




Обучил лору на лайнарте. Результат - пикрил. Что я делаю не так?
Обучил лору на лайнарте. Результат - пикрил. Что я делаю не так?
Обучил лору на лайнарте. Результат - пикрил. Что я делаю не так?
Обучил лору на лайнарте. Результат - пикрил. Что я делаю не так?
Обучил лору на лайнарте. Результат - пикрил. Что я делаю не так?
Выглядит как очень высокая скорость обучения/слишком длинное обучение
Всего 6400 шагов на 50 картинок. Мне более поздние эпохи чекнуть?
версия 0.3.1, если что, другие стили норм на таком обучаются
> другие стили норм на таком обучаются
Ну значит этот датасет требует другого подхода. Не вижу ни картинок ни настроек, могу только гадать
могу датасет скинуть, настройки от 1060анона
Ну показывай всё что есть
# Настройки обучения
$learning_rate = 1e-4 # Скорость обучения
$unet_lr = 1e-4 # Скорость обучения U-Net
$text_encoder_lr = 1e-4 # Скорость обучения текстового энкодера
$scheduler = "constant" # Планировщик скорости обучения. Возможные значения: linear, cosine, cosine_with_restarts, polynomial, constant (по умолчанию), constant_with_warmup
$lr_warmup_ratio = 0.1 # Отношение количества шагов разогрева планировщика к количеству шагов обучения (от 0 до 1). Не имеет силы при планировщике constant
$network_dim = 128 # Размер нетворка. Чем больше значение, тем больше точность и размер выходного файла
$is_random_seed = 1 # Сид обучения. 1 = рандомный сид, 0 = статичный
$shuffle_caption = 1 # Перетасовывать ли теги в файлах описания, разделённых запятой
$keep_tokens = 2
16 эпох, 8 повторений концепта
бля 1повтор в датасете случайно попался, ну бывает

Я бля не знаю даже что сказать, это супер тяжелый датасет особенно если ты тренишь 512px, вот для наглядности прикрепил пик который уменьшил до размера 512px по длинной стороне. Это то, как видит его нейронка при обучении. Если бы я пытался натренить такое, во-первых я бы откропал все изображения аккурат под размер тренировки и постарался чтобы всё самое нужное мне во-первых влезло в квадратный пик (чтобы линии выглядели как можно толще), во-вторых я хуй знает, наверное пробовал бы нащупать на constant'е нужную скорость обучения (она может быть как и выше чем твоя, так и ниже, я тебе тут на глах не подскажу)
А если просто через промпт? Но у меня получается только в стиле скетча, а не лайнарт



Во времена пика дримбуха у меня была проблема с альфа каналом. Некоторые пикчи вот так для нейросети виделись. Поэтому сейчас фон всегда ставлю через фотошоп белый.
Скачал и запустил у себя. Посмотрю что выйдет.
В этом и дело, мне бы стабильный результат monochrome или лайнарта для манги.
>запустил
С таким же фоном или с белым?
А как удобно сохранять все настройки и промпт для последней сгенеренной картинки? Чтобы еще удобно переключаться.
Белым
Думаю можно через апскейл папку пикч пропустить со значением 1 и он там зальется. Но я что-то в фотошоп полез.
Я запустил обучение на monochrome. Результаты через 4 часа
Посмотрим, что выйдет.

Кстати лайнарт это самая тупая и рутинная работа для художника, еще и дохуя скилла нужно. Жопу даю, что фотошопы и прочие paint tools сделают кнопочку для AI лайн арта и непоехавшие художники будут только рады.

впрыг



По крайне мере без артефактов и рисует чисто черно-бело. Пробовал на v4.0 при dim32 alpha16, loss на последней эпохе был 0.750. Еще попробую на v3.2 при dim128
Ок, скинь потом обе в тред
Нах тренить на не оригинальной модели да ещё и с кривым клипом? Бери наи и все
Най без вае?
Привык на ACertainty с вае от Anything 3.0, а потом тестить на Anything 4.5
Я всегда выбираю по такому принципу, что рисовка датасета и стиль модели должны быть примерно одинаковые. Чаще всего это NAI/ACertainty. Иногда оранж.
Брать что-то кроме наи бессмысленно, в любой анимемодели наи является базой (имею в виде все популярные анимемерджи), а значит все разные результаты базированных на наи моделей не более чем флуктуационные зависимости уже содержащиеся до этого в наи. Ну и второе: базы обычно стабильные в получаемых результатах, в отличие от мерджей.
Наи кста не может в лайнарт совсемб тренить на нем - безрассудство
И настроечки бы с версией мокрописи, плиз
Дай датасет я натреню изи
Выше по треду же
На пиках энифинг?




Получилось у меня в итоге натренить как и хотел, но мэх... Вообщем уловилась суть датасета лишь на стоке старых версий, то есть 128 дим/альфа и 1е-4 лр. Есть один серьёзный минус, периодически, при хайрез фиксе НЕ латентными апскейлерами картинка на первом шаге хайреза превращается в черный канвас с полоской снизу как на пик 4, лол, на которой даже что-то дорисовывается в последствии, хз что это, может напрямую связано как раз с проебанными округлениями в связи с такими дим/альфой, подскажите если кто знает.
Попробовал менять лишь дим/альфа 32/16; 64/32 - эффекта намного меньше, пик 2 - 32/16.
Получше улавливает стиль с 32/16 с 4.5е-4 пик3, но всё равно не то и такие настройки как-то по другому совсем уловили тёмные тона, вообщем мне больше всего понравился именно вариант с 128
Пробовал выставлять текст экнодер в ~7 раз меньше Унета, одновременно с повышением батча и скоростей как ТЕ так и Унет, может я слишком проебался с настройками, там они совсем другие, но получилась вообще полная шляпа по стилю, обычные персонажи из стока тоже слабо поменялись, в пост уже не влезет, если интересно, могу скинуть в некст сообщении грид, даже хз юзать ли такой подход в дальнейшем для стилей
Попробовал менять лишь дим/альфа 32/16; 64/32 - эффекта намного меньше, пик 2 - 32/16.
Получше улавливает стиль с 32/16 с 4.5е-4 пик3, но всё равно не то и такие настройки как-то по другому совсем уловили тёмные тона, вообщем мне больше всего понравился именно вариант с 128
Пробовал выставлять текст экнодер в ~7 раз меньше Унета, одновременно с повышением батча и скоростей как ТЕ так и Унет, может я слишком проебался с настройками, там они совсем другие, но получилась вообще полная шляпа по стилю, обычные персонажи из стока тоже слабо поменялись, в пост уже не влезет, если интересно, могу скинуть в некст сообщении грид, даже хз юзать ли такой подход в дальнейшем для стилей
>вариант с 128
это база




Тест с grin, sand, beach, summer, sky, day, full body
бля датасет собираю а шишка то колом
Неплохо, можно в мангу вкатываться.
Но это обычный тег monochrome ...
Для манги нужен более специфичный стиль
У меня есть датасет схожий с манга стилем.
Еще бы научить сетку ракурсам. А пока надо крутить барабан, пока не выпадет нужное.
Да и нет единого мангастиля, разные манги имеют разную рисовку
Обмаз 3дболванки
Нужно еще и обстановку делать =( Надеюсь для блендера есть аддоны, как с улицами и домами или что-нибуть на нодах.



Сап технический. У меня почему-то additional-networks не видит мои файлы лоры. Причем сама нативная поддержка автоматик1111 их видит. Я ес что через коллаб. ЧЯДНТ?
Для экстеншна их надо в папку самого экстеншна класть.
Ферштейн, пасиба.
О, найс. Надо посмотреть
Начал тренить етот кал.
в пизду я не буду вручную тегать тысячу пикч


закончил тренить, альфа срет в эпохи
тогда залей фон белым, хули
ну залей сам, мне лень

не знаю, похоже ли это на манга-стиль или нет
рейт
это похоже на запоротый тренинг изза альфа канала братан
Что именно там запорото, чел?
И в том датасете нет ни одной пикчи с прозрачным фоном.
не должно быть черных заливок, черного фона, ток лайнарт


У меня датасет другой, чел. Читай на какой пост я отвечаю.
>обучение на monochrome
а, тогда норм
понял понял
И это 12 эпоха на низких весах. Перетрен дикий к 16 эпохе пошел, там на 14 эпохе лосс был 0.05
Похоже на манга-стиль? Как по мне, вышло схоже.
И тренил я на капусте основанной на энифинге 4.5.

16 эпоха, уже начинает спавнить скринтоны, сама по себе.

Эти пикчи на наи дефолтном, а вот энифинг выдаёт более детализированные результаты, что интересно.
А нах вы манга стиль переизобретаете? Разве через промт не получается? И даже нет специальных манга моделей что ли? Или вы тут все по фану?
Через промт хуета выходит, и через раз.
>мангамоделей
Я не нашел
И как их натренить, если в манге изображение постоянно перекрывает облачко. Я с бур еле набрал для лоры датасет, хз, как на модель собрать.
Тогда удачи. А получится ли nsfw пикчи генерить с твоей манга моделью? Или тебе для этого уже нужен nsfw-манга датасет? (сорри если тупой вопрос я нуб)
Как сделать вайлдкарту с лорами?


Запилил гриды на разных планировщиках. Все сделано с
$learning_rate = 6e-4
$unet_lr = $learning_rate
$text_encoder_lr = 3e-4
По качеству - двоякие ощущения. Констант виз вармап дает очень разные результаты на одном сиде. Стиль держат +- одинаково.
$learning_rate = 6e-4
$unet_lr = $learning_rate
$text_encoder_lr = 3e-4
По качеству - двоякие ощущения. Констант виз вармап дает очень разные результаты на одном сиде. Стиль держат +- одинаково.


Задник - это задник. Отдельная фича.
Ставь в промптах simple background, white background, - и не будет "скринтонов".
>а вот энифинг выдаёт более детализированные результаты, что интересно.
Я про это в НАИ-треде написал, кстати.
Базовый НАИ может выдавать очень простую картинку с минимальным набором стилистических тэгов, а вот с Эни фиг, имеет место тенденция к переусложнению картинки. Что вообщем-то применимо и к цветным картинкам тоже, в Эни более сложные пикчи получаются, чем в НАИ.
6гигов потянут датасет на 4гига 1000 картинок?
Могу ошибаться, но размер сета к памяти отношения не имеет.
Он ж не весь целиком сразу прогружается, а пофайлово, согласно Batch Size. Вот оно влияет, и очень сильно. На 6гб врядли выше 2 можно выставить, а скорее даже и 2 не получится.
Работает 2 на 6гб. Но по итогу медленнее чем на 1




Есть тут кто подкованный в миксах? Запилите laolei newberry + gorynich местного анона, будет оче годно. Пикрелейтед laolei.

вроде пашет
дрючить 10 часов видюху на датасете из рандомных 3д рендерах я конечно же не буду.
Ясна блядь, тупая лора. Датасет 1к картинок, 250 эпох и как было коряво словно первая эпоха, так оно и осталось. С первую блядь по 250 эпоху лосс как был 0.11, так он таким и остался. Нахуй этот лосс вообще пишется?
попробуй 100 картинок и 10 эпох. помогает.
40 тыщ шагов, убиться веником.
Зачем?



а хули нет? делаю 30к для этой тёти с супер уебанским датасетом. завтра скину чо получилось
Блядь, полистаешь этот цивит ебучий, одна анимепараша однотипная, все нетворки пережаренные и весят по 144 мегабайта. Некоторые блядь на диме 256 своё говно клепают, чую скоро найдутся умники и будем кушать гигабайтовые лоры.
Пару адекватных людей на весь сайт умудряются запихнуть лору в мегабайт, за что им респект.
Пару адекватных людей на весь сайт умудряются запихнуть лору в мегабайт, за что им респект.
Ссылки давай, будет пуре микс тебе
> Датасет 1к картинок, 250 эпох и как было коряво словно первая эпоха, так оно и осталось.
гавнонастройки тренинга, сынок
по опыту скажу что нужно ориентироваться на время тренинга 20-40 минут, ну и на лосс
>С первую блядь по 250 эпоху лосс как был 0.11, так он таким и остался.
гавнонастройки тренинга, сынок
чем меньше лосс, тем более так скажем точная лора будет, но не надо переусердствовать с настройками и выбивать когда loss=nan - тогда лора вообще не заработает
>Нахуй этот лосс вообще пишется?
лора лосс это буквально ГНИЕНИЕ ВЕСА, то есть его распад при тренинге, если ты будешь ебланить и твой лосс будет расти - веса лоры ПРОГНИЮТ и модель обосрется, но есть и обратная сторона - при отсутствии малого гниения лоры не происходит сборки тензорными говнами из шума на основе весов так как они не производят флуктуаций, поэтому гниение нужно но минимальное
>все нетворки пережаренные
проблема тренеров, которые юзают миксы (с хуевыми клипами причем) вместо базовых моделей найки или сд
>весят по 144 мегабайта
а вот это норма, 128 нетворк дим (от него зависит вес лоры) очень точный, оптимум для тренинга и база
> лору в мегабайт
хуита получается, либо нужно долго и упорно перебирать и тестить буквально каждую эпоху с филигранными настройками тренинга
50 на 50 с просранным TE прошлый век, я буду миксить правильнее
один вопрос: тебе надо графон горынача на ньюберри или наоборот?




Думаю, наоборот.
Горыныч разносторонний и делает клёвых лолек. Ньюберри - душевный графоуни с йоба-материалами и поверхностями, объемными формами.
дай промт чтобы тебе потом тестов кидануть на выбор конечного вварианта
желательно для 512 разрешения
an official art, album cover. scan of brunette {{Reika Shimohira}} from gantz. from side, wearing bra and highleg g-string, high heels. highres, absurdres, reflective, perfect shapes, detailed anatomy, vibrant, at pixiv and weibo
в негативном:
lowres, chubby, obese, ugly, by amateur, unfinished draft
> гавнонастройки тренинга, сынок
Учить меня будешь? Показывай свою лору на тысячи пикчах.
> на время тренинга 20-40 минут
Хуйню несешь. Время тренинга варьируется от размера датасета и мощности видеокарты, а также изначальной скорости обучения.
> поэтому гниение нужно но минимальное
Бред. Если у лосса началась тенденция роста, значит ты её пережарил = обосрался с настройками. Пик 3 оппоста.
> юзают миксы
Ничего плохого в этом нет. Если унет модели выдаёт средние результаты похожие по стилистике на усреднённую рисовку датасета, то лучше использовать такую модель.
> с хуевыми клипами причем
С чего ты вообще взял что клип модели используется при тренировке лоры?
> норма
Хуёрма.
> 128 нетворк дим
Это тренд с форчана где зародился первый гайд с такими рекомендованными настройками, и все ебланоиды полетели без раздумий тренировать на этом ранке. На деле ранк 128 это оверкилл для 99.9% обучений, где обычно тренируют один концепт, такой как стиль или персонаж. 128 ранк с соответствующей альфой выжаривает своими весами твою модель так, что ты более не способен по промту 1girl сгенерировать что либо, помимо своего персонажа. И даёт тебе нулики, но ты видимо и не против.
> хуита получается
Ты пробовал? Ну вот и не пизди.
https://civitai.com/models/7231/luisap-3-glitchs-lora
https://civitai.com/models/7024/luisap-cyberpunk-portrait-1mb
https://civitai.com/models/7003/luisap-social-media-profile-pic-1mb

ок
там на цкптшный горыныч жалуются что там троян кста, придется в сендбоксе в сейфтензоры конвертить этот кал
>Учить меня будешь? Показывай свою лору на тысячи пикчах.
да я могу твое говно нормально натренить просто сразу раз уж на понт берешь, кидай свой сет
>Время тренинга варьируется от размера датасета и мощности видеокарты, а также изначальной скорости обучения.
ну тут не соглы, настройки трена как сообщающиеся сосуды - в одном месте перегнешь - другое место отбалансишь, и от карты это зависит постольку поскольку
>Если у лосса началась тенденция роста, значит ты её пережарил = обосрался с настройками. Пик 3 оппоста.
так я про наличие гниения пишу без которого лорка не работает просто, а рост лосса это просто обосрамся
>Ничего плохого в этом нет
это контрпродуктивно
> чего ты вообще взял что клип модели используется при тренировке лоры?
потому что Bayesian Learning Rule
>Хуёрма
делаю только 144 и что ты сделаешь?
>На деле ранк 128 это оверкилл для 99.9% обучений
да тебе и тренить на миксах норм
>128 ранк с соответствующей альфой выжаривает своими весами твою модель так, что ты более не способен по промту 1girl сгенерировать что либо, помимо своего персонажа
гавнонастройки тренинга, сынок
>Ты пробовал?
так я пишу что это невозможно, вполне возможно но усилия не стоят результата когда можно в 128 дим не ебаться
>да тебе и тренить на миксах норм
Заебись кстати.
фурфаг
ну если под конкретную модель ток если тренить, в других моделях эта лора будет такое себе
Сладко сегодня подрочил на собачку.
фурфаг
ты бы и собаку
Лол, не ты один...
слушай а конвертни мне горыныча в сейфтензоры, ты ж его все равно юзаешь, а то у меня 6 часов на самом деле меньше будет но долго все равно конвертер будет копироваться на виртуалку
>Или тебе для этого уже нужен nsfw-манга датасет?
это

А, это.
Ну, чутка в ФШ фигарнуть, и норм.
Сначала блюром чуть, или удалением шума.
А потом уровнями или постеризацией. И будет черненькое.
Анончики, родные, можете натренить для меня модель? Кое как собрал датасет по гайдам, надеюсь правильно, сижу на лютом ведре с 4 гигами
точнее лору
>уровнями
Что конкретно там крутить?
Зафигарь в колабе.
Ссылки ж в первом посте есть.
LoRA [2] прям вообще минимальная. Даже я, никогда с колабом не работавший, почти всё сразу понят там.
Ставишь уровень белого по тому цвету, который хочешь считать белым.
Ставишь уровень черного по тому, что хочешь считать черным.
Дрыгаешь центральный и граничный ползунки, пока результат не устроит.
вроде прочитал про коллабу, звучит не так страшно, но не понял один момент - там будет происходить установка всяких модулей и прочей шняги, это всё будет происходить в пределах коллаба или это установится на мою печь?

Да, вижу, черного добиться можно, но вот серого.

> кидай свой сет
Там ножки девичьи, тебе такое не надо :з
> Bayesian Learning Rule
Каво
> делаю только 144 и что ты сделаешь?
Сдую до 4 мб через скрипт китайца. Пуф!
> да тебе и тренить на миксах норм
Когда возникает такая потребность - да
> гавнонастройки тренинга, сынок
Ну так а ты попробуй возьми лору у которой в датасете был тег 1girl и сделай ген с этим тегом. На кого похожа? 128 ранк + 128 альфа = умножение выходных весов на 128. Никакие настройки от этого не спасут.
> вполне возможно но усилия не стоят результата
Да нет там никаких усилий, берешь и делаешь

Блюром бахай чел. Выборочным.
мимо из прикрепленного


Бля, хотел вручную по-кривому залить серым и прогнать через апскейлер, так апскейлер тупо оставил мою кривоту, даже выделил её.
Ты все равно будешь печатную матрицу делать, всё это выровняется в нормальный монохром . Да и вообще, хочешь генерить пикчи c flat colors - не используй для этого криволорку под стиль манги.
Ну хотя кстати да, пример не слишком идеальный вышел все равно, нужно зерно побольше делать.
>не используй
А что использовать?


Ну я пик на капусте с набитыми от балды тегами получил, подправить черную заливку, перегнать в грейскейл - вуаля, регультат превосходит все ожидания, можно хоть куда использовать. Но лучше конечно поискать нормальные теги в промпт модельку/лорку которая нормально давит из себя цвета без градиентов.
Ну хз, я уж точки лучше поправлю сверхдетализация, плюс нашел лору на флат колорс, на цивите
Каждый раз весь питон и прочие штуки ставятся на сам коллаб. Это быстро.
На подключенном гуглодиске будут лежать оригинальная модель + тренировочный сет картинок, и туда же будет выводиться результат.
Главное путь к папкам правильный укажи, там справа иконка с папкой, после того как диск подключишь - оттуда копируй.
Третий шаг в Лора[2] лишний, кстати, на него можно не кликать.
>справа
Т.е. слева, кек.
Серый тоже можно, но там уже потруднее будет.
Я уже давно сканлейтом не занимался, забыл, как там это всё делается.
По факту из практически любой убитой скринтонной заливки можно получить грейскейл-заливку силами ФШ.
Ну, типа чел отсканил мангу, и в жипеге ее в интернет загрузил, (гореть ему в аду за такое). И вот из такого ужатого шакального жипега можно было как-то получать грейскейльный пнг.
Но как - я уже не помню. Инструкции по идее в интернете остались где-то, можешь погуглить, если не лень.




Блядь. Ну и куда мне с таким гигантским датасетом пиздовать. 20 эпох на cwr, который в теории должен постоянно нормально дообучать все равно какую-то кашу делает. Файнтюн/дримбудку попробовать что ли. Эх, а я так на лору надеялся, но видимо для таких больших датасетов она не годится. Пикрел черрипик. Без текст энкодера, потому что как оказалось он делает только хуже.
Кидай сет



Немного сравнивал для себя разные скорости, не обрезку до квадратов\обрезку, планировщики.
Почему-то лишь в первых двух случаев редактируемость в плане lewd хорошая. Можно cum на нее налить, заставить платье задрать, а вот в других случая почему-то нихрена не выходит, приходится делать (cum:1.4) на nsfw орандж миксе. Хотя цвет трусов, например, редактируется нормально, как и позы, и какие-то действия, предметы в руках.
Почему-то лишь в первых двух случаев редактируемость в плане lewd хорошая. Можно cum на нее налить, заставить платье задрать, а вот в других случая почему-то нихрена не выходит, приходится делать (cum:1.4) на nsfw орандж миксе. Хотя цвет трусов, например, редактируется нормально, как и позы, и какие-то действия, предметы в руках.
А, ну и было 8 повторений на 10-и эпох. Но лишь 5-е эпохи где-то были нормальные в плане редактируемости.
>Почему-то лишь в первых двух случаев редактируемость в плане lewd хорошая. Можно cum на нее налить, заставить платье задрать, а вот в других случая почему-то нихрена не выходит, приходится делать (cum:1.4) на nsfw орандж миксе.
Предполагаю что если лора не редактируема, то веса лоры перекрывают веса модели, а значит чанки пытаются вызвать cum из лоры, а не из модели -> снижай вес.
Для проверки читаемости чанков с лорами скачай https://github.com/mcmonkeyprojects/sd-dynamic-thresholding, выстави там пикрел с мимиком под цфг на твоих пикчах, а потом выкрути основной CFG на 20-30 и перепроверь промты на лорах, высокий цфг бустит максимально учитываемость чанков.
Оказалось, что банально ни одна моя модель lewd нужный мне не рисует сама по себе по стоку. Я уж об этом и забыл. Либо nude + (cleft of venus:1.4), либо нихуя. То есть что-то оголить сложно им, либо в одежде, либо сразу без нее.
Походу чел забил попробовать натренить лору с моей датой на перса с 2 видами одежды. Там мб эпох побольше дать ей? И еще вопрос, у меня с некоторыми чекпоинтами на выходе получаются пикчи с тусклыми цветами, а вот на том же энисинге яркие цвета. Vae стоит в обоих случаях от энисинга. В чем может быть трабл?
Как можно конвертнуть картинку в пиксель арт?
В вае, меняй на вае от сд.




Намана. Это та милфа из мушоку тенсея?

не милфа

Подскажите сколько loss должен быть что бы понимать увеличивать скорость обучения илиьуменьшать ? Или это немного не так работает? Постоянно такое +-
В целом меньше 0.2 вполне ок. Чем меньше, тем точнее тренировка весов, но не нужно чтобы вообще лоссов будет писать nan вместо циферок не было.
Не помогло, на превьюшах, которые каждые 10 шагов, картинка выглядит более яркой, чем итоговая. Мб как-то связано с выводом изображения?
На HF есть safetensors
там в1, а цкпт в1.1
Тебе не похуй? Будто автор чекпойнта дохуя вкладывается в его развитие.
А как сделать превью для чекпоинтов и лоры?
Как исправить клип скип у модели?
калфу убери
https://github.com/lllyasviel/ControlNet
Во какая штука.
В конце даже аниме-лайнарт есть.
Только вот без релиза пока.
Во какая штука.
В конце даже аниме-лайнарт есть.
Только вот без релиза пока.
А повторения указываются в номере папки или где?
Да
8_ass furry

Господа, хотел по поводу ускорения генераций поспрашивать.
Сижу на RTX3060 и помимо прописывания --xformers в батнике ничего не подрубал.
В автоматике внизу страницы пишет:
python: 3.10.6 • torch: 1.13.1+cu117 • xformers: 0.0.16rc425 • gradio: 3.16.2
В командной строке nvidia-smi выдает:
NVIDIA-SMI 528.49 Driver Version: 528.49 CUDA Version: 12.0
Ну и собсна вопросы. Есть ли еще какие-то человеческие, не мозгоебательные способы увеличить скорость генераций? Мб обновить что-то из компонентов?
Слышал про pytorch 2.0 и cuDNN библиотеки. Есть ли смысл париться и даст ли какой выхлоп на 3060?
Сижу на RTX3060 и помимо прописывания --xformers в батнике ничего не подрубал.
В автоматике внизу страницы пишет:
python: 3.10.6 • torch: 1.13.1+cu117 • xformers: 0.0.16rc425 • gradio: 3.16.2
В командной строке nvidia-smi выдает:
NVIDIA-SMI 528.49 Driver Version: 528.49 CUDA Version: 12.0
Ну и собсна вопросы. Есть ли еще какие-то человеческие, не мозгоебательные способы увеличить скорость генераций? Мб обновить что-то из компонентов?
Слышал про pytorch 2.0 и cuDNN библиотеки. Есть ли смысл париться и даст ли какой выхлоп на 3060?
Вроде только на 4ХХХ есть смысл пердолиться

Ну в основном все про 40 линейку и пишут, на 4090 производительность в разы растет. А вот черт знает про 30-ые и 3060 в частности.
Сейчас у меня на стандартных настройках Эйлер А 20 шагов 512x512 одну картинку без батчей делает в среднем за ровно 3 секунды, мб чуть больше. 7.2 итераций в секунду. Без андервольта или снижения power limit, разгон карточки без зверства.
Вроде и норм, но блять, если можно как-то еще ускорить простым путем было бы кайф, хочется хайрезы делать шустрее. Про тот же торч 2.0 не понятно даст ли че вообще.
Ничего не должно поменяться.
0.110-0.070 норм. Но это не 100% показатель, даже если он начинает то возрастать, то падать. У меня часто было такое, что loss аж до 0.045 падал, а выходило говно.
Хуева.
У меня 3080 простаивает иногда без дела, норм идея если продавать мощности для ai кому-нибудь? Можно даже просто свой webui с триллионом моделей расшаривать платно. Или платно это нахуй никому не нужно?
А можно как-то автоматизировать webui чтобы сгенерировалось несколько картинок от 15 до 30 steps?
>А 20 шагов 512x512 одну картинку без батчей делает в среднем за ровно 3 секунды
ебать ты зажрался чел
35 секунд генерации нищук
>Есть ли еще какие-то человеческие, не мозгоебательные способы увеличить скорость генераций? Мб обновить что-то из компонентов?
Надо дать пиздов этим хуебесам чтобы они в паблик свою хуйню выложили https://github.com/chavinlo/sda-node
>А можно как-то автоматизировать webui чтобы сгенерировалось несколько картинок от 15 до 30 steps?
Можно, в XYZплоте выбрать степсы и прописать
Анонче, подскажи пожалуйста, как сохранить маску из фотошопа, чтоб использовать в SD? Как сделать, то я знаю, но вот как сохранить отдельным файлом именно черно-белую маску...
в пнг
Ну это-то я тоже подумал, но как сохранить маску отдельно от изображения, потому что в фотошопе сохраняется именно в пнг привязанное к этой маске изображение... Ну или я чего то недопонимаю

Это нормально, что есть lr, text encoder lr, но нет net lr?
пропиши
Продаваться твоя 3080 будет за 6 рублей в час. Устроит?
Привык к хайрезам 1024x1408(1536). А там уже около минуты на одну картинку.
Да и потом, посмотришь на лороведов тут и в других местах - многие на топовых картах сидят, пиздец.
Ну судя по всему у них сыровато пока или скрывают свой паверлевел. Хех, через JSON запросы генерить. Но цифры скорости впечатляющие.


>Привык к хайрезам 1024x1408(1536). А там уже около минуты на одну картинку.
А, проблемы хайрезфиксеров.
Если у тебя 3 сек на 512, то хайрез апскейл с 512 до 1024 будет секунд 12 через ультимейт апскейл + доп секунды для симсфикса.
> то хайрез апскейл с 512 до 1024
> через ультимейт апскейл
А для чего? Эти разрешения тянут все карты с 6-8 гб врам, когерентности хватает чтобы делать качественный апскейл без разбивки на куски, можно использовать латент, в чем профит скриптовых костылей?
Не, ну 3 секунды с чем-то это квадраты и 20 шагов, а обычно 30 и высота побольше 704, 768 для портретных соотношений и с него хайрез по классике.
>ультимейт апскейл
Честно говоря хуево понимаю какие там настройки выставлять для стабильно нормальных генов без артефактов, кроме Scale from image size: 2. Нужно ли ползунки разрешения изначальной картинки двигать, размеры тайла и т.д.
> Есть ли смысл париться и даст ли какой выхлоп на 3060?
У меня был на 3070, в цифрах не скажу, по ощущениям процентов на 15-20 генерации быстрее делаются. Если захочешь попробовать у себя -
Схоронил. Тогда как освобожусь предварительно скорость хайрезов своих прочекаю, чтоб сравнивать.
При заливке автоматика с нуля просрал старое репо кохи. Поздравте меня..
Стоит копаться и искать старую версию или на новой все починили? И нужно ли искать новый гайд для последних версиий?
Стоит копаться и искать старую версию или на новой все починили? И нужно ли искать новый гайд для последних версиий?
У кохи в релизах много разных версий. Не вижу смысла в старой, на новой всё работает




Идея тренировать Ливси на NAIfull была ошибкой..
Рисовка - чек
Костюм +\-
Анатомия - полный провал
Рисовка - чек
Костюм +\-
Анатомия - полный провал
а инструкт мощная залупа оказывается
>инструкт
Ват?

Прописал
Не работает


Закинул пару косплей сетов в лору по приколу
Обучал на ACertainty, генерировал тоже на всяких аниме моделях от най до миксов с орандж миксами
Обучал на ACertainty, генерировал тоже на всяких аниме моделях от най до миксов с орандж миксами
А как ты маску то отдельным слоем сделал, анон??? Та, которая Layer 1! Я только слой-маску видел, это всегда какой то слой и справа от него маска. Она может быть привязана или отвязана, но никогда не идет отдельным слоем!
Мне вот интересно, а почему нейросетку тренируют делать арты в растре, а не в векторе? В векторной графике можно было бы забыть про такую вещь как разрешение, и рисовать бы АИ начал на проце, а не на видюхе.
Идея, кстати, хороша!
Но нужен промпт от косоглазия
В растре понятно, что такое близкие части изображения - это близкие пиксели. А в векторе для поиска близких частей нужно много вычислений. Это если очень кратко и упрощённо и именно о диффузионных моделях.
Проще потом векторизовать любую картинку. Но такой технологии нет. Надеюсь, скоро будет.
Ты изобрёл Horde и vast.ai
А можно как-то объединить куски с картинок? Например на одной взять ноги, на другой руки, на еще на другой часть фона и наложить на третью? Куда смотреть? img2img inpaint?
Есть варик платить за это без пердолинга с впнами и покупками предоплаченных карт?

У меня проблема с колабом дримбуч. Дело в том, что я скачал модель с civital и загрузил на гугл диск, указал в колабе путь на ckpt файл, но оно не работает и выдаёт ошибку, я експерементировал с разными моделями и выяснилось, что модели созданные непосредственно в этом колабе, без проблем загружаются и их можно обучать, где бы они на диске не находились, а вот когда пытаешься загрузить инородный ckpt файл, то всё нихуя не работает. Что ему не хватает? При этом если просто указать путь к модели во вкладке тестирования, то всё работает.
Микс горыныча с Laolei еще не запилили? Я б даже добавил в Stable Horde, если получится годнота
Что лучше для SD на 4090 - ddr4 или ddr5?
>4x RTX A6000 $1.61/hr
окей, я всосал
чел, это просто слои обычные с покрасом в белый и черный, потом экспортишь в пнг и суешь в вебуй
Вот я идиот! Спасибо!


Снеси папку venv и перезапусти.
>иди нахуй
Ок
Что тебе непонятно?

Почему-то все же отваливается unet lr. Через метаданные посмотрел. Табличку даже составил.
Там должная быть какая-то логика уровня, что lr должен быть либо равен, либо делиться на unet на два\четыре и т.д.?
хз туплю
Там должная быть какая-то логика уровня, что lr должен быть либо равен, либо делиться на unet на два\четыре и т.д.?
хз туплю
Если ты юзаешь скрипт из лорагайда, то когда ты ставишь унет лр равным обычному лр, то он в параметры не добавляется. Если ты внимательно читал гайд, то должен знать, что есть два способа настройки скорости обучения: либо менять значение learning_rate, в этом случае ты контролируешь скорости unet и te одновременно (они будут одинаковые), либо менять скорости unet и te по отдельности
В таблице какую-то хуйню сморозил с повторами... Забейте.
Короче, можно ли вообще не указывать lr тогда? Если я этот параметр удалю, а оставлю лишь te и unet, то ошибка в консоли появляется.
Поставил lr = 0 и заработало.
Короче, можно ли вообще не указывать lr тогда? Если я этот параметр удалю, а оставлю лишь te и unet, то ошибка в консоли появляется.
Поставил lr = 0 и заработало.
>Поставил lr
юнет?

Вот чего не хватает "мозгу" stable diffusion, так это абстракции. Стейбл хорошая сетка, но к сожалению в большинстве случаев рисует только то, что было в датасете. Не умеет смешивать концепты. Например практически нереально без различных ухищрений нарисовать что-то вроде "странный обед состоящий из ржавых труб, болтов и гаек" или "автомобиль сделанный из человеческих органов". У миджорни и далли вроде как получше с этим. Очень надеюсь на DeepFloyd, за ней вроде те же челы что и за стейблом, и по слухам опенсорс релиз в этом месяце.

В декабре я мог генерить пики в 1980х1060.
Потом в начале января обновился, там появился этот новый хайрез фикс. С тех пор ни с ним, ни без не могу сгенерить в таком разрешении.
В чем дело, анонцы?
Потом в начале января обновился, там появился этот новый хайрез фикс. С тех пор ни с ним, ни без не могу сгенерить в таком разрешении.
В чем дело, анонцы?
deep purple pink floyd, дубина
Писать надо сверху, что это для лоры. И не хватает возможности без (с)траха и упрёка тянуть *.ckpt по урлу. Гуглодиск не резиновый!

Сюда еще не приносили?
https://github.com/opparco/stable-diffusion-webui-two-shot
https://github.com/opparco/stable-diffusion-webui-two-shot
О, вот и в поломатик принесли новейшее изобретение нейронщиков - композицию! Добра тебе, анон!
как использовать это???

а понятно, патч надо прмиенить
хех, можно без опаски ставить 30 цфг даже без цфг фикса получается, ток надо блекнвайт прописать в негативах а то чбшки одни
блин классная штука
Ничего не напутал с начальным разрешением и конечным?
В настройках есть галка, которая включает логику выбора разрешения как раньше, то есть чтоб сразу конечное задать можно было.
Не понял. Зачем оно нужно?
околоидеальный композ каждый ролл, можно юзать с 30cfg изменяя параметром weights силу весов и как следствие бернинг, можно юзать с апскейлерами на высоком цфг что дает экстрадетализацию, ну кароче крутая штука
а ну и так как это композабельная залупа можно нормально контролировать количество персонажей и кастомайзить каждого из них
Нужны примеры.
установи, настрой и погенерируй епт
Щас бы судорожно накатывать каждое первое говно, которое тащат в тред такие торопыги.
как будто тебя кто-то заставляет, не хочешь не накатывай, ретроградище

С форчка, примеры и всякое для Latent Couple extension.
Для пикрелейтед.
Well I understand the parameters now, but the way it's set up makes it kinda annoying, but I also get it because it was probably the quickest implementation for still being flexible.
Divisions is how many times you want it split in y:x respectively, and positions is which chunk you want to use for that division, the position being zero indexed, again being y:x. Weights is self explanatory.
If you want to do a more complex split like 3/4 & 1/4, picrel, you need to do:
>Latent Couple: "divisions=1:1,1:4,1:4,1:4,1:4 positions=0:0,0:0,0:1,0:2,0:3 weights=0.2,0.8,0.8,0.8,0.8 end at step=20"
And you need to then modify your prompt to duplicate that chunk that it uses like so:
>nsfw, 1girl, 1boy, sex, from side
>AND 1girl, 1boy, (hakurei reimu:1.1), nude, sex, doggystyle, from side
>AND 1girl, 1boy, (hakurei reimu:1.1), nude, sex, doggystyle, from side
>AND 1girl, 1boy, (hakurei reimu:1.1), nude, sex, doggystyle, from side
>AND nsfw, 1boy, nude, penis, standing, from side
This assigns each of those prompts to each chunk, and since divisions can't be given a size for an individual dimension, you have to create 3 divisions for the first 3/4, and 1 division for the last 1/4.
Thank you for reading my blog.
https://files.catbox.moe/c55noq.png
https://files.catbox.moe/0gj315.png
https://files.catbox.moe/m1j9rc.png
https://files.catbox.moe/cprnds.png
Для пикрелейтед.
Well I understand the parameters now, but the way it's set up makes it kinda annoying, but I also get it because it was probably the quickest implementation for still being flexible.
Divisions is how many times you want it split in y:x respectively, and positions is which chunk you want to use for that division, the position being zero indexed, again being y:x. Weights is self explanatory.
If you want to do a more complex split like 3/4 & 1/4, picrel, you need to do:
>Latent Couple: "divisions=1:1,1:4,1:4,1:4,1:4 positions=0:0,0:0,0:1,0:2,0:3 weights=0.2,0.8,0.8,0.8,0.8 end at step=20"
And you need to then modify your prompt to duplicate that chunk that it uses like so:
>nsfw, 1girl, 1boy, sex, from side
>AND 1girl, 1boy, (hakurei reimu:1.1), nude, sex, doggystyle, from side
>AND 1girl, 1boy, (hakurei reimu:1.1), nude, sex, doggystyle, from side
>AND 1girl, 1boy, (hakurei reimu:1.1), nude, sex, doggystyle, from side
>AND nsfw, 1boy, nude, penis, standing, from side
This assigns each of those prompts to each chunk, and since divisions can't be given a size for an individual dimension, you have to create 3 divisions for the first 3/4, and 1 division for the last 1/4.
Thank you for reading my blog.
https://files.catbox.moe/c55noq.png
https://files.catbox.moe/0gj315.png
https://files.catbox.moe/m1j9rc.png
https://files.catbox.moe/cprnds.png
рейму так нравится, хочу быть на её месте
И как этим, блять, пользоваться?
Скрыл тред.
Держи вкурсе, чмоня
А как эта галка выглядит, покажешь плз?
Вдруг сработает.
ну на гад базовый, но вообще можно пользоваться хоть как, даже без AND оператора и со всякими плогенсами
Prompts & Quick Guide
Disabling Latent Couple: In Latent Couple's parameters, set End at this step to 0
Prompts are made out of "sections" separated by AND. I'll try to break down the structure that I've noticed.
Base Prompt: Your overall words, such as quality, backgrounds, number of characters, etc. The base prompt is repeated in each section to reinforce the overall words for each section. We want to reinforce these to make sure we have the right amount of characters, the correct location and so on.
Character (number): Details of your character, their embeds, etc
A prompt for 2 characters can be broken down as follows:
Base Prompt AND Base Prompt, Character 1 AND Base Prompt, Character 2
Note for LORAs: Only use a LORA once, it can be tacked on to the end of the prompt. If you use it by the Base Prompt just be careful you don't paste it throughout the prompt, or it'll be extra fried.
For the Params:
Default - 2 Characters: Latent Couple: "divisions=1:1,1:2,1:2 positions=0:0,0:0,0:1 weights=0.2,0.8,0.8 end at step=20"
3 Characters: Latent Couple: "divisions=1:1,1:2,1:2,1:2 positions=0:0,0:0,0:1,0:2 weights=0.2,0.8,0.8,0.8 end at step=20"
4+ Characters: Use either this: Latent Couple: "divisions=1:1,1:2,1:2,1:2,1:2 positions=0:0,0:0,0:1,0:2,0:3 weights=0.2,0.8,0.8,0.8,0.8 end at step=20" or the above 3 character code if you start to see issues.
5+ Characters: If you really wanna try, use either this: Latent Couple: "divisions=1:1,1:2,1:2,1:2,1:2,1:2 positions=0:0,0:0,0:1,0:2,0:3,0:4 weights=0.2,0.8,0.8,0.8,0.8,0.8 end at step=20" or try the above codes.
End of Quick Guide
Params
The main part of the Params is Division. Adding more Divisions allow you to have better control of the separate "sections" of the image. But, there is diminishing returns to adding too many Divisions, such as drop in quality of the image and diverting from the prompt.
Division:
This parameter effects the rest of the extension while also allowing for a lot of experimentation.
For the basics, you can use an amount of Divisions to account for all of your prompt "sections". The first Division is for the overall image. The other Divisions effect the "sections" of your prompt.
The amount of Divisions you use can depends on how many prompt "sections" you have. There are diminishing returns as you add more Divisions, such as diverting from prompt and low image quality. I highly recommend you keep your total amount of Divisions to at most 4, unless you wanna try experimenting.
To use Position, there must be the same amount (or more) Divisions as Positions.
---
Now for the advanced part, if you're interested. The numbers themselves can be changed to create variations of your image, such as by changing the first Division from 1:1 to 1:2 or to even 1:100. Bear in mind, using 1:1 on other Divisions can divert from prompt, and increasing it to 1:5 can divert drastically from prompt. Higher numbers have diminishing returns for variations such as 1:50 to 1:100 having barely any difference.
Positions:
This arranges the Divisions in the image. Each position is defined as such 0:0, 0:1, 0:2, etc. Positions count up from 0. The first Division and second Division share the 0:0 Position.
Using values that exceed the number of Divisions causes that Division to divert from the prompt, such as have 3 Divisions but using a position of 0:10.
The first position effects the overall image, changing this causes minor differences with the overall image.
The 2nd position and onward deal with each Division. If you keep your Position values within the total of sections you have, you wont see any errors.
Changing the first number of a position (the 0 of 0:1 for example) appears to always divert from prompt.
Changing the second number of a position swaps a Division's location relative to the other Division:
0:0,0:0,0:1 will have Character 1 on the left and Character 2 on the right.
0:0,0:1,0:0 will have Character 2 on the left and Character 1 on the right.
Weights: The weight of each section.
End at Step: How many steps the extension runs. Setting to 0 disables the extension
Объясните мне, почему ckpt модели созданные непосредственно в этом колабе, загружаются и я могу их обучать, а модели ckpt с civitai у меня не загружаются и выдают ошибку? В чём их разница и как её нивелировать что бы всё работало? Чего ей не хватает?
Пожалуйста
Пожалуйста

"For hires fix" в поиск по странице набери, предварительно нажав на Show all pages
Я никогда не пользовался колабом, но судя по логу он пытается сконвертировать ckpt в diffusers формат и обсирается, т.к. в конвертируемом файле не хватает некоторых ключей, а также есть непредвиденные ключи. В общем несовместимо. Либо пробуй каким-нибудь другим софтом сконвертировать в diffusers, либо еще как вариант возможно не хватает EMA компонента (?), раз тебе для обучения.
Спасибо за ответ, ты случайно не знаешь какие нибуть из таких софтов? Диффузия это разве одно из расширений прямо как ckpt?
> какие нибуть из таких софтов
https://github.com/kohya-ss/sd-scripts/blob/main/tools/convert_diffusers20_original_sd.py
https://github.com/huggingface/diffusers/blob/main/scripts/convert_original_stable_diffusion_to_diffusers.py
https://huggingface.co/spaces/diffusers/sd-to-diffusers
https://github.com/Sunbread/Ckpt2Diff
> Диффузия это разве одно из расширений прямо как ckpt?
Да, это другой формат диффузионных моделей
И ещё, как пользоваться софтами из гитхаба? Я не вижу там кнопки активации.
Бля, чел, это уже в другой раздел
двачую. тебе сюда
Ну блин, учить как качать репозитории с гитхаба и пользоваться терминалом для запуска питон скриптов - этот тред совсем не для этого имхо. Хочешь помочь анону - помогай, а я сейчас занят
Гугл быстрее поможет

Прикольная штука. Расписывать области то еще удовольствие, но лучше так чем ничего. Криво работает (?), вроде есть две чёткие конкретные области, но по итогу все равно происходит бленд между ними и иногда один промт берет превосходство над другим настолько, что влияния последнего на генерацию вообще не видно. Еще одна неприятная особенность это использование оператора AND - очень сильно бьет по производительности и скорость уменьшается еще сильнее с каждой новой областью и соответствующим AND в промте (по крайней мере на моём корыте). Круто было бы если вместо AND использовалась конструкция [prompt1|prompt2], но судя по всему это два принципиально разных метода и со вторым расширение не смогло бы работать.
Жду перевода через месяц.




Да какого перевода. Младенец с этой дичью справится.
Пикрел 2 - три горизонатльные области. Пикрел 3 - три вертикальные. Пикрел 4 - да хоть в шахматном порядке, на что фантазии хватит.
Потом в промте просто пишешь:
промт для обл. 1 AND промт для обл. 2 AND (...) AND промт для обл. N
Когда 30-цфг лахта уже успокоится?
Я хуй знает, опять сегодня этот додик накинул, я думаю "а давай попробую", разделил на области ген, поставил кфг 30 и естественно получил выжженное мыло. О какой "сверхдетализации" он говорит? Больной какой-то. Думает что кфг это волшебная палочка которая позволяет модели выдавать нечто сверх того что она умеет. Игнорируем.
Шизофреники, цфг фикс юзаем и не ноем
> Шизофреник
Погоняло твоё.
> цфг фикс юзаем и не ноем
Я его крутил и так, и сяк, ставил кфг 30 мимик 7, кфг 15 мимик 7, крутил персентили 99-100, констант, линеар даун, но так и не понял одного: нахуя мне всё это? У меня в стоке и так всё работает прекрасно.
К слову форс кфг 30 появился еще до релиза расширения, а без него бёрнинга избежать невозможно. Твои оправдания?
>а без него бёрнинга избежать невозможно
Возможно вполне, но только ты не знаешь как.
>нахуя мне всё это?
Ну тебе незачем. Зачем есть котлетки, когда есть пюрешка?
> Возможно вполне, но только ты не знаешь как.
Рассказывай.
> Ну тебе незачем. Зачем есть котлетки, когда есть пюрешка?
Объясни по-человечески, мы не в вайфутреде.
Когда лору на идеальные руки доделает




Тот агрессивный чухан хоть и пишет хуйню, но высокий CFG можно использовать как костыль для борьбы с говняком на первом шаге семплинга. Я в своём скрипте хайрез фикса этот костыль использую. Первые два пика - стоковый хайрезфикс, остальные два - с бустом CFG до 25. Семплер Euler a и апскейлер Anime6B. Без костыля семплер и мыльный апскейлер все детали сжирают, а с ним их даже слишком много становится. Но 30+ это уже реально много, тогда надо другие костыли использовать чтоб уже бороться с избыточной детализацией на первом шаге - UNET не любит такое на входе.
> Я в своём скрипте хайрез фикса
Бля, молю, если будет время, разберись почему поломались сиды. Просто я на своем корыте не могу позволить бесконечно генерировать хайрезы, это очень долго. Я делаю батчи из мелких пикч и апскейлю только интересные мне. Но к сожалению с твоим скриптом я так делать больше не могу.
За информацию спасибо.




> разберись
Я уже пофиксил сиды и перепилил немного скрипт, на гитхабе новая версия.
Вот ещё примеры оригинала и после апскейла с умеренным бустом. С костылём CFG можно иметь много деталей и при этом сохранять композицию - руки и поза вообще без изменений.
Можешь написать, как править скрипты? Интересно в этом поковыряться, но не знаю где и с чего начать
> уже пофиксил
Не знал, красава! поцеловал
Да, с костылем мне нравится больше.
Прикольной была бы фича не просто менять кфг на первом шаге, а уменьшать линейно или как-нибудь еще с кастомного значения в скрипте до значения из автоматика в течении N шагов. Не знаю зачем и что это даст, просто мысля прилетела
> уменьшать линейно
Пробовал, кроме засветов нихуя не даёт. Самые большие изменения в композиции происходят на первом шаге, потому что там отдельная формула для инициализации семплинга и предполагается что на вход придёт рандомный шум, а не готовая пикча. Поэтому достаточно первый шаг прожарить высоким CFG, а дальше вернуть как было. Повышение яркости минимальное, зато нет мыла.
> с чего начать
С изучения питона и вычитывания кода автоматика.


Не уверен, что сюда вопрос, может в каких-то настройках SD других покопаться, но проблема возникла на обученной мной Lora-сетке.
Вблизи ебало норм, вдали ехидная хуйня.
Пробовал face restoration крутить - особо эффекта нет.
Вблизи ебало норм, вдали ехидная хуйня.
Пробовал face restoration крутить - особо эффекта нет.
на 512 всегда так, апскейли
Что за гитхаб? Я опять все пропустил
Найс, спасибо

>Euler a
Какой смысл сравнивать на говняном семплере?
У тебя справа пики точно такие же выжженные. Если тащишь сравнения, то изменяй только что-то одно, в данном случае у тебя явно скрипт что-то делает по другому окромя CFG на первом семпле чего блять? апскейла? генерации?. Деталей скрипт добавляет не больше чем обычный латентный ресайз, да и картинке пизда точно так же наступает, если не сильнее. Было бы охуенно если бы ты запили не черрипикнутые тесты, тем самым опровергнув или подтвердив мой тезис - заебись и уважение.
>Какой смысл сравнивать на говняном семплере?
извинись
Свою табличку инфоцыганскую можешь не приносить.
> >Euler a
> Какой смысл сравнивать на говняном семплере?
Не понял. С каких пор? Крутой анцестральный сэмплер.
Он на DDIM сидит, не обращай внимания на пропуки.
Напишите плес за сколько у вас в среднем генерит 768x768 и какая у вас карточка.
С каких пор мыло стало признаком крутости?
Сейчас бы сидеть на DDIM, когда есть DPM++ 2M Karras..
>мыло
Таблетки
Где ты там мыло увидел? 15 шагов и нет никакого мыла, не неси чепухи. Эулер А раньше стоял по дефолту в автоматике и никто никогда не жаловался. Выкатили караси и резко стал мылом, ну да.



> Какой смысл сравнивать на говняном семплере?
Потому что на любом другом семплере ванильный хайрезфикс не может сохранить композицию.
> в данном случае у тебя явно скрипт что-то делает по другому окромя CFG
Естественно, но семплер там всё так же Euler a был.
> обычный латентный ресайз
> пизда точно так же наступает
Чел... Пикрилейтед DPM++ 2M Karras и latent-апскейл. Сам догадаешь на каком пике ванильный хайрезфикс, а на каком нет? Даже позу не может сохранить, а ведь это квадрат, с ванильным только и остаётся черрипикать где он не запорол пикчу.
Это охрененная вещь, господа. Пока не пробовал, с упоением читаю сорцы и облизываюсь. Если оно правда работает хотя бы примерно так, как заявлено, то:
а) Несколько персонажей в кадре - больше не проблема.
б) Два лица друг на друге и руки из жопы вместе с прочими нарушениями когерентности - тоже больше не проблема: face в негативы на нижнюю половину, knees - на верхнюю, и вперёд.
в) Есть шанс более точно задавать фигуру. Длинные ноги, короткие ноги и всё такое прочее. То есть нормальная генерация 512х1024 даже на каком-нибудь AnalogDiffusion, который для этого не предназначен, или там на AnythingV3, да хоть на тряпочке в полосочку.
Делись, на чём обучал, какая модель, какой датасет...
На каком деноизе все происходит в обоих случаях?

Ну интересно миксует, не как MBW, картинка всегда перенасыщенная цветами еще получается
>Естественно
Так получается проблема разных параметров всё же есть.
>Сам догадаешь на каком пике ванильный хайрезфикс, а на каком нет?
Мне не нужны догадки, ты принес сравнения, но так и не избавился от того, что у тебя в твоем апскейлере наворочено хуйни, вместо одного единственного первого семпла на CFG 30. Ты сравниваешь жопу с хуем.
> CFG 30
Ты тот шиз? Зря вообще стал тебе отвечать, извини.
Нет, ты обознался. Ты же сам писал про то что используешь большой CFG на первом семпле.
почему лоры скачанные с цивитал не работают? литеррали не делают ничего в вебуи показываются, но при генерации не прогружаются

Продублирую свой пост из NAI-треда.
Попробовал провести один тест по датасетам и гиперам сегодня. В частности, я хотел выяснить, насколько сильно влияют на итоговый результат обучения такие вещи как:
1. Сторонние элементы окружения на изображениях в датасете - такие, как залезающие в кадр другие персонажи, бекграунд, и иероглифы
2. Наличие в датасете неверно проставленных тегов
В первую очередь мне было интересно, насколько это влияет на фоны, так как у меня было ощущение, что мои старые гиперы делали фоны на орандже более примитивными.
У меня был датасет на пикрелейтед слева. Как видно, там есть фоны и иногда проскакивают другие персонажи в кадре. Кроме того, я не редактировал теги, которые стянул с буры, так что в тегах присутствовали указания на других персонажей, элементы окружения, а, так же, на обрезанные части тела персонажа - например, для получения квадратных изображений, мне в датасете несколько пришлось обрезать юбку и обувь, но информация о них осталась в тегах.
Я решил немного поправить этот датасет, поэтому выпилил все вышеупомянутые вещи с кадра и проревьювил теги, чтобы в тегах присутствовало только то, что по итогу осталось на кадрах в датасете. Результат можно увидеть на правой части пика.
Для эксперимента, я обучил два гипера с одинаковыми параметрами по этим двум датасетам и сделал гриды, где можно сравнить ванильный орандж и оба гипера. Оба гипера применялись с силой 0.7
Сейчас я собираюсь скинуть вам в тред 5 гридов из своих 17 и приложить свой вывод вместе с последним гридом. Все подряд гриды кидать не буду, иначе это будет уже на вайп похоже. Да и смысла всё подряд кидать не вижу.
Попробовал провести один тест по датасетам и гиперам сегодня. В частности, я хотел выяснить, насколько сильно влияют на итоговый результат обучения такие вещи как:
1. Сторонние элементы окружения на изображениях в датасете - такие, как залезающие в кадр другие персонажи, бекграунд, и иероглифы
2. Наличие в датасете неверно проставленных тегов
В первую очередь мне было интересно, насколько это влияет на фоны, так как у меня было ощущение, что мои старые гиперы делали фоны на орандже более примитивными.
У меня был датасет на пикрелейтед слева. Как видно, там есть фоны и иногда проскакивают другие персонажи в кадре. Кроме того, я не редактировал теги, которые стянул с буры, так что в тегах присутствовали указания на других персонажей, элементы окружения, а, так же, на обрезанные части тела персонажа - например, для получения квадратных изображений, мне в датасете несколько пришлось обрезать юбку и обувь, но информация о них осталась в тегах.
Я решил немного поправить этот датасет, поэтому выпилил все вышеупомянутые вещи с кадра и проревьювил теги, чтобы в тегах присутствовало только то, что по итогу осталось на кадрах в датасете. Результат можно увидеть на правой части пика.
Для эксперимента, я обучил два гипера с одинаковыми параметрами по этим двум датасетам и сделал гриды, где можно сравнить ванильный орандж и оба гипера. Оба гипера применялись с силой 0.7
Сейчас я собираюсь скинуть вам в тред 5 гридов из своих 17 и приложить свой вывод вместе с последним гридом. Все подряд гриды кидать не буду, иначе это будет уже на вайп похоже. Да и смысла всё подряд кидать не вижу.





5/5
---
По правде говоря, эксперимент вышел не совсем чистый, поскольку:
1. Гиперы обучались на разных версиях автоматика. Не знаю, накручивали ли они что-то с процессом обучения гиперов в процессе разработки
2. В новом датасете присутствует одна новая картинка, но это составляет 1/30 часть датасета, так что, вероятно, можно списать на погрешность
Теперь мой итог:
Кривые теги и наличие бекграунда в датасете не влияет на результат обучения. Спасибо за внимание.
А если серьёзно, то это, вероятно, может быть связано с тем, что значительная часть картинок в моём датасете изначально имела либо белый, либо какой-то монотонный бекграунд. Так что я не уверен, что по такому одиночному эксперименту можно делать какие-то далеко идущие выводы.
В любом случае, я не могу на глаз определить каких-либо значительных различий в стилистике между вторым и третьим столбцом, впрочем, гриды у вас в наличии, так что вы, возможно, сделаете другие выводы.
>Кривые теги и наличие бекграунда в датасете не влияет на результат обучения.
Так и есть. Но вот что реально срет при обучении - альфа каналы на пнгшках.
Шейдинг же изменился, с датасетом из белых фонов на глаз кажется больше пикч получается в рисовке модели, но как-то слишком даже много тени на ней стало периодически. Ну и символ пролез, хз короче, если есть время и желание, почему бы не сделать чуть лучше будущий результат тренировки.
Вроде было обсуждение в прошлых тредах насчёт лишних символов и подписей от художников, естественно они начинают пролезать в генерациях, по крайней мере с лорой. А вот по бекграундам я так и не понял, с лорой же вроде наоборот белый бекграунд плохо, были мнения что для лоры лучше собирать с разными бекграундами датасеты, но без лишних персов.
Ты бы хоть шаги и сэмплер уточнил...
20 дефолт шагов, семплеры дефолтные эйлер а и 2м каррас.
примерно 7,5 сек чуть ниже 3ит в сек на 3060

Как подгрузить лору на колаб анона?
Если оно протэгано как "симпл бэкраунд" в датасете - то нормально должно быть.
В промптах потом либо определяешь бэк позитивом, либо добавляешь в негативы, и нормально становится.
В некоторых особо убитых случаях может потребоваться докинуть скобочек.
Вот с позами дело куда хуже обстоит, ибо они не всегда так просто фиксируются.
Вопрос знатокам. Если я хочу натренить лору сразу на 4-5 персонажа, то лучше скармливать фотки, где они соло, или можно(нужно) фотки, где эти персы вместе? И сколько оптимально для каждого перса фоток?
Помню вроде кто-то тут просил челенж на тренинг. Так вот, сделай норм крылья из спины с видом сзади, а то ИИ не понимает, как крылья должны выходить из спины.
Помню вроде кто-то тут просил челенж на тренинг. Так вот, сделай норм крылья из спины с видом сзади, а то ИИ не понимает, как крылья должны выходить из спины.
> Вопрос знатокам. Если я хочу натренить лору сразу на 4-5 персонажа, то лучше скармливать фотки, где они соло, или можно(нужно) фотки, где эти персы вместе?
Ты можешь разделить по концептам, одна папка 1 перс, вторая папка 2 перс, третья папка где они вместе.
>И сколько оптимально для каждого перса фоток?
Сколько хочешь, но чем больше без перегибов и разнообразнее тем более гибкой будет лора.
Я заметил, что если несколько лор подключаешь, натрененных на разных персов, то хуита получается. Нужно видимо в одной лоре тренить весь зоопарк, ну либо по отдельности подключать сети.
1. инъекция лоры через автоматика и через плагин дает разные результаты, можно комбинировать
2. используй веса, нередко для жирной лоры хватает веса 0.05 для применения
3. пять оттюненых по весам лор вполне сейф
https://github.com/Mikubill/sd-webui-controlnet
сделоли плогенс для контролнета
сделоли плогенс для контролнета
Там wd 1.5beta вышла. Никто не пробовал?
https://huggingface.co/waifu-diffusion/wd-1-5-beta
https://huggingface.co/waifu-diffusion/wd-1-5-beta
> IMPORTANT: this is a BETA MODEL! It is not done!
> Никто не пробовал?
А нахуя?
Хуя как быстро! Сейчас будем обкатывать.


Ёбаный насос. Начну с нормала и походу им же и закончу

upd.
Модели прунятся тулкитом если переименовать расширение в .safetensors/.ckpt/.pt
Сейчас проверю влияет ли это на функциональность


Не, к сожалению пока что через тулкит нельзя прунить модели контролнет. Очень много нужных слоев тулкит не знает и прунит их как мусор, соответственно модель ломается.
нихуя нипанятна как пользоваться




Сасно конечно, 1060 6гб, полёт нормальный. Спасибо что принёс в тред.

Ну интересный новый тул, как ещё им можно пользоваться только пока не понятно, ну кроме вот такого
А у тебя все препроцессоры работают? У меня черные пикчи mlsd и openpose выдают рядом с основной
А у тебя все препроцессоры работают? У меня черные пикчи mlsd и openpose выдают рядом с основной
Щас буду качать всё и тестить. Поддержки normal кстати пока что в расширении нет, может быть еще чего-то.





А можно эти позы напрямую с рига маникена снимать?

Скринишь и пихаешь в гуй, в чем проблема
Так то нет проблем, но было бы круто без картинок
А какие настройки? Гит пульнул, всё равно не работает, коммит тоже интересен, пуллил буквально пару часов назад, пока качал модели, это уже оказалась некроверсия

Непонятно только, чем эта штука от имг2имг отличается.
Оно ж тоже позу сохраняет, если денойз сильно высокий не ставить.
Оно ж тоже позу сохраняет, если денойз сильно высокий не ставить.

Короче дело в том, что со скетчами млсд и опенпоуз не срабатывает, взял цветную пикчу с тян you will never get this pov и вуаля, всё сработало
позинг, чел
На скилл уровня пик 1 уйдёт минимум 2 года.
> Короче дело в том, что со скетчами млсд и опенпоуз не срабатывает
Ну офк, млсд сам по себе скетч рисует, а опенпоуз скорее всего натренирован на позах реальных людей. Если тебе надо по скетчу что-то сгенерировать, вставляй его, а препроцессор оставляй none (не уверен в этом), либо юзай модель control_sd15_scribble.pth

Ну я хз что они конкретно делают, к некоторым в ридми вообще написано что-то типо, просто попробуй и увидишь, вот и копаюсь наугад. Скетч кстати переделывал canny+aom2sfw_canny комбой


Красная линия.
Разве название папок(концептов) на что-то влияет кроме как указания шагов для обучения?
Если нет текстовых файлов с промтами пикч, то название папки идет в концепт



Кал какой, имг2имг с моим обмазом бы идеально справилось.
Ну ты можешь хоть сколько папок в обучение пихнуть. Если укажешь 1_pizda и 1_huy, то будут 50 на 50 браться по разу, если 1_pizda и 2_huy, то хуй будет в два раза больше использоваться при обучении и при этом 66.67% лоры будет занимать обучение хуем.
skill issue
где тут скилл применять? покажи


пикрил выдало интересней, но все равно калово
Зря я короче тряску из-за этого устроил, кал полный.
Простую позу не может съесть, полный кал.
openpose кстати вообще не завёлся
Мы поняли что кал, можно 4 раза не писать.
угадай, что внутри?кал.
Ты мне про скилл так и не пояснил



Ну и дерьмо...
пик3 - имг2имг
Вы нахуй вообще это обсуждаете?
пик3 - имг2имг
Вы нахуй вообще это обсуждаете?
Прости, я не хотел тебя задеть. Сравнивать эту штуку с имг2имг это как хуй с пальцем. Для твоих задач не подходит - ради бога, юзай имг2имг, тебя никто не заставляет.
А мне все нравится. Крутая технология, парни молодцы. Получаю крутые результаты с различными моделями, можно тупо стянуть любую референс позу и без промтоебли сгенерировать персонажа так, как наверное ни одним промтом описать невозможно. И параллельно одеть персонажа и поместить в любую сцену, не ломая при этом анатомию. Может ли так имг2имг? Очень сильно сомневаюсь.
>Для твоих задач не подходит
Для каких оно вообще задач?


openpose тоже работает отлично, прямо охуенчик, позы заебато стягиваются
Да, да, анимеребенок, openpose ведь обучали на 2д шкурах, а не на реальных людях. Съеби в вайфутред, заебал тут какать.

Тебя анимешники в туалете что ли опускали? Чё ты такой злой?
Мне с тобой серьёзней разговаривать? На дваче не принято серьёзно говорить.
> This is guideline to transfer the ControlNet to any other community model in a relatively “correct” way.
> relatively
И нах ты это говно сюда притащил?
> все молча юзают
> говно
> кал
> кал
> кал
> мам ну скажи им
> Чё ты такой злой?
Как кста сделал пик3 имг2имг, можешь фулл пнг инфо скинуть или catbox? Ни разу скетчи не перерисовывал, интересно.
Это каждый умеет, я ничего особенного там от себя не добавлял.
>relatively
Выше же марису сделали на скетче.
> Выше же марису сделали на скетче.
Ну повезло значит. Метод сам по себе костыль. Ожидать чуда не стоит. Даже обычный openpose бывает мажет.
>зажопил инфу по картинке
Ясно.


Хуя, пару часов назад сказал что нормали не работают, а уже оказываются работают.
Кстати. Нашел как прунить controlnet чекпоинты. Всего лишь надо было прочитать ридми не жопой. Есть волшебный скрипт extract_controlnet.py в корневой папке.
Кстати. Нашел как прунить controlnet чекпоинты. Всего лишь надо было прочитать ридми не жопой. Есть волшебный скрипт extract_controlnet.py в корневой папке.
Как мне воспользоваться кодом из гитхаба? Я зарегистрировался, скачал терминал, я в него зашёл вставил ссылку на репозиторий, он загрузился но при этом мне ничего не показывает. Я почитал в описании что нужен питон, я его скачал, но я не могу найти ярлык от него на своём рабочем столе. Что мне делать?
А что ты хочешь сделать?
> Я почитал в описании что нужен питон, я его скачал, но я не могу найти ярлык от него на своём рабочем столе
Ну вообще, если ты ставил вебюи, то пихон у тебя уже установлен

сложно
ладно, похуй
подожду какого-нибдуь гайда на ютубе
А что ставить-то хочешь?
> скачал терминал
git bash?
> не могу найти ярлык
Он ставится как переменная для консоли. Может видел когда-то, как ffmpeg пользуются.
ладно, похуй
подожду какого-нибдуь гайда на ютубе
А что ставить-то хочешь?
> скачал терминал
git bash?
> не могу найти ярлык
Он ставится как переменная для консоли. Может видел когда-то, как ffmpeg пользуются.
Здравствуйте, дело в том что я не могу загрузить модель из civitai в колаб дримбуч для его обучения, при загрузке оно выдаёт конфликт. Как я понял дело в самом файле модели, недавно мне посоветовали конвентировать файл модели в некий диффузор. И мне представили ссылки на эти конвентаторы, одна из хаггинг фейс и другая на гитхабе. Я пробовал на хаггинг фейсе, но ничего не получалось, теперь я думаю попробывать на гитхабе, но как оказалось это слишком сложно. Может есть обходные пути?
> диффузор
safetensors? Насколько я знаю, дримбухт наоборот работает лишь с ckpt.
Попробуй другой колаб. А лучше юзать модель наиболее стандартную, вроде nai для аниме и SD1.5 для фото.
>safetensors
Нет, я скачиваю ckpt версии, ведь их колаб и требует, но он всё равно выдаёт конфликт.
Мне нужна уже обученная модель с civitai, что бы обучить её недостающими компонентами от себя. Стандартные мне не нужно.
Основной колаб с которым я работаю этот (https://colab.research.google.com/github/TheLastBen/fast-stable-diffusion/blob/main/fast-DreamBooth.ipynb) он то и выдаёт ошибку.
Я так же пробовал и этот колаб (https://colab.research.google.com/github/ShivamShrirao/diffusers/blob/main/examples/dreambooth/DreamBooth_Stable_Diffusion.ipynb?au), но там даже со стандартной моделью ничего не выходит
А по этой инструкции с реддита не пробовал?
https://www.reddit.com/r/StableDiffusion/comments/xooavu/how_does_this_script_works_ckpt_to_diffusers/
Модель смогла загрузиться, но я не понимаю куда вставлять картинки?
Если кому надо залил на хаггин все прунькнутые модели controlnet
https://huggingface.co/anon653139/pruned-models/tree/main/ControlNet
https://huggingface.co/anon653139/pruned-models/tree/main/ControlNet
Instance Images. Только Concept Images (Regularization) не трогай, игнорируй.
Я бы помог, но никогда колабом не пользовался. Посмотри на ютубе, полюбому что-то есть пошагово.
https://youtu.be/OxFcIv8Gq8o
Уже обзорчик-инструкцию сняли
Уже обзорчик-инструкцию сняли




Попробовал сделать Юлю из БЛ.
Из супер хуевого дата сета вышло просто идеально, если сравнить с тем, что у меня получалось на гиперсети. Там такая крипота выходила - просто охуеть. Я скорее сюда гомо негров залью, чем вам покажу такое, что у меня там вышло. Острые волосы разлетелись по всей пикче, а вся одежда была в какой-то желтой чешуе.
Короче, пытался встроить еще фоны из игры. Уменьшал скорость обучения, увеличил повторения в два раза, а само количество пикч уменьшил в два раза, в промте поднял значение до (текен:1.2) и выходит лишь вот так, при совмещении тегов персонажа и тега фонов.
Сам дата сет фонов обозначил лишь одним токеном в .txt файлах. Если бы их нормально протегал, скорее всего все остальные локации из самой модели тянулись лишь из Лоры, а мне хотелось бы опционально включать.
Из супер хуевого дата сета вышло просто идеально, если сравнить с тем, что у меня получалось на гиперсети. Там такая крипота выходила - просто охуеть. Я скорее сюда гомо негров залью, чем вам покажу такое, что у меня там вышло. Острые волосы разлетелись по всей пикче, а вся одежда была в какой-то желтой чешуе.
Короче, пытался встроить еще фоны из игры. Уменьшал скорость обучения, увеличил повторения в два раза, а само количество пикч уменьшил в два раза, в промте поднял значение до (текен:1.2) и выходит лишь вот так, при совмещении тегов персонажа и тега фонов.
Сам дата сет фонов обозначил лишь одним токеном в .txt файлах. Если бы их нормально протегал, скорее всего все остальные локации из самой модели тянулись лишь из Лоры, а мне хотелось бы опционально включать.
Красивое
Найс. Можешь поделиться фонами или где их взять? У меня только фоны из ванильной версии
Мимо сделал лору Алисы т тренирую Лену.
Скачал по ссылке из гугла
https://disk.yandex.ru/d/n-F7ed8E3J458E
А в каком смысле ванильная? Разве несколько версий игры было, не считая очень ранних демо-сливов?
Спасибо;3 Я затупил и подумал, что в посте фоны их модов..
>А в каком смысле ванильная?
Базовая игра без модов
download.ubuntu.com
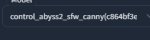
перечислите мне не миксы, а тру трейнд модели анимешные три штуки норм
допустимCounterfeitV25 ориджинал, yohan-diffusion ориджинал
какие еще ориджиналы есть?
допустимCounterfeitV25 ориджинал, yohan-diffusion ориджинал
какие еще ориджиналы есть?
> не миксы
> тру трейнд модели анимешные
NAI.
Прочел гайд по лоре и не нашел ответа на вопрос, если я хочу лору на определенного персонажа, то картинки в датасете должны быть в одном стиле, или можно в разных если персонаж один и тот же?
Baka-Diffusion -- файн-тюн
ACertainModel, ACertainThing -- дримбуз файн-тюн
DH_ClassicAnime, DucHaitenAIart, DucHaitenAnime -- ?
kantoku-artstyle -- ?
Любой вариант сработает, но у датасета с одной рисовкой гены будут с баясом в сторону датасета. Стиль рисовки станет неотъемлиемой частью персонажа. Помогает медленный файн-тюн на network_alpha 1, либо разнообразный датасет.
Господа, а какой инструмент вы используете для замены одного (из двух и более) персонажа на картинке?
Я люблю побаловаться, превращая всякий рисованный арт в реалистичный, путём замены сначала одного персонажа (одним промптом), потом второго (другим промптом), потом задника - всё посредством инпейнта (с рисованой порнухой тоже интересно получается, кстати).
В целом-то всё работает хорошо, правда приходится очень хорошенько поебаться, тщательно накладывая маски, чуть ли не попиксельно. Может существует какой-нибудь более удобный/интересный способ/инструмент? Попробовал detph2mask, работает, конечно, отлично, но конкретно в этой задаче особо погоды не делает (или я ещё не все возможности раскрыл).
Я люблю побаловаться, превращая всякий рисованный арт в реалистичный, путём замены сначала одного персонажа (одним промптом), потом второго (другим промптом), потом задника - всё посредством инпейнта (с рисованой порнухой тоже интересно получается, кстати).
В целом-то всё работает хорошо, правда приходится очень хорошенько поебаться, тщательно накладывая маски, чуть ли не попиксельно. Может существует какой-нибудь более удобный/интересный способ/инструмент? Попробовал detph2mask, работает, конечно, отлично, но конкретно в этой задаче особо погоды не делает (или я ещё не все возможности раскрыл).
Ну най это база просто, она не считается
Спс посмотрю
Инпейтом за 5 секунд. Поставь плагин на фотошоп, если хочешь поудобнее.
Чутка поизучал тему, но пока не ставил. Вроде и прикольная штуковина, но пока не совсем ясно чем это поможет в моей задаче.
depth2mask делает примерно то же самое. Хотя его, вот, тоже потыкал, я думал из-за того что маска разных градаций серого, то и инпейнтить будет тоже в соответствии с яркостью - например, совсем белые не трогать, светло-серые минимально изменять, серые побольше и чёрные полностью (ну, в соответствии с уровнем денойза, конечно же). На деле по ощущениям модель всё равно воспринимает два цвета - то что не трогаем, и то что меняем. Но эт может я ещё не до конца разобрался.
Да, похоже, рисование масок в инпейнте пока единственный способ, особенно с inpaint upload.
А что за плагин на фотошоп имеется ввиду? Слышал, их там много сейчас по теме имеется.



шаболды не срастаются только если делать прокладку между ними ввиде арбуза.
Есть ли толковые гайды по подборе датасета? (Какие теги ставить, в каком лучше порядке, на чем заострять внимание. В чем различие учить нейронку рисовать какуюто вещь и стиль и тд)
задай лучше один конкретный вопрос, или кури шапку и читай тред
Тогда в чем принципиальная разница подбора датасета и его тегирование под стиль или под какой то концепт(Персонаж\предмет и тд)
для датасета персонажа не так важно качество рисунка, как детали персонажа\персонажа.
для стиля-же содержание не важно, тебе нужно выбирать только картинки подходящие по стилю. в тегировании разницы нет - что видишь - то и тегаешь.
Я нуфак, поэтому не знаю, где тут спросить.
А вы можете натренировать нейросетку, например, на стиль артов близард? Что для этого нужно? Чому у вас всё очень похоже, а в аниме могут быть разные стили?
А вы можете натренировать нейросетку, например, на стиль артов близард? Что для этого нужно? Чому у вас всё очень похоже, а в аниме могут быть разные стили?
да. датасет. говнари анимешники срут одинаковым. незнаю
>на стиль артов близард?
ez
>Что для этого нужно?
сотка-тыщенка картинок
>а в аниме могут быть разные стили?
нет, это же для аутистов придумано
> можете натренировать нейросетку, например, на стиль артов близард?
Да.
> Чому у вас всё очень похоже
Тред полностью захвачен анимедаунами, они дрочат вприсядку друг другу и игнорят другие стилистики, отчего желание что-то делать и уж тем более выкладывать полностью отсутствует. Ищи в других местах, а лучше потыкайся по скриптам, разберись как оно работает и делай свое, это возможно.
Пробовал. Говно.
подрывом 3дмразей удовлетворён, съебите в ИРЛ, чмохи

> #Ручной рисунок в стиле AI
лол
> Чому у вас всё очень похоже, а в аниме могут быть разные стили?
Именно здесь так, потому что тестируем персонажей в основном. Стиль берется от базовой модели по большей части. Если в дата-сете были аниме скрины, а при генерации работает базовый усредненный стиль или стиль "реализма" (по сути 3d артов из блендера обведенных), то значит все, обкатали, остальное наложить уже по вкусу может кто-то другой.
> Что для этого нужно?
Если рассматривать Лору, то 6гб vram, дата-сет, хотя бы пич 100, часа два и еще неделю на игру с перебором настроек обучения.
лол
> Чому у вас всё очень похоже, а в аниме могут быть разные стили?
Именно здесь так, потому что тестируем персонажей в основном. Стиль берется от базовой модели по большей части. Если в дата-сете были аниме скрины, а при генерации работает базовый усредненный стиль или стиль "реализма" (по сути 3d артов из блендера обведенных), то значит все, обкатали, остальное наложить уже по вкусу может кто-то другой.
> Что для этого нужно?
Если рассматривать Лору, то 6гб vram, дата-сет, хотя бы пич 100, часа два и еще неделю на игру с перебором настроек обучения.
Купил наконец-то 4090. Лучше тренить на дримбусе или Лоры с хайрез картинками?
Стиль тренировать можно на чем угодно. Не обязательно с аниме.
Недавно вон комиксовую лору запилили.
Я лично делал два стиля с 3д-рендерами.
И 3д рендеры на "аниме-модели" прижились вполне неплохо - тренил на Any4.5.
Так что бери как можно больше артов, прогоняй их через таггер, и запускай в тренировку. Только учти, что если ты тренируешь именно стиль - то он у картинок должен быть постоянным. Никаких набросков, никаких ЧБ иллюстраций, никаких ранних или "ученических" работ - иначе оно повлияет на результат.
Если комп не тянет - в шапке есть ссылки на тренировку в гугле. Оно даже удобнее.
https://civitai.com/models/9357
А пиздабол говорил что масюню выкладывать не будет
А пиздабол говорил что масюню выкладывать не будет



Последние столбцы на данных гридах - так выглядит переобученная лора? Персонаж выглядит хорошо, но фоны становятся примитивными, если сравнивать с гипером, обученным на аналогичном датасете.
Только начал разбираться с лорами, поэтому, вероятно, что-то не то указал в параметрах, поскольку данная лора у меня обучалась дольше гипера по итогу.
Или же это подтверждение гипотезы, что лора, в отличие от гиперов, плохо обучаются на белых фонах? Датасет на пике >> справа.
Только начал разбираться с лорами, поэтому, вероятно, что-то не то указал в параметрах, поскольку данная лора у меня обучалась дольше гипера по итогу.
Или же это подтверждение гипотезы, что лора, в отличие от гиперов, плохо обучаются на белых фонах? Датасет на пике >> справа.
Поздравляю, анон. Торч обновил уже?
У меня после проведения манипуляций по этой инструкции скорость генерации на 4090 x2 начала делать, если сравнивать с либами, поставляемыми по дефолту.
>500 эпох
Ебать, а сколько повторений на концепт было и сколько шагов в итоге вышло?
>max token length = 75
А у тебя там все токены влезли?
> так выглядит переобученная лора?
Пробабли, попробуй ее переодеть и поменять там цвет волос например или че-нить еще
Батч сайз можешь крутить насколько врам позволит
У тебя лернин рейт низковат наверное, дохуища эпох, что в итоге дохуя по времени занимает, и грид по эпохам не то что б информативен сильно
Ты с ума сошёл? 500 эпох для лоры, охуеть...
Она у тебя скорее всего с 10-15 уже ничем от этих не отличается. Сколько повторений на папке делал?

Решил попробовать Лору потренить через скрипт, делал всё по гайду, в итоге утечка памяти что ли происходит (32 Гб оперативы и 3050 с 8 Гб) и выдаёт пикрил. Было у кого-нибудь такое? В чём я накосячил?
Ну там же написано. Увеличь файл подкачки. Автоматом его поставь или from-to.
У меня на 16 гигах своп до 60-65 разрастается во время трени. У тебя наверн в 30-40 влезет.
Спасибо, поставил 64 Гб, помогло.
Не думал что он так оперативу ест
Пытался делать Ливси, но он ка-то не получился. Хотя на тех же настройках натренировал лору по кукле Мику.
Попробую, а на чем ещё можно тренить с любым разрешением кроме Лоры?
Благодарю.
да я сам каломешник такто
Я не он, но не похуй ли куда лить?
Сет маленький скорее всего.
Такой специфичный персонаж (т.е. сильно отличающийся от того, что в самой модели лежит) должен большого датасета потребовать. Чтоб нейронка поняла, что у него вообще где.
И на простых повторениях картинок тут выехать не получится.
Плюс тэги. Эта его фирменная улыбка прям должна тэгаться, чтоб АИ понял, что это такое вообще. И нужны пикчи без нее, чтоб сравнивать было с чем.
Ну, это как я концепцию тренировки понимаю.


> Ебать, а сколько повторений на концепт было и сколько шагов в итоге вышло?
Один концепт, одно повторение, всего 30 картинок x 500 эпох = 15к шагов
> А у тебя там все токены влезли?
Может быть не влезли для пары картинок - там тегов, в основном, не много, но было несколько и таких, где мог и не влезть в лимит по токенам. Потом перепроверю.
> Пробабли, попробуй ее переодеть и поменять там цвет волос например или че-нить еще
> У тебя лернин рейт низковат наверное, дохуища эпох, что в итоге дохуя по времени занимает, и грид по эпохам не то что б информативен сильно
Спасибо за советы, попробую позднее и буду тыкаться дальше.
> Батч сайз можешь крутить насколько врам позволит
Ага, 15 картинок сразу в VRAM влезает, попробую дальше так тренить.
> Она у тебя скорее всего с 10-15 уже ничем от этих не отличается. Сколько повторений на папке делал?
Один повтор. Я думал, если концепт один, то количество повторов без разницы, просто в гайде увидел только цифры 1 и 2 на числе повторов. Это не так, выходит? Хотя, теперь вижу, что, в качестве примера хорошего датасета, используются 10 и 20 повторов, а не 1 и 2.
Есть и такой признак, но обычно начинает страдать стиль персонажа, тут возможно лр низкий и потому так проявляется, а количество шагов уж точно огромно.
> лора, в отличие от гиперов, плохо обучаются на белых фонах
Нет, если в тегах прописано "симпл бекграунд" и подобное то все норм, хуже если в датасете фоны все с содержимым но похожие по стилистике. Но, обычно, если правильно подобран лр и время обучения даже так проблем нет.
Попробуй в промт добавить "дитейлед бекграунд" и в негативы симпл бекграунд, что получится.
Эпох у тебя действительно огромное количество, с точки зрения обучения важно только количество шагов а эпохи лишь виртуальное деление когда сохранять (50 эпох с 10 повторениями = 500 эпох с одним), но чем их меньше тем меньше пауз и быстрее обучается.
Господа лорадрочеры технознатоки, поясните текущее положение по лру и длине обучения. Какие оптимальные значения, их корреляция между собой и с другими параметрами? Кто-нибудь за последние 3 треда что исследовал или каждый делает по-своему и довольно урчит? Делитесь своими настройками

> Это не так, выходит?
Вот этот анон годно расписал
> Эпох у тебя действительно огромное количество, с точки зрения обучения важно только количество шагов а эпохи лишь виртуальное деление когда сохранять (50 эпох с 10 повторениями = 500 эпох с одним), но чем их меньше тем меньше пауз и быстрее обучается.
Я лично целюсь в 150-200 шагов на эпоху, тоесть 30-50 пикч с 4-6+ повторениями, если один концепт, или делю уже дальше соответствующим образом несколько, чтобы влезть в 200. Получается свитспот в основном 8-12 эпоха, то есть около 2000 шагов, дальше слишком маленькие отличия, на гриде отлично видно, v1, v2 - это cosine и linear с 16/1 batch 2, 2e-4, платье вообще не уловило, v3 - cosine 32/16. Кстати анон не упомянул кое что важное про батч сайз, с ним нужно увеличивать лернинг рейт в равное количество раз батч сайзу, такие советы были в прошлых тредах, у меня лично с батч сайзом больше двух так ничего дельного и не вышло, по крайней мере со стилями.
Из моих последних наблюдений на 0.4.0:
Стиль получился только с 128/128 дим/альфа, персонажи хоть 16/1 работают, если не очень сложные, но платье вот не получилось, пришлось завышать.
Алсо так и не решился что лучше linear или cosine, вроде разницы почти нету. А вот constant вообще говно какое-то тренит, если без вармапа.
О, наконец разъяснение про альфу, а то "все что кроме 1 дает поломанные значения". Ты не пробовал отдельно сравнивать высокий лр с альфой и просто большую альфу, ведь она на скорость обучения влияет? С высокой альфой вообще получались наиболее интересные модели, но иногда так обучалось достаточно тяжело и давало стабильно поломанный фон или частую хтонь.
> про батч сайз, с ним нужно увеличивать лернинг рейт в равное количество раз батч сайзу, такие советы были в прошлых тредах
А кроме советов никто не проверял?
> Ты не пробовал отдельно сравнивать высокий лр с альфой и просто большую альфу
Пробовал, в прошлом вроде треде есть гриды, 4.5е-4 и низкая альфа с димом и просто 128/128 с 1е-4. Результат в превом случае другой, но не тот который нужен, возможно нужно ещё играться со скоростью обучения
> "все что кроме 1 дает поломанные значения"
Ну это правдиво, с 128/128 у меня получилась лора, которая с не латентным хайрезом иногда выдаёт чёрный канвас на первом шаге, зато стиль на месте.
> А кроме советов никто не проверял?
Где то в прошлых тредах вроде было, мне просто не понравилось так делать, решил сейчас попробовать делать 768 на батче 1, чем 512 на большом батче с какими то странными результатами на выходе, скорее всего я косячил с батчем большим, хотя и следовал советам.
Тогда еще вопросы. На что влияет Gradient Chekpoints и какие настройки скорости лучше(С каких начинать и в какую сторону смещатся?)
> делать 768
А это интересно, модель же тренилась на 512, такой финт сработает?
> 512 на большом батче
Стараюсь тренить на максимально возможном и лр оче большие п осравнению с тем что тут обычно пишут, но в то же время для эксперимента снижал до 1-2 с тем же лр и перетрена в привычном виде не замечал, просто чуть менее качественная модель что не так подхватывает детали и хуже слушается
> Может быть не влезли для пары картинок
У тебя перемешивание тегов включено, я хз как они токенизируются при превышении, но полагаю что таким образом может проебаться какой-нибудь важный тег.
> Ага, 15 картинок сразу в VRAM влезает, попробую дальше так тренить.
Если ты про генерацию, то это другое как говорится. Я на своих 8 гигах могу 16-20 штук 512 сгенерить в батче с медврам правда, хз границы не щупал, а при тренировке батч сайз максимум 3, больше не влезает. Так что подбирай под свой врам.
> Один повтор. Я думал, если концепт один, то количество повторов без разницы
Ну в принципе так и есть, однако шаги считаются как: (количество пикч Х повторы Х количество эпох) / батч сайз. В одной эпохе (количество пикч Х повторы) шагов. 30 шагов на эпоху это оче мало например, а как уже написали, старт эпох замедляет тренировку.
Просто имхо желательно тюнить число эпох так, что бы ты с помощью автозаполнения мог вставить в поле ху плота все N эпох без всякой ебли, 8-15, ну 20 максимум время генерации гридов не бесплатное, и на них бы ты при удачных лернин рейтах, видел бы эпохи с недотреном и перетреном, что бы лучше соориентироваться как дальше тюнить тренировку. Нутыпон наверн что я имею ввиду. Еще кста полезно строить грид по весу лоры/эпохам.
> Кстати анон не упомянул кое что важное про батч сайз
Май бэд как говорится. Алсо помню слышал что увеличение батч сайза это не просто увеличение скорости тренировки, а пикчи в батче как-то аппроксимируются или чет такое хуе-мое, так ли это?


Вроде пофиксел баг когда модели пердят артефактами на еблах и таком прочем на низком разрешении.
> Если ты про генерацию, то это другое как говорится. Я на своих 8 гигах могу 16-20 штук 512 сгенерить в батче с медврам правда, хз границы не щупал, а при тренировке батч сайз максимум 3, больше не влезает. Так что подбирай под свой врам.
Я про обучение, параметр $train_batch_size. С 24 GB VRAM у меня 15 картинок 512x512 влезает, тогда VRAM почти под завязку забит.
Спасибо за советы.
> 24 GB VRAM
А, так ты боярин. Штош, теперь буду знать сколько в 24 влезает.
> Вроде пофиксел баг когда модели пердят артефактами на еблах и таком прочем на низком разрешении.
Рассказывай как
Вроде как обучение идет не на каждой по очереди а сразу на пачке, из нее оно пытается вытащить суть и подогнать веса так чтобы в них попадать, говоря простым языком. В теории должно качество и скорость улучшать, на практике сказать сложно. Проблема подобных исследований в том что за рандомом разница может вовсе не проявиться, ну и обучение с батчем 1 занимает ну совсем неадекватное время вместо нескольких минут.

> А это интересно, модель же тренилась на 512, такой финт сработает?
Ну я только одну лору пока сделал с 768, вроде нормально работает, качество не сказал бы что прямо намного лучше стало, хотя должно было по идее. Восьмая эпоха лучше всего на мой взгляд получилась, датасет стоило бы наверное переделать, перешарп какой-то уже заметен, несколько пикч было таких. Сравнить не с чем, 512 не тренил на этом.
> Май бэд как говорится. Алсо помню слышал что увеличение батч сайза это не просто увеличение скорости тренировки, а пикчи в батче как-то аппроксимируются или чет такое хуе-мое, так ли это?
Такую ссылку тут когда-то видел, видимо самое время это почитать: https://towardsdatascience.com/what-is-gradient-accumulation-in-deep-learning-ec034122cfa
Вот кстати буст из-за большого батч сайза всего то в два раза лично у меня, потому что бутылочное горлышко это до сих пор своп, который забивает и освобождает 30-40 гигов между эпохами, это вообще можно как-то оптимизировать? Другие же методы обучения не требуют столько системной памяти
Ничесе, прямо как из учебника плавное обучение, свитспот а потом пережаривание. С какими параметрами запускал, сколько пикч и повторений на эпоху? Получилось прям хорошо.
> Вот кстати буст из-за большого батч сайза всего то в два раза лично у меня
Если смотреть по эффективной скорости обработки то рост значительный, на малых числах почти линейно, хорошо видно по потреблению. Но из-за долгих моментов запуска каждой итерации там эпоха просчитывается секунд за 10-15 а потом еще 30-40 думает перед началом следующей, поэтому разница между 8 и 14 почти нет, но когда 1-2 это сильно медленнее.
> до сих пор своп
А сильно он мешает там? Обращений к выделенным областям всеравно нет, по идее если на шустром ссд то всего несколько секунд к паузам между эпохами должен добавлять.
> С какими параметрами запускал, сколько пикч и повторений на эпоху?
27х6
train_batch_size: 1
learning_rate: 1e-4
lr_scheduler: linear
resolution: 768,768
clip_skip: 2
network_dim: 128
network_alpha: 128
shuffle_caption: True
max_token_length: 225
keep_tokens: 1
seed: -1
Забыл сменить альфу с димом, не хотел явно на таких тренить, ну и хуй с ним, получилось же
> А сильно он мешает там?
Он пиздец как сильно мешает там. Если с батчем в один на нормальной гпу эпоха тренится примерноенихуя, с батчем в 5 ну приблизительно примерноенихуя/5 то эти выделения и освобождения памяти между эпохами занимают в лучшем случае по минуте с моим ссд, что руинит весь смысл от повышения батч сайза с хорошим гпу, но малым количеством системной памяти не на диске
Попробуй max_data_loader_n_workers снизить, с 8 до 4х эпохи стартуют в пару раз быстрее, импакта на производительность не заметно, гигов на 15-20 меньше памяти выделяет.
АААААААААААААААААА
> каждый делает по-своему и довольно урчит
Именно так
Лично для персонажей у меня это:
- unet_lr 1e-4, text_encoder_lr 5e-5, constant, dim 32, alpha 16. 6-12 повторений при 8-10 эпохах. ACertainty с вае от Anything.
- unet_lr = 3e-4, text_encoder_lr = 1.5e-4, linear, dim 32, alpha 1. Остальное как в первом случае.
Для стиля версия скрипта 3.2 и в нем 1e-4, dim 128
А вот это уже интересно.
> 6-12 повторений при 8-10 эпохах
А пикч сколько?
50-100. От дата сета зависит. Иногда даже повышал до 20 повторов на 50 пикч, ибо концепт был слишком не стандартный, а именно киборг.
Привет, где почитать про кастомные хайрез фиксы?
Если я хочу например разные костюмы персонажа то можно ли просто тренить один концепт с этим всем в перемешку или делать разные концепты? Еще что такое gradient chekpoints и bucket size?
Спасибо, годно. Трудно списать на погрешность когда на значении 8 - общее время тренировки было 25 минут, 4 - 20, 2 - 18. Потребление памяти кстати куда меньше с уменьшением числа, может с одним и в 32 врама не считая собаки системы влезет, если все остальное позакрывать, потом проверю
> один концепт с этим всем в перемешку или делать разные концепты
По моему опыту как-то все равно. Главное чтоб теги стояли, которые описывают одежду одинаково. Удобно разделять, если, например, тебе надо повысить количество повторений при крайне не равным количестве пикч. Например, 100 пикч в красном платье ты ставишь 6 повторов, а при 10 пикчах в белой рубашке и шортах уже 12.
> gradient chekpoints
Какая-то оптимизация для экономии памяти. Мало шарю, если честно. Отвечаю только потому, если никто больше не ответит.
А перемешивание тегов влияет? Если я хочу разную одежду то условно ее ставить в начало списка, а остальные теги мешать или как? Ещё по скорости можно совет, как и по бач сайзу с альфой и димом. Что значит bucket size. (Я натренил пару штук, даже вроде неплохо но лучше изучить как надо)

Перемешивание улучшает редактируемость в будущем при генерации. Ставь уникальный токен в начало, остальное пусть мешает. Поэтому скорее вопрос должен быть, ставить ли разные токены для одной одежки, а для другой - другой? Как по мне токен вообще нихрена не работает как надо.
По идеи ты пишешь xyi332, 1girl, red dress, blonde hair - у тебя срабатывает как ты хотел. А если без xyi332, то лора будто отключается и генерирует совсем другую тянку. Но на деле Лора помнит, как должно выглядеть red dress при blonde hair, помнит стиль пикч, какие глаза были, и по этому у тебя выйдет тоже самое, что с токеном.
Короче, все лей в одну папку, тегируй автоматически как выйдет, пиши уникальный токен в начало, keep_tokens = количеству занимаемых токенов твоим выдуманным токеном. Например, для xyi332 это 5.
> bucket size
Где ты это нашел? Что по умолчанию стоит?


В одном с токеном, в другом с токеном в негативе
> Ещё по скорости можно совет, как и по бач сайзу с альфой и димом
Ну вот это я делал с:
$train_batch_size = 1
$learning_rate = 1e-4
$unet_lr = 1e-4
$text_encoder_lr = 5e-5
$scheduler = "constant"
$network_dim = 32
$network_alpha = 16
8 повторов при 43 пикчах переменного разрешения. То есть не резал на квадраты 512x512 строго, а закинул как есть с буры.


Стоять блять, я получается вообще неправильно текены тогда организовывал? Или тут скрипт сам берет один целый токен? Потому что мои лоры тригерятся на первое тег который по идеи не должно было мешать(У меня там стояло 1)
Ресолюшн степс.

Коя вон че пишет
мимо
Если хочешь персонажа переодевать то закидывай все что есть, так будет лучше. Если хочешь наилучшего воиспроизведения всех деталей конкретного костюма и с ним набирается достаточное количество пикч то можно оставить только их.
> Главное чтоб теги стояли, которые описывают одежду одинаково.
Да, но важно чтобы были не (только) абстрактные однотоккеновые названия, а подробное описание знакомыми модели тегами, результат будет лучше. И при вызове их описывать офк.
> надо повысить количество повторений при крайне не равным количестве пикч
Хз, не рекомендовал бы, чтобы без проблем выдавало один из вариантов костюма достаточно единичных пикч среди сета, выделять в разные количества стоит прежде всего по качеству пикч.

Вы все воры, которым дали инструмент для коллажа и воровства работ художников, вы просто хуёвые люди, ничего не умеющие, ленивые и тупые.
Хуйдожник, да не трясись ты так.
> воровства работ художников
Сегодня лично своровал 15 работ, прогнал и2и с минимальными изменениями и запостил на площадки
> вы просто хуёвые люди
Я лучше тебя и это не обсуждается
>ничего не умеющие
Мы то как раз умеем дохуя всего
>ленивые
Ну тут совсем мимо, да и напомнить как хуйдожники прокрастинируют?
> и тупые
Туда ли ты зашел? Тут весь тред умнее тебя
покормил, мне скучно, моча все равно снесет

Сап технический, как бороться с этой херней? Случается иногда когда меняю модели/ваешки, причем не всегда, 50/50 случаев.
Память кончилась. Своп увеличивай.
Терпи, хуйня. Я тоже художник, но уже прошел стадии отрицания. Иди скорее переучиваться, пока молодой.
Тогда перестань использовать фотошоп и другие фоторедакторы, тварь лицемерная. И комп вообще. Иди покупай мальберт и краски, которыми ты даже пользоваться не умеешь, рисобака.
Тоже запрунил все модельки, видимо код обновили, весят на несколько байт больше и естественно имеют другие хеши. Для чего нужен extract_controlnet_diff.py скрипт случаем не в курсе? Модельки созданные через него весят еще меньше, но выдают уже другие результаты, не уровня погрешности иксформерс. Алсо как их в сейфтензоры переводить лучше?
Все еще остается открытым вопрос по Gradient chekpoints? Как оно влияет? И как влият batch size. Вот с градиентом я могу поставить около 20 на своих 8 гигах но скорость примерно та же самая что и на 3 без него. Что лучше?
Посмотрел резульатт, лучше делать как я и делал. Вообще насколько я понял оно немного по разному работает. Условно когда у тебя батч сайз 1 то оно смотрит на картинку и подстраивает веса нейронов под нее и так далее.
Когда он батч сайз 2 то он делает то же самое, ток сразу смотрит на две картинки.
Есть win11-бояре, у которых нормально получилось pytorch 2.0 установить? Я слишком туп и даже по официальным гайдам максимум что получается - попытки скачать сразу все nightly билды. И чтобы automatic1111 ui нормально его съел.
Нахуй он тебе? Просто попердолиться? Так пердолься.
В наи треде
Перед всеми действиями скачиваешь https://visualstudio.microsoft.com/vs/ в запустившемся исталлере вбираешь библиотеки под c и питон чтобы доставились. Потом качаешь https://developer.nvidia.com/cuda-11-8-0-download-archive все это нужно чтобы собрать xformers.
Далее все по инструкции, при скачивании выбирай последний торч и последний тарчвизуал одинаковых версий-дат, идешь по инструкции и все получается. Можешь лениво скачать старый xformers по гайду
шинда 11 от 10 не то чтобы отличается во всех этих областях


> в запустившемся исталлере вбираешь библиотеки под c и питон чтобы доставились
Буду рад, если кто-нибудь скрин доставит или укажет конкретные пункты в установщике VS, чтобы я мог это в гайд добавить.


В теории вот этого достаточно, под питон ставил ранее и при запуске установщика оно их не показывает в перечне доступных. Нужно чтобы кто-то с чистой системой весь путь прошел и указал на другие возможные косяки, у работяг все и так собирается.

Под питон в VS разве есть какие-то дополнительные либы? Кажется, вместо установки йобы в виде VS можно просто билд-тулзы скачать и всё, или я не прав?
https://download.microsoft.com/download/5/f/7/5f7acaeb-8363-451f-9425-68a90f98b238/visualcppbuildtools_full.exe
> Нужно чтобы кто-то с чистой системой весь путь прошел и указал на другие возможные косяки, у работяг все и так собирается.
Я попробую в виртуалке сегодня-завтра проверить.
https://download.microsoft.com/download/5/f/7/5f7acaeb-8363-451f-9425-68a90f98b238/visualcppbuildtools_full.exe
> Нужно чтобы кто-то с чистой системой весь путь прошел и указал на другие возможные косяки, у работяг все и так собирается.
Я попробую в виртуалке сегодня-завтра проверить.
> можно просто билд-тулзы скачать и всё, или я не прав?
Верно, хорошо что нашел только нужную ссылку, главное чтобы работало.
> Под питон в VS разве есть какие-то дополнительные либы?
Да хуй знает, в свое время там прямо целый пакет был который ставил а не просто отдельный питон, сейчас хз.
Новый мерджероплоген, нихуя нипанятна как работать с моделями, но зато можно подсаживать лоры в модели или мерджить лоры между собой.
https://github.com/hako-mikan/sd-webui-supermerger
https://github.com/hako-mikan/sd-webui-supermerger
>можно подсаживать лоры в модели
Ну вы понимаете наверно какие горизонты это открывает
Нет, не понимаем. Лоры - это в 99% переобученная дрисня, ломающая модель. Для рисования конкретных изображений может и норм, но для универсальных задач - кал. В моделях наоборот борются с запоминанием датасета, а Лоры как раз для запоминания того что им дали.
Въебал лору карины в рандом модель, теперь все телочки это карина. Где твой бог теперь?
Еще больше бесполезных мерджей и миксов?
Ну да. Прикольные уникальные результы получаются.

о прикольно, можно стилистику из модели полностью лоризировать


> тупа один тег girl
Нормальные модели рисуют тянок вообще с одним только негативом. Пикрилейтеды без позитивного промпта.
так суть не в етом
ты не художник, хуйня из под ногтей, чему там учится?
а они тоже копируют чужие работы без разрешения авторов, говно?
А есть какой-то способ быстро закомментить тэг или несколько, чтоб они в запросе не обрабатывались, и на генерацию не влияли?

Если потом его назад вернуть потребуется - надо будет заново печатать.
Мне именно нужно, чтоб он был в строке, но не влиял на генерацию. Для оценки влияния на картинку, например, и чтоб без гемора с гридами.
ну автоматик не умеет в комментирование чанков насколько я знаю

>Если потом его назад вернуть потребуется - надо будет заново печатать.
Юзай копипастовые проги на хоткеях чел.

Подскажите настройки для последней версии скрипти кохи.
Делал лору на одном датасете с одинаковыми растройками. Новый скрипт не впитал прическу..
Делал лору на одном датасете с одинаковыми растройками. Новый скрипт не впитал прическу..
Тысячу добра и помогу настроить ControlNet тому, кто поможет разобраться с этим
> настроить ControlNet
Каждый раз проигрываю.
У меня работает, делай по гайду анона
Смешной скуф, дай соус на него.
Я за 5 минут у себя настроил всё по текстовому гайду на гитхабе.
Итак, я генерю тяночек на AnalogDiffusion (см. https://huggingface.co/wavymulder/Analog-Diffusion , https://huggingface.co/wavymulder/Analog-Diffusion/discussions/18 ) и иногда получаю вот такое. Сразу привыкаем и приучаем к хорошему настройки:
Промпт: high quality extremely detailed shot of 12yo girl in bikini standing on the beach near a river in the forest, close up, portrait, perfect detailed face, perfect anatomy, f22, focus on face, ((outie navel)), thin waist, slim flat belly, closeup, very slim adorable teen girl with detailed face, intricate details
Негатив: ugly, fused fingers, hazy, blur, blurry, distant view, bad anatomy, three legs, three hands, extra leg, extra hand, smashed face, low quality, view from distance, two girls
CFG 9.4, 75 steps, семплер не знаю, и, внимание, разрешение - 512х1024. Без апскейла и хайрезфикса.
Когда я получаю результат как на пикриле, я радуюсь. Но, как ты догадываешься, если бы у меня всё было хорошо, я бы пришёл в соседний тред...
Промпт: high quality extremely detailed shot of 12yo girl in bikini standing on the beach near a river in the forest, close up, portrait, perfect detailed face, perfect anatomy, f22, focus on face, ((outie navel)), thin waist, slim flat belly, closeup, very slim adorable teen girl with detailed face, intricate details
Негатив: ugly, fused fingers, hazy, blur, blurry, distant view, bad anatomy, three legs, three hands, extra leg, extra hand, smashed face, low quality, view from distance, two girls
CFG 9.4, 75 steps, семплер не знаю, и, внимание, разрешение - 512х1024. Без апскейла и хайрезфикса.
Когда я получаю результат как на пикриле, я радуюсь. Но, как ты догадываешься, если бы у меня всё было хорошо, я бы пришёл в соседний тред...
Чурка, ты заебал. Сиди тихо и не отсвечивай.
Двач, шозанафиг, почему не даёт загрузить пикчу???
Больно что в скетче можно сделать тоже самое тремя мазками без всяких OpenPose?
(girl:0) пробовал? Ненуавдруг
Правда может попортить паддинг тэгов, даже если заведётся.
> тремя мазками
> на видео десятки истеричных мазков
Самоподдувный, спок.
у тя промтище не структурирован - точнее он вообще переебан по последовательности и блочно записан без разделителей, то есть иди от большего к меньшему и эффекты с деталями в самую жопу, т.к. сд последовательно добавляет чанки друг к другу, если иное не задано весами
во вторых я не чекал аналогдифужен возможно он соснутый, чекни тензоры
в третьих негативы надо обощать, у тебя они слишком четко обозначены, все с руками и ногами кривыми можно пихнуть в обощающие теги например
вчетвертых 75 степов нахуя
> теги например
бля не скопировалось, кароче чето уровня deformed, distorted, disfigured poorly drawn, bad anatomy, wrong anatomy, extra limb, missing limb, floating limbs, mutated hands and fingers, disconnected limbs, mutation, mutated
общие фразы ну ты понил, сетке поебать же она может тебе не нарисовать three legs, но нарисет заместо них четыре просто и все, т.к. иное не задано, а если указано что не нужны эстра ноги, то сделает тебе эстра сиську
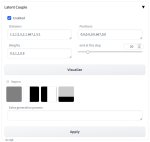
Добра тебе, схоронил. А как переструктурировать промпт?
Хренасе ты телепат! Кажется, реально стало лучше.
>А как переструктурировать промпт?
ну типа такого
(12yo girl:1.3), perfect anatomy, thin waist, slim flat belly, ((outie navel)), perfect detailed face, wearing bikini, standing on the beach near a river in the forest, high quality extremely detailed shot, portrait, perfect detailed face, focus on face, intricate details
Добрый вечер, раньше была установлена самая первая версия лоры, сейчас обновил автоматик, конкретная лора просто не работает. Как я понял, нужно обновить лору, но на гитхабе код полностью изменился с версии 0.1.0, не очень разобрался как установить, текстового гайда по установке на странице тоже нет


Не серчайте, что по одной, анончики. Больно хреново всё работает. Так вот, как с таким бороться? Кажется, это называется "потеря когерентности"?



То есть, чсх, попадается много мастерпись (с пофикшенным промптом ещё больше) типа вот такого:




1. чекаем тензоры модели, возможно они пукнутые, если да - фиксим
2. удаляем лишние чанки, вполне вероятно что триггерится на портрет в конце, потому что на моей модели даёт инлайн шот, я просто поставил в болилимение правильном порядке чанки

Но есть и совершенно типовые мутации! Вот, например, одна голова над другой. Легитимная композиция для нейронки, обученной в том числе и на групповых фото (а-ля для выпускного альбома)
> инлайн шот
Что это? Гугл выдаёт какие-то ружья
картинка в картинке
-
По сравнению со старой версией если стоит альфа 1 то лр нужно поднимать. Если обладаешь кучей врам то можешь поставить батч сайз 12+ и лр юнет в диапазоне 1..5e-3, для текста в 2 раза меньше, планировщик косинус, свитспот в диапазоне от 2к до 3к шагов (число пикччисло их повторенийэпохи).
По сравнению со старой версией если стоит альфа 1 то лр нужно поднимать. Если обладаешь кучей врам то можешь поставить батч сайз 12+ и лр юнет в диапазоне 1..5e-3, для текста в 2 раза меньше, планировщик косинус, свитспот в диапазоне от 2к до 3к шагов (число пикччисло их повторенийэпохи).
Чтоб этого криворукого коху!
На старом уже на 1.7К шагов всн было готово и без ебли с параметрами
Поставь альфу равную диму, тогда будет вести себя точно также как и раньше.

Я улучшил лослес миксер, теперь он считает средние значения тензоров и работает с неограниченным количеством моделей. Можно делать трушные перфект миксы одной командой. Принимаю реквесты как еще можно улучшить, если у кого есть идеи.
Олсо прикручена работа с двумя моделями, чего нельзя было делать в оригинальном лослесе.




Привет! Может кто помоджет с созданием LORA? Я скорее всего неудачные изображения выбрал но все же можно что то сделать?
Накатил по интсрукции ласт торч и иксформери. Теперь по какой то причине я могу выставить butch size хоть 40 (На моих то 8 гигах видеопамяти) и оно суко генерит.
В общем кому интересно мерджить и тестить вот вам скриптец https://github.com/deGENERATIVE-SQUAD/stable-diffusion-losslessmix-v2
Можно, но если это весь сет, то это oche mali set.
Катить будете
А разве катимся не на 1000+ посте?
> средние значения тензоров
Чел, ты всё испортил, у тебя теперь обычный weighted sum...

Пиздос, даже не mean, а среднее арифметическое.
Поделюсь болью по этим лорам...
Понял что батч сайз вообще в единицу-2 надо ставить... Увеличение убивает всю вариативность исходной модели (на anything гоняю) или перестает запускаться, на 3090 уже отваливается полностью на 6+. 4-5 уничтожает умение рисовать всё подряд, начинает пытаться копировать датасет, чтобы ты в промт не забивал.
лр в районе 2е4 юнет 4е5 все остальные сочетания от 1 до 10 тех же порядков хренью оказалось
альфа 128 дим 256 самое то, ниже хрень и убивает вариативность, как и батч сайз.
В итоге разделяю унет и ТЕ и когда подключаю лору и те в нули сгоняю...
Только тогда можно хоть какой-то результат получить, например, очень неблизкое не всратое подобие того персонажа или стиля, который в датасете был, и возможность крутить его в разные позы ситуации и переодевать туда сюда с промта или скетча.
Из плюсов - несколько надроченых лор на разные датасеты сильно увеличивают разнообразие того, что можно рисовать с лорами. Буквально вьебал десяток лор любимых рисовак, подрубил этот десяток лор и оно пердя и крякая, через раз отваливаясь по врам, но смогло в более-менее вариативность поз, причесонов и т.п. Но опять же надо ролить к-ты для разных лор подключеных...
Лучше конечно, чем гиперсетки всякие, но как-то все равно не очень... До сих пор надо роллить нужный результат часами, и плюс еще две крутилки на лору прибавилось, которые тоже ролить надо.
А тут блять уже какие-то контролсеты придумывают и вовсю форсят.
Как за этим всем угнаться, за 5 месяца нейросеток уже ощутил себя старым и уставшим, только с одной хуйней освоишься, они новую выдумывают.
Понял что батч сайз вообще в единицу-2 надо ставить... Увеличение убивает всю вариативность исходной модели (на anything гоняю) или перестает запускаться, на 3090 уже отваливается полностью на 6+. 4-5 уничтожает умение рисовать всё подряд, начинает пытаться копировать датасет, чтобы ты в промт не забивал.
лр в районе 2е4 юнет 4е5 все остальные сочетания от 1 до 10 тех же порядков хренью оказалось
альфа 128 дим 256 самое то, ниже хрень и убивает вариативность, как и батч сайз.
В итоге разделяю унет и ТЕ и когда подключаю лору и те в нули сгоняю...
Только тогда можно хоть какой-то результат получить, например, очень неблизкое не всратое подобие того персонажа или стиля, который в датасете был, и возможность крутить его в разные позы ситуации и переодевать туда сюда с промта или скетча.
Из плюсов - несколько надроченых лор на разные датасеты сильно увеличивают разнообразие того, что можно рисовать с лорами. Буквально вьебал десяток лор любимых рисовак, подрубил этот десяток лор и оно пердя и крякая, через раз отваливаясь по врам, но смогло в более-менее вариативность поз, причесонов и т.п. Но опять же надо ролить к-ты для разных лор подключеных...
Лучше конечно, чем гиперсетки всякие, но как-то все равно не очень... До сих пор надо роллить нужный результат часами, и плюс еще две крутилки на лору прибавилось, которые тоже ролить надо.
А тут блять уже какие-то контролсеты придумывают и вовсю форсят.
Как за этим всем угнаться, за 5 месяца нейросеток уже ощутил себя старым и уставшим, только с одной хуйней освоишься, они новую выдумывают.
> вовсю форсят
Это скорее всего один шиз по доске бегает и срёт. Ни одной нормальной генерации я так и не увидел с ControlNet, только "смотрите я могу перерисовать пикчу в другом стиле".
Расслабься, просто сейчас на гитхабе специальная олимпиада у желающих оставить след в истории - каждая первая пердоля выдумывает всё новые костыли в надежде примазаться к автоматику и высрать такой, которым будет пользоваться кто-то ещё помимо автора и обсуждать хотя бы в паре тредиков на реддите.
Практической пользы у большинства из них нет.

дайти ссылОчку на custom hires fix
Как тренировать лору на webui? Появился ли уже неизъебистый способ?
спасибо
>у тебя теперь обычный weighted sum
с двумя моделями да (надо бы доп версию сделать где енкодер берется из A модели), с тремя и более уже нет:
вейтед: ((1+2):2 + 3):2 = 2.25
lsm: (1+2+3):3=2
Ну сделаю с мином, вообще похую
Спасибо
>даже не mean, а среднее арифметическое.
Погоди-ка, а ты какой именно мин хочешь получить заместо арифметического?
Ладно, сделаю и с геометрической и с гармонической.
>надо бы доп версию сделать где енкодер берется из A модели
А бля --alpha аргумент же есть, похуй тогда



>у тебя теперь обычный weighted sum...
Ну так вот насчет WS, если прописать --alpha --beta аргументы, то получится WS без измененного TE от базовой A модели например или миксить енкодер как угодно, значит LSM более гибкий чем базовый мерджер даже для двух моделей.
На пике 1 WS для двух моделей, пик 2 mbw alpha 0, пик 3 lsm alpha 0.
Ох лол. Внезапно вспомнил, как фапа на нее году так в 2009. Первый раз за 14 лет увидел с ней пикчу.
Я думаю выйдет. Пикч достаточно с ней автор нарисовал, а главное что фулл боди и в стиле концепт-арта.
Прямо сейчас заняться не могу, но обязательно попробую. Если все сам хочешь, то нужно делать так в идеале, чтобы на пикче была лишь одна тян на белом фоне. Без собак, медведей, подписей автора. Старайся это минимизировать по возможности и своему скилу в фотошопе. Больше пикч - лучше запомнит Лора стиль. Можно даже другие работы автора добавить лишь для этого.
Ну, значит никак,похоже.
Жаль, могли бы придумать чего такого.
Насколько я помню, все равно влияет на генерацию.
Лора с нулевой силой не влияет, а вот тэги - влияют.
>Ну, значит никак,похоже.
Можно скрипт написать с кастомным обозначением комментирования чанков и подгрузить его в скрипты.
>Насколько я помню, все равно влияет на генерацию.
Именно так, 0 и минусовые значения влияют.
>Можно скрипт написать с кастомным обозначением комментирования чанков и подгрузить его в скрипты.
Всё моё знание о "написании скриптов" ограничивается Папирусом для Скайрима.
Питоны и всякое такое-прочее для меня - темный лес.
> батч сайз вообще в единицу-2 надо ставить... Увеличение убивает всю вариативность исходной модели
Покажи свой датасет, какие в нем теги и разъясни что ты понимаешь под вариативностью.
Все модельки с корректными настройками и большим батч сайзом прекрасно переодеваются, стают в позы, меняют прическу, выражения, стиль также подхватывает. Если у тебя недотрен то пойдет рандомайзер исходного конфига вместо устойчивого воспроизведения по запросу, при перетрене все просто поломается и будет лезть.
> альфа 128 дим 256 самое то
Хуясе ебать
Так получается поломанная модель, то что она поломана не обязательно плохо ибо может генерировать что-то дохуя необычное или хтонь, а потом на последующих шагах пытаться подогнать это под концепт персонажа, провоцировать проявление специфичных моделей в миксе и т.д., на выходе большей частью шлак но редкие могут ай как выстрелить. Как раз похоже на
> До сих пор надо роллить нужный результат часами
> на 3090
Она тебе за ночь десятки моделей натренит, из них уже поймешь с какими настройками лучше выходит, чем ныть.
Поделитесь каким-нибудь каналом где оперативно дают самые актуальные новости по SD без всякой тупой мемной хуйни, надоело шерстить по двачам и гитхабам каждый день.
На каком-то китайском телеграме напрмиер нашел такую прикольную штуку. https://github.com/DominikDoom/a1111-sd-webui-tagcomplete
Это базовый экстеншен, сам автоматик на него ссылку дает.
Реддит, дискорд анстейбл диффужена, атф, мой канал куда я периодически сливаю всякое интересное что сам нахожу.
Мимо вылез из осени 2022, вернулся домой и зашел обновить свой автоматик, спустя почти 4 месяца, появилась строка Hires steps, что такое степы на пикчу это понятно, а нахуя добавили их на Hires? и на что влияет изменение параметров?
Это ты еще кастомного хайрезфикса не видел..
Блин а мы можем как то связатся? Как мне найти тебя?
Анончики, а в гайде-то косячок.
https://rentry.co/clipfix
Скрипт для клипфикса выложен в тележеньке и без аккаунта в оной не скачивается!
https://rentry.co/clipfix
Скрипт для клипфикса выложен в тележеньке и без аккаунта в оной не скачивается!
В гайде написано что обрезать изображения необязательно, но при этом изображения должны быть квадратными, без прозрачности, разрешение - 512х512, мне их обрезать?
Проверил тензоры расширением, результат вот: https://pastebin.com/v6aqTRK8
(не даёт грузить листинг сюда, непонятно, почему)
Max dev-n: 0.00000
Min dev-n: 0.00000
Mean dev-n: 0.00000
Я ведь правильно понимаю, что тензоры в порядке? да и с чего бы им не, если модель сделана через DreamBooth ?




Итак, мы имеем следующую стандартную девиацию, которую можно условно классифицировать как "вертикально-двойная голова". НЯП, это расплата за генерацию в 512х1024.
Идея заключается в том, чтобы объяснить нейросетке, что такое verticallydoubledface, а потом попросить её это НЕ рисовать.
Вопрос к тебе, обучач: какую технологию использовать? Dreambooth ради такого дела - это из пушки по воробьям, да и не единственная это из классифицируемых девиаций, там ещё есть. Если тренить DreanBooth на этих девиациях последовательно - огребём catastrophical forgetting и прочую деградацию модели, а если параллельно - то крайне затруднительно будет подбирать рабочий рецепт.
Лора, насколько я понимаю, тоже чутка не для этого. (Или я неправ?). Гипернетворки плохо сочетаются между собой (а типовых девиаций несколько).
Получается - самый что ни на есть банальнейший textual inversion? А можно ли его тренировать на разрешениях, отличных от 512х512 ?
Есть ли умельцы, готовые (при условии подбора датасета мной) за это взяться на благо всего человечества?
Это в гайде про лору, резать изображения нужно?
Вы посмотрите на него! Он открыл, как работает опенсорс, и недоволен этим!
Иди целуй сво а*фон и молись на портрет БилГейТса, потребитель хренов!
>Я ведь правильно понимаю, что тензоры в порядке?
Да
>да и с чего бы им не, если модель сделана через DreamBooth ?
Всякое бывает
>это расплата за генерацию в 512х1024.
Ну тащемта да, все модели модели на основе сд обычно тренируют на 512 и 768 разрешении, все что выше это латент спейс на усмотрение сетки с пересекающимися концептами, поэтому лучше беспроблемно генерить на размерах на которых тренировалась модель, а потом хайрезфиксить или сдапскейлить и ультимейтапскейлить по вкусу до ультрахд 8к.
>а потом попросить её это НЕ рисовать.
Можно жестко весами закоментить все что связано с 1girl и сопутствующие теги и роллить до нужного результат.
>Лора, насколько я понимаю, тоже чутка не для этого. (Или я неправ?).
Лора как раз подходит, ты можешь ее натренировать чисто на рандом бабах и совсем чутка подмешать в генерацию и она будет работать как референс.
> потом хайрезфиксить
Здравствуйте, здравствуйте, глазки на трусиках...
Вообще похуям, в скрипте все картинки ресайзятся до рабочих разрешений сами без обрезаний.
Как будто тебя заставляют выше 0.3 подымать денойз.
> все модели модели на основе сд обычно тренируют на 512 и 768 разрешении
А как тогда лоры тренят на разрешениях выше стандартного для SD 1.5, те.е. 512х512 - например, на 512х768 ?
Просто берут и тренят, можешь тренить лоры на любых разрешениях, это пресижн надстройка над моделью просто. Вопрос то был в том что сама сд это 512 и 768 версии онли.

Что я не так делаю? Пишет image does not have caption хотя у всех пикч есть txt файл, или я не правильно это понимаю
Забыл поди в конфиг расширение для этих файлов прописать. Вот он их без расширения и не увидел.
А мне почему то один парень из за рубежа сказал тренировть ЛОРУ на 30 num epochs. Так вот он никак ее ненатренирует. Это что то даст?
> 30 num epochs
Если для поиска свитспота то может быть, однако он почти никогда не выходит за 3-4к шагов. Даст более подробное разбиение, кучу моделек в которых соседние 4 штуки будут неотличимы или 2/3 перетренены. Увеличит затрачиваемое время ибо сохранение модели и последующий запуск продолжения обучения происходит не быстро, а если у тебя не 64+гб рам то еще 30 раз будешь ждать пока оно просвопается.


Где этот конфиг? Этот скрин на этапе 4.5. Create JSON file for Finetuning, причём описание из txt подхватывает, вот пример из meta_clean.json
"cherry coloured funk Photo": {
"tags": "by ueda hajime, 1girl, solo, socks, sitting, long sleeves, kneehighs, school uniform, pleated skirt, miniskirt, long hair, traditional media, tree, short hair",
"train_resolution": [
384,
640
]
},
Но на этапе обучения ловлю ошибку
Смотря что хочешь, но как правило кропать нужно только те где персонаж занимает малую долю площади. Главное удалить крупный текст, интерфейс и желательно других персонажей
Это если тренишь лору скриптом, для остального обрезать.
Что-то запутался, как посчитать число повторов за эпоху?
в датасете две папки 32 и 40 пикч
в датасете две папки 32 и 40 пикч
Количество пикч в папке умножить на число повторов указанное в имени этой папки это число шагов на эпоху, если папок несколько то их сумма.
> в датасете две папки 32 и 40 пикч
А чем они отличаются?
> А чем они отличаются?
в одной портреты, в другой с тушей
> Количество пикч в папке умножить на число повторов указанное в имени этой папки это число шагов на эпоху, если папок несколько то их сумма.
Тогда что-то странное, почему тогда число повторов уменьшается при увеличении batch size ? У меня получается эпоха 5-15 пикч и оно переключает на другую.
-
Ну мысль понятная. Слушай а как с тобой саязаться?
> почему тогда число повторов уменьшается при увеличении batch size
То что показывает в прогрессбаре это не число обрабатываемых шагов а итерации обучения, когда несколько пикч параллельно обрабатывает то и итераций нужно меньше но то же число.
Если вопрошать за обучения - пиши здесь, один хуй экспертом не являюсь, если есть другие предложения - озвучь.
А как понять, сколько шагов норм?
При bs = 8 например приходится по 4_ повтора на каждую папку. Это нормально? И сколько эпох тогда надо? Пока поставил 50, мало? Всего 2900 шагов
> А как понять, сколько шагов норм?
Сделай обучение на 10-15 эпох чтобы последняя соответствовала 4к шагов, построй гриды на все полученные модели с разным промтом, сравни и выбери где лучше получается. Оно или будет соответствовать 4му оппику, или выйдет на постоянные значения.
На 4 оппике просто график ошибок, я делал чтобы так соответствовало, но на деле рисует всрато, особенно если начать промт деталями грузить или заставлять кого-то душить что-то.
Ладно, мне только число шагов надо было понять что такое...
Вообще насколько актуален 4 оппик?
Ставлю и бешено большие и низкие лр, но loss все равно низкая в районе 0.1 пляшет
Я так и не понял что я не так делаю, пикчи находятся в 1 папке с txt файлами, но мне пишут что image does not have caption, хоть и создаёт 2 json файла с названиями и описанием
Суть не в графике ошибок, в начале оно мало будет похоже на целевое, потом отлично, далее уже пережариваться. Если лр низкий то последнее может быть мало заметно.
> но на деле рисует всрато, особенно если начать промт деталями грузить
Это странно
> заставлять кого-то душить что-то
Не кожанного змея хоть? В такие сложные взаимодействия с нуля нейронки не могут, забей.
> loss
Не стоит по нему ориентироваться, у хороших моделей он бывает 0.17+, у пережаренной дичи 0.05
> Не кожанного змея хоть?
Нет, другого перса.
> Не стоит по нему ориентироваться, у хороших моделей он бывает 0.17+, у пережаренной дичи 0.05
Я этот график воспринимал так, что должно быть в районе от 1 до 0.2 у нормального, но это надо ЛРы в районе 2е-3 / 2е-4 и 4000к шагов почти час мусолятся при 50 эпохах...
А как грид с разными эпохами делать в автоматике? А то я как дурачок только меняю лоры и смотрю, что поменялось.
> Нет, другого перса.
Что-то осудительное делаешь?
> почти час мусолятся
> при 50 эпохах
Неудивительно лол
Натравливаешь на разные модели, очевидно
> Неудивительно лол
Ну ты же сказал 4000 шагов, вот что и есть...
> Натравливаешь на разные модели, очевидно
Не понял.
> Что-то осудительное делаешь?
У меня фетишь на удушение и дерущихся рвуших друг другу волосы девок, и не только, но вообще меня расстаривают эти нейронки пока, они умеют только казуалщину рисовать простую на рандоме, а вытянуть из неё что-то специфическое и детально по запросу почти анрил до сих пор...
4к шагов на 15 эпох - по 267 шагов на одну, у тебя 72 пикчи, ставь 4 повтора. Все.
У тебя по завершению каждой эпохи сохраняется своя модель, если не трогал настройки.
Сильно специфическое - или самому рисовать, или знать как заставить это сделать сеть, иначе без шансов.
> 4к шагов на 15 эпох - по 267 шагов на одну, у тебя 72 пикчи, ставь 4 повтора. Все.
а батч сайз? Он у меня 6 сейчас. Это 760 шагов выйдет, значит надо не 4 повтора, а 12
Какой смысл тогда в разнице 50 эпох или 15 эпох, если число шагов одинаково? Сохранять промежутки можно с разным интервалом.
И по времени одинаково выходит, тот же 1 час.
> а батч сайз?
Выше читай внимательно
> Какой смысл тогда в разнице 50 эпох или 15 эпох, если число шагов одинаково?
Смысл делать 50 эпох есть только если у тебя много лишнего времени или ты хочешь подробно исследовать как будет меняться на оче большом числе шагов, реальный юзкейс хз
> Выше читай внимательно
Ну так я и прочитал.
> 4к шагов на 15 эпох - по 267 шагов на одну, у тебя 72 пикчи, ставь 4 повтора. Все.
Это при батч сайз 1
При батч сайз 6 например, надо будет не 4 повтора ставить, а 4000/720 = 5,55 * 4 = 22 повтора. При этом получается те же 4к шагов, то же время обучения.
Но не видел, чтобы кто-то так делал еще в треде, разве что странные люди на 40к шагов и 9000 эпох.
Нуу, перечитай или продолжай в том же духе, но 50 эпох уже лишними не будут.
Там странное написано, как оно может параллельно обрабатывать быстрее сразу несколько пикч и одинаково?
Типа 4к шагов при бс1 = 720 шагов при бс6 ?
Шаги это число обработанных пикч, бс никак не влияет, то что тебе показывает скрипт на прогрессбаре это его внутренние попугаи
> и одинаково
Не факт, попробуй с максимальным бс и с единичкой и сравни результаты, запостить сюда не забудь. При изменении бс вроде как надо менять и лр.
> Шаги это число обработанных пикч, бс никак не влияет, то что тебе показывает скрипт на прогрессбаре это его внутренние попугаи
Хорошо бы это в гайд добавить. А то ведь вообще не ясно, зачем нужен батч сайз и чем 1 от 8 отличается.
> зачем нужен батч сайз
Зачем он нужен есть, и выше в треде обсуждалось.
У меня максимально возможный дает результат как минимум не хуже бс1, выше вон противоположное мнение. У большинства с обычным объемом врам максимум 2-3 вместится и им это не то чтобы актуально. Хочешь поисследовать - вперед, будет только польза всем.

Что значит no metadata / メタデータファイルがありません: /content/fine_tune/meta_lat.json, в первый раз тренерую лору, без понятия что я не так сделал
Всё запустился
Появились ли какие-нибудь новые VAE кроме дефолтного от nai и vae-ft-mse-840000-ema-pruned?
Vae от наи часть дает черные квадраты при апскейле, в второе не нравится по цветам и с лорами картинка выглядит пережаренной.
Vae от наи часть дает черные квадраты при апскейле, в второе не нравится по цветам и с лорами картинка выглядит пережаренной.
сижу на тринарте



У него свое вае? Где можно найти?


Тоже делал на Лену. Но я использовал девушку из косплея




Узнаете?

вы же просто конченные ублюдки, нет бы самим научиться рисовать, нет, надо воровать и подделывать, мрази, что тут сказать
нет это делается не для этого. Я тоже хочу рисовать научится.
Да здесь пиши лучше. Коллективно тебе поможем по ходу дела.


Красава, воспроизводит аутентично, более менее переодевается. Тегов на прическу не использовал?
Не трясись ты так. Нет бы самому современные технологии освоить, нет, надо поднимать вой и гадить под себя.
Найс;3
>Тегов на прическу не использовал?
Использовал. short hair, twintails, two sides up.
По идее можно сделать длинные волосы, но работает не очень
Без этой хуйни люди учились, тебе она не нужна, карандаш бумага вокзал
Я не вор и мне дорога репутация
Что за AddNet
Лора и ее сила
Хм, а у меня при увеличении лоры пидарасит задники и теряется вся детальность Anything 4.0 на которую он способен.
Во, с ними должно устойчивее ее похватывать с меньшими весами.
Вот деды с кожаной подошвой воевали одним ножом по 4 штуки за день вырезая, не нужны ваши станки и оснастки!
> Я не вор и мне дорога репутация
Ультимейт рваный рисовака бинго. Теперь расскажи как ты не юзал обводку и готовые ассеты, а на шарнирный манекен даже не смел посмотреть, ага.
Если выше 1 то так и должно быть, если на уровне 0.7-0.8 значит лора хуевая. Та же лена стиль чуть меняет но не смертельно, особенно если в дальнейшем будешь апскейлить и дорабатывать.
Я чет заебался уже, не получается лору хорошую сделать...
Какое отношение лучшее между лр и текстом? у меня все время 2е-4 / 4е-5 - самое нормальное выходит на разных датасетах, но все равно теряется возможность остальное рисовать и лора начинает копировать датасет на свитспоте. Не могу побороть никак это...
json.decoder.JSONDecodeError: Invalid \escape: line 2 column 39 (char 40) - пишет что ошибка
"pretrained_model_name_or_path": "D:\Music\novelaileak\stableckpt\animefull-latest\animefull-latest.ckpt", недоволен Но почему?
"pretrained_model_name_or_path": "D:\Music\novelaileak\stableckpt\animefull-latest\animefull-latest.ckpt", недоволен Но почему?
Лучшее не искалось, хорошее для текста в 2 раза ниже юнет. Сильно ниже - падает качество пикч, выше - ломается.
> лора начинает копировать датасет на свитспоте
А вот это интересно, прямо копирует или некоторые элементы воспроизводит? Вон та же Лена любит руки сводить, но это решается тегами.
> Не могу побороть никак это...
Скидывай свой датасет, посмотрим
Нафига тебе этот этап?
Лору делаешь? Используй пункты 1.1, 1.2, 1.3.2, 5.1, 5.2. Остальное не нужно.
Только придется базовую модель и датасет на гугл-драйв грузить, и в 5.1 ссылки проставить на это дело. Ну и папку для вывода результатов там же указать.
Правильные ссылки и пути берутся в левой колонке, после подключения гугл-драйва там можно дерево папок найти.
Но вообще, вторая ссылка на тренировку более понятная, без лишнего контента, в котором можно запутаться.
какие изображения брал? Есть дптсет?
Есть ли теггер для реалистичных моделей? Или wd14 теггер тоже норм для sd образных моделей?
> Или wd14 теггер тоже норм для sd образных моделей?
Вполне. Я был приятно удивлен.
Я другой анон Вообщем запустил я в итоге вебуи с новым торчем и иксформерами в обход батника, вообще без понятия что он там за венв цепляет, но не тот что нужен, просто из нужного венва python launch.py --xformers --no-half-vae --deepdanbooru --listen --api и получил отрицательный прирост на 3080, ничего не изменено, кроме версий либ, ну и экстеншен на будку отодвинут подальше:
python: 3.10.6 • torch: 1.13.1+cu117 • xformers: 0.0.16rc425:
512x512 150 euler a:
150/150 [00:08<00:00, 17.74it/s]
150/150 [00:08<00:00, 17.30it/s]
768x768 50 euler a + hires x2 valar 50 euler a:
50/50 [00:07<00:00, 6.51it/s]
50/50 [00:58<00:00, 1.17s/it]
100/100 [01:13<00:00, 1.35it/s]
python: 3.10.6 • torch: 2.0.0 • xformers: 0.0.17+cc36858.d20230219:
512x512 150 euler a:
150/150 [00:08<00:00, 17.24it/s]
150/150 [00:08<00:00, 17.03it/s]
768x768 50 euler a + hires x2 valar 50 euler a:
50/50 [00:09<00:00, 5.24it/s]
50/50 [01:07<00:00, 1.34s/it]
100/100 [01:23<00:00, 1.19it/s]
Там ещё какой-то accelerate в батнике был, он как то задействуется при запуске или это просто дохлый номер апгрейдить либы не на аде?



Что-то сделал, коряво конечно. Детальнее тестируй сам под что именно тебе надо.
Примерный промт в png найдешь там же.
https://mega.nz/folder/bpxUUZaL#h22Txy1JjgP88yAN0s1iBw
Офигеть, да как так-то?! Другой анон отписался, что на 4080 апдейт торча на 2.0 и xformers до 0.0.17 дал прирост на 5% всего, хотя говорили, что сильный буст должен быть для всего 40XX поколения. У меня на 4090 разница более чем в два раза стала. Я вообще уже нихера не понимаю логики в том, как это работает.




https://mega.nz/folder/bwIgRSoJ#aoFJriWGIRDRUp8ATqaMdg
ЮВАО залил, может надо кому-то. Пока что забил с идеи интеграции фонов.
ЮВАО залил, может надо кому-то. Пока что забил с идеи интеграции фонов.
В гайде по трене лоры в 5 пункте сказано про редактирование скрипта содержащего параметры тренировки, но не сказано какой именно, на сколько я понял речь идёт о train_network_README-ja.md ?
Спасибо я понял но мне просто интересно как самому делать?
Если не сложно напиши параметрі или залей файл конфига мне для анализа. Спасибо.

Mandy.ps1 и есть файл конфигурации. В винде есть встроенный редактор. Правой кнопкой мыши и изменить.
Это для https://github.com/kohya-ss/sd-scripts То есть в нем и делал лору.
Нахуя вы это делаете? Почему не на питоне?
P.S. иди на хуй.
А какая разница?
То что поверщель медленная и неудобная. У нас всё на питоне, но зачем-то тащат ещё один скриптовый язык.
> с новым торчем
Кринж. Вы вообще в курсе что в бете абсолютно все новые фичи выключены под виндой и работают только на линуксе? Ну и естественно будет падать производительность на некрокартах, потому что там свежие либы под новое железо.
Технычи кто может пояснить пару вопросов за байес аппроуч итт?
Спрайты и арты из ленопака;)
>Коллекция лор от анонов: https://rentry.org/2chAI_LoRA (заливать лоры можно сюда https://technothread.space/ пароль 2ch)
У меня сдох сервак с лорами, а я не успел (поленился) настроить зеркалирование на другой.
Доверите мне новый поднять, или на чей-нибудь еще сервис редирект сделать? И нужен ли он вообще?
Большая часть народу все равно на мегу льет как я вижу.
Что послужило причиной смерти? Лоры то сохранились?

>Что послужило причиной смерти?
Сдох SSD, на котором лежал volume docker-а.
Без него файлы есть, но они без расширений.
Моя отсеять по размеру пикчи от лор и сгрузить куда угодно, но - без имен.
>Моя отсеять
Моя, конечно, отсеять. Но я имел ввиду "могу".

Это то где нужно редактировать параметры, или файл с параметрами нужно самому создать? Или тупо можно передать параметры в train_network.py в консоли?
Их там сильно много? Твоя может справиться отсеять по названиям заодно? Там вроде в расширении в метаданных лор названия должны оставаться.
Я лично только за то чтоб у треда свое репо лор было желательно конечно на зеркале, ну или хотя бы просто не отваливающееся, даже не смотря на то что тут в последнее время перекати поле, да и 1060 куда то пропал. Я бы заливал тебе на сервак лоры, но пока все что я тренил оставалось интересно лишь мне и никто даже не просил делиться
>Их там сильно много?
22
>Твоя может справиться отсеять по названиям заодно?
У девочки них теперь нет имени
>Там вроде в расширении в метаданных лор названия должны оставаться.
Посмотрю попозже, есть ли какая-то информация в них полезная.
>Я лично только за то чтоб у треда свое репо лор было
Я тоже. Но последний раз туда кто-то что-то грузил неделю назад, и это вроде были ехидные йобы.

Там вот этот скрипт имеется ввиду. То есть .ps1
Понял, спасибо

Если что, то запускать всю эту шарманку нужно таким образом после редактирования
Учился по гайдам, другого и не знаю даже. Привык. Даже не использую gui

>Теперь расскажи как ты не юзал обводку и готовые ассеты
Как у ничтожества рвёт сраку, ведь ему даже представить невозможно что есть честные люди не использующие читы и короткие пути, ничего из этого я не делал
>а на шарнирный манекен даже не смел посмотреть
у меня такой есть, но он по сути бесполезен


Выдаёт такую ошибку при запуске скрипта на лору, обновил powershell, я где то пропустил закрывающую скобку?
Уходил на работу не мог сказать спасибо всем кто помогал с генерацией Мэнди! Теперь надо научится и делать самому! Возьму за основу ваши файлы.
> медленная и неудобная
> медленная
> на питоне
проиграл конечно
Человек на чем удобно написал достаточно простой код, параметры в нем стоят в начале и менять их удобно, ньюфаг не запутается, в любой шинде павершелл есть, простые проверки есть, что еще надо? Скажи спасибо что не на шеллскрипте или перле, лол.
Хочешь - напиши свой, а потом отвечай на вопросы нюфагов что такое if main == name, почему по двойному клику оно сразу завершается, почему не хочет активироваться венв другого скрипта и т.д.
Результат интересный, если он не тащит что-то поломанное что вполне возможно то на 3к серии такое делать не надо. У кого еще 3к серия пусть отпишутся, таки интересно.
{
"pretrained_model_name_or_path": "D:/animefull-latest/animefull-latest.ckpt",
"v2": false,
"v_parameterization": false,
"logging_dir": "D:/01/kohya_ss/train/log",
"train_data_dir": "D:/01/kohya_ss/train/image",
"reg_data_dir": "",
"output_dir": "D:/01/kohya_ss/train/model",
"max_resolution": "512,512",
"learning_rate": "0.0001",
"lr_scheduler": "constant",
"lr_warmup": "0",
"train_batch_size": 1,
"epoch": "10",
"save_every_n_epochs": "1",
"mixed_precision": "bf16",
"save_precision": "bf16",
"seed": "1234",
"num_cpu_threads_per_process": 2,
"cache_latents": true,
"caption_extension": ".txt",
"enable_bucket": false,
"gradient_checkpointing": true,
"full_fp16": false,
"no_token_padding": false,
"stop_text_encoder_training": 0,
"use_8bit_adam": true,
"xformers": true,
"save_model_as": "safetensors",
"shuffle_caption": false,
"save_state": false,
"resume": "",
"prior_loss_weight": 1.0,
"text_encoder_lr": "5e-5",
"unet_lr": "0.0001",
"network_dim": 128,
"lora_network_weights": "",
"color_aug": false,
"flip_aug": false,
"clip_skip": 2,
"gradient_accumulation_steps": 1.0,
"mem_eff_attn": true,
"output_name": "mandy_0.1",
"model_list": "runwayml/stable-diffusion-v1-5",
"max_token_length": "75",
"max_train_epochs": "",
"max_data_loader_n_workers": "1",
"network_alpha": 1024,
"training_comment": "",
"keep_tokens": "0",
"lr_scheduler_num_cycles": "",
"lr_scheduler_power": "",
"persistent_data_loader_workers": false,
"bucket_no_upscale": true,
"random_crop": false,
"bucket_reso_steps": 64.0,
"caption_dropout_every_n_epochs": 0.0,
"caption_dropout_rate": 0
у меня такой вид а там другой.
Training comment - важное ли поле? Стоит ли туда что то вносить?
Что за файл и от куда ставил?
Тогда настройки перенеси вручную. Там немного править.
> bf16
Если у тебя видуха не 3000 или 4000 серии, то ставь fp16
Это же просто комментарий, не?

mandy_0.1 - у меня генерит такую чушь
Пиши в промте <lora:Mandy-000007:0.7>, например. Или как ты вообще используешь Лору?
ну я стал генерить сам свою лору. но как видишь... скинуть мои настройки?
Ты чтоли лору или гиперсеть вместо основной модели сд выбрал?

<lora:mandy_0.1:1> Mandy, 1girl, solo, blonde hair, twintails, green eyes, cleavage, large breasts, midriff, crop top, hair ribbon, nail polish, beach <lora:mandy_0.1:1>
мы с тобой переписывались в дискорде может там поглядишь
Это не то что скинули а то что я делаю сам.

Кто мы блять кто мы?! Я здесь один нахуй!
Путаешь меня с кем-то, но у тебя явно херня вместо модели стейбл дифужн загружена, лора так не испортит ибо просто вылетит с ошибкой в процессе генерации
Странно. Обычно лору хрен сломаешь, чтоб прям вот так вот.
Скинь, посмотрим.
У вас там рили конфа что-ли? Я думал это прикол такой.



Я ещё раз скопировал скрипт и следил чтобы не задеть ни какие скобки, по итогу та же ошибка, менял только те параметры что указаны в гайде, ничего ниже скриптов и сами скрипты трогал, powershell последняя, что я не так делаю
Слеши в конце путей убери
> resolution = 704
512 или 768 поставь
Если не поможет, то качай скрипт с английскими комментариями.
Слеши не влияют.
> проиграл конечно
По производительности питон сверхбыстрый по сравнению с ПС.
> отвечай на вопросы нюфагов
Для людей конфиги в yaml делают, юзер не должен лезть в код скрипта. Вон постом выше уже спрашиваю про скобочки, сразу видно удобство.
> по двойному клику
Как будто ПС по двойному клику запустить можно. А ещё ньюфагу может потребоваться лезть в настройки и выключать политики безопасности для запуска скриптов из интернета.
Вангую что автор серии вчерашних вопросов таки доебался до кого-то кто здесь сидит а тот уже жалеет что согласился лол
Влияют оказывается, в гайде в конце слеши, только что убрал и заработало

Хехехе
in progress
in progress
Спасибо за подсказку, к сожалению у меня снова ошибки по вылезали, попробую пока сам пофиксить, зато продвижение есть
Сорта же. Производительность здесь вообще не нужна ибо только формируются правильные параметры запуска основного скрипта.
> Для людей конфиги в yaml
Потом диагностировать ошибки что нюфаг один отступ проебал, в json еще скажи.
> Как будто ПС по двойному клику запустить можно.
Да вообще можно, но для его запуску по дефолту инструкция проста, а питоноскрипты большинство неофитов тупо кликая запускают.
Обсуждение уровня "разрешите доебаться" и "почему делаете не так как я считаю нужным", напиши свой скрипт с отладкой и мастерписями, благо знаний особых не нужно, или по делу высказывай.
Уже две есть на цивит
Ну вот =(


Не, лучше запилю свою. Мне не нравится стиль
Тебе легче у коллективного разума здесь спросить
вангую у тебя там файл подсоса маленький

Пока не разобрался, погуглил и подозрения пока только на bitsandbytes
> отступ
Не пизди на yaml, ему поебать на отступы в пределах блока. Можно и без отступов структуру конфига делать, это же не json тебе, чтоб заниматься форматированием и расставлением скобочек.
У тебя же в PATH нет пути до либ CUDA, вот он и не видит её.
Не пойму, у меня потери в районе 0.1..0.09 с самого начала обучения и кривые ебала, как добиться этих ваших идеальных потерь в 0.2..0.17 ?
По эпохам сначала рисует типично анимешно, потом резко кривые ебала и так до конца... Нет свитспота вообще.
По эпохам сначала рисует типично анимешно, потом резко кривые ебала и так до конца... Нет свитспота вообще.
> резко кривые ебала и так до конца
Очевидное переобучение. А если ещё скорость обучения высокая, то со ступенчатыми потерями и будет говно всегда.
Показывай что и как ты тренируешь, на каком датасете, что получается.
> ваших идеальных потерь в 0.2..0.17
Вообще не стоит смотреть, разве что сильно малые значения - 90% перетрен
Вот и сделай, удобнее будет циклы с варьированием нужных параметров запускать.
> Очевидное переобучение. А если ещё скорость обучения высокая, то со ступенчатыми потерями и будет говно всегда.
Так что, дробить на сотни эпох и медленно обучать шесть часов?
Лр сбавь и
сейчас
<lora:mandy_0.1:1> Mandy, 1girl, solo, blonde hair, twintails, green eyes, cleavage, large breasts, midriff, crop top, hair ribbon, nail polish, beach <lora:mandy_0.1:1>
Negative prompt: (makeup:1.4), (milf:1.4), (porn:1.4), (glamour:1.4), (instagram:1.4),(monochrome:1.4), (orgy:1.4), (homo:1.4), (multiple girls:1.4), (multiple boys:1.4), (duplicate:1.4), (sfw:1.6), (censorship:1.2), extra fingers, mutated hands, (bad eyes:1.2) (poorly drawn hands:1.2), (mutation:1.4), (deformed:1.4), (bad anatomy:1.4), (bad proportions:1.4), (extra limbs:1.4), cloned face, (disfigured:1.6), extra limbs, (bad anatomy:1.6), (malformed limbs:1.2), (missing arms:1.4), (missing legs:1.4), (extra arms:1.4), (extra legs:1.2), mutated hands, (fused fingers:1.2), (too many fingers:1.4), (long neck:1.2), text, logo, blood, animal, pig, long neck, deformed ears, (futa:1.4), lowres, (bad anatomy:1.4), (bad hands:1.4), text, error, (missing fingers:1.4), extra digit, fewer digits, cropped, worst quality, low quality, normal quality, jpeg artifacts, signature, watermark, username, blurry, (child:1.4), (loli:1.4), (old:1.4), (ugly:1.4)
Steps: 20, Sampler: Euler a, CFG scale: 7, Seed: 447825254, Size: 512x768, Model hash: 7fb9c64bb4, Model: --model-epoch09-full
Не думаю что в этом дело. Скинь лору короче через мегу. Посмотрю мета-данные.
Негатив немного упрости. Слишком агрессивно накидывается значения 1.4-1.6, у меня аж изображения более блеклые становятся.
там только steps: 60%|██████████████████████████████▌ | 74400/124000 [15:02:08<10:01:25, 1.37it/s, loss=1.04]saving checkpoint: D:/01/kohya_ss/train/model\mandy_0.1-000006.safetensors
Ну скидывай последнюю, которая есть. Обычно из 10 эпох по итогу выбираю 6-8 где-то.
> loss=1.04
Что-то как-то слишком много. Больше 0.150 никогда не видел.
я новичок мне тяжко это у меня первая лора
(makeup), (milf), (porn), (glamour), (instagram),(monochrome), (orgy), (homo:1.4), (multiple girls), (multiple boys), (duplicate), (sfw), (censorship), extra fingers, mutated hands, (bad eyes) (poorly drawn hands), (mutation), (deformed), (bad anatomy), (bad proportions), (extra limbs), cloned face, (disfigured), extra limbs, (bad anatomy), (malformed limbs), (missing arms), (missing legs), (extra arms), (extra legs), mutated hands, (fused fingers), (too many fingers:1.4), (long neck:1.2), text, logo, blood, animal, pig, long neck, deformed ears, (futa), lowres, (bad anatomy), (bad hands), text, error, (missing fingers:1.4), extra digit, fewer digits, cropped, worst quality, low quality, normal quality, jpeg artifacts, signature, watermark, username, blurry, (child), (loli), (old), (ugly)
так сделать?
ну получил файлы

Ну да
Что-то сломанная она у тебя вышла сама по себе.
> "network_alpha": 1024
Ставь либо 1, либо половину от dim, либо как dim. Я предпочитаю половину. То есть если dim 32, то alpha 16.
> "mixed_precision": "bf16"
> "save_precision": "bf16"
Попробуй все же fp16

> 100_mandy_0.1
> steps: "124000"
Это слишком ДОХУИЩЕ, другого слова и не подобрать. Ставь где-то 8-12 повторений. Можно даже 5 или 6. Но никак не 100, чтобы 25 часов вертелось. Больше и дольше, тут не равно лучше и качественнее.
network_alpha": 1024 dim 32 так надо написать?
Или что? network_alpha надо написать по дугому?
Или что? network_alpha надо написать по дугому?
У тебя же там gui. Запусти lora_gui.bat и там все забивай в браузере.
"network_alpha": 16
"network_dim": 32
"124000" где это у меня? не нахожу
Это количество шагов, которые были посчитаны из количества_пикчколичество_повторенийэпохи. Пока шаги не забивай. Снижай через переименование папки до 10 хотя бы.
Как её добавить, без понятия где она находиться
Спасибо за ответ и подсказки! 100_mandy_test - нормальное имя?
total optimization steps / 学習ステップ数: 124000 опять вышло столько шагов
num train images * repeats / 学習画像の数×繰り返し回数: 12400
num reg images / 正則化画像の数: 0
num batches per epoch / 1epochのバッチ数: 12400
num epochs / epoch数: 10
batch size per device / バッチサイズ: 1
total train batch size (with parallel & distributed & accumulation) / 総バッチサイズ(並列学習、勾配合計含む): 1
gradient accumulation steps / 勾配を合計するステップ数 = 1
num train images * repeats / 学習画像の数×繰り返し回数: 12400
num reg images / 正則化画像の数: 0
num batches per epoch / 1epochのバッチ数: 12400
num epochs / epoch数: 10
batch size per device / バッチサイズ: 1
total train batch size (with parallel & distributed & accumulation) / 総バッチサイズ(並列学習、勾配合計含む): 1
gradient accumulation steps / 勾配を合計するステップ数 = 1

10_mandy_test пиши, блин
Мда блин я туплю

...\sd-scripts\venv\Lib\site-packages\bitsandbytes
Здесь должно быть. Ты по гайду делал перемещние .dll вот этих?
Спасибо сделал все теперь жду
Вроде да, но на всякий случай ещё раз сделаю
num train images * repeats / 学習画像の数×繰り返し回数: 1240
num reg images / 正則化画像の数: 0
num batches per epoch / 1epochのバッチ数: 1240
num epochs / epoch数: 10
batch size per device / バッチサイズ: 1
total train batch size (with parallel & distributed & accumulation) / 総バッチサイズ(並列学習、勾配合計含む): 1
gradient accumulation steps / 勾配を合計するステップ数 = 1
total optimization steps / 学習ステップ数: 12400
num reg images / 正則化画像の数: 0
num batches per epoch / 1epochのバッチ数: 1240
num epochs / epoch数: 10
batch size per device / バッチサイズ: 1
total train batch size (with parallel & distributed & accumulation) / 総バッチサイズ(並列学習、勾配合計含む): 1
gradient accumulation steps / 勾配を合計するステップ数 = 1
total optimization steps / 学習ステップ数: 12400
я пробовал сбавлять, это приводит лишь к тому, что точка дефолтное аниме -> перекошеное ебало сдвигается вверх и всё...
Не, так то я получал плюс минус нормально, но на 20 тысячах шагов, это 3-4 часа тренировки... Но при этом сталкивался с такой проблемой, что лора начинала копировать датасет, не мог переодевать и ставить в другие позы.


Моделька Мэнди уже сделанная Анонимом отсюда.
> но на 20 тысячах шагов
Ахуеть, сильно длинное обучение может к подобному приводить. Тащи что там у тебя есть, показывай как протегано, какие результаты и т.д. иначе толку не будет
После установки либ автоматически путь не добавляется, туда bitsandbytes пихать?
Если ты про эти файлы, то по идеи они должны в ту папку откопироваться. Но у некоторых не выходит, приходится вручную.
Ну так уж, попробовал с двух раз.
Почему каждый раз, когда я что-то выкладываю анимешное-рисованное, первом же делом все пытаются навалить супер-гипер-реализм?
скорее это Зд а не релизм

О оно вроде живое, надеюсь ошибок не выскочит, спасибо
А вот еще вопрос не связанный с лорами.
Когда пикчи генерю, автоматик выдает промежуточные мыльные превьюшки, и практически всегда на любых настройках с любыми шагами, сфг скейлом и т.п. я наблюдаю такую картинку - от 0 до 70% пикча моська выходит почти идеальными, а последние 40% генерации он тупо всирает все что было идеальным. Я приноровился останавливать генерацию пикчи на 60-70%, и получаю интересную пикчу до того, как оно успеет всраться.
Вот как это можно пофиксить/подтюнить/автоматом на 70% останавливать?
Уменьшить число шагов не предлагать, уменьшив шаг, просто уменьшиться число шагов, а всирание на 70% все так же останется.
Когда пикчи генерю, автоматик выдает промежуточные мыльные превьюшки, и практически всегда на любых настройках с любыми шагами, сфг скейлом и т.п. я наблюдаю такую картинку - от 0 до 70% пикча моська выходит почти идеальными, а последние 40% генерации он тупо всирает все что было идеальным. Я приноровился останавливать генерацию пикчи на 60-70%, и получаю интересную пикчу до того, как оно успеет всраться.
Вот как это можно пофиксить/подтюнить/автоматом на 70% останавливать?
Уменьшить число шагов не предлагать, уменьшив шаг, просто уменьшиться число шагов, а всирание на 70% все так же останется.
Хайрезфикс
Кстати подскажите лучшее количество изображений для ЛОРЫ? Спасибо!
Не, эта шляпа совсем до конца всирает плюс какую-то чешую лепит на пикчи
Минимум 20, оптимально я бы сказал 60-100
спасибо

Если я хочу продолжить тренить лору, то здесь нужно указывать название лоры?
> Результат интересный, если он не тащит что-то поломанное что вполне возможно то на 3к серии такое делать не надо. У кого еще 3к серия пусть отпишутся, таки интересно.
Автоматик поставленный начисто, никаких поломанных венвов, запуск так же через батник, результат такой же, производительность падает, может более старые либы, янаварские там например, покажут результат лучше:
Clean automatic old libs:
Euler a 150 512x512:
150/150 [00:08<00:00, 18.00it/s]
150/150 [00:08<00:00, 18.06it/s]
Euler a 50 768x768 + hires latent(nearest):
50/50 [00:07<00:00, 6.68it/s]
50/50 [00:56<00:00, 1.13s/it]
100/100 [01:05<00:00, 1.52it/s]
Clean automatic new libs:
Euler a 150 512x512:
150/150 [00:08<00:00, 18.03it/s]
150/150 [00:08<00:00, 17.98it/s]
Euler a 50 768x768 + hires latent(nearest):
50/50 [00:07<00:00, 6.54it/s]
50/50 [01:04<00:00, 1.29s/it]
100/100 [01:14<00:00, 1.35it/s]
Кстати торч по другому в вебуи подписан стал, почему то - torch: 2.0.0.dev20230219+cu118, алсо производительность чуть подросла, походу автоматик лучше периодически вычищать от говна
Вопрос по лоре. Можно ли как-то использовать всю оперативку, а не половину с файлом подкачки? Из 32 загружено в пике 15
Она просто перезапишется и все, если название такое же, которое уже есть.

Ребята спасибо! Получилось.

Раздевает плоховато

+ бимбостайл
Как в ControlNet рисовать позу?

1 - лора на близняшек
2 - лора на криповую куклу Мику
Забавно, что при смешивании оно начинает лучше понимать позы
2 - лора на криповую куклу Мику
Забавно, что при смешивании оно начинает лучше понимать позы
Спасибо, включил твой пик в датасет :3
Вот кстати тоже
Ты про обучение? Откуда такие малые числа? Увеличивай max_data_loader_n_workers пока не достигнешь удовлетворения
дайте ссылку на кастомный хурезфикс
А смысл? С пробовал, но кроме потребления памяти не заметил влияния. Паузы между эпохами такие же, скорость та же



Охуительно получается, анон. Очень жду когда выложишь.
Имеющиеся, конечно, тоже неплохие, но твоя с виду уже выглядит гораздо лучше.
А есть местный лора-репозиторий как у форчановских примерно? Общая папка какая-нибудь, куда собирают с борды все не убер всратые лорки.
Есть, он прилег отдохнуть, но обязательно вернется
Привет! А для фото тоже хватает 60 фото и те же настройки только модель другая?




Сегодня сдела новю ЛОЛУ




то же но с другими весами
У ней на губах помада по дата-сету? Вчера делал Менди, у которой тоже помада была и тоже такие же артефакты на рту на аниме-моделях.





Если делать по реальному чеовеку ЛОРУ то мне тоже хватит 60 фото и тех настроек? Только сменить модель анимешную?
Попробуй, расскажешь. Если только лицо я думаю и меньше хватит.
Абсолютно никакого, хз почему он хочет рам загружать.
не знаю ну по пояс или полностью даже
Зачем? Если у тебя там не анорексичка или не качок, то тренируй только лицо, сможешь потом промптом посадить его на любое тело.
Инфы об этом море на ютубе. У нас же наоборот тут преимущественно за иллюстрации, ибо такого очень мало уже там.
Обычно только лицо делают по плечи.
Всем Спасибо! Мне интересно делать все и фото и по аниме и по пин апу
запрещаю использование моей интелектуальной собственности как материал для фотоманипуляции в том числе и нейросетями
Пупсик, тебя никто не спрашивает, все уже сделано. Еще раз благодарю за содействие в приближении киберкоммунизма!


Скорее анархо-кибер-транс-гуманнизма


Как-то так.
На фтором гриде посадил с помощью контролнета
На фтором гриде посадил с помощью контролнета

А это получается, если примешивать лору роботов к лоре Мику
Одно из лучших моих творений!
честно говоря я ничего не понял как это делать?
https://github.com/opparco/stable-diffusion-webui-two-shot - я поставил. Есть ли хороший гид на русском про это?
>nsfw, 1girl, 1boy, sex, from side
>AND 1girl, 1boy, (hakurei reimu:1.1), nude, sex, doggystyle, from side
>AND 1girl, 1boy, (hakurei reimu:1.1), nude, sex, doggystyle, from side
>AND 1girl, 1boy, (hakurei reimu:1.1), nude, sex, doggystyle, from side
>AND nsfw, 1boy, nude, penis, standing, from side
Зачем столько дублей?
>AND 1girl, 1boy, (hakurei reimu:1.1), nude, sex, doggystyle, from side
>AND 1girl, 1boy, (hakurei reimu:1.1), nude, sex, doggystyle, from side
>AND 1girl, 1boy, (hakurei reimu:1.1), nude, sex, doggystyle, from side
>AND nsfw, 1boy, nude, penis, standing, from side
Зачем столько дублей?

На русском нет, есть https://t.me/h0rnee/119
Если делаю батч в четыре раза больше, как менять скорости?

>nsfw, 1girl, 1boy, sex, from side >AND 1girl, 1boy, (hakurei reimu:1.1), nude, sex, doggystyle, from side >AND 1girl, 1boy, (hakurei reimu:1.1), nude, sex, doggystyle, from side >AND 1girl, 1boy, (hakurei reimu:1.1), nude, sex, doggystyle, from side >AND nsfw, 1boy, nude, penis, standing, from side
Negative prompt: (makeup), (milf), (porn), (glamour), (instagram),(monochrome), (orgy), (homo), (multiple girls), (multiple boys), (duplicate), (sfw), (censorship), extra fingers, mutated hands, (bad eyes) (poorly drawn hands), (mutation), (deformed), (bad anatomy), (bad proportions), (extra limbs), cloned face, (disfigured), extra limbs, (malformed limbs), (missing arms), (missing legs), (extra arms), (extra legs), mutated hands, (fused fingers), (too many fingers), (long neck), text, logo, blood, animal, pig, long neck, deformed ears, (futa), lowres, (bad anatomy), (bad hands), text, error, (missing fingers), extra digit, fewer digits, cropped, worst quality, low quality, normal quality, jpeg artifacts, signature, watermark, username, blurry, (child), (loli), (old), (ugly)
Steps: 20, Sampler: Euler a, CFG scale: 7, Seed: 3523241364, Face restoration: CodeFormer, Size: 512x512, Model hash: 8191ba9306, Model: 1980sAestheticJemAnd_10, Denoising strength: 0.7, Latent Couple: "divisions=1:1,1:2,1:2 positions=0:0,0:0,0:1 weights=0.2,0.8,0.8 end at step=20", Hires upscale: 2, Hires upscaler: Latent
Negative prompt: (makeup), (milf), (porn), (glamour), (instagram),(monochrome), (orgy), (homo), (multiple girls), (multiple boys), (duplicate), (sfw), (censorship), extra fingers, mutated hands, (bad eyes) (poorly drawn hands), (mutation), (deformed), (bad anatomy), (bad proportions), (extra limbs), cloned face, (disfigured), extra limbs, (malformed limbs), (missing arms), (missing legs), (extra arms), (extra legs), mutated hands, (fused fingers), (too many fingers), (long neck), text, logo, blood, animal, pig, long neck, deformed ears, (futa), lowres, (bad anatomy), (bad hands), text, error, (missing fingers), extra digit, fewer digits, cropped, worst quality, low quality, normal quality, jpeg artifacts, signature, watermark, username, blurry, (child), (loli), (old), (ugly)
Steps: 20, Sampler: Euler a, CFG scale: 7, Seed: 3523241364, Face restoration: CodeFormer, Size: 512x512, Model hash: 8191ba9306, Model: 1980sAestheticJemAnd_10, Denoising strength: 0.7, Latent Couple: "divisions=1:1,1:2,1:2 positions=0:0,0:0,0:1 weights=0.2,0.8,0.8 end at step=20", Hires upscale: 2, Hires upscaler: Latent
ну вот ничо не выходит
Что делать, трахаться?
Да нет же
>nsfw, 1girl, 1boy, sex, from side
>AND 1girl, 1boy, (hakurei reimu:1.1), nude, sex, doggystyle, from side
>AND 1girl, 1boy, (hakurei reimu:1.1), nude, sex, doggystyle, from side
>AND 1girl, 1boy, (hakurei reimu:1.1), nude, sex, doggystyle, from side
>AND nsfw, 1boy, nude, penis, standing, from side
как это вводить

Ну там же на гитхабе всё есть.
((ultra-detailed)), ((illustration)), 2girls
AND ((ultra-detailed)), ((illustration)), 2girls, black hair
AND ((ultra-detailed)), ((illustration)), 2girls, blonde hair
Сперва общее описание картинки, дальше два описания для размеченных областей соответственно.
>2girls
Везде?
((ultra-detailed)), ((illustration)), 2girls
AND ((ultra-detailed)), ((illustration)), 2girls, black hair
AND ((ultra-detailed)), ((illustration)), 2girls, blonde hair - это надо писать в промт???
AND ((ultra-detailed)), ((illustration)), 2girls, black hair
AND ((ultra-detailed)), ((illustration)), 2girls, blonde hair - это надо писать в промт???
Вопрос залу - а почему в примерах по обучению не предлагается обучать по раскадровке из аниме? Почему там в примерах какие-то васянские аниме-арты. Разве раскадровка за 12 серий не будет лучшим примером? Или каждая пикча должна иметь различные, где-то уникальные теги по возможности?

Это для примера с гитхаба, очевидно. Ты под себя пересобирай.
Я имею в виду зачем 2гёрлс на индивидуальных описаниях?
Полагаю, чтобы сохранялась общая консистентность изображения, а для регионов уже идут уточнения.
Костыль какой-то
Весь автоматик - гигакостыль, но мы же здесь за этим и собрались.

Что это вообще? Откуда мне знать о поддержке этих двухбукв+двухцифр. Хоть бы пояснялку добавили в гайд..

((ultra-detailed)), ((illustration)), 2girls
AND ((ultra-detailed)), ((illustration)), 2girls, black hair
AND ((ultra-detailed)), ((illustration)), 2girls, blonde ha
в этот раздел вводить или в общий промт можеет я очень туплю извините.
AND ((ultra-detailed)), ((illustration)), 2girls, black hair
AND ((ultra-detailed)), ((illustration)), 2girls, blonde ha
в этот раздел вводить или в общий промт можеет я очень туплю извините.

Я в общий промпт вводил, а это поле оставил пустым, хз. Получил что хотел.
Долго рулетку не крутил, один из генов с первой попытки подошел.
щас попробую

nsfw, 1girl, 1boy, sex, from side>nsfw, 1girl, 1boy, sex, from side
>AND 1girl, 1boy, (hakurei reimu:1.1), nude, sex, doggystyle, from side
>AND 1girl, 1boy, (hakurei reimu:1.1), nude, sex, doggystyle, from side
>AND 1girl, 1boy, (hakurei reimu:1.1), nude, sex, doggystyle, from side
>AND nsfw, 1boy, nude, penis, standing, from side
Negative prompt: (makeup), (milf), (porn), (glamour), (instagram),(monochrome), (orgy), (homo), (multiple girls), (multiple boys), (duplicate), (sfw), (censorship), extra fingers, mutated hands, (bad eyes) (poorly drawn hands), (mutation), (deformed), (bad anatomy), (bad proportions), (extra limbs), cloned face, (disfigured), extra limbs, (malformed limbs), (missing arms), (missing legs), (extra arms), (extra legs), mutated hands, (fused fingers), (too many fingers), (long neck), text, logo, blood, animal, pig, long neck, deformed ears, (futa), lowres, (bad anatomy), (bad hands), text, error, (missing fingers), extra digit, fewer digits, cropped, worst quality, low quality, normal quality, jpeg artifacts, signature, watermark, username, blurry, (child), (loli), (old), (ugly)
Steps: 20, Sampler: Euler a, CFG scale: 10, Seed: 1371738805, Face restoration: CodeFormer, Size: 512x512, Model hash: 7fb9c64bb4, Model: --model-epoch09-full, Denoising strength: 0.7, Latent Couple: "divisions=1:1,1:2,1:2 positions=0:0,0:0,0:1 weights=0.2,0.8,0.8 end at step=20", Hires upscale: 2, Hires upscaler: Latent
>AND 1girl, 1boy, (hakurei reimu:1.1), nude, sex, doggystyle, from side
>AND 1girl, 1boy, (hakurei reimu:1.1), nude, sex, doggystyle, from side
>AND 1girl, 1boy, (hakurei reimu:1.1), nude, sex, doggystyle, from side
>AND nsfw, 1boy, nude, penis, standing, from side
Negative prompt: (makeup), (milf), (porn), (glamour), (instagram),(monochrome), (orgy), (homo), (multiple girls), (multiple boys), (duplicate), (sfw), (censorship), extra fingers, mutated hands, (bad eyes) (poorly drawn hands), (mutation), (deformed), (bad anatomy), (bad proportions), (extra limbs), cloned face, (disfigured), extra limbs, (malformed limbs), (missing arms), (missing legs), (extra arms), (extra legs), mutated hands, (fused fingers), (too many fingers), (long neck), text, logo, blood, animal, pig, long neck, deformed ears, (futa), lowres, (bad anatomy), (bad hands), text, error, (missing fingers), extra digit, fewer digits, cropped, worst quality, low quality, normal quality, jpeg artifacts, signature, watermark, username, blurry, (child), (loli), (old), (ugly)
Steps: 20, Sampler: Euler a, CFG scale: 10, Seed: 1371738805, Face restoration: CodeFormer, Size: 512x512, Model hash: 7fb9c64bb4, Model: --model-epoch09-full, Denoising strength: 0.7, Latent Couple: "divisions=1:1,1:2,1:2 positions=0:0,0:0,0:1 weights=0.2,0.8,0.8 end at step=20", Hires upscale: 2, Hires upscaler: Latent
> 512x512
Амудаун, ты?
А что я не так то пишу???

В гайде об этом так написано мимходом, будто я понимаю о чем речь лол.
Что тут под СД версиями подразумевается и где их взять, что за NAI, AnythingV3 блин? Это обычные модели что ли? Типа animefinal-full-pruned и Anonmix
Что тут под СД версиями подразумевается и где их взять, что за NAI, AnythingV3 блин? Это обычные модели что ли? Типа animefinal-full-pruned и Anonmix

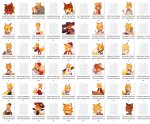

Вот результаты обучения по 600 фреймам с аниме vs по 30 артам от мангаки. Стоит-ли оно того? Нуу, не знаю.
Мне кажется, что может скорее иметь смысл именно качественных фреймов с аниме нарезать, а не полную раскадровку делать. Либо как-то кадры расгруппировать по ((quality)) в концепты и настраивать это уже так, чтобы не очень удачные кадры слабее влияли на результат обучения - хотя, может результат обучения чисто по условным top 50 кадрам будут лучше, я такое не пробовал тестировать.
Наверное неудобно с такими ногами, как на сиде 3 справа.
Куда ваш перекатчик пропал, кстати?
>Мне кажется, что может скорее иметь смысл именно качественных фреймов с аниме нарезать, а не полную раскадровку делать.
Да, я как бы это и имел ввиду. Скажем персонаж с разных ракурсов за серию появляется и достаточно по одному с фрейма. Я как-то так и хотел.
> Стоит-ли оно того?
арты несколько неудачные, гамма какая-то слишком перенасыщенная/густая что ли. А я б хотел что б как в оригинале было. Слева вариант кажется правильно тени уловил, то что мне нужно было бы, захоти я такую лисичку.
не выходит все равно... блин

Ух, годнота полилася.
>>1271
напиши пожалуйста детально как ты вводил? А то я совсем запарился.
напиши пожалуйста детально как ты вводил? А то я совсем запарился.
> Вот результаты обучения по 600 фреймам с аниме vs по 30 артам от мангаки. Стоит-ли оно того? Нуу, не знаю.
30 пикч отборных красивых, относительно разнообразных - вполне достаточно для качественного обучения. А в анимце уровень рисовки заметно проигрывает, точно не то что нужно не смотря на количество.
> именно качественных фреймов с аниме нарезать, а не полную раскадровку делать
this, причем стоит выбирать необычные (типа 152) и фуллбади, в других костюмах, позах и дополнить ими основной датасет с артами. Число повторений подобрать таким образом чтобы 70% шагов приходилось на Римукоро а остальное на кадры. Алсо можно скриншоты заменить на отборный арт других авторов, выйдет даже интереснее.
Ты про гайд чтоли? Нужно автора расшевелить, он вроде обещал его структурировать по собранному фидбеку, но не похоже. Гриды-примеры лр так вообще треш, ничего не понятно и значения времен старой версии с поломанными тензорами.
> Или каждая пикча должна иметь различные, где-то уникальные теги по возможности?
Лучше так, количество не равно качество, чем разнообразнее тем лучше будет результат и больше гибкость модели а не просто перемешанные копии датасета без возможности ими управлять. Теги важны, офк допускают небольшие волности.
Арты и есть оригинал, но здесь уже вкусовщина, и никто не мешает сделать нужный цвет до или после.
>Гриды-примеры лр так вообще треш, ничего не понятно и значения времен старой версии с поломанными тензорами.
Пиздос, и чо делать нуфагу? Я вот ток вкатываться собираюсь.
Возможно юзать 2 разные карты на одном компе для ии - 3080 и 4090?

nsfw, 1girl, 1boy, sex, from side
AND 1girl, 1boy, (hakurei reimu:1.1), nude, sex, doggystyle, from side
AND 1girl, 1boy, (hakurei reimu:1.1), nude, sex, doggystyle, from side
AND 1girl, 1boy, (hakurei reimu:1.1), nude, sex, doggystyle, from side
AND nsfw, 1boy, nude, penis, standing, from side
Negative prompt: solo, lowres, bad anatomy, bad hands, text, error, missing fingers, extra digit, fewer digits, cropped, worst quality, low quality, normal quality, jpeg artifacts, signature, watermark, username, blurry
Steps: 20, Sampler: Euler a, CFG scale: 7, Seed: 3395608675, Face restoration: CodeFormer, Size: 768x512, Model hash: 7fb9c64bb4, Model: --model-epoch09-full, Latent Couple: "divisions=1:1,1:2,1:2 positions=0:0,0:0,0:1 weights=0.2,0.8,0.8 end at step=20"
Template: nsfw, 1girl, 1boy, sex, from side
AND 1girl, 1boy, (hakurei reimu:1.1), nude, sex, doggystyle, from side
AND 1girl, 1boy, (hakurei reimu:1.1), nude, sex, doggystyle, from side
AND 1girl, 1boy, (hakurei reimu:1.1), nude, sex, doggystyle, from side
AND nsfw, 1boy, nude, penis, standing, from side
Negative Template: solo, lowres, bad anatomy, bad hands, text, error, missing fingers, extra digit, fewer digits, cropped, worst quality, low quality, normal quality, jpeg artifacts, signature, watermark, username, blurry
AND 1girl, 1boy, (hakurei reimu:1.1), nude, sex, doggystyle, from side
AND 1girl, 1boy, (hakurei reimu:1.1), nude, sex, doggystyle, from side
AND 1girl, 1boy, (hakurei reimu:1.1), nude, sex, doggystyle, from side
AND nsfw, 1boy, nude, penis, standing, from side
Negative prompt: solo, lowres, bad anatomy, bad hands, text, error, missing fingers, extra digit, fewer digits, cropped, worst quality, low quality, normal quality, jpeg artifacts, signature, watermark, username, blurry
Steps: 20, Sampler: Euler a, CFG scale: 7, Seed: 3395608675, Face restoration: CodeFormer, Size: 768x512, Model hash: 7fb9c64bb4, Model: --model-epoch09-full, Latent Couple: "divisions=1:1,1:2,1:2 positions=0:0,0:0,0:1 weights=0.2,0.8,0.8 end at step=20"
Template: nsfw, 1girl, 1boy, sex, from side
AND 1girl, 1boy, (hakurei reimu:1.1), nude, sex, doggystyle, from side
AND 1girl, 1boy, (hakurei reimu:1.1), nude, sex, doggystyle, from side
AND 1girl, 1boy, (hakurei reimu:1.1), nude, sex, doggystyle, from side
AND nsfw, 1boy, nude, penis, standing, from side
Negative Template: solo, lowres, bad anatomy, bad hands, text, error, missing fingers, extra digit, fewer digits, cropped, worst quality, low quality, normal quality, jpeg artifacts, signature, watermark, username, blurry
Я мегатупой похоже но я не понимаю что не так делаю???
Извините что задолбал.
Извините что задолбал.
Ставь lr для юнет 2e-4, для текста в 2 раза меньше, постепенно повышай. Выше в треде про настройки есть, оно зависит от множества параметров, в идеале - сделать много вариантов и по ним уже выбрать самый лучший поняв подходящие настройки.
Так я не про генерацию ЛОРЫ я про Latent Couple там такого параметра вроде нет


Повторюсь, я особо не вникал, абсолютно уверен, что что-то неправильно. Дождись того, кому не жалко времени проверить нормально и нахуярить гридов.
А он тебе ответил?
Prompt: nsfw, 1girl, 1boy, sex, from side AND 1girl, 1boy, (hakurei reimu:1.1), nude, sex, doggystyle, from side AND 1girl, 1boy, (hakurei reimu:1.1), nude, sex, doggystyle, from side AND 1girl, 1boy, (hakurei reimu:1.1), nude, sex, doggystyle, from side AND nsfw, 1boy, nude, penis, standing, from side Negative prompt: solo, lowres, bad anatomy, bad hands, text, error, missing fingers, extra digit, fewer digits, cropped, worst quality, low quality, normal quality, jpeg artifacts, signature, watermark, username, blurry Steps: 20, Sampler: Euler a, CFG scale: 7, Seed: 1413753252, Size: 768x512, Model hash: fdd93be86a, Clip skip: 2, Latent Couple: "divisions=1:1,1:4,1:4,1:4,1:4 positions=0:0,0:0,0:1,0:2,0:3 weights=0.2,0.8,0.8,0.8,0.8 end at step=20", VAE: kl-f8-anime2, VAE hash: 9f45927e; 5.02; xFormers: False, Channels Last: True, GPU: NVIDIA GeForce RTX 3090, Driver version: 528.24, Web UI commit hash: ea9bd9fc, k-diffusion commit hash: 5b3af030;
Image Width: 768 px
Image Height: 512 px - там такой промт
Image Width: 768 px
Image Height: 512 px - там такой промт
Суетолог, ты или в том посте вопрошал не про то, или этот зря в свой адрес воспринял.
Потому что на 4 области картинка разбита, ты слепошарый что ли блять?
Уже понял но отчего у меня нагенерить не выходит??? Чего ему не хватает. И извини меня если что.
Начнем с того, что у тебя какая-то залупа вместо модели.
Model: --model-epoch09-full - это что такое вообще?
> this, причем стоит выбирать необычные (типа 152) и фуллбади, в других костюмах, позах и дополнить ими основной датасет с артами. Число повторений подобрать таким образом чтобы 70% шагов приходилось на Римукоро а остальное на кадры. Алсо можно скриншоты заменить на отборный арт других авторов, выйдет даже интереснее.
Как раз думал на днях переработать свой датасет. Спасибо за советы.
В твоих датасетах для персонажей по сколько примерно картинок выходит? Получается, ты разных авторов миксишь?
Это НАИ
Model hash: fdd93be86a - что это за модель?
понял он почему то не применят верные значения Latent Couple: "divisions=1:1,1:2,1:2 positions=0:0,0:0,0:1 weights=0.2,0.8,0.8 end at step=20


В основном 70-150. Для Джессики (грустнокошка пикрелейтед) что в прошлых тредах как пример выкладывал было 50 штук и норм получилось. Там вообще был ленивый сбор граббером с буры по тегу персонажа +1girl с небольшой сортировкой и обрезкой/замазкой неподходящих. Собираюсь попробовать около 400-800 штук но с 1 повторением на эпоху, но проблема в том что такое сортировать тяжело.
> Получается, ты разных авторов миксишь?
Смотря какова задача, если просто делать персонажа в стиле модели и с возможностью применять еще стили то лучше так, максимальное разнообразие. Офк всяких чиби и некрасивых отсеять.
Только если в конфиге есть выбор устройства

Сам датасет для понимания насколько он может быть пиздецовым те ссылки наверно уже протухли.
настройки обучения>>правильное теггирование>использование модельи>>разнообразие датасета>>качество датасета>>>>большое количество пикч
Должно быть divisions=1:1,1:4,1:4,1:4,1:4 positions=0:0,0:0,0:1,0:2,0:3 weights=0.2,0.8,0.8,0.8,0.8 end at step=20 но он дает divisions=1:1,1:2,1:2 positions=0:0,0:0,0:1 weights=0.2,0.8,0.8 end at step=20 - то есть он отсекает часть чисел... Не понимаю с чем связано?
Ты их до квадрата не кропаешь, выходит? Скрипты тогда обрезают картинку или белый фон по краям накидывают?

Кропнуты только те где персонаж далеко или есть еще что-то что может потенциально мешать. Скрипт сам ресайзит и немного обрезает, используя разные соотношения сторон на 0.25 мегапикселя.
Ага, я просто помню, что, в части оригинальных картинок в моём датасете, персонаж далеко от центра экрана стоит, поэтому поинтересовался, как скрипт этот момент обрабатывает. Значит, всё подряд можно не кропать вручную, это полезная инфа, спасибо.




Мда что то пока не выходит. Хотя Ближе.

То есть на жиывх фото
nsfw, 1girl, 1boy, sex, from side
AND 1girl, 1boy, (hakurei reimu:1.1), nude, sex, doggystyle, from side
AND 1girl, 1boy, (hakurei reimu:1.1), nude, sex, doggystyle, from side
AND 1girl, 1boy, (hakurei reimu:1.1), nude, sex, doggystyle, from side
AND nsfw, 1boy, nude, penis, standing, from side
Не работает?
nsfw, 1girl, 1boy, sex, from side
AND 1girl, 1boy, (hakurei reimu:1.1), nude, sex, doggystyle, from side
AND 1girl, 1boy, (hakurei reimu:1.1), nude, sex, doggystyle, from side
AND 1girl, 1boy, (hakurei reimu:1.1), nude, sex, doggystyle, from side
AND nsfw, 1boy, nude, penis, standing, from side
Не работает?
>AND 1girl, 1boy, (hakurei reimu:1.1), nude, sex, doggystyle, from side
почему только 3 раза повтор, надо 4

Дружище, ты...
ну ты и гиена, тварь ебаная, я больше не буду тут писать из-за таких токсичных тваребасин как ты
Интересно, что за болезнь у человечка выше и из какого раздела пикабу он вылез. Теперь и там срать начал, да еще так криворуко, как я почти никогда не видел.
Господи, блять... И смешно и страшно.
Господи, блять... И смешно и страшно.
Можешь два инстанса запустить для двух разных карт.
Я просто блять не знаю, есть аноны которые тренят? Подскажите как блять все нормально сделать. Скиньте кто как тренит.
просто берешь и тренишь
У меня тоже не получается нормально обучить LORA
Было бы не плохо если бы был подготовленный датасет с параметрами обучения из которого гарантированно получается хорошо работающая модель LORA
Было бы не плохо если бы был подготовленный датасет с параметрами обучения из которого гарантированно получается хорошо работающая модель LORA
Потому что маинтейнер отказывается признавать дробные соотношения. А они работают. Фигачь 1:1.667 или что-то такое и будет тебе две неравных области. Там есть кнопка типа Visualize, она покажет области наглядно.
С какими тегами обучаться на персонажах из черно белой манги?
dolboeb, zaebal, autist_(dvach), slavik, nolife, helpme.
Ну понятно все с двачем
Нужно ли апскейлить изображения если они в 1 из размерностей меньше 512 пикселей или лора их и так примет? И Как это может повлиять на результат
Не нужно. Скорее никак не повлияет.
чем они от цветных кроме цвета отличаются, шизло?
Какие у тебя настройки тренировки? Интересуют скорости, повторения, эпохи и начальная модель.
Почитай тред. Много уже кто скидывал как.
Да и базовых хватает. Разве что dim до 32 лучше снизить где-то. Можно и до 4, но 32 золотая середина, если только начинаешь тренировать. 128 слишком жирно и редактируемость зачастую страдает.
Хотя у каждого свой вкус. Встречал гайд, где предлагают юзать dim 128 alpha 128, lr = 15e=5
Так же как и написано на бурах\тебе автоматически протегал wd
привет
>128 слишком жирно и редактируемость зачастую страдает.
Откуда это пошло вообще? Тренировал на 128, и всё отлично редактировалось.
Редактируемость от датасета зависит, от тэгов, и от перетренировки. dim тут ни при чем совершенно.
Я тоже так делал, но на 32 стало намного лучше. Меньше деталей лишних, редактируемость выросла все же. 128 отлично для стилей, но не персонажей, где ты используешь дата-сет из 10-30 пикч.
У лопухов бомбит с 128 потому что они много весят. На деле с 128 только лучше все.
Скинь свой любимый конфиг для обучения с dim128. Попробую на нем что-то сделать. У меня дата-сет крайне ограниченный и никак не выходит нормально что-то сделать с ним.
>Скинь свой любимый конфиг для обучения с dim128
ну например один из рабочих на сете до 50 картинок
!accelerate launch \
--num_cpu_threads_per_process 8 train_network.py \
--network_module=networks.lora \
--pretrained_model_name_or_path="/content/drive/MyDrive/15.ckpt" \
--train_data_dir="/content/drive/MyDrive/sd/dataset/sincos" \
--reg_data_dir="/content/drive/MyDrive/sd/dataset/sincos_reg" \
--output_dir="/content/drive/MyDrive/sd/stable-diffusion-webui/models/Lora/" \
--caption_extension=".txt" \
--prior_loss_weight=1 \
--resolution=512 \
--enable_bucket \
--min_bucket_reso=320 \
--max_bucket_reso=960 \
--train_batch_size=4 \
--learning_rate=4.416e-3 \
--unet_lr=4.416e-3 \
--text_encoder_lr=4.416e-3 \
--max_train_epochs=250 \
--mixed_precision="fp16" \
--save_precision="fp16" \
--use_8bit_adam \
--xformers \
--save_every_n_epochs=50\
--save_model_as=pt \
--clip_skip=1 \
--seed=1 \
--network_dim=128 \
--network_alpha=1 \
--max_token_length=225 \
--cache_latents \
--lr_scheduler="cosine" \
--lr_scheduler_num_cycle=1 \
--output_name="sincoslora" \
--shuffle_caption \
--keep_tokens=1 \
# --lr_warmup_steps= 40 \
> --max_train_epochs=250
Это для дримбух-лоры?
Поддвачну, все правильно. Алсо разницы с 64 особо не заметил но ставлю 128 ибо БОЛЬШЕ НЕ МЕНЬШЕ А ВДРУГ СЫГРАЕТ
О, у тебя тоже высокий лр, таки интересно
> --max_train_epochs=250 \
12.5к шагов даже если 1 повторение, ахуеть, и где свитспот выходит?
> --clip_skip=1 \
Не анимцо?
>num_cpu_threads_per_process 8
Вот это что такое? Сколько ставить если у меня 8 ядер 16 потоков?
> у меня 8 ядер 16 потоков
Всем поебать. Ставь сколько видеокарт у тебя есть.
Господа, мы тонем.
Но написано цпу…
> написано
На заборе хуй написано, а там дрова лежат. Ну и ты слово следом за cpu видишь какое?


Обучил на Боджека
Вижу. У меня 16 threads у процессора, что дальше?
Да это только если ты юзаешь проц вместо видухи. Забей. Хоть 1 ставь, хоть 16, все равно игнорируется.
Делал начиная с 32 до 256 и вообще разницы не заметил никакой, один хуй не могу свитспот поймать, из аниме ебал ебала сразу в труху...
Подскажите плз как обновлять автоматик и стоит ли вообще?


Вбил твои настройки. Только вместо 250 эпох сделал 8 повторений на 12 эпох. Не знаю что за хуйня, но - хуйня. Супер жесткий перетрен. 40 пикч было.
На 4 эпохах еще более или менее рабочее вышло.
Какая-то жеская хуйня, видимо существует еще какая-то настройка, о которой умалчивают те, у кого успешно тренится, не считая ее важной...
Я тоже не могу получить нормальную лору.
Анон, дай рабочий пример конфиг+датасет+готовая лора+результат пикча с использованием лоры, все на обычном наи или any4.0, чтобы повторить локально у себя то же самое попытаться.
Вообще ничего путного по гайдам не получается, кривые ебала перманентно, от числа повторов и скорости обучения зависит только время и переход из аниме в кривые ебала, без вменяемого промежуточного результата...
Вообще ничего путного по гайдам не получается, кривые ебала перманентно, от числа повторов и скорости обучения зависит только время и переход из аниме в кривые ебала, без вменяемого промежуточного результата...



Хочу из этого сделать ЛОРУ потом отпишусь что вышло. Кто там БЛ занимается могу скинуть пусть выкладывет.
А у тебя что за дата сет?
Я на эту куклу убил уже 11 попыток. Хотя зачастую делаю штуки 3 и первая оказывается лучше всего.

Вот что можно в это поле писать? Я посмотрел гайды и так и не понял.
Где-то было дохуя, но нашел лишь вот это
https://mega.nz/folder/RQg0QDoT#zAejhyg-ZyCx8zSr6z0yRw
Тут для очень старой версии скрипта видимо, без альфы и с 768 разрешением.
это чтобы настройки применить чужие але блять че тупишь так
Ребят, а вы че лоры на весе 1 юзаете по дефолту чтоли? Вы в курсе что условная перетрен лора будет работать на весе скажем 0.05?
В курсе, но толку от этого немного.
А скрипту не надо до 512 кропать картинки?
Да нет. Я всего гоняю лишь на 0.7. Хотя сейчас набегут и будут говорить, что правильная, ИСТИННАЯ лора на 1.25 должна хорошо отрабатывать, а если нет, то говно-лора и такая не нужна.
Можно не кропать. Есть проблема, когда ты не кропаешь пикчи и потом ноги-руки хреного совмещаются при генерации, но это не у всех и не всегда.
Скидывай. Еще раз попробую интегрировать в лору с Юлей.


>Какая-то жеская хуйня, видимо существует еще какая-то настройка, о которой умалчивают те, у кого успешно тренится, не считая ее важной...
>
>Я тоже не могу получить нормальную лору.
Хз че у вас не так, у меня с самой первой лоры все отлично делается вообще на любых настройках, ориентируюсь чисто по времени тренировки на колабе - если минут 20-40 трениться будет то заебись.
>дай рабочий пример конфиг+датасет+готовая лора+результат пикча с использованием лоры
конфег можно ебнуть 128 дим
!accelerate launch \
--num_cpu_threads_per_process 8 train_network.py \
--network_module=networks.lora \
--pretrained_model_name_or_path="/content/drive/MyDrive/15.ckpt" \
--train_data_dir="/content/drive/MyDrive/sd/dataset/sincos" \
--reg_data_dir="/content/drive/MyDrive/sd/dataset/sincos_reg" \
--output_dir="/content/drive/MyDrive/sd/stable-diffusion-webui/models/Lora/" \
--caption_extension=".txt" \
--prior_loss_weight=1 \
--resolution=512 \
--enable_bucket \
--min_bucket_reso=320 \
--max_bucket_reso=960 \
--train_batch_size=8 \
--learning_rate=8e-4 \
--unet_lr=8e-4 \
--text_encoder_lr=8e-4 \
--max_train_epochs=100 \
--mixed_precision="fp16" \
--save_precision="fp16" \
--use_8bit_adam \
--xformers \
--save_every_n_epochs=10\
--save_model_as=pt \
--clip_skip=1 \
--seed=1 \
--network_dim=32 \
--network_alpha=1 \
--max_token_length=225 \
--cache_latents \
--lr_scheduler="cosine" \
--lr_scheduler_num_cycle=1 \
--output_name="sincoslora" \
--shuffle_caption \
--keep_tokens=1 \
# --lr_warmup_steps= 40 \
датасет https://pornolab.net/forum/viewtopic.php?t=2893680 + пикчи с инсты
пак эпох лор (рабочая на 60 эпохе) https://drive.google.com/drive/folders/1SBKky3B3DUTuJ50EMbAxj2tk2fmG0Plo?usp=share_link
Тег вызова sharisha
результаты на пике + тест со свиньей (анончик в прошлом треде подсказал что генерация со свиньей тестит качество тип если ебало свиньи остается свиным а ебало модели модельной то все ок) для каждой эпохи и в прошлом треде еще лежит пара картинок
Я сетку строю на 0.3 0.7 1.0 но все равно ловлю переход аниме -> кривое ебало.
А ты с хайресфиксом генеришь пикчи?
Может я тупой и единственный из всех в треде пытаюсь лору использовать без хайресфикса?
Просто с ним-то я результат получаю, но мне не нравится хайресфикс по другим причинам.
>А ты с хайресфиксом генеришь пикчи?
Без
>датасет https://pornolab.net/forum/viewtopic.php?t=2893680 + пикчи с инсты
Фул датасет с тхт https://drive.google.com/drive/folders/1BabHgVPWtzzJamCx-6fCr-xaV_xF6HYR?usp=share_link
Если делаешь анимцо на аниме модели то какой еще клипскип 1? Оно и будет ломаться так.
А батч сайз выставлен? Лр для текста в 2 раза снизить пробовал?
Норм лора не даст такое распидорашивание даже при весе 1
> перетрен лора будет работать на весе скажем 0.05
Но будет довольно таки хуево
Оно вообще и так и так работать должно
> не нравится хайресфикс по другим причинам
А почему? Как пикчи апскейлишь?
>А почему?
Медленно, на некрокартах не имеет смысла из-за OOM
>Как пикчи апскейлишь?
UU
тож не люблю хуйрес
>Но будет довольно таки хуево
Да нет, норм.
Как работать с reg пикчами?
И в чем отличие обучение ЛОРЫ на Художника а не на Персонажа?
То есть я имею ввиду на работы художника.
То есть я имею ввиду на работы художника.
Не юзаю, они не обязательны
Ну вообще рег пикчи это типа датасета для датасета, генеришь условные 100 изображений woman если тренишь тян на базовой модели, суешь в реги, както так эта хуйня работает, есть готовые датасеты регов есличе лежат на хагинфейсе и гитхабе
И в чем отличие обучение ЛОРЫ на Художника а не на Персонажа?
У художника пиздишь illustration style
При обучении на художника в датасете разные персонажи но один художник.
При обучении на персонажа в датасете один персонаж но один или разные художники.
Поидее логично в датасетовых промтах будет размещать спереди имена персонажей, художника, с соотв. keep_token в длину тега персонажа и художника.
Вообще канеш хуиту с токенами придумали, вот бы жосткие теги с бур иметь в качестве обучения, через _, железно.
> батч сайз выставлен
Блять забыл
Для стиля больше пикч надо. Скорость повыше.
Я знаю, но интересно
Тоесть я генерю дефолтную тян на этой модели в папку reg, а а датасет пихаю желаемую тянку по тому же промту?
>Тоесть я генерю дефолтную тян на этой модели в папку reg, а а датасет пихаю желаемую тянку по тому же промту?
Ну вот в гайде написано как: Например, если вы тренируете лицо человека (мужчины) и в каждом файле описания есть слова photo of a PersonName, хорошей идеей будет открыть WebUI и нагенерировать изображений по запросу photo of a man. Сколько? Не меньше чем количество изображений лица мужчины из примера. Больше – лучше.
Запаситесь папками с двухстами изображениями 1boy, 1girl, photo of a man, photo of a woman и будет вам счастье.
А что если у меня промт сложнее, чем 1girl?
>Для стиля больше пикч надо. Скорость повыше.
то есть выше чем 10???
под основные чанки реги делай
Спасибо!
Хотел на рисунках Шубиной обучить если знаете ее.
Хотел на рисунках Шубиной обучить если знаете ее.
А, окей. Надо попробовать
Ну... 1e-3 где-то. То есть 0.001, если ты про скорость.
Если по пикчам, то штук 100-150 как по мне, чтобы нейронка поняла, что от нее требуется не деталь персонажа скопировать, а общие черты.
Почему-то никто не пишет прямо, но это работает так:
датасет:
пик_1.жпг
пик_1.тхт
пик_2.жпг
пик_2.тхт
итд
в пик_1.тхт:
если треним стиль/автора:
уникальный_токен_лоры_определяет_общий_стиль_берем_отсюда_https://github.com/2kpr/dreambooth-tokens/blob/main/all_single_tokens_to_4_characters.txt_какой_нравится, все остальные токены описывающие картинку через запятую (1girl, standing, blone hair, pubic hair, medium breasts и т.д.)
в конфиге скрипта:
keep_tokens = длина_уникального_токена_лоры
если треним персонажа:
все то же самое, но уникальный токен выбираем для персонажа и так же прописываем первым. Либо можно в качестве уникального токена использовать реальный тег имени персонажа, и выставить keep_tokens = длина имения перса в токенах.
Можно тренить сразу несколько персов одновременно, раздав им по уникальному токену и прописав их через запятую в начале тхт и обязательно задав keep_tokens = длину токенов. При этом на тех пикчах, где какого-то из персов нет, можно просто дублировать и чуть ослабить токены перса, например, (cirno), (cirno), чтобы keep_tokens соблюсти для всех пикч. Но это ебать неудобно, нужен инструмент прямого указания в промтах датасета какие токены удерживать, а какие рандомить. Потому все же рекомендуется использовать один общий токен на одну лору.
Ну я так и делаю. Мне непонятны только reg пикчи. С ними нормальная лора становится нерабочей на том же датасете.


<lora:es-000009:1> es, 1boy, full size - сгенерил а фон не подставляет. Почему?

Не понимаю
> keep_tokens = длина_уникального_токена_лоры
А на реддите писали что там не длина токена а число тегов, отделяемых запятыми, где правда?
У тебя там негативы вообще есть? Почему такое странное разрешение?
es, 1boy, full size <lora:es:1>
Negative prompt: (makeup), (milf), (porn), (glamour), (instagram),(monochrome), (orgy), (homo), (multiple girls), (multiple boys), (duplicate), (sfw), (censorship), extra fingers, mutated hands, (bad eyes) (poorly drawn hands), (mutation), (deformed), (bad anatomy), (bad proportions), (extra limbs), cloned face, (disfigured), extra limbs, (malformed limbs), (missing arms), (missing legs), (extra arms), (extra legs), mutated hands, (fused fingers), (too many fingers), (long neck), text, logo, blood, animal, pig, long neck, deformed ears, (futa), lowres, (bad anatomy), (bad hands), text, error, (missing fingers), extra digit, fewer digits, cropped, worst quality, low quality, normal quality, jpeg artifacts, signature, watermark, username, blurry, (child), (loli), (old), (ugly)
Steps: 20, Sampler: DPM++ 2M Karras, CFG scale: 7, Seed: 2827059742, Face restoration: CodeFormer, Size: 512x512, Model hash: a7529df023, Model: animefull-latest, Denoising strength: 0.51, Hires upscale: 1.8, Hires upscaler: Latent
Negative prompt: (makeup), (milf), (porn), (glamour), (instagram),(monochrome), (orgy), (homo), (multiple girls), (multiple boys), (duplicate), (sfw), (censorship), extra fingers, mutated hands, (bad eyes) (poorly drawn hands), (mutation), (deformed), (bad anatomy), (bad proportions), (extra limbs), cloned face, (disfigured), extra limbs, (malformed limbs), (missing arms), (missing legs), (extra arms), (extra legs), mutated hands, (fused fingers), (too many fingers), (long neck), text, logo, blood, animal, pig, long neck, deformed ears, (futa), lowres, (bad anatomy), (bad hands), text, error, (missing fingers), extra digit, fewer digits, cropped, worst quality, low quality, normal quality, jpeg artifacts, signature, watermark, username, blurry, (child), (loli), (old), (ugly)
Steps: 20, Sampler: DPM++ 2M Karras, CFG scale: 7, Seed: 2827059742, Face restoration: CodeFormer, Size: 512x512, Model hash: a7529df023, Model: animefull-latest, Denoising strength: 0.51, Hires upscale: 1.8, Hires upscaler: Latent
> А на реддите писали что там не длина токена а число тегов, отделяемых запятыми, где правда?
Ну вообще хуй знает, но все таки название keep_tokens, а не keep_tags.
Да, это и смущает, но вроде как сам kohya это писал, хуй знает. Сейчас сходу ссылка не находится
Я тренил персонажей с первым тегом из пяти слов, и вроде нормально получалось с keep = 1.
так в чем у меня проблема?
Таблетки, таблетки забыл!
Если все теги помещались, или было обрезано их незначительное количество то даже и не заметишь.
> (makeup), (milf), (porn), (glamour), (instagram),(monochrome), (orgy), (homo), (multiple girls), (multiple boys)
> (futa)
> error
> 10 дубликатов одного и того же в разных вариациях
Хм, что же здесь не так
Оставь только (worst quality, low quality:1.2) в негативах, снизь вес лоры до 0.7, подними денойз до 0.6 и скинь хотябы 4 пикчи результатов
нужен дебажный вывод промта во время тренировки чтобы точно сказать.
Но по смыслу shuffle_caption перемешивает именно теги, т.е. поидее keep_tokens = 1 означает лишь то, что при shuffle_caption = true первый тег не будет перемешиваться и всегда будет впереди.
Автор конечно мудило тот еще...







Попробовал еще раз. Пикчи с фонами не тегаю, лишь один токен стоит в txt. Не выходит. Только по отдельности, если совмещаю, то либо ничего, либо пытается деревья рисовать даже при (токен:1.2).
Опробую протегать все же.


На реалистичной модели вышло забавно.

Каким лучше тегать, какой трешхолд выставлять?
это не с моей ЛОРЫ?








Тредом ошибся?
Какой твоей?
Скачал пак фонов архивом из оригинальной игры.
Предпочитаю convnext 0.35. Про -v2 и -2-git даже не знал.
Пирожочки, есть у кого апскейлеры NMKD, хотел Siax попробовать?
На https://upscale.wiki/wiki/Model_Database все ссылки на апскейлеры от данного чела (NMKD) мертвые.
На https://upscale.wiki/wiki/Model_Database все ссылки на апскейлеры от данного чела (NMKD) мертвые.
Они все каловые.
Пример параметров обучения lora от анона с 4chan и там же ссылка на датасет
https://huggingface.co/khanon/lora-training/blob/main/junko/README.md
https://huggingface.co/khanon/lora-training/blob/main/junko/README.md

В очередной раз ахуеваю с гения автоматика - в forward семплера парсится промпт. Ебал его китайский рот. Проще этот кал полностью переписать, чем экстеншон запилить.
Было?
Error loading script: two_shot.py
Traceback (most recent call last):
File "C:\Users\user\git\stable-diffusion-webui\modules\scripts.py", line 229, in load_scripts
script_module = script_loading.load_module(scriptfile.path)
File "C:\Users\user\git\stable-diffusion-webui\modules\script_loading.py", line 11, in load_module
module_spec.loader.exec_module(module)
File "<frozen importlib._bootstrap_external>", line 883, in exec_module
File "<frozen importlib._bootstrap>", line 241, in _call_with_frames_removed
File "C:\Users\user\git\stable-diffusion-webui\extensions\stable-diffusion-webui-two-shot\scripts\two_shot.py", line 11, in <module>
from modules.script_callbacks import CFGDenoisedParams, on_cfg_denoised
ImportError: cannot import name 'CFGDenoisedParams' from 'modules.script_callbacks' (C:\Users\user\git\stable-diffusion-webui\modules\script_callbacks.py)
Error loading script: two_shot.py
Traceback (most recent call last):
File "C:\Users\user\git\stable-diffusion-webui\modules\scripts.py", line 229, in load_scripts
script_module = script_loading.load_module(scriptfile.path)
File "C:\Users\user\git\stable-diffusion-webui\modules\script_loading.py", line 11, in load_module
module_spec.loader.exec_module(module)
File "<frozen importlib._bootstrap_external>", line 883, in exec_module
File "<frozen importlib._bootstrap>", line 241, in _call_with_frames_removed
File "C:\Users\user\git\stable-diffusion-webui\extensions\stable-diffusion-webui-two-shot\scripts\two_shot.py", line 11, in <module>
from modules.script_callbacks import CFGDenoisedParams, on_cfg_denoised
ImportError: cannot import name 'CFGDenoisedParams' from 'modules.script_callbacks' (C:\Users\user\git\stable-diffusion-webui\modules\script_callbacks.py)
Да, автор криворукое хуйло, надо файлы автоматика патчить чтоб эта дрисня заработала.
Блять, датасет бы еще туда для наглдяности с текстовиками тэгов. Этож чуть ли не самое важное.
Привет! Так в чем у меня проблема?
Ты пидор.
Там есть ссылка на датасет с тегами в самом низу страницы
> Dataset can be found on the mega.co.nz repository
Да, я уж нашел, но написать забыл.

Чем замазывать диалоги, сразу скажу нейрошуму нейронка обучаеться, если чёрным замазать то норм? Или достаточно протегать такие пикчи где замазано и потом в негатив засунуть?
Почему на цивитаи у большинства лор стоит исходная модель сд 1.5? Кто на ней тренил персонажей (аниме/игры имеются в виду, не ирл), в чем секрет? У меня на НАИ тренириуется из коробки, с хорошими результатами, но когда запускаю с теми же настройками на СД, вообще ничего не получается, буквально, даже отдаленно похожего. Юзаю v1-5-pruned-emaonly.ckpt, мб это не то?
Там просто другую не указать




Пытался делать ЛОРУ по фонам из Бесконечного Лета пока добился такого.
Как по мне ничего замазывать не надо. Просто чтобы были теги вроде speech_bubble, comic, flashback, а потом их добавить в негатив при генерации.






Да я по гайду читал что вроде нужно замазывать то что не нужно, теперь если добавить много лоры то будет как на 2, к счастью сразу на 3 рисоваках тренил, и много исправлений было только у 1




Надо, но делать это органично. Если есть возможность - фотошопом делаешь заливку с учетом содержимого. Если у тебя нет возможности сделать красиво, а эта пикча нужна и без нее никак, то оставляешь.
То есть, например, из первый пикчи ты ничего не вытащишь. Лучше от нее отказаться.
Из второй лучше оставить как есть, ибо исправления затрагиваю волосы и руки.
Третью - лучше отредактировать до состояния четвертой

У него все такие, только единицы возможно отредачить до состояния 4, в целом вообще можно от него отказаться, будет достаточно 2 других, но если бы я хотел обучить лору чисто на него то без понятия как бы можно было это сделать
Геометрия, к сожалению, будет всрата в любом случае.
Попробуй. Мне кажется не выйдет и будет всегда рисовать тебе multiple_girls multiple_views +6girl
Хотя бы отдельные комиксовые блоки раздели на отдельные пикчи.

Ребят, помогите, после того, как лору накатил все съехало.. как пофиксить?
Так, ребзя...
А может быть такое что Anything v4.0 какой-то особенный кривой, и что треня на нем делает хуевую лору?
Я попробовал чисто на наи сделать, и вроде как вышло непблохо сразу, а до этого тренил подключая any 4.0 и получал резкий и неустойчивый переход от дефолтного наи на пережареные ебала сколько бы шагов и повторов ни пытался накрутить.
А может быть такое что Anything v4.0 какой-то особенный кривой, и что треня на нем делает хуевую лору?
Я попробовал чисто на наи сделать, и вроде как вышло непблохо сразу, а до этого тренил подключая any 4.0 и получал резкий и неустойчивый переход от дефолтного наи на пережареные ебала сколько бы шагов и повторов ни пытался накрутить.
Хм, неплохой способ обезопасить себя от нейроворишек, просто вкатывать в пикчу кучи текста с пузырями...
> А может быть такое что Anything v4.0 какой-то особенный кривой
А может быть иначе?
А можно как ueda hajime не разбрасываться своим стилем, нашёл 46 пикч от него и в похожем стиле, и всё, причём все разные так что хуй на них что то обучишь
Ну мне пиздец нравится как оно в дефолте рисует, вот и пытался лору на Ане 4.0 сделать, думал лучше будет...
Ты юзал именно 4 или 4.5, потому что 4 полный кал
46 должно вполне хватать.
Я ебало и комплекцию бывшей на 12 обучил, теперь твою все свои грязные фантазии с ней и шлю в телегу её текущему хахалю, а он только ещо просит.
Тренил стиль+концепт на Эни4.5 много раз.
Нормально получалось.
Именно 4, ибо 4.5 не понравилась, 3 тоже.
Напомните, как там случайный тэг из списка взять? Через : же?
Типа, (short hair:long hair)
И можно ли запилить это на группу тэгов?
Типа, (short hair, sidelocks):(long hair:ponytail)
Типа, (short hair:long hair)
И можно ли запилить это на группу тэгов?
Типа, (short hair, sidelocks):(long hair:ponytail)
Напомните, как там случайный тэг из списка взять? Через : же?
Типа, (short hair:long hair)
И можно ли запилить это на группу тэгов?
Типа, (short hair, sidelocks):(long hair,ponytail)
Типа, (short hair:long hair)
И можно ли запилить это на группу тэгов?
Типа, (short hair, sidelocks):(long hair,ponytail)
в смысле случайный? случайный это через мокрописьки с вилдкартами, а [chunk:chunk:шаг] и [chunk|chunk] это морферы
чтобы случайно примнялся тот или другой тег. чтобы было разнообразие в выдаче и не надо было перетряхивать промты чтобы поменять девочку, а просто включить, нажать кнопку и драчить
Wildcards
Если у меня карта батч больше 1 не тянет, сколько ставить повторений на картинку на датасете из 30?
В прямом. Чтоб записать набор, и он мне из этого набора чего-нибудь выдавал.
Типа того, да.
Я не нашел, как там это реализовать.
Можно в текстовый файл положить набор тэгов, и вызывать его одним словом через двойное подчеркивание - это да. Это удобно.
А вот чтоб оно случайно перебирало - это нет. Ну или я тупой.
Вайлдкарта вызывает случайную строку из этого файла. Перенос строки на энтер если что.
Ставишь Wildcards, вообще ничего не трогаешь в нем, по умолчанию он уже включен. Пишешь прямо в промт что-то вроде ({bedroom|street|town, building, castle|outdoors| |forest, feet}). Все, работает.
Ставлю обычно 8-12. Зависит от дата сета. Иногда ставил 20. иногда 6.
А эпох?
Блин, наебал тебя. Вот это имел ввиду.
https://github.com/adieyal/sd-dynamic-prompts
8-12 так же, с запасом. Обычно самая нормальная 6-8 в итоге выходит.
Ага, это работает.
Как раз то, что надо.
Тьфу, не тому ответил =)
Вот это работает как раз так, как мне нужно.
А как правильно тегировать датасет для стиля?
Так же, как и любые другие пикчи
Для аниме выбирай wd-1-4 tagger выбирай и convnext
Для не аниме вроде CLIP, который есть по стоку в webui
Я понимаю, но если условно в персонаже я обычно убираю все вещи котоыре описывают персонажа что бы оно все впиталось в его тег. То как тут делать?
Мне кажется лучше полностью тегать, чтобы потом убирать можно было через не использование этих тегов.
Ну попробуй, потом отпишись.


Вот так пытался повторить стиль художника Deaver. Вторая картинка от художника. Еще есть проблема что у художника все арты с кошкодевками


Учил на Шубиной... Вышло вот так


Почему то работает только в одной модели.


3d на такой модели похоже просто не сделать.

В чем может быть проблема когда модель после мерджа выебывается пиком?
Через Difference? Вычел не то.
Для стиля тэги как обычно ставишь. Можешь дополнительный тэг проставить на имя автора, но он все равно влияния не даст практически никакого.
Если автор рисует только кошкодевок - в итоге это впечатается в стиль намертво, и сетка будет тебе кошкодевок по-дефолту выдавать. Тут даже негативы могут не помочь, потому что стиль автора будет с кошкодевками ассоциироваться, и негатив будет что-то от этого стиля убирать.
Еще заметил, что очень хорошо тренируется стиль, отличающийся от исходников того, что сетка умеет делать "из коробки". А если входные данные не слишком отличаются - то стиль автора затирается самой сеткой.

Так, я проснулся через неделю, и у меня все еще эта проблема. Что за своп и как его увеличить, если на языке для совсем овощей?
Файл подкачки windows гугли
Ставь минимум 30гб на ssd
Я с коллаба, в том то и дело. На нем можно файлы подкачки увеличить? Путем поиска в гугле мне вообще что-то про память процессора выдавало, но хз, я там так ничего и не понял.
Высер - это то что выпало из твоей мамаши, когда тебя рожала.

знает кто как фиксить данную хуйню кога грузишь кривые модели? потом просто автоматик отказывается работать и нужно релоад делать




Переделал лору, сделал теги на шум от замазки, и это сработало, aiu тут выглядит хуёво так как сделал :1.4 если уменьшить веса то как на 2-3 пикчах, но теперь не могу получить хуёвые линии как на 4




Ебать, до сих пор не перекатили. Че нового за две недели?
оп
оп

Что это такое и как это победить?
Пытаюсь через Additional Networks свои лоры протэгать и рассортировать, и оно вот такую фигню выводит.
Пытаюсь через Additional Networks свои лоры протэгать и рассортировать, и оно вот такую фигню выводит.
UPD:
Обновил автоматик, обновил экстеншн, перезагрузился, теперь работает.
Все, я сдался.
Ничего с лорами не получается нормального.
Нихера нет свит спотов. дефолт дефолт а потом сразу ебало и пикча в мясо и кашу. клипскип 1 или 2, наи или другие модели, всё похуй. Большой лр, малый, тоже похуй, влияет лишь на то, на какой эпохе произойдет разрыв картинки в мясо. Число повторов шагов так же не влияет, только на время этой бесполезной хуйни, уже на 6+ часов десятки тысяч повторов ставил, похуй, так же разрыв в мясо.
Это все без хайресфикса. хайресфикс лечит, и даже выходит похоже, но он убивает детализацию на картинке, плодит чешую и мыло...
Ничего с лорами не получается нормального.
Нихера нет свит спотов. дефолт дефолт а потом сразу ебало и пикча в мясо и кашу. клипскип 1 или 2, наи или другие модели, всё похуй. Большой лр, малый, тоже похуй, влияет лишь на то, на какой эпохе произойдет разрыв картинки в мясо. Число повторов шагов так же не влияет, только на время этой бесполезной хуйни, уже на 6+ часов десятки тысяч повторов ставил, похуй, так же разрыв в мясо.
Это все без хайресфикса. хайресфикс лечит, и даже выходит похоже, но он убивает детализацию на картинке, плодит чешую и мыло...
Соболезную тебе, ты что-то делаешь не так.

Пытаюсь по гайду из шапки делать лору. Почему когда нажимаю Create то ничего не происходит?
все пофиксил, переустановив
А почему на последнем шаге во время генерации пикчи может изображение ломаться?

Накатил последние xformers с торчем, эта хуйня пиздец заебала. Как фиксить?
В __init__.py xformers поменял _is_triton_available, убралось кто бы мог подумать
Если я хочу научить сеть рисовать лицо своей учительницы, что мне лучше использовать для обучения? Lora, embedning или hypernetwork?
Борда 18+
Смешно, я закончил школу 10 лет назад
Кати давай.
Lora.
Exception training model: 'Accelerator.unwrap_model() got an unexpected keyword argument 'keep_fp32_wrapper''.
после обучения лоре вылезла ошибка, чяднт?
после обучения лоре вылезла ошибка, чяднт?
Чем смотреть логи loss'а лоры? У меня на второй эпохе случается loss=Nan, на первой все ок вроде бы

Я извиняюсь, но из шапки не совсем понятно. Что следует скачать нуфаку, чтобы натренировать сетку на какой-нибудь аниме стиль? Какую сетку? Где?
Заранее спасибо.
Заранее спасибо.







Вот такая ЛОЛА но не все вышло гладко



точно не знаю почему так




Вопрос - на сколько максимум персонажей можно натренить одну лору? 10? 15?
>рабочая на 60 эпохе
Блядь, чел, не позорься нахуй. Я скачал твой высер. Проверил разные эпохи, везде лютое дерьмо. На посторонних моделях так вообще отрицательная схожесть. Включи 1.5, напиши emma watson - вот таким должен быть минимальный результат обучения. На нормальном трейне почти неотличимо от реальных фото. Он сука еще параметры кому-то кидает. Даже на самом уебанском датасете с дефолтными настройками получится втрое лучше.
Криворучка спок
вав
ОП или кто знает, подскажи где схемки рисовали на первом пике из поста?




Тред общенаправленныей, тренировка дедов, лупоглазых и фуррей приветствуются
Предыдущий тред:
➤ Гайды по обучению
Существующую модель можно обучить симулировать определенный стиль или рисовать конкретного персонажа.
✱ Текстуальная инверсия (Textual inversion) может подойти, если сеть уже умеет рисовать что-то похожее:
https://rentry.org/textard (англ.)
✱ Гиперсеть (Hypernetwork) может подойти, если она этого делать не умеет; позволяет добавить более существенные изменения в существующую модель, но тренируется медленнее:
https://rentry.org/hypernetwork4dumdums (англ.)
✱ Dreambooth – выбор 24 Гб VRAM-бояр. Выдаёт отличные результаты. Генерирует полноразмерные модели:
https://github.com/nitrosocke/dreambooth-training-guide (англ.)
✱ LoRA – "легковесный Dreambooth" – подойдет для любых задач. Отличается малыми требованиями к VRAM (6 Гб+) и быстрым обучением:
https://rentry.org/2chAI_LoRA_Dreambooth_guide
✱ Text-to-image fine-tuning для Nvidia A100/Tesla V100-бояр:
https://keras.io/examples/generative/finetune_stable_diffusion (англ.)
Бонус. ✱ Text-to-image fine-tuning для 24 Гб VRAM:
https://rentry.org/informal-training-guide (англ.)
Не забываем про золотое правило GIGO ("Garbage in, garbage out"): какой датасет, такой и результат.
➤ Гугл колабы
﹡Текстуальная инверсия: https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb
﹡Dreambooth: https://colab.research.google.com/github/TheLastBen/fast-stable-diffusion/blob/main/fast-DreamBooth.ipynb
﹡LoRA [1] https://colab.research.google.com/github/Linaqruf/kohya-trainer/blob/main/kohya-trainer.ipynb
﹡LoRA [2] https://colab.research.google.com/drive/1bFX0pZczeApeFadrz1AdOb5TDdet2U0Z
➤ Полезное
Гайд по фиксу сломанных моделей: https://rentry.co/clipfix (англ.)
Расширение WebUI для проверки "сломаных" тензоров модели: https://github.com/iiiytn1k/sd-webui-check-tensors
Гайд по блок мерджингу: https://rentry.org/BlockMergeExplained (англ.)
Гайды по апскейлу от анонов:
https://rentry.org/SD_upscale
https://rentry.org/sd__upscale
Подборка мокрописек от анона: https://rentry.org/te3oh
Группы тегов для бур: https://danbooru.donmai.us/wiki_pages/tag_groups (англ.)
Коллекция лор от анонов: https://rentry.org/2chAI_LoRA (заливать лоры можно сюда https://technothread.space/ пароль 2ch)
Гайды, эмбеды, хайпернетворки, лоры с форча:
https://rentry.org/sdgoldmine
https://rentry.org/sdg-link
https://rentry.org/hdgfaq
https://rentry.org/hdglorarepo
https://gitgud.io/gayshit/makesomefuckingporn
Сервер анона с моделями: https://static.nas1.gl.arkprojects.space/stable-diff/
Шапка: https://rentry.org/ex947
Прошлые треды:
№1 https://arhivach.ng/thread/859827/
№2 https://arhivach.ng/thread/860317/
№3 https://arhivach.ng/thread/861387/
№4 https://arhivach.ng/thread/863252/
№5 https://arhivach.ng/thread/863834/