


Анонче, подскажи, можно ли как-то с помощью SD сменить стиль уже готовой картинки? Гайды, которые я находил, подразумевают что ты уже до этого генерил её, и чтобы не проебывать рисовку нужно копировать промпт и сид.
А если это вообще левая картинка? Попытаться описать что на ней и просто надеяться что с низкими Denoising strength и CFG он не напридумывает лишнего?
Да, там даже описалка BLIP встроена для такого. Ну и контролнетом можно обмазаться, от канни до тайлового, в зависимости от того, как близки стили визуально.
Понял, благодарю

Помогите пожалуйста, поиск ничего не выдает.
Как вообще гуглить артефакты тренировок?

Сап, аноны. Обоссыте мне ебало, выебите мать, но только подскажите как мне генерить в заданной палитре цветов? Мне нужны только конкретные цвета в txt2pic, но я вообще не понимаю как добиться этого. HALP
Ты эмбед тренируешь? Лучше смотри на финальный результат, в каком то старом гайде читал что на пробные сэмплы во время тренировки эмбеда лучше не смотреть, там наверное нужно как то настроить генерацию, а то оно скорее всего генерит с пустым промптом.
VAE

Ты эмбед тренируешь?
Да.
>Лучше смотри на финальный результат, в каком то старом гайде читал что на пробные сэмплы во время тренировки эмбеда лучше не смотреть, там наверное нужно как то настроить генерацию, а то оно скорее всего генерит с пустым промптом.
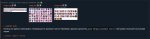
Пик1 результат шаг 1000. (слева промпт (без эмбедда), с права с эмбеддом). В этот раз тренировал на своем ПК.
А скинь его, буду использовать для розовых волос. Не баг а фича так сказать.
Подсказать правда нечего.
Что ты от него получить то в итоге хочешь? Ты же в курсе что он просто те тренит?


https://dropmefiles.com/gQN3Q
>Что ты от него получить то в итоге хочешь?
Стиль одежды и приблизительную внешность.
>Ты же в курсе что он просто те тренит?
Вы смысле не тренит? Нет, не в курсе. Но в пустом промпте он всегда генерирует тянок - чему-то он научился.
Пробовал с черно-белого фотографа треннировать вроде стиль понимает. (у фотографа очень мыльные фотки с сильным DOF что заметно.)Пик1
Вообще нет никаких туториалов про то как нужно интерпретировать результаты тренировки. Еще хоть как понятно с overtrained - это когда оно пихает определенные детали ко всем или большинству генерируемых пикч, а undertrained это когда эмбеддинг оказывает слишком слабое влияние. А все остальное это просто дикий лес.
1 Текущий датасет:
Пик2
2 Embedding Learning rate:
0.05:10, 0.02:20, 0.01:60, 0.005:200, 0.002:500, 0.001:3000, 0.0005
3 Steps:
1000
> Вы смысле не тренит?
Всмысле TE - text encoder тренит, посмотри в пик1 в шапке, это не замена полноценному файнтюну или лоре с новой инфой, просто как лазерная указка что генерить.
> Стиль одежды и приблизительную внешность.
У тебя же там датасет просто рандомных тянок, понятия не имею как ты из такого хочешь стиль одежды или внешность вытянуть, но получится просто что то среднее.
> Вообще нет никаких туториалов про то как нужно интерпретировать результаты тренировки. Еще хоть как понятно с overtrained - это когда оно пихает определенные детали ко всем или большинству генерируемых пикч, а undertrained это когда эмбеддинг оказывает слишком слабое влияние. А все остальное это просто дикий лес.
В гайдах по лорам есть. Вкратце овертрейн отлично будет отличим по артефактам на итоговой картинке, а андертрейн недостаточностью результата на дефолтном весе лоры.

>просто как лазерная указка что генерить.
Это то что мне нужно.
>В гайдах по лорам есть. Вкратце овертрейн отлично будет отличим по артефактам на итоговой картинке, а андертрейн недостаточностью результата на дефолтном весе лоры.
Про овертрейн и андертрейн я понимаю, а как свою проблему загуглить, да и вообщем-то любые с проблемы с тренировкой особенно эмбеддов очень проблемно. В основном "embedding is not woriking" пишут что выходит ошибка в консоли, а у меня цвета добавляются. "Embedding training pink colors" вообще никаких релевантных результатов не выдает.


решил попробовать sdxl, обновил SD, кинул базовую модель и еще какую-то на пробу. При переключении периодически получаю ошибку как на скрине. Чего ему надо? Модельки ведь лежат
Модель не загружается, поэтому webui сбрасывается на предыдущую модель aresmix.
Попробуй перезагрузить автоматик.
Аноны, что лучше при тренировке лоры: 50 изображений и 10 повторений или 100 изображений и 5 повторений?
20-30 изображений и 100 повторений
Оно же пережарится, лол
1 изображение 500 повторений
А если 500 изображений и одно повторение?
Зависит от изображений.
Если у тебя получилось 100 собрать, на которых именно то, что тебе надо, да еще и протэгать всё правильно - будет лучше 100.
Кто-нибудь может сказать, какого черта автоматик генерит разную картинку на одном и том же сиде, если генерить не по одной, а батчами по несколько?
Типа, при Batch count = 4 и Batch size = 1 получаем 4 картинки, потом ставим на том же сиде Batch count = 1 и Batch size = 4 - и получаем уже другие картинки. Похожие, да, но не идентичные.
Как его заставить выдать одну и ту же картинку независимо от этих настроек?
Типа, при Batch count = 4 и Batch size = 1 получаем 4 картинки, потом ставим на том же сиде Batch count = 1 и Batch size = 4 - и получаем уже другие картинки. Похожие, да, но не идентичные.
Как его заставить выдать одну и ту же картинку независимо от этих настроек?
Не подтверждаю, у меня абсолютно одинаковые картинки генерятся.
Version: v1.6.0-78-gd39440bf, xformers: 0.0.21
В итоге первый вариант оказался лучше


1girl, solo focus
Одна батчем в 4, вторая последовательно по 1-й картинке 4 раза.
SDE-карась.
Версия автоматика, правда, старая была.
Обновился - и оно перестало запускаться.
Ожидаемо.
Перекачиваю всё заново, напишу по результатам.
У тебя старые иксформерсы, в которых выходные изображения недетерминированы. В версии 0.0.19 это пофиксили. Либо ты использовал SDP-attention.

Всю папку убил, заново качнул - одна фигня.
>Либо ты использовал SDP-attention.
Где смотреть?
Settings — Optimizations — Cross attention optimization
Стояло на automatic, переставил на x-formers.
Сохраняется.
Отключить надо чтоль? На производительности не скажется?
Отключил - вообще ппц.
Всё медленно, батч 4 не влез в память =)
Что-то фигня какая-то нездоровая.
Попробуй поставить None и посмотреть, что получится.
Смотри выше.
Картинки в батче 2-2 получились заметно более различными, чем с auto\x-formres, кстати.
Странная хуйня, с отключенными оптимизаторами картинки по определению должны быть одинаковыми. А с другими семплерами пробовал, DPM++ 2M Karras например?
Так же проверь не стоит ли галочка "Do not make DPM++ SDE deterministic across different batch sizes" в Settings — Compatibility




В последней версии были затронуты батчи, что позволило гонять по 8 768х768х2 пикч сразу и умещаться в 16гб врам. У меня тоже не генерит идентичные, причём степень отличий ещё и зависит от сэмплера. Пик 1-2 эйлер а, сначала batch size 8, потом batch count 8. 3-4 тоже самое с 2м каррасом. Xformers достаточной версии, чтобы был детерменистик xformers: 0.0.21+c853040.d20230624
Нет, не стояла.
ЧСХ эта галка меняет аутпут даже без батча, в одной картинке, и очень серьезно.
Я это вообще на 1.5.6. чтоль заметил, до того, как обновился.
Т.е. оно давно началось.
Заметил, главное, чисто случайно - никогда раньше батчами не генерил, только последовательно. А тут решил попробовать, и офигел с того, что картинки разные начали вылезать.
На нем тоже.
И на DDIM различия тоже есть, но гораздо менее заметные.
Одна из четырех так вообще идентичная сгенерилась.
Надеюсь в той теме спрашиваю.
Хочу примерно оценить сколько времени /мощности может понадобится для обучения своей модели с нуля под узкоспециализированую не широкую тему изображений
На 11 гигах врам 1 видяхи это совсем космическое время или там неделя/месяц/полгода
Наверно есть ориентиры на других анонов которые себе чот обучали типо аниме тян
Хочу примерно оценить сколько времени /мощности может понадобится для обучения своей модели с нуля под узкоспециализированую не широкую тему изображений
На 11 гигах врам 1 видяхи это совсем космическое время или там неделя/месяц/полгода
Наверно есть ориентиры на других анонов которые себе чот обучали типо аниме тян
>обучения своей модели с нуля
>На 11 гигах врам 1 видяхи
Ебать шиза. Годы чувак, годы, отлетит твоя 1080Ti за это время.
А на 4090 получается полугоды?

> с нуля
Советую передумать, если ты не глава какой-либо мегакорпорации с крупными бюджетами. Представитель StabilityAI говорил, что для обучения SD1 они использовали кластер из 256 видеокарт A100, суммарная длительность обучения была 150k часов (17 лет, если делать на одной A100).
Существующие модели можно дообучать на домашней ПеКе (Dreambooth, надо 24GB VRAM для дообучения SD1.X моделей). Так же возможно обучать свои микромодели под названием Lora и LyCORIS, которые будут взаимодействовать в паре с другой крупной моделью. Подавляющее большинство тех, кто тренирует нейронки для рисования картинок на этой доске, выбирают этот вариант. На твоей видюхе это без проблем можно сделать; обучение лор, как правило, идёт меньше часа.
> для обучения SD1 они использовали кластер из 256 видеокарт A100, суммарная длительность обучения была 150k часов
Индус пиздит как дышит, пытаясь наебать дурачков-инвесторов. CompVis за 3 месяца допилили модель и обучили её. Там даже 1000 часов не было, в просто 150 я ещё поверил бы. Я уж молчу про то что если взять в руки калькулятор и посчитать сколько займёт обучение всего датасета LION Aesthetics на 256хА100 - там меньше трёх суток получится. Даже языковые модели с размером 13В в 20 раз больше параметров чем у первой SD и датасетом под лярд токенов столько не обучают - в пределах нескольких недель на таком количестве А100.
Анонасы, кто-нибудь юзал вундервафлю LoRA_Easy_Training_Scripts?
https://github.com/derrian-distro/LoRA_Easy_Training_Scripts
UI выглядит охуенно удобно, но туториала по тому что именно делают те или иные опции и как вообще использовать это вот всё я не нашёл. Я так понимаю что это всё делалось для людей которые уже пилили лоры, просто собрано в более удобный вид, а я только-только решил вкатиться
Если у кого есть ссыль или время на написание поста с объясненим как юзать, был бы благодарен.
Ну или хз, можете посоветовать альтернативу
https://github.com/derrian-distro/LoRA_Easy_Training_Scripts
UI выглядит охуенно удобно, но туториала по тому что именно делают те или иные опции и как вообще использовать это вот всё я не нашёл. Я так понимаю что это всё делалось для людей которые уже пилили лоры, просто собрано в более удобный вид, а я только-только решил вкатиться
Если у кого есть ссыль или время на написание поста с объясненим как юзать, был бы благодарен.
Ну или хз, можете посоветовать альтернативу
>Индус
Это бангладешец, причем мусульманин. Хз к чему ты это сюда приплел.
Там вообще всплывающие подсказки есть почти на всё, довольно круто сделано.
По поводу чего и куда - в шапке есть туториалы для тренировки лор, там параметры описаны. Названия везде одни и те же, так что прочитай - и понятно будет (почти всё).
я как-то тренировал для себя на фотках одной девушки. по итогу въебал почти сутки на это. больше как-то не хочется самому этим заниматься
> подразумевает что бенгальцы не индусы, когда треть Бенгалии в Индии
Чего, блять?
А они обучали с нуля или дообучали?
Тогда Алекс Шоненков и Бабушкин хохлы, ну а чо, Донецк тоже там был.
Когда научишься индусов от индуистов отличать, тогда пасть и раскрывай.

Анончики, как эта одежда называется? Пилю лору на Наточку, скоро с вами поделюсь.
Если ошибка несколько эпох не уменьшается, значит ли, что датасет или тэги плохо подобраны? lr 1e-4, количество эпох 10, всего шагов 2100.
long sleeve
Куда выложишь?
Спасибо.
На обменник залью. Но пока так себе выходит, положил в долгий ящик. Будет настроение, вернусь.
Аноны, скажите пожалуйста, если я пдросто возьму и перекину папку с SD с одного харда на другой, оно будет работать?
Просто место на диске С заканчивается, а второй хард пустой стоит.
Просто место на диске С заканчивается, а второй хард пустой стоит.
Будет.
На нее хороших фоток хуй да маленько.
мимо тоже пробовал тренить

Тебе нужны фотки с acursednat-исты или с модельного агенства?
Как генерировать нюдсы бывшей?

Хватит на коллаб заходить и пытаться в нем что то запустить.
И да, я вижу, если вы пытаетесь запустить «мой» код в своем блокноте
Дай ссылку
Неплохо, если скинешь пак, будет полезно.
Да хуй знает, иногда выходит нормально, но только меняешь модель или промт, выходит говно.
Спасибо.

Аноны, на мой взгляд существующие 3д модели одежды и волос обычно выглядят всрато, особенно лоупольные. Поэтому генерации с ControlNet Depth получаются крутыми только для порно-картинок без одежды.
А что если начать генерировать голого и лысого персонажа с ControlNet, а потом отключить его и генерировать одежду/волосы уже без? Это вообще в Автоматике1111 возможно сделать?
Алсо, может кто-нибудь видел хорошие туторы по эффективному использованию Depth модели? На ютубе одно говно с персонажами подозрительно похожими на примитивную болванку. Я бы за хороший тутор даже денег не пожалел бы. Хотелось бы научиться ставить своего персонажа в самые разные и сложные позы с помощью 3д модели.
А что если начать генерировать голого и лысого персонажа с ControlNet, а потом отключить его и генерировать одежду/волосы уже без? Это вообще в Автоматике1111 возможно сделать?
Алсо, может кто-нибудь видел хорошие туторы по эффективному использованию Depth модели? На ютубе одно говно с персонажами подозрительно похожими на примитивную болванку. Я бы за хороший тутор даже денег не пожалел бы. Хотелось бы научиться ставить своего персонажа в самые разные и сложные позы с помощью 3д модели.

На каждый отдельный модуль можно задать начальный и конечный процент от общих шагов, где контролнет будет работать.
Плюс то, насколько сильно этот модуль влияет.
Плюс можно подключать больше одного модуля.
Например, задать позу, подключить сверху depth, чтоб он на первых 15% шагов поработал, а потом пусть нейронка сама рисует. Только с болванкой тут врядли что получится, а вот одетого перса - уже нормально может обработать.
Экспериментируй, вообщем.

Спасибо, анон, я и забыл про этот ползунок.
>Только с болванкой тут врядли что получится, а вот одетого перса - уже нормально может обработать.
Проблема в низком качестве моделек одежды. Пикрелейтед, например. Вообще даже плохие 2д рисоваки намного лучше справляются с одеждой чем даже самые крутые 3д модделлеры и системы симуляции ткани. С этим вряд ли что-то можно поделать.
Было бы круто если бы нейросеть дорисовывала одежду сверху на голого персонажа.



Поставь для depth поменьше значимости (или вообще нафиг выруби), подключи сверху canny или lineart, чтоб по контурам больше руководства было.
Плюс tile с низкой силой, типа 0.25 или около того, с быстрым отключением, чисто для контроля цвета.
Ну и денойз повыше, прям в 0.8 или даже 0.9.
Там, где канни ничего не нарисует, нейронка с высоким денойзом будет сама что-то придумывать. В итоге что-то типа пикрила получится.


Плюс не забывай, что картинки контролнета можно редачить.
Вот, например, что получилось, если отключить тайл, закрасить часть контролнетовского файла, и немного пошаманить с промптами.

И чем я только занимаюсь?..
Вот что бывает, когда у человека слишком много свободного времени =)
Крутая штука всё-таки, этот контролнет.
Вот что бывает, когда у человека слишком много свободного времени =)
Крутая штука всё-таки, этот контролнет.



Добавьте в шапку смешивание моделей.
В крайнем случае, можно, хотя бы, добавить ссылку на гайд:
https://rentry.org/BlockMergeExplained
У тебя чисто по скриншоту 3д-модели получилось лучше чем у автора пикчи, который и Depth карту рендерил и OpenPose вроде тоже.
Забавно, может быть в самом деле для аниме, где преимущественно плоский стиль, canny будет лучше работать чем depth.
>если отключить тайл
Что за тайл?
>закрасить часть контролнетовского файла
Если тебе одну картинку нужно, то норм так лицо стирать. Если больше, то каждый раз разное лицо будет небось.
Теоретически, можно натренировать лору на лицо какого-нибудь персонажа по набору 2д картинок и тогда будет норм. Это должно будет помочь с типичными косяками 3д-аниме, когда 3д модели в профиль выглядят странно.
Анон могу ли я обучить нейросеть генерить контент для себя с моей бывшей, она была вебкам моделью и в целом онлифанс девочкой ?
Кал дабы всё. Как быть то. Платным вроде тоже нельзя



>Забавно, может быть в самом деле для аниме, где преимущественно плоский стиль, canny будет лучше работать чем depth.
Оно и на реалистиках хорошо работает.
Но там, правда, лайнарт модуль должен лучше себя показывать, он не настолько жестко на контуры давит, больше свободы для интерпретации дает.
>Что за тайл?
Модуль контролнета tile. Много где полезен - в и2и или в т2и для задачи цветов и общей композиции, при многотайловом апскейле с полным промптом для уменьшения галлюцинаций, при использовании мультидиффужн, и хз где еще. Работает как референсная картинка, короче, не позволяет ИИ сильно далеко от входящих данных отклоняться.
>Теоретически, можно натренировать лору на лицо какого-нибудь персонажа по набору 2д картинок и тогда будет норм.
А можно просто рулетку подольше покрутить, что-то похожее рано или поздно срендерится. Если, конечно, там не что-то прям шибко специфичное.




Можешь.
Если качественных фоток нужное количество насобираешь.
Гайды на тренировку лор в шапке лежат.
Есть еще модули, которые могут на тело от ИИ или из интернета лицо твоей бывшей налепить, тут даже тренировка не нужна.
просто покажи что ты хочешь сделать


Тренькнул на своем старом датасете новой пердолькой, лично мне результат нравится. Правда, не юзаю абсолютный реализм, сижу на дримшейпере или чем-нибудь типа epic25d. Смотри, может, тоже пригодится.
https://www.upload.ee/download/15694277/f1cb26dbdd671d8d6c4a/notcursednat.safetensors
Почему не загрузишь модель на цивитай?
Не умею и мне лень.
А там не ЗОБАНЯТ за такое? А то натренировать ЛоРЫ на всяких камвхор по слитым фоткам и пустить их с помощью ИИ в тираж - это вполне себе легко и вызовет просто ядерное полыхание пуканов и у модели, и у её пиздолизов, которые за тоже самое денег отваливали.
Максимум удалить могут. И то если персона, на которую лора натренена, пожалуется.
Ну, насколько я помню, и если у них там ничего не поменялось с тех пор.
Персоне может и похуй будет - даже лучше - дополнительная реклама НАСТОЯЩИХ фотачек. Но вот армию боевых куколдов никто не отменял.
Сап технач, есть ебаный вопрос. Посравнивал бенчи своей 4080 с другими и чет какое-то говно у меня. В 512x512 в 1 батч на ейлере максимум что видел 12 it/s в SD.Next, в обычном вебхуе последнем не выше 8 it/s, а на хайрез проходе просто пиздец, 1-1.5 it's. Без токен паддингов и прочей хуйни, дефолт конфиг. У всех 15-20+ а то и 25, а у меня насрано. Нихуя не пойму в чем дело. Может кто подскажет куда копать?
Либы torch:2.0.1+cu118 Autocast half xformers:0.0.20
device:NVIDIA GeForce RTX 4080 (1) (compute_37) (8, 9) cuda:11.8 cudnn:8700 driver:536.67 16GB, проц 5800x
Либы torch:2.0.1+cu118 Autocast half xformers:0.0.20
device:NVIDIA GeForce RTX 4080 (1) (compute_37) (8, 9) cuda:11.8 cudnn:8700 driver:536.67 16GB, проц 5800x
Попробуй sdp вместо xformers.
Скачай свежую версию cudnn и подмени библиотеки в торче.
Webui, надеюсь, запускаешь без всяких no-half и no-half-vae?
На sdp ещё хуже в среднем.
cudnn и прочее подрочить попробую, но сомневаюсь что толку будет.
>без всяких no-half и no-half-vae?
Офк.
в диспетчере задач нагрузку на GPU и VRAM во время генерации смотрел? ничего необычного?
Ничего, всё чисто.
>cudnn и подмени библиотеки в торче
Где оно там лежит? Забыл чёт.
stable-diffusion-webui\venv\Lib\site-packages\torch\lib\
Файлы cudnn64_8.dll, cudnn_adv_train64_8.dll, cudnn_cnn_train64_8.dll, cudnn_ops_train64_8.dll, cudnn_adv_infer64_8.dll, cudnn_cnn_infer64_8.dll, cudnn_ops_infer64_8.dll нужно подменить.

Спасиб. Вроде чуть получше стало, но один хер выше 17its в моменте не поднимается. Но хоть что-то.
И да, еще посмотри чтобы Hardware Accelerated GPU Scheduling (Планирование графического процессора с аппаратным ускорением) было отключено в настройках винды.

Вот оно чё блять оказывается. Ебать, спасибо за помощь, анон, инфу хуй нагуглишь сам.
А как быть тем, у кого таких настроек и вовсе нет?
Значит его тупо нет в твоей винде, не беспокойся.
>Webui, надеюсь, запускаешь без всяких no-half и no-half-vae?
Так оно на какие-то десятые доли процента вроде тормозит, не критично вообще, не?
У меня с ним на 4080 25its на настройках как у анона рядом.
>У меня с ним на 4080 25its на настройках как у анона рядом.
Вот какого хуя у меня после выключения шедулинга и с последними либами максимум 20its и это на разогнанной видяхе, куда ещё 5 проебались. Или в общем конфиге пекарни дело, или какие-то приколы вебуя.
Проц тут тоже влияет, насколько я помню.
Дрова еще. НВидия там какие-то оптимизоны периодически выкатывает, попробуй обновиться.
cudnn-файлы я, кажется, в этот раз не ставил отдельно именно для автоматика. Только для кохай-вебуя для лор.
Чому у меня получается либо лицо фотографичное, но портрет на полтела, либо full body с обувью, но лицо по пизде?
Deliberate 3.
Restore face стоит.
Deliberate 3.
Restore face стоит.
>Restore face стоит.
Убери. Только хуже делает.
>либо full body с обувью, но лицо по пизде?
А ты прикинь, какой процент картинки занимает лицо на "портретной" картинке, и на "фуллбоди". Нейронке просто разрешения не хватает, чтоб его нормально детализировать.
Отправляй картинку в инпэинт, и улучшай лицо там. Гайд с правильными настройками легко загуглишь.
>НВидия там какие-то оптимизоны периодически выкатывает
Скорее деоптимизоны, лол.
>Отправляй картинку в инпэинт, и улучшай лицо там.
Или Adetailer, или как его там.
>Или Adetailer, или как его там.
То же самое, только в автоматическом режиме.
Если кучу картинок генеришь - оно лучше подойдет. А вот если какую-то конкретную хочешь - лучше инпэинтом.
какая-то фигня творится, у 4070ti было 18-19 it/s, теперь же 13-14, дрова последние и аппаратный планировщик отключен. пробовал разгон, ничего не меняется. в диспетчере задач показывает загрузку гпу ~70%. с одной стороны и так сойдёт, не минуты уходят как на 1050ti, с другой - раздражает что всё начинает замедляться без видимых причин.

установил SD на manjaro, всё быстро работает, хз что не так с 11 виндой
Подскажите пожалуйста, --opt-sdp-attention и xformers можно вместе использовать?
Нет
А что из этого лучше? Видеокарта 3060
если последняя версия xformers то разницы нет в скорости
Дайте сылку на телеграм групу анона по гугл-колабу.
>Нейронке просто разрешения не хватает
А ты прав. Спасибо.
Достаточно было высоту картинки увеличить на ~60%
Обновляю сейчас пеку и стоит выбор между 3060 12 GB и 3070. Смотрел всякие тесты и по ним 3070 очевидно лучше, но все говорят про нехватку VRAM. Так вот, что лучше взять и для чего в основном нужно больше рамы?
>для чего в основном нужно больше рамы?
От памяти зависит то, насколько большое полотно ты сможешь захайрезить или апскейльнуть.
То есть, если мне важна детализация, то лучше будет 3060 взять?
Да между ними разница минимальна, если 3060 возьмешь с 12гб памяти, ты разве что секунд на 20 дольше будешь свою простыню апскейлить. Плюс если ты юзаешь лорыхуёры, не прунед модель и хочешь ебенить с кастомными апскейлами, которые весят не мало, то их явно легче будет утрамбовать в 12гб. Если тебе для счастья достаточно сгенерить пикчу 512х512 и просто захайрезить её х2 без наворотов и и2и, то тебе можно брать и 3070 (сколько там памяти хоть?).
8 там. Мало.
Очень неудобно с 8, если честно. Постоянно бьешься в верхний лимит памяти. Так что если есть возможность - бери побольше.
Хотя я слушал, что НВидия вроде бы какой-то "оптимизон" на нейронки накатывала, который позволяет еще и оперативку подключать - но ценой значительного снижения скорости.
Хз, как оно точно работает, может аноны с треда подробнее объяснят.
Понял, спасибо
Когда про память читал, писали, что это деоптимизон какой-то, потому что при нехватке памяти начинает жрать оперативку и генерация может замедляться в десятки раз
Вот и я то же самое читал.
Но генерация всё же идет. А без такой "деоптимизации" - вообще бы не шла. Всё-таки прогресс.
Насколько вообще заебись обучать стиль, не трогая текстовую часть модели? Минусы есть?
Если смотреть чисто для работы на дифуззии, основанной на sd1.5 - 3070 будет лучше. Она быстрее а ограничения памяти можно победить через tiled vae. Но если взять sdxl, дополнительные костыли, или, не дай бог, ллм - там 12гигов сильно предпочтительнее и 3060@12 уже будет доминировать.
Так что смотри, если применение узкие и еще игрун или в ближайшем будущем будешь апгрейдить видюху - бери 3070, а так 3060 на 12 сильно лучше и дешевле.
Оно уже есть, просадки дикие но зато возможно делать картинки даже на 1030.
Хуйня на пике. Мало того что у разный моделей разные слои за отрисовку объектов отвечают, так ещё и нигде нет такого чёткого разделения.
узнали, согласны

Для тех, у кого трудности с локальной генерацией. Кастомный UI для генерации манямэ 512x512 через бесплатный веб сервис, чисто чтоб тестировать промпты. Работает достаточно шустро, цензура отсутствует, + возможность сохранения по правому клику. Регаться нигде не требуется.
https://pastebin.com/raw/NYExP1Ux
На сайте есть в наличии и реалистичные модели, но поленился добавлять.
https://pastebin.com/raw/NYExP1Ux
На сайте есть в наличии и реалистичные модели, но поленился добавлять.
Не нужно, когда на цивитаи уже давно прикрутили возможность генерить на моделях прямо там, без скачки. Пока только без хурезфикса.
>на цивитаи
Трут модели, лоры, комментарии, небо и Аллаха.
Всё, чем пользуюсь не терли. Видимо ты педофильское что-то использовал.
Из педофильского я только делиберейт использую.
Он кстати на основен Бстабера сделан, отсюда и педофилия. А бстабер тренировали на сырной пицце. Уровень работы мозга Хача имаджинировал? Надо мразулину на него натравить.
Сгенерируйте, пожалуйста по промпту
wooden fireplace, stove, Scandinavian style, in perspective
Раньше генерил на гугл колабе, т. к. своей видюхи нет, а сейчас приходится просить у вас помощи
Помогите, пожалуйста, если можно, несколько вариантов
> технотред
> ИТТ делимся советами, лайфхаками, наблюдениями, результатами обучения, обсуждаем внутреннее устройство диффузионных моделей, собираем датасеты, решаем проблемы и экспериментируем
Реквесты в других тредах, братишка.
> Сгенерируйте, пожалуйста по промпту
> wooden fireplace, stove, Scandinavian style, in perspective
> Раньше генерил на гугл колабе, т. к. своей видюхи нет, а сейчас приходится просить у вас помощи
> Помогите, пожалуйста, если можно, несколько вариантов
Сорри, не туда запостил
Ну попробуй погенерь там одетых лолек по тегу loli
Твои педофилопроблемы никого не волнуют, съебался в страхе, изврат.никто в здравом уме не использует этот педофильский тэг для педофилов
Я не он, но у меня есть сфв персонаж-лоли, для которой мне нужны спрайты с эмоциями и цг.
Это правда, что начиная с сд 2.0 теперь нельзя генерить детей?
>теперь нельзя генерить детей
Конечно, лично товарищ майор приезжает и пиздит за каждое loli в позитивном промте.
Нормально всё работает даже на сдохле, только голых не делай, а то умрёшь от кринжа.
Короче нашел какой-то гуид на дваче, по всем шагам прошелся, но чет при запуске выходит ошибка по установке торча
RuntimeError: Couldn't install torch.
Command: "E:\StableDiffysion\stable-diffusion-webui\venv\Scripts\python.exe" -m pip install torch==2.0.1 torchvision==0.15.2 --extra-index-url https://download.pytorch.org/whl/cu118
Error code: 1
кто-то сталкивался? Как фиксить? Если я тупо руками его накачу - нихуя не заработает же, потому что не в виртуальной среед ставлю
RuntimeError: Couldn't install torch.
Command: "E:\StableDiffysion\stable-diffusion-webui\venv\Scripts\python.exe" -m pip install torch==2.0.1 torchvision==0.15.2 --extra-index-url https://download.pytorch.org/whl/cu118
Error code: 1
кто-то сталкивался? Как фиксить? Если я тупо руками его накачу - нихуя не заработает же, потому что не в виртуальной среед ставлю
соре мужики - я даун, сначала вкинул, потом пошел гуглить - по итогу помогла вот эта статья - https://stackoverflow.com/questions/73817772/stable-diffusion-couldnt-install-torch-pip-version
обновил pip и удалил папку venv из корневой - по итогу вроде установка пошла
нашел более подходящий тред для своего вопроса
зачем нужен ComfyUI? я работаю с нодовыми редакторами больше 10 лет, и ни разу не встречал настолько бессмысленного инструмента
вижу единственный плюс в том, что процесс более "продакшеновый". можно настраивать узкие сетапы, сохранять их и открывать впоследствии. в вебуи не завезли файлового воркфлоу. в комфи он хотя бы есть, правда всё равно неудобен
сама творческая работа с нейронкой в комфи занимает в 10 раз больше усилий и времени, чем в вебуи
в вебуи: отключил галку HRFix, чтобы быстрее найти интересный сид
в комфи: отсоединяешь четыре сопли, потратив секунд 5
в вебуи: тыкаешь в галку обратно. 1 клик
в комфи: присоединяешь все сопли на место. 4 драгндроп операции
всё делается через переплетение нод... но зачем?
авторы в курсе, что эти переплетения нод в нормальных редакторах схлопываются в подграфы и выставляют наружу интересующие их крутилки со внутренних нод, превращая всё в одну ноду? и да, при этом получатся подобие вебуи. и по сути является функцией
вебуи это аналог гигантского комфи нетворка с вынесенным наружу интерфейсом для удобства... только в комфи нет возможности выносить интерфейс, потому что авторы комфи не знают как работают нодовые редакторы? не знают, зачем нужны функции?
зачем нужен ComfyUI? я работаю с нодовыми редакторами больше 10 лет, и ни разу не встречал настолько бессмысленного инструмента
вижу единственный плюс в том, что процесс более "продакшеновый". можно настраивать узкие сетапы, сохранять их и открывать впоследствии. в вебуи не завезли файлового воркфлоу. в комфи он хотя бы есть, правда всё равно неудобен
сама творческая работа с нейронкой в комфи занимает в 10 раз больше усилий и времени, чем в вебуи
в вебуи: отключил галку HRFix, чтобы быстрее найти интересный сид
в комфи: отсоединяешь четыре сопли, потратив секунд 5
в вебуи: тыкаешь в галку обратно. 1 клик
в комфи: присоединяешь все сопли на место. 4 драгндроп операции
всё делается через переплетение нод... но зачем?
авторы в курсе, что эти переплетения нод в нормальных редакторах схлопываются в подграфы и выставляют наружу интересующие их крутилки со внутренних нод, превращая всё в одну ноду? и да, при этом получатся подобие вебуи. и по сути является функцией
вебуи это аналог гигантского комфи нетворка с вынесенным наружу интерфейсом для удобства... только в комфи нет возможности выносить интерфейс, потому что авторы комфи не знают как работают нодовые редакторы? не знают, зачем нужны функции?
В нормальных нодовых редакторах можно еще "мутить" хоткеем выделенные ноды не нарушая само древо, сродни твоей этой галочки в веб уи. Может и тут есть, прочекай хоткеи
>в комфи: отсоединяешь четыре сопли, потратив секунд 5
Там разве нет какой-нибудь ноды-переключателя?
> Может и тут есть
Есть, конечно.
> ноды-переключателя
Есть, конечно.
Ну так в чём проблема? Настраиваем и не тыкаем 4 сопли.
Как тренировать сетку если у тебя нет видеокартовых мощностей
В калабе.
Смотри. Покупаешь видеокарты, а потом делаешь по инструкции "Как трейнить нейросети, когда у тебя есть компутаторные мощностя".

Народ, вкорячил лора лоадер в комфли юай, и оно начало срать ошибками
RuntimeError: mat1 and mat2 shapes cannot be multiplied (924x2048 and 1280x768)
как говорится, ЧЯДНТ?
RuntimeError: mat1 and mat2 shapes cannot be multiplied (924x2048 and 1280x768)
как говорится, ЧЯДНТ?
Отбой, сам дурак, забыл к рефайнеру присобачить
Аноны, когда использовать регуляризацию при обучении лоры, я так и не разобрался как это работает и поэтому так и не понял в каких случаях её юзать и какие пикчи для регуляризации юзать, а так же в каком количестве, кто то говорил что так можно отделить стилистику от персонажа, но можно более конкретное применение
>в вебуи: отключил галку HRFix, чтобы быстрее найти интересный сид
>в комфи:Mode>Never
Лично для меня это единственный полноценный ГУИ который работает сразу из коробки. С каломатиком уже посидел пока искал оптимальные настройки 6 гб нищеёб и в документации и среди устаревших и среди советов которые не работают на текущей версии. Еще классная ебля с xformers которая тупо, блять, не устанавливается. В итоге А1111 не может даже 2 пикчи 512х512 в батче обработать, уходит OOM, в то время как комфи ебашит 8.
>в то время как комфи ебашит 8.
Я так думаю, это с апдейтами дров НВидии связано, которые теперь научились оперативку подключать, если в видеопамять всё целиком не лезет.
Потому что 8 картинок 512х512 - это 2.1 мегапиксела. В автоматике без этого апдейта на восьми гигах до недавнего времени больше 1.3 не помещалось. Даже с иксформерсами.
Яхз, что там за чудо-оптимизация должна быть, если оно чисто через видеопамять на 6 гигах столько пропускать умудряется.


Это еще в NORMAL_VRAM, в full precision потому что если переполнить память то он переходит в lowvram mode или как там. И нет общая память не используется, как видно во время генерации озу освобождается.
Мне это кажется, или Heun самый лучший сэмплер? (для манямэ 1.5 моделей, на XL не тестировал)
Конечно, он и самый неудобный: более рассыпанная композиция, медленно работает, с ним нужно минимум 50 шагов и выше риск запороть изображение - но в этом и состоит вся суть ИИ для генерации изображений. Это лутбокс, как в мобильных играх - крути ручку, вращай мельницу, тряси дерево. Одна крутая пикча лучше ста посредственных, поэтому разброс в качестве выигрышнее посредственной стабильности.
Еще хороши ancestral сэмплеры, когда делаешь хайрез с низким денойзом. Ancestral означает что он дорабатывает изображение вплоть до 150-го шага, поэтому детали будут годными даже с denoise 0.4 + 4x-ultrasharp.
Конечно, он и самый неудобный: более рассыпанная композиция, медленно работает, с ним нужно минимум 50 шагов и выше риск запороть изображение - но в этом и состоит вся суть ИИ для генерации изображений. Это лутбокс, как в мобильных играх - крути ручку, вращай мельницу, тряси дерево. Одна крутая пикча лучше ста посредственных, поэтому разброс в качестве выигрышнее посредственной стабильности.
Еще хороши ancestral сэмплеры, когда делаешь хайрез с низким денойзом. Ancestral означает что он дорабатывает изображение вплоть до 150-го шага, поэтому детали будут годными даже с denoise 0.4 + 4x-ultrasharp.
Ну т.е. такой лайвхак автоматический, что если видюха не тянет - то комфи в лоу-врам переходит?
Интересно, в автоматике это так же теперь не работает случайно?
Чот сколько не тестил, с моими моделями не получается ничего лучше dpm++ 2m karras на 25 шагах.
> Ancestral означает что он дорабатывает изображение вплоть до 150-го шага
Это у которых "a" в названии? Интересно. Жалко каломатик не умеет раздельный сэмплер на хайресфикс ставить.
> даже с denoise 0.4
Чем больше генерю, тем сильнее скручиваю денойз.

>Жалко каломатик не умеет раздельный сэмплер на хайресфикс ставить.
Умеет.
И даже промпт с негативом умеет.
И чекпоинт менять тоже, прикинь?
В настройках всё устанавливается.
Что за ControlNet Hooked - Time = 61.062315940856934
Раньше такого дерьма не было, чтоб целую минуту ждать приходилось, пока он тайл обработает.
Раньше такого дерьма не было, чтоб целую минуту ждать приходилось, пока он тайл обработает.
Пока писал, он принялся за третий и последующие тайлы и теперь обрабатывает их по пол секунды. Что за херня?
Как видишь, обновляют и улучшают.
С какого калькулятора дифузишь?
Пару месяцев назад пользовался прогой, потом удалил, а сейчас решил скачать обратно. Выдает ошибку, а в чем проблема не понимаю, в программировании не шарю от слова совсем. Как пофиксить и в чем проблема?
Хуясе.
RTX 2060. И да, раньше быстрее было. Что они там улучшили, что дольше стало?
Лень разбирать эту простыню, но очевидно же что тебя провайдер ебет. Включай/отключай впны, днс проверяй.
Моё имхо, лоры - костыльная хуйня (как и всё остальное в SD):
1. Полноценная модель должна знать всё из коробки и уметь в любые стили.
2. Если некий концепт все же слишком нишевый - ИИ должен подхватить его с одного-двух рефов, без какого-либо трейнинга.
>Полноценная модель должна знать всё из коробки
Увы, анусов твоей матери слишком мало в интернете, чтобы модель о нём знала.
Переписал старый гайд по лорам от 1060 анона, актуализировав инфу, кому не похуй, укажите в чем не прав https://rentry.co/2chAI_hard_LoRA_guide
Посаны мне всегда говорили, что коха лох и мёрджить надо супермёржером прям из каломатика.
> укажите в чем не прав
Буквально во всём.
> Суть любой тренировки лоры заключается в попадании в свитспот сразу двух составных частей Stable diffusion модели, Unet и TE.
Невероятная шиза. На SDXL вообще не тренируют текстовый энкодер. На полторашке только в особо тяжёлых случаях, когда нейросеть вообще не знает таких слов. 2/3 поломок лор как раз из-за шизов, тренирующих текстовый энкодер на lr почти как у unet.
Соответственно вся последующая шиза про поломки и подбор эпох на глаз - высер.
> network_dim=network_alpha=64-128
Опять же совет как сделать хуже. При том что рекомендуемая альфа как у кохи, так и у ликориса - 1.0 или меньше. Альфа размером с ранг - ещё одна причина поломок.
> constant (default)
Отвал пизды просто.
> Если есть RTX3000 и выше, оба значения нужно ставить в BF16. FP16 подойдёт для владельцев других карт, но этот формат имеет слишком мало бит на экспоненту и из-за этого в итоговой лоре может получиться очень много нулевых тензоров.
Как будто бред сумасшедшего читаю.
> --noise_offset
> Ужасная заплатка
А альфу ебашить под 64-128 - это конечно же другое, да.
> Normal train
> loss не уменьшается
С такими высерными конфигами другого и не ожидал.
Да и вообще через строчку ересь какая-то. Ты бы хоть это перевёл, а не высерал шизу - https://rentry.org/59xed3
> На SDXL вообще не тренируют текстовый энкодер.
Как же тогда привязать чара к тегу? Ладно ещё стиль, но для перса.
> 2/3 поломок лор как раз из-за шизов, тренирующих текстовый энкодер на lr почти как у unet.
Ну а какое значение ты считаешь нормальным? Сколько не тренил, 1/3 от юнета иногда даже недожаривается, не то что перетрен.
> При том что рекомендуемая альфа как у кохи, так и у ликориса - 1.0 или меньше.
Ещё скажи что ты готов по рекомендациям кохи тренить, у него там как раз был пиздец типо 4е-7 адафактор без те для хл файнтюнов, результатом был вдхл.
> Отвал пизды просто.
А вот это с прошлого гайда скопировал не заметив, надо поправить.
> Как будто бред сумасшедшего читаю.
А ты сам натренеть сначала с одним, потом с другим и сравни, или тебе именно формулировка не понравилась?
> А альфу ебашить под 64-128 - это конечно же другое, да.
Согласен, что для перса этого многовато, но стиль на низкой альфе нихуя не улавливает.
> С такими высерными конфигами другого и не ожидал.
Скинь свой конфиг, я не против узнать как можно лучше.
> https://rentry.org/59xed3
Да, это охуенный гайд, я его читал, но там автор больше фокусится на трене чаров.
Последняя версия супермерджера какая то багнутая кстати, может смерджить поломанную модель.


> к тегу
Чел, в SD frozen clip, т.е. его вообще не тренируют изначально. Если банально по имени персонажа модель рисует любую тянку - значит тестовый энкодер уже понимает о чём идёт речь, надо только научить как рисовать это.
> Ну а какое значение ты считаешь нормальным?
Я тебе уже написал - на SDXL его вообще нельзя тренировать, на полторашке самый минимум или вообще выключить, если как я выше написал работает.
> по рекомендациям кохи
А ты предлагаешь по рекомендациям васянов, даже не понимающих что делают эти параметры? Отсутствие скейла весов - это альфа 1.0. Всё что выше - это костыли ничем не лучше кучи других костылей. Бездумно втыкать костыли куда не надо - это вообще за гранью.
> результатом был вдхл
Результат был закономерный для тренировки ванильной полторашки на рандомном кале с бур, точно такой же результат получали с любым другим способом обучения, потому что проблема в датасете. На SDXL аналогичные результаты получали с датасетом такого же уровня.
> А ты сам натренеть сначала с одним, потом с другим и сравни
От альфы у тебя веса пидорасит, а ты потом удивляешься почему же модель ломается. fp16 всегда лучше по скорости и памяти, а поломок модели вообще никогда не бывает если тренируешь нормально. Особенно учитывая что NaN это в первую очередь про кривые градиенты от идущего вверх loss, поломка весов уже следствие.
> стиль на низкой альфе нихуя не улавливает
И самое лучше что ты придумал - просто скейлить веса до поломки модели? При том что у тебя всякое говно для демпфирования обучения стоит, типа больших батчей/лимита гаммы SNR/weight decay. С loss как пила естественно нихуя не тренируется нормально, тебе только и остаётся скейлить веса и потом на этих волнах высматривать где же изображение поломано меньше. Когда у тебя средний loss идёт вниз без пилы, то и результат стабильный без поломок модели и распидорашивания картинки. Пикрилейтед как loss должен выглядеть, на больших однотипных датасетах вообще как на втором пике.
> Пикрилейтед как loss должен выглядеть, на больших однотипных датасетах вообще как на втором пике
С какими параметрами и что именно тренилось?

Можете пожалуйста мой рисунок улучшить, чтобы реалистично было?
Слизни на фоне Фудзи
Слизни на фоне Фудзи
Он неплох уже как есть, за этим в nai/sd тред с развернутым описанием реквеста.
Понял, спасибо
Брах, чего ругаешься, посоветуй лучше стартовые параметры, чтобы стиль на 1.5 натренить. Я думал с продиджи начать, но не уверен...
мимо


> Чел, в SD frozen clip, т.е. его вообще не тренируют изначально. Если банально по имени персонажа модель рисует любую тянку - значит тестовый энкодер уже понимает о чём идёт речь, надо только научить как рисовать это.
Не помогая тегами, просто вжарив юнет? В чём смысл так делать?
> на SDXL его вообще нельзя тренировать
Чтобы не иметь возможности промптить персонажа? Как просто ты собираешься рисовать чаров на хл, если она их изначально не знает? А разделять как собираешься, исключительно юнетами от лор? Ладно там ещё 1.5 с её наи, в которой есть знания как приблизительно чаров многих рисовать, такую и тренить долго обычно не надо, там и 1/10 хватит для те.
> А ты предлагаешь по рекомендациям васянов, даже не понимающих что делают эти параметры?
Я предлагаю то, что не один раз срабатывало.
> Отсутствие скейла весов - это альфа 1.0.
В гайде, на который ты же ссылаешься:
> This is used to scale weights (the model's actual data) when saving them by multiplying them by (alpha/net dim) and was introduced as a way to prevent rounding errors from zeroing some of the weights.
> Alpha 0 = Alpha 128 = 128/128 = x1
Альфа 1 = отсутствие скейла весов, будет верным, только если дим тоже будет 1.
> От альфы у тебя веса пидорасит, а ты потом удивляешься почему же модель ломается.
Ты про нулевые значения? Ну так они литералли из-за выбранной точности становятся такими.
> fp16 всегда лучше по скорости и памяти, а поломок модели вообще никогда не бывает если тренируешь нормально. Особенно учитывая что NaN это в первую очередь про кривые градиенты от идущего вверх loss, поломка весов уже следствие.
Вот натренил, как ты предлагаешь с 1 альфой и фп16. Не особо то график меняется, NaN'ы в отличии от бф16 присутствуют, 103 штуки. В каком месте это быстрее тоже не понятно, такая же скорость как и всегда.
> И самое лучше что ты придумал - просто скейлить веса до поломки модели? При том что у тебя всякое говно для демпфирования обучения стоит, типа больших батчей/лимита гаммы SNR/weight decay.
Я их наоборот не скейлю, а дампенеры как раз стоят чтобы эта хуйня не сжарилась вусмерть.
> С loss как пила естественно нихуя не тренируется нормально, тебе только и остаётся скейлить веса и потом на этих волнах высматривать где же изображение поломано меньше. Когда у тебя средний loss идёт вниз без пилы, то и результат стабильный без поломок модели и распидорашивания картинки. Пикрилейтед как loss должен выглядеть, на больших однотипных датасетах вообще как на втором пике.
Ты лучше расскажи, что ты делаешь, чтобы лосс стал не бесполезной метрикой.
> В чём смысл так делать?
Чел, я тебе в очередной раз напишу - в SD текстовый энкодер не тренируется, он оригинальный от LAION. Это как раз нет смысла тренировать его. Это текстовая модель, она ничего не рисует, ей не надо знать ничего про то как выглядит твой персонаж. В лорах есть тренировка только как костыль из-за хуёвого CLIP, когда например логические цепочки в промпте, на SDXL уже жирный CLIP и от его тренировки только хуже становится. Даже у кохи об этом написано, чтоб дурачки не пытались его тренировать.
> Альфа 1 = отсутствие скейла весов, будет верным, только если дим тоже будет 1.
Ты только половину понял. У тебя веса сначала умножаются на альфу, тренируются, а потом делятся перед сохранением. При альфе 128 у тебя веса в 128 раз больше, костыль чтоб не округлялись до нуля. Но у тебя из-за этого и колебания значений весов выше.
> лосс стал не бесполезной метрикой
Loss не метрика, по нему градиенты для весов считаются. Если у тебя он идёт вверх - значит тренировка идёт в обратную сторону от референса. Нет забора - нет пережарок и поломанных лор, так же как и NaN никогда не будет, не будет проблем с подрубанием кучи лор, можно будет вес лоры хоть до 2 поднимать и генерация не будет в кашу/шум превращаться.
В душе не ебу что ты там нахуевертил что он у тебя не падает. Если у тебя датасет протеган как попало или текстовый энкодер ломает кривыми тегами, то это запросто может быть причиной пилы вне зависимости от настроек.
Покажи пример как надо делать чтобы было пиздато, чтобы запоминались вайфу, чтобы ухватывался стиль и получался красивый, убывающий на порядки лосс как из учебника. Не общие рассуждения как вы с кохой против дедов тренировали а конкретику. Будем тебе очень благодарны.
> на SDXL уже жирный CLIP и от его тренировки только хуже становится. Даже у кохи об этом написано, чтоб дурачки не пытались его тренировать.
Да я видел. Я только понять не могу как тогда модель должна будет догадаться что чар А это чар А, а чар Б это чар Б, как их потом промптить?
> У тебя веса сначала умножаются на альфу, тренируются, а потом делятся перед сохранением. При альфе 128 у тебя веса в 128 раз больше, костыль чтоб не округлялись до нуля.
Ну ок, но в том же гайде про такое не упоминается, а вот про rounding errors есть, которые бывают только на фп16.
> Но у тебя из-за этого и колебания значений весов выше.
Но я же поставил без колебаний, ты ведь видел конфиги, я менял лишь то, про что ты писал, то бишь альфу и точность, но это не помогло, судя по графикам.
> Loss не метрика, по нему градиенты для весов считаются. Если у тебя он идёт вверх - значит тренировка идёт в обратную сторону от референса. Нет забора - нет пережарок и поломанных лор, так же как и NaN никогда не будет, не будет проблем с подрубанием кучи лор, можно будет вес лоры хоть до 2 поднимать и генерация не будет в кашу/шум превращаться.
> В душе не ебу что ты там нахуевертил что он у тебя не падает. Если у тебя датасет протеган как попало или текстовый энкодер ломает кривыми тегами, то это запросто может быть причиной пилы вне зависимости от настроек.
Ну если я нахуевертил, скидывай хороший, по твоему мнению, конфиг. Потреню без ТЕ вообще, если он так мешает.
> Чел
Маркер долбоеба, дальше не читал
>>
Маркер долбоёба: >, дальше не читал.
Какую модель стоит использовать для тренировки лоры на реального человека?
Чистый SD
Понял, спасибо.

Памахите, можно как-нибудь заюзать апскейлеры из вкладки Extra и с ними Codeformer из командной строки? Из UI не подходит, нужно апскейлить очень много разных файлов батчем, потом удалять, для этого даже вкладка Batch from directory не подходит. Апскейлером пользуюсь Remacri с upscale.wiki. По идее же их должно быть можно как-то запускать с командной строки, если они там в вики без SD лежат. Настройки юзаю как на пикрелейдед. В документации по автоматику не пишут, как их с командной строки можно запустить.
https://www.chub.ai/characters/XanaduMio/sd-chan-60958867/main
ИИ-ассистент для claude, чтобы генерировать промпты
ИИ-ассистент для claude, чтобы генерировать промпты
https://github.com/KohakuBlueleaf/LyCORIS/blob/document/docs/Guidelines.md
Что за algo=full, это просто тренировка чекпонита?
Что за algo=full, это просто тренировка чекпонита?
Чот ебался с этой парашей, ебался, а она так и не запустилась, ошибка сыпет при попытке мёрджа. Что этот реп, что бета. Кто-нибудь пользуется, как оно вообще, когда работает? Может альтернативные какие-нибудь похожие штуки есть?
https://github.com/Xerxemi/sdweb-auto-MBW
https://github.com/Xerxemi/sdweb-auto-MBW

Поясните за AnimateDiff почему оно нормально генерит при разрешении 512х512, но если взять выше, те же 768х768, то видюха отказывается разгоняться и ползет на 1% мощностей.
>Да и вообще через строчку ересь какая-то. Ты бы хоть это перевёл, а не высерал шизу - https://rentry.org/59xed3
Чет попробовал настройки автора с автоматическим ЛР на Prodigy - и какая-то фигня вместо стиля натренилась. Похожесть была, но очень отдаленно. Почти 2000 шагов - мало, чтоль?
Ты сам не видишь что ли что на твоём скрине?
Ладно, я тупой, сравнил ГПУ на арте и щас, когда генерирую 512х512. Разницы нет, но я не понимаю, почему при попытке генерить 768х768, видеокарта начинает работать медленно, бесшумно и генерация замедляется в 100 раз.

> почему
Видеопамять у тебя забивается, ну.
Не хватает объема, переходит в режим low-vram, отчего и замедление.

Анончики, помогите расшифровать что чат-жопа с японского перевела: https://rentry.org/bp87n
В общих чертах как он это делает? Так что ли:
1) Тренерует Лору на скриншотах дефолтного болванчика из Хани Селект.
2) Болванчик-Лору он как-то мержит вместе с требуемой моделью, модель у него под аниме стиль.
3) Тренирует Лору своего персонажа.
В общих чертах как он это делает? Так что ли:
1) Тренерует Лору на скриншотах дефолтного болванчика из Хани Селект.
2) Болванчик-Лору он как-то мержит вместе с требуемой моделью, модель у него под аниме стиль.
3) Тренирует Лору своего персонажа.
Да, можно ещё отдельные части выбирать https://github.com/KohakuBlueleaf/LyCORIS/blob/e4259b870d3354a9615a96be61cb5d07455c58ea/lycoris/config.py
Всё так, про нюансы только хз, не пробовал
Понял-принял, благодарю.
Можно и без хани-селекта обойтись было.
Перс же примитивный, промптом задается.
А если он промптом задается - тупо генеришь штук 300 картинок, из них отбираешь сколько тебе надо, где чар на себя похож, апскейлишь, инпэнтишь лицо (если надо), и на этих картинках сразу и тренируешь.
>можно ещё отдельные части выбирать
Отдельные части тела? Типа он только на лицо обучал, а можно было тело полностью?
Алсо, кто-нибудь вообще пробовал мержить Лору с моделью? Какие скрипты для этого нужно использовать?
>Перс же примитивный, промптом задается.
В целом да, но промптом ты не сможешь тонкие нюансы прописать. Типа размеры, формы и разреза глаз, расположения прядей волос и т.д.
Хотя сейчас вроде бы можно такую мелочь с помощью Ip-adapter модели пофиксить.
>А если он промптом задается - тупо генеришь штук 300 картинок, из них отбираешь сколько тебе надо, где чар на себя похож, апскейлишь, инпэнтишь лицо (если надо), и на этих картинках сразу и тренируешь.
Это дохуя работы. Для тренировки сколько картинок надо? штук 10 минимум. Их из этой кучи достать нужно, а потом еще выдрачивать каждую до идеала.
А тут он просто скриншотов наделал за несколько минут и все, можно обучать.
> Отдельные части тела?
Отдельные части сд модели
> Алсо, кто-нибудь вообще пробовал мержить Лору с моделью?
С сд-скриптс прямо скрипты лежат для мерджа. Можешь вот этот гуй ещё юзать, он и локоны умеет примердживать https://github.com/bmaltais/kohya_ss
>ты не сможешь тонкие нюансы прописать.
Вот для этого и надо генерить много пикчей. Выбираешь то, что попало в образ - и норм.
>выдрачивать каждую до идеала.
Зачем? Вообще не надо. Главное, чтоб образ был ухвачен, и особых/повторяющихся косяков не было.
>А тут он просто скриншотов наделал за несколько минут и все, можно обучать.
Он сначала поставил хани-селект, сделал дизайн персонажа, наделал с ним скриншотов, обучил на них лору, смерджил с моделью, нагенерил картинок с персом на таком мердже, и уже на них тренировал финал.
Это далеко не несколько минут =)
По факту весь первый этап с хани-селектом и лорой на нем - это чтоб модель более стабильно тебе сравнительно похожего персонажа выдавала. И то там с попаданием в образ не очень получилось.
Почему и говорю - там, где можно чисто промптом справиться - такой изврат не нужен.
Ещё вопросец по AnimateDiff.
Если я использую больше 75 токенов в позитивном промпте, то это приводит к тому, что AnimateDiff не способен сохранять ту же композицию, больше чем на 16 кадров. Кто-нибудь нашел решение?
Если я использую больше 75 токенов в позитивном промпте, то это приводит к тому, что AnimateDiff не способен сохранять ту же композицию, больше чем на 16 кадров. Кто-нибудь нашел решение?
> Он сначала поставил хани-селект, сделал дизайн персонажа, наделал с ним скриншотов, обучил на них лору, смерджил с моделью, нагенерил картинок с персом на таком мердже, и уже на них тренировал финал.
Ты последовательность перепутал. Здесь смысл что он от стиля избавлялся, он сделал рандомного персонажа и натренил с ним, чтобы стиль впитать и примерджить к модели и уже с этого тренил, того которого хотел, чтобы стиль 3дшный не подхватывало.
Есть какие-то подвижки по дистилляции XL моделей? Чекпойнты по 12 с копейками гигов это чет как-то дохуя.
Как в теории допилить SD до уровня Dall-e 3?
Кодировщик текста чрезвычайно велик (вероятно, он мог бы даже использовать в качестве входных данных встраивания размера GPT3.5). Для т екстового кодировщика SD 1.5 используется 123M параметров, GPT3 — 150B параметров.
Нет ничего, что Stability AI не смогут сделать, просто такие вещи не будут работать на потребительском оборудовании, за исключением, возможно, загрузки/выгрузки кодировщика текста при каждом изменении промпта и кэширования после промпта. Даже в этом случае использование огромного встраивания может увеличить размер Unet без улучшения качества изображения.
С точки зрения качества изображения и того, как проработаны руки или согласованность изображения (освещение, тени), Unet (или что-то еще, что используется для обработки изображений) вовсе не является революционным по сравнению с SDXL или MJ.
Кодировщик текста чрезвычайно велик (вероятно, он мог бы даже использовать в качестве входных данных встраивания размера GPT3.5). Для т екстового кодировщика SD 1.5 используется 123M параметров, GPT3 — 150B параметров.
Нет ничего, что Stability AI не смогут сделать, просто такие вещи не будут работать на потребительском оборудовании, за исключением, возможно, загрузки/выгрузки кодировщика текста при каждом изменении промпта и кэширования после промпта. Даже в этом случае использование огромного встраивания может увеличить размер Unet без улучшения качества изображения.
С точки зрения качества изображения и того, как проработаны руки или согласованность изображения (освещение, тени), Unet (или что-то еще, что используется для обработки изображений) вовсе не является революционным по сравнению с SDXL или MJ.
В Дейли три походу насколько баз на ТЕРРАБАЙТ
Палю лайфхак. Генерируешь изображения нужного персонажа с Dall-E 3, трейнишь на них лору для SD
Спасибо, анон, если гуи есть то разобраться смогу скорее всего.
>Зачем? Вообще не надо. Главное, чтоб образ был ухвачен, и особых/повторяющихся косяков не было.
Вангую что эти косяки тебе потом аукнутся когда будешь Лорой пользоваться. Не думаю что прямо говно будет, но качество будет хуже чем у обычных Лор которых тренировали на картинках от рисовак.
К тому же, мне вот хочется персонажа в одежде, а не просто лицо. При твоем способе даже на 300 картинках одежда будет пиздец какая разная. А в 3д хоть одежда и хуже по качеству, но она везде одинаковая.
>Для т екстового кодировщика SD 1.5 используется 123M параметров
У кодировщика SDXL в сумме уже около 800M параметров. Мало, но все же какие-то подвижки вперед есть.
Ничего не получится. Как ты сгенеришь несколько картинок одного персонажа?
Хотя я для SD видел один способ в котором чувак при помощь ControlNet openpose и эмбеддинга генерировал одну картинку типа Character Sheet с персонажем в разных позах и ракурсах. Потом апскейлил картинку, резал ее на части и ебался с каждой частью отдельно.
Или ты думаешь что с помощью очень подробного промпта можно в Dall-e получить постоянного персонажа?
Ничего я не перепутал.
Если генерить просто с лорой, тренированной на 3дшном персе - ИИ будет генерить тебе 3дшного перса.
А вот если с моделью замерджить - перс (ну, какая-то часть) останется, зато 3дшный стиль должен забиться почти полностью. И на втором шаге, когда уже на таком аутпуте тренируют - он уходит вообще.
Надо будет, кстати, самому попробовать. Посмотреть, что получится. Есть у меня лора, на 3дшных рендерах разных персов тренированная. Если ее просто подключать - она этот 3д стиль и выдает в точности.
Основная тренировка лоры на 3д-персонаже у него была для того, чтоб после мерджа модель этого перса более стабильно выдавала.
>которых тренировали на картинках от рисовак.
Ты картинки рисовак то давно видал? =)
Лишних руг-ног нет, лицо не поехало, глаза не вкось? Всё, в тренировку сгодится.
>При твоем способе даже на 300 картинках одежда будет пиздец какая разная. А в 3д хоть одежда и хуже по качеству, но она везде одинаковая.
Так это ж наоборот хорошо! Нейронка лучше концепт перса от одежды отделить сможет, особенно если одежду протэгать как следует. Если у тебя будет 300 картинок перса в одинаковой одежде, как ты ее не тэгай, а она намертво с персонажем будет ассоциироваться. Ты просто не сможешь его ни во что другое без сурового гемора потом переодеть.
Не, если тебе как раз такое и надо - то окей. Но вообще для гибкости нужен разнообразный датасет.
Опять же, генерить можно с вилдкардами на 3-5 сетов одежды. закрытый Купальник, бикини, какой-нибудь кэжул, униформа, всё такое. Это вообще в идеале, чтоб потом с тэгами для второго этапа не париться.

Далл-Е 3 далеко не всех персов знает, и не всегда в образ попадает.
Даже Рей или Аску точно сгенерить - и то проблема, через раз промахивается. Хотя казалось бы, артов с ними в интернете ну просто максимально много.
Зачем?..
>Как ты сгенеришь несколько картинок одного персонажа?
Пикрил. Видел на одном дискорд серваке, картинка не моя.
Качество говно, конечно.
Before|After в промпте или что-то типа того, очень хорошо работает. Прям зацени, насколько точно совпадение по лицу получается.
(выше твой пост не протэгал в ответе, эх).
Далли3 - мультимодалка, в этом и секрет.
Действительно текстовая часть там больше, а сама тренировка была с фокусами на концепты, причем четко и правильно обозначенные.
> Для т екстового кодировщика SD 1.5 используется 123M параметров, GPT3 — 150B параметров.
Врядли там даже 1 миллиард параметров есть, столько не нужно. Но вот отдельная llm там очень даже участвует, через нее проходят все юзер промты и она уже их переводит/достраивает/модифицирует для приведения к формату, который понятен, заодно выдает подходящие параметры генерации. Потому и результаты могут разительно отличаться на вроде похожих промтах, или случаются казусы.
Далее, если понаблюдать за генерацией и поведением - за текст и логотипы отвечает отдельная сеть. Оно получается криво-всрато как или даже хуже чем в сд, если запрос пошел не туда, или классно-четко если она задействуется. То же самое может быть в другими запросами тех же концептов или стилей, о чем свидетельствует рандомайзер реакции при смене последовательности в промте. Как именно оно сделано, заранее формируется маска с отдельными частями промта, используются заранее заготовленные разные модели, проходит несколько этапов обработки, используются техники как в контролнете - возможно все сразу, врядли подробно расскажут.
> Нет ничего, что Stability AI не смогут сделать, просто такие вещи не будут работать на потребительском оборудовании
Ерунда, с точки зрения качество самих пикч и т.д. оно вообще не далеко от 1.5 ушло, а то и проигрывает в чем-то конкретном. Считай требования как для XL, но сверху еще 2-4-6 гигов памяти на дополнительную сеть, что делает препроцессинг и асист. Только сразу полезут проблемы с управляемостью и рандомом, потому эту часть целесообразнее запускать заранее, а потом контролировать/править то что она выставила. В этом случае требования мало изменятся.
SDXL то вообще тоже не простая сеть, но в ней фокус сделали на "качество пикч", используя пост-обработку рефайнером.
Хочешь реализовать - двигайся в этом направлении, для начала научив llm по запросу составлять тебе идеально отформатированный промт(ы) и пачку json с параметрами, картами и прочим.
Внимание платиновый вопрос.
С чем-нибудь из всех этих ликорисов стоит вообще ебаться для стиля? Или лучше обычной лоры так ничего и не придумали?
С чем-нибудь из всех этих ликорисов стоит вообще ебаться для стиля? Или лучше обычной лоры так ничего и не придумали?
Поменял в шаблоне гайд по лорам от 1060 на твой.
Спасибо за твой труд.
Нет. Это говно придумали для шизов, дрочащих на размер файла. На деле всё это говно имеет очень плохую переносимость между моделями. Обычные лоры уже давно умеют обучать те же слои, что и ликорис.
> дрочащих на размер файла
> плохую переносимость между моделями
> Обычные лоры уже давно умеют обучать те же слои, что и ликорис
Слои обучать не надо и даже плохо, но обычные слои их могут обучать. Что хотел сказать то?
> обычные слои
обычные лоры офк, фикс
Пиздец, там 30 слайдеров крутить в разных комбинациях, ебясь с моделью долгими зимними вечерами. Это какой-то садюга аутист изобретал.
Не, слайдеры как раз не надо трогать, но настроек всё равно больно дохуя для "сделать пиздато" модуля. Но у меня один хуй не работает.

Почаны, а гугл теперь блочит колабы с SD?
Долго не дифузировал. Сейчас снова хотел вкатиться, но на колабе, где я сидел, висит сообщение, что гугл лавочку закрыл. Но в калабе от того же Христа такого нет.
Так Гугл сворачивает SD'шников или нет?
Долго не дифузировал. Сейчас снова хотел вкатиться, но на колабе, где я сидел, висит сообщение, что гугл лавочку закрыл. Но в калабе от того же Христа такого нет.
Так Гугл сворачивает SD'шников или нет?
С возвращением. Давно уже. И аккаунт могут забанить, ибо нехуй. Покупай своё железо.
Мне одному было очевидно, что лавочку прикроют?
Ок, бро, я-то комп обновлю так и так. А почему вы в шапке не пропишите такую важную инфу? Мало того, что нет предупреждения об удалении аккаунта, так еще и висят ссылки на гугл-колабы.
>Если у тебя будет 300 картинок перса в одинаковой одежде, как ты ее не тэгай, а она намертво с персонажем будет ассоциироваться. Ты просто не сможешь его ни во что другое без сурового гемора потом переодеть.
По мне, так это хорошо. Это же самая большая проблема нейронок - невозможность рисовать персонажа в одной одежде на разных генерациях.
Если нужно переодеть, то я бы лучше еще одну Лору обучил. Постоянная одежда в разных кадрах - это бесценно.
>Пикрил. Видел на одном дискорд серваке, картинка не моя.
Увы, фигня полная, для тренировки Лоры этого и близко не хватит. Хотя да, совпадение по лицу есть очень точное. В общем, если использовать метод анона выше который про генерацию 300 картинок в СД говорил, то думаю что толку больше будет.
Пиздец, аноны, SDXL в автоматике1111 оказывается не умеет нормально в img2img.
https://github.com/AUTOMATIC1111/stable-diffusion-webui/discussions/12187
Точнее умеет, но нужно запускать модель с --no-half что поднимает требования по видеопамяти в небеса. У меня под завязку жрет 16 гигов видеопамяти на 1024 х 1024 картинку без ничего.
Если у вас нет 24 гигов то можете даже не вкатываться в сдхл, разочаруетесь.
https://github.com/AUTOMATIC1111/stable-diffusion-webui/discussions/12187
Точнее умеет, но нужно запускать модель с --no-half что поднимает требования по видеопамяти в небеса. У меня под завязку жрет 16 гигов видеопамяти на 1024 х 1024 картинку без ничего.
Если у вас нет 24 гигов то можете даже не вкатываться в сдхл, разочаруетесь.
Чел, проблемам с VAE уже год, SDXL тут не при чём. Всё нормально работает в fp16, если у тебя нормальная карта.
Что значит нормальная? У меня Quadro P5000, 16 гигов видеопамяти.
Ты хотел сказать достаточно новая видюха?
Ну хорошо, 24 гига не нужно, нужно просто быть мажором и купить новую видюху за тыщу баксов.
Чел, твоей картонке чуть ли не десятилетие, там архитектура уже всё.
Купи 3060 12ГБ, она быстрее будет, лол.
>По мне, так это хорошо.
Нет, не хорошо. Ибо в идеале надо совмещать.
300 картинок с персом, 100 в его фирменном костюме, 100 в разных простых костюмах, 100 чисто голым. И будет красота вообще - и костюм натренится, и переодевать можно будет запросто.
Куча лор так натренирована.
>Увы, фигня полная, для тренировки Лоры этого и близко не хватит.
Да понятно, это была просто демонстрация того, как эта нейронка концепты понимает. Сколько лор на подобное в СД не видел - всегда лажа выходит, никакого постоянства ключевых моментов между картинками. А тут прям из коробки.
>on Jul 31
Обновиться пробовал?
>в автоматике1111
Комфи пробовал?

Это не совсем моя карта, я ее в аренду у Paperspace на пару часов взял. Алсо, сегодня по твоему совету взял нормальную: A4000.
Пиздос, ровна такая же проблема.
Но на ней уже с --medvram --no-half по крайней мере работать img2img может. Правда у этой виртуальной машины 45 гигов оперативки, поэтому все помещается.
Короче, нужно очень хорошее железо. А вот в text2img почти на любом старье можно генерить (если есть хотя бы 8 гигов видеопамяти).
>Сколько лор на подобное в СД не видел - всегда лажа выходит
Лоры не пробовал, но вот ембеддинг и просто промпт сharacter sheet, multiple views of the same character СД вполне понимает. Без помощи контролнета правда сложно будет. Вот он очень неплохо Лору обучал на основе чарактер щита: https://youtu.be/iAhqMzgiHVw?si=aRD4g-K7TPZOQHhp
Пикрелейтед я сам генерил, правда это для 3д модели было.
>Обновиться пробовал?
Я через Gradient блокнот запускаю, хз как его обновить, думаю что там и так последняя версия автоматика.
>Комфи пробовал?
Нет, но думаю попробовать. Вроде там более щадящие требования к железу.
>Но на ней уже с --medvram --no-half по крайней мере работать img2img может.
Ещё бы. Я на 12 гигах работаю, и таких проблем нет, хватило --no-half-vae.
В целом норм в текущей ревизии. Доебаться можно по мелочам:
Изображения нужно сделать кликабельными (обязательно), а в последовательностях где 1-2 выставить их подряд а не таблицей, ненужное ужимание и шакалит (на усмотрение).
В самом начале нужно обозначить что нужен питон такой-то версии и куда тулкит.
Начало где использование, к способ 3 ставь не рекомендуется или для справки, а то начнут так портить модели.
Пример хорошего датасета - серьезно? Одни ковбойшоты с сомнительным качеством, в тегах к которым нету имени персонажа. Папка 20 вообще отборная. Присутствуют регуляризации, хотя дан совет их не делать. Везде из раза в раз повторяется эта структура 10_x 20_x, что создает впечатления что именно так надо делать. Стоит прояснить как именно выбирать и ставить эти цифры, и сказать что в большинстве случаев можно обойтись одной папкой.
В разделе Easy way пункт 5
> Внимание, в настройках Additinal networks нужно указать дополнительный путь для сканирования лор, чтобы они подхватывались из дефолтной директории вебуи.
тогда как выше написано что все по дефолту ок, и ласт коммит ищет в стандартной папке webui.
Там же, какой смысл тестировать при весах 1.3-1.5? Куда важнее сделать несколько вариантов изображений чтобы оценивать не по одному сиду а хотябы по 4-8. Для этого лучше отказаться от варьирования веса, оставив его 0.8-1.0, выставить батч сайз-батч каунт а в webui изменить число строк или столбцов в гридах (лучше вынести его в квиксеттингс). Тогда можно будет сравнивать и видеть сразу много вариантов. Аналогично не помешает использовать вайлкарты на фон/позу/... и оценивать также косвенное влияние на окружение.
--unet_lr - лучше не значение а просто что равно LR
> conv_dim - тоже самое, что и network_dim, только для этих слоёв. Размер этих слоёв складывается с размером network_dim в выходном файле. Хорошим значением будет network_dim/2-4
Откуда?
> Есть разные мнения использовать вае во время тренировки или нет
Без него сама тренировка невозможна, здесь речь о том будет ли использоваться встроенное в модель или внешнее.
> что если и использовать то только вот это
Ты же на базе тренируешь, что там по дефолту? 840к с kl-f8 и наи сравнивал (только при тренировке офк)?
Сап тренеры.
RAM дохуища (93 гига), а вот VRAM в 1063 не завезли. --lowvram оно сожрет, или я зря надеюсь?
RAM дохуища (93 гига), а вот VRAM в 1063 не завезли. --lowvram оно сожрет, или я зря надеюсь?

Оно ведь не работает с общей памятью, да? Только с хардварной?

Аноны, есть сейчас какие-нибудь виртуальные окружения вроде Колаба гуглавского, чтобы БЕСПЛАТНО вот зайти в окружение, нагрузить своих моделей и питоновских скриптов и генерировать?
Пробовал ещё сервис Paperspace, но там всё обмазано завлекалочками "FREE FREE FREE !!11". а как доходит дело до подключения к мощностям - а-тя-тя-тя, подключите свою кридиточку.
Как быть?! Раньше делал всё в колабе, горя не знал, но вот вернулся после 2х месячного перерыва и с ужасом обнаружил что гугл ВСЁ, а цены там неприемлемые, особенно учитывая курс. В общем покупать подписку не вариант.
Пробовал ещё сервис Paperspace, но там всё обмазано завлекалочками "FREE FREE FREE !!11". а как доходит дело до подключения к мощностям - а-тя-тя-тя, подключите свою кридиточку.
Как быть?! Раньше делал всё в колабе, горя не знал, но вот вернулся после 2х месячного перерыва и с ужасом обнаружил что гугл ВСЁ, а цены там неприемлемые, особенно учитывая курс. В общем покупать подписку не вариант.
на новых драйверах работает и с общей памятью, но где-то в 10 раз медленнее
купи rtx 3060 12gb
Норм, годится.
>купи
Не куплю.
>СД вполне понимает
Понимать то понимает, но чтоб важные моменты были точно ухвачены - этого в 90% случаев уже не будет.
Типа тот же before\after, или sequence - будут тебе два разных (но похожих) перса вместо одного с изменениями. В character sheet тоже не слишком много постоянства без кучи неудачных генераций.
> Изображения нужно сделать кликабельными (обязательно)
Сделал на самые мелкие, которые было не видно.
> В самом начале нужно обозначить что нужен питон такой-то версии и куда тулкит.
Про куду было, перенёс повыше с питоном.
> Начало где использование, к способ 3 ставь не рекомендуется или для справки, а то начнут так портить модели.
Ну добавил, но этим уж заморачиваться будут наверное только те, кто с чекпоинтами постоянно пердолится.
> Пример хорошего датасета - серьезно? Одни ковбойшоты с сомнительным качеством, в тегах к которым нету имени персонажа. Папка 20 вообще отборная. Присутствуют регуляризации, хотя дан совет их не делать. Везде из раза в раз повторяется эта структура 10_x 20_x, что создает впечатления что именно так надо делать. Стоит прояснить как именно выбирать и ставить эти цифры, и сказать что в большинстве случаев можно обойтись одной папкой.
Реально полная хуйня, со старого гайда, я хотел было это переписать, но походу пока про параметры писал забыл. Что думаешь, так пойдёт?
> тогда как выше написано что все по дефолту ок, и ласт коммит ищет в стандартной папке webui.
Поправил.
> Там же, какой смысл тестировать при весах 1.3-1.5?
Ну в том же гриде что я тренил видно недожар, после кстати ещё всякие тестовые тренировки были и как раз на бОльшем лр сетка получилась лучше, без этого графика я бы хуй это узнал, я её даже юзать стал.
> выставить батч сайз-батч каунт а в webui изменить число строк или столбцов в гридах (лучше вынести его в квиксеттингс). Тогда можно будет сравнивать и видеть сразу много вариантов.
Не пойму зачем эта гимнастика с батчами нужна? Можно же просто сиды рандомные поставить.
> Аналогично не помешает использовать вайлкарты на фон/позу/... и оценивать также косвенное влияние на окружение.
Ещё сложнее определить по такому влияние на бекграунд, если честно. Лучше для начала просто оценивать насколько хорошо вышел тренируемый концепт, но я всё же допишу.
> --unet_lr - лучше не значение а просто что равно LR
Уверен? Просто лр можно вообще указать произвольным, он нихера не влияет, если разделяешь и указываешь правильные значения для юнета и те по отдельности с адамом.
> Откуда?
Тестил с этими значениями, выходило хорошо. Есть другие предложения?
> Без него сама тренировка невозможна, здесь речь о том будет ли использоваться встроенное в модель или внешнее.
Да ты прав, плохо сформулированно, переделал.
> Ты же на базе тренируешь, что там по дефолту? 840к с kl-f8 и наи сравнивал (только при тренировке офк)?
А сам не знаешь насколько ужасное в наи вае по дефолту? Сравнения в старых тт кидал, наи вае, не то что в модели, и 840к, kl-f8 не тестил, 840к это энивей его файнтюн, на собственно 840к шагов https://huggingface.co/stabilityai/sd-vae-ft-mse-original#decoder-finetuning , 840к выигрывал в детализации даже на 512


Спасибо за совет, кстати. Заменил --no-half на --no-half-vae и уже не так сильно память жрет. Работает даже на P5000
Расскажи получилось ли генерить с сдхл моделями. Вангую что постоянные вылеты будут.
Кстати, аноны, а кто-нибудь пробовал генерить на основе 3д рендеров, но так чтобы стиль получился 2д?
Мне раньше было это неинтересно из-за низкого разрешения SD1.5, но на SDXL можно любопытные результаты получить если несколько controlnet моделей добавить. Пикрелейтед я генерил без Лоры на персонажа, тупо img2img с денойзом 0.6.
>низкого разрешения SD1.5
>несколько controlnet моделей добавить
С контрол нетом можно хоть 4к пикчи делать на полторашке, никаких проблем не будет, кроме памяти, лол.
>никаких проблем не будет
Не все так просто. Даже с контролнетом при увеличении размера картинки ИИ имет свойство чрезмерно засирать нейрошумом пустые пространства. Даже там, где это не требуется.
Если, конечно, тебе не простой апскейл нужен на денойзе 0.25, а именно обработка картинки с увеличением детализации.
>генерить наоснове 3д рендеров, но так чтобы стиль получился 2д?
Выше тред почитай, я кидал несколько картинок, забодяженных на основе карточки из койкатсу.
>ИИ имет свойство чрезмерно засирать нейрошумом пустые пространства. Даже там, где это не требуется.
Так оно всегда так работает, просто при размере с почтовую марку это незаметно.
>Так оно всегда так работает
Ну, не совсем прям всегда.
Но контролировать эту тенденцию трудно.
Я пока стабильного способа не придумал.
Насрать в картинку нейрошумом - это вот запросто, это завсегда пожалуйста.
>Выше тред почитай, я кидал несколько картинок, забодяженных на основе карточки из койкатсу.
Ага, нашел тот пост.
Даже не верится что у тебя с таким высоким денойзом (0.8) получается похоже на оригинальный 3д рендер. У меня даже на 0.6 цвета жестко проебывает.
Сколько ты примерно ставил веса depth и canny? И tile примерно на каком шаге отключал?
Хотя ведь тайл модели вроде нет еще в сдхл, то есть цвет контролировать я не смогу.
Можно, но в родном разрешении работать проще. Если мне не нужен арт в высоком разрешении, то я тупо могу 1024 х 1024 рендер сделать и на его основе генерить картинку в том же разрешении. Никаких апскейлов вообще не нужно.
На тайл есть много вариаций, как я заметил.
Можно поставить 0.25 силы и отключать на 0.1 (24 шага всего, это как раз вариант с картинки). Задаст базу и спокойно отключится, дальше нейронка будет сама думать.
Можно поставить 0.25 силы и вести до конца. Тут более точный контроль будет, ради сохранения деталей и цвета, но меньше фантазии.
Можно поставить 1 силы и тоже вести до конца. Тут уже будет усиление базовых деталей (если они есть) с добавлением всякого поверх, вплоть до "пережаривания" картинки в некоторых сетапах.
Есть еще экспериментальный - сила 2, отключить на 0.1. Выдает интересные результаты порой.
depth я в том примере не использовал, canny был полностью по стандарту, с дефолтовыми настройками.
Есть интересный вариант, который я для латент апскейла применяю:
tile 0.25; 0-0.1
canny 0.65; 0-0.25
Lineart (realistic) 0.65; 0.24-1
Первое - сила, второе шаги включения/отключения.
Входная картинка контролнета при этом - высокого разрешения, полученная через апскейл каким-нибудь валаром или другим не-латентным апскейлером.
А, ну да, без tile даже на низком денойзе цвета пойдут по тому самому месту. Там вон ниже другие картинки были, как раз без тайла, сам видишь, что получалось.
А в некоторых случаях иногда надо дать ему подольше поработать, потому что на определенных картинках/сидах бывают глюки, и нейронка все равно цвета на половине генерации начинает пересирать. Тут уже экспериментировать только остается.
Спасибо, тоже попробую когда наконец в сдхл запилят tile модель.
Кстати, а зачем вообще нужна Lineart модель дополнительно к Canny, разве они примерно не то же самое делают?
Я вот думаю что поза и перспектива у пикчи были простые. Если какая-нибудь акробатика или хентай, то нейросеть будет портить колени и другие сложные места. Желательно все же Depth или Openpose добавить.

Помогите у меня бесконечно надпись висит "Installing requirements for CodeFormer"
>когда наконец в сдхл запилят tile модель
Если запилят.
Канни дает очень жесткие контуры, лайнарт более мягкие и побольше свободы для интерпретации.
Мне кажется, что в такой последовательности апскейл получше получается.
Но может и плацебо, конечно, можно и целиком на канни идти от начала и до конца.
> так пойдёт?
Ничесе датасет, алсо это уже не только стиль а еще и мультиперсонаж, лол. Да, заебумба, и по тексту иллюстративно.
> Не пойму зачем эта гимнастика с батчами нужна? Можно же просто сиды рандомные поставить.
Тогда делать несколько гридов с разными сидами и промтом. Вот только пока одни смотреть будешь уже другие забудешь, а лишняя информация по весам/эпохам будет только отвлекать. Тут можно сеточную систему или на выбывание постепенно самые хреновые откидывать, увеличивая при этом количество сравнений.
Ну это все другая история, важно отметить что нужно сравнивать не по одной генерации что сделано, вполне.
А батчи - чтобы не заморачиваться прописывая лишнюю ось в графике и генерить с ними, что быстрее на больших видеокартах. Буквально 2 клика и грид+оптимальный бс.
> Ещё сложнее определить по такому влияние на бекграунд
Он или взрованн-распидорашен, состоит из множества некогерентных частей по разным сторонам от персонажа со странным углом, или нормальный. А позы - это для персонажа, чекнуть чтобы не провоцировало бадихоррор и не копировало датасет. Для того и нужен none как контрольная группа, ведь поломаться может оно и само по себе а не из-за лоры.
> Уверен?
Тут про то что для LR расписано какое значение для такой-то альфы, что для разных оптимайзеров другие значения, а где юнет лр - просто ставь 1e-4.
> Тестил с этими значениями, выходило хорошо. Есть другие предложения?
Нет, не заморачиваясь ставлю таким же размером. Тут именно оптимум на этих значениях нащупал или же просто на них хорошо получалось и дальше начал шпарить? Еще на релизе примеры с разными и выводы из этого - ну вообще неубедительные были.


>пробовал генерить на основе 3д рендеров, но так чтобы стиль получился 2д?
юзай только контролнет, желательно 3 сразу, аля тайл на 0.5, кенни на 0.75 и аниме лайнарт на 0.75 для поддержки форм, потом дефолт апскейл при максимально мелких диноизов чтоб не было гостов. У меня модель хорошая, юзаю как первое значение в 0.4 и опускаю на 0.1 каждый апскейл х2
Пик сгенерил из разрешения 1280х720, потом апскейл на 0.4 + контролнет при апскейле тоже юзал, лайн арт аниме на 0.75 для поддержания формы.
Прямо как прочитал твое сообщение, вот сгенерил за 10 минут, правок в фотошопе нет
мимо анон который по кд юзает коикатсу+нейронка
дополню от себя.
руку можно было перегенерить, а еще колготки в сетку хуево переваривает, на месте окончания волос был изначально второй хвостик, артефакт, лень было поправлять, поэтому там каша
Это я к тому, что артефакты будут, больше времени потратишь, можешь убрать эти артефакты

промт
silver hair, rabbit costume, rabbit ears, rabbit tail, fishnet pantyhose, ass, ahegao, open mouth, tongue
Negative prompt: (panties:1.2), easynegative
Steps: 25, Sampler: DPM++ 2M Karras, CFG scale: 7, Seed: 526260194, Size: 1280x720, Model hash: 2f33c329b7, Model: !custom_mix_v1_stable, Clip skip: 2, ControlNet 0: "preprocessor: canny, model: control_canny-fp16 [e3fe7712], weight: 0.75, starting/ending: (0, 0.75), resize mode: Crop and Resize, pixel perfect: False, control mode: Balanced, preprocessor params: (1536, 100, 200)", ControlNet 1: "preprocessor: lineart_anime, model: controlnet11Models_lineart [5c23b17d], weight: 0.75, starting/ending: (0, 0.75), resize mode: Crop and Resize, pixel perfect: False, control mode: Balanced, preprocessor params: (512, 64, 64)", ControlNet 2: "preprocessor: tile_resample, model: controlnet11Models_tileE [e47b23a8], weight: 0.45, starting/ending: (0, 0.5), resize mode: Crop and Resize, pixel perfect: False, control mode: Balanced, preprocessor params: (512, 1, 64)", CFG Rescale phi: 0, TI hashes: "easynegative: c74b4e810b03", Version: 1.5.1
Пробовал опенпоуз + дэпс? Их еще можно прямо по ходу отредачить, предварительно поигравшись с препроцессорами.
Спасибо, похожу если в сдхл тайл скоро не завезут то буду перекатываться в 1.5.
Тут и модель в самом деле годная, но то что counterfeitXL. Ты из чего ее намешал?
Двачую вопрос. Главное преимущество 3д моделей ведь в получении точной карты глубины (или нормалей), по идее должна быть польза от depth. Ну хотя бы по части нормального рисования кистей рук.
С другой стороны, карта глубины ведь может добавить глубины, что плохо для плоского аниме стиля.
Помогите аноны, не загружаются модели. Сначало пишет что calculating, потом через 10 секунд в браузере пишет errored out и в консоле "нажмите клавишу для продолжения" и всё
venv "D:\stable-diffusion-webui\venv\Scripts\Python.exe"
Python 3.10.6 (tags/v3.10.6:9c7b4bd, Aug 1 2022, 21:53:49) [MSC v.1932 64 bit (AMD64)]
Version: v1.6.0
Commit hash: 5ef669de080814067961f28357256e8fe27544f4
Launching Web UI with arguments: --xformers
Calculating sha256 for D:\stable-diffusion-webui\models\Stable-diffusion\realismEngineSDXL_v10.safetensors: Running on local URL: http://127.0.0.1:7860
To create a public link, set `share=True` in `launch()`.
Startup time: 17.5s (prepare environment: 5.7s, import torch: 7.5s, import gradio: 1.1s, setup paths: 0.9s, initialize shared: 0.2s, other imports: 0.7s, setup codeformer: 0.1s, load scripts: 0.7s, create ui: 0.4s, gradio launch: 0.2s).
7b399aa4be60ddbc8d7e1dbe7d45de65c9a80c881586b3666491d736ac7086d8
Loading weights [7b399aa4be] from D:\stable-diffusion-webui\models\Stable-diffusion\realismEngineSDXL_v10.safetensors
Для продолжения нажмите любую клавишу . . .
venv "D:\stable-diffusion-webui\venv\Scripts\Python.exe"
Python 3.10.6 (tags/v3.10.6:9c7b4bd, Aug 1 2022, 21:53:49) [MSC v.1932 64 bit (AMD64)]
Version: v1.6.0
Commit hash: 5ef669de080814067961f28357256e8fe27544f4
Launching Web UI with arguments: --xformers
Calculating sha256 for D:\stable-diffusion-webui\models\Stable-diffusion\realismEngineSDXL_v10.safetensors: Running on local URL: http://127.0.0.1:7860
To create a public link, set `share=True` in `launch()`.
Startup time: 17.5s (prepare environment: 5.7s, import torch: 7.5s, import gradio: 1.1s, setup paths: 0.9s, initialize shared: 0.2s, other imports: 0.7s, setup codeformer: 0.1s, load scripts: 0.7s, create ui: 0.4s, gradio launch: 0.2s).
7b399aa4be60ddbc8d7e1dbe7d45de65c9a80c881586b3666491d736ac7086d8
Loading weights [7b399aa4be] from D:\stable-diffusion-webui\models\Stable-diffusion\realismEngineSDXL_v10.safetensors
Для продолжения нажмите любую клавишу . . .
>опенпоуз + дэпс
Юзлис хуйня, слишком много рандома же.
>Ты из чего ее намешал?
zMix_v21
hassakuHentaiModel_v13
toonyouJP_alpha1
flat2DAnimerge_v30
И мешал их много раз, больше не смог повторить намешанное, сотни вариантов комбинаций было
>точной карты глубины (или нормалей), по идее должна быть польза от dept
Зачем если эту траблу решает более лучше лайн арты, кенни и тайлы? тайл даже сохраняет нужный цвет в нужных местах

Я обычно уменьшаю пикчу до небольшой, потом делаю латентный апскейл под контролнетом, за базу беру оригинальную большую пикчу.
Ну и промптов наваливать надо побольше, чтоб ИИ понимал, чего от него хотят вообще.
Типа:
masterpiece, best quality, 1girl, solo focus, from behind, leaning forward, bent over, hand on thigh, looking at viewer, turning head, white hair, blue eyes, open mouth, large breasts, huge ass, wide hips, playboy bunny, strapless, fishnet pantyhose, shoes, rabbit tail, rabbit girl, rabbit ears, shiny skin, shiny clothes, latex, abstract background, star \(symbol\),
Чем точнее промпт под картинку попадает, тем ИИ меньше глючит. Контролнет - это, конечно, хорошо, но и описательная часть тоже важна.
Опенпоз для обработки готовых пикч не рекомендую, только запутывает. С ним генерить надо, но тоже осторожно, а то будет бодихорор.
Depth нужен больше когда у тебя прям вообще голый манекен на исходнике, без одежды, без лица, без прически, чисто чтоб какой-то начальный пинок ИИ дать, чтоб было потом с чем работать.


ЧЯДНТ? Контролнет Tile производит столько мыла что им можно мылить жопу в тюряге
Настройки, исходник, промпт?
Вообще замыливает только фон, попробуй blurry, blurry background в негативы дописать.
Любопытно, обучаю лору на 768px, а генерации с неё пидорит уже на 640, при том что базовая модель очень хорошо с 768 справляется... Мистика...
Обучай на 512, всё будет нормально.
Стиль смазывается на 512. Ну, придётся ещё покропать, может, поможет.

> Ничесе датасет, алсо это уже не только стиль а еще и мультиперсонаж, лол.
Да тут все три сразу, стиль, концепт и чары, не отходя от кассы, всё равно стиль дольше всего тренить и всё остальное подхватит, немногие художники могут похвастаться такими датасетами.
> Тогда делать несколько гридов с разными сидами и промтом. Вот только пока одни смотреть будешь уже другие забудешь, а лишняя информация по весам/эпохам будет только отвлекать. Тут можно сеточную систему или на выбывание постепенно самые хреновые откидывать, увеличивая при этом количество сравнений.
> А батчи - чтобы не заморачиваться прописывая лишнюю ось в графике и генерить с ними, что быстрее на больших видеокартах. Буквально 2 клика и грид+оптимальный бс.
Не понял про настройки что ты имеешь ввиду. Вот так типо как на пике, bs|bc = той настройке про гриды и вайлдкарды с промптами концептов ну или просто беков?
Ну и да, заебёшься же такое высматривать, легче приблизительную годную эпоху найти и там уже точечно тестить вокруг неё по эпохам что тебе нужно.
> ведь поломаться может оно и само по себе а не из-за лоры
А может случиться и так, что лора наоборот исправит сид.
> Тут про то что для LR расписано какое значение для такой-то альфы, что для разных оптимайзеров другие значения, а где юнет лр - просто ставь 1e-4.
А, ну ок, поправил. Так понятнее?
> Нет, не заморачиваясь ставлю таким же размером. Тут именно оптимум на этих значениях нащупал или же просто на них хорошо получалось и дальше начал шпарить? Еще на релизе примеры с разными и выводы из этого - ну вообще неубедительные были.
Второе скорее, просто мне понравилось это значение и на них сетки получались сочнее вот и всё, слишком много было не оч, слишком мало давало меньше эффекта. Конкретных тестов не было, если прямо уж заморочиться нужно фулл стиледатасет собрать и тренировать conv_only, тогда видно будет различие, но в отрыве от основной реализации лоры естественно, потом с ней по хорошему бы.


Примерно таким способом сгенерировал такое. Ничего не редактировал, только инпеинт одной перчатки.
Аноны, так что получается, Лоры собственных персонажей не нужны? Выходит ведь что проще собрать 3д модельку в Койкатсу или еще где и обрабатывать рендеры. 3д происхождение картинки лично я не замечаю.
Лора же обычно дает меньшую стабильность и часто творит дичь с одеждой.
Хотя вот сейчас заметил что по лицу жесткий проеб.
У меня был денойз 0.5 при первой генерации. Глаза и рот на пикче мелкие слишком для такого денойза.
Скорее всего нужно было еще вариант с низким денойзом делать и потом в фотошопе склеить.
> Выходит ведь что проще собрать 3д модельку
Конечно проще. Только стабильный дифундер убрать из пайплайна, рендор триде ближайшую сотню лет будет выдавать гораздо более лучшее качество.
> Юзлис хуйня, слишком много рандома же.
Зато потом любой стиль, любой бэкграунд и небольшая корреция позы прямо на месте, а не подшумливание и перерисовка глаз. Накрайняк тайл 10% окончание. Крутануть рулетку на 16 пикч дело не долгое. Ну ладно, ответ получен, спасибо.
На кэтбокс залей.
> bs|bc = той настройке про гриды
Да
> и вайлдкарды с промптами концептов ну или просто беков
Сравнение с ними лучше, будет охватывать много вариантов а не один изолированный.
> Ну и да, заебёшься же такое высматривать
Берешь и сравниваешь, все перед глазами.
> легче приблизительную годную эпоху найти и там уже точечно тестить вокруг неё по эпохам что тебе нужно
Так и надо, офк не нужно все все тащить а только самые отборные, отсечку же можно и по малой выборке делать, или вообще по тензорфлоу.
> А может случиться и так, что лора наоборот исправит сид.
Сидам веры нет, количественно оценивать надо. Может там сложный промт и т.д. и 3/16 в None поломались, тогда поломка того же количества с лорами - не проблема лор. А если None стабилен везде, а одна или несколько лор выдают в половине случаев хтонь - повод задуматься.
> и тренировать conv_only
Проебутся корреляции с вниманием и т.д., лучше уж сразу все и варианты. Может вообще оказаться что рандома там больше.
Одно другому не мешает, юзай и лору и модель, на апскейлах точно поможет.
> Сравнение с ними лучше, будет охватывать много вариантов а не один изолированный.
Ну я уже такой в пример же положил тоже, или думаешь его недостаточно?
> Сидам веры нет, количественно оценивать надо. Может там сложный промт и т.д. и 3/16 в None поломались, тогда поломка того же количества с лорами - не проблема лор. А если None стабилен везде, а одна или несколько лор выдают в половине случаев хтонь - повод задуматься.
Сам часто настолько тщательно высматриваешь, или только с хвостами? Но вообще да, это один из способов количественной оценки без черрипика. Ну можно тоже как нибудь упомянуть, но это конечно геморно уже слишком сидеть высчитывать удачные/неудачные, только самый упорный займётся.
> Проебутся корреляции с вниманием и т.д., лучше уж сразу все и варианты. Может вообще оказаться что рандома там больше.
Ну так а я что написал, сначала тест просто этих слоёв, дальше уже вместе, чтобы увидеть точно.
Теперь намного лучше оверолл читается бтв?
Если я не положу текстовые файлы к датасету тогда обучение не будет ничем срать в текстовую часть модели, верно?
А то я сейчас пробую с --трейн-юнет-онли и я не уверен, что оно нормально работает.
А с лохой поди вообще эта команда всё всрёт. Или нет?
А то я сейчас пробую с --трейн-юнет-онли и я не уверен, что оно нормально работает.
А с лохой поди вообще эта команда всё всрёт. Или нет?
Пример норм, достаточно.
> настолько тщательно высматриваешь
Не нужно тщательно, в общем что-то типа в этой колонке 5 штук распидарасило все, в этой фоны взорвались, здесь костюм не воспроизводится, в этой 2 так себе а остальные норм, в этой 3 поломаны но остальные мастерпись. Смотришь на None - там 2.5 испорчены - значит все ок. 1-2 гридов достаточно для оценки, больше нужно если требования специфические.
> только с хвостами
Особенно с хвостами
> лучше оверолл читается бтв
Лучше, дальше уже такие мелочи что не стоят внимания.

Что же аноны нет решения? Никто в кал_лабе не генерирувает что ли?
> Если я не положу текстовые файлы к датасету тогда обучение не будет ничем срать в текстовую часть модели, верно?
Неверно, концепты будут иметь названия папок как тег текстовой части.
> А то я сейчас пробую с --трейн-юнет-онли и я не уверен, что оно нормально работает.
Почему? Это и есть правильный параметр чтобы тренить только юнет.
> А с лохой поди вообще эта команда всё всрёт. Или нет?
Не должна, но лоха сама по себе не оч, ты ради эксперимента хочешь её потренить?
Ладно, спасибо что помог с правками.
> Почему? Это и есть правильный параметр чтобы тренить только юнет.
Понял, спасибо, скрипт мне просто пишет при обучении про текстовые слои и не пишет, что не будет их трогать, потому я сомневаюсь всё ли работает как надо.
> но лоха сама по себе не оч, ты ради эксперимента хочешь её потренить?
Угу, пробую все эти ликорисы. Хорошо если это никак не конфликтует с ними.
Я генерирую , но не на гугол колабе а в paperspace. Правда в месяц 8 долларов плачу (я не в РФ живу). Можно и вообще бесплатно, но там жуткие очереди на бесплатный сервак.
За 8 баксов и сервера нормальные (вплоть до машины с А4000 и 45 гигов оперативкой) и 15 гигов хранилища дают.
> Понял, спасибо, скрипт мне просто пишет при обучении про текстовые слои и не пишет, что не будет их трогать, потому я сомневаюсь всё ли работает как надо.
Можешь просто посмотреть в тензорборд, там не должно быть других лров, кроме юнета во время тренировки.
> Угу, пробую все эти ликорисы. Хорошо если это никак не конфликтует с ними.
Локон попробуй, он хорош для стиля.
Так блядь. Если в кохагуе нажать на запрет апскейла бакета, то мне скрипт пишет, что будет игнорировать предельные разрешения и обучает со всякими бесполезными условными 1280x64.
Попробовал убрать галку с неапскейла — вижу характерную малафью от обучения на низкокачественном сете, то есть он наелся мыльного апскейльного говна, которое сам же и породил.
Чзх? Как ограничить разрешение и запретить апскейл одновременно?
Попробовал убрать галку с неапскейла — вижу характерную малафью от обучения на низкокачественном сете, то есть он наелся мыльного апскейльного говна, которое сам же и породил.
Чзх? Как ограничить разрешение и запретить апскейл одновременно?
Очевидный minister, я всё делаю там. Не как колаб, но с api.
Поешь говна, маркетолог.
мимокрок
>Поешь говна, маркетолог
очередное бесполезное кидание фекалиями от шкилы. можешь что-нибудь нормальное посоветовать страдающим без колаба? нет
Единственный выход это купить видеокарту, а 3060 12ГБ это самый разумисткий выбор. Во всех остальных случаях коллабобляди жрут говно, ебутся там, где ебли вообще быть не должно, банятся и проёбывают деньги на подписки.
вот именно. если на новую денег жаль, есть вторичка. есть ещё 2060 с 12 гигами, может ещё продаётся, дешевле 3060 должна быть. можно кредит оформить как вариант. а ноют очевидно безработные неумехи\школьники, которым всё это недоступно.

В треде уже советовали + есть тред по этой теме где накидали годноты
Наркоман, как ты собрался подключать эту залупу к ведру?
Вообрази, задрот: не все имеют ПеКа, так как не каждому он вообще нужен
>не все имеют ПеКа
Бомжам с улицы с сажей в жопе голоса не давали.
>так как не каждому он вообще нужен
>жуёт говно без ПК
>орёт, что ПК не нужен
В голосину.
> можно кредит оформить как вариант
Перетолстил.
Ну а вообще рили сейчас даже сраный школьник в возрасте, когда он сознательно хочет и может абузить нейронки, может заработать/насобирать сумму чтобы дополнительно выклянчив у родителей купить бюджетную карточку что позволит делать все. В пролете только студентота-общажники или постоянно переезжающие с безальтернативностью ноута. Бибу сосут еще странные люди без пекарни/возможности выделить 200-300$, но это уже их выбор а не ситуация.
> не все имеют ПеКа
Как жить без пекарни в 2д23 году? Не существовать будучи овощем, которому достаточно потреблять примитивный контент с мобилки, а полноценно жить?
Убейся, чмо. Поди еще и социал-дарвинист, хорошо хоть путинская власть иногда закапывает подобную мразь (правда, ненамеренно)
Норм. Потребляю контент на мобилке, генерирую нейроарт, между делом твою маман в сортире за волосы таскаю.
Это имитация жизни и страдания. Сам это понимаешь и осознаешь уместность насмешек над тобой, потому ты и злой, защитная реакция слабого человека. Еще и политоту приплел, может и не осознаешь а просто глупой злой шизик.
для тех кто вопит "ПИКА НИНУЖОН!!1!"
https://github.com/ShiftHackZ/Stable-Diffusion-Android
в настройках выбираем local diffusion (beta)
SD 8 gen 2 и 12 гб озу желательны, и то будет медленно всё по сравнению с компом
https://github.com/ShiftHackZ/Stable-Diffusion-Android
в настройках выбираем local diffusion (beta)
SD 8 gen 2 и 12 гб озу желательны, и то будет медленно всё по сравнению с компом
Чел если ты про очередной говносайт песочницу, где забиваешь промт и тебе высирает картинку, то это пиздец. Тебе там дают покрутить только пару настроек и промпт. После работы с полным функционалом вебуи это жрать невозможно. никакого тебе регионального промпта, ни контролнета, ни настроек хайреса, ни смешивания моделий и кучи лор и эмбендингов и текстуал инверсий.
Алсоу если ты про тот сайт который первый в выдаче гугла, то вообще плохие новости - он на 100% засран вирусами, переустанавливай винду.
Ананасы, кто делал - дайте плз полные и проверенные настройки для тренировки на каком-нибудь автоматическом планировщике, который сам ЛР настраивает.
Потому что я уже 3 варианта лоры на стиль сделал, и получается всё время какая-то херня по сравнению с базовыми настройками и косинусом. Плохая карикатура, а не стиль.
Хочу все-таки постичь эту мудрость.
Потому что я уже 3 варианта лоры на стиль сделал, и получается всё время какая-то херня по сравнению с базовыми настройками и косинусом. Плохая карикатура, а не стиль.
Хочу все-таки постичь эту мудрость.
Кто пробовал трейнить lora на civitai, дефолтные настройки норм? Кто пробовал абьюзить баззы мультиакком?


мои\сивитаи
Оу, оно еще не успело ухватить нужное, но уже полезли мертвые нейроны. Хорошая тренировка.
А капшоны влияют на что-то если тренишь только юнет?
>гугл ВСЁ, а цены там неприемлемые, особенно учитывая курс. В общем покупать подписку не вариант.
Чувак, в vast.ai аренда 3090 стоит 10-30 центов/час. Цены бросовые.
Чот ору, не хватает 32гб оперативки штобы скомпилить хформеров. Это что за обновления такие, ебануться.
> хформеров
Зачем тебе это говно, когда есть SDP?

Ну.
Там разница 200 мб при 2048х2048.
Любопитно, любопитно.
xformers
Time taken: 2 min. 26.5 sec.
A: 6.36 GB, R: 6.89 GB, Sys: 8.0/8 GB (99.5%)
xformers --medvram
Time taken: 2 min. 6.0 sec.
A: 5.25 GB, R: 6.55 GB, Sys: 7.6/8 GB (95.2%)
opt-sdp-attention
Time taken: 1 min. 28.6 sec.
A: 9.21 GB, R: 9.81 GB, Sys: 8.0/8 GB (100.0%)
opt-sdp-attention --medvram
Time taken: 1 min. 4.2 sec.
A: 7.19 GB, R: 7.33 GB, Sys: 8.0/8 GB (100.0%)
opt-sdp-no-mem-attention
Time taken: 1 min. 31.1 sec.
A: 9.21 GB, R: 9.81 GB, Sys: 8.0/8 GB (100.0%)
opt-sdp-no-mem-attention --medvram
Time taken: 1 min. 7.2 sec.
A: 7.19 GB, R: 7.35 GB, Sys: 8.0/8 GB (100.0%)
Или я дурак, или оно на самом деле на медврам быстрее?
Почему?
Да, быстрее, ибо медврам отключает предспросмотр, а он тормозной.
У меня чот получается, что SDP козявит детали на хвйрезе по сравнению с хформерами. Но большую выборку лень делать, так что может и рандом.
> Плохая карикатура, а не стиль.
Перетрен же.
Эта автоматика то ещё наебалово, точно также лр надо подбирать, просто другими рычагами. Прикольно что оно нанами не начинает сыпаться и может обучить всякой хуйне с которой Адам не справится.
Короче, продиджи с ди коефом 1 пробуй, констант вис вармап.
>Перетрен же.
Там плюс-минус одна фигня с 300-го шага, и до 3000.
Т.е. не ухватывает ни в начале, ни в конце, ни в середине.
Продиджи один раз пробовал, тоже ерунда получалась.
Какие там дополнительные параметры прикрутить, какой разогрев поставить?
У меня с дадаптом были такие проблемы, в данный момент продиджи с адамом сравниваю, очень похожие результаты дают.
>Какие там дополнительные параметры
Из статьи из шапки:
decouple=True weight_decay=0.01 d_coef=1 use_bias_correction=True safeguard_warmup=True betas=0.9,0.999
Разогрев на дефолтных 10.
Min SNR gamma по ощущениям срала в результат, выключил.
Сейчас смотрю последний тест и, судя по всему, разрешение очень сильно влияет на результат, на 512 бомбануло просто мгновенно.

Не знаю в какой тред писать, отпишу тут. Пытался поставить ControlNet для автоматика, он как то поставился неудачно и теперь при запуске ловлю такую ошибку. Попробовал пофиксить способом который писали на stackoverflow, не помогает. Думаю что ошибка в версии OpenCV, но я не знаю какая необходима для работы автоматика, потому что в requirements.txt репозитория его даже нет
Судя по всему у тебя какая то ошибка связанная с препроцессорами карт глубин, сам автоматик же последней версии? Лучше в самое репе вебуи контролнета насчёт такого кстати искать.
Аноны с 4080 есть?
25 ит\с на 4080 - это норм вообще?
>512х51
>эйлер_а
>masterpiece, best quality
>(worst quality, low quality, lowres, jpeg artifacts:1.4)
Что-то такое ощущение, что раньше скорость выше была...
25 ит\с на 4080 - это норм вообще?
>512х51
>эйлер_а
>masterpiece, best quality
>(worst quality, low quality, lowres, jpeg artifacts:1.4)
Что-то такое ощущение, что раньше скорость выше была...
> --no-half
> --no-half-vae
Зачем? Отключи их и заодно medvram убери.
С ошибкой попробуй активировать вэнв и вручную запустить установку реквайрментсов.
Конвертировал модель в TRT, получил ускорение с 11 секунд на генерацию картинки до 6 минут на генерацию. Успешен?
Сурово

Ещё как. В целом впечатление, что эта хуйня сыровата.
Удалось нормально конвертнуть 1.5 с генерацией картинки вроде бы быстрее, чем на голом автоматике. Но это сказывается только на генерации батчами из-за выгрузки-загрузки всей требухи, если генерить по одной картинке, то смысла нет. Запечь для генерации в фуллашди не удалось, причина на пике. Модель весит около 2 гигов. А запекать при использовании с апскейлом нужно в два разрешения - до апскейла и после. Хуй знает, как запеклась XL модель на 1024 разрешении, но мне, опять же, не хватает VRAM, из-за чего генерация длится около 6 минут. В шаред память эта хуйня не лезет принципиально.
> Но это сказывается только на генерации батчами из-за выгрузки-загрузки всей требухи, если генерить по одной картинке, то смысла нет.
Всё так.
> причина на пике
У меня кстати даже с оомами билдилось, правда я не фуллашди билдил а всего 1536х1024. Там в зависимости от твоей рам, подели её на два и столько шейред мемори будет, во время билда будет количество врам+этой шейред для билда доступно, если не хватит, то тут уж ничего не поделаешь.


По диспетчеру смотрел. В шейред не лезет вообще. В итоге с другой версией куды запеклось.
Генерация батчей 10 картинок 512х512 и в фулл ашди разрешении. Почти фулл ашди, на 8 пикселей по высоте больше из-за требований тензорной хуйни.
Итераций в секунду у меня мало, хуй знает, так и надо, или картонке пизда. Но их всегда мало, так что смысла смотреть на абсолютные значения нет, только в сравнении.
>если не хватит
Оно 136 гигов пытается выделить.
> По диспетчеру смотрел. В шейред не лезет вообще.
А вот у меня лезет во время запекания, причём не стесняясь, сразу куском так на 36гб, 24+12. А как у тебя в итоге получилось забилдить фуллашди, это же очень много пикселей, нихера не пролезет ведь, в куде дело? Какая тогда версия?

>вот у меня лезет во время запекания
Что крутишь кроме разрешения? У меня любой размер оптимального батча больше одного - сразу фейл. Подозреваю, что дело как раз в памяти. Ну и вот на пике запекается пятигиговая 1.5 модель на фулл ашди. Всё так же хочет 136 гигов, но в итоге печёт за две с половиной минуты и так. Лоры тоже нужно запекать, иначе не хочет работать. Короче охуенно, в два раза буст. Да, надо ебаться с разрешениями, или запекать под каждое, которое ты используешь, надо печь лоры. Но два раза.
>Какая тогда версия?
У меня 117 стояла, т.к 118 не работала с другой хернёй. Поставил torch 2.0.1+cu118 и, вроде, работает.
> Что крутишь кроме разрешения?
Да ничего вроде не крутил, к вечеру скину подробнее.
> У меня любой размер оптимального батча больше одного - сразу фейл
У меня 4 батч получался с 1536х1024, но батч 1 с 1536х1536 уже нет почему то. Батч вроде вообще не влияет на потребление памяти, я и не динамик пробовал пресет сделать, тоже фейл.
> Лоры тоже нужно запекать, иначе не хочет работать
Да, это херово, можно сразу несколько вмерджить в чекпоинт предварительно конечно, любой мерджилкой.
> Короче охуенно, в два раза буст. Да, надо ебаться с разрешениями, или запекать под каждое, которое ты используешь, надо печь лоры. Но два раза.
Чем лучше карта, тем хуже будет работать буст, с 4090 он только хуже сделает, переключение профилей между хайрезом и не хайрезом занимает какое то время. Если без картинка условно делается 10 секунд, то с трт даже чуть дольше, несмотря на буст итераций.
> У меня 117 стояла, т.к 118 не работала с другой хернёй. Поставил torch 2.0.1+cu118 и, вроде, работает.
Я вообще про системную куду спрашивал, а не про ту что в венве, в венве у меня такая же.
> с 4090 он только хуже сделает
Не пизди. У меня на хайрезах почти в два раза буст на 4090 с динамическим разрешением, статику можно не печь. Да даже если делать статику - переключение секунду занимает.

>можно сразу несколько вмерджить в чекпоинт
А нахуя? Печёшь лоры и не ебёшь себе голову.
>Чем лучше карта, тем хуже будет работать буст
Ну, у меня нищебродская 3080ti, так что местами буст в 2.5 раза.
>переключение профилей между хайрезом и не хайрезом занимает какое то время
Хуй знает, почти мгновенно. Опять же,
>Я вообще про системную куду спрашивал
А вот это сложно.
Затестил на одиночном пике, генерация 344 064 пикселей, потом апскейл до 2088960.
Без trt: Time taken: 2 min. 13.6 sec.
С trt: Time taken: 49.8 sec.
То есть даже при наличии всех переключений, trt ебать, как ускоряет.

Ну короче у меня было всё этими профилями засрано, создал один единственный, так действительно лучше, без переключений. Лоурез+хайрез+ад 38 секунд с трт, без 56.
> А нахуя? Печёшь лоры и не ебёшь себе голову.
А несколько как юзать будешь сразу?
> Хуй знает, почти мгновенно. Опять же
Да, тут с профилями обосрался сам короче. Вот просто с такими настройками собрал.
Ебать, ты зачем столько куд одновременно наставил разных версий то?
Я чисто на статике проверял. Не ожидал таких охуенных результатов. Надо динамику проверить, если так и будет х2, то вообще заебись.
>А несколько как юзать будешь сразу?
Лора печётся под чекпоинт, но если запек, то потом просто пишу в промпт, как обычно. Работает. Если не печь, то игнорируется полностью.
>ты зачем столько куд одновременно наставил
Так уж получилось, не хотела разная хуйня работать с одной кудой. Проверил, автоматик работает на 12.2
Напрягает оом на самом деле. Я так на XL вообще хуй забью, лол. Ещё заметил ошибку, если неправильно выгрузить trt модель, то потом на этапе VAE будет попытка выделить 30+ гигов VRAM.
Чувак, дримбут полторашки идёт уже и на 16 ГБ девять месяцев уж как...
Ну либо ADetailer
Сяп коллеге-линуксоиду!
Отвечаем: с 11 виндой не так то, что она не под GPL. Ещё вопросы?
Сяп, двач. Какие есть хорошие модели-полторашки для дримбута? Именно для дримбута. То есть я понимаю всю красоту и гибкость понятия лоры, но... треню я на колабе. Лороколабы я видел, однако дримбутный колаб от Шивама я успел хорошенько профоркать - там и половины не осталось от оригинала. Автопуш на обниморду в фоне, датасеты (концепт и реги) под гитом... Сейчас вот прикручиваю дедупликацию vae (оно ж не тренится) через хардлинки. Если получится - то можно будет держать не 9, а 10 промежуточных точек (включая итоговую).
Короче, чтобы воспроизвести всё это с лорами - трах тот ещё. Это первая причина.
Причина вторая - лоры я вообще-то пробовал, но получалась фигня. То есть - хуже, чем дримбут. Вроде как так и должно быть: лора тренится меньше времени, но даёт худший результат. Возможно, плохо пробовал.
Причина третья - я генерю не Автоматиком, а через библиотеку diffusers. В качестве профита - пока нет банов на гуглоколабе, да и с бесплатными HuggingFace spaces при умелом использовании API... ммм... А поддержку лор в diffusers завезли совсем недавно.
Итак, дрёмобудка. Вопрос: какие модели брать в качестве базовых?
Одна из самых удачных моих моделей - на основе AnythingV3 (причём в два прохода - сначала 6000 шагов, а потом новая модель как базовая и ещё 1200/2400/3600 шагов).
Flat2dAnimerge v2.0 - пока получается хтонь. Возможно, она в принципе необучаема, поскольку микс. Что ещё посоветуешь, анон, для 2д-рисовки в стиле 90х?
Тот же вопрос про реалистик-модели. ChilloutMix разок удалось натренировать так хорошо, что по некоторым генерациям ЕОТ её можно ВК найти поиском по лицу.
Короче, чтобы воспроизвести всё это с лорами - трах тот ещё. Это первая причина.
Причина вторая - лоры я вообще-то пробовал, но получалась фигня. То есть - хуже, чем дримбут. Вроде как так и должно быть: лора тренится меньше времени, но даёт худший результат. Возможно, плохо пробовал.
Причина третья - я генерю не Автоматиком, а через библиотеку diffusers. В качестве профита - пока нет банов на гуглоколабе, да и с бесплатными HuggingFace spaces при умелом использовании API... ммм... А поддержку лор в diffusers завезли совсем недавно.
Итак, дрёмобудка. Вопрос: какие модели брать в качестве базовых?
Одна из самых удачных моих моделей - на основе AnythingV3 (причём в два прохода - сначала 6000 шагов, а потом новая модель как базовая и ещё 1200/2400/3600 шагов).
Flat2dAnimerge v2.0 - пока получается хтонь. Возможно, она в принципе необучаема, поскольку микс. Что ещё посоветуешь, анон, для 2д-рисовки в стиле 90х?
Тот же вопрос про реалистик-модели. ChilloutMix разок удалось натренировать так хорошо, что по некоторым генерациям ЕОТ её можно ВК найти поиском по лицу.
Могу поспорить с тем, что завышенный CFG это всегда плохо. При тайловом апскейле с низким денойзом (0.2) поверх esrgan, высокий cfg (15) устраняет артефакты и добавляет детали, при этом не портя сэмпл.
>Что ещё посоветуешь, анон, для 2д-рисовки в стиле 90х?
Ну, если ищешь экзотики, то очевидно пробуй TrinArt Derrida и Waifu diffusion. Тринарт очень нежная хуйня, но может что и получится, WD хтоническое изначально, но потенциал есть. А так его величество NAI, конечно, какие тут варианты вообще.
Есть хорошие альтернативы этой параше?
https://github.com/innightwolfsleep/stable-diffusion-webui-randomize
Размер картинок козявит при попытке рандомить - ресайзит вместо того чтобы менять размер генерации - чекпоинтам неправильные названия в мете прописывает, ресайзер не меняет... Пиздец просто.
Находил один с китайскими домиками вариант, но там нельзя чекпоинты рандомить.
https://github.com/innightwolfsleep/stable-diffusion-webui-randomize
Размер картинок козявит при попытке рандомить - ресайзит вместо того чтобы менять размер генерации - чекпоинтам неправильные названия в мете прописывает, ресайзер не меняет... Пиздец просто.
Находил один с китайскими домиками вариант, но там нельзя чекпоинты рандомить.
Есть. Отправлять готовые реквесты в API, с рандомизацией в скрипте. Но я так делаю онлайн не локально
Может тебе будет интересно это https://github.com/KohakuBlueleaf/LyCORIS/blob/document/docs/Guidelines.md
С помощью либы ликорисов теперь можно хоть целый чекпоинт тренировать, если захотеть. А анон выше правильно заметил, лучше всего для 2д стиля будет наи, по крайней мере для лор.
Это для каломатика? Теоретически норм тема, куда гуглить?
Шлак. На civitai есть чекпойнты и лоры в стиле 90х.
мимо
Пользуюсь онлайн платформами. С каломатиком на компе должно тоже работать (не пробовал), но потребуется кодить на питоне, кури библиотеку requests.
Так не для лор, для дримбута.
Hyperworks вообще использую? Вкладка в webui есть, на civitai тоже категория есть. А моделей там нет
По качеству между эмбедом и лорой, обучать сложно пиздец. Нинужно.
Впечатления по тренировке на Civitai:
UI годнота, приятнее чем колаб
Трейнятся оче долго
Старым аккам дали по 500, новые получают 100 - этого недостаточно для одной лоры, но можно использовать ссылки для приглашения по 500 за акк.
Это тупо платная функция как в f2p онлайн игорях
UI годнота, приятнее чем колаб
Трейнятся оче долго
Старым аккам дали по 500, новые получают 100 - этого недостаточно для одной лоры, но можно использовать ссылки для приглашения по 500 за акк.
Это тупо платная функция как в f2p онлайн игорях
Никто не замечал, что запущенная генерация может программы в фоне выбивать?
В частности у меня периодически ФШ падает почему-то.
Неужели заполнение видеопамяти влияет? Так ФШ вроде не шибко много ее жрет (если вообще). Оперативки же более чем достаточно.
В частности у меня периодически ФШ падает почему-то.
Неужели заполнение видеопамяти влияет? Так ФШ вроде не шибко много ее жрет (если вообще). Оперативки же более чем достаточно.
С фотошопом не дружит сд, всегда так было. И вообще, он прилично видимокарту использует, если специально не выключить это в настройках.
Да в том то и дело, что как на 4080 переехал - так и началось.
На 2070 сидел - и ни разу не упало, всё в порядке было. А тут прям по нескольку раз за день.
> Hyperworks вообще использую?
Было актуально до появления лор, сейчас просто легаси.
Там, аниметедифф обновился. выдает такую ошибку:
2023-10-22 13:15:45,594 - AnimateDiff - WARNING - exiftool not found, required for infotext with optimized GIF palette, try: apt install libimage-exiftool-perl or https://exiftool.org/
Я немного не умный, как это установить так, что бы не сломать автоматик к херам?
2023-10-22 13:15:45,594 - AnimateDiff - WARNING - exiftool not found, required for infotext with optimized GIF palette, try: apt install libimage-exiftool-perl or https://exiftool.org/
Я немного не умный, как это установить так, что бы не сломать автоматик к херам?
Это же просто варнинг, можешь хуй забить.

Так прикол в том, что он должен фиксить цвета и повышать качество картинки, если верить описанию, вот поэтому и спрашиваю. Забивать на качество, это такое себе предложение.
Ты читать умеешь? Он там для мета-данных в гифке нужен.
> заполнение видеопамяти влияет
Влияет, жрет, вылетает причем странно. В настройках сними галочку "использовать графический процессор", тогда будет норм работать одновременно с сд.
Скачай готовый бинарник экзифтула по ссылке и пропиши его в path. Но прав, он для метадаты.
Понял-принял, спасибо, вразумили.
>"использовать графический процессор"
Какие-то функции поди отрубятся из-за этого?..
Блин, почему на 2070 с ее 8 гигами было нормально, а на 16 гигах вылеты начались?
У меня такое ощущение, что тут не само заполние влияет, а кто-то в драйверах или софте напортачил с распределением памяти. Куча обновлений ж с тех пор была. И ФШ я при переезде на новый комп тоже обновил.
В ФШ наговнокодили скорее всего. Под критичной нагрузкой от нейросетей если частоты слишком задраны - может происходить короткий "отвал" карты, большинство софта без проблем такое отрабатывают, просто мигают изображением. А особо конченый говнокод может падать от такого, хотя в доках директ икса требуют обрабатывать события "видеоадаптер отключён".
Да вроде частоты не гнал, как купил - так и поставил. Экран не мигает.
ЧСХ ФШ еще может "частично" отвалиться. Интерфейс глюкануть, например.
Или зум с перетаскиванием может отключиться (это когда ты кнопку зажимаешь, мышкой двигаешь, и картинка в зависимости от движения масштабируется).
Но в этих случаях хоть сохраниться нормально можно.
Ха, так оно и есть.
Отрубил использование видюхи - и теперь плавный зум по-умолчанию так себя и ведет. То бишь просто отсутствует =)
Значит действительно в работе ФШ с видюхой что-то не в порядке.
Как эти "отвалы" вообще можно зафиксировать, если они в наличии?
Видюха на гарантии, можно будет попробовать ее поменять.
Отрубил использование видюхи - и теперь плавный зум по-умолчанию так себя и ведет. То бишь просто отсутствует =)
Значит действительно в работе ФШ с видюхой что-то не в порядке.
Как эти "отвалы" вообще можно зафиксировать, если они в наличии?
Видюха на гарантии, можно будет попробовать ее поменять.
> Как эти "отвалы" вообще можно зафиксировать, если они в наличии?
Частоты GPU на 50-100 мгц понизь и посмотри как оно будет.
> можно будет попробовать ее поменять
Это не брак. Лучше ФШ верни в Адоб, вот там явно пидорасы сидят и говнокодят.
> Видюха на гарантии, можно будет попробовать ее поменять.
Ещё хочу заметить, что в любом стресс-тесте графики ты этого не увидишь. Заводской разгон может под стресс-тесты графики делали, а отвалы идут когда тензоядра подрубаются и нагрузка под соточку и ты дополнительно ещё ФШ врубаешь.
Версия фотошопа какая?
>Версия фотошопа какая?
25.0.0
>Лучше ФШ верни в Адоб, вот там явно пидорасы сидят и говнокодят.
Да понятно, что говнокод, но альтернативы не шибко удобные, да и привык я за столько лет к нему уже.
>Частоты GPU на 50-100 мгц понизь и посмотри как оно будет.
Попробую.
С торрента?
Похуй откуда, адобовские продукты отвратительно работают с аппаратным ускорением с того момента, как оно у них появилось. Что фотошоп, что премьер, что - особенно - афтерэффектс.
мимо
У меня с запущенным SD и загруженной в память SDXL всё прекрасно работает без вылетов и багов, даже если в шопе открыто несколько файлов, в каждом из которых по десятку слоёв.
Если у анона выше фотошоп торрент-эдишн, то скорее всего это кривой репак. У меня был такой, который рандомно вылетал при использовании фильтра ликвифай.
Конечно.
Баги у них везде одинаковые, впрочем.
>это кривой репак
Тоже не исключаю. Посмотрю, может чего поновее завезли.
У меня была лицуха на работе и она откисала ровно так же, как пиратка.
> дрёмобудка. Вопрос: какие модели брать в качестве базовых?
Буквально очевидный наи. Преимущество будет в том, что потом натрененное можно будет легко примердживать к любым другим моделям с помощью современных техник, а не фиксироваться на какой-то конкретной модели.
> Какие-то функции поди отрубятся из-за этого?..
Из дефолтного фотомонтажа и около того все работает. Может где-то поубавилось плавности и фильтры применяются чуть дольше, но не заметно. Со всякими 3д модельками внутри фш и прочей дичью - хз, но врядли тебе они интересны.
> а кто-то в драйверах или софте напортачил с распределением памяти
Там какую-то дичь наговнокодили с этим ускорением, что оно еще проблемы с интерфейсом или странные лаги само по себе может порождать. Так что забей, а на прошлой не вылетало потому что видюха не поддерживало нужное - соответственно и не использовалась в полной мере.
Полагаю если честно купить последнюю версию программы то таких проблем уже не будет.
> плавный зум по-умолчанию так себя и ведет
Пользуйся кнопочками возле, сочетаниями клавиш (самое адекватное), органами управления на планшете (если ты из этих).
> Видюха на гарантии, можно будет попробовать ее поменять.
Твой выбор.
А у тебя убунта или дебиан? В любом случае, не забудь перед этой командой sudo.
Зачем тебе некро формат gif?
>Полагаю если честно купить последнюю версию программы то таких проблем уже не будет.
Тут вон анон выше пишет, что точно так же падает.
Плюс Адоб очень жадный, и цены там совершенно конские. Ну их в жопу.
>Пользуйся кнопочками возле, сочетаниями клавиш (самое адекватное),
Неудобно.
> > дрёмобудка. Вопрос: какие модели брать в качестве базовых?
> Буквально очевидный наи. Преимущество будет в том, что потом натрененное можно будет легко примердживать к любым другим моделям с помощью современных техник, а не фиксироваться на какой-то конкретной модели.
Добра тебе, анон! Прошу просветить ещё про современные техники мёржа и где они обитают. Это просто Add Difference (какой уж он там современный - не меньше полугода ему, а то и 9 месяцев), который A + k*(B-C), или что-то хитрожопое типа block merge ?
Ля, щас бы на говнофотожопе сидеть, когда есть альтернатива в виде гимпа. Функционал тот же, разве что свистоперделок меньше. Зато весит в 100 раз меньше и не отваливается от каждого пука.
Шиндовс.
Так он удобнее. Поставил на конвеер тестовый промпт на разных моделях, потом смотришь через "просмотр изображений" клацаяя клавишу влево. С MP4 или WEBP ты нихуя не поклацаешь, их каждый раз по отдельности открывать надо, а мне лень, плюс гифка зациклена, а видос стопорится. Но это не мешает мне сохранять во всех форматах сразу. Говно удалил, нужное залил на сайты.
> что точно так же падает.
Он пишет что в какой-то момент отслеживал одинаковые баги как в пиратке так и в лицензии. Фотожоп сам по себе глючный, но для начала стоит устранить прочее фактоы.
> Неудобно.
Выцеливать ползунок удобнее чем нажать альт и крутануть колесо, или провести пальцем по области?
Ууф, в наи несколько тредов назад достопочтенный господин делился своим опытом и рекомендациями, нужно найти этот пост. Там и несколько ссылок было, сейчас новые методы добавили.
> что-то хитрожопое типа block merge
Это уже искать надо, не подскажу.
> щас бы на говномайбахе ездить, когда есть альтернатива в виде 50кубового мопеда.
Починил тебя
> потом смотришь через "просмотр изображений" клацаяя клавишу влево
Шиндовский просмотрщик уже давно умеет во все эти форматы нативно, и под прыщи тоже были совместимые.
>Выцеливать ползунок удобнее чем нажать альт и крутануть колесо, или провести пальцем по области?
Да не. Зум ж без ползунка. Зажимаешь кнопку, двигаешь вправо-влево - и картинка уменьшается/увеличивается.
Если поддержку видюхи вырубить - оно не работает. При зажатии у тебя начинает рамка образовываться, в которую ты условный зум хочешь сделать.
Я наверно медленный, но:
https://latent-consistency-models.github.io/
Дистиляция моделей SD за 32 А100-часов. Дистилированная модель работает раз эдак в 5 быстрее.
https://github.com/rupeshs/fastsdcpu
демка от индуса на ЦПУ, действительно работает.
самому подистиллировать, что ли? кто-то вроде собрался это реализовывать для имеющихся уёв
только по ходу контролнеты тоже заново надо обучать будет, и всё остальное
https://latent-consistency-models.github.io/
Дистиляция моделей SD за 32 А100-часов. Дистилированная модель работает раз эдак в 5 быстрее.
https://github.com/rupeshs/fastsdcpu
демка от индуса на ЦПУ, действительно работает.
самому подистиллировать, что ли? кто-то вроде собрался это реализовывать для имеющихся уёв
только по ходу контролнеты тоже заново надо обучать будет, и всё остальное
>Как в теории допилить SD до уровня Dall-e 3?
Заземлить на хорошую языковую модель, как это было сделано в DF IF. У того гугловская LLM на 11B параметров, и он вполне себе понимает довольно сложные промпты уровня "koi fish doing a handstand on a skateboard". Да и в самом далле 3 похоже сделано, только он ещё и обучен на развёрнутых GPT тегах и инференс идёт на них же, что очевидно по его фривольностям.
А вообще понимание промпта и продвинутый текст-ту-имадж - тупиковый путь. Текстом всё равно многого не сделаешь, или сделаешь но долго. Локальную модель нужно дрочить под лёгкость обучения и управления хинтами высшего порядка (например скетчами). Это гораздо проще, см. контролнеты и адаптеры, и результат лучше и быстрее работает. Пусть даже унет будет сильно дистилированный, и понимает мало высокоуровневых концептов - но чтобы хорошо обучался и следовал контролнету. Тогда можно будет и на ёлку влезть и жопу целой оставить.
Точнее даже не обучение, а обобщённо - трансфер стиля и концептов. Обучение это лишь один из вариков сделать это
Неутешительные результаты долгих слепых тестов в том, что адам с наотъебись выставленным лром ебёт продиджи в рот снова и снова. Снова и снова. Снова и снова.
Даже когда получается подойти к очень близким выхлопам.
Даже когда получается подойти к очень близким выхлопам.
Смотрите какие чудеса.
https://github.com/PixArt-alpha/PixArt-alpha
Заявляют результаты на уровне SDXL при унете в 600 млн параметров (правда трансформер на входе большой) и смешных 25млн картинок в датасете, тренировка стоила всего $26к. Всё это за счёт мультимодальности, хорошо отфильтрованного и протегированного датасета (не забываем что LAION был натурально мусорного качества).
Пиздят или нет, думаю что в ближайшие несколько месяцев все наши эксперименты с обучением лор глубоко устареют, если фундаментальные модели уже становятся доступными небольшим конторам.
https://github.com/PixArt-alpha/PixArt-alpha
Заявляют результаты на уровне SDXL при унете в 600 млн параметров (правда трансформер на входе большой) и смешных 25млн картинок в датасете, тренировка стоила всего $26к. Всё это за счёт мультимодальности, хорошо отфильтрованного и протегированного датасета (не забываем что LAION был натурально мусорного качества).
Пиздят или нет, думаю что в ближайшие несколько месяцев все наши эксперименты с обучением лор глубоко устареют, если фундаментальные модели уже становятся доступными небольшим конторам.

> щас бы на говномайбахе ездить, когда есть альтернатива в виде 50кубового мопеда.
> в ближайшие несколько месяцев все наши эксперименты с обучением лор глубоко устареют
Так или иначе. Будет всё с одной картинки обучаться в одно касание, так чтобы последний полуслепой кумер справился.
Ну или хайп на днях резко прервётся, что называется в самый неожиданный момент, и мы останемся с удивлением и тем что есть.
> без ползунка
> кнопку, двигаешь вправо-влево
Дай угадаю, та кнопка и есть ползунок?
Не пробовал менять датасет на разных фазат обучения?
> эксперименты с обучением лор глубоко устареют, если фундаментальные модели уже становятся доступными небольшим конторам
Почему? Какой для этого повод и связь с обучением каких-то моделей конторам, что готовы раскошелиться на десятки дысяч денег?
Ip-адаптер, референс и прочие уже есть
>Ip-адаптер, референс и прочие уже есть
Пока это скорее игрушки, они довольно тухло работают и не умеют хорошо выхватывать то что ты хочешь с одной пикчи. Чтобы зерошот по одной пикче работал приемлемо, нужны гораздо более дрочные методы, чтоб оно анализировало пикчу всерьёз как GPT-4V, и ты ему подсказывал что именно ты хочешь ухватить (например промптом).
> Не пробовал менять датасет на разных фазат обучения?
Нет. А что будет? Какой юзкейс?
Webp то почему нет?

Почему соевым индусам так хочется привести генерации к правому говну? Это же литералли главная проблема SDXL, а оказывается эти дегроды специально такое делают.
Потому что иначе их отменят.
> чтоб оно анализировало пикчу всерьёз как GPT-4V
Анализировать уже сейчас можно, есть разные модели. А вот чтобы из этого еще взять да и в управление контролнетом перекинуть - это уже мультимодалки нового уровня. В принципе с развитием того же ip адаптера можно, но там модель окажется больше чем сд.
Обучить что-то специфическое не ломая. Столько дрочева с лр, оптимизаторами и прочим, а сегментирование датасета не смотрят, хотя сейчас при обучении моделей этому не последнее внимание уделяют и в кохе возможность продолжить обучение есть.



Это всё из-за говнозеркалок. Там типа модно делать ультрахуёвую глубину резкости.
>Обучить что-то специфическое не ломая.
Так оно всё равно ломать будет, хоть обучение аля дримбут, хоть лоры. Всё одно это пердолинг с параметрами, датасетами и прочим.
>Обучить что-то специфическое не ломая.
Ну, практический пример, практический. Мы тут и без сегментирования учим специфическому не ломая.
>та кнопка и есть ползунок?
Да кнопку мыши же. Включаешь инструмент зума с хоткея, и у тебя на одну-единственную ЛКМ сразу оба направления зума привязаны - и вниз, и вверх, в зависимости от того, куда мышкой двинешь.
Тогда как без этой штуки тебе надо либо инструмент зума переключать, либо через пкм масштаб сбрасывать и зумить заново на конкретный участок, либо тот самый слайдер где-то в интерфейсе искать.
Потому что формат говна, и вдобавок в нем серьезную уязвимость недавно обнаружили.
Ну, с учетом дефолтного юзкеса лоры и сильно ограниченного датасета это не сильно актуально. Разве что для определенных концептов или специфичных стилей где обучение с нарастающей сложностью (читай постепенное повышение отклонений от того что модель уже умеет а не сразу с двух ног смягчив вармапом), ну и для будки, всеже интересно посмотреть подобное.
Не ломая - вон ту же самару взять фон и местами анатомия вышли из чата. Можно компенсировать меняя вес лоры, используя обработку и прочее, но это борьба со следствием а не причиной.
Вот где могло бы хорошо сыграть - с файнтюном того же xl.
Офк не факт что это окажется целесообразно, просто в рамках размышлений, а то столько пердолинга с одним а другое игнорируем.
Да, прикольно. Но alt+скролл или сенсорная полоска как-то нативнее и работают без гпу ускорения.
Инсайд из дискорда: в SD 3 вместо CLIP будет BLIP.
Но справа выглядит пизже
>Текстом всё равно многого не сделаешь, или сделаешь но долго
Текстом или нет, главное чтобы все было автоматическим и делалось батчами. Руками я и сам на планшете в графическом редакторе нарисовать могу.
> модно делать ультрахуёвую глубину резкости
2012, вроде, давно позади
А еще на говнозеркалки принято делать перспективу уебищную, чтобы лицо было как бы вывернутое, как блин
Это когда на телевик за 10 килобаксов снимают, еблет плоский/жирный получается на 300мм фокусном.
А какой смысл в trt, если есть AIT, который работает с лорами без необходимости что-то с ними делать и где не надо модель в onnx переводить?
Проверил производительность - они одинаковое ускорение дают, как минимум на тех разрешениях и батчах, что я обычно использую.
Проверил производительность - они одинаковое ускорение дают, как минимум на тех разрешениях и батчах, что я обычно использую.
Ты наверное на сральном ведре сидишь, раз AIT у тебя по скорости как TRT. А вообще забавно наблюдать как пользователи SD не проходят базовый тест на интеллект и не могут нормально сконвертить модель даже с подсказками на экране.
> AIT у тебя по скорости как TRT
Возможно потому что я с SDXL работаю обычно. Типа 1024х1024 батч из 4, 30 шагов dpmpp_2m. 8 секунд что с TRT, что с AIT.
Про tensorrt пишут что с ним работает медленней чем без, при включённом medvram-sdxl. А жаль, это было бы единственное ему применение
Я, кстати, medvram-sdxl не врубал, это без всех оптимизаций каломатика по памяти для sdxl. А AIT я в комфи запускал, тоже без каких-то особых трюков.
Скетч нарисовать в разы быстрее и точнее, чем крафтить строку ебучую, в итоге не получив в точности то что нужно. У текста просто нет столько семантической ёмкости, сколько есть в простом наброске от умеющего рисовать чела, который понимает динамические позы, анатомию, светотень и т.п.
>Руками я и сам на планшете в графическом редакторе нарисовать могу.
В этом случае 95% времени займёт рендер. Скетч или тегированная 3Д геометрия на разных слоях, обрисованные моделью, куда быстрее.
>tensorrt
Эта штука крайне требовательна к vram, так как, по сути, отрубает шаред мемори. Если тебе не хватает vram, то идут лютые замедления, на моём ведре trt от 3 до 6 раз медленее, чем без него. На sdxl, само собой. Проверил с флагом medvram-sdxl, euler a, сто шагов, разрешение 1024. TRT медленнее ровно в пять раз, с ним расход памяти ушёл в потолок. Без него расход 8гб ровно, памяти хватает с запасом. Возможно если у тебя 3090\4090, то буст будет. Ну и сам trt не работает при включении xformers, хотя он, по моим тестам, даёт буст в районе погрешности.
Быстрее, но качество ниже. Но ты во всём прав, конечно, это так, для справедливости.
На SDXL прироста никакого. C SDP у меня скорость генерации 6.42 it/s Euler A 1024x1024 150 steps. C TRT при тех же параметрах 5.85 it/s, и расход VRAM 22.7 Гб, лол.
А вот на полторахе уже другое дело — с SDP батч из 4 картинок 512х768 Euler A 150 steps 6.57 it/s, расход памяти 5.2 Гб. С TRT 9.27 it/s, расход памяти 6.8 Гб.
Но заёбывание с конвертацией моделей, очень ограниченная поддержка лор и хайрез фикса, и отсутствие поддержки контролнетов пока что рубят всю идею на корню.
мимо-4090-боярин


Не прогромист итт. Хочу попробовать научить лору. Помогите найти терминатор. Жалуется на 369 строчку 4 символ (2 пик), то есть на "p"
В гугле ничего похожего не нашел.
В гугле ничего похожего не нашел.
А как долго конвертируется модель на 4090? Если достаточно быстро, типа секунд 30, то можно рм предложить сделать автоконвертацию с кешированием
А в сфере генерации картинок что то круче и прорывнее SD вышло? Или все крутое основано на нем?
Gigagan 1 раз видел, но после ничего не слышал о нём
Диффузия по всем метрикам ебёт GAN. Сейчас уже кроме генерации другие задачи с GAN на диффузию начинают переводить. Например восстановление изображений или супер-резолюшен уже только в диффузии имеют какой-то прогресс за этот год, из недавнего - IR SDE. Все попытки вернуться к однопроходной генерации мертворожденные, буквально движение назад, только для нищежелеза имеют смысл чтоб получить больше скорости ценой качества.
GAN в целом работают, но с трудом управляются и при тренировке и при инференсе. В них вложили дохуя усилий и годами ебались с шаманством с гиперпараметрами, пока не поняли что это тупиковый путь из-за капризности. Стоило придумать диффузионный процесс и восстановление из шума, как всё попёрло при минимальных усилиях.
Диффузия не единственный способ генерить пикчи. Есть ещё визуальные трансформеры, например Stable unCLIP тренировано на эмбеддингах из такого. Есть RNN, разные другие аналоги из физики, например электростатика вместо термодинамики у диффузии. Но в реальности все юзают диффузию. Диффузионная сетка это не единственный компонент реальной модели конечно, понимание инпута требует языковой модели (для промпта) или чего-нибудь управляющего типа контролнета, перевод в/из латентного пространства требует автоэнкодера (которые кстати могут и независимо использоваться для генерации), и т.п., всё это пытаются стакать вместе с переменным результатом.

Ещё одна проблема с TRT это размер. Все ваши модели удваиваются. И вот этот файлик на 1.6гб - это лора, которая изначально весила 144 мегабайта.
Ну вот поэтому мне и кажется, что AIT все же перспективней, несмотря на то, что с ним куча своих приколов. Все же вот эта перегонка моделей- то какая-то фигня и не будет работать с тем как обычно народ с моделями работает.
Как я понял недавно вышедший LCM, который за 32 часа a100 запечатывает семплер, зажопили? Нигде не нахожу код для тренировки. Нашел максимум на гитхабе сообщение от создателя, что он другие модели планирует сконвертировать
Все же странный выбор изначальной модели: dreamsharper v7. Автор сомнительный, для xl модели он просто Лору вмержил в базовую модель
Все же странный выбор изначальной модели: dreamsharper v7. Автор сомнительный, для xl модели он просто Лору вмержил в базовую модель
Тебе уже объяснили что результаты там говно, надо черрипикать чтоб не было пиздеца. Поэтому и кода нет никакого.




> LCM
Ммм, жидкое говно, как же хочется. Жаль только выглядит оно хуже ванильного SD 1.4, даже если оба на 10 шагах сравнивать. Квантование или дистилляция даже лучше выглядят чем это.
Автор в дискорде говорит что код будет когда XL модель конвертнёт в LCM.
>просто Лору вмержил в базовую модель
Потому что лора как таковая не работает с LCM. Оно запекает итерации в дополнительную нейросетку, в этом вся суть. Поэтому лору придётся либо вмёрживать, либо пользоваться файнтюном LCM через описанный в пейпере способ. Контролнеты тоже надо реализовывать заново (как минимум тренить). И т.п.
Я про не LCM, а просто dreamsharper xl. Там в комментах один чел выяснил что это просто мерж с лорой, выдаваемый якобы за чекпойнт. И вычленил его, можно скачать отдельно
https://civitai.com/models/112902/dreamshaper-xl10?commentId=274242&modal=commentThread
Короче создатель dreamsharper - это инфоциганин. Почему выбрали его модель для основы, не понятно
>Почему выбрали его модель для основы, не понятно
Да просто авторы яйцеголовые математики, вряд ли они следят за всей этой драмой на сайте для дрочеров, скорее всего они тупо ткнули в первый попавшийся популярный чекпоинт с красивыми картинками и прогнали свой скрипт на нём.
Яйцеголовые выбрали бы стандартную официальную модель, а не васяномерж.
Яйцеголовые стремятся к публичности и демкам, это добавляет видимости и цитат. Публикуйся или умри. Базовая модель хуйня, в любом случае васянщину пришлось бы брать, чтобы привлечь внимание. Вот сейчас автор в дискорде спрашивает какую модель конвертить следующей (ему отвечают базовую SDXL или какую-нибудь лору/файнтюн на XL)
Вот зря вы ненавидите все стандартную модель. Она обучена на миллионах изображений, а все, основанные на ней - это дообученные файнтюны на всего нескольких тысячах картинок
Честно говоря не понятен этот хейт на XL! У нее есть уйма преимуществ
- Больше параметров, больше генерализации, поэтому любые концепты (в т.ч. nsfw) подхватывает с полуоборота.
- гораздо сильнее в "чтении" промптов, так что для нее не нужно повторять дважды или писать громоздкие негативы. Что написал, то и получишь.
- трудность в трейнинге лоры вознаграждается более высоким качеством. Лоры для реализма пригодны также для мультов чмонимэ и наоборот.
- Больше параметров, больше генерализации, поэтому любые концепты (в т.ч. nsfw) подхватывает с полуоборота.
- гораздо сильнее в "чтении" промптов, так что для нее не нужно повторять дважды или писать громоздкие негативы. Что написал, то и получишь.
- трудность в трейнинге лоры вознаграждается более высоким качеством. Лоры для реализма пригодны также для мультов чмонимэ и наоборот.
Гоняю XL уже с недельку, хуй знает, хейтить её особо не за что. У меня только две претензии - ей абсолютно поебать на твой промпт, она всё равно проигнориует всё, кроме пяти-шести кейвордов. И тут нельзя исправить дело :1.0 или скобочками. Нужно брать важный кейворд и копипастить в промпт 3, 4, 5 раз. Но никакой гарантии не даёт. И второе, это мыло ебаное.
>Честно говоря не понятен этот хейт на XL!
1. Проебали порнуху
2. Вместе с порнухой проебали анатомию
Ну и общий тренд на вырезание порно из базы залуживает только урины в лицо.
Стабилити и опенаи - based, дрочеры должны страдать. Не, ну попены говно, но по другой причине
Это вопрос скилла, у меня всё подхватывает.
Имеет ли смысл тегить LLaVA'ой пикчи для файнтюна? (примерно 10к пикч) Для лоры? (на ~100 пикч)
Будет ли качество выше от такого теггинга?
Будет ли качество выше от такого теггинга?
Так это недостаток XL, что к ней требуется какой-то особый скилл. Когда с 1.5 всё заебись, а для XL такие промпты не годятся.
Свои мастерписи для полторашки прямо с первого раза правильно писал?
Загуглил рабочие теги, если не работают - сделал скобочки или 1.0. XL на это похуй, гарантированно рабочих команд тупо нет.
Не знаю, пока мне кажется что по анатомии файнтьюны SDXL вполне на уровне. Плюс понимание промптов и когерентность у неё на высоте. SD1.5 не может даже нарисовать нормально сидящую девушку в комнате, если не роллить как угорелый. Либо анатомия кривая, либо кресло плывёт, либо место комнаты на фоне какое-то неконсистентный мусор. А с SDXL - вообще проблем нет, с первой попытки по сути.
SDXL - это не NAI-based модель, она не понимает теги с данбуры, ей надо писать обычный человеческий текст, она с ним куда лучше справляется чем с другими вариантами. Если с этим руками плохо выходит, то можно юзать трюк из пейпера DALLE-3 и просить LLMку улучшить и дополнить свой промпт эпитетами, это на эстетику в положительную сторону влияет.
Даже ультрадетализированный содержательный фон с перспективой без мыльца можешь?
Нет, возможно ее файнтюны откуда еще им взяться с этим бы справились, но сама херь выдаст.
Мыло видел только в niji journey и ранней модели от Linaqruf, а чтобы убрать, достаточно написать в negative, + добавить лоры, и всё. Сэмплер euler может иногда делать мыльно.
На фон и детали есть лоры slider, adjuster, хотя и без них выходят годные. Мне вообще норм и с мылом.
Вопрос - есть ли какая-нибудь хитроёбаная метода, чтобы задать SD референс одним изображением, но при этом указать какие именно фичи из него извлекать? Что-то типа IP-Adapter, но чтобы например можно было промпт вписать "такой-то объект" или "такой-то цвет", или "текстура асфальта", и он извлечёт это и использует как референс.
А то все методы что я пробовал, извлекают всякую рандомную херню, но только не то что мне нужно. Может попробовать потренить кастомные IP-Adapterы? Там 22 млн параметров всего, по идее не должно быть слишком дрочно
А то все методы что я пробовал, извлекают всякую рандомную херню, но только не то что мне нужно. Может попробовать потренить кастомные IP-Adapterы? Там 22 млн параметров всего, по идее не должно быть слишком дрочно
Короче я почитал пейпер IP-Adapters и они говорят что эта шняга должна быть генерализуемой, т.е. управляться с основного промпта (или что там у тебя вместо текста выдаёт кондишионинг). Типа, если в промпте есть "велосипед", и в референсе нарисован велосипед, он будет склонен его рисовать как в рефе.
В общем если подумать оно действительно плюс-минус так и работает, но видимо пока недостаточно хорошо, нужно мутить ещё какую-то более сложную штуку для переноса концептов с рефа.
inpaint by example?..
>inpaint by example
А это как?
В любом случае вот например мне надо текстуру сменить у объекта с кожи на мех, или поменять форму с круглого на квадратное - инпеинт с таким не справится, тут нужен именно перенос концепта. Ну или лора/полноценный файнтюн, но там совсем другие заморочки
Кто-нибужь уже ковырял конфиги ультимейт СД апскейлера? Если да, то где в его ебенях стоит ограничение Target size type на 8192 пикселей и размер тайла с ограничением 2048? Если в 16к генерить, тайлы настолько крохотные выходят, что лезут артефакты.
inb4: Tiled Diffusion корраптит цвета, а ждать рендер, что бы поменять настройки и снова ждать, не вариант.
inb4: Tiled Diffusion корраптит цвета, а ждать рендер, что бы поменять настройки и снова ждать, не вариант.
Файл ultimate-upscale.py, строки 453,454,463,464
> и размер тайла с ограничением 2048
Для 1.5 уже в таком размере херь, а ты еще больше хочешь, не факт от артефактов получится избавиться или не получить другое. Но всеравно по результатам отпиши что вышло.
> Tiled Diffusion корраптит цвета
Контролнет, постобработка в крайнем случае, в tiled vae сними галочки быстрого энкодера/декодера. Алсо для 16к там оче много рам потребуется.
Это не автоматиком делается, это отдельный проект годичной примерно давности на обниморде.
Аноны, нужна ваша помощь. Хочу создать свою LoRA, но получаю ошибку.
Двач жалуется на спамлист, залил на пастбин https://pastebin.com/8jLgBg0N
Во-первых, что у тебя за дрисня вместо скриптов кохи? Во-вторых, он пиздит что у тебя версии пакетов не те.
>что у тебя за дрисня вместо скриптов кохи?
>он пиздит что у тебя версии пакетов не те
Я сделал git clone, потом запустил setup.bat. Он должен был установить нужные скрипты и зависимости.
Только сейчас понял, что установил github.com/bmaltais/kohya_ss вместо того что из шапки.
Но он есть в шапке.
Тогда почему он не работает? Я сделал все те немногие шаги что указаны в readme репозитория.
> NVIDIA GeForce GTX 1080 Ti
> use 8-bit AdamW optimizer
Эта карточка не поддерживает этот оптимизатор. Попробуй "Lion"
А, помню это. Ну это тоже зеро-шот экстрактор фич, да, их много (IP-Adapter, reference controlnet и т.п.), просто этот почему-то так и не достиг ни автоматика, ни комфи. Мне надо чтобы можно было указывать, что именно он будет брать из референса. Например прописываешь ему "эйфелева башня" и он копирует из референса эйфелеву башню. Прописываешь "композиция" и он копирует из референса композицию и пытается её применить. Прописываешь "текстура кирпича" и он берёт оттуда именно эту кирпичную стенку и пытается её всунуть в результат.
IP-Adapter пользуется на входе визуальным трансформером, распознающим концепты на пикче, и в принципе так и работает. Но через пень-колоду, потому что трансформер вытаскивает сразу все фичи что может, а ты потом задаёшь веса этого всего через кондишионинг. Нужны более дрочные методы и более качественные модели для распознавания.
Спасибо анон. Абсолютно неприметная для меня опция, о которой никто не говорит.
Начал обучение для теста, не выбирая никакие дополнительные опции, из 24 картинок вышел файл на 9 мегабайт. Stable Diffusion его не видит.
Будущее - за мультимодальностью, dall-e 3 тому подтверждение.
ИИ следующего поколения будет понимать натуральный язык без тегов и токенизации, создавать по описанию + рефам любую пикчу и дорабатывать её по следующим уточнениям. Вспомните как в SD 1.5 пишешь red hair, blue eyes - а сэмплер делает наоборот, потому что в данных такая комбинация встречалась чаще. И добавляет эти цвета на другие детали. Совершенно костыльная архитектура, чисто на уровне обработки статистики.
ИИ следующего поколения будет понимать натуральный язык без тегов и токенизации, создавать по описанию + рефам любую пикчу и дорабатывать её по следующим уточнениям. Вспомните как в SD 1.5 пишешь red hair, blue eyes - а сэмплер делает наоборот, потому что в данных такая комбинация встречалась чаще. И добавляет эти цвета на другие детали. Совершенно костыльная архитектура, чисто на уровне обработки статистики.
Теперь увидела лору. Странно что не с первого раза. Результат впечатляет: я не вводил никаких настроек но с третьего раза получил более-менее приличную картинку.
>вместо скриптов кохи?
Лол, какие скрипты, когда на civitai есть такая-то годнота. За приглашенного юзера дают на двоих 1200 баллов (два трейнинга), так что приглашаю себя сам и еще сам себя лайкаю (кукущка хвалит петуха, лол)
мимо шел
>увидела
Ты знаешь правила, сиськи (не нейронные) или пошла нах отсюда
>Будущее - за мультимодальностью
Ты хотел сказать настоящее? Мультимодальные сейчас все новые модели, больше того датасеты даже пошли чисто синтетические уже. (пиксарт обучали на синтетике)
>создавать по описанию + рефам любую пикчу
Так оно давно уже есть, с добрым утром. Зеро-шот обучение и экстракторы фич это оно и есть. BLIP и ViT энкодеры, IP Adapter (самый продвинутый и контролируемый из всех), reference controlnet, paint by example, куча их. Они в зачатке, но работает, вон в SD треде аноны дракона со свиньёй скрещивают безо всяких лор.
>Вспомните как в SD 1.5 пишешь red hair, blue eyes - а сэмплер делает наоборот, потому что в данных такая комбинация встречалась чаще. И добавляет эти цвета на другие детали. Совершенно костыльная архитектура, чисто на уровне обработки статистики.
Это не "костыльная архитектура", это хуёвый датасет LAION и хуёвый текстовый энкодер CLIP. А "обработка статистики" это и есть интеллект, это было главное открытие NLP сделанное ещё 10 лет назад.
Достаточно просто юзать хороший датасет и приличный трансформер на входе, что показывает пиксарт, у которого понимание вполне приближается к далле, при этом тренирован он за копейки.
Пиксарт это конечно хорошо, но трансформер на 4 c хуем лярдов параметров это пиздец немного.
Там 11млрд, тот же самый что в DeepFloyd IF был (T5 гугловский). И этого вполне достаточно для отличного понимания промпта, ему же не рэп-батлы Шекспира и Гомера писать, он заземлён на датасет из пикч высокого качества, и используется лишь в качестве второй моды диффузионной модели, выдавая кондишионинг для неё.
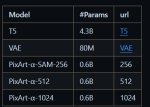
> Там 11млрд
где
> приличный трансформер на входе
>Inference requires at least 23GB of GPU memory
Очень вкусно (нет)

Нэ понел. Там же ссылка стоит на T5 1.1 XXL, а он 11 млрд.
https://github.com/google-research/text-to-text-transfer-transformer/blob/main/released_checkpoints.md
Это же требования говнокода яйцеголовых, им лишь бы влезало на A100. SD вначале требовал 12 кажется ГБ, и со скрипом запускался на 10. Большую часть этой памяти занимает трансформер, его квантизованным до 4-8 бит надо запускать, а не в сыром виде. Или вообще на ЦПУ. Можешь помацать ноду для ComfyUI, там уже есть поддержка, правда сырая.
Я читал обсуждения про тренировку на разных сэмплерах, мол, модели тренированы на одних, мы пользуемся другими. Так это, у кохи можно сэмплер сменить? Чот я не видел рычага на сэмплер, на чём он тренируется?
> тренировку на разных сэмплерах
Семплер - это реверс стохастического распределения. Они не используются при тренировке.
Эксперт по лорам для XL1.0 врывается в тред. Поясняю по теме всё как есть, что для чего.
Лоры могут быть легковесные (один определенный предмет, либо один персонаж) или тяжеловесные (стиль одного рисоваки, какие-то технические особенности для изображений). В первом случае бывает достаточно 32 dim / 16 alpha, иначе будет чрезмерно обученная (повторяющая одно и то же). Во втором, нужно как минимум 64 / 32, а лучше сразу 128 / 64, иначе толком не схватит стиль. Лучше лора весом в гигабайт но годная, чем весом в 30 мегабайт, но кривая. 128/16 не советую, сразу начинает срать под себя из-за высокого learning rate. Самое главное в МЛ это параметры моделей, благодаря которым ИИ условно "знает" что-то и "понимает" что-то - но у параметров должен быть и высокий КПД без мусорных нейронов.
Больше данных = лучше, для XL в особенности. Не верьте мудакам, кто рассказывает как они запилили годноту из 5-6 образцов - с таким же успехом можно использовать одну пикчу в контролнете. Попробуй подборку из 16 пикч, и в самом начале трейна будет оверфит: модель будет воспроизводить только один и тот же образец из датасета и больше ничего. 30 необходимый минимум, для персонажа лучше 60-100, для своеобразных стилей может не хватить и нескольких сотен.
Лучший способ подготовки данных - тащить с Danbooru программой imgbrd-grabber для винды, для этого нужно зарегаться и получить токен. Можно качать с Gelbooru, но там хуевые теги,+ не работает сортировка по качеству или дате). Метаданные сохранять как Separate log file, потом вручную (скриптом) добавить ключевое слово в начало каждого txt. Если модель уже знает этот предмет, то используй реальное название, а если нет - придумай короткое несуществующее слово. В настройках тренировки включить рандомное перемещение тегов, кроме переднего слова. Тогда лора будет лучше понимать, что на пикчах главное и что второстепенное. Иногда неплохо срабатывает добавление реальных фотографий в манямэ датасет (получится универсальная модель), но описания для них не обязательно основывать на той же системе тегов.
Лоры могут быть легковесные (один определенный предмет, либо один персонаж) или тяжеловесные (стиль одного рисоваки, какие-то технические особенности для изображений). В первом случае бывает достаточно 32 dim / 16 alpha, иначе будет чрезмерно обученная (повторяющая одно и то же). Во втором, нужно как минимум 64 / 32, а лучше сразу 128 / 64, иначе толком не схватит стиль. Лучше лора весом в гигабайт но годная, чем весом в 30 мегабайт, но кривая. 128/16 не советую, сразу начинает срать под себя из-за высокого learning rate. Самое главное в МЛ это параметры моделей, благодаря которым ИИ условно "знает" что-то и "понимает" что-то - но у параметров должен быть и высокий КПД без мусорных нейронов.
Больше данных = лучше, для XL в особенности. Не верьте мудакам, кто рассказывает как они запилили годноту из 5-6 образцов - с таким же успехом можно использовать одну пикчу в контролнете. Попробуй подборку из 16 пикч, и в самом начале трейна будет оверфит: модель будет воспроизводить только один и тот же образец из датасета и больше ничего. 30 необходимый минимум, для персонажа лучше 60-100, для своеобразных стилей может не хватить и нескольких сотен.
Лучший способ подготовки данных - тащить с Danbooru программой imgbrd-grabber для винды, для этого нужно зарегаться и получить токен. Можно качать с Gelbooru, но там хуевые теги,+ не работает сортировка по качеству или дате). Метаданные сохранять как Separate log file, потом вручную (скриптом) добавить ключевое слово в начало каждого txt. Если модель уже знает этот предмет, то используй реальное название, а если нет - придумай короткое несуществующее слово. В настройках тренировки включить рандомное перемещение тегов, кроме переднего слова. Тогда лора будет лучше понимать, что на пикчах главное и что второстепенное. Иногда неплохо срабатывает добавление реальных фотографий в манямэ датасет (получится универсальная модель), но описания для них не обязательно основывать на той же системе тегов.
> Лучший способ подготовки данных - тащить с Danbooru
Говно с бур - буквально худший датасет. Особенно если там каша из 20+ тегов. Нахуй иди с такими советами.

Так что там, обновлять драйвер или нет? Сколько уж времени прошло-то.
https://github.com/vladmandic/automatic/discussions/1285
https://github.com/vladmandic/automatic/discussions/1285
Да сразу обновлять надо было. Шаред мемори контролируется на уровне приложения это раз, память освобождается при любом из medvram флагов в том же автоматике. Никаких минусов нет.
Замедление итераций\сек в несколько раз норм что ли?
Если кончилась память - норм, лучше чем перезапуск автоматика. Если не кончилась, никаких замедлений нет.
Причина альфы = 1/2 дим?
> 32 dim / 16 alpha, иначе будет чрезмерно обученная (повторяющая одно и то же)
Уменьшение размерности при обучении сказывается эффективнее чем лр, шедулеры, ...?
> 128/16 не советую, сразу начинает срать под себя из-за высокого learning rate
Типа на xl большие альфы работают хорошо а просто больший лр без скейла - плохо?
> Больше данных = лучше, для XL в особенности. Не верьте мудакам, кто рассказывает как они запилили годноту из 5-6 образцов
Это для всех актуально ведь.
> тащить с Danbooru
Там же ведь даже с регой лимит по количеству тегов в поиске, не?
> Gelbooru, но там хуевые теги,+ не работает сортировка по качеству или дате
Сортировка работает, теги +- данбуру и больше зависит от давности арта.
Выходит ты дефолтными буру тегами для xl пользуешься?
> Иногда неплохо срабатывает добавление реальных фотографий в манямэ датасет (получится универсальная модель)
Хуясе ебать.
Честно не очень ты на эксперта похож, спорные вещи и совсем базовые, а важного не обозначит. Но может мы тебя просто не поняли и на самом деле сами не догоняем, ответь, пожалуйста, на вопросы, будем разбираться.
Этого двачую
> Эксперт по лорам для XL1.0 врывается в тред. Поясняю по теме всё как есть, что для чего.
Дай хоть пощупать свои лоры то, эксперт.
> Лучше лора весом в гигабайт но годная, чем весом в 30 мегабайт, но кривая.
Что мешает натренить на большом диме и потом ресайзнуть с минимальной потерей качества?
> 128/16 не советую, сразу начинает срать под себя из-за высокого learning rate.
Насколько высокого? Из опыта 64/16 на 1.5 с бешеным стартовым 4е-3 показал себя неплохо в приемлемые сроки тренировки с ещё несколькими дампенерами.
> Лучший способ подготовки данных - тащить с Danbooru программой imgbrd-grabber для винды, для этого нужно зарегаться и получить токен.
Для 1.5 с наи, для хл ты не сможешь так же просто заоверрайдить теги, там дедоязык.
> 64/16 на 1.5 с бешеным стартовым 4е-3
График лр есть? А то если там только короткий пик между разогревом и спадом то это уже не то, но потенциально интересный прием.
>Шаред мемори контролируется на уровне приложения
В треде автоматика на гитхабе написано ровно обратное.
> Причина альфы = 1/2 дим?
Умственная отсталость. Альфа нужна для прожарки и против слишком мелких градиентов. Тот дурачок напердолил демпинга и очевидно оно нихуя не тренится, а вместо того что бы убрать демпинг въебал прожарку альфой. В итоге вместо ровного обучения получает обновление весов скачками, любые говняки всегда будут усиливаться в разы и ебать лору.

Хм, по идее же наверное там можно на меньший T5 поменять просто если не влезает.


Есть, пик1, но там какие то экспериментальные новые параметры были для лосса, продиджи кстати примерно такой же лр ставит с этими настройками на пик2, сейчас небось шизик из секты свидетелей нулевых весов сагрится, что нету градиентного спуска.
Вообще пока скам какой-то, в ридми хуйня написана и модели пока даже не выложили.
>Самое главное в МЛ это параметры моделей
>Лучший способ подготовки данных - тащить с Danbooru
Хуею с этих МЛ-экспертов по лорам уже почти год. Про данбуру вообще охуенно, с её часто насранными тегами, которые для SDXL неюзабельны в никаком виде и говнят нахуй понимание моделью промпта. Для XL для SD1 вообще-то тоже в 95% случаев половину нахуй переписывать руками надо и дополнять кучей проебанных тегов капшионы писать только или руками полностью, или делать синтетику автоматом.
> Если модель уже знает этот предмет, то используй реальное название
Что работает от случая к случаю и в зависимости от того что тебе от лоры надо.
>Лучше лора весом в гигабайт но годная
Лору весом в гигабайт ты в жизни не обучишь до полного её "забития" на тех датасетах и их объемы что обычно для лор используются.
>тяжеловесные (стиль одного рисоваки)
>тяжеловесные
>стиль
Я даже комментировать не буду.
Эксперты я хуею

Почему нет гпу и генерит процессором?
Торчом не вышел.
https://docs.nvidia.com/cuda/cuda-c-programming-guide/index.html#shared-memory-9-0
>The shared memory capacity can be set to 0, 8, 16, 32, 64, 100, 132, 164, 196 or 228 KB.
>228 KB
Там ниху не килобайты, и явно там ничего никто не вызывал. У людей софт полез в оперативку сразу после обновления дров.
Есть такое понятие, как поведение по умолчанию. По умолчанию драйвер берёт объем RAM, делит на два и пытается выделить это под шаред мемори. Если поведение не устраивает - есть возможность это всё перенастроить. Но это не нужно, поведение адекватное, логичное и полностью оправданное.
>ниху не килобайты
Это килобайты на 1 CUDA блок. У той же 4090 этих блоков 16 384
>Самое главное в МЛ это параметры моделей
Самое главное это блять качественный датасет.
Модели утекли в сеть, в комфи (и вроде автоматике) уже есть поддержка, см.
>Если поведение не устраивает - есть возможность это всё перенастроить.
Окей, как мне это выключить?
>Но это не нужно, поведение адекватное, логичное и полностью оправданное.
Маркетолог куртки, ты? Это невидия обосралась с объёмом врама своего картона, что пришлось костыли лепить.
Скажи спасибо индусам с их никчемностью, куртка даже этого мог не делать, и те кто сейчас медленно-но-верно что-то могут все также бы сосали бибу.

Да ебануться блять
>Окей, как мне это выключить?
Делай форк автоматика. В статье, на которую я принёс ссылку - есть код.
>невидия обосралась с объёмом врама
Ты не понимаешь. Если сделать много врам на пользовательских видимокартах, то нужно сделать ещё больше на сороковых. А если сделать дохуя памяти на сороковых, то A100 нахуй не нужны будут. А это основной доход невидии.
>Ты не понимаешь.
Я прекрасно понимаю, что они жадные мудаки, ты мне америки не открыл. Но это не повод не называть их мудаками
М, спасибо. Про коми и автоматик чет не гуглится или у меня еблан на гугле.


Запустил это поделие в комфи. При генерации 1024х1024 с использованием T5 bnb8bit расход памяти чуть больше 13Гб, скорость около 5 it/s. При использовании bnb4bit расход ровно 12Гб, скорость такая же.
Понятно что на текущий момент у модели очень маленький датасет и она очень слабая в плане композиции и понимании промпта. Но, если китайцы не напиздели, то в перспективе всё выглядит очень многообещающе.




Я привел усредненные настройки которые срабатывают в 90% попыток, при этом превосходят дефолтные значения существующих скриптов. Пикрелейтед моя сегодняшняя лора на XL base 1.0. по простым настройкам без выебонов и с тегами Gelbooru.
Придумывать "крутые йоба-настройки" смысла нет, лучшее - враг хорошего. Если выкрутить lr на максимум, тогда например, сэмплер берет деталь с волос (заколку) и лепит ее на одежду, будто смысл лоры в этих деталях, а не в персонаже. Причем уже на втором чекпойнте. Про другие мокрописьки не в курсе, потому что трейню лоры в облаке (не в колабе).
Погонял тоже, выглядит в перспективе пиздец вкусно, да, но Т5-xxl это пиздец жирно конечно.
Как думаете, что станет настоящим некстгеном и раскрытием потенциала - SD 3.0 с новым энкодером как в Dall-e 2 или SD XXL Pro+ Evo edition который трейнили на 2048p со сжатием латентов
>тяжеловесные (стиль одного рисоваки)
>тяжеловесные
Ну давай подумаем. Что лора запоминает для одного персонажа? Пару типичных деталей, прическу и шмот. Всего лишь концепт.
Что нужно запомнить для уникального стиля как Abe Yoshitoshi? Характерные искажения в анатомии, приемы в композиции, текстурные поверхности, соотношение различных форм, чтобы воспроизводить это по-новому в сэмплах. Стиль - это не цветовой фильтр, это дофига всего. Он должен подходить для любых предметов и сцен, а не только тех которые часто встречаются у рисоваки.
Зависит от стиля, объема и качества датасета. Стиль можно как и в 32 dim натренить нормально, так и хоть в 256 обосраться.
> Придумывать "крутые йоба-настройки" смысла нет, лучшее - враг хорошего.
С параметрами - да, с датасетом - нет, его нужно по максимуму улучшить.
> сэмплер берет деталь с волос (заколку) и лепит ее на одежду
Опять заколки, год назад боролись с ними, так и не закончили. А вообще не должна она лепиться на одежду, если на всех картинках она была на голове.
> сегодняшняя лора на XL base 1.0
Просто скажи зачем вообще нужен XL? Фурри чекпоинт имеет базовое 1024, ушёл дальше по технологиям в виде vpred+ztsnr, его тренить так же просто как 1.5 и больше того, к нему подходят те же параметры, что и к наи, единственный минус, придётся заговорить на собачьем. Из коробки может в хентай без лор. Вот пример того что я сегодня на нём натренил
> Фурри чекпоинт имеет базовое 1024, ушёл дальше по технологиям в виде vpred+ztsnr
Объясните для долбоеба не работавшего с sdxl
Есть предложения что поменять в шаблоне перед катом?
Тут особо и нечего объяснять, фуррикумеры натренили на полторашке чекпоинт лучше, чем SAI своё дерьмо, которое ещё и фиксили лорой с нойз оффсетом, чтобы динамический диапазон цветов был лучше. Fluffyrock лучше понимает промпт, может сгенерить полностью белую или чёрную пикчу (тот самый рейндж), и может в хентай концепты и любого вида гениталии из-за обильного количества соответствующего в датасете. Минус в том, что этот файнтюн вымыл всё, что было в наи и привычные теги там не сработают, нужно искать на e621 замену, как для промптинга так и для тренировок. Но юзать его надо так же, лишь для тренировок, а генерить с Easyfluff или подобных его производных, как это было и с наи. Недавно анон кстати скидывал трюк улучшения любой модели в наи через изифлафф, он хоть и не перенесёт все фичи, но бустанёт модельку, не похерив совместимость с привычной генерацией, как на наи производных.
>Фурри чекпоинт имеет базовое 1024, ушёл дальше по технологиям в виде vpred+ztsnr
Толку с этого, если он не сможет ничего согласовать в HD через крошечное окно сэмплера? sdxl это не просто 4x разрешение - это эстетические слои, благодаря ним модель сама без пользователя знает что красиво, и как сделать художественно. А с рефайнером все же обосрались, потому что в finetune для него нет применения, он чисто для борьбы с uncanny valley.
Посоветуйте новичку
1. Куда смотреть если я хочу не просто эмбеддинг, а трейнить полноценно модель на базе XL, используя Danbooru данные гверна? есть 14 GB GPU
2. Есть ли смысл соединить базовую модель с несколькими лорами, чтобы последующий дотрейн поверх нее был не booru дженериком, а кастомизированным так, как мне надо?
1. Куда смотреть если я хочу не просто эмбеддинг, а трейнить полноценно модель на базе XL, используя Danbooru данные гверна? есть 14 GB GPU
2. Есть ли смысл соединить базовую модель с несколькими лорами, чтобы последующий дотрейн поверх нее был не booru дженериком, а кастомизированным так, как мне надо?
> sdxl это не просто 4x разрешение
> это эстетические слои
> благодаря ним модель сама без пользователя знает что красиво
> и как сделать художественно
Подобную индусятину с релиза не раз видел, но оно так и не ушло дальше нормальных файнтюнов для реалистик пикч.
Ты лучше лору свою залей на цивит например, раз она такая классная вместе с примерами, чтобы можно было прикоснуться к прекрасному.
> Толку с этого, если он не сможет ничего согласовать в HD через крошечное окно сэмплера?
Что вообще высрал?
> фуррикумеры натренили на полторашке чекпоинт лучше
Даже не удивлен. В очередной раз куминг продвигает ML.
> трейнить полноценно модель на базе XL, используя Danbooru данные гверна? есть 14 GB GPU
>XL
>14GB
Смотреть на аренду облаков с видеокартами или на ценники A100 в магазинах.
Настоящему МЛ где крутятся миллионы инвестиций - насрать на дрочеров, попены так вообще всё обложили фильтрами.
Вопрос был не про это, а про работающие из коробки скрипты как dreambooth.
Олвейс хес бин, кумеры на острие мышиного обучения.
Да ничего, инфы нормальной по пиксарту пока нет, надо ещё один тред дать отстояться. В следующую шапку уже точно придётся включать.
Ему не насрать, просто не хотят пиздюлей от рассерженых моралфагов получать.
Хм. В одном ИИ-дискорде видел реплику, что у фурри прям очень крепкое комьюнити и они ваще молодцы, офигенные вещи делают.
Не обратил тогда особого внимания, а тут такое.
Главный вопрос теперь - где скочать и пощупать? Что-нибудь простое, которое скачал, и начал генерить с теми же промптами, что и раньше, на НАИ и производных.
> ИИ-дискорде видел реплику, что у фурри прям очень крепкое комьюнити и они ваще молодцы, офигенные вещи делают
И не только ИИ они там делают в дискорде...
Так ей бумер промпт нужен, человеческий т.е., а не простыня запятых. Ты бы ещё мастерписов от грега рутковски напихал, ёба. Кто-то сравнивал как гигантский апельсин врезается в Нью-Йорк, SDXL нихуя не понимал, а эта штука учуяла своим трансформером.
Это промпт из примеров с их гитхуба (с небольшим отличием)
Ну типа сделать дженерик персонажа можно просто фейсроля не дефолтных параметров гуйни или шатая их в широком пределе. Для оценки, что у нее из особенностей кроме двойной-тройной-четверной (?) лямки трусов с одной стороны, ремня под бубсами и шипасных/гладких (?) наплечников? Показал бы гибкость своей лоры, с разных ракурсов и поз, с частичным или полным изменением костюма но сохраняя узнаваемость персонажа, на разных фонах, в сочетании с чем-то еще. А то ошибаться в мелочах, воспроизводить единичный ракурс из датасета и ломать фон еще на самой заре умели.
> сэмплер берет деталь с волос (заколку) и лепит ее на одежду
Что-то сильно поломалось значит, такого быть не должно. Или проблемы с текстовым описанием.
> имеет базовое 1024
Если объективно, насколько он хорош в нем? XL в естественных для него условиях очень когерентен и четок, а тут? И по восприятию концептов подробнее.
Тут вообще сочетание куминга с "притесняемым" комьюнити и некоторым фанатизмом, взрывная смесь.
> Главный вопрос теперь - где скочать и пощупать? Что-нибудь простое, которое скачал, и начал генерить с теми же промптами, что и раньше, на НАИ и производных.
Вот тут расписан алгоритм, как это сделать не все фичи перенесутся, в основном разрешение и послушность промпту должна добавиться, рейнджа не будет, потести вообщем.
> Хм. В одном ИИ-дискорде видел реплику, что у фурри прям очень крепкое комьюнити и они ваще молодцы, офигенные вещи делают.
Да, неприятно это признавать, особенно юзая аниме чекпоинты, но они более компетентны, чем sai, их чекпоинт просто работает и тренится легче.
> Если объективно, насколько он хорош в нем?
Сколько не генерю, просто работает и не имеет артефактов присущих наи или его производным в этом разрешении, попробуй просто сам, всё сразу поймёшь, я тоже раньше плевался, меэх фурри, но зря, для аниме оно тоже годится.
> XL в естественных для него условиях очень когерентен и четок, а тут?
Это говно вообще ни в какое сравнение не идёт, оно просто не слушается промпта, даже трусы не могло нарисовать, спустя месяца полтора с релиза, сейчас уже вроде лучше, но нахуй не нужен с такими подходами.
> И по восприятию концептов подробнее.
Что конкретно? Сразу напомню, это простой кондишионинг с промпта в пару тегов с е621, с наи такое возможно только с лорами/кнетом/инпеинтом. Я пробовал простые хентайные концепты, которые на наи можно сделать только лишь с лорой, и то там бадихоррор будет, ну типо job_name, здесь из коробки работает, даже посмотреть со стороны работает, и не плодит кучу конечностей, только пальцы подхеривает, ну это такое. Ещё удивило, что хвосты тоже никуда не летают в 90% случаев.
ПЕРЕКАТ
Я не силен в новуке, поясните: возможна ли нейронка которая делает по описанию уникальные видосы как на порнхабе, будто обычная поисковая выдача по тегам но все ролики сгенерированы ИИ? Или, в чем сложность ее создания?




Тред общенаправленныей, тренировка дедов, лупоглазых и фуррей приветствуются
Предыдущий тред:
➤ Софт для обучения
https://github.com/kohya-ss/sd-scripts
Набор скриптов для тренировки, используется под капотом в большей части готовых GUI и прочих скриптах.
Для удобства запуска можно использовать дополнительные скрипты в целях передачи параметров, например: https://rentry.org/simple_kohya_ss
➤ GUI-обёртки для kohya-ss
https://github.com/bmaltais/kohya_ss
https://github.com/derrian-distro/LoRA_Easy_Training_Scripts
https://github.com/anon-1337/LoRA-train-GUI
➤ Обучение SDXL
Если вы используете скрипты https://github.com/kohya-ss/sd-scripts напрямую, то, для обучения SDXL, вам необходимо переключиться на ветку "sdxl" и обновить зависимости. Эта операция может привести к проблемам совместимости, так что, желательно, делать отдельную установку для обучения SDXL и использовать отдельную venv-среду. Скрипты для тренировки SDXL имеют в имени файла префикс sdxl_.
Подробнее про обучение SDXL через kohya-ss можно почитать тут: https://github.com/kohya-ss/sd-scripts/tree/sdxl#about-sdxl-training
Для GUI https://github.com/bmaltais/kohya_ss и https://github.com/derrian-distro/LoRA_Easy_Training_Scripts/tree/SDXL так же вышли обновления, позволяющее делать файнтьюны для SDXL. Кроме полноценного файнтьюна и обучения лор, для bmaltais/kohya_ss так же доступны пресеты для обучения LoRA/LoHa/LoKr, в том числе и для SDXL, требующие больше VRAM.
Всё пока сырое и имеет проблемы с совместимостью, только для самых нетерпеливых. Требования к системе для обучения SDXL выше, чем для обучения SD 1.x.
➤ Гайды по обучению
Существующую модель можно обучить симулировать определенный стиль или рисовать конкретного персонажа.
✱ Текстуальная инверсия (Textual inversion) может подойти, если сеть уже умеет рисовать что-то похожее:
https://rentry.org/textard (англ.)
✱ Гиперсеть (Hypernetwork) может подойти, если она этого делать не умеет; позволяет добавить более существенные изменения в существующую модель, но тренируется медленнее:
https://rentry.org/hypernetwork4dumdums (англ.)
✱ Dreambooth – выбор 24 Гб VRAM-бояр. Выдаёт отличные результаты. Генерирует полноразмерные модели:
https://github.com/nitrosocke/dreambooth-training-guide (англ.)
✱ LoRA – "легковесный Dreambooth" – подойдет для любых задач. Отличается малыми требованиями к VRAM (6 Гб+) и быстрым обучением:
https://rentry.org/2chAI_easy_LORA_guide - гайд по подготовке датасета и обучению LoRA для неофитов
https://rentry.org/2chAI_LoRA_Dreambooth_guide - ещё один гайд по использованию и обучению LoRA
https://rentry.org/59xed3 - более углубленный гайд по лорам, содержит много инфы для уже разбирающихся (англ.)
✱ LyCORIS (Lora beYond Conventional methods, Other Rank adaptation Implementations for Stable diffusion) - это проект по созданию алгоритма для более эффективного дообучения SD. Ранее носил название LoCon. В настоящий момент включает в себя алгоритмы LoCon, LoHa, LoKr и DyLoRA:
https://github.com/KohakuBlueleaf/LyCORIS
✱ LoCon (LoRA for Convolution layer) - тренирует дополнительные слои в UNet. Теоретически должен давать лучший результат тренировки по сравнению с LoRA, меньше вероятность перетренировки и большая вариативность при генерации. Тренируется примерно в два раза медленнее чистой LoRA, требует меньший параметр network_dim, поэтому размер выходного файла меньше.
✱ LoHa (LoRA with Hadamard Product representation) - тренировка с использованием алгоритма произведения Адамара. Теоретически должен давать лучший результат при тренировках с датасетом в котором будет и персонаж и стилистика одновременно.
✱ LoKr (LoRA with Kronecker product representation) - тренировка с использованием алгоритма произведения Кронекера. Алгоритм довольно чувствителен к learning_rate, так что требуется его тонкая подгонка. Из плюсов - очень маленький размер выходного файла (auto factor: 900~2500KB), из минусов - слабая переносимость между моделями.
✱ DyLoRA (Dynamic Search-Free LoRA) - по сути та же LoRA, только теперь в выходном файле размер ранга (network_dim) не фиксирован максимальным, а может принимать кратные промежуточные значения. После обучения на выходе будет один многоранговый файл модели, который можно разбить на отдельные одноранговые. Количество рангов указывается параметром --network_args "unit=x", т.е. допустим если network_dim=128, network_args "unit=4", то в выходном файле будут ранги 32,64,96,128. По заявлению разработчиков алгоритма, обучение одного многорангового файла в 4-7 раз быстрее, чем учить их по отдельности.
✱ Text-to-image fine-tuning для Nvidia A100/Tesla V100-бояр:
https://keras.io/examples/generative/finetune_stable_diffusion (англ.)
Не забываем про золотое правило GIGO ("Garbage in, garbage out"): какой датасет, такой и результат.
➤ Тренировка YOLO-моделей для ADetailer
YOLO-модели (You Only Look Once) могут быть обучены для поиска определённых объектов на изображении. В паре с ADetailer они могут быть использованы для автоматического инпеинта по найденной области.
Гайд: https://civitai.com/articles/1224/training-a-custom-adetailer-model
Тулза для датасета: https://github.com/vietanhdev/anylabeling
Больше про параметры: https://docs.ultralytics.com/modes/train
➤ Гугл колабы
﹡Текстуальная инверсия: https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb
﹡Dreambooth: https://colab.research.google.com/github/TheLastBen/fast-stable-diffusion/blob/main/fast-DreamBooth.ipynb
﹡LoRA [1] https://colab.research.google.com/github/Linaqruf/kohya-trainer/blob/main/kohya-trainer.ipynb
﹡LoRA [2] https://colab.research.google.com/drive/1bFX0pZczeApeFadrz1AdOb5TDdet2U0Z
➤ Полезное
Гайд по фиксу сломанных моделей: https://rentry.org/clipfix (англ.)
Расширение WebUI для проверки "сломаных" тензоров модели: https://github.com/iiiytn1k/sd-webui-check-tensors
Гайд по блок мерджингу: https://rentry.org/BlockMergeExplained (англ.)
Гайд по ControlNet: https://stable-diffusion-art.com/controlnet (англ.)
Гайды по апскейлу от анонов:
https://rentry.org/SD_upscale
https://rentry.org/sd__upscale
https://rentry.org/2ch_nai_guide#апскейл
https://rentry.org/UpscaleByControl
Ручная сборка и установка последней версии xformers и torch в venv автоматика:
Windows: https://rentry.org/sd_performance
Linux: https://rentry.org/SD_torch2_linux_guide
Подборка мокрописек от анона: https://rentry.org/te3oh
Группы тегов для бур: https://danbooru.donmai.us/wiki_pages/tag_groups (англ.)
Коллекция лор от анонов: https://rentry.org/2chAI_LoRA
Гайды, эмбеды, хайпернетворки, лоры с форча:
https://rentry.org/sdgoldmine
https://rentry.org/sdg-link
https://rentry.org/hdgfaq
https://rentry.org/hdglorarepo
https://gitgud.io/gayshit/makesomefuckingporn
Шапка: https://rentry.org/catb8
Прошлые треды:
№1 https://arhivach.top/thread/859827/
№2 https://arhivach.top/thread/860317/
№3 https://arhivach.top/thread/861387/
№4 https://arhivach.top/thread/863252/
№5 https://arhivach.top/thread/863834/
№6 https://arhivach.top/thread/864377/
№7 https://arhivach.top/thread/868143/
№8 https://arhivach.top/thread/873010/
№9 https://arhivach.top/thread/878287/
№10 https://arhivach.top/thread/893334/
№11 https://arhivach.top/thread/908751/