

О, насчёт datagrip не знал.
Жаль она платная, месяц триал...
Хай только устроился в компанию на должность аналитика-маркетолога хехе. Отчетность на основе кубов в excel, но я видел что есть MSQL. Какие подводные камни если я буду писать запросы к кубу из менеджера или сразу к таблицам обращаться минуя кубы?
Есть непонятка по микросервисам
Постоянно говорят что на каждый сервис должна быть строго 1 база, что шареная между несколькими сервисами база это плохо-плохо
Но есть следующий кейс: отправляется запрос на main back сервис на выгрузку некого большого файла, он создает запись в таблице event, отправляем реквест в сервис file handler и возвращаем фронту id ивента. В это время сервис file handler начинает обрабатывать запрос.
Если база с таблицей event не шарится между несколькими сервисами то как тогда иначе?
Для пайчарма и осмелюсь предположить любой Иде от жидбрейнс есть плагины, которые повторяют функции датагрип. Также полно другого бесплатного софта для управления базами данных, например dbeaver
Только в Про Пайчарме
Но сейчас бы в 2023 не мочь его украсть...
Не считается ли моветоном mssql? ну кто будет держать сервера на шиндовсе?
> В это время сервис file handler начинает обрабатывать запрос.
А дальше что должно произойти? Фронт обратится к file handler по id ивента, и он должен вернуть результат выгрузки? Ну сохраняй эти id в отдельной таблице в БД file handler. Да, данные в БД разных микросервисов дублируются.
MSSQL работает на линуксе. Но моветоном считается всё, кроме постгреса.
>постгреса
чем он так хорош в отличие от, например, мускула или марии?
Да хуй его знает, никто конкретно ответить не может. Любые доводы спорны и вызывают срач. Но на крупных проектах, где пытаются слезть с Oracle/MSSQL, мускул часто даже не рассматривают, не нравится от им, слишком PHP пахнет.
А есть хорошие гайды или книги где подробно объясняют как правильно строить модель данных, которая бы ложилась на NoSQL базу данных? Как не приду на проекте - каждый раз кто-то пытается натянуть реляционную модель и выдумать внешние ключи на стороне приложения.



>есть хорошие гайды или книги где подробно объясняют как правильно строить модель данных
Гугли single table design.
Как пруфануть ХРющке знание sql чтобы она меня до собеса допустила? Думаю сделать какой-то из сертификатов, какой лучше databricks data analyst associate или Oracle sql 1z-071? Дата брикс больше к моему стэку подходит тк я азур учу так же, но оракул чисто sql экзамен можно сказать с некоторыми вкраплениями оракловчкой версии а датабрикс всякие визуализации и тд еще есть.
Шо парни, скока получаете, скока по времени работаете?
100/6мес
100/6мес
Никак. Собеседование не с разработчиками - строго нахуй.
Отговорить становиться датаинженером, а то мне начинает нравиться.
hh.ru
>>100/6мес
Год назад тоже был 100/6 мес.
Теперь я 120/1,5 года
Прошу, скиньте арт со второй пикчи
А чо так хуево?
Ты не из дс?
Привет. Вопрос по PSQL
Есть Пикей с настроенными автоматическими значениями. Как сделать так, чтобы после удаления строк из таблицы следующий пикей выбирался минимальным? Пример:
id
1
2
3
Дропаем вторую строчку и вставляем новую
id
1
3
4
вместо 4 хотелось бы получить 2. Такое реально?
Есть Пикей с настроенными автоматическими значениями. Как сделать так, чтобы после удаления строк из таблицы следующий пикей выбирался минимальным? Пример:
id
1
2
3
Дропаем вторую строчку и вставляем новую
id
1
3
4
вместо 4 хотелось бы получить 2. Такое реально?
Можешь написать триггер, который будет на каждый инсерт вычислять максимум и записывать в id, причём надо каждый раз блокировать всю таблицу, чтобы другая транзакция не сгенерировала такой же id. Представь, какие будут тормоза.
Пропуски в генераторе id - меньшее зло.
Согласен.
Думал малой кровью обойдусь, но раз нет так нет, просто глаза мозолят индексы не от 1...
Я конеш хз, но вот чет я даже не оьращаю внимания на пк. Какая разница что у тебя пк 12949393, а не 12938322, например? Да и в целом меня больше смущает то, что они по идеи могут повторяться из за cycle, а если у тебя no cycle, а там уже подходит к концу, то ждет прекол
Привет, нужна обучалка по mdx. Есть кто знает?
предположим вопрос на собесе про оптимистическую и пессимистическую блокировки.
В случае постгреса можно ли через базу сделать оптимистическую блокировку?
isolation_level = serializable - оно защищает только от параллельных изменений. Читаем данные 2 раза, отдаем 2 клиентам. Первый клиент присылает данные, мы коммитим. Второй клиент присылает данные, мы коммитим и перезатираем данные первого. Т.е. оптимистичную блокировку нужно делать только руками?
Пессимистичная - я так понимаю это select for update?
В случае постгреса можно ли через базу сделать оптимистическую блокировку?
isolation_level = serializable - оно защищает только от параллельных изменений. Читаем данные 2 раза, отдаем 2 клиентам. Первый клиент присылает данные, мы коммитим. Второй клиент присылает данные, мы коммитим и перезатираем данные первого. Т.е. оптимистичную блокировку нужно делать только руками?
Пессимистичная - я так понимаю это select for update?
Уважаемые, нужен ваш совет.
Есть N таблиц в кликхаусе, которые периодически транкейтятся и заполняются заново (пару раз в сутки, точный период будет настраиваться чужим человеком во внешней проге).
Нужно сделать денормализованную таблицу из этих N, чтобы быстренько из неё селектить и, чтобы денормализованная таблица сбрасывала данные и заполнялась снова, когда это делают остальные N таблиц.
Как тут можно поступить? Триггиров в кликхаусе нет, а всякие штуки типа materializedView не обращают внимание на транкейты
Есть N таблиц в кликхаусе, которые периодически транкейтятся и заполняются заново (пару раз в сутки, точный период будет настраиваться чужим человеком во внешней проге).
Нужно сделать денормализованную таблицу из этих N, чтобы быстренько из неё селектить и, чтобы денормализованная таблица сбрасывала данные и заполнялась снова, когда это делают остальные N таблиц.
Как тут можно поступить? Триггиров в кликхаусе нет, а всякие штуки типа materializedView не обращают внимание на транкейты
>Есть N таблиц
>транкейтятся и заполняются заново пару раз в сутки
А нахуа тогда кликхаус?
Если бы я знал, но маэмо то що маэмо
Похоже тот случай когда технологию ради названия в проект пихают. Прост юзкейсы кликхауса противоречат тому что ты описал.
1) Кликхаус не заточен под быструю встаку большого объема данных. У него есть буфер специальный, в котором данные хранятся пока сам кликхаус должен пропердется мелкими порциями.
2) Кликхаус заточен под накопление данных и аналитические запросы к ебическому количеству записей. Причем поскольку это колоночная БД, денормализация не приветствуется так как можно оптимизировать запросы выбирая только те колонки которые нужны.
3) Кликхаус до некоторого времени не умел в DELETE.
>денормализация не приветствуется
нормализация не приветствуется
слоуфикс
Меня в данный момент не интересует БЫСТРАЯ вставка чего-то куда-то, я хочу хоть какую-то АВТОМАТИЧЕСКУЮ вставку в денормализованную таблицу и очистку её, при очистке "таблиц-источников"
Как MaterializedView, только чтобы очищалась еще сама
Наверное вопрос не совсем по теме, но интересно.
Уже не первый замечаю, что стандартные пакеты из ряда дистрибутивов (будь-то арч или убунту) делают владельцем директории /var/lib/postgresql рута:
drwxr-xr-x 3 root root 18 Jun 2 15:18 postgres
При это /var/lib/postgres/data/ уже имеет нормальные права.
drwx------ 19 postgres postgres 4096 Jun 2 15:40 data
Есть идеи зачем? Вот я сходу ловлю проблемы, потому что как обычно при инициализации БД приходится работать:
sudo su postgres
initdb -k -D ./data
И допустим я правлю конфиг или хба через вим, а он мне сразу фигу показывает, т.к. не может своп файл создать в домашней директории постгресаправа на запись в которой у самого постгреса нет.
Права на весить не проблема, но я не понимаю, почему бы сразу не дать права на /var/lib/postgresql ?
Уже не первый замечаю, что стандартные пакеты из ряда дистрибутивов (будь-то арч или убунту) делают владельцем директории /var/lib/postgresql рута:
drwxr-xr-x 3 root root 18 Jun 2 15:18 postgres
При это /var/lib/postgres/data/ уже имеет нормальные права.
drwx------ 19 postgres postgres 4096 Jun 2 15:40 data
Есть идеи зачем? Вот я сходу ловлю проблемы, потому что как обычно при инициализации БД приходится работать:
sudo su postgres
initdb -k -D ./data
И допустим я правлю конфиг или хба через вим, а он мне сразу фигу показывает, т.к. не может своп файл создать в домашней директории постгресаправа на запись в которой у самого постгреса нет.
Права на весить не проблема, но я не понимаю, почему бы сразу не дать права на /var/lib/postgresql ?
Мастер процесс запускают от рута, а воркеры от постгрес?
Да нет, все процессы от юзера постгрес, ни одного от рута. Это же вроде как за стандарт взято, чтобы все процессы от постгреса запускались, а не от рута. Иначе бы в демонах не прописывался запуск от юзера постгрес.
Мой вопрос довольно простой, почему /var/lib/postgresql ,как правило, принадлежит руту и при этом является домашней директорией постгреса?
/home/username/ же не принадлежит руту, а принадлежит username
делаю select for update, строка блокируется для изменения и для других select for update.
А обычный select без update будет блокироваться? В мануале прямо не написано, значит будет читать?
А обычный select без update будет блокироваться? В мануале прямо не написано, значит будет читать?
select for update блокирует для чтения и изменения
select for share для изненения
что делает просто select зависит от субд

> блокирует для чтения
написано что блокирует для изменения. Про простые селекты ничего не написано. Значит эту заблокированную строку можно читать селектом?
In the context of database transactions, "SELECT FOR SHARE" and "SELECT FOR UPDATE" are clauses used in SQL statements to control concurrent access to data. These clauses are typically used in conjunction with the "SELECT" statement in database systems that support transaction isolation levels.
SELECT FOR SHARE:
When you use the "SELECT FOR SHARE" clause, it indicates that the selected rows are to be locked in a shared mode. This mode allows other transactions to read the selected rows but prevents them from making any modifications to those rows until the lock is released. Multiple transactions can acquire a shared lock on the same rows simultaneously, enabling concurrent reading operations.
SELECT FOR UPDATE:
On the other hand, when you use the "SELECT FOR UPDATE" clause, it indicates an exclusive lock on the selected rows. This mode not only prevents other transactions from modifying the selected rows but also prevents them from reading those rows until the lock is released. The intention is to ensure that the transaction that acquired the lock has exclusive access to modify the data.
мимо чатгпт
оно английскую версию перепечатало. Понятнее не стало
где обсуждение 23 стандарта
Наконец-то не надо писать FROM DUAL.
Ребята, это пиздец, уже сегодня сдавать курсовую.
У меня возникла проблема с Mongo db compass , выдает такую ошибку connect ECONNREFUSED 127.0.0.1:27017
Я облазил уже просто все, дойдя до служб , mongo там просто не оказалось. Я решил добавить - тщетно, пробовал по-всякому, нихуя не получается. У меня, откровенно говоря, уже горит с этой ситуации и я чувствую себя дауном (мб так и есть). Поэтому, прошу у вас помощи, завтра утром надо доделать курсовую без вариантов. Буду безумно благодарен, я уже не знаю к кому обратиться
У меня возникла проблема с Mongo db compass , выдает такую ошибку connect ECONNREFUSED 127.0.0.1:27017
Я облазил уже просто все, дойдя до служб , mongo там просто не оказалось. Я решил добавить - тщетно, пробовал по-всякому, нихуя не получается. У меня, откровенно говоря, уже горит с этой ситуации и я чувствую себя дауном (мб так и есть). Поэтому, прошу у вас помощи, завтра утром надо доделать курсовую без вариантов. Буду безумно благодарен, я уже не знаю к кому обратиться
Ребята, это пиздец, уже сегодня сдавать курсовую.
У меня возникла проблема с Mongo db compass , выдает такую ошибку connect ECONNREFUSED 127.0.0.1:27017
Я облазил уже просто все, дойдя до служб , mongo там просто не оказалось. Я решил добавить - тщетно, пробовал по-всякому, нихуя не получается. У меня, откровенно говоря, уже горит с этой ситуации и я чувствую себя дауном (мб так и есть). Поэтому, прошу у вас помощи, завтра утром надо доделать курсовую без вариантов. Буду безумно благодарен, я уже не знаю к кому обратиться
У меня возникла проблема с Mongo db compass , выдает такую ошибку connect ECONNREFUSED 127.0.0.1:27017
Я облазил уже просто все, дойдя до служб , mongo там просто не оказалось. Я решил добавить - тщетно, пробовал по-всякому, нихуя не получается. У меня, откровенно говоря, уже горит с этой ситуации и я чувствую себя дауном (мб так и есть). Поэтому, прошу у вас помощи, завтра утром надо доделать курсовую без вариантов. Буду безумно благодарен, я уже не знаю к кому обратиться
докер


Анон, смотри. На первом скрине админер (бывший пхпмайадмин), на втором - dbeaver. Можно ли во втором как-то сделать вывод строки в столбец, как на первом скрине. Руководитель иногда бывает запрашивает данные и делать скриншоты 3 экранов ради одной строчки - ну такое себе. а так бы был аккуратный столбец. На втором скрине одна из простых таблиц, но бывают и в разы обьемнее. dbeaver в приоритете, потому что у нас несколько типов баз данных, в том числе такие, которые не поддерживаются админером.
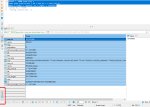

Выгрузи в эксель и сделай специальную вставку с транспонированием.
Офигенно, то, что надо! А как по быстрому переключить записи не нажимая в grid ? Типа пробелом например итд. Но в целом, то, что надо, спасибо!!
Ой, я довен, увидел, вон же внизу кнопки влево-вправо. Вопрос закрыт.
Что должен знать джуниор дата инженер?
Своё место под шконкой

Да, но заёбно, лучше кодом
шалом, анон
Не получается на sql, я орм обезьяна, нужен совет
еот оракл
В таблице А фк на Б
В таблицу А добавили новый столбец
В столбец надо добавить номер от 0 до n
n - количество строк из А, которые имеют фк на одну и ту же строку в Б
есть кабинет
и его работники: славик, антон, ерохин
Надо дать работникам порядковые номера
Не получается на sql, я орм обезьяна, нужен совет
еот оракл
В таблице А фк на Б
В таблицу А добавили новый столбец
В столбец надо добавить номер от 0 до n
n - количество строк из А, которые имеют фк на одну и ту же строку в Б
есть кабинет
и его работники: славик, антон, ерохин
Надо дать работникам порядковые номера
Надо придумать систему логирования событий в базе Постгрес
Какой-то юзер меняет данные -> следовательно это должно быть отражено в БД: что за юзер и что он менял. Поначалу казалось норм идеей сделать это на триггерах, но в таком случае вместо реального юзера будет записываться юзер БД (а он один, очевидно, приложение коннектится к БД всегда от имени конкретного пользака БД)
Как это осуществить вообще? Как-то на уровне самого приложения питона? Или притащить другую БД, например монгу?
Есть БД Access, в него юзеры пишут циферки через формы.
Есть скрипт выгружающий из бд в эксель.
Есть дашборд Power BI в котором визуализируются эксельки.
Проблема - после показывания дашборда руководству, циферки вносятся шаловливыми ручками и отчетность идет по пизде.
1) Как посчитать разрыв в цифрах до-после отчёта?
2) Логи нельзя внедрить, разграничить доступ тоже. Как не давать довбивать данные?
Есть скрипт выгружающий из бд в эксель.
Есть дашборд Power BI в котором визуализируются эксельки.
Проблема - после показывания дашборда руководству, циферки вносятся шаловливыми ручками и отчетность идет по пизде.
1) Как посчитать разрыв в цифрах до-после отчёта?
2) Логи нельзя внедрить, разграничить доступ тоже. Как не давать довбивать данные?
> (а он один, очевидно, приложение коннектится к БД всегда от имени конкретного пользака БД)
ну сделай чтобы не один.
в Древние Времена на Дельфи это не было проблемой.
>ну сделай чтобы не один
Ты ебобо? У меня около сотни потенциальных пользователей в прилоежнии. Мне сотню юзеров заводить в БД? А если их тысячи или миллионы?
Да, на уровне приложения. Просто отдельный инсерт в таблицу событий.
И где все эти двухзвенки теперь? Потому они и остались в нулевых, что проблем они создавали дохуя.
Взять нормальную БД, которая умеет авторизовывать внешних пользователей, из Active Directory например, то есть MSSQL. Ну или прикручивай костыли к своему красноглазому говну, зато швабода.
решил с помощью ROW_NUMBER() с указанием партишонов
Что мешает написать логику в коде и не дрочить бд?
Привет. Расскажите про датаинженеринг. Востребовано? Какая конкурентность? Что учить, чтобы стать? Моих вводных достаточно? Python, базовые знания SQL, один раз жизни написал макрос для Excel, могу делать схему базы данных в НФ3.
Реально ли в реббите посылающему (publisher) получить уведомление о том что его сообщение было взять потребителем (consumer) из очереди?
Что по ci/cd или хотя бы ide для разработки на sql? Я потыкался, только какие-то синтакс хайлайтерыи форматтеры для написания одной функции (одну я и так в голове удержу), которые потом, видимо, планируется руками в интерфейс бд копировать?
Есть PL/SQL Developer. Вообще, такие IDE мало кому нужны, сейчас почти никто не держит бизнес-логику в БД.
Это тред баз данных, а не брокеров сообщений.
Спиздани такую хуйню на работе и можешь сразу искать новую
> на работе
Это должность администратора баз данных, а не девопса.
Есть мнение, что второе из первого вылезает, а не наоборот.
Есть задача. Сохранять, читать целиком, удалять джейсонки. Нагрузка может быть большой, джейсонки от пары килобайт до 10 мегабайт. Джейсонки с критичными данными, терять нельзя.
Какая база под эти задачи подходит? Монга?
Какая база под эти задачи подходит? Монга?
Привет.
Есть таблица
[obj_id, label_id] N:N
Как мне найти все obj_id, для которых существуют ВСЕ label_id из некоторого множества?
Есть таблица
[obj_id, label_id] N:N
Как мне найти все obj_id, для которых существуют ВСЕ label_id из некоторого множества?
Пацаны, надо бы в постгре накатить check constraint на поле с датой, чтобы все значения когда день не равен 1 не позволялись к записи. Как мутить?
По жсончикам часто читаем данные или пишем? Обновлять их нужно? Что значит "удалять"?
rocksdb
Любая база подходит.
Они нужны временно, их заберут через ручку и их можно удалить.
Удалить критически важные данные? Софт делит?
Они критически важные пока не будут вычитаны.
По сути как в очереди реббита. Сохраняем, один раз читаем и удаляем. Но через бд + рест.
Да, это тупо, криво и костыльно, но такие ограничения.
Хранить большие jsonb в постгресе, как мне сказали это плохая идея. Особенно с учетом что на одно чтение будет одна запись и одно удаление.
Если они вычитываются строго иерархично, по таймстемпам например или по категориям, то просто юзается Кафка, она как раз для этого и придумывалась. Данные не удаляются, просто в определенном файле где они лежали теперь мы знаем что ниже определенного порога это "старые" данные

продублирую сюда
подскажите как open server запустить, вот такую ошибку выдаёт, а после того как закрываю окно программа закрывается и пропадает из панели задач. в антивируснике выключил защиту в реальном времени.
по поводу файла hosts, его раньше получалось показать командой attrib.exe -s -r -h -a C:\Windows\system32\drivers\etc\hosts сейчас даже так не выходит. ещё почему то после начала всех моих манипуляций винда создала аккаунт администратора отдельно от того которым я пользовался всё время.
подскажите что делать я тупой
подскажите как open server запустить, вот такую ошибку выдаёт, а после того как закрываю окно программа закрывается и пропадает из панели задач. в антивируснике выключил защиту в реальном времени.
по поводу файла hosts, его раньше получалось показать командой attrib.exe -s -r -h -a C:\Windows\system32\drivers\etc\hosts сейчас даже так не выходит. ещё почему то после начала всех моих манипуляций винда создала аккаунт администратора отдельно от того которым я пользовался всё время.
подскажите что делать я тупой
Что это за хуйня? Не нужно ее запускать
Лол, может у тебя малварь какая-то сидит и захватила хостс.
Васянская зборочка лампа.
Нет, читаем мы по айдишникам.
Решил.
Select distinct(object_id) from ...
Where label_id in ([N])
Group by object_id
Having count(*) >= N

PHP-тред тебе на что? Зачем оффтоп разводить?
В пхп треде обсуждать как редактировать hosts файл на винде?
Как будто в SQL-треде обсуждают.
Помогите пожалуйста разработать комплекс программ создания и обработки базы данных из трех таблиц.
Содержание кейса
1. Создать базу из основной таблицы с оперативными данными и четырех таблиц‑справочников с наименованиями кодов (используются для расшифровки кодов в формах, в представлениях, в запросах и в отчетах).
2. Создать базовый, перекрестные, итоговые, графические представления и запросы (не менее шести). Запросы и представления оформить в виде табличных форм, диаграмм.
3. Сформировать формы для заполнения таблиц и просмотра запросов, представлений с русифицированными кнопками, наименованиями полей (по одной форме для каждой таблицы и представления или запроса и по одной составной форме).
4. Сформировать отчет с детальными строками, с расшифровками кодов и с итогами по двум уровням группировки (указаны в условии), по одному простому отчету для каждой таблицы, представления, запроса .
5. Сформировать меню из пунктов: таблицы, формы, представления, запросы и отчеты для вызова разработанных таблиц, форм, представлений, запросов и отчетов.
6. Разработать систему программной защиты с регистрацией пользователей и их полномочий, журнала аудита для основной таблицы и защиты параметров настройки от изменений (п. 3.14.3). (Как мне объяснили - это значит, что, когда в БД заходишь, там окошечко пароля должно быть, чтобы её не мог изменить каждый)
Вариант 15. Учет поставок товаров.
Поставки товаров: код поставщика, код товара, количество, цена, единица измерения, дата поставки.
Справочники: поставщики (код, наименования, адрес, телефон, код города), товары (код, наименование), города (код, наименование, код области), области (код и наименование).
Отчет по городам и поставщикам с итоговой стоимостью поставленных товаров по городам и поставщикам.
Оплату гарантирую
Содержание кейса
1. Создать базу из основной таблицы с оперативными данными и четырех таблиц‑справочников с наименованиями кодов (используются для расшифровки кодов в формах, в представлениях, в запросах и в отчетах).
2. Создать базовый, перекрестные, итоговые, графические представления и запросы (не менее шести). Запросы и представления оформить в виде табличных форм, диаграмм.
3. Сформировать формы для заполнения таблиц и просмотра запросов, представлений с русифицированными кнопками, наименованиями полей (по одной форме для каждой таблицы и представления или запроса и по одной составной форме).
4. Сформировать отчет с детальными строками, с расшифровками кодов и с итогами по двум уровням группировки (указаны в условии), по одному простому отчету для каждой таблицы, представления, запроса .
5. Сформировать меню из пунктов: таблицы, формы, представления, запросы и отчеты для вызова разработанных таблиц, форм, представлений, запросов и отчетов.
6. Разработать систему программной защиты с регистрацией пользователей и их полномочий, журнала аудита для основной таблицы и защиты параметров настройки от изменений (п. 3.14.3). (Как мне объяснили - это значит, что, когда в БД заходишь, там окошечко пароля должно быть, чтобы её не мог изменить каждый)
Вариант 15. Учет поставок товаров.
Поставки товаров: код поставщика, код товара, количество, цена, единица измерения, дата поставки.
Справочники: поставщики (код, наименования, адрес, телефон, код города), товары (код, наименование), города (код, наименование, код области), области (код и наименование).
Отчет по городам и поставщикам с итоговой стоимостью поставленных товаров по городам и поставщикам.
Оплату гарантирую
Почему обычно на проде не ставят БД (постгрес например) через докер-контейнер а накатывают ее как отдельный сервис? Много раз слышал, но не врубаюсь почему
А смысл? СУБД обычно одна и работает постоянно, её не надо запускать десятками и уметь перезапускать налету в зависимости от нагрузок, как обычные приложения.

>Какой-то юзер меняет данные
>приложение коннектится к БД всегда от имени конкретного пользака БД, то есть БД ВООБЩЕ НЕ ЕБЁТ КТО ТАМ МЕНЯЕТ ДАННЫЕ
>осуществить логирование на уровне самого приложения питона или накатить авторизацию КАЖДОГО пользователя напрямую в БД, ПОЛНОСТЬЮ СДУБЛИРОВАВ ЛОГИКУ ПРАВ ДОСТУПА ИЗ ПРИЛОЖЕНИЯ ВНУТРИ БД БЛЯДЬ чтобы БД могла сама логировать на уровне БД?
Nigga, please!
Ты сам себе ответил считай, хули ты в себя не веришь, всё правильно подумал про уровень приложения.
Придумал гениальную защиту от sql-инъекций:
Мы просто при интерполяции строк проверяем данные по регулярке:
[A-Za-z\_0-9]+
Если не проходят проверку то сразу дроп. В принципе ситуация когда в строку вставляют что-то кроме этих символов очень подозрительна и в любом случае должна пресекаться. При таком подходе вероятность инъекций - 0%
Мы просто при интерполяции строк проверяем данные по регулярке:
[A-Za-z\_0-9]+
Если не проходят проверку то сразу дроп. В принципе ситуация когда в строку вставляют что-то кроме этих символов очень подозрительна и в любом случае должна пресекаться. При таком подходе вероятность инъекций - 0%
Нахуя снова и снова решать проблему, которую решили давным-давно? Параметризованные запросы придумали лет 30 назад.
>почти никто не держит бизнес-логику в БД
А как же бизнес-отчётики?
Или уже все пересели на носкл и в приложении конструируют свои ебовейшие запросы?
Как будешь параметризовать следующий запрос:
`SELECT DISTINCT {$attr_name} FROM reestr WHERE creation_date=to_date(:dto_date_str, 'YYYY-MM-DD') and {$attr_name} IS NOT NULL`
Или вот этот:
`CREATE DATABASE {$test_name} TEMPLATE {$default_db}`

>накатывают ее как отдельный сервис?
Потому что для "накатывания отдельного сервиса" достаточно одной команды apt install postgres? Плюс автоматические обновления и все-все-все. Контейнеры обычно применяются для запуска непосредственно разрабатываемого приложения, причем обычно это приложение разрабатывается на всякой говнине, типа питона, в которой нормально без контейнера нельзя управлять зависимостями, не поломав систему.
Конечно, бывают и случаи, когда админят бд зумеры, умеющие только докер, тогда и БД будет в контейнере.

Я наверное долбоеб раз такое спрашиваю, но все же. Как связать штуки из одной таблицы и цены из другой на основе таблицы категорий?
В Power BI делал объединение слева, нихуа не отображает значения.
В Power BI делал объединение слева, нихуа не отображает значения.
Пиздос. Там, где с клиента приходят названия столбцов и баз данных, бессмысленно что-то параметризовывать. Остаётся лишь выдать права админа всем пользователям и прямой коннект к БД, хуже уже не будет.

Реляционные БД - это как правило технологии древних, ими занимаются олдовые свитера, заставшие мейнфреймы. Они эти ваши докеры искренне не любят без всякой объективной причины, просто из классовой вражды.
redis, rabbit, монгу постоянно через контейнер гоняют
Получается, петушиная каста?
Относительно постгреса - это все технологии пориджей, поэтому так
На дев контуре у нас постгря - одна субд на десяток проектов, там несколько сотен баз.
А редисы, монги и еще более редкие штуки они обычно на одном-двух проектах есть и их себе разработчкики сами в контейнере понимают на той же машине где крутится контейнер сервисов проекта.
>одна субд на десяток проектов, там несколько сотен баз
Ну вот это не то чтобы хорошо. Это прикол из 80х, когда время ЦПУ стоило бабок, потому на кучу проектов выкатывали одну точку отказа с зашкаливающей инженерной ответственностью.
Ну и еще базы разработчики на этой общей постгре не могут сами создать, через опсов по заявке. А в носикулях и брокерах опсы разбираться не хотят, поэтому их поднимают разработчики.
Там какое-то кряхтение про безопасность и всякое такое, а сколько цп и памяти экономится на постгре без контейнера - хз.
Может поведение какое-то особое в контейнере. На проде ведь все будет в отдельных субд на отдельных машинах стоять без всяких контейнеров. Там экономить цп имеет смысл.


++
Слева типичный юзер nosql, справа - юзер рсубд

Есть постгрес, есть 100+ схем, в каждой есть нужная таблична с нужным полем. Как нормально одним селектом получить данные из каждой схемы, если названия и кол-ва схем могут меняться?
Т.е что-то на подобии SELECT foo FROM ALL_SCHEMA. Понимаю что такого нет, а то найти не могу, но надеюсь посыл понятен. Просто писать 100 FROM schema_1 ... FROM schema_2 не выйдет, да и просто тупо как-то выглядит
Т.е что-то на подобии SELECT foo FROM ALL_SCHEMA. Понимаю что такого нет, а то найти не могу, но надеюсь посыл понятен. Просто писать 100 FROM schema_1 ... FROM schema_2 не выйдет, да и просто тупо как-то выглядит
Написать код на питоне с for-loop и async, очевидно же
У меня жаба с multitenancy, где у каждого тенанта своя схема. Пока у меня доходят руки только до цикла с тучей селектов, потому подумал что хуета и надо искать ответ внутри самой бд
Гайз
Не кидайтесь камнями сразу.
Я ОРМ макака и вместо джойнов у меня они делаются через жопу QxOrm делаю пару селектов для выбора нужных мне айдишников, затем вставляют условие where id in(...) and id in(...)
Вопрос - когда я обосрусь по производительности или базе похуй?
Не кидайтесь камнями сразу.
Я ОРМ макака и вместо джойнов у меня они делаются через жопу QxOrm делаю пару селектов для выбора нужных мне айдишников, затем вставляют условие where id in(...) and id in(...)
Вопрос - когда я обосрусь по производительности или базе похуй?
>in(...)
Внутри массив циферок или селект это важно?
И какая БД вообще?
Должно быть похуй, поскольку ты линейно обсираешься с самого начала
Разве что расставить твои всратые in в порядке возрастания кол-ва возможных значений внутри, но это не точно.
другая_ORM_макака
>where id in(...) and id in(...)
where exists (select 1 from (твой селект) where твой_селект_id = id)
или как-то так
Внутри в разных запросах по разному, есть где массив цифр, есть где селект.
Бд постгрес, но скорее всего надо будет заставлять работать и на склайте.
Как сделать чтоб не обсираться?
Задача фильтрануть айдишники по куче параметров из других таблиц.
Так быстрее будет?
>Внутри в разных запросах по разному, есть где массив цифр, есть где селект.
>Бд постгрес, но скорее всего надо будет заставлять работать и на склайте.
>Плюсы блядь
Ебал в рот спасать ваш комок костылей да и скиллов не хватит, но может ты попытаешься как-то обернуть свою поисковую парашу в WITH перед основным запросом, чтобы оно хотя бы общую таблицу не дрочило столько времени, а дрочило один раз по итогу всех твоих левых селектов, последовательно перетёртых друг об друга?
Бля, подумаю... Но вообще вроде я дрочу каждую таблицу только раз, а далее в in(...) Вставляю дохуилион айдишников.



Братушки двачеры, помогите остолопу решить тестовое для собеса, умоляю
Зарплату тоже за тебя получать?
Попроси чат гопоту. В бинге из под эджа с впном бесплатно работает из рф.
> оператор выбора
Хуя канцелярит

Это на какую роль такие задачи и какую зарплату? Решил все
Что за редактор/ide?
dbeaver
> я дрочу каждую таблицу только раз, а далее в in(...) Вставляю дохуилион айдишников
>Внутри в разных запросах по разному, есть где массив цифр, есть где селект.
Вот там где селекты ты будешь дрочить основную таблицу её id-индексом об результат селекта, а потом об результат другого селекта, а потом об список циферок, и т.д.
НО
т.к. у тебя and между in, ты можешь хотя бы наванговать в каком in будет меньше всего строк результата и поставить его впереди остальных, чтобы он отпилил для дальнейшего скана об другие in(...) минимум строк из основной.
НО
ты не можешь гарантировать, что планировщик не пошлёт твои вангования нахуй и не перевернёт порядок in'ов исходя из своих сообажений, тем более что у тебя прям живые селекты там бывают.
ТАК ЧТО
безопаснее запереть все твои in(...) в WITH, только обязательно WITH MATERIALIZED, ибо обычный WITH только на читаемость влияет и на выполнении может закешить, а может и дёргать свой селект ))0)00)))0))0)))) каждый раз, как будто ты его как обычно прямо в запросе написал.
Результаты потом в тред принеси пжл.
P.S. неебу что там с WITH в sqlite, я после Postgres смотрю с пониманием только на Oracle на MSSQL с осторожностью.
Бля выглядит сложно, пойду думать.
Что именно притащить? У меня щас нет никакой нагрузки и в рамках посгреса скорее всего не будет, у меня это спортивный интерес.
Есть смысл сделать интерсект idшников программно? Мне это сделать не тяжело.
>сделать интерсект idшников программно
Ты просто кроме памяти БД потратишь ещё память приложения.
>Мне это сделать не тяжело
А вот приложению будет тяжело, если ты будешь тянуть id из базы создавая сущность для подтягивания, дёргая id и запихивая его в лист.
Постгре на С написан, быстрее ты посчитаешь разве что спаяв собственный контроллер с собственной прошивкой и всравно на самописных драйверах потеряешь всё что выиграл с большим запасом
>EXISTS
>Так быстрее будет?
EXISTS заебись, там же будут повторы, инфа сотка. Тебе же по сути нужно только чекнуть условие что id из основной встречается в in(...), данные из подзапроса не нужны.
Только я не уверен что тот анон привёл правильную структуру.
Короче я заебался и избавился от векторов in(), заменив их на in select. База же закеширует если я один и тот же запрос делаю?
Как exists прикрутить пока не придумал придумал, но дохуя переписывать. В целом действительно в логике косяк, хотя бы понял где, но на сегодня я заебался. в целом полезу сюда теперь когда мне не будет лень явно будет затык на этом месте, а его скорее всего никогда и не будет.
Спасибо за помощь всем.
ах да, ради чего это все: ща в таблице 2500 записей, при запросе из узкого пула айдишников время выполнения увеличилось, при запросе из широкого уменьшилось.
>закеширует если я один и тот же запрос делаю
Если оно в кеш влезет конечно.
>при запросе из узкого пула айдишников время выполнения увеличилось, при запросе из широкого уменьшилось.
Прелести планировщика пг, иногда он плохо планирует.
Вопрос от новичка, не пинайте. Как сильно постгре без дополнительных действий со стороны разработчика (то есть без каких-то оптимизаций и переписываний) зависит от производительности на ядро и многопоточной производительности? Что, условно, лучше, иметь 4 ядра Xeon Gold 6240 R или восемь-шестнадцать ядер старенького Xeon 2678 v3?
Да, я могу запустить pgbench и увидеть там рост от многопоточности, а в жизни эта многопоточность как, используется вообще самой СУБД, например когда пользователь выполняет запрос с подзапросом, или когда пользователя одновременно два?
Особенно интересна зависимость от многопоточности в задачах посложнее TPC-B, где в одном запросе могут быть подзапросы, нечеткие поиски с LIKE, агрегатные функции...? Есть кстати готовые бенчмарки, которые может запустить любой нуб, на подобные извращения?
вопрос по улучшению скорости добавления записи mySQL. Есть таблица в ней сейчас ~150к записей, постоянно добавляются новые. Есть текстовое поле VARCHAR с длиной ~35 символов. Проблема в том что при добавлении ищу есть ли такая запись по этому полю
SELECT link FROM {tablename} WHERE link = %s и на это уходит 1 секунда. Столбец в таблице для поиска не уникальный. Есть ли способ увеличить выполнение запроса? Или вообще сделать его уникальными и тупо добавлять?
SELECT link FROM {tablename} WHERE link = %s и на это уходит 1 секунда. Столбец в таблице для поиска не уникальный. Есть ли способ увеличить выполнение запроса? Или вообще сделать его уникальными и тупо добавлять?
Добавить индекс на это поле, ну или сделай уникальный индекс, тогда вставка с таким же значением отъебнёт и все

Коллеги с релевантным опытом, какие мнения насчёт пикрила?
selectOrUpdate
делать через int count = update ...
if (count == 0) {
insert into
}
или
boolean isExist = select true from ...
if (isExist) {
update ...
} else {
insert into ..
}
?
делать через int count = update ...
if (count == 0) {
insert into
}
или
boolean isExist = select true from ...
if (isExist) {
update ...
} else {
insert into ..
}
?
insertOrUpdate
fix
UPSERT.
Почему при инсерте сначала перечисляются столбцы, а потом значения?
Почему не сразу col1='aa', col2='bbb', col3='ccc'.....
Почему не сразу col1='aa', col2='bbb', col3='ccc'.....
Так исторически сложилось.

чот не могу всосать.
Предположим есть два select for update. В первой транзации эта строка удаляется. Когда блокировка снимется, что увидит вторая транзакция?
BEGIN
select where id = 1 for update
delete where id = 1
COMMIT
и параллельно вторая транзация ждёт
select where id = 1 for update
Первая транзация коммитится, строка удаляется, блокировка снимается, вторая транзация выполнится? Ведь строки уже не существует
Предположим есть два select for update. В первой транзации эта строка удаляется. Когда блокировка снимется, что увидит вторая транзакция?
BEGIN
select where id = 1 for update
delete where id = 1
COMMIT
и параллельно вторая транзация ждёт
select where id = 1 for update
Первая транзация коммитится, строка удаляется, блокировка снимается, вторая транзация выполнится? Ведь строки уже не существует
Если первая транзакция заблокирует запись раньше, селект во второй транзакции зависнет, пока не завершится первая. Ну а дальше селект во второй транзакциио либо ничего не вернёт (если первая транзакция закоммитилась), либо заблокирует запись (если первая откатилась). Пустой результат селекта корректен и не вызовет ошибок, т.к. SQL работает с наборами строк, отобранными по условию, а не с конкретными записями.
Если вторая транзакция заблокирует запись раньше, селект в первой зависнет, затем удалится запись, когда завершится вторая транзакция.
redis, пишу в конфиге
user default off -@all nopass ~
user erdogan on +@all nopass ~
, подразумевая, что всем юзерам, кроме одного, будет отказано в доступе. Однако доступ закрывается для всех. Что там нужно написать, кто-нибудь в курсе?
user default off -@all nopass ~
user erdogan on +@all nopass ~
, подразумевая, что всем юзерам, кроме одного, будет отказано в доступе. Однако доступ закрывается для всех. Что там нужно написать, кто-нибудь в курсе?
А, короче проблема решилась установкой пароля на пользователя. То есть логин можно сделать от любого юзера в системе. Ладно.
т.е. селект выполняется, видит что стоит блокировка, ждёт. Когда блокировка снимается, селект выполняется второй раз?
Это детали реализации. Скорее всего, нет, СУБД увидит запрос, найдёт у себя блокировку на такое же условие и просто не будет выполнять выборку, пока другая транзакция не завершится.
мы юзаем, но мне кажется в нашем кейсе науй не нужно
Смарите, есть куча файлов за много лет со структурой вида
all 100
_hui1 50
__hui11 25
__hui12 25
_hui2 50
__hui21 25
__hui22 25
Т.е. иерархичная структура и циферки это составляющие высшего уровня.
Надо провалидировать, что это так, т.е. из самой глубины сверять суммы с родителями.
Потом надо высрать в эксель сумму за все годы каждого элемента с той же иерархией.
Я пока придумал хранить в реляционке плоско и отдельно иерархию и уже кодом ебаться, но это как-то тупо. Может есть более подходящие решения?
all 100
_hui1 50
__hui11 25
__hui12 25
_hui2 50
__hui21 25
__hui22 25
Т.е. иерархичная структура и циферки это составляющие высшего уровня.
Надо провалидировать, что это так, т.е. из самой глубины сверять суммы с родителями.
Потом надо высрать в эксель сумму за все годы каждого элемента с той же иерархией.
Я пока придумал хранить в реляционке плоско и отдельно иерархию и уже кодом ебаться, но это как-то тупо. Может есть более подходящие решения?
Звучит как кейс для Nosql
600-700к/4года
Ну как с курсом повезет
Какую вышку получать по Базе Данных для корочки? Заочно вуз или курсы? На чьи лучше пойти? Всерьёз задумался профессию сменить, ибо инженерка по ОВИК оказалась- не моё.
Нюфаня в треде. Нужно написать приложуху - обертку над sql базой. Сама база есть. Думаю как правильно начать. чтобы потом не переделывать. Хуярю в WindowsForms.
Правильно ли будет создать отдельный класс, например SQLMyClass который будет отвечать за всю работу с базой - подключение, получение данных, добавление данный и прочее.
А остальные формы, будут общаться только с этим классом. По идее проблем быть не должно?
Запускаем приложуху, создается объект класса SQLMyClass, получаем список имеющихся баз по фильтру имени. Кликаем на нужную базу и она у нас база по умолчанию, пока пользователь не выберет другую. Если баз нет - создаем базу и пользуем.
И потом, все время работаем с объектом класса SQLMyClass - соединяемся, получаем данные, меняем что нужно и тд.
Выглядит вроде логично, но могут быть подводные? Просто раньше у меня был проект, где был адский пиздец и куча запросов из разных форм и вообще нихуя не понятно что и где.
П.С. Стоит ли пробовать использовать LINQ или ну его нахуй и проще руками все писать, без изъебонов?
Правильно ли будет создать отдельный класс, например SQLMyClass который будет отвечать за всю работу с базой - подключение, получение данных, добавление данный и прочее.
А остальные формы, будут общаться только с этим классом. По идее проблем быть не должно?
Запускаем приложуху, создается объект класса SQLMyClass, получаем список имеющихся баз по фильтру имени. Кликаем на нужную базу и она у нас база по умолчанию, пока пользователь не выберет другую. Если баз нет - создаем базу и пользуем.
И потом, все время работаем с объектом класса SQLMyClass - соединяемся, получаем данные, меняем что нужно и тд.
Выглядит вроде логично, но могут быть подводные? Просто раньше у меня был проект, где был адский пиздец и куча запросов из разных форм и вообще нихуя не понятно что и где.
П.С. Стоит ли пробовать использовать LINQ или ну его нахуй и проще руками все писать, без изъебонов?
САМОСБОР
САМОJOIN with recursive
Суки блядские закладчики-вебкамщики, СТЭК кто указывать будет?
>Нужно написать приложуху - обертку над sql базой
Гугли CRUD и пиши на чём хочешь.
Смотря что может понадобиться переделывать, вдруг тебе хватит один раз накидать контролы мышкой со всякими Form12 и Buttton43 с SQL-запросами в OnClick и потом 15 лет пользоваться и не дорабатывать.
Если делать по науке, читай про MVVM и MVP. Узнаешь основные принципы, как отделить пользовательский интерфейс от логики и от работы с БД. Хотя там не всё применимо к винформам.
В добавок к LINQ можешь взять Entity Framework.
Спасибо!
Я уметь писать сложный скуль запрос? Куда катиться дальшэ?
PL/SQL
А админить скуль сервер уметь?
Если под админить скуль ты подразумеваешь умение подключиться к бд через консоль, то да, уметь
Нет, я подразумеваю проектировать и масштабировать, настраивать всякие заумные DWH и ETL залупы, там уже не только sql требуется.
postgresql 9.6 + немного php
еба, неплох. че у тебя по стеку, радной?
Bitrix, WordPress, MySQL
для валидации просто сравниваешь сумму родителя и сумму дочерних
для екселя через рекурсию собираешь
Надо быть тоньше, перетолстил с битриксом. Не, я еще могу поверить что Дон Боар, у которого микросервисы на вордресе исторически сложились, будет платить $7k. Но битрикс кабаны никогда не будут платить стока, да даже в 5 раз меньше.
Нюфаг итт, пытаюсь разобраться в PG. Объясните, как в security_invoker view открыть/закрыть доступ к столбцу? Ну например таблица users со столбцами user_id, name, avatar, email. Она закрыта на публичное чтение через rls по user_id (типа чтобы по дефолту данные только сам юзер мог прочитать), теперь хочу дать всем зареганым смотреть avatar и name в профиле юзера на сайте. Это же через view делается с опцией security_invoker, или я не туда полез? Есть где-то примеры такого?
Если ты майор, то вот этого не должно тебе на доказательную базу хватать. А если анон* (с мозгами), то хватит чтобы найти.
Попробуй поиск через гугл, там есть ссылки на соцсеть и двач. Чел в соцсети был рад дать сурс на пиксиве.
Шевели булками, если хочешь подрочить!
acl
Есть некий набор Х из значений в количестве около 100 штук. И есть postgres таблица material_data в которой около миллиона записей, надо проверить, какие из значений набора X есть в определенной колонке таблицы material_data а какие - нет. Как это сделать?
Я могу конечно отсылать по запросу на каждое значение из X и смотреть, есть оно в табличке или нет (в ней есть индекс по нужной колонке), но делать так 100 раз?.. Причем даже асинхронное - такое себе. Какие есть еще варианты? Как видите, выгрузить все значения из таблицы material_data в память и потом с ними играться - невариант, их слишком много
Я могу конечно отсылать по запросу на каждое значение из X и смотреть, есть оно в табличке или нет (в ней есть индекс по нужной колонке), но делать так 100 раз?.. Причем даже асинхронное - такое себе. Какие есть еще варианты? Как видите, выгрузить все значения из таблицы material_data в память и потом с ними играться - невариант, их слишком много
select max(opredelyonnaya_kolonka) from material_data where opredelyonnaya_kolonka in (список значений через запятую) group by opredelyonnaya_kolonka;
Или создать таблицу из этих 100 значений и делать inner join.
SELECT UNNEST(array[%x_data])
INTERSECT (SELECT name FROM material_data)
А где примерно работаешь? Что за компания с такими зарплатами на битриксе?
>такими зарплатами
Он называет зарплату в долларах, что при нынешнем говнокурсе выглядет ниче так если живешь в Рашке или ЮВА
Если же живешь в Эмиратах или тем более Европке или США - это довольно хуевый уровень
Пацаны, а как "развернуть" record в обычную запись чтобы из него сделать ARRAY в постгресе?
Ну вот такая хуйня получается:
ARRAY[('100', '200', '300')]
Очевидно что оно падает потому что в array надо передать сразу значения через запятую, но блять sqlalchemy передает множественные значения в query именно так. Как это обойти? Все что пока что нашел это конвертировать мой массив в строку, вставить в query строку и потом сделать string_to_array (!) - хуйня конечно но работает вроде
Ну вот такая хуйня получается:
ARRAY[('100', '200', '300')]
Очевидно что оно падает потому что в array надо передать сразу значения через запятую, но блять sqlalchemy передает множественные значения в query именно так. Как это обойти? Все что пока что нашел это конвертировать мой массив в строку, вставить в query строку и потом сделать string_to_array (!) - хуйня конечно но работает вроде
А вот я чет задумался: если мы пишем
SELECT <звездочка> FROM mytable
Без указания сортировки то по какому принципу (в каком порядке) нам выведутся данные? Что там за "дефолтная сортировка"? Они совсем рандомно не выводятся, на первый взгляд они сортируются по id (pk) но при более тщательном рассмотрении это не так. Как это работает в тех же Postgres / Oracle ?
SELECT <звездочка> FROM mytable
Без указания сортировки то по какому принципу (в каком порядке) нам выведутся данные? Что там за "дефолтная сортировка"? Они совсем рандомно не выводятся, на первый взгляд они сортируются по id (pk) но при более тщательном рассмотрении это не так. Как это работает в тех же Postgres / Oracle ?
implementation defined
Чисто логически - в том порядке, в котором лежат в памяти
Сап. Есть какие годные роадмапы для sql?
sql-ex около 100 задач
Пару пет проектов на postgresql или oracle или ms sql
Собес
Может, оно неправильно, но испрользую BEGIN EXCLUSIVE на базе SQLite, чтобы запретить запуск еще одного экземпляра приложения. Но нужно периодически между своими запросами вклинивать "COMMIT; BEGIN EXCLUSIVE". Может ли в промежутке между COMMIT и BEGIN другой поток или приложение успеть залочить базу? В принципе, если я сделаю один общий BEGIN EXCLUSIVE при запуске приложения и COMMIT при завершении, а в середине буду все делать через SAVEPOINT, то это то же самое получится? При отрубе питания ничего не пропадет в режиме journal_mode = WAL?
Какие пет-проекты пилить то?
И на какие вакансии мне потом откликаться? DBA?
Зочем? Просто зарабатывай на паскодах
А если серьезно?
почекай тестовые в свободном доступе от озона вайлдбериза от сбера от любой конторки, раньше валялось всегда че нить на просторах. Потом на разраба. Пока будешь пилить читай доку. На постгрис про есть целые лекции в пдф на разраба и дба. ты идешь на разраба.
энивей без sql-ex хотябы в 80 задач лезть дальше тупо смысла нет.

Артем, ты?
не, я его последователь, прошел его путь и стал им по итогу. уже почти годик на постгри прогаю и работаю. так шо он так то дело говорит
Павел? Я сразу про вас подумал!
Кароче хочешь ASSкуэлить, то проходи шарагу а дальше токо сотни hr с собесами. Токо так. Ну или поступай в итмо на большие данные, учись 4 года и быыыть может ты сможешь пробиться на стажировочку куда нибудь за +-0 рублей, а мб и нет и по итогу 4 года вьебешь. Ну вобщем то вот.
Короче стало мне любопытно, как бы это на SQL сделать. Сделал.
Действительно заебно. Однако очень познавательно. Пока делал кучу новых фишек для себя открыл. Современный SQL позволяет тебе делать ТАКОЕ...
https://dbfiddle.uk/2l5odSO7
Вопрос есть дамп базы данных, как мне определить из какого он типа базы (MySQL, MS SQL, ...)?
Если базу открыть то она состоит из текста в начале в виде: {"_index":"prodindex","_type":
Если базу открыть то она состоит из текста в начале в виде: {"_index":"prodindex","_type":
Красиво сахарком постгреса оперируешь.
Не не не. Тут очень важный момент, что это сахарок не постгреса, а именно SQL стандарта.
UNNEST WITH ORDINALITY, например, в стандарте 99 года https://ronsavage.github.io/SQL/sql-99.bnf.html#xref-ORDINALITY
Это нужно понимать когда выбираешь mysql в качестве базы. Иронично, но mysql несмотря на sql в названии, формально sql базой не является. Потому что не поддерживает полностью ни один из стандартов sql.
Ну майскл это вообще кринж так то. А кодик харош. Оконочки наше всё. Попробуй как нить написать код который будет искать максимальное значение и почекай скорости на больших данных (на пг)
>Попробуй как нить написать код который будет искать максимальное значение
Максимальное значение в группе? Опиши задачу поконкретней.
ну типо того. есть лог данных и тебе надо вывести ласт (по времени) строку лога определенного id. Тут чисто на скорости посмотреть интересно было. на моем серваке с моими настройками с помощью оконки быстрее всего получилось.
А насколько "большие" данные?
это логи, точное число не скажу. полтора лямчика вроде было. есть индекс по времени и на ойди тоже индекс есть
А по сколько дат на один id?
я когда тестил брал рандомных 50 ойди. когда я чекал всего по датам то у меня выходило всегда что то около 1к
Кароче попробовал всякое https://dbfiddle.uk/kGoWz2Do . Гонял на 50кк и все способы примерно одинаковые по скорости 40-50мс. Даже обычный group by. Попробуй по тестируй на живых данных, может что-то окажется получше.
Да и еще важный момент. Если таблица большого размера, то я бы рекомендовал не ебашить по ней целиком запрос в тупую, а сделать процедуру, которая в цикле пачечками по 10к будет обрабатывать и складывать. Тем более что это логи, их никто блокировать не будет.
Зобыл добавить. Таблица партиционированая. Там 24 партиции
А нахуя?
Для каждой таблицы своя таблица таьлица лога
Типо есть таблица родитель называется лог
А дальше идут от нее наследники лог_для_таблицы_1.
вообще в целом бд говна по ощущениям, так шо странных вещей там хватает
без индекса разница еще заметнее
Вопрос нахуя остается открытым.
В некоторых ситуациях группировка бывает оооочень медленной. Полезно уметь обойтись без группировки. Хотя на 500к время выполнения совпадает до микросекунды. Похоже под капотом движок одну и туже оптимизацию делает.
>без индекса разница еще заметнее
Ну это не реальная ситуация. Индекс есть всегда.
ну вообще говоря про индекс всегда тоже спорно. это расходы на его обслуживание. хотя по факту это мусорка и оттуда нехйу селектить по кд и жить можно и без индексов, чтобы никак не влияла вставка на общую производительность.
мой код становиться мега гавном когда речь идет не про 1 ойди, а я говорил как раз о задаче когда нужно токо для определенного.
плюс мы сча тестим хуйню не на ссд и без норм настроек пг и статистики.
И кста, поч ты так любишь цтешки? этож кал говна, не?
.
Проект не нравится этот в целом, но пока так. И поменять особо ничего не могу. А надо бы... и партиции это токо верхушка, если бы я тебе расказал чуть больше, ты бы охуел...
бля под этот пример и этот код говна, видимо я неправильно в целом задачу описал. ну да похуй.
>ну вообще говоря про индекс всегда тоже спорно. это расходы на его обслуживание
И какие у тебя расходы на его "обслуживание"? Типа вставка на наносекунду ниже? Ваще пахую на такое. Места он конечно занимает, но место щас вообще никто не считает. А если тебе нужно поиск по терабайту делать, так нахуй тебе вообще реляционная база тогда.
>мой код становиться мега гавном когда речь идет не про 1 ойди
Посмотри последний пример отсюда https://explainextended.com/2009/11/26/postgresql-selecting-records-holding-group-wise-maximum/ там как раз несколько полей для группировки используется.
Вообще статья четкая, я вот этой конструкции просто охуел и кончил:
SELECT (SELECT n FROM (VALUES (1, 2)) AS n(n1, n2))
Внутри селект части можно сделать подзапрос, но он должен возвращать только одно значение. А если надо несколько? Да нехуй делать, просто возвращай значение, содержащее весь ряд нахуй. Причем это не строка какая-нибудь, ты по прежнему можешь получать оттуда отдельные значения через (n).n1
Отвал башки просто.
А так это типо select record получился какой то, прик.
Не уверен насчет небольших трат на индекс. В среднем дмлка которая чето добавляет /изменяет ведет за собой каскадных изменений на кесик-три кесика (в моем текущем проекте). Собсно вечь этот каллл надо записать. А че если одновременно будет 5 юзеров, которые чето добовляют. Там итак у базф горм будет работки а мы еще ему накидываем обслуживать мусорку. Ну хз. Если появляется потребность читать логи прям постоянно никто не мешает накатить индекс потом, но я так подозреваю что ечли мы начинаем читать логи по кд, то мы чето анализируем а в логах сам понимаешь больше инфы чем ойди и время, там как минимум состояние строки или что то этакое, а там обычный битри индекс не катит, там скорее всего будет гист. Кароче хзхз. В целом если не планируется дохуя инсертов и апдейтов то мб и можно, а так... Мне чот не кажется это охуенной идеей, не зря брин индекс существует жеж
А ну и накину то шо обычно запись в лог это делается триггером фор ич ров, что как бы изначально хуево а потом в процессе этой хуйни будет какой нить вакуум работать или просто гин индекс будем вставлять в мусорке ну це пизда
>Там итак у базф горм будет работки а мы еще ему накидываем
Мой пойнт что ты на самом деле не знаешь сколько ты накидываешь, просто где-то прочитал что индексы это дораха.
>там скорее всего будет гист
Не будет. Этот индекс работает не так как ты думаешь. Если нужен полнотекстовый поиск по логам, то это 100% эластик, кибана и вся вот эта хуйня. Туда прямо терабайтами можно логи хуярить, без дурацкого партицирования.
>не зря брин индекс существует
Опять же он в этой ситуации не подходит.
Запросы которые я писал были на группировку логов по дате. Если нужен поиск по ТЕКСТУ, то сразу мимо. По json'у еще куда ни шло, но все равно медленно будет. Но просто по тексту это сразу мимо реляционной базы.
>Мой пойнт что ты на самом деле не знаешь сколько ты накидываешь, просто где-то прочитал что индексы это дораха.
Зайди в свой код и не добавляй индекс, посмотри на скорость вставки (спойлер примерно в 10 раз будет быстрее).
Как раз таки я знаю сколько я докидываю и знаю что бд под большим кол-вом одновременных вставок/изменений превращается в тыкву(мертвых строк в пг становиться ПИЗДЕЦ как много, ибо хот update тупо нет в случае если есть индекс и если нет места на странице). Не веришь - твоё дело. Мне доказывать что я чё то не знаю не нужно, по крайней мере без пруфов.
>полнотекстовый поиск
Кто тебе про это сказал? Существуют hstore с ключом=>значением и иногда нужено найти что то по ключу
> По json'у
Кек, какой нахуй json. Кто его юзает блядь в реляционке? Кринг... jsonb - да, но это не json в твоем понимании.
>Опять же он в этой ситуации не подходит
Его вешать на дату и всё. Никаких других стратегий юзанья не вижу в той задаче, о которой мы сейчас толкуем.
> 100% эластик, кибана и вся вот эта хуйня.
Ну и дополню тем что не все проекты могут это юзать. Привет из ФСБ, друг =)
>Зайди в свой код и не добавляй индекс, посмотри на скорость вставки (спойлер примерно в 10 раз будет быстрее).
Я третий раз говорю: конкретно, сколько? Без наверное и похоже. Сколько на самом деле?
>Кто тебе про это сказал? Существуют hstore с ключом=>значением и иногда нужено найти что то по ключу
Это не полнотекстовый поиск.
>jsonb - да
Я про его и говорил. И все равно медленно на больших данных.
>Его вешать на дату и всё.
Неправильно. Нам все равно нужно все даты в таблице проверять и этот индекс тут не поможет. Если бы нам нужно было задать диапазон по дате, то да.
>Ну и дополню тем что не все проекты могут это юзать. Привет из ФСБ, друг =)
И че фсбшиники не умеют пользоваться эластиком? Прям все поголовно?
>Я третий раз говорю: конкретно, сколько? Без наверное и похоже. Сколько на самом деле?
Возьми и чекни. https://dbfiddle.uk/imIvr4UT
Плюс пиздуем в доку и читаем
https://postgrespro.ru/docs/postgresql/9.6/indexes-intro
>После создания индекса система должна поддерживать его в состоянии, соответствующем данным таблицы. С этим связаны неизбежные накладные расходы при изменении данных. Таким образом, индексы, которые используются в запросах редко или вообще никогда, должны быть удалены.
Я говорил про сценарий когда мы а) пишем не "логические" логи, б) очень редко из них читаем в)логи в нашей базе и пишутся самой базой
>Это не полнотекстовый поиск.
Да он и не всегда и нужен, второй раз говорю. Но ты не сможешь создать на хсторку ничего другого вразумительного что тебе позволит быстро ползать по ключам
>Неправильно. Нам все равно нужно все даты в таблице проверять и этот индекс тут не поможет. Если бы нам нужно было задать диапазон по дате, то да.
Чекай линк и план. Плюс я не вчитывался в твой код с тем как ты генерируешь и вставляешь даты, но в реальности не будет такого что у тебя сначала вставился лог июлем, а потом января этого же года. И в этом случае брин будет еще лучше работать ну и настройки сервака нужны. Ну и задача на максимум это тоже диапазон ))))) если есть начало 01.01.23 то если и конец 31.12.23 )) упс конец диапазона и есть макс число! не может быть)
>И че фсбшиники не умеют пользоваться эластиком? Прям все поголовно?
Лни не могут юзать что то , что не имеет сертификации и мандатных меток или аналога. даже постгрис у них свой и нет, это не постгрис про, а вообще свое ядро.
Братишка, ты ведь в памяти все это делаешь. В этом запросе на создание у тебя индекс и таблица по размеру одинаковые и в памяти хранятся целиком, получается в два раза больше ресурсов тратится. В реальности никто по 500к записей не вставляет. Ты ведь всерьез не думаешь что btree индекс тупо в два раза вставку замедляет? Кто бы тогда постгрей пользовался вообще.
>Да он и не всегда и нужен, второй раз говорю.
А хсторка тем более не нужна. По jsonb если че делается стандартный btree индекс по выражению column ->> 'field'. Потому что он гораздо быстрее всего остального.
>Чекай линк и план.
Ну ты конечно хитрый. У тебя же в первом запросе всего одна запись выбирается. Сделай обычный GROUP BY id LIMIT 10 и скорость будет такая же.
А дело в том что BRIN индекс нужен чтобы ПРОПУСКАТЬ строки. Типа ты знаешь что начальная дата периода на диске вон там, а поскольку данные последовательные, то заданный период может быть только после строки с начальной датой. И ты пропускаешь все страницы и строки до строки с начальной датой. За счет этого прирост производительности и идет.
А в нашем запросе надо максимальную дату определить для КАЖДОГО id, а для этого нужно ВСЕ даты прочитать. Нечего скипать. И индекс нам из-за этого мало помогает, нам тупо надо прочитать каждую строку в таблице.
А вот в запросе с рекурсией, хотя он и получился медленнее всех, мы именно что скипаем строки за счет повторной сортировки в рекурсивной части. А медленный он потому что мы буквально по одной строчке прибавляем 25к раз. Если это будет десять раз. Или если надо будет выбрать по большему количеству условий или идентификаторов будет не 1 к 20 датам, а 1 к 10к, то прирост будет очень сильный.
Запрос с лефт джойном кстати совсем плохой. Потому что сначала в памяти происходит джойн, а потом условие. Убери лимит и охуей: Rows Removed by Join Filter: 2 446 129. Это при размере таблицы 500к. А если там 50кк будет? Охуенный способ нагенерить неколько гигов мусора.
>Лни не могут юзать что то , что не имеет сертификации и мандатных меток или аналога. даже постгрис у них свой и нет, это не постгрис про, а вообще свое ядро.
Ну а кто им мешает сертифицировать эластик кроме их собственной лени? Ну или сделай виртуалку на "сертифицированном" линухе, закрой на ней доступы по своим ебанутым фсбшным правилам, и крути там эластик. То что погоны умом и сообразительностью не отличаются это всем известно.
> В реальности никто по 500к записей не вставляет.
Вставим 1 строку
https://dbfiddle.uk/JUDvVeE8
Я не понимаю, ты доку принципиально никогда не читал или ты её игнорируешь? Энивей успехов те в создании логов с индексами, чо сказать.
>А хсторка тем более не нужна
Угу сча бы старую легаси проект взять и переписать с нуляку под jsonb вместо хсторки, каждый день токо это и делаю.
Ясен хуй хсторка не нужна, но приколись не все базы разрабатываются с нуля! Иногда тебе надо поддерживать говно мамонта.
>Сделай обычный GROUP BY id LIMIT 10
Ты почему то сам это написал а теперь считаешь это за изначальную мою задачу
> тебе надо вывести ласт (по времени) строку лога определенного id
Определенное ойди это не LIMIT 10
А если ты уберешь и лимит 10, то че будет?)
>Запрос с лефт джойном кстати совсем плохой.
А каким он еще должен быть то? Я тебе его написал к своим словам из
>Ну и задача на максимум это тоже диапазон )))))
>Ну а кто им мешает сертифицировать эластик кроме их собственной лени? Ну или сделай виртуалку на "сертифицированном" линухе
Чел, чтобы он стал сертифицированным ему едро надо переписать целиком, потому что у тебя на серваке будет дохуя пользаков, с разными доступами секретности. И кто то даже не должен блядь знать что какая то запись вообще существует на серваке.
>То что погоны умом и сообразительностью не отличаются это всем известно.
Ну, хотя бы читать умеют доку, в отличии от некоторых)
>>
>Вставим 1 строку
>Execution Time: 0.224 ms
>Execution Time: 0.925 ms
Вывод: индекс замедляет вставку в четыре раза. Ты это хочешь сказать?
>Иногда тебе надо поддерживать говно мамонта.
Ну и? Я так-то все запросы на 14 версии писал. Не понимаю зачем ты вообще хстор приплел? Ну было и было. Но прошло.
>Ты почему то сам это написал а теперь считаешь это за изначальную мою задачу
Я это написал чтобы сайт по 500к записей на страницу для каждого запроса не вываливал (а он пытался). А так-то ты сам задачу поставил на выборку по всей таблице.
>А если ты уберешь и лимит 10, то че будет?)
Я и описал в своем посте что будет. Будет поиск по всей таблице и оптимизатор не будет срезать углы зная что надо всего одну строку высрать.
>А каким он еще должен быть то? Я тебе его написал к своим словам из
>Ну и задача на максимум это тоже диапазон )))))
Нет, ты просто свел её к диапазону, по сути сгенерировав этот диапазон лефт джойном. Я в своем посте объяснил как правильно эмулировать диапазон сортировкой. Сортируем 1234 и берем первую запись. Потом сортируем 4321 и опять берем первую запись. Получаем 1-4 диапазон при том же самом количестве строк. Рекурсивный запрос примерно так и делает, просто на таких данных он немного медленнее. А с диапазонами 1-10к очень ускорится.
>Чел, чтобы он стал сертифицированным ему едро надо переписать целиком, потому что у тебя на серваке будет дохуя пользаков, с разными доступами секретности.
Ты вообще не читаешь что я пишу? Ты можешь создать организацию доступов НАД эластиком. На уровне пользователей ОС, например. Или сам её написать если есть время и бюджет.
>Ну, хотя бы читать умеют доку, в отличии от некоторых)
Ну это слишком жирно.
>Вывод: индекс замедляет вставку в четыре раза. Ты это хочешь сказать?
ну явно не ускоряет в 4 раза. Я просто не понимаю твою позицию в корне, как можно считать, что понаписав индексов на таблицу фулл логирования с учетом того, что из нее селектят раз в месяц +- можно быть уверенным что ты все сделал правильно. Абсурд.
>14 версии
толстота. старая версия это 9.6 и на них до сих пор работают
потому что
>Или сам её написать если есть время и бюджет.
и ты сам знаешь с чем тут проблемы)
> А так-то ты сам задачу поставил на выборку по всей таблице.
для определенного ойди а не для каждого.
>Я просто не понимаю твою позицию в корне
Моя позиция в том что все не настолько драматично. Да замедляет, но процентов на десять каждый индекс.
>что понаписав индексов на таблицу фулл логирования
Что значит "понаписав"? По содержимому там никаких индексов нет. Если че Primary key автоматически создает Btree индекс.
>толстота. старая версия это 9.6 и на них до сих пор работают
Ну работают. Опять не понял к чему это вообще?
>и ты сам знаешь с чем тут проблемы)
Знаю. Ну и кто в этих проблемах виноват? Разве эластик? Сапоги-погоны сами себе дураки. Вот пусть и катают квадратное. А нормальные люди пишут логи туда где от них будет толк.
>для определенного ойди а не для каждого.
Это щас шутка была? Не смешно.
>Да замедляет, но процентов на десять каждый индекс.
ого! прогресс! и зачем нам тогда тратить ресурсы на логи, которые мы редко юзаем?
>По содержимому там никаких индексов нет
там это где? ты написал составной битри на все поля
>Если че Primary key автоматически создает Btree индекс.
ну у тебя нет pk и кстати pk эт не просто битри, а уникальный битри если че =) а на проверку уникальности тоже времечко будет уходить в жестокой боевой реальности и уже от этого уйти нельзя вообще.
> Опять не понял к чему это вообще?
к причине юзанья хсторки
> А нормальные люди пишут логи туда где от них будет толк.
Использовать редко <>бестолковые
И че за негатив к людям в форме? это из за смузи или чего? у меня негатив к людям, которые цтешками обкладываются с ног до головы, например.
>Это щас шутка была? Не смешно.
да никто и не смеется, ты буквально написал код который ищет для всех, а я писал про задачу поиска для одного конкретного ойди.
Ты сам возьми и попробуй в 5 сеянсах вставить по 1 кесику строчек в одну таблицку и все сразу станет ясно. нужны индексы, не нужны индексы и скока там процентов. А то мне сдается что ты нихуя и не разраб бд, дружище, а какой то аналитик или хз кто, который тока в селект и может
>и зачем нам тогда тратить ресурсы на логи, которые мы редко юзаем?
Зависит от того насколько "редко" и нагрузки на базу вообще. Если база под нагрузкой, то запрос без индекса на 50кк строк может насрать всем остальным. Кстати один из вариантов создания таких логов - через репликацию. Отдельная нода, которой на всех остальных похуй и индекс твою основную вставку нагружать не будет.
>там это где? ты написал составной битри на все поля
Там это в настоящей базе. Хватит троллить тупостью, пример это всего лишь пример. Я не могу на этом сайте еще и логи генерить, там и так даже 1кк записей не вставить. Этот сайт просто чтобы показать запросы красиво.
>ну у тебя нет pk
Опять же потому что это твой пример. В моей базе очевидно pk был бы.
>к причине юзанья хсторки
Круг замкнулся.
>И че за негатив к людям в форме? это из за смузи или чего?
Ну это ты начал людей в форме обсирать. Сам начал рассказывать как они ограничены и что у них все не как у людей.
>да никто и не смеется, ты буквально написал код который ищет для всех, а я писал про задачу поиска для одного конкретного ойди.
Ты понимаешь что для этого нужно просто сделать запрос WHERE id = n и все? Никаких оконных функций, никаких группировок, никаких CTE.
>Ты сам возьми и попробуй в 5 сеянсах вставить по 1 кесику строчек в одну таблицку и все сразу станет ясно.
Я думал над этим. Слишком сложно получается такое провернуть. Это либо какую-то очень хитрую процедуру писать. Либо из кода так срать в базу. Дохуя мороки. Мое понимание стоимости индексов из опыта работы с хайлоадом. Если идет только вставка, а удаление чисто логическое, то оверхед от индексов вполне терпимый. Он буквально вопринимается как налог на работу с таблицей больше миллиона записей. Потому что без индекса это просто пиздец, который всю память засрет.
просто в нем есть все и он бесплатный!
мимо работал и на MSSQL и на MySQL, даже на Oracle
NoSQL в 2023? Ты долбоеб? Эта залупа изначально смузи-уебками придумано было, что не смогли осилить все формы Бойса — Кодда. Не взлетела и нахуй никому не нужна
Суп, появилась возможность вкатится в администрирование Oracle NetSuite, собна вопроса два:
1) Что базовое можно почитать для вката?
2) Какой IDE лучше для написание кастомных скриптов для этой ебанины?
дед, таблетки принял?
Это ты примерно так прочувствовал что все они не взлетели?
Эластик вполне себе взлетел, не видел ни одной компании где его не используют.
Редис взлетел. Опять же везде и повсюду.
Кликхаус взлетел. Этот уже не везде, но много где встречается.
Кассандра, сцилла взлетели. В кассандру вставка данных быстрее чем чтение. Если у тебя запись миллионов строк в секунду, то у тебя вариантов всего пара. И это пара не rdbms.
neo4j взлетела. Если данные хоть немного походят на граф, то она в сотни раз быстрее реляционной.
>Эластик вполне себе взлетел, не видел ни одной компании где его не используют.
Эластик - можно реализовать и без ваших nosql
>Редис взлетел. Опять же везде и повсюду.
кроме редиса - все говно ( и то, в большистве своем это тупо memory-кэш который на коленке за 10 минут делается )
Остальное говно без задач
смузи уебок порвался. Иди мафина наверни и в доку 2 подрочи или там в овервотч
>Кликхаус
А его то зачем в эту гоп-компанию приплел?
отключи индексы долбоеб
>Эластик - можно реализовать и без ваших nosql
Реляционный эластик? Ну скинь перфоманс тесты реализации, поржу.
>это тупо memory-кэш который на коленке за 10 минут делается
Кек. А репликация тоже на коленке делается? Давай сбацай мне на коленке реализацию HyperLogLog.
>Остальное говно без задач
Ну так у тебя задачи говно. Для них и microsoft access достаточно.
>А его то зачем в эту гоп-компанию приплел?
Популярное nosql решение. Многие логи и журналы там хранят. А тебе что вкусно только заграничное?
>отключи индексы долбоеб
Хули еще отключить? Транзакцции? mvcc? acid?
Autovacuum на шесть утра настроил и бегом за пивандепалой для nosql батьков.
В каком месте кликхаус nosql?
>В каком месте кликхаус nosql?
А в каком месте нет?
Не реляционная база, которая на поддерживает ни один из SQl стандартов.
Про кассандру ты почему-то этого не спросил, хотя там язык запросов тоже на SQL похож.
Давай жопой не виляй. Все более менее соответствует
https://clickhouse.com/docs/ru/sql-reference
https://clickhouse.com/docs/ru/sql-reference/ansi
Ну ты и еблан канеш.
Ты типа думаешь что nosql означает что SELECT'а нету? Это в первую очередь относится к тому как хранение данных устроено.
Вот запрос SELECT lastname FROM cycling.cyclist_name LIMIT 50000;
Обычный такой SQL запрос. Вот только это запрос для кассандры https://docs.datastax.com/en/cql-oss/3.3/cql/cql_reference/cqlSelect.html
Перестала от этого кассандра быть nosql базой? Ясен хуй нет. Потому что cql просто похож на sql.
>более менее


>Это SQL база
>А ты чё не верил?
Она даже не ACID-compliant, блядь!
Ну если серьезно, то ей и не надо. Вся эта sql залупа там только чтобы легче переезжать на неё было. Больше потенциальная аудитория - больше классов яндексу. Это додик выше начал её в реляционные базы записывать, непонятно нахуя.
Давай жопой не виляй 2. Ты пытаешься подменить предмет обсуждения. Речь шла о кликхаусе, а не касандре. Когда люди говорят о nosql то подразумевают кей-валуе и графовые СУБД
Если это не реляционная СУБД то нафейхоа там JOIN
https://clickhouse.com/docs/en/sql-reference/statements/select/join
То есть реалиционные операции на табличках это основа кликхауса - значит РСУБД


>говорят о nosql то подразумевают кей-валуе и графовые СУБД
Ну тоесть hbase и кассандра не nosql?
clickhouse точно такая же колоночная база. Тебе даже анимацию красивую нарисовали. Имаджинирую ебало разрабов когда каждому додику нужно картинки красивые рисовать чтобы до него дошло.
>Если это не реляционная СУБД то нафейхоа там JOIN
Чтобы данные в памяти объединять? Ради мира на земле? Ты че хочешь услышать, еблан?
>То есть реалиционные операции
Ну типа они берут свои нереляционные данные, преобразуют их в реляционные, и делают джойн.
Ты можешь над эластиком надстройку написать, которая будет делать два запроса, преобразовывать json'ы в формат таблицы и делать джойн. Эластик от этого реляционным станет?
Давай как и ты начну на другие СУБД съезжать...
У Mysql есть колоночный движок https://warpsqlblog.wordpress.com/2020/02/02/warpsql-introduction/
Mysql не РСУБД?
>ACID Compliant with MVCC capabilities
Бля, ебанько, ты бы хоть читал че постишь.
Ты понимаешь слово реляционная? Причем здесь транзакции? Транзакции нужны для OLTP. Кликхаус специально для OLAP задизайнен. Реляционные операции он поддерживает. Я переносил запросы между мускулем и кликхаусом, туда и обратно. Проблем не было. Короче я устал от тебя, иди нахуй

Посоветуйте OLTP решение:
- Open Source;
- Распределенную;
- С нативной поддержкой UUID7;
- С авто-партиционированием из коробки: у меня мультарендность и есть желание не хранить перемешанные данные, чтобы затем читать с диска лишние данные на запросы;
- Open Source;
- Распределенную;
- С нативной поддержкой UUID7;
- С авто-партиционированием из коробки: у меня мультарендность и есть желание не хранить перемешанные данные, чтобы затем читать с диска лишние данные на запросы;
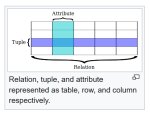
Бля, чучело ты понимаешь что термин "relation" относится к организации данных внутри таблицы? Хоть википедию почитай, неуч https://en.wikipedia.org/wiki/Relation_(database) . Кликхаус нереляционная потому что в ней хранение данных организовано не так. Нет там отношений внутри таблицы.
А исходя из твоей дегенеративной логики excel это реляционная база. Таблицы есть, объединять их можно. Шах и мат ебать.
>OLTP
Технически и кассандра oltp. Тебе acid нужен или нет?
>Распределенную
Как распределенную? Хоть аналог приведи чтобы было понятно что тебе нужно.
>С авто-партиционированием из коробки
Насколько "авто"? Поставить на постгрес pg_partman это достаточно "из коробки"?
>и есть желание не хранить перемешанные данные, чтобы затем читать с диска лишние данные на запросы
Ебал её рука. Тут опечатка что-ли? Нихуя не понятно.
А самый главный вопрос: щас-то че стоит? Ты откуда мигрировать собрался?
cassanda, ch, vertica, amazon,databrick...Блять Коля, скажи чо надо то?
да отключи транзакции вливай bulk'ом и будет тебе счастье , долбоеб
тебя уже обоссали , а ты не уймешься, чучело
>на коленке за 10 минут делается
>ну сделай
>пук
>да отключи транзакции вливай bulk'ом
И упирайся в скорость записи на хард. Эта переписка с душевнобольным начинает утомлять.
Не снимая штанов.
Поясните за dblink в Postgres, там обязательно нужны superuser privilege? Можно как-то изолировать это, например дать права только на вью?
блять , ты реально не можешь кэш сервер накатать? Нахуй мне с тобой вообще говорить тогда
блять ты всегда будешь упираться в скорость записи на хард долбоеб. А если тебе не надо на хард, ну тогда извини, свет отрубят твоим данным пизда . Я еще раз говорю, NoSQl - это хуйня , по факту большинство классических SQL серверов все это умеют .
а ты хочешь , чтобы тебе еще и штаны приспустили и обоссали при этом?
>на коленке за 10 минут делается
>ну сделай
>не могу сам сделай
>блять ты всегда будешь упираться в скорость записи на хард долбоеб
На реляционной базе. Потому что ты еблан.
А умный человек поставит кассандру, которая мультимастер и в принципе стартует минимум с трех нод. И каждая нода будет писать на свой хард.
Какой же ты тупой опущ.
>а ты хочешь , чтобы тебе еще и штаны приспустили и пососали при этом?
Нет, тобой побрезгую. Трипак гарантирован.
долбоеб, ты видимо не слышал про linked сервера, сервера master-slave и прочие кластерные забавы. Этому говну уже лет так 15 как ! И все без твоей обоссандры работает, опущ!
Cassandra написана на Java, уябывай, долбоеб
>linked сервера, сервера master-slave и прочие кластерные забавы. Этому говну уже лет так 15 как ! И все без твоей обоссандры работает, опущ!
Ну ты бы хоть почитал про что пишешь, чучело. При чем тут вообще master-slave? Как он вообще скорость записи увеличивает? Мастер-мастер теоретически да, но все равно реплицироваться данные будут с одного мастера на другой.
А в кассандре данные хранятся на разных нодах и пишутся ВСЕГДА на разные ноды. И скорость записи там увеличивается ЛИНЕЙНО. В кассандру если есть железо, то можно 1кк записей в секунду хуярить. Не чтений блядь а ЗАПИСЕЙ.
Хватит писать рандомные слова, ты уже обосрался, а теперь говно себе по еблу размазываешь.
>Cassandra написана на Java, уябывай, долбоеб
Расскажи это ебланам из апаче и дегенератам из гугла, которые все свои хадупы, спарки и кафки на джаве пишут. Кончи тупые не понимают, что это зашквар.
Мы тут обсуждали использование постгреса в нашем проекте и наш сенька сказал что "лучше откоывать коннекшн ненадолго, записывать что нам нужно небольшим батчем и идти дальше, подолгу не удерживая соединение, как в принципе постгрес и подразумевал работу с коннекшнами" - я попытался найти что-то подобное в доках но нихрена, мне немного стремно подходить к нему и спрашивать "ты это че, выдумал?"
Это вообще дельная тема что он сказал или нет?
Я не эксперд ,но у постгреса нет менеджера конекшенов, этим внешие библиотеки занимаются. Вроде все они держат пул конекшенов и реюзают эти конекшены. Это связано с тем что постгрес на каждый конекшен ебашит отдельный процесс со со всеми кешами.
Постгрес - это такая ебанина что да, все так
ты тот самый сенька?
Вот этот анон прав . Все вопросы с коннекшенами закрывает PgBouncer.
По поводу
>записывать что нам нужно небольшим батчем
Я в свое время убил кучу часов на вычисление оптимального размера батча. Надо было раз в десять минут пидорить по 100к строк примерно, апсертом. Получилось что-то около 2к строк на транзакцию. Меньше и станет больше транзакций и все замедляется. Больше и транзакции дольше обрабатываются и все замедляется.
Ну и разумеется нужно убедиться что не вставляется в текстовое поле какая-нить "война и мир" чтобы в максимальный размер запроса влезать.

Сап, аноны. Не знаю, где спросить, но есть одна экселевская задачка. Туплю и не могу понять решение, реквестирую советов.
Пацаны, получил недавно ошибку:
<class 'asyncpg.exceptions.DiskFullError'>: could not extend file "base/16388/21415.2": No space left on device
Но ведь девопс говорил что там на кластере предостаточно места... втф? Где посмотреть общее потребление памяти диска постгрей?
<class 'asyncpg.exceptions.DiskFullError'>: could not extend file "base/16388/21415.2": No space left on device
Но ведь девопс говорил что там на кластере предостаточно места... втф? Где посмотреть общее потребление памяти диска постгрей?
VLOOKUP
ВПР
Вкатываюсь в функции постгри, вроде тема помогает неплохо так сократить дублирование. Функции у меня создаются на старте моего приложения через CREATE OR REPLACE
Я поменял сигнатуру одной функции, но на startapp эта хуйня упала с мессагами:
DETAIL: Row type defined by OUT parameters is different.
HINT: Use DROP FUNCTION km_prep_func(character varying) first.
Нипонял, почему это я должен делать еще и DROP? У меня ж там CREATE OR REPLACE, а значит должен происходить REPLACE, это БАЗА бля
Код покажи.
Так на вскидку ты дропаешь функцию возвращающую один тип, а создаешь возвращающую другой. Если тип меняется, то нельзя сделать REPLACE, а можно только DROP + CREATE.
вопрос платиновый как делать межсерверные запросы из одного newsql окна? в гугле нет, я работаю с удалённого рабочего стола, в mssql где уже подключаюсь к серверам
есть два основных сервера black и white на них по 15 баз, между ними импорты экспорты настроены автоматам, так вот иногда они ломаются, работают через жопу
70% работы пишу запросы в черном к 1 базе, но случается что надо из белого достать данные тоже из 1 базы, и сверить прост посмотреть есть или нет там
так вот как быстро переключатся менять их? потому что открыл newsql или свои, то что написал, пук пук, надо из 2 что то достать, и начинается, надо от одного откл, закрыть окно с запросом, подключится, снова открыть окно, выбрать базу и весь этот дроч естественно лагает данные идут по пизде потому что их там тысячи естественно я не запоминаю их. даже простой селект 1 строки из двух серверов занимает по 5 минут клацания одного и тогоже
межбазовые я нагуглил, пишешь use такая то база? или полное имя и тп, вьюшки там еще какие то похуй, вот это надо редко, а меж серверные как? никакие плагины и прочее установить нельзя? названия то я помню, адреса тоже и было бы заебись писать use черный сервер и селект там
а с новой строчки уже, use белый сервер и селект там
есть два основных сервера black и white на них по 15 баз, между ними импорты экспорты настроены автоматам, так вот иногда они ломаются, работают через жопу
70% работы пишу запросы в черном к 1 базе, но случается что надо из белого достать данные тоже из 1 базы, и сверить прост посмотреть есть или нет там
так вот как быстро переключатся менять их? потому что открыл newsql или свои, то что написал, пук пук, надо из 2 что то достать, и начинается, надо от одного откл, закрыть окно с запросом, подключится, снова открыть окно, выбрать базу и весь этот дроч естественно лагает данные идут по пизде потому что их там тысячи естественно я не запоминаю их. даже простой селект 1 строки из двух серверов занимает по 5 минут клацания одного и тогоже
межбазовые я нагуглил, пишешь use такая то база? или полное имя и тп, вьюшки там еще какие то похуй, вот это надо редко, а меж серверные как? никакие плагины и прочее установить нельзя? названия то я помню, адреса тоже и было бы заебись писать use черный сервер и селект там
а с новой строчки уже, use белый сервер и селект там
Господа, что происходит когда я на бекенде (питоновский asyncpg + sqlalchemy например) в рамках 1 открытой сессии пуляю асинхронно несколько select запросов к базе постгреса и запускаю их всех разом через asyncio.gather (аналог Promise.all из js)?
У меня реально параллельно они отрабатывают или один хер последовательно т.к. я использую 1 сессию?
У меня реально параллельно они отрабатывают или один хер последовательно т.к. я использую 1 сессию?
Мы вам перезвоним
Где вакуум вкатуну искать? В моей мухосрани 2 конторы и то с образованием нада.
Вакухи*
>межбазовые я нагуглил, пишешь use такая то база? или полное имя и тп, вьюшки там еще какие то похуй, вот это надо редко, а меж серверные как?
с курлом пробовал ебаться?
На ЖД станциях ищи цисцерны с жидким вакуумом
По какой причине рсубд на практике почти никогда не поднимают в контейнере / поде, а ставят для этого отдельный сервак? Каковы причины?
По причине того, что бд обычно админятся бумерами, а контейнеры придуманы зумерами
В РФ есть вакансии на разработчика баз данных? Мне как бекэндеру интересно, может перекатиться.
Не еби голову, моя прошлая спецуха физику и химию совмещала больше, чем ты думаешь.

Звучит как говенный инструмент. Нахуя окна закрывать? Нахуя соединения отключать? У меня в шторме datagrip от idea и ни одной из твоих проблем там нет. Можно подключаться хоть к десяти базам, открывать сколько надо консолей и даже есть пикрелейтед тулза чтобы сравнивать результаты.
выглядит как гигантский костыль, но почитаю подробнее
>в шторме datagrip от idea
есть только mssql без всяких плагинов и тп, idea не купят
>хоть к десяти базам
серверам. надо к двум хотябы, в идеале к 4. баз там по 15шт на каждом и с этим проблем нет
> По какой причине рсубд на практике почти никогда не поднимают в контейнере / поде, а ставят для этого отдельный сервак? Каковы причины?
А какой смысл поднимать базу в контейнере? Чтобы что? У тебя что, 2,000 баз данных и ты пытаешься размножить их по всей планете? Классические БД типа MySQL исторически плохо масштабируются по горизонтали. Несколько очевидных минусов - БД будет общаться с файловой системой через драйвер докера, что медленнее чем прямой доступ. Второй минус - это невозможность тонкого тюнинга. Откуда ты знаешь на какую конкретно машину задеплоиться база данных, сколько у неё памяти, сколько кеша ставить в конфиге? И третий минус, можно нечаянно дропнуть данные. Некоторые персонажи утверждают что контейнеры нужны чтобы "заморозить" зависимости. Типа, вот если ты создал проект семь лет назад на mysql версии 5.7.42, то ты должен на неё молиться всю свою жизнь. Или ещё некоторые пишут, чтобы развёртывать было проще. Под базы данных и так уже куча средств автоматизации, миграции, бекапов и всего прочего.
Опять же, есть специально адаптированные БД под контейнеры - vitess, cockroachdb, percona, cassandra, tidb, и прочие. Если тебе прям очень хочется, можешь поднять vitess/tidb и поиграться с ними.
Конечно есть, гугли pl/sql разработчик либо просто sql
>А какой смысл поднимать базу в контейнере
Приложение поднято в контейнере? Чек
Система кеша в виде Редиса поднята в контейнере? Чек
Очередь реббита поднята в контейнере? Чек
Нгинкс поднят в контейнере? Чек
Так с чего бы и РСУБД не поднять в контейнере?
Ну а причём здесь приложение, redis, nginx, и проч? Ты перечислил сейчас stateless-приложения. Они ничего не сохраняют на диск. Их как удалили, так и перезапустили. Ничего не потерялось. А базы данных stateful. Это самый критический компонент в системе. Если данные стереть, всей компании может быть пизда.
Тем более, nginx, redis - это микроскопические сервисы. Они занимают может быть 2-5 мегабайт оперативной памяти. На одном сервере может спокойно 200 контейнеров с нжинксом/редисом висеть. Сравнил ебать редис который потребляет 3 мб ОЗУ с БД.
Удачи тебе такое провернуть с базой данных. Она мало того что требует минимум 1 гигабайт оперативки (а лучше 2 гигабайт), так ещё желательно быстрый диск (NVM SSD соединённый в RAID-массив). Конечно если тебе на IOPS похуй, ты можешь обычный HDD поставить и в контейнере деплоить.
БД стейтлфул, но СУБД такое же стейтлесс приложение. Запускаешь СУБД в контейнере, ему указываешь volume для хранения данных на реальном диске, и никуда эти данные не денутся после рестарта контейнера.
Нууу? А volume где будет? У тебя 10 серверов. На каком сервере будет volume? Или ты используешь шаред фс а-ля NFS или NAS? Допустим, ты используешь NFS, тогда у тебя будет риск потери данных. И как ты будешь своей оркестрацией выбирать кто мастер а кто slave? Если ты два мастера выберешь, у тебя опять будет порча данных.
И все эти мучения ради чего? Ну то есть подведём итоги - ты мучался с volume, с оркестрацией, с тюнингом, чтобы что? Чем "контейнеризованная бд" лучше чем неконтейнеризованная?
У тебя единственный аргумент "все так делают".
Писал выше, существуют оптимизированные под докер базы, но MySQL/PostreSQL это не тот случай
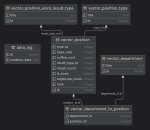
>idea не купят
Хуйня какая-то, это в рамках компании сумма микроскопическая. Я бы крепко задумался нахуя вообще работать на таких жопошников. Куда вообще можно вложить бабки более выгодно чем в разработку? Где твоя контора от этих жалких ста баксов больше прибыли получит?
>серверам.
Офк я имею ввиду именно сервера. Настраивай доступ хуярь свои запросы. Все будет кучеряво. Список недавних запросов, отдельные консоли для каждого источника данных. Дампы хуямпы в любом формате. Даже если ты консоль закрыл, то когда откроешь все запросы что там были сохранятся. Диаграммы сочные, с экспортом в разный формат.
>Нууу? А volume где будет? У тебя 10 серверов. На каком сервере будет volume?
На каждом офк.
>Или ты используешь шаред фс а-ля NFS или NAS? Допустим, ты используешь NFS, тогда у тебя будет риск потери данных.
Какие-то костыли, есть стандартные средства репликации.
>И как ты будешь своей оркестрацией выбирать кто мастер а кто slave? Если ты два мастера выберешь, у тебя опять будет порча данных.
Бля, а как ты выбираешь кто будет мастер на реальных серверах? Так же блядь как обычно и выбираешь.
>И все эти мучения ради чего? Ну то есть подведём итоги - ты мучался с volume, с оркестрацией, с тюнингом, чтобы что? Чем "контейнеризованная бд" лучше чем неконтейнеризованная?
Тем что это стандартный подход. Все работает в контейнерах и не надо ни для чего специально раздвигать булки.
Ты забываешь что если у тебя десять продакшен виртуалок, то у тебя еще пол сотни виртуалок тестовых, запасных, девелоперских итд. Клячить все это на голое железо нахуя? Работаешь в стандартном режиме и когда нужно стейдж для билда развернуть и когда новую реплику на проде поднимаешь и не ебешь мозги.
Зумеры не в курсе, что в постгресе можно создать несколько баз!
А в базе несколько схем! Ебать, вот это ломающие новости! Вот это круто.
Вот это все меняет (нет), пошел нахуй.
Суть разговора как раз в том, что в реальности идешь нахуй ты, потому что бд в большинстве случаев настраивают олдскульным способом без зумерских контейнеров
>микроскопическая
там иб ебет и логируется каждый пук потому что банки и бабки, и два что бы понимал какие жмоты, в программе для автотестов и ручного юзают триальный период и каждый месяц его сбрасывают, да да скоро свалим с него, но уже 2 год пошел
>Где
в банке. но с деньгами не обижают и во всем прекрасно
>пик
бля как же красиво, я и забыл уже про него, в 2019 игрался. надо попробовать тоже и может себе установлю
спасиб за идею
>бд в большинстве случаев настраивают олдскульным способом без зумерских контейнеров
Бля, ебанько. Вот тебе пример из "реальности". На каждую ветку с фичей или ветку релиза нужно поднять нужную версию базы с нужной схемой. Как ты собрался это делать "олдскульным способом"? Где ты физически это все будешь делать "олдскульным способом"?
А так у тебя есть готовая виртуалка, настроенная как надо, со списком команд, которые нужно выполнить, сама применяющая миграции, с нужной версией базы. Ты эту виртуалку и разрабу новому можешь дать, и развертывание стейджей автоматизировать и на прод её же деплоить. И самое главное ХРАНИТЬ ЕЁ СУКА В VCS. Чтобы удобно было её менять и отслеживать изменения.
при чем здесь вообще шаблонизация раскатки и контейнеры. тем более ты сказал что у тебя одна виртуалка - одна база в докере. ну можно также хоть salt'ом, хоть ансиблом намутить автоматизацию раскатки. вместо артефактов в виде образов у тебя из репы тянутся какие-нибудь rpm-пакеты с определенной версией и все. контейнеры ещё раз какую задачу решают? я лично (я не тот анон которому ты отвечал) как бы понимаю что это будет работать, но вот например какое-нибудь профилирование с контейнерами усложняется. а зачем тогда закладывать себе палки в колеса ещё при старте?
Мелкобуквенный хуесос, КУДА ТЫ БУДЕШЬ РАСКАТЫВАТЬ СВОЮ ХУЙНЮ? Куда блядь. Надо десять независимых инстансов, куда ты их раскатаешь, ебанько?
или нахуй чорт ёбаный.
я не он
всмысле куда. на 10 вм. а задача какая, 10 инстансов поднять на одной вм? я тебя не понимаю нихуя, ты же сам сказал выше, у тебя 10 вм, на каждой вм будет бд в докере со своим волюмом.
я предложил такой же вариант, только без докера.
И нахуй ты влез в разговор, ебанько, если даже не понимаешь о чем речь шла?
ладно, че ты...
Господа, как обычно работают с текстовыми null-полями?
Вот у меня есть колонка comment в таблице, она типа Text в постгрес, по дефолту что лучше ставить - null, либо сделать поле ненулабельным ставить по дефолту пустую строку - "" ?
Вот у меня есть колонка comment в таблице, она типа Text в постгрес, по дефолту что лучше ставить - null, либо сделать поле ненулабельным ставить по дефолту пустую строку - "" ?
Null это самое хуевое значение в базе. С ним по уебански работает сортировка и поиск. В идеале null'ов в базе вообще быть не должно.
Пустой текст по умолчанию "" это норм тема. Я видел как даже специальную пустую дату делали или пустой uuid. Лишь бы этих нулов ебучих небыло.
>В идеале null'ов в базе вообще быть не должно
Это где ты такую "мудрость" подчерпнул?
NULL полностью валидное значение и придумало было еще на заре РСУБД, наверно блять не просто так, да?
А кто говорит что оно не валидное? Без null так-то left join нельзя бы сделать было. Речь о том что ВНУТРИ таблицы Null очень сильно портит жизнь. Миллион статей на эту тему есть.
Банальный вопрос: при сортировке значения с Null будут где? В начале или в конце? Начинается пляска и тряска, кто-то забыл поставить NULLS FIRST и все пошло по пизде.
Или вот ты сравниваешь поля в рекурсивном запросе, а там Null нахуй. Что будет если норм поле с null сравнить? А если null с null? И кому спрашивается весь этот гемор нужен? Все время задним умом думать: а нет ли там null'ов, это ж надо запрос переписывать под них специально. При том что реальной необходимости держать null в таблице просто нет. Создаешь нормальное значение по умолчанию и пишешь обычные запросы без ебли.
>нормальное значение по умолчанию
Ну давай, ка же разрулишь вот эти ситуации с дефолтом:
- FK на соседнюю сущность. Этой сущности также может и не быть. Будешь дефолтную сущность для этого кейса создавать? Как стороннему юзеру об этом узнать?
- Закупочная цена не определена для данного айтема. Но знаешь ли "не определена" и "ноль" - разные вещи, а ты скорее всего предложишь нулями засрать ячейки? А может есть еще более гениальные идеи, типо ОТРИЦАТЕЛЬНУЮ цену туда ебануть? И как юзер сторонний это поймет?
- Номер телефона пользователя в таблице не указан, заменишь его пустой строкой? Вместо проверок на null теперь длину будешь проверять (ахуенно)?
>FK на соседнюю сущность. Этой сущности также может и не быть
Почитай что такое нормализация. Ты срешь избыточностью. Должна быть таблица связей с "соседней сущностью". Связь либо есть либо нет. Никаких null'ов тут не нужно.
>Закупочная цена не определена для данного айтема
То же самое. Есть таблица с ценами, цена в таблице либо есть, либо нет. Нулл нахуй не нужен.
>Номер телефона пользователя в таблице не указан, заменишь его пустой строкой? Вместо проверок на null теперь длину будешь проверять (ахуенно)?
Да какая нахуй разница как ты будешь че там проверять? Важно что пустая строка ведет себя как СТРОКА БЛЯДЬ.
Я не понимаю что ты пытаешься доказать. Ну нельзя везде заменить нулл на дефолтное значение. Ну и что с того? Кому от этого заебись стало? Я тебе объясняю что null это как дополнительный тип в нагрузку к заданному типу, который требует от тебя лишней ебли. С интеджерами поработал? А теперь изволь имаджинировать что там нуллы, которые не интеджеры нихуя, но с которыми надо поработать как с интеджерами. И поперли COALESCE IS NOT NULL NULLIF и прочая поебень.
Нуллы в sql это настолько старая и избитая тема что ну просто пиздец. Этот холивар старше самих реляционных баз. И спорили люди поумнее дебилов с двощей. Те деды самого кодда еще видали, и еще тогда говорили ему что он сука доиграется с нуллами своими блядь.
https://sigmodrecord.org/publications/sigmodRecord/0809/p23.grant.pdf
https://www.dcs.warwick.ac.uk/~hugh/TTM/Missing-info-without-nulls.pdf
>нормализация
Шиз, возвращайся в свою академ среду и не лезь к нормальным людям с реальными проблемами. Никто блять твою "6 нормальную форму" не делает в реальной БД
>Должна быть таблица связей
У тебя обыкновенный FK на другую запись, отдельная таблица тебе нахер не нужна если это не many-to-many
>Да какая нахуй разница как ты будешь че там проверять
Такая блять что это неинтуитивно и ты начинает изменять данные в угоду своим шизотеориям. Данные блять первичны. Их не надо менять потому что какой-то престарелый петух, не занимавшийся реальной разработкой лет 20, так решил, потом проблем не оберешься
>И спорили люди поумнее
Если у старого петуха есть PhD это еще не делает его "вумным" или пригодным для обсуждения реальных продуктовых проблем. Я не теоретик, я практик блять, мне бабки за это платят. Тьюринг разработал хорошую модель но он не прикладывал руки к конструкции и распайке ENIAC, потому что он в этом не шарил нихуя
>Шиз, возвращайся в свою академ среду и не лезь к нормальным людям с реальными проблемами. Никто блять твою "6 нормальную форму" не делает в реальной БД
Ебанько, ты даже первую не сделал. У тебя эксель ебаный от дурочки серетарши получился, а не реляционная база. Ты в натуре что-ли просто прочитал как таблички создавать?
>У тебя обыкновенный FK на другую запись, отдельная таблица тебе нахер не нужна если это не many-to-many
У тебя обыкновенная избыточность данных, потому что связей меньше, чем записей в таблице.
>Такая блять что это неинтуитивно
>Два типа в колонке вместо одного
>интуитивно
>один тип
>неинтуитивно
Ты тупой?
>Если у старого петуха есть PhD
Этот "петух", как ты выразился, придумал реляционные базы данных. Пиздец, Дейт это БАЗА, ОСНОВА блядь. Он блядь в шапке этого треда в рекомендованной литературе, чучело ты тупорылое.
Поддерживаю всё тобою вышесказанное.
После того как подключился к контейнеру с постгрей, какие операции там можно совершать? Внутри него даже psql не работает для коннекта с базой, что там вообще можно делать7 Где статы смотреть?
>какие операции там можно совершать?
Те же операции что и везде. Докер контейнер это виртуальная ОС. Какая ОС такие и команды.
>Внутри него даже psql не работает
Внутри кого? Что за контейнер, что в нем установлено? Как настроен постгрес?
Нет, это в корне неправильный подход. Докер-контейнер- это не виртуальная машина, это архив с бинарником и его зависимостями. Если у тебя туда что-то еще «установлено», значит ты делаешь все не так, жопой
Во первых. Я не спрашивал "что еще" там установлено. Я спросил что там установлено.
А во вторых. Текстовый редактор в твоем "правильном" контейнере установлен? Вот ебало то свое и завали.
Эти концептуальные правила касаются назначения контейнера, а не пересчета того что там в виртуальной системе установлено. У контейнера назначение быть базой данных, и способы доступа к этой базе и управления ею этого назначения не нарушают.
Нет, текстового редактора там не установлено, ты по прежнему делаешь все не так
То есть нет vi, vim или nano? Охуительные истории. Дай ссылку на свой контейнер в котором "так".
Ни в одном нормальном контейнере нет никаких редакторов, вообще никаких сторонних бинарников. Продакшен-контейнер - это контейнер FROM scratch.
Да, многие публичные контейнеры содержат редакторы и прочие базовые утилиты, чисто потому, что они основаны на базовых контейнерах из типовых дистрибутивов. Это исторически так сложилось (когда не было multi-stage builds) и это не значит, что они подразумевают редактирование чего-то внутри контейнера.
>Дай ссылку на свой контейнер в котором "так"
>пук
Слив засчитан.
Я написал тебе, в каком контейнере "так":
> FROM scratch
Но ты конечно можешь продолжать редактировать контейнеры, подключаясь к ним, как к виртуальной машине, долбоебом быть не запрещено.
>Дай ссылку на свой контейнер в котором "так"
>пук номер 2
>Докер контейнер это виртуальная ОС
Мгновенный ноухайр
тот кто пизданул про бинарник с зависимостяни не лучше
Не бомби так, дурачок, редактирующий контейнер
Детектор чини, еблан
Долбоёбы оба, идите нахуй отсюда со своим докером.
В постгре в таблице есть текстовое поле format_area_txt, там строка по типу "1200 кв.м." или "800 кв.м.", от клиента с фронта приходит запрос отсортировать данные по этой колонке, они сортируются по ORDER BY по как текстовые данные, а надо бы чтобы они сортировались как числовые... как это сделать? понимаю что выглядит как хуйня НО не я придумал делать колонку именно такую и не в моих силах сказать "давайте забьем хуй", бизнес просит именно так делать.
Преобразовать в запросе текст в число и делать order by уже по нему. План запроса пойдёт назуй, но бизнес получит желаемое.
https://stackoverflow.com/questions/8502505/order-varchar-string-as-numeric
То что тебе нужно называется natural sort.
В постгресе есть специальный способ задать правила сортировки: COLLATION.
https://www.postgresql.org/docs/10/collation.html
CREATE COLLATION numeric (provider = icu, locale = 'en@colNumeric=yes');
ALTER TABLE "your_table" ALTER COLUMN "format_area_txt" type TEXT COLLATE numeric;
После этого должно сортировать как числовое поле.
Зачет
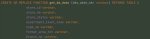
COLLATE действительно хорошо помог, стоило его навесить на таблицу НО возникла проблема что он не работает если данные вытащили из таблицы при помощи вьюхи/функции как на пикриле. Я подумал что раз моя функция возвращает TABLE то логично что на эту TABLE тоже можно повесит ькакие-либо constraint в том числе collate. Но как блэт? Эта table не именована by design, он ошибку кидает если пытаюсь ей имя дать, как на нее что-либо повесить?
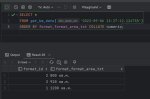
Какой же там у вас бардак просто пиздец, я хуею. dto_date_str, store_nm, type_sm какие-то блядь вьюхи, функции возвращающие таблицы, просто пизда.
Задание COLLATE при создании таблицы нужно просто чтобы по сто раз не писать.
COLLATE это просто способ сказать что с этим значением нужно работать по вот таким правилам. Ты можешь COLLATE прилепить в любой части запроса, как на пикрелейтед например. Можно задать правила сравнения строк как чисел в WHERE:
WHERE col1 COLLATE numeric > col2 COLLATE numeric
>Какой же там у вас бардак просто пиздец, я хуею. dto_date_str, store_nm, type_sm
А че такого? Нормалек же
>вьюхи, функции возвращающие таблицы
Это база в общем-то, тут ничего зазорного нет
>Ты можешь COLLATE прилепить в любой части запроса
Ow damn, тогда пошед эксперементировать, проблемы лишь в динаимке это делать, но это уже частности
>А че такого? Нормалек же
Комментариев к полям я так понимаю ноль. Классика жанра. Куча таблиц с полями названными в стиле "абырвалг" и логика приложения, зашитая в процедуры. Документация в больной голове этот шизобред написавшего. Это примерно как зашифровать все данные компании, а ключ выбросить. "Нормалек".
>Это база в общем-то, тут ничего зазорного нет
А какого хуя таблицы не соответствуют запрашиваемым данным? Нахуя строить виртуальную базу поверх настоящей? Зачем?

;
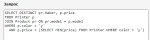
оно удаляет ;, да пофиг я переписал уже на пикрил. Кстати, он же кеширует здесь получение списка элементов таблиц?
1) Ты не показываешь с какой базой работаешь.
2) Mssql и oracle LIMIT не поддерживают, там нужно специальные конструкции писать для этого.
>Кстати, он же кеширует здесь получение списка элементов таблиц?
Ебал её рука. Что такое вообще "список элементов таблиц"?
Научись пользоваться CTE, так будут запросы гораздо понятнее получаться. По шагам будешь двигаться к заданной цели. Сравни насколько нихуя не понятно в твоем запросе и насколько все становится понятно в запросе пикрелейтед.
Посоны, в Redis делать ZADD/ZRANK для миллионов записей одновременно- это заведомо плохая идея или шансы есть?
> А во вторых. Текстовый редактор в твоем "правильном" контейнере установлен? Вот ебало то свое и завали.
Это не повод не использовать контейнер.
Ты всегда можешь доставить нужные тулы в контейнер.
Хотя это слегка портит воспроизводимость, но лишь только слегка.
От текстового редактора точно не поплохеет
Куда ты звонишь? Ты ошибся номером, друг.
У меня в мухосранске открылась вакансия без опыта связанная с бд. Посоветуйте какие курсы можно посмотреть и как подготовиться к собесу. Из бд знаю только селект фром тейбл и дроп тейбл.
вакуха на постгресе
вакуха на постгресе
Аноны, 1 месяц вкатывался в БД, второй месяц искал и таки нашёл работу. Буду сопровождать етл. Как же повезло, что вкатился минуя парашную тех.поддержку (которая по моему мнению нахуй не нужна в трудовой)
Пожелайте 25-летнему вкатышу-пердуну удачи. Встретимся на кофе-брейке с чизкейками, будем обсуждать тик ток и клаву коку.
Пожелайте 25-летнему вкатышу-пердуну удачи. Встретимся на кофе-брейке с чизкейками, будем обсуждать тик ток и клаву коку.
Брат, нахуй эти курсы, меня на лайв-кодинге даже похвалили, что самовкатчик. За курсы отдашь хуеву тьму денег, в то время как сам за пару месяцев управишься. Я не ебу какого уровня вакансия, но задумайся, что если на изучение скл ищешь курсы, то нужно ли вообще это твоё ойти?
Пидоран, свколько там рубль уэе?
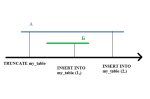
Задали недавно один ахуительный вопрос на собесе:
У тебя есть 2 транзакции в БД (постгрес). Транзакция А транкейтит таблицу и ждет, в этот период начинается транзакция Б, которая добавляет в эту таблицу новую строчку и завершается, после этого транзакция А продолжает работу и записывает свою 1 строчку в таблицу, завершаясь после этого. Какие именно данные мы увидим в таблице после прохождения этих 2х транзакций на каждом из уровней изоляции?
На самом деле нормальный вопрос нормальный в плане что на него реально ответить, просто сложный. Я бы завалил потому что не помню. Но на хабре была норм статья по уровням изоляции и там инсерты делиты рассматриваются тоже
На какую зепу вопрос был кст
320к
На бекенд а не на ДБА
Ну это вопрос не "просто сложный", а вопрос с подъебкой.
1) Уровни изоляции транзакций влияют на ЧТЕНИЕ из базы. Мы что-то прочитали и пытаемся с этими данными что-то сделать. Отсюда и пляшем. Кто что может читать, перечитать перед вставкой итд.
2) Локи это то что влияет на возможность делать определенные действия с базой. Например "читать", лол.
Если ты правильно описал заданный тебе вопрос, то это звучит примерно так: крокодил больше зеленый или длинный?
Рассказываю.
Действие TRUNCATE ставит самый ебейше жесткий лок на таблицу AccessExclusiveLock https://postgres-locks.husseinnasser.com/?pgcommand=TRUNCATE . Это означает что делать во время этой транзакции нельзя нихуя, даже читать. Любая транзакция начатая во время TRUNCATE будет сидеть и ждать доступа к таблице.
А как сюда относятся уровни изоляции? А никак нахуй, все сидят и ждут, никакой конкуренции нет.
А ну тем более тогда вот видите как приятно что на двач зашёл что-то новое узнал для себя
>husseinnasser.com
У него канал на ютубе кстати крутой про бекенд-штуки
Пацаны рассказывали что если нужно загрузить много (10-100 миллионов строчек в таблицу) строк из одного источника в другой (РСУБД и там и там) то не зашкварно это делать промежуточно через csv - select-им данным из базы A, сохраняем в csv на диск, чанками из csv insert-им в базу B. Это норм? Как вообще обычно такие проблемы решают?
Фкшки должно быть залупно переносить, если таблиц много, не? Я теоретизирую интересно мнение опытных коллег тоже
Варианты переноса по степени хуевости:
1) Самый лучший вариант использовать mysqldump или pg_dump. Если базы разные, то есть конверторы дампов.
2) SQL скрипт с инсертами. IDE от IntelliJ и их datagrip, например, такие дампы делать могут.
3) Не SQL формат. XML, JSON, YML.
4) Моча.
5) Говно.
6) CSV.
CSV самый хуевый вариант, потому что формат самый не строгий. На больших объемах гарантированно будут косяки. Лишние точки с запятой, переносы строк, потерянные кавычки и прочая дрисня. Все, что имеет хоть какие-то правила и структуру, будет лучше. SQL скрипт полностью сохраняет исходную структуру, типы итд. А дамп сохраняет полную структуру таблицы, секвенции, индексы и триггеры, самый надежный, так еще и самый быстрый вариант.
>pg_dump
>mysqldump
А если я переносу из мускла в постгрес или наоборот? То есть сурс и таргет не совпадают?

>Если базы разные, то есть конверторы дампов.
>Как вообще обычно такие проблемы решают
spark
Сап двач, есть способ заабъюзить sql-ex? Решил сам 65 задач, на 66 затупил и пошел погуглил ответ. В итоге забанили, вторые акки банят на раз-два. ТП говорит мол сам виноват долбоёб. А сертификат хочется, сталкивался кто-нибудь?
аче всмысле
они типа новые вкладки в браузере отслеживают?
Даже не вкладки, а в другом браузере делал, с другими почтами. Судя по всему видят по апишнику и устройству

Анон, подскажи. В моей системе хочется сделать слив изображений на сервак. Почитал, понял, что базу с данными лучше делать отдельно (Postgres), а в ней хранится ссылка на картинку/бинарник. Блоб хуйня.
И как-то не могу нагуглить типовой нормальный инструмент, чтобы хоть какое-то сжатие было, эффективно использовался сервер, мб. хранение было с диффами. Как всякие сайтики пикчи хранят? Алсо, у меня Astra Linux, там новый перспективный двухнедельный фреймворк не поставишь.
Прикладного опыта в БД мало, но я теорию знаю + с чатжпт общаюсь, он в sql хорош
И как-то не могу нагуглить типовой нормальный инструмент, чтобы хоть какое-то сжатие было, эффективно использовался сервер, мб. хранение было с диффами. Как всякие сайтики пикчи хранят? Алсо, у меня Astra Linux, там новый перспективный двухнедельный фреймворк не поставишь.
Прикладного опыта в БД мало, но я теорию знаю + с чатжпт общаюсь, он в sql хорош
Файлы хранятся в облачном бакете, в бд лежит путь к файлу в бакете, бакет с остальным клиентским кодом работает через адаптер
>Блоб хуйня
Дело не конкретно в типе данных, просто из-за внутреннего устройства постгреса невозможно хранить файлы очень большого размера "как есть", он использует под капотом указатель в какое-то очко и там что-то я не помню что. Гугли TOAST если интересно
>базу с данными
>я теорию знаю
>с чатжпт общаюсь, он в sql хорош
Я хз смеяться или плакать.
>И как-то не могу нагуглить типовой нормальный инструмент, чтобы хоть какое-то сжатие было
gzip
>Алсо, у меня Astra Linux
Ты же сам мне позвонил. Все пока.
Записываю разом много строчек в таблицу постгри. Перед записью дропаю индексы и после - снова их создаю чтоб запись резче была. Это норм тема? Или хуйню делаю?
>погуглю
Бумер, плез. Гугл это прошлый век, сейчас все ГПТ-ИИ юзают

Пукнул в воду. Я для сдачи не своих лаб по mysql вечер посидел с чатжп, вполне эффективно.
Гзип не решит проблему фрагментации, когда много маленьких файлов лежит. Хорошо самому доводить объем данных до например мегабайта и уже потом сжимать.
Да, я понимаю, что блоб то работает, но он немного не для того. И мне не нравится, что 90% массы базы будет состоять из пикч, которые толком не обязательны.
Не, система закрытая, без всяких облаков. Да и вопрос мой связан с внутренней архитектурой этих облаков.
Я не верю, что какой-нибудь Яндекс или гугл картинки держат тупо файлопомойкой на дисках. Можно искать схожие данные, особенно две одинаковых пикчи с разным сжатием (из сравнить легко по спектру), чтобы хранить только одну из них. Все ради экономии памяти.
Баз данных много, даже чересчур, а опенсорс инструментов по хранению тех же изображений как-то не очень
>вечер посидел
Звучит авторитетно, заваливаю ебало.
>Можно искать схожие данные, особенно две одинаковых пикчи с разным сжатием
Можно. А когда запрос на картинку пришел че делать? Разжать надо получается. А где? На своем проце или в браузере? Поэтому так ебутся со всякими форматами пикч webp, heif. Чтобы блядь расшифровкой занимался пользователь.
Архиватор делает все что тебе надо, хитрожеппо сжимает шакалов по умным алгоритмам. Так хули нет-то? Да потому что нужна ДОСТУПНОСТЬ. А железо для хранения уже лет десять как нихуя не стоит.
Винт на терабайт стоит дешевле, чем твое время потраченное на гуглинг несуществующей хуйни.
Буквально. Там выше писали про вакансию на 320к. Зп как раз под уровень подобной задачи в условном хуяндексе. 2к в час. Два часа = винт на терабайт. Сколько надо в хуяндексе народу на создания такого алгоритма/сервиса? Пол года и команда? Сколько железа можно на эти бабки купить? И на рэйды хватит с бекапами и на благотворительность останется.
> Баз данных много, даже чересчур, а опенсорс инструментов по хранению тех же изображений как-то не очень
Ты не понимаешь, что у крупных сервисов через одного такие инструменты. Это вовсе не уникальная задача, можно в интернете разные описания найти.
Если у тебя один запрос в час, то вообще нет смысла выбирать. Более очевидные факторы учитывай, вроде того, есть ли у клиентов доступ к системе мимо единственного соединения с базой данных, и того, как авторизация всего этого хозяйства должна быть устроена. Если запросов достаточно много, предполагается, что ты знаешь, какие циферки способен выдать тот или иной вариант сервера при правильной настройке, есть ли пики использования, узкие места в сети. Если объём данных таков, что стоимость инфраструктуры становится ограничивающим фактором, надо думать об удобстве масштабирования и взаимодействия с CDN, которые управляются не тобой.
Нужна реляционная помоечная ДБ без консистентности, куда я буду срать терабайтами неизменяемых данных.
Что взять?
Что взять?
Кликхаус мб
Вообще в целом тебе нужна OLAP базёнка
Основная нагрузка - поисковая с кучей строк, не агрегации + желательно быстро писать
Ch по обоим критериям не подходит
Эластиксеч тогда мб
>желательно быстро писать
Сри значит в Кафку или Эластик
Возможно все-таки тебе нужна колоночная база типо Кликхауза, так и не понял что у тебя за данные и как ты по ним будешь искать
>Нужна реляционная помоечная ДБ без консистентности
Тебе не нужна реляционная дб.
>куда я буду срать терабайтами неизменяемых данных
Ты не будешь туда срать терабайтами данных.
>Основная нагрузка - поисковая с кучей строк, не агрегации + желательно быстро писать
Все тебе правильно написали. Любая олап хуйня от кликхауса, до эластика.
>Ch по обоим критериям не подходит
По обоим критериям подходит.
Сап. Какой самый простой способ настроить типа репликацию в оракле 19, если ты нюфаг? Раньше юзали 11 версию, там был параметр standby_archive, но в 19 он стал депрекейтед и нихуя не работает.
Оракл стримс это про это? Не обязательно прям на лету синкать базы, достаточно раз в несколько минут каким нибудь скриптом по архивным файлам или типа того... Хуй что нагуглишь блять по этому ораклу
Оракл стримс это про это? Не обязательно прям на лету синкать базы, достаточно раз в несколько минут каким нибудь скриптом по архивным файлам или типа того... Хуй что нагуглишь блять по этому ораклу
Вопрос на миллион:
У меня в Постгресе в таблице существует индекс уникальности по колонке client_ident. Помогает ли этот индекс в поиске когда ищу по этому полю или же когда джойню с другими таблицами по client_ident? Или он просто для уникальности и никакого повышения производительности не дает?
У меня в Постгресе в таблице существует индекс уникальности по колонке client_ident. Помогает ли этот индекс в поиске когда ищу по этому полю или же когда джойню с другими таблицами по client_ident? Или он просто для уникальности и никакого повышения производительности не дает?
Я нагулил твой вопрос и первой ссылкой в выдаче был стековерфлоу с ответом
Хлопцы, дивіться, яку річ зробив:
Кароч, у нас есть набор данных который возвращает некая вьюха в постгре gather_view, там джойны и вся херня, довольно тяжелый запрос на самом деле который около 600 мс исполняется. Мне надо по каждому из колонок этой вьюхи (их около 10 штук) сделать distinct и вернуть эти значения на фронт. Короче значения для фильтра. Собственно я чтобы всех переиграть перед запросами distinct рефрешу заранее созданный materialized view:
CREATE MATERIALIZED VIEW mat_gather_view AS SELECT * FROM gather_view
REFRESH MATERIALIZED VIEW mat_gather_view
И кидаю distinct запросы в него
Нормас? Или какая-то херня?
Кароч, у нас есть набор данных который возвращает некая вьюха в постгре gather_view, там джойны и вся херня, довольно тяжелый запрос на самом деле который около 600 мс исполняется. Мне надо по каждому из колонок этой вьюхи (их около 10 штук) сделать distinct и вернуть эти значения на фронт. Короче значения для фильтра. Собственно я чтобы всех переиграть перед запросами distinct рефрешу заранее созданный materialized view:
CREATE MATERIALIZED VIEW mat_gather_view AS SELECT * FROM gather_view
REFRESH MATERIALIZED VIEW mat_gather_view
И кидаю distinct запросы в него
Нормас? Или какая-то херня?
>Мне надо по каждому из колонок этой вьюхи (их около 10 штук) сделать distinct
А нахуя туда кладутся дублирующие записи? Тут определенно кто-то занимается хуйней.
>Собственно я чтобы всех переиграть перед запросами distinct рефрешу заранее созданный materialized view
"Лучше день потерять, потом за пять минут долететь"
Тебе зачем вьюха вообще нужна? Если чтобы было быстро, то ты все равно по сути выполняешь каждый раз её создание с нуля. Плюс с верху время на запросы к вьюхе. Сам себя наебал получается.
Короче. Судя по рассказу происходит какая-то хуйня. Непонятно зачем вьюха вообще. Непонятно почему она именно такая. Если хочешь реальной помощи, то показывай запрос. На создание, на выборку.
Может реально проще отдистинктить запрос сам (т.е. нематериализованную вьюху)
>А нахуя туда кладутся дублирующие записи
Чаво?
У меня таблица (view но сути это не меняет) с данными. Нужен distinct по каждой колонке чтобы эти данные передать на фронт, потому что как юзеру иначе узнать, по какому параметру он может фильтроваться а по какому нет?
>Непонятно зачем вьюха вообще
Потому что у меня есть 2 запроса которые по сути используют эту же вьюху и также запрос на фильтры с distinct про который говорил выше. Мне на каждый такой запрос заново с нуля всю эту хрень писать? Чтоб потом что-то где-то забылось и данные не консистентными на фронт пришли? Или может все-таки лучше заранее создать сурс с данными который будет переиспользоваться?
>Чаво?
Кто засунул в твою view такие данные, что по ним нужно делать distinct? И, главное, зачем?
>Мне на каждый такой запрос заново с нуля всю эту хрень писать?
Телепатов тут нет. Показывай запрос.
>Кто засунул в твою view такие данные, что по ним нужно делать distinct
Блэт, еще раз объясняю: фронтэнд получает некую таблицу - массив строчек. По каждой колонке из этой таблицы он должен иметь возможность фильтроваться - выбирает галочки напротив значений которые нужно включить в запрос. Как же это сделать? Очевидно что в другом запросе фронт должен получить значения для фильтров в каждой колонке. Как это сделать на бекенде?.. Думаю ответ напрашивается сам собой
Пчел. Ты ходишь по кругу. Это ведь ты формируешь содержимое вьюхи. Зачем ты сформировал его так, что тебе нужно делать distinct? Это значит что во вьюхе есть дубли и избыточные данные. Зачем самому себе генерить из воздуха избыточные данные?
sup g
посоветуйте для новичков че-нибудь по sql на русском почитать или посмотреть, основы так скзть
посоветуйте для новичков че-нибудь по sql на русском почитать или посмотреть, основы так скзть
Любой первый попвшийся туториад, который гуглится типа "SQL основы".

Крик помощи.
Как зарегаться на сайте оркала на Хуйлостане Пынебабве?
Как зарегаться на сайте оркала на Хуйлостане Пынебабве?
Через VPN.
Пытался через ТОР не получается.
>>2853356
Пошёл нахуй, порашный опущенец-недочеловек. Ты тупой, никчёмный неудачник. Зарепортил.
Пошёл нахуй, порашный опущенец-недочеловек. Ты тупой, никчёмный неудачник. Зарепортил.
Вот это огонь
А чо там было? Опять солевой деняк просит?
Зачем? Оракл юзают 50iq мальчики. Тебе то он зачем?
Guyz, идет обычный запрос на UPDATE в постгре в конкретной таблице, апдейтиться каждый аз будет разное произвольное число строк (из-за условия WHERE), в результате этой операции надо узнать сколько строк было заафекчино и соответственно изменилось. Как это с помощью sql сделать?
Есть очевидный подход где я сначала делаю SELECT и посчитаю сколько там таких строк лежит, затем уже UPDATE. Но эт какая-то хуйня
Почему хуйня? Если делать SELECT FOR UPDATE, вообще фича.
Надо в postgres создать пользака который может только select-ить данные откуда угодно и фсе. То есть никаких DDL операций и даже никаких update/insert/delete. Как это реализовать?
GRANT
RETURNING
Вернет например айдишники всех заафекченных строк, но не РЕАЛЬНО обновленных строк. Это разные вещи
>сколько строк было заафекчино и соответственно изменилось
>айдишники всех заафекченных строк, но не РЕАЛЬНО обновленных строк
Ты еблан?
Ну ней бей, насяльника
шо вы, головы?
Large Objects совершенно точно не для для этого.
Постгрес понятия не имеет что это просто картинка, и делает с данными кучу картинкам нахуй не нужной хуйни. А тебе потом еще и полученные из базы данные обратно в файл перегонять.
Хранить изображения просто в папке на диске гораздо менее затратно, чем таким макаром в базе.

Есть одна задачка, не могу догнать решение, реквестирую помощи.
Сгруппируй по дате, посчитай по кол-ву названий и условие поставь больше 5
А, бля, там ещё легче. Пиздуй перечитывать теорию тогда.
Да я уже решил, лол, но и на том спасибо.
Приветствую уважаемые аноны!
Подскажите пожалуйста, хочу поднять сервак БД в дибью через постгрис, смог сделать локальную бд, но хочу пойти дальше и сделать общедоступным, подскажите куда топать и что почитать, т.к. инфы особо нарыть не смог, либо смог, но объяснение старенькое и половины инструментов тупо нет
Заранее спасибо за ответы!
Подскажите пожалуйста, хочу поднять сервак БД в дибью через постгрис, смог сделать локальную бд, но хочу пойти дальше и сделать общедоступным, подскажите куда топать и что почитать, т.к. инфы особо нарыть не смог, либо смог, но объяснение старенькое и половины инструментов тупо нет
Заранее спасибо за ответы!
1) Ты можешь купить сервак и купить у своего провайдера белый статический ip-адрес, чтобы можно было к твоему домашнему компуперу хоть из сети
2) Ты можешь купить хостинг
Второй вариант очевидно лучше. Потом разматываешь там свою БД
Попробую пойти по первому варианту, позже отпишусь об успехах
спасибо
капчаневалидна


Почему не пашет? Всё же правильно делаю, по синтаксису, нужный столбец title обозначен как VARCHAR с максимум 255.
Возможно названия полей не нужно заключать в кавычки
Пробовал, всё равно ту же ошибку выдаёт. Использую OpenServer, норм софт? Емнип, кавычки не играют в sql критической роли, как в других ЯП.

1 секунда в гугле и уже видно что у тебя синтаксис кальный

Что так, что сяк не пашет, я не троль, просто удача не на моей стороне. С начала пытался как все белые люди через докер и pgAdmin делать БД, но она банально не заводиться, чтобы ты не писал в config.env и как бы не настраивал контейнер.
https://stackoverflow.com/questions/1992314/what-is-the-difference-between-single-and-double-quotes-in-sql
Читай всё, затем читай документацию конкретно к своей БД.
Надеюсь, база у тебя создана и доступ пользователя есть.
А дк внатуре. ` это ", а должно быть '
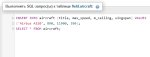
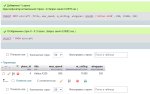
Благодарю за ваши ответы. Мне это помогло.
И ещё, вот эти `ковычки` пишет сама система, поэтому я думал, что правильнее использовать их, а вот оно как на самом деле оказалось.
Кажется, проблема в том, что ты начал с интерфейса со свистелками и перделками, в который ты вбиваешь магические слова, не понимая, что они значат, что должно происходить, и что не так.
Возьми локально запусти и в голой консоли голым текстом вбивай запросики, смотри, что происходит, если ты в чём-то ошибаешься, и так далее.
Пагни, не могу найти ответ - можно ли делать в Транзакт SQL Alter table с переменными без использования динамики?
Задача проста - пишу скрипт типа
Declare @NewC Varchar='QWERTY';
ALTER TABLE [test]
ADD
@NewC VARCHAR(255);
Естественно выдает ошибку.
Гугление нихера не выдаёт.
Задача проста - пишу скрипт типа
Declare @NewC Varchar='QWERTY';
ALTER TABLE [test]
ADD
@NewC VARCHAR(255);
Естественно выдает ошибку.
Гугление нихера не выдаёт.
Ты можешь внятно изъясняться?
Что такое "Транзакт"? Что значит "с переменными без использования динамики"?
Чем тебе не нравится стандартный подход с выполнением строки? https://dbfiddle.uk/SlCM4724
Протыки микрософтовские так свой вариант процедурного серверного sql в MS SQL Server так называют.
Пацаны.
Есть запрос примерно такого вида
insert into table1(
num1,
num2,
secret_num3.
name,
typeId
)
values(
(SELECT min(t1.num1) FROM (((SELECT num1 from table1) union (SELECT 1 as num1)) as t1 JOIN table1 as t2 on t2.num1 = t1.num1 + 1 WHERE t2.num1 = null and t1.num1 > 2),
(SELECT min(t1.num2) FROM (((SELECT num2 from table1) union (SELECT 256 as num2)) as t1 JOIN table1 as t2 on t2.num2 = t1.num2 + 1 WHERE t2.num2 = null and t1.num2 > 257),
(SELECT min(t1.secret_num3) FROM (((SELECT secret_num3 from table1) union (SELECT 1024 as secret_num3)) as t1 JOIN table1 as t2 on t2.secret_num3= t1.secret_num3+1 WHER t1.secret_num3 > 1025),
'Ivan',
(SELECT id from types where name = "Admin" LIMIT 1)
)
Так вот. С ним есть пара проблем.
1. Он выполняется медленно. Даже на не самой большой базе. Всего 100к записей - уже секунду выполняется.
2. Я не представляю как его можно распаралелить, чтобы можно было сразу из нескольких потоков эту бяку делать.
Как ускорить вот это вот, если индексы уже есть и судя по плану - в них вроде как БД лезет.
Есть запрос примерно такого вида
insert into table1(
num1,
num2,
secret_num3.
name,
typeId
)
values(
(SELECT min(t1.num1) FROM (((SELECT num1 from table1) union (SELECT 1 as num1)) as t1 JOIN table1 as t2 on t2.num1 = t1.num1 + 1 WHERE t2.num1 = null and t1.num1 > 2),
(SELECT min(t1.num2) FROM (((SELECT num2 from table1) union (SELECT 256 as num2)) as t1 JOIN table1 as t2 on t2.num2 = t1.num2 + 1 WHERE t2.num2 = null and t1.num2 > 257),
(SELECT min(t1.secret_num3) FROM (((SELECT secret_num3 from table1) union (SELECT 1024 as secret_num3)) as t1 JOIN table1 as t2 on t2.secret_num3= t1.secret_num3+1 WHER t1.secret_num3 > 1025),
'Ivan',
(SELECT id from types where name = "Admin" LIMIT 1)
)
Так вот. С ним есть пара проблем.
1. Он выполняется медленно. Даже на не самой большой базе. Всего 100к записей - уже секунду выполняется.
2. Я не представляю как его можно распаралелить, чтобы можно было сразу из нескольких потоков эту бяку делать.
Как ускорить вот это вот, если индексы уже есть и судя по плану - в них вроде как БД лезет.

В чём смысл юнионить хуйню с t2.num2=256, если ты потом делаешь WHERE t2.num2 = null? У тебя эти 256 сбреются
Я хуйню написал там алаяс на t1. Но он сбреется тоже так как WHERE > 257. Короче как будто хуйню там реально написал видно же. Подробностей не будет я пивка ёбнул лень думать
Ещё ты должен знать что индексы тебе тут не помогут. Индексы наоборот ЗАМЕДЛЯЮТ инсерты
Короче. Судя по тому что я увидел все юнионы из вложенных таблиц которые ты собираешь надо тупо удалить. Они ни для чего. Это во-первых
Во-вторых самое медленное в данном запросе это абсолютно точно JOIN. Ты джойнишь таблицу саму на себя по +1. Я бы на твоём месте заюзал LAG() если или аналог для твоего языка. В целом видно что запрос какой-то ебанутый но реально мне очень лень думать сейчас
В-третьих оптимизатор явно сам разобрался но тебе всё-таки лучше вынести хуйню которая LIMIT 1 в конце в WITH
WHERE t2.num = null тоже долбоёбизм кстати. У тебя там INNER JOIN, значит уже не может быть t2.num = null никак, это лишнее. И вообще я думаю ты меня сейчас затралил этим запросом потому что я щя посижу и ещё найду до чего доебаться
Бля, какая же дрисня. Это мускуль что-ли? Пиздец без CTE живется хуево.
>on t2.num1 = t1.num1 + 1
>WHERE t2.num1 = null
t2.num1 равно null только если t1.num1 равно null, потому что только null + 1 равно null. Нахуя для такого результат вообще джойнить вопрос риторический.
Признавайся, ты ебалом по клавиатуре катался, а потом притащил эту дрисню сюда?
в mysql есть CTE.
читать чужие запросы я, конечно, не буду.
Это в восьмой версии. Только её никто не использует. Предпочитают старый, проверенный кал.
пошол вон изучать что там в dockerhub под меткой latest
1. Смысл юниона в том, что таблица может быть изначально пустая, а делать отдельный запрос для случая если таблица пустая - не хочется.
2. Джоин на самого себя + 1 - нужен чтобы найти пропуск.
Т.е. вот имеем записи
(1,256, 1024, "Petya", 2)
(3,258, 1026, "Kolya", 2)
А этой вот ебаниной - должны получить
(2, 257, 1025, "Ivan", 1)
Тут уже я проебался. Там лефт джоин должен быть.
Я по памяти восстановил запрос который вызывает у меня попоболь своей медленностью.
>Я по памяти восстановил запрос который вызывает у меня попоболь своей медленностью
Ладно. Предположим что CTE у тебя нет, запроса у тебя нет, ты еблан и нихуя не понимаешь что происходит.
1) Мудень, почитай в чем разница между UNION и UNION ALL. UNION сканирует и сортирует всю таблицу, потому что ищет дубли с добавляемыми строками.
2) LEFT JOIN делает x2 к размеру твоей таблицы в памяти. Было 100к, стало 200к.
3) Вся вышеперечисленная херня происходит НЕСКОЛЬКО РАЗ.
Что можно сделать.
0) Переписать эту дрисню на нормальный SQL. С CTE и оконными функциями. Сейчас не дветыщиседьмой.
1) Избавиться от LEFT JOIN. Там у тебя конкретная ебанина написана. Как эффективно искать пропуски гуглится за три секунды.
2) Объединить все группировки в один подзапрос. А там группировки ага. Если написал только аггрегирующую функцию, но не написал GROUP BY группировка все равно есть.
3) Написать процедуру, которая будет работать не со всей таблицей, а с небольшой пачкой. И дергать её сколько надо раз.
А есть у кого под рукой видео или статья, где по простому объясняется, как работать с джоинами? Нихуя не понимаю из тех материалов , что в топе гугла
Ты параллельно пока материалы смотришь сам потыкайся. С практикой сильно понятнее

>Нихуя не понимаю
На завод не предлагаю, там надо понимать.
Пиздуй лук в пятерочке раскладывать.
В 98% случаев юзаются только inner join (он же просто join) и left join. Тыкай в первую очередь их.
Подскажите как найти работу чтобы писать и оптимизировать хранимки всякие.
Есть 3 года опыта на MSSQL с хранимками ебанутыми, понимание блокировок, уровней изоляции транзакций, реляционного исчисления, умею оптимизировать всякую хуйню вроде неплохо, но можно было бы получше подготовиться.
1) Как называется эта профессия?
2) К чему готовиться на собесах?
Есть 3 года опыта на MSSQL с хранимками ебанутыми, понимание блокировок, уровней изоляции транзакций, реляционного исчисления, умею оптимизировать всякую хуйню вроде неплохо, но можно было бы получше подготовиться.
1) Как называется эта профессия?
2) К чему готовиться на собесах?

Лучше писать как на пикриле, будет понятнее что происходит и меньше ошибок, плюс можно легко комментировать строки или подцепить вниз ещё одну запись через UNION ALL.
> На завод не предлагаю
Я с завода только....
Сап, двачик, помоги советом, пытаюсь ли натянуть сову на глобус или нужно продолжать копать?
Есть таблица, в ней id записи, название сервиса и время создания записи
Нужно делить записи на утро и вечер, группировать по названию сервиса и возвращать на фронт
Подскажи, как делить на утро и вечер?
Есть таблица, в ней id записи, название сервиса и время создания записи
Нужно делить записи на утро и вечер, группировать по названию сервиса и возвращать на фронт
Подскажи, как делить на утро и вечер?
Во многих СУБД есть функции для работы с датами и временем и условные выражения через CASE WHEN. В зависимости от того, что конкретно тебе нужно, можешь написать выражение с проверкой вхождения времени в диапазоны, принимаемые за утро или вечер.
Кейсом?
>Нужно делить записи на утро и вечер
Тут важный что ты имеешь ввиду под "делить".
1) Если нужно просто обозначить какая запись утро, а какая вечер, то какого хуя это должно делаться в SQl вообще? Они там на фронте сами не могут решить какое время утро, а какое нет? Зачем для этого логику в базу тащить?
2) Если нужно группировать записи на основе времени дня, то самый лучший вариант вычислять какое время дня при создании записи и хранить в отдельной колонке. Тут действует правило: не обрабатывай выборки на основе вычисляемых прямо сейчас значений, они будут попадать мимо индексов и жрать ресурсы.
О том как это непосредственно сделать пацаны все объяснили получаешь из таймстампа часы extract(hour from field) и потом с помощью CASE WHEN решаешь что этот час означает. Но повторюсь, это логика приложения в базе. С какого хуя хранилище данных должно вообще знать который час утро, а какой не утро? В него либо приходит время сразу с указанием что это утро, либо выходит время, а утро ли это вы уже сами интерпретируйте.
Спасибо!! Все-таки сову на глобус натягиваю
Но внезапно селект вхере тайм офдэй = утро таки будет быстрее чем селект с вытаскиванием и сравнением часа (сохраняться таймофдэй естественно должен приложением при инсерте)
Здравствуй, двач, мне задали курсач: сделать сайт, прикрутить БД и донаты. Подскажите, пожалуйста, чем лучше воспользоваться, какую БД выбрать, какой хостинг, можно ли опубликовать тупо в gitHub? Какие гайды стоит посмотреть?
Всем ответившим спасибо.
Всем ответившим спасибо.
> какую БД выбрать
Для курсача без разницы, хоть Sqlite бери. Дефолтное решение - постгрес.
> какой хостинг
Локалхост.
> можно ли опубликовать тупо в gitHub
Нет, там только статика
> Какие гайды стоит посмотреть
Любой, который тебе будет понятен.
Спасибо, анон, попробую так сделать
>Курсач
>Какие гайды стоит посмотреть?
Бля, а в шараге в которую этот курсач надо сдать, совсем с гайдами тухло? Я слышал есть такие "гайды" парами называются, это в 2к23 не модно уже?
Это никогда не было модно, сычуш, вспомни, ты же один ходил на эти гайды и потом курсачи всем делал
Я еще помню, там на парах всегда сидит такой невзрачный хуй. Это тот самый хуй, который потом будет оценивать твой курсач.
Так вот, если немного пробздется от солей, пивандепалы, дотки или чего ты там вместо пар употребляешь. То можно догадаться что этот, на первый взгляд совершенно бесполезный хуеплет, гораздо лучше каких-то рандомов с двачей знает как должен быть сделан курсач, где он должен хоститься, что и как кнему должно быть прикручено и какая бд должна там использоваться.
Пиздец просто, ты бы блядь еще пришел сюда спрашивать какая у твоего курсача тема.
Во, у сычуши флешбеки пошли, вспомнил значит и не будет больше нести хуйню про моду
Тут такое дело, я вообще бэкенд осваиваю и столкнулся с проблемой:
-- Установил PostgreSQL последний стабильный
-- Установил pgAdmin последний
-- В pgAdmin создал сервер, подключаюсь к нему, приложение с ним взаимодействует, всё хорошо
-- Мне нужно создать ещё один сервер на другом порту, создаю, при попытке к нему подключиться - connection timeout expired
В чём дело может быть? Всё работает на localhost, свободные порты проверял, в конфиге аж две переменные port сделал, не работает
-- Установил PostgreSQL последний стабильный
-- Установил pgAdmin последний
-- В pgAdmin создал сервер, подключаюсь к нему, приложение с ним взаимодействует, всё хорошо
-- Мне нужно создать ещё один сервер на другом порту, создаю, при попытке к нему подключиться - connection timeout expired
В чём дело может быть? Всё работает на localhost, свободные порты проверял, в конфиге аж две переменные port сделал, не работает
Ты просто запутался в терминах.
1) Сервер с базой = пк на котором установлен и запущен постгрес. Собственно ты это сделал со своим пк. Поэтому ты можешь обратиться к своему постгрес серверу через localhost.
2) В пгадмине создаются не "сервера", а "подключения к серверам". Так что когда ты выбираешь "create server" ты на самом деле просто пытаешься подключиться к какому-то уже существующему серверу используя вбитые данные. Очевидно, что если ты новый сервер (пк из первого пункта) не создавал, никуда оно не подключится.
С этим надеюсь понятно. Теперь к тому что ты на самом деле пытаешься сделать и нужны ли тебе вообще несколько серверов.
1) Если тебе просто нужно две независимые базы, то просто создай две базы на одном сервере и два подключения к ним в пгадмине. В настройках подключения ты прописываешь название базы.
2) Если тебе действительно нужно несколько баз с разными портами, то используй виртуальные машины. В частности докер. Там можно за пару минут поднять хоть десять контейнеров с постгресами на нужных портах.
Как методами только postgres и pl/sql сделать динамический sql следующего вида:
У меня запрос по типу SELECT name FROM customers WHERE email = %s
email в виде строки подставляется извне, в некоторых случаях он может быть null, в таком случае условие WHERE игнорирутеся и совершается поиск по всей таблице customers
Если у вас там вместо параметризованных запросов васянская конкатенация строк, как у говнокодеров на PHP из нулевых, надо будет городить что-то типа такого: https://stackoverflow.com/a/29617481
Обычная хранимая функция, которая принимает строку с мылом https://dbfiddle.uk/0sviVzxJ .
Тут не нужно никакой конкатенации.
И кстати для базы ЛЮБОЙ sql не из хранимки это просто "строчка", которую еще надо распарсить и понять что это на самом деле.

Ну у меня как бы и так функция, но есть нюанс:
если name это null то мы НЕ используем условие WHERE
Я намутил следующую оптимизацию, в WHERE у меня не проверка равенства идет в LIKE. В случае null мы в начале превращаем его в '%' следовательно условие LIKE везде будет TRUE (колонка не нулабельна)
>проверка равенства идет в LIKE
LIKE медленная параша, не используй без крайней необходимости.
Гораздо проще свести выражение к тавтологии с помощью COALESCE. column = COALESCE(parameter, column) , то есть если параметр равен NULL, то сравнить колонку с собой https://dbfiddle.uk/yR14AVU7 . Оптимизатор такие простые тавтологии знает и сам условие отбросит.
Однако то что ты пытаешься сделать это очень плохая идея. Возвращать всю таблицу это самое хуевое что можно придумать.
В идеале вообще запретить использовать null https://dbfiddle.uk/S1E8YUHI .
Или пометить функцию как STRICT https://dbfiddle.uk/58c4F8rh тогда она с NULL просто выполняться не будет. Как по мне вариант с явным запретом лучше.
В крайнем случае можно возвращать не таблицу, а курсор https://dbfiddle.uk/qe9cXGgi , чтобы потом фетчить помаленьку. Гарантировано никто не попытается прочитать условный миллион пользователей и положить нам базу.
Во, спс, как раз то что искал. Забыл пр оcoalesce
Вообще про одну таблицу я сказал для упрощения, чтоб вам было легче меня понять
У меня в реале не таблица, а pl/sql функция которая возвращает результат query запроса с несколькими джойнами и условиями where. Так сложилось исторически, поэтому просто выпилить эту функцию не особо получается, надо было реворкать
А фронт получает данные через пагинацию все равно
Мужички, подскажите как бы выглядел код функции SUM() написанный на самом pgplsql.
Пытался найти это в гитхабе постгреса думая что сами агрегатные функции написаны на нем же, а не на си.
Пытался найти это в гитхабе постгреса думая что сами агрегатные функции написаны на нем же, а не на си.
См. документацию по CREATE AGGREGATE.
Код SQL-Сервера может быть написан как угодно с совершенно зубодробительными оптимизациями.
Например, так https://github.com/ClickHouse/ClickHouse/blob/8b13b85ea0e059bc5356981c9b675549855dc1b2/src/Storages/MergeTree/MergeTreeData.cpp#L720
Мальчики, а в постгре когда юзать хеш, когда би-три этот ваш? Все понять не могу
Как ты вообще прошел алгоритмическое собеседование?
вообще, лучшена mysql переходи. ведь там нет других индексов кроме btree, тк они по сути и не нужны в OLTP.
Ну да, есть hash, но поддерживается только для движка memory.
Да как минимум я рядовой бекенд разработчик, а не архитектор бд
От хэшиндексов больше проблем, чем пользы. Практически всегда нужно юзать B-tree. С хешами ты пососёшь в order by, в сложных условиях фильтров where и при поиске по неселективным значениям. Польза будет разве что в индексе на столбец с рандомными UUID-ами или подобным, и то спорно.
>mysql
Как там в 2008?
Как там в 1970 с постгресом, ты хотел спросить?
Свинья пытается в перефорс, вы только поглядите!
Не трясись ты так, дыши глубже, любимое пердольное говно у тебя никто не отнимает

Я тут на досуге придумал более продвинутую концепцию
У нас будет не динамический sql и не функции/процедуры а ДИНАМИЧЕСКИЕ ФУНКЦИИ, то есть тело функции будет определяться в рантайме в зависимости от условий, питон это сделает
Уверен мало кто до меня до такого додумывался
Перед каждым запросом вызывать CREATE OR REPLACE FUNCTION?
>пердольное
Сказала чмоня, контейнер для чьего говна без пердолинга и не накатывается, тем более на архитектуру arm
Нет. Надо делать DROP FUNCTION, тогда и сигнатура может быть динамической
Не благодари

Братцы, хелпаните с мусклом, вижу у вас тут дискуссии как раз на этот счет.
Поднял себе контейнер мускла, т.к. на проекте у них именно он. Чтобы работало на Убунте пришлось поебаться, вольюмы поменять, вроде завелся, в логах вот такой вот херня как на скрине. Какие-то незнакомые базы гоняют какие-то апгрейды "from version X to version Y" - это шо вообще такое?
Поднял себе контейнер мускла, т.к. на проекте у них именно он. Чтобы работало на Убунте пришлось поебаться, вольюмы поменять, вроде завелся, в логах вот такой вот херня как на скрине. Какие-то незнакомые базы гоняют какие-то апгрейды "from version X to version Y" - это шо вообще такое?
ПЕРЕКАТ
ПЕРЕКАТ
ПЕРЕКАТ
ПЕРЕКАТ
ПЕРЕКАТ
ПЕРЕКАТ
ПЕРЕКАТ
ПЕРЕКАТ
ПЕРЕКАТ
Наверное ты поднял не просто "контейнер", а кластер с настроенной репликацией? Это системные базы реплицируются у тебя
Есть тут bi аналитики которых можно помучить глупыми вопросами? На связи тян 24 годика, пытаюсь вкатиться.
@Annellissa
@Annellissa
Попробовал
select (n).n1 from (SELECT (SELECT n FROM (VALUES (1, 2)) AS n(n1, n2)))t
и словил ошибку record type has not been registered
чядн?

Как это исправить в MS SQL?




Ссылки:
- https://www.postgresqltutorial.com/
- https://www.mysqltutorial.org/
- https://www.sqlitetutorial.net/
- https://www.oracletutorial.com/
- https://github.com/agarcialeon/awesome-database
Задачи:
- https://www.sql-ex.ru
- https://www.codewars.com/?language=sql
Продвинутый MySQL:
- https://www.mysqltutorial.org/mysql-resources.aspx
- https://shlomi-noach.github.io/awesome-mysql/
Инструменты проектирования БД
- https://www.mysql.com/products/workbench/
- https://explain.dalibo.com/
Видосики:
- Плейлисты по разным СУБД: https://www.youtube.com/c/SQLDeveloperBI/playlists
- https://www.youtube.com/playlist?list=PLY7PmJJFH5nT-lbFKxfbp3rw5BBuq5Azo
Литература:
- Томас Кайт. Oracle для профессионалов
- https://postgrespro.ru/education/books/dbtech
- Алан Бьюли. Изучаем SQL. - про MySQL
- К. Дж. Дейт. Введение в системы баз данных
Прочее:
- https://dbdb.io/
- https://db.cs.cmu.edu/
- https://www.youtube.com/channel/UCHnBsf2rH-K7pn09rb3qvkA/playlists
- Сравнение диалектов SQL: http://troels.arvin.dk/db/rdbms/
- Как БД работают изнутри: https://habr.com/ru/company/mailru/blog/266811/
Ссылки для альтернативно мыслящих:
- https://www.w3schools.com/sql/
- https://learnxinyminutes.com/docs/sql/
- https://metanit.com/sql/
- http://sql-tutorial.ru/
- https://metanit.com/nosql/mongodb/
FAQ:
Q: Нужно ли знать английский?
A: Нет.
Q: Что лучше, SQL или NoSQL?
A: SQL.
Q: Вопросы с лабами и задачками
A: Задавай, ответят, но могут и обоссать.
Здесь мы:
- Разбираемся, почему PostgreSQL - не Oracle
- Пытаемся понять, зачем нужен Тырпрайс, если есть бесплатный опенсурс
- Обсуждаем, какие новые тенденции хранения данных появляются в современном цифровом обеществе
- Решаем всем тредом лабы для заплутавших студентов и задачки с sql-ex для тех, у кого завтра ПЕРВОЕ собеседование
- Анализируем, как работает поиск вконтакте
- И просто хорошо проводим время, обсирая чужой код, не раскрывая, как писать правильно.
Поехали!