайти на страницу((
Объясните как искать? У меня одна хуета какая-то
Алсо, конечно выборка будет огромная
но можно ещё типа пробовать пробирать Ира, Маша, Женя, Оля и прочие женские имена, на архивы zip rar 7z и прочее.
может что будет
но можно ещё типа пробовать пробирать Ира, Маша, Женя, Оля и прочие женские имена, на архивы zip rar 7z и прочее.
может что будет
там больше нет ничо
добавить фотку к себе в доки и посмотреть
Да там максимум шлюха будет и то фейковая



Бамп





Добавь к себе в документы, там плюсик справа. Потом снесёшь за ненадобностью.
Поверь, что мини-пак собрать, я тонны говна пересмотрел
Сюда чаю, пожалуйста
скрипт на галерею охуенен, спасибо анончик, а то глаза плавиться начали








Сюда вот галку плес
Удвоил


бамп

Вместо решеток нужно что-то писать? Или просто так вставлять? Я тупой 10 айсикью
Вот пасту случайно нашёл, плюс к скрипту:
Эта инструкция собрана по крупицам анонов и призвана помочь всем тем, кто не знает как скачивать личные документы из вк.
Часто возникает один вопрос.
Можно ли скачивать личные документы конкретного пользователя вк?
Да, можно и нужно. Читай подробнее инструкцию и поймешь как это сделать.
==============
ДЕЛАЕМ РУЧКАМИ
==============
1) Заходим на vk.com/docs
2) Вводим в поиске или дату (20161224) или стандартный префикс для фото(DCIM, SRC, SCAN, IMG, gifpal, picachoo и тд. SAM DSCN img_ gifme topgifme)
3) Просматриваем найденное
4) Находим годноту и кидаем в тред
5) PROFIT!
- FAQ : Как узнать id человека по найденному документу?
Адрес ссылки: doc386641432_439078355 id - 386641432
- ИТАК! Учу анонов по поводу поиска moar доков понравившейся вам жертвы:
Пример: Вот видите, тот, кому я отвечаю, запостил две ссылки на тетю. Видите, да? Так вот. https://vk.com/doc334129431_443359124 Видите, что последние цифры рядышком? 124. Надеюсь, мозги заработали ваши? Теперь пишите 125 и так далее или же 123. В общем, добавляйте либо +1 либо -1 к окончанию, добавляйте и проверяйте. -
Объясняю блядь еще раз. Заходишь вконтакт. Пишешь радномные цифры вк.ком/doc71383259_279208233
Если годнота, то кидаешь в тред, если нет то другой рандом вк.ком/doc71385459_219208233
Поясняю особенно подробно
вк.ком/doc1111111_2222222
1111111 - это id пользователя
2222222 - это номер файла
Таким образом можно брутить файлы одного человека. Скрипт делает именно это. Для венды пилить лень, для линухи смотрим шапку.
Рандом это очень сложнааа, потому палю еще один способ.
Заходишь на https://vk.com/docs
Пишешь JPG или GIF.
Дебе выдает фотографии рандомных людей
Среди фотографий попадаются лютые вины
Присматривайтесь к названиям годноты. Это может быть IMGTRIKA01343.JPG какой-то фапабельной тни из какого-то говнофотошопа. Потому пишем IMGTRIKA и находим похожий фап-контент.
Пример полученной ссылки:
https://vk.com/doc1111111_222222222
Чекайте цифры на месте единиц и пишите их вместо цифр после id
( например vpashe.ком/id1111111)
Сохранил давно, проверьте)
На странице под концом списка есть кнопка "Показать ещё", но она почему-то по умолчанию скрыта. Надо через "Исследовать элемент" убрать у неё атрибут style = "display: none;" и дальше просто на неё нажимать. То есть : 1. Создать закладку (на панели браузера) 2. В поле ввода урла вставляем javascript:(function()%7Ba%3Ddocument.getElementById(%22docs_search_more%22).style%3B%20a.display%3D%22block%22%3B%20a.visibility%3D%22visible%22%7D)() 3. Когда вводим поиск на вк-докс, нажимаем кнопку и у нас теперь СКРОЛИТТТЦА!1 -
У кого вытекают глаза смотреть на маленькие картинки при поиске
в коде сделай поиск по слову "docs_search_more" выдели его мышкой и справа сними галочку с блока "display: none;" 1) в коде сделай поиск по слову "docs_item_thumb" выдели его мышкой и справа сними галочку с блоков "width" и "height" 2) потом в коде сделай поиск по слову "docs_item_thumb_img" выдели его мышкой и справа сними галочку с блоков "max-height" и "height"
===================
ДЕЛАЕМ ИНСТРУМЕНТОМ
===================
https://radiokot.com.ua/vkdocs парсер на питоне, посоны говорят что ворует данные
http://rghost.ru/52243464 какой-то десктопный парсер, посоны говорят что нерабочий
http://poiskvk.org возможно интим уже есть там, но я ни рдин раз не нашел
http://scotobaza.org запрещен в рахе и работает только под определенными проксями
еще парсер на питоне от одного замечательного анона:
http://rgho.st/7WqgXPv6s (версия 1.0)
Теперь можно выбрать стартовое значение.
А также вместо дохуя кол-ва циклов теперь один
http://rgho.st/8sPqCDDN2 (версия 1.1)
крч опять поправил, теперь она сам должен устанавливать посторонюю библиотеку без которой не будет работать скрипт
http://rgho.st/8tXzHBftv (версия 1.2)
Ну, значца, качаешь питон
https://www.python.org/downloads/release/python-363/
Сохраняешь скрипт
Запускаешь cmd если возникнут проблемы при записи в файл, запускай от имени администратора и там прописываешь
cd путь_к_папке_с_файлом
cd C:\Users\анон\Desktop
После пишешь:
python main.py
это bash-скрипты под Linux:
код качалки http://pastebin.com/EZPhDWrx
код чистилки http://pastebin.com/2cPRY47D
1.sh 200005 300000 300100
Вывод
doc200005_300000
doc200005_300001
doc200005_300002
doc200005_300003
...
doc200005_300100
Все документы хранятся в папках от 0 до 10
Запускаешь 1.sh ИД_ПОЛЬЗОВАТЕЛЯ ФОТКИ_С ФОТКИ_ДО
1.sh 111111 222222 222922
Запускаешь второй 2.sh docs.txt
Он проверяет все айдишники доков, каких доков и сохраняет в docs.txt ссылки на все найденые документы пользователей и удаляет мусор.
через CURL СОЛУШН:
1. Качаем curl: http://www.paehl.com/open_source/?download=curl_752_1_ssl.zip
2. Создаем на диске D, папку vk, закидываем туда curl.exe, создаем go.bat, редактируем
3. Вставляем curl -k https://vk.com/doc341219317_4436533[00-99] -o #1.html
4. сохраняем.
5. запускаем, сортируем файлы по размеру, те которые отличаются - имеют картинки, даблклик и в браузере картинка.
6. Чтобы добавить новое урл, нужно заменить старый. (работаем только в батнике)
7. Можно задавать диапазоны хоть 1234567[0-9], хоть 123[00000-99999], хоть аллаха
8. кому лень делать - залил на ргхост: http://rgho.st/68l4fhNn6
9. скорость большая, можно ебашить задержку через команды курла
10. А теперь можно и пивка
1. качаешь http://rgho.st/68l4fhNn6
2. открываешь go.bat
3. у тебя урл https://vk.com/doc77887170_443542988, значит попробуем curl -k https://vk.com/doc77887170_4435429[00-99] -o #1.html (перебор по последним двум цифрам) 4. сохраняем, запускаем
5. оно скачало 100 файлов, 4 из которых не такого размера как остальные, это файлы с картинками если есть время, можно посканить 4435430[00-99] , т.е. след. СОТНЮ
Вопрос/Ответ:
-1.Могу ли я найти документы определенного человека?
-2.Можешь, но для это придется вручную чекать 9 цифр, что займет уйму времени и не факт, что документы у жертвы вообще есть.
еще CURL СОЛУШЕН от дискорд-конфы:
http://rgho.st/87LGlGHcK
универсальная программа для Linux и Windows
не требует авторизации, гоняет рандомных людей, гоняет доки конкретного пользователя
если будут ошибки, то качаем Cookie Export на лису или cookies.txt на хром и кидаем в папку с прогой
http://rgho.st/8JD94nXHb [ DocsMiner ]
подробная инструкция Докс Майнера:
1. Качаем Java если нет.
2. Качаем плагины cookies.txt для хрома и Export Cookies для лисы (не обязательно, но у некоторых без этого не работает).
3. Экспортируем в файл cookies.txt и сохраняем в папке с программой.
4. Тестируем программу запустив DocsMinerTest и написав doc452578610_452200429.
5. Смотрим в папку Docs. Там должна появится картинка.
6. Запускаем поиск по ID или общий поиск. Соответствующие файлы.
Также доступна функция выкачки доков из поиска
Допустим заходишь в https://vk.com/docs и пишешь IMG, тебе дает результат, но тебе надо все просматривать и ручками качать
Модуль DocsMinerSearch делает это автоматический, а там уже разбирайся нравятся тебе эти доки или нет
Работы по улучшению ДоксМайнера ведутся, пишите жалобы\пожелания по следующим адресам телеграма: @Netlez @zakukan @Az0955565 @wannabedead
все эти секреты были взяты из хакерской дискорд-конфы:
https://discord.gg/47tbYyb
она была создана с целью находить секреты сайтов и использовать их на благо анона
присоединяйся если знаешь код или хочешь получить полезные инструменты от наших анонов
сейчас идут обсуждения того, как доставать личные фотографии из других соцсетей
не стесняйся, мы будем тебе рады, особенно если у тебя есть идеи где и что искать*
Эта инструкция собрана по крупицам анонов и призвана помочь всем тем, кто не знает как скачивать личные документы из вк.
Часто возникает один вопрос.
Можно ли скачивать личные документы конкретного пользователя вк?
Да, можно и нужно. Читай подробнее инструкцию и поймешь как это сделать.
==============
ДЕЛАЕМ РУЧКАМИ
==============
1) Заходим на vk.com/docs
2) Вводим в поиске или дату (20161224) или стандартный префикс для фото(DCIM, SRC, SCAN, IMG, gifpal, picachoo и тд. SAM DSCN img_ gifme topgifme)
3) Просматриваем найденное
4) Находим годноту и кидаем в тред
5) PROFIT!
- FAQ : Как узнать id человека по найденному документу?
Адрес ссылки: doc386641432_439078355 id - 386641432
- ИТАК! Учу анонов по поводу поиска moar доков понравившейся вам жертвы:
Пример: Вот видите, тот, кому я отвечаю, запостил две ссылки на тетю. Видите, да? Так вот. https://vk.com/doc334129431_443359124 Видите, что последние цифры рядышком? 124. Надеюсь, мозги заработали ваши? Теперь пишите 125 и так далее или же 123. В общем, добавляйте либо +1 либо -1 к окончанию, добавляйте и проверяйте. -
Объясняю блядь еще раз. Заходишь вконтакт. Пишешь радномные цифры вк.ком/doc71383259_279208233
Если годнота, то кидаешь в тред, если нет то другой рандом вк.ком/doc71385459_219208233
Поясняю особенно подробно
вк.ком/doc1111111_2222222
1111111 - это id пользователя
2222222 - это номер файла
Таким образом можно брутить файлы одного человека. Скрипт делает именно это. Для венды пилить лень, для линухи смотрим шапку.
Рандом это очень сложнааа, потому палю еще один способ.
Заходишь на https://vk.com/docs
Пишешь JPG или GIF.
Дебе выдает фотографии рандомных людей
Среди фотографий попадаются лютые вины
Присматривайтесь к названиям годноты. Это может быть IMGTRIKA01343.JPG какой-то фапабельной тни из какого-то говнофотошопа. Потому пишем IMGTRIKA и находим похожий фап-контент.
Пример полученной ссылки:
https://vk.com/doc1111111_222222222
Чекайте цифры на месте единиц и пишите их вместо цифр после id
( например vpashe.ком/id1111111)
Сохранил давно, проверьте)
На странице под концом списка есть кнопка "Показать ещё", но она почему-то по умолчанию скрыта. Надо через "Исследовать элемент" убрать у неё атрибут style = "display: none;" и дальше просто на неё нажимать. То есть : 1. Создать закладку (на панели браузера) 2. В поле ввода урла вставляем javascript:(function()%7Ba%3Ddocument.getElementById(%22docs_search_more%22).style%3B%20a.display%3D%22block%22%3B%20a.visibility%3D%22visible%22%7D)() 3. Когда вводим поиск на вк-докс, нажимаем кнопку и у нас теперь СКРОЛИТТТЦА!1 -
У кого вытекают глаза смотреть на маленькие картинки при поиске
в коде сделай поиск по слову "docs_search_more" выдели его мышкой и справа сними галочку с блока "display: none;" 1) в коде сделай поиск по слову "docs_item_thumb" выдели его мышкой и справа сними галочку с блоков "width" и "height" 2) потом в коде сделай поиск по слову "docs_item_thumb_img" выдели его мышкой и справа сними галочку с блоков "max-height" и "height"
===================
ДЕЛАЕМ ИНСТРУМЕНТОМ
===================
https://radiokot.com.ua/vkdocs парсер на питоне, посоны говорят что ворует данные
http://rghost.ru/52243464 какой-то десктопный парсер, посоны говорят что нерабочий
http://poiskvk.org возможно интим уже есть там, но я ни рдин раз не нашел
http://scotobaza.org запрещен в рахе и работает только под определенными проксями
еще парсер на питоне от одного замечательного анона:
http://rgho.st/7WqgXPv6s (версия 1.0)
Теперь можно выбрать стартовое значение.
А также вместо дохуя кол-ва циклов теперь один
http://rgho.st/8sPqCDDN2 (версия 1.1)
крч опять поправил, теперь она сам должен устанавливать посторонюю библиотеку без которой не будет работать скрипт
http://rgho.st/8tXzHBftv (версия 1.2)
Ну, значца, качаешь питон
https://www.python.org/downloads/release/python-363/
Сохраняешь скрипт
Запускаешь cmd если возникнут проблемы при записи в файл, запускай от имени администратора и там прописываешь
cd путь_к_папке_с_файлом
cd C:\Users\анон\Desktop
После пишешь:
python main.py
это bash-скрипты под Linux:
код качалки http://pastebin.com/EZPhDWrx
код чистилки http://pastebin.com/2cPRY47D
1.sh 200005 300000 300100
Вывод
doc200005_300000
doc200005_300001
doc200005_300002
doc200005_300003
...
doc200005_300100
Все документы хранятся в папках от 0 до 10
Запускаешь 1.sh ИД_ПОЛЬЗОВАТЕЛЯ ФОТКИ_С ФОТКИ_ДО
1.sh 111111 222222 222922
Запускаешь второй 2.sh docs.txt
Он проверяет все айдишники доков, каких доков и сохраняет в docs.txt ссылки на все найденые документы пользователей и удаляет мусор.
через CURL СОЛУШН:
1. Качаем curl: http://www.paehl.com/open_source/?download=curl_752_1_ssl.zip
2. Создаем на диске D, папку vk, закидываем туда curl.exe, создаем go.bat, редактируем
3. Вставляем curl -k https://vk.com/doc341219317_4436533[00-99] -o #1.html
4. сохраняем.
5. запускаем, сортируем файлы по размеру, те которые отличаются - имеют картинки, даблклик и в браузере картинка.
6. Чтобы добавить новое урл, нужно заменить старый. (работаем только в батнике)
7. Можно задавать диапазоны хоть 1234567[0-9], хоть 123[00000-99999], хоть аллаха
8. кому лень делать - залил на ргхост: http://rgho.st/68l4fhNn6
9. скорость большая, можно ебашить задержку через команды курла
10. А теперь можно и пивка
1. качаешь http://rgho.st/68l4fhNn6
2. открываешь go.bat
3. у тебя урл https://vk.com/doc77887170_443542988, значит попробуем curl -k https://vk.com/doc77887170_4435429[00-99] -o #1.html (перебор по последним двум цифрам) 4. сохраняем, запускаем
5. оно скачало 100 файлов, 4 из которых не такого размера как остальные, это файлы с картинками если есть время, можно посканить 4435430[00-99] , т.е. след. СОТНЮ
Вопрос/Ответ:
-1.Могу ли я найти документы определенного человека?
-2.Можешь, но для это придется вручную чекать 9 цифр, что займет уйму времени и не факт, что документы у жертвы вообще есть.
еще CURL СОЛУШЕН от дискорд-конфы:
http://rgho.st/87LGlGHcK
универсальная программа для Linux и Windows
не требует авторизации, гоняет рандомных людей, гоняет доки конкретного пользователя
если будут ошибки, то качаем Cookie Export на лису или cookies.txt на хром и кидаем в папку с прогой
http://rgho.st/8JD94nXHb [ DocsMiner ]
подробная инструкция Докс Майнера:
1. Качаем Java если нет.
2. Качаем плагины cookies.txt для хрома и Export Cookies для лисы (не обязательно, но у некоторых без этого не работает).
3. Экспортируем в файл cookies.txt и сохраняем в папке с программой.
4. Тестируем программу запустив DocsMinerTest и написав doc452578610_452200429.
5. Смотрим в папку Docs. Там должна появится картинка.
6. Запускаем поиск по ID или общий поиск. Соответствующие файлы.
Также доступна функция выкачки доков из поиска
Допустим заходишь в https://vk.com/docs и пишешь IMG, тебе дает результат, но тебе надо все просматривать и ручками качать
Модуль DocsMinerSearch делает это автоматический, а там уже разбирайся нравятся тебе эти доки или нет
Работы по улучшению ДоксМайнера ведутся, пишите жалобы\пожелания по следующим адресам телеграма: @Netlez @zakukan @Az0955565 @wannabedead
все эти секреты были взяты из хакерской дискорд-конфы:
https://discord.gg/47tbYyb
она была создана с целью находить секреты сайтов и использовать их на благо анона
присоединяйся если знаешь код или хочешь получить полезные инструменты от наших анонов
сейчас идут обсуждения того, как доставать личные фотографии из других соцсетей
не стесняйся, мы будем тебе рады, особенно если у тебя есть идеи где и что искать*

Запустил я его, манки выдает циферку 1 рядом со своим значком. Чего я делою нетак?
цифры пиши ггммдд или ддммгг допустим


обнови страницу
блять..
обнови страницу
обнови страницу
Охуеено, вышел в свои доки

ухххх блять
ну ебана, чтоб скрипт начал отображать страницу как галерею, надо обновить
Какая у него пиздатая бровь. ЗДОРОВАЯ СУКА!





Бамп, пока за пивом сгоняю



Бамп
















Как пользоваться этими масками ?





Почему антоны находят годноту, а у меня только ебанина типа пкрлтд
нада иметь терпение
нахожу только хуи


с хуев все начинается, потом товары на авито, а потом нет-нет и годнота

>нахожу только хуи






максимум, что нашёл - вот эту дряблую жепу


Это какая-то кушетка у кадавров штоле?








Закупился, продолжим
Бамп
Че пачаны? Деанон?
Вот, кстати, мне кажется, что это нихуя не домашние фото, а в каком-то косметическом кабинете чтоли. Может у неё даже и муж есть.








Просил же авакода в своей шапке...
Не качайте, там вишмастер.
Тогда вот инструкция к документ треду:
Эта инструкция собрана по крупицам анонов и призвана помочь всем тем, кто не знает как скачивать личные документы из вк.
Часто возникает один вопрос.
Можно ли скачивать личные документы конкретного пользователя вк?
Да, можно и нужно. Читай подробнее инструкцию и поймешь как это сделать.
==============
ДЕЛАЕМ РУЧКАМИ
==============
1) Заходим на vk.com/docs
2) Вводим в поиске или дату (20161224) или стандартный префикс для фото(DCIM, SRC, SCAN, IMG, gifpal, picachoo и тд. SAM DSCN img_ gifme topgifme)
3) Просматриваем найденное
4) Находим годноту и кидаем в тред
5) PROFIT!
- FAQ : Как узнать id человека по найденному документу?
Адрес ссылки: doc386641432_439078355 id - 386641432
- ИТАК! Учу анонов по поводу поиска moar доков понравившейся вам жертвы:
Пример: Вот видите, тот, кому я отвечаю, запостил две ссылки на тетю. Видите, да? Так вот. https://vk.com/doc334129431_443359124 Видите, что последние цифры рядышком? 124. Надеюсь, мозги заработали ваши? Теперь пишите 125 и так далее или же 123. В общем, добавляйте либо +1 либо -1 к окончанию, добавляйте и проверяйте. -
Объясняю блядь еще раз. Заходишь вконтакт. Пишешь радномные цифры вк.ком/doc71383259_279208233
Если годнота, то кидаешь в тред, если нет то другой рандом вк.ком/doc71385459_219208233
Поясняю особенно подробно
вк.ком/doc1111111_2222222
1111111 - это id пользователя
2222222 - это номер файла
Таким образом можно брутить файлы одного человека. Скрипт делает именно это. Для венды пилить лень, для линухи смотрим шапку.
Рандом это очень сложнааа, потому палю еще один способ.
Заходишь на https://vk.com/docs
Пишешь JPG или GIF.
Дебе выдает фотографии рандомных людей
Среди фотографий попадаются лютые вины
Присматривайтесь к названиям годноты. Это может быть IMGTRIKA01343.JPG какой-то фапабельной тни из какого-то говнофотошопа. Потому пишем IMGTRIKA и находим похожий фап-контент.
Пример полученной ссылки:
https://vk.com/doc1111111_222222222
Чекайте цифры на месте единиц и пишите их вместо цифр после id
( например vpashe.ком/id1111111)
Сохранил давно, проверьте)
На странице под концом списка есть кнопка "Показать ещё", но она почему-то по умолчанию скрыта. Надо через "Исследовать элемент" убрать у неё атрибут style = "display: none;" и дальше просто на неё нажимать. То есть : 1. Создать закладку (на панели браузера) 2. В поле ввода урла вставляем javascript:(function()%7Ba%3Ddocument.getElementById(%22docs_search_more%22).style%3B%20a.display%3D%22block%22%3B%20a.visibility%3D%22visible%22%7D)() 3. Когда вводим поиск на вк-докс, нажимаем кнопку и у нас теперь СКРОЛИТТТЦА!1 -
У кого вытекают глаза смотреть на маленькие картинки при поиске
в коде сделай поиск по слову "docs_search_more" выдели его мышкой и справа сними галочку с блока "display: none;" 1) в коде сделай поиск по слову "docs_item_thumb" выдели его мышкой и справа сними галочку с блоков "width" и "height" 2) потом в коде сделай поиск по слову "docs_item_thumb_img" выдели его мышкой и справа сними галочку с блоков "max-height" и "*height"
===================
ДЕЛАЕМ ИНСТРУМЕНТОМ
===================
https://radiokot.com.ua/vkdocs парсер на питоне, посоны говорят что ворует данные
http://rghost.ru/52243464 какой-то десктопный парсер, посоны говорят что нерабочий
http://poiskvk.org возможно интим уже есть там, но я ни рдин раз не нашел
http://scotobaza.org запрещен в рахе и работает только под определенными проксями
еще парсер на питоне:
https://pastebin.com/xVVxwtAm
Принимаются три аргумента, например
foo.py id_цели от до
Ну, значца, качаешь питон
https://www.python.org/downloads/release/python-363/
Сохраняешь скрипт, называешь doc.py например
Запускаешь cmd если возникнут проблемы при записи в файл, запускай от имени администратора и там прописываешь
cd путь_к_папке_с_файлом
cd C:\Users\анон\Desktop
После пишешь:
python имя_файла id_цели число_от число_до
python doc.py 278962009 449286300 449286399
Число от и после обычно начинается с 20000000 до 50000000
Файлик с найденными ссылками по дефолту C:\doc.txt
Так же можно попробовать брут по рандомным числам.
Последние строчки заменить на:
#brute(sys.argv[1], sys.argv[2], sys.argv[3])
forcerandom(sys.argv[1])
это bash-скрипты под Linux:
код качалки http://pastebin.com/EZPhDWrx
код чистилки http://pastebin.com/2cPRY47D
1.sh 200005 300000 300100
Вывод
doc200005_300000
doc200005_300001
doc200005_300002
doc200005_300003
...
doc200005_300100
Все документы хранятся в папках от 0 до 10
Запускаешь 1.sh ИД_ПОЛЬЗОВАТЕЛЯ ФОТКИ_С ФОТКИ_ДО
1.sh 111111 222222 222922
Запускаешь второй 2.sh docs.txt
Он проверяет все айдишники доков, каких доков и сохраняет в docs.txt ссылки на все найденые документы пользователей и удаляет мусор.
через CURL СОЛУШН:
1. Качаем curl: http://www.paehl.com/open_source/?download=curl_752_1_ssl.zip
2. Создаем на диске D, папку vk, закидываем туда curl.exe, создаем go.bat, редактируем
3. Вставляем curl -k https://vk.com/doc341219317_4436533[00-99] -o #1.html
4. сохраняем.
5. запускаем, сортируем файлы по размеру, те которые отличаются - имеют картинки, даблклик и в браузере картинка.
6. Чтобы добавить новое урл, нужно заменить старый. (работаем только в батнике)
7. Можно задавать диапазоны хоть 1234567[0-9], хоть 123[00000-99999], хоть аллаха
8. кому лень делать - залил на ргхост: http://rgho.st/68l4fhNn6
9. скорость большая, можно ебашить задержку через команды курла
10. А теперь можно и пивка
1. качаешь http://rgho.st/68l4fhNn6
2. открываешь go.bat
3. у тебя урл https://vk.com/doc77887170_443542988, значит попробуем curl -k https://vk.com/doc77887170_4435429[00-99] -o #1.html (перебор по последним двум цифрам)
4. сохраняем, запускаем
5. оно скачало 100 файлов, 4 из которых не такого размера как остальные, это файлы с картинками если есть время, можно посканить 4435430[00-99] , т.е. след. СОТНЮ
Вопрос/Ответ:
-1.Могу ли я найти документы определенного человека?
-2.Можешь, но для это придется вручную чекать 9 цифр, что займет уйму времени и не факт, что документы у жертвы вообще есть.
еще CURL СОЛУШЕН от дискорд-конфы:
http://rgho.st/87LGlGHcK
универсальная программа для Linux и Windows
не требует авторизации, гоняет рандомных людей, гоняет доки конкретного пользователя
если будут ошибки, то качаем Cookie Export на лису или cookies.txt на хром и кидаем в папку с прогой
https://fex.net/get/559100946109/110826476 [ DocsMiner ]
подробная инструкция DocsMiner:
1. Качаем Java если нет.
2. Качаем плагины cookies.txt для хрома и Export Cookies для лисы (не обязательно, но у некоторых без этого не работает).
3. Экспортируем в файл cookies.txt и сохраняем в папке с программой.
4. Тестируем программу запустив DocsMinerTest и написав doc452578610_452200429.
5. Смотрим в папку Docs. Там должна появится картинка.
6. Запускаем поиск по ID или общий поиск. Соответствующие файлы.
Также доступна функция выкачки доков из поиска
Допустим заходишь в https://vk.com/docs и пишешь IMG, тебе дает результат, но тебе надо все просматривать и ручками качать
Модуль DocsMinerSearch делает это автоматический, а там уже разбирайся нравятся тебе эти доки или нет
Работы по улучшению DocsMiner ведутся, пишите жалобы\пожелания по следующим адресам телеграма: @Netlez @zakukan @Az0955565 @wannabedead
все эти секреты были взяты из дискорд-конфы:
https://discord.gg/47tbYyb
она была создана с целью находить секреты сайтов и использовать их на благо анона
присоединяйся если знаешь код или хочешь получить полезные инструменты от наших анонов
сейчас идут обсуждения того, как доставать личные фотографии из других соцсетей
не стесняйся, мы будем тебе рады, особенно если у тебя есть идеи где и что искать
Ее взгяд и поза говорят что эти фотки далеко не длятак всех
Аноны ебаште деанон







Спасибо, анончик :3

Есть много с этой... Раньше травил ее, остались только контакты матушки.
Да я не читал тред плиз, не бей только







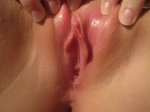
Вообще, особого выхлопа какого то со скрипта курловского нет 2-3 фотки если повезет, котопые встретятся в поиске чуть ниже или черещ день-два, весь массив чекать не пробовал максимум 5 последних знаков, но тож такое, 000-999 находит тож самое как правило
Вообще, особого выхлопа какого то со скрипта курловского нет 2-3 фотки если повезет, котопые встретятся в поиске чуть ниже или черещ день-два, весь массив чекать не пробовал максимум 5 последних знаков, но тож такое, 000-999 находит тож самое как правило





















находил эту тоже










хуй

>Сап мой любимый бредач с ракалом и анончиками. Предлагаю docvk - thread. В чём суть, открываем вдруку, там в документы и ищем по рандом маске, то что держат у себя ракалы в документах.
Знаете, как определить, что ты уже старик?
Просто и без задней мысли читаешь ОП-пост на харкаче трижды и все равно нихуя не понимаешь ни слова.









Верно.
И вот тут я нихуя не понял...
Бля, как вы находите такие фото? В смысле, они же должны быть в документах, а такие фотки обычно в ЛС кидают.

если захотеть то можно отправить её как документ.
Смотрите, что нашел. Она же еще малолетка, но
https://vk.com/doc156509800_448347943
https://vk.com/mirha?z=albums156509800

Находит очень мало результатов, а дальше не ищет. Как фиксить?

Открываешь пустую вкладку в браузере, вставляешь туда:
javascript:(function()%7Ba%3Ddocument.getElementById(%22docs_search_more%22).style%3B%20a.display%3D%22block%22%3B%20a.visibility%3D%22visible%22%7D)()
всё

У сочинского адвоката Виктора Коварыкова фотка тни, явно не дочь и не жена. Среди доступных его фоток её нет.


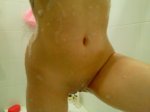


У меня от лика брат здох, пишу с его яиц
может нечяанно тыкнул, листая новостную ленту вк на своем айфончике. я у себя постоянно нахожу уйму лайкнутой порнухи и скачаных доков



Ебать, тут даже такое есть. Люди практикуют, интересуются


Вместе с аватарками их документы весело выходят
Vk.com/wedma_ja
Кто может эту прочекать ? У самого возможности нет.
Кто может эту прочекать ? У самого возможности нет.

Как ты это себе представляешь
цопэ
В прошлом треде какой то анон писал, что можно чекнуть доки конкретного человека. У меня комп не запускается, потому прошу помощи у добрейших о/b/итателей.









Ты стал тупым или родился?
Это пиздец медленно. Я бы тебе помог, но комп занят профилем одноклассницы
Я хз тогда как это делать, кроме как подбором номера дока, бамп
галка ёбана
хорошо пивки идёт
Вот пиздец вы тупые. Выше блять пять раз писали как делать перебор автоматом. Я нихуя не шарю, тупой, и то разобрался




АП что-ли.

Как будто большую лягуху ебет.
Как будто что-то плохое


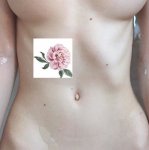

Удвоил, всегда лягух ибу
И пенту люблю проёбывать...


>Смотрим в папку Docs. Там должна появится картинка.
Папка пуста, в чем трабл? Ошибок джавы нет
Хз в чем дело, даже если ссылки не ведут на документ то curl скачивает страницу, попробуй еще раз строго по гайду сделать. Я юзал это

@echo off
goto start
rem начало жи есть :start
:start
setlocal EnableDelayedExpansion
rem переход в текущую директорию
cd %CD%
rem курлом пытаемся скачать диапазон ссылок на доки, с ограничением в 4000 байт (было замечено что пустые страницы весят 15кб)
curl --max-filesize 4000 -k https://vk.com/doc160823520_452126[000-999] -o #1.html
rem ищем все скачанные файлы с расширением .html, ищем там ссылку на фото и качаем по этой ссылке, выписываем ссылку в файл лога с датой
for /f f in ('dir /b .html') do FOR /f skip^=109^ tokens^=2^ delims^=^" a in (f) do curl -k a -O | echo a >>log.txt
rem избавляем файл от мусора в расширении
for A IN (.jpg*) DO ren "A" "~nA%.jpg"
rem удаляем хтмл файлы
такой батник курла юзаю, потому что с удалением хтмл нигде ничо не остается и файла log.txt нет, а так - хтмлки на найденныее файлы
goto start
rem начало жи есть :start
:start
setlocal EnableDelayedExpansion
rem переход в текущую директорию
cd %CD%
rem курлом пытаемся скачать диапазон ссылок на доки, с ограничением в 4000 байт (было замечено что пустые страницы весят 15кб)
curl --max-filesize 4000 -k https://vk.com/doc160823520_452126[000-999] -o #1.html
rem ищем все скачанные файлы с расширением .html, ищем там ссылку на фото и качаем по этой ссылке, выписываем ссылку в файл лога с датой
for /f f in ('dir /b .html') do FOR /f skip^=109^ tokens^=2^ delims^=^" a in (f) do curl -k a -O | echo a >>log.txt
rem избавляем файл от мусора в расширении
for A IN (.jpg*) DO ren "A" "~nA%.jpg"
rem удаляем хтмл файлы
такой батник курла юзаю, потому что с удалением хтмл нигде ничо не остается и файла log.txt нет, а так - хтмлки на найденныее файлы
Кнопка через JavaScript не работает, что делать? Вроде сделал закладку с URL этим. листаю до конца, есть кнопка "показать ещё", но она не прожимается(Толку от неё нету)


мур, сладкий


акаунт удален
Алсо нашел какой-то архив на 20 метров, проверьте
в поиске VK.COM/HIDFOL.rar
в поиске VK.COM/HIDFOL.rar
е
Ух какая горячая мамка. Я хотеть быть её сыночкой. Будил бы её каждое утро на работу язычком


сука малолетняя смешариков смотрит мда

aheago





бамп
Что там было?

Анон, объясни тупому, можно ли по одному айди найти все фото?
прям все все - точно нет, ток те что загружены как документы, при условии что в настройках не стоит галочка о приватности
ну плюс еще времени дохуя потому что это тупо подбором придется проверять хуеву гору ссылок
смешно


шакал

познал бы




Ты бы и собаку познал




А что по ЦП?
Обьясните, это находит только то что в документах, или еще все что юзер шлет?
Вбил, листаю уже 15 минут, даже сисек нет, одна хуета
ЧЯДНТ?
ЧЯДНТ?
Нашел Бабко, и случайно скачал с вк.. теперь мне пизда..
А что ты вбил?
Я, например, вбиваю DSC. Типа от нормальных фотиков, на которые делаются фотосессии с телочками. А ты, наверное, вбиваешь какую-нибудь хуйню с нокий
Вбиваю как ОП по дате

Найс
Скинь пожалуйста посмотреть



8-летняя девочка с сосками
Я ахуеваю. Новые фотки (если просто вводить DSC) появляются по 3-5 штук
только то что в документах
педофила нашел, вроде
Так увлекло что забыл изначальную цель
Теперь охуеваю с того, что пидорахи не могут в фото
нахуй они покупают зеркалки за дохуя шекелей? чтобы фоткать хуету типа цветов в саду, собак, сраных личинусов? Да еще и фоткать хуево, все размазано и криво блдяь
Теперь охуеваю с того, что пидорахи не могут в фото
нахуй они покупают зеркалки за дохуя шекелей? чтобы фоткать хуету типа цветов в саду, собак, сраных личинусов? Да еще и фоткать хуево, все размазано и криво блдяь
Да не говори, столы какие-то, ручки от кастрюли, коляски с жигулями
https://vk.com/doc319354263_414535165
У этого чувака, видимо, очень много документов, постоянно на него натыкаюсь
У этого чувака, видимо, очень много документов, постоянно на него натыкаюсь
Так да
Ебать, крышки от кастрюли в саду в 4к, рашка эдишн
спешите видеть
как им пользоваться?
Я один кроме своей голой тян ничего не фотаю?
побольше бы таких людей)




Как через Content Downloader отсеять ссылки на документы одного пользователя? И тупо тыкать на ссылку и палить документ кента. Есть ссылка ( http://vk.com/docXXXXXXXX_ YYYYYYYY), и что бы он отсеял номер документа(Y) и я палил.







Вот моя добыча. Я успешен?

Соуса 3-4 нет?

22



Поясните. Какие фотографии сохраняются в doc? Сам попробовал глянуть свои документы там только png, а как обычные фото туда попадают?




Аноны, а нельзя никак найти документы именно нужной страницы?




Маски:
"dcp#####.jpg" - Kodak, range of 0 to 4000
"dsc#####.jpg" - Nikon, range of 0 to 4000
"dscn####.jpg" - Nikon, range of 0 to 4000
"mvc-###.jpg" - Sony Mavica
"mvc#####.jpg" - Sony Mavica
"P101####.jpg" - Olympus, Using default camera date of 101
"PMDD####.jpg" - Olympus, M is in hex from 1 to c, DD is 01-31
"IMG_###.jpg" - Some other camera
"IMAG####.jpg" - RCA and Samsung
"1##-####.jpg" - Canon 1TH-TH##
"1##-####_IMG.jpg" - Alternate Canon name.
"IMG_####.jpg" - Canon
"_MG_####.jpg" - Canon raw conversion.
"dscf####.jpg" - Fuji Finepix
"pdrm####.jpg" - Toshiba PDR
"IM######.jpg" - HP Photosmart
"EX######.jpg" - HP Photosmart timelapse?
"DC####S.jpg" - Kodak DC-40,50,120 S is (L)arge, (M)eduim, (S)mall.
"pict####.jpg" - Minolta Dimage.
"P#######.JPG" - Kodak DC290.
"MMDD####.JPG" - Casio QV3000 and QV4000.
"YYMDD###.JPG" - Casio QV7000 - M is hex.
"IMGP####.JPG" - Pentax Optio S.
"PANA####.JPG" - Panasonic video camera stills.
"IMG_YYYYMMDD_HHMMSS.JPG" - HTC Desire Z (AKA Tmobile G2).
"Image(##).JPG" - Nokia 3650 camera phone.
"DSCI####.JPG" - Polaroid PDC2070.
DCM
DCIM
Фото там не много всплывает, я искал по дате самого фото, например: 20180609*.jpg
И да анончики, схоронил с идентификатором юзвера. Просьба не траллировать. Вбасываем в нить то что находим\хотелосьбы\понравилось\годнота. Бампаю до первого хейтера, потом уёбываю в закат.