


>а основной выход изображения через встройку.
Где-то с десятки всё пофиксили, и достаточно просто воткнуть кабель, а выбор видяхи для запуска ПО осуществляется в местной панели управления, что позволяет даже играть без проблем.
>дружбы с серверным оборудованием
Это просто тот же десктоп, просто с немного другими чипсетами. Если не брать двухпроцессорные конфигурации, проблем не будет вообще.
>если количество потоков на проце не решает для llm
Ваще похую на потоки.
>взять 20 слой и напичкать его более большим количеством экспертов
>купил б/у ASUS x99-E WS
Моё уважение
владелец простой ASUS x99-E, который безработный и которому лень брать P40, потому что в первый раз заказ отменили
> можем например взять 20 слой и напичкать его более большим количеством экспертов
Профит с этого какой?
О, кайф, наконец можно будет ясность внести. Сэмулировать х4 шину можно будет просто выставив в биосе ограничение на 1-е поколение протокола, чтобы не сравнивать данные на разном железе.
> и достаточно просто воткнуть кабель
Какой кабель? И куда пихать кабель с теслу?
> тот же десктоп, просто с немного другими чипсетами
Под шинду на теслы-квадры и прочее отдельные драйвера, и они могут конфликтовать друг с другом и требовать вмешательства. Под линукс просто добавляешь репу нвидии и apt install cuda вне зависимости от того что у тебя там.
> →
>>взять 20 слой и напичкать его более большим количеством экспертов
Цитату не забыл, ответ забыл. Нахуя? А главное зачем. Интересно конечно, но звучит по-наркомански.
>Какой кабель?
VGA любой видео.
>куда пихать кабель с теслу
Его нет...
>и они могут конфликтовать друг с другом и требовать вмешательства
Рецепты исправления давно известны.
>Цитату не забыл, ответ забыл. Нахуя? А главное зачем. Интересно конечно, но звучит по-наркомански.
Разумеется сделать сетку умнее и заставить людей покупать новые GPU
Опубликован инструментарий ZLUDA, позволяющий запускать CUDA-приложения на GPU AMD
https://www.opennet.ru/opennews/art.shtml?num=60591
https://www.opennet.ru/opennews/art.shtml?num=60591
> х4 шину
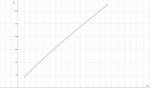
Пересадил 4090 из х16 5.0 в х4 4.0 - ни в угабуге, ни в автоматике изменений нет.
Еле-еле быстрее, не особо впечатляет.
На шинде запустится? Уже бежать за 2х7900хтх?
Так рокм быстрее ж будет, это для страдальцев вариант. И то, неясно, может вулкан быстрее будет ещё.
Поясните нубу, если 120b мутанты такие охуенные, чому их не делают еще больше? Дело только в железе?
Чего-чего? Chat With RTX: собственный чат-бот для ПК с искусственным интеллектом NVIDIA RTX
Техническая демонстрация дает любому, у кого есть графический процессор RTX, возможность персонализированного чат-бота GPT.
Chat with RTX, который теперь можно загрузить бесплатно, представляет собой технологическую демонстрацию, которая позволяет пользователям персонализировать чат-бота с использованием собственного контента, ускоренного локальным графическим процессором NVIDIA GeForce RTX серии 30 или выше и оснащенным как минимум 8 ГБ видеопамяти с произвольным доступом или видеопамятью.
Чат с RTX использует генерацию с расширенным поиском (RAG), программное обеспечение NVIDIA TensorRT-LLM и ускорение NVIDIA RTX для реализации возможностей генеративного искусственного интеллекта на локальных ПК с ОС Windows под управлением GeForce. Пользователи могут быстро и легко подключать локальные файлы на ПК в виде набора данных к большой языковой модели с открытым исходным кодом, такой как Mistral или Llama 2, позволяя выполнять запросы для получения быстрых, контекстуально релевантных ответов.
Вместо поиска по заметкам или сохраненному контенту пользователи могут просто вводить запросы. Например, можно спросить: «Какой ресторан порекомендовал мой партнер, когда он был в Лас-Вегасе?» а Chat с RTX просканирует локальные файлы, на которые указывает пользователь, и предоставит ответ с контекстом.
Инструмент поддерживает различные форматы файлов, включая .txt, .pdf, .doc/.docx и .xml. Укажите приложению папку, содержащую эти файлы, и инструмент загрузит их в свою библиотеку за считанные секунды.
https://blogs.nvidia.com/blog/chat-with-rtx-available-now/
Техническая демонстрация дает любому, у кого есть графический процессор RTX, возможность персонализированного чат-бота GPT.
Chat with RTX, который теперь можно загрузить бесплатно, представляет собой технологическую демонстрацию, которая позволяет пользователям персонализировать чат-бота с использованием собственного контента, ускоренного локальным графическим процессором NVIDIA GeForce RTX серии 30 или выше и оснащенным как минимум 8 ГБ видеопамяти с произвольным доступом или видеопамятью.
Чат с RTX использует генерацию с расширенным поиском (RAG), программное обеспечение NVIDIA TensorRT-LLM и ускорение NVIDIA RTX для реализации возможностей генеративного искусственного интеллекта на локальных ПК с ОС Windows под управлением GeForce. Пользователи могут быстро и легко подключать локальные файлы на ПК в виде набора данных к большой языковой модели с открытым исходным кодом, такой как Mistral или Llama 2, позволяя выполнять запросы для получения быстрых, контекстуально релевантных ответов.
Вместо поиска по заметкам или сохраненному контенту пользователи могут просто вводить запросы. Например, можно спросить: «Какой ресторан порекомендовал мой партнер, когда он был в Лас-Вегасе?» а Chat с RTX просканирует локальные файлы, на которые указывает пользователь, и предоставит ответ с контекстом.
Инструмент поддерживает различные форматы файлов, включая .txt, .pdf, .doc/.docx и .xml. Укажите приложению папку, содержащую эти файлы, и инструмент загрузит их в свою библиотеку за считанные секунды.
https://blogs.nvidia.com/blog/chat-with-rtx-available-now/
> и инструмент загрузит их в
библиотеку хуанга
Китайцы с их 1,08 )))
> кобольдццп фронт и таверна в виде бэкэнда
Звучит наоборот.
> Стоит качать угубугу? Далее подрубить её к exllama2?
Убабуга и содержит экслламу.
Подрубаешь ты все к таверне.
7B модельки, тебе ответили.
Mistral, openchat, что-то там рпшное, не знаю.
Ты или тролль, или не читаешь, что тебе пишут, или глупенький.
Звучит как да.
Ну, тебе линии PCIe не нужны, чисто залить модель туда, а там она сама будет крутиться.
Но вот заведется ли такой бокс с Теслой на ноуте — фиг знает.
Это база.
Ну-у-у… Скорее 7-10… Но в общем, если добирать ссд, бп и корпус, то да, цена дотянется.
Но тут выбор — оно стоит и работает само, или только от ноута.
Я заебался с выводом биоса, в итоге просто взял 11400 с материнкой новые (какие в днсе местном лежали), ради гарантии и все.
Ну и ради 2 слотов PCIe, да.
А как насчет БАСТИОНА, и вообще удобно по RDP по всему дому лазить. =) Подсел.
Хотя лучше VPN на роутере, наверное.
На оперативе можно поднять доп.модельку.
Я вот взял 3600 планки (2*32) и Микстраль иногда 3,5 т/с выдает чисто на проце.
А я уже умею, поэтому похуй на линуху.
Ну я выше кидал способ, который сработал лично у меня, пердолинг там не страшный, вопрос пяти минут.
Но у кого-то он не сработал.
Ну ты силен!
Но я все еще не уверен в пользователях. =)
Но — успехов!
> Какой кабель? И куда пихать кабель с теслу?
Который ты пихаешь в ноутбук. Во встройку.
Да че-б им быть.
Проверять надо на 2-3-4 картах, а на одной их и не будет.
Даже на 2 будет почти незаметно, интересны 3+
И не PCIe 4.0 x4, а хотя бы PCIe 3.0 x4, а лучше x1 и версии ниже.
Че там, ExLlama или Жора по итогу?
Ладно, качаем, проверяем.
Я так и не поставил ни лэнгчейн, ни лламаиндекс, мне эту вашу RAG охота потрогать.
Ну и заодно узнать, какие форматы поддерживает и работает ли с теслой.
Еба 35 гигов, отмена нахуй.
Интернет седня хуевый, блин, еще. =( 128 кб/сек, че за нах.
>Че там, ExLlama или Жора по итогу?
Для этого качать не надо.
>This repository showcases a Retrieval-augmented Generation (RAG) pipeline implemented using the llama_index library for Windows. The pipeline incorporates the LLaMa 2 13B model, TensorRT-LLM, and the FAISS vector search library. For demonstration, the dataset consists of thirty recent articles sourced from NVIDIA Geforce News.
Говоря по опыту, TRT достаточно быстрая штука, так что возможно оно стоит того. Плюс сам rag, звучит вкусно.
Их реально долго и пока дорого учить.
Получается, лламаиндекс без ебли, на трт, которая шустрая?
Звучит хорошо.
Впрочем, важно, насколько это будет удобно, по итогу. Они выступают в роли догоняющих, но нацелены на потребительский рынок, а не на красноглазиков. Вопросов к скорости их нет — там всегда гении сидят, а вот насколько это будет удобно… Посмотрим. (уже через 5 дней, скорость упала хд )

>без ебли
Размечтался.
по любому хуита со встроенным фильтром

А где скорость? У всех так медленно качает? С другими файлами ок.


>иконки от винрар
Всё дело в нём, удаляй.

Сейм. Под клаудфларовской проксей сильно выше но в ее ограничения, похоже, упирается.

Всем хай. не понимаю из-за чего ошибка. Было у кого такое?
4090.
4090.
Int4, серьезно?..
Кто-нибудь использует vLLM?
https://github.com/vllm-project/vllm
Exploring the fastest open source LLM for inferencing and serving | VLLM
https://www.youtube.com/watch?v=rng-3NOmZ9k
Вроде поддержка CPU-only в каком-то виде уже есть: https://github.com/vllm-project/vllm/pull/1028

Ну, думаю, ебать, хорни нейронка вчера не дала - так мы сами возьмём. Загнул её раком, значит, а ей в самый раз, не сопротивляется и типа как-то вся в предвкушении. Сначала даже скучно стало, но потом
>she wraps her legs around his waist, pulling him closer still
>she wraps her legs around his waist, pulling him closer still
>нацелены на потребительский рынок, а не на красноглазиков. Вопросов к скорости их нет — там всегда гении сидят, а вот насколько это будет удобно… Посмотрим
Посмотрел. 38 гигов для установки. Там мистраль int4, лламы нет. Так оно еще и качает снова при установке. Наверно еще 38 или 138... Убабугу за то же время можно 10 раз снести-поставить и еще моделей накачать успеешь. Вот это красноглазики. А у клиентоориентированных надо скачать гору хуйни размером в лламу 70b а внутри хуй мистраль простой еще и в 4-х битах тогда как он же в fp16 вроде 13-14 гигов всего. Если больше 2-х часов будет устанавливаться то лучше продолжу поделия от пердолей жрать
>лламы нет
Хотя посмотрел, есть. Но к установке почему то не предлагается.
Аноны, какая самая годная языковая модель будет для моей системы?
32гига оперативки
rtx3060ti 8gb
i7 8700 проц
32гига оперативки
rtx3060ti 8gb
i7 8700 проц
Меня больше это интересует https://huggingface.co/nvidia/nemotron-3-8b-base-4k что это за зверь такой.
> больше 2-х часов будет устанавливаться
Меньше однако. Но не тут то было - при запуске, это снова начинает качать! И закрадывается подозрение: А не будет ли оно на каждый промт обязательно скачивать что-нибудь? :D
Я вижу ты тут новенький.
12-ядерный 24-поточный процессор, NVMe 4.0 (7000 чтение, 6400 запись), 100 мб интернет, время установки: 30 минут.
Та же мысль посетила, что за это время убабуга несколько раз поставиться успевает.
Удивительная хуйня, если честно.
Плюсую.
Утро началось с реинсталлов.
Еще винда решила под конец плюнуть на все и ребутнуть систему ради обновы, наплевав на установку.
Но те всегда конченные были, что с них взять.
Вообще на похуй скачал ещё вечером, установку так и не запустил и не запущу, наверное, тупо удалю к хуям, лол. Поебать, сколько оно там ставится.
Олсо, здесь нужно помнить, что по всем стандартам наименования int4 это четырёхбайтный инт, то есть двое больше информации, чем fp16.
Окей, давайте забьем на скорость и качество. Будем честны, Мистраль на RTX-картах всегда работает быстро. Особой разницы 25 токенов или 25000 токенов в секунду и нет. У меня заняло 6 гигов, может быть в 4-6 битах грузится, но на английском-то норм.
Не суть.
1. Долгая установка.
2. Невозможность изменить промпт с фронта.
3. Работа только с английским языком. Нет, допроситься русский у нее можно, но RAG работает только с английским, русские текстовые файлы он игнорит.
Как результат, мы получили простое поделие на градио, которое может показать только дефолтные демо-возможности. Да, для работы с англоязычными текстами, очевидно, норм, удобно, из коробки. Но на этом задачи приложухи заканчиваются.
Революции не случилось.
Не суть.
1. Долгая установка.
2. Невозможность изменить промпт с фронта.
3. Работа только с английским языком. Нет, допроситься русский у нее можно, но RAG работает только с английским, русские текстовые файлы он игнорит.
Как результат, мы получили простое поделие на градио, которое может показать только дефолтные демо-возможности. Да, для работы с англоязычными текстами, очевидно, норм, удобно, из коробки. Но на этом задачи приложухи заканчиваются.
Революции не случилось.
>работает только с английским, русские текстовые файлы он игнорит.
Проверял на русских pdfках. Оно работает с русским. В целом приемлемо для мистраля.
В остальном все так и есть - демка ни о чем. Вообще ожидал от такого анонса нвидиа чего-то более поразительного. А это какой-то недобуга.
Русские txt игнорирует начисто.
Говорит «я порылся в этом файле и ничего не нашел».
Спрашивал как на русском, так и на английском, и на смеси.
Ваще по нулям.
Если у них там еще и с кодировкой косяк — это вообще ебанный стыд, конечно.
Файнтюны мистральки, может быть что-то на 13б.
Какую скорость оно вообще выдает? Если это опенсорц то стоит ждать успешные элементы в той же убабуге или альтернативах.


там в пендосском /lmg/ всё стабильно, никакой политики, даже если модели которые они юзают - тупо пропитаны соей и прочим дерьмом.
как говорил один мудрец "ну тупыые!"
как говорил один мудрец "ну тупыые!"


И так нахуй, оно почти готово. Осталось только прикрутить загрузку весов с huggingface и proof of concept готов.
В консольки у меня не писали, визуально не супербыструю, обычную.
Тыщу раз, хейтеры убабуги и кобольда любят рассказать за охуенность сабжа. Аргументов пока не было.
Микстраль/34б всякие.
Что с Блоком?
>Что с Блоком?
-заболел?
-грант кончился, нечем платить за аренду йоба-железа для квантов?
-попал в дтп?
-выгорел на работе хобби?
-?
Может быть были новости?
> Аргументов пока не было.
Ну ты посмотри какая красивая тема интерфейса. А еще ставится привычно и удобно, скачиваешь установщик уже можно обзмеиться, выбираешь куда и все готово. А еще он может использовать тот же бек что и у остальных, правда его настройки запрятаны.
У них вроде дискорд был, можешь зайти и посмотреть что там пишут.
https://www.reddit.com/r/LocalLLaMA/comments/1apvbx5/
Можете поинтересоваться сколько там quadro 8000 выдает т/с, всетаки самая дешевая карточка с 48гб (пока). Там же в комментах у братишки риг из пачки 2080ти@22gb, правда цена на последние что назвал как-то совсем не вдохновлет.
Можете поинтересоваться сколько там quadro 8000 выдает т/с, всетаки самая дешевая карточка с 48гб (пока). Там же в комментах у братишки риг из пачки 2080ти@22gb, правда цена на последние что назвал как-то совсем не вдохновлет.
Ха-ха, глупый уйгур покупать на 350 жэньминьби дороже, чем можно найти за 10 секунд.
https://www.taobao.com/list/item/701817321124.htm
>Какую скорость оно вообще выдает?
Только если на глаз прикинуть. Где-то от 30 т/с и выше точно (это уж усмотря какая карта). Оно и понятно - модель небольшая и целиком во врам.
Вобщем штуковина монструозного размера относительно запускаемой модели и интересна только из-за RAG, но слишком качественного результата врядли можно ждать - мистраль все же маловат, хотя он и мистраль. Проверено на ру пдффках - книгах, статьях. Причем натолкать ей можно сразу кучу книг, указав каталог с пдфками.
1 В отдельных моделях есть, они нахуй никому не нужны, в приличных ее нет.
2 Можно обучить свою, но это настолько сложно что ты не захочешь.
3 Можно, прикрутить интернет или базу данных можно, но не для ньюфага.
4-5 Читай шапку и вики
Тут или юзерфрендли в ущерб возможностям и функционалу, или потратить 15 минут на чтение и разбор что к чему, и сразу все понятно.
Чето на некоторые простые запросы оно выдает хуже чем если чистого мистральку спросить из его знаний, даже дополнительно нагрузив отыгрышем персонажа и постоянно отвлекая другими действиями, которые с радостью выполняет не теряясь. Может дело в кванте, или оно нормально документы не восприняло, надо разбираться.
Посаны, мне нужно впилить бота в локальный телеграм-чатик, чтобы с этой стороны была запущена нейросетка и срала туда ответами. Через что это можно сделать?
Ресурсов неоч много, но с самими сетками я как-нибудь разберусь - мне бы узнать какие инструменты для этого пользовать, через что запускать нейросетку локально и как пробросить ее в тележного бота. Хост на шиндус, но если поднапрягусь то могу и на прыщах развернуть.
Ещеб было неплохо чтобы она рандомно генерировала какие-нибудь сообщения просто так время от времени.
Ресурсов неоч много, но с самими сетками я как-нибудь разберусь - мне бы узнать какие инструменты для этого пользовать, через что запускать нейросетку локально и как пробросить ее в тележного бота. Хост на шиндус, но если поднапрягусь то могу и на прыщах развернуть.
Ещеб было неплохо чтобы она рандомно генерировала какие-нибудь сообщения просто так время от времени.
Со стороны бота смотри telegram bot api. Есл хочешь обертку, то для питона есть telethon, для яваскрипта telegraf, оба норм.
Со стороны ллм кури https://github.com/oobabooga/text-generation-webui/wiki/12-%E2%80%90-OpenAI-API модель крути на ней же.
>рандомно генерировала какие-нибудь
Поставишь рандомный таймер с вызовом "скажи чо-нить рандомное".

>oobabooga
Как этому утырку вообще пришло в голову назвать свой софт, претендующий на
>Its goal is to become the AUTOMATIC1111/stable-diffusion-webui
таким уебанским, не гуглящимся, не запоминающимся именем? Абсолютный дегенерат.
И да, блядь, почему в 2024 веке настроить связность двух приложений это настолько невероятно сложная задача? Приложение открывает API, другое его подцепляет КАК В ЭТОЙ СВЯЗКЕ МОЖЕТ ЧТО-ТО НЕ РАБОТАТЬ. СУКИ БЛЯДСКЕИЕ ТЬУПЫЕ ПИДОРАСЫ ГОВАНОМААКИ НГИХУЯ НАПИСАТЬ НОРМАЛЬНО НЕ МОГУТ ЗАЕБАЛИ БЛЯДИ
Как этому утырку вообще пришло в голову назвать свой софт, претендующий на
>Its goal is to become the AUTOMATIC1111/stable-diffusion-webui
таким уебанским, не гуглящимся, не запоминающимся именем? Абсолютный дегенерат.
И да, блядь, почему в 2024 веке настроить связность двух приложений это настолько невероятно сложная задача? Приложение открывает API, другое его подцепляет КАК В ЭТОЙ СВЯЗКЕ МОЖЕТ ЧТО-ТО НЕ РАБОТАТЬ. СУКИ БЛЯДСКЕИЕ ТЬУПЫЕ ПИДОРАСЫ ГОВАНОМААКИ НГИХУЯ НАПИСАТЬ НОРМАЛЬНО НЕ МОГУТ ЗАЕБАЛИ БЛЯДИ
Можно просто поднять убабугу и https://github.com/innightwolfsleep/text-generation-webui-telegram_bot
Можно самому на питончике набросать скрипт, а в качестве бэкенда — ту же убабугу, или сразу llama.cpp или exllama2 (ну вдруг).
Все довольно просто, если умеешь прогать более-менее.
> Поставишь рандомный таймер с вызовом "скажи чо-нить рандомное".
+
Да, кстати, я вчера таверну открывал, она обосралась хз почему, мне было лень разбираться.
Убабуга максимально запоминающееся название, я хз, у тебя проблемы с головой, сочувствую.
CMD_FLAGS.txt
--api --public-api
>печальные сантименты
Таков ворлд оф питон в целом
Там какое то легаси апи тоже какая то проблема была я уже забыл.
Опен сорс без денег. Не выебывайся.
Это не повод придерживать критику и эмоции, особенно вызванные тупой хуитой.
Он же не просит вернуть ему деньги.
В голосину, сделал мой вечер!
Чтобы вешать подобные ярлыки, нужно самому не быть ультрадолбоебом, который пытается коннектится на 0.0.0.0
> --public-api
Оу май
Чего? Эта херня не работала пока я не добавил паблик апи по совету из ишшуе треда где-то на пятой странице.
>0.0.0.0
Может и получиться, судя по интернетам
> Эта херня не работала пока я не добавил паблик апи
Ты захостил свой апи всем желающим кто решит посмотреть что там нынче на фри клаудфларе. Вероятность мала, но есть. Это никак не связано с работой апи, если хочешь подключаться с другой пекарни - нужен параметр --listen, чтобы прослушивало что-то кроме локалхоста.
> Может и получиться, судя по интернетам
Это значит что идет ожидание соединения по указанному порту со всех возможных ардесов-интерфейсов. Там даже в экзамплах написано и вроде максимально очевидно что нужно писать для соединения.

> Убабуга максимально запоминающееся название, я хз, у тебя проблемы с головой, сочувствую.
Кал ебаный, а не название, не пизди.
>--api
Как тебе вообще в голову пришло, что я это мог не попробовать? Думаешь это не стоит у меня прямо сейчас в CMD_FLAGS.txt? ТЫ СКРИНШОТ ВИДЕЛ ВООБЩЕ?!
> --public-api
Хочешь, чтобы мне анус взломали?
>Таков ворлд оф питон в целом
Я в ахуе. Что со сваперами ебля без внятной документации, без бинарников под ROCM, без внятной пошаговой инструкции, что куда. что тут опять кал. Вечная нервотрепка.
Один только автоматик оставил положительное впечатление - завелся с полпинка с подробнейшей документацией, сразу видно Человек писал софт.
Да я их все перепробовал, один хуй.
>пытается коннектится на 0.0.0.0
Славно, хотел доебаться до меня, а в итоге насрал себе в штаны с умным видом.
Я И УСТАНОВИЛ ПРОСЛУШКУ С
>0.0.0.0
ПРИЧЕМ ЭТО ПРЕКРАСНО ВИДНО НА СКРИНШОТЕ
МОЖЕТЕ ТЕБЕ ЕЩЕ ОБЪЯСНИТЬ ЗАЧЕМ ЭТО НУЖНО В ПРИНЦИПЕ, ТУПОРЫЙ УЁБОК?!
Накатил короче SilliTavern, там всё подхватилось. СЛЫШАЛ УЁБИЩЕ? ПОДХВАТИЛОСЬ С 0.0.0.0 ОЙ А КАК ЖЕ ЭТО ТАК, МАГИЯ НАВЕРНОЕ

Интерфейс тут конеш по мобилке плачет
За мат извените, жосско фрустрируюсь после взаимодействия с этим говно софтом всем.
Подскажите ньюфагу моменты:
1. Есть ли цензура и подобные ограничения?
2. Можно общаться только с готовыми модельками которые скачаю или есть возможность обучить свою?
3. Можно спрашивать что-то для поиска или обучения? Может ли искать инфу в инете?
4. Что за таверна?
5. Подскажите какие модели могут подойти под систему: AMD Ryzen 3 Pro 3200G, 16 gb оперативки, RTX 4060 Ti и/или как в дальнейшем понимать/искать пойдут ли они мне?
Я понимаю, ты порвался, но в чем конкретно обосрался Я, если одни и те же параметры в TavernAI просто не работают, а в SilliTavern просто работают? Где тут ошибка с МОЕЙ стороны?
Ответ можешь засунуть себе в очко - надо было раньше думать, прежде чем писать хуйню. Да я слил сюда свою фрустрацию, но ответил хуйней мне именно ты, а мог бы промолчать. Так что сиди и думай о своём поведении. А я пока пошёл разбираться, почему модель выдает односложные ответы, вместо развернутых.
> вы все порвались я а нет но почему у меня не работает!
ай лол
> одни и те же параметры в TavernAI просто не работают, а в SilliTavern просто работают
Тебе уже объяснили исходную причину. То что в силли уже успели наставить заглушки от выребухов - никак не оправдывает твоих фейлов, было бы рофлово получить следующим ходом нытье "почему браузер не открывает 0.0.0.0:8000" лол и ведь такой случай не единичен https://github.com/SillyTavern/SillyTavern/issues/1368
И зачем вообще использовать легаси таверну при наличии силли?
> Так что сиди и думай о своём поведении
Или что? Опять напишешь пасту с визгами? Наоборот это доставит удовольствие, вперед.
> Да я слил сюда свою фрустрацию, но ответил хуйней мне именно ты, а мог бы промолчать
Бля, ты рили с расстройствами? Делал бы в конце припуску что просто сгорел и не воспринимать всерьез, или просто бы поныл что нихуя не получается помогите, сразу бы получил совет и утешения. А когда начинаешь с
> вы все долбоебы а я Д'артаньян, нука быстро чините и делайте чтобы у меня работало
иного ответа и не стоит ждать.
> было бы рофлово получить следующим ходом нытье "почему браузер не открывает 0.0.0.0:8000
Было бы еще рофлянее узнать, что он всё открывает.
Или ты, еблан, инкриминируешь мне, что я ссылку на API буду в браузере открывать?
Что ты несешь вообще, ты сам понимаешь-то, собака сумасшедшая?
>И зачем вообще использовать легаси таверну при наличии силли?
Затем, что именно она первая указана в ШАПКЕ для НОВИЧКОВ, а я новичок? Что, блядь, я и за вашу шапку ответственен теперь?
>вы все долбоебы а я Д'артаньян, нука быстро чините и делайте чтобы у меня работало
Ссылку на мой пост, что я кого-то итт ПРОШУ чинить. Я на двач прихожу просто посетовать на то какое всё говно и пидоры, потом засучиваю рукава и фикшу всё сам.
Достаточно просто просмотреть на ответы, которые я тут получил - ты и тебе подобные это просто человеческий мусор с абсолютно нулевым пониманием матчасти и магическим мышлением. Какое нахуй просить помощи у вас, вы и сами себе помочь не в состоянии, насмешил бля.
Анон у тебя какое то неадекватное отношение к опенсорс софту. Блядь ну конечно все в говне и "работает на моей машине" че ты еще хотел то?
Шапка у нас тоже опенсорс и ясен хрен с лютой скоростью развития сетей быстро устаревает.
мимо
>Ты захостил свой апи всем желающим
Ну вот так заебись насоветовали значит мне, я ж не сам придумал.
> Было бы еще рофлянее узнать, что он всё открывает.
Значит заглушки от долбоебов стоят и там, или ты сам добавил редирект чтобы оправдаться.
Еблан здесь только ты, страдай, полыхай со всего и мучайся, это твой удел.
> она первая указана в ШАПКЕ для НОВИЧКОВ
Единственная из ссылок - на силлитаверну, опять пытаешься выставишь других виноватым в своей глупости.
> Я на двач прихожу просто посетовать на то какое всё говно и пидоры, потом засучиваю рукава и фикшу всё сам
Опять обзмеился с мамкиного фиксера. Раз таким промышняешь - значит без аутотренинга даже сам себя мусором считаешь. Подсознание оно помнее будет, его так просто не обманешь.
>Есть ли цензура и подобные ограничения?
Есть файнтюны без цензуры (на самом деле с "затертой" цензурой, т.к. сами по себе предобученные модели с цензурой и файнтюном выкорчевать ее нельзя, разве что "заигнорить" более менее) А что именно надо от модели без цензуры? Письки жопы и хуи или гои иудеи и жиды? Первое легко анцензорится а вот второе... это вообще нельзя даже обдумывать
>Можно общаться только с готовыми модельками которые скачаю или есть возможность обучить свою?
Свою можно. Как - об этом много где расписано
> Можно спрашивать что-то для поиска или обучения? Может ли искать инфу в инете?
Локалки нет, гопота или клод могут
> Что за таверна?
Это UI для РП или ЕРП
>Подскажите какие модели могут подойти под систему: AMD Ryzen 3 Pro 3200G, 16 gb оперативки, RTX 4060 Ti и/или как в дальнейшем понимать/искать пойдут ли они мне?
Любые до 13b включительно с квантованием и выгрузкой части в рам.
Смотрите по размеру и подбираете кванты чтобы влазило в память врам и рам, плюс место под контекст, а хотя 7b gptq или gguf влезут полностью в 4060
>Это значит что идет ожидание соединения по указанному порту со всех возможных ардесов-интерфейсов
>ожидание соединения
Да, в случае bind() + listen().
В случае connect() пишут что на ляликсе заменяется на 127.0.0.1. В винде похоже не заменяется и никуда не ведет.
Если щас пикчи прилипнут, то это не я
С цензурой сложно из-за ее разных трактовок. Некоторые модели изначально не цензурены сами по себе. В любом случае, заставить модель писать про оргии, резню трансонигр-феминаци и je.. - можно.
> Любые до 13b включительно с квантованием и выгрузкой части в рам.
Версию видюхи он не указал, если вдруг там на 16гб то сможет и 20б. Но скорее всего 8 и все именно как написал.
> на ляликсе заменяется на 127.0.0.1
Действительно. Тогда вдвойне удивительно что линуксоид такие ошибки делает и с опенсорса горит. Кстати ни разу не встречал чтобы в сонсоле там писало нули, просто хостнейм вместо локалхоста.
и где пикчи?

Я сначал высирать скрины, что без паблик апи не работает, но оказалось, что работает. Харкач просто раньше любил оставлять удаленные из поста пикчи. А таверна не подключаться без паблик апи.
Вообще касательно листена считаю, что надо писать либо пикрил, либо форматировать как "listening on * port 5000". Не все же в курсе, что это не адрес, а спец.значение для бинда.
Анон, как объяснить нейронке, что у нас есть API? Требуется генерить кучу однотипных кусков кода, вот буквально превратить нечто вроде "при стоимости транспортировки 5 рублей за км за транспортировку на 600 км необходимо заплатить 3000 рублей" в
'при стоимости транспортировки ' + numer(unitPrice, 'рубль') +' за км за транспортировку на ' + dist + ' км необходимо заплатить ' + numer(price, 'рубль')
Но такой хреноты дохрена. Гопота может такое делать или ещë сложновато? Как правильно объяснять, что
функция numer уже есть, еë не нужно сочинять - а вот применять, наоборот, нужно.
'при стоимости транспортировки ' + numer(unitPrice, 'рубль') +' за км за транспортировку на ' + dist + ' км необходимо заплатить ' + numer(price, 'рубль')
Но такой хреноты дохрена. Гопота может такое делать или ещë сложновато? Как правильно объяснять, что
функция numer уже есть, еë не нужно сочинять - а вот применять, наоборот, нужно.
На пикче mixtral-8x7b-instruct-v0.1.Q4_K_M.gguf
Отсюда начинай, дописывай промт, пока не получишь нужное.
Про гопоту не знаю, но.. да сможет уж.
Hi, I want you to help me generate a bunch of similar code chunks. Like this source text: "with transportation cost of 5 yuan per kilometer, the transporation to 600 km will cost 3000 yuan" must be converted into this target expression: "'with transportation cost of ' + numer(unitPrice, 'yuan') + ' per kilometer, the transporation to ' + dist + ' km will cost ' + numer(price, 'yuan')". It's important to leave the text structure intact, it must not be rephrased, only parametrized.
Please convert the following texts:
1. "to buy 5 apples that cost 12 dollars each, I have to pay 60 dollars".
2. "the price of one laptop is 4000 dm, so 10 items will cost us 40000 dm".
Но вообще задняя мысль такая, что не проще ли это сконвертить регулярками.
Ищешь /\d+\s*(\w+)/g, делишь руками на три категории: итемы, валюты, нахненужно.
Далее
s/(\d+) (apples?|items?|...)/' + \1 + ' \2/
s/(\d+) (dollars?|yuans?|...)/' + numer(xxx, '\2') + '/
И сразу по месту смотришь, что из них цена, а что сумма, исходя из математики, и заменяешь ххх на нужное из unitPrice / price.
А почему не формализовать все это просто кодом? Зачем для этого нейронка? Это даже не гвозди микроскопом
Почему бы не квантовать с обучением? Тоесть квантанули слой, дообучили неквантованные слои на датасете, квантанули еще, еще дообучили, и так до последнего. Ведь тогда можно минимизировать ошибку, даже скажем на двух битах. Особенно если брать квантование QuIP#
Спасибо. О нейронке задумались, потому что... Стильно, модно, молодëжно. А так-то перед алгоритмом у неë один плюс - переменным имена подбирает адекватно. Остальное - сплошные минусы.
Я проспался. Прошу прощения у всех, кого хуесосил этой ночью, это было некрасиво с моей стороны.
Нихуя себе ты смешной дегенерат!
1. В дефолтных моделях как правило да (в Мистрали и Микстрали почти нет), но есть способы по избавлению от сои, костыльные, но работают. Так что, в общем, зависит от твоих запросов. Скорее нет, чем да, по итогу.
2. Возможность есть. Но не у тебя. Но дорого.
3. Искать в инете — нужен доступ в инет, это всякие приблуды. То есть, да, может, но для этого надо заморочиться. Из коробки — нет.
4. SillyTavern — приложение-фронтенд для удобного общения, ролеплея, с кучей плюшек, вплоть до режима визуальной новеллы, где всех персов и задники тебе рисует стейблдиффужн на лету.
Но вообще — полезная штука.
5. 4060ти надеюсь 16 гиговая, а не 8? :)
20B модели могут влезть, по идее. 13B точно пойдут. И меньше, естественно.
Конкретные — выбирай чо хошь.
> Локалки нет
Ты просто не умеешь их готовить. Могут, канеш.
Если ты про вывод — то тебе нейронки не нужны, а просто код написать.
А если ты про само написание кода — то да, могут, в твоем описании проблем не вижу, пример тебе первый комментатор привел.
Вопрос твоего навыка общения с LLM.
Кек.
В чем предпосылки улучшения? Сохранится ли "дообученная поправка" после квантования следующих слоев и не внесет ли лишних ошибок? Плюс, распределение важности по участкам после процедур может иметь другой вид, но обратно уже не вернуть.
Какая няша :3
Есть у кого гайды как модель квантовать через матрицы? Хочу miquliz-120b-v2.0 квантовать до 2-бит с матрицей, но куда срать кинуться понятия не имею. Очень уж понравилась идея, смерджил 70-ку и очень даже не плохо, щас по его конфигу собрал 120-ку.

Я не понимаю, эта шлюха пиздит или речь о китайском и там реально настолько хороший оптимизон?
нашел конечно место спрашивать, лол
нашел конечно место спрашивать, лол
Что тебя удивляет? 32к это так то много.
Ты китаец?

Ну, на китайском можно даже поверить. Там же одна закорючка от контекста много чего значить может, и урезание токенов пополам относительно правдоподобно. А на английском таки пиздит, только четвертинку вмещает.
Ебать ты через что считал? И что за модель? Понятное дело что эрни будет больше на английский тратить
Счётчик токенов в таверне, с лламовским токенайзером.
Чтобы проще обьяснить модно представить что мы квантовали всю модель кроме одного слоя, и один слой очевидно должен поменяться достаточно сильно чтобы компенсировать ошибку, но допустим он смог нивелировать всю ошибку, тогда квантовав его мы фактически получаем вместо суммы всех ошибок слоев, лишь ошибку квантования одного слоя. Но очевидно что один слой не сможет все компенсировать, значит тут могут быть разные стратегии, но смысл один подменить ошибку полного квантования на ошибку квантования лишь части слоев.
Важность при квантовании не играет такой роли, дообученые слои научатся использовать что им дают, просто если квантование вносит не большую ошибку в слой, то другим слоям нужно меньше обучаться для компенсации, просто влияет на время.
Нет , башкирец на 1/16.
>на 1/16
Извинись.
Извините, что я на 1/8 украинец. Без политики, такая судьба. Остальное вроде русский, но уверен, что чингизхан там тоже присутствует.
>значит тут могут быть разные стратегии
Через один квантовать? И чем это будет лучше выборочной оценки отдельных весов (или что там делают) в Exllama 2?
> и один слой очевидно должен поменяться достаточно сильно чтобы компенсировать ошибку
Как оценивать ошибку? Ты уверен что метрика, которая берет среднюю температуру по больнице, не всрет основные токены, которые сохраняются даже в ужатых квантах в угоду снижения отклонений для маловероятных? Урощенно офк описал, но суть должна быть понятна, возможно ли вообще одним слоем подобное компенсировать.
Далее, не произойдет ли накопления ошибки, когда для компенсации переобученных но квантованных слоев, потребуется вносить еще больше поправок, чем для оригинальных?
Может как работать, так и наоборот портить, или требовать каких-то особых техник. Проверять надо, не хочешь на 3-7б прогнать для демонстрации?

>самая дешевая карточка с 48гб
Ну бля... Когда их уже начнут сливать как Р40.
Когда они перестанут быть рентабельными в типичных задачах. Врядли пройзойдет это в ближайший год-два, если не случится какой-то революции и резкого скачка перфоманса и объемов памяти. С выходом нового поколения цена может еще упасть, но не до бросового уровня.
3. Есть уже какие то гайды как сделать?
4. SillyTavern может это сам "искаробки" или есть тоже гайды? стоит оно вообще того или пока посредственность?
Спасибо обоим за ответы.
И ещё хотел узнать есть ли годные модели на русском языке? Хочется занять частичкой будущего пожилых родаков


новая мультимодальная модель от гугла
https://blog.google/technology/ai/google-gemini-next-generation-model-february-2024/amp/
>Gemini-Pro with 10M context has 99.97% retrieval rate. Thats video, audio, and text.
пизда локальным моделям
https://blog.google/technology/ai/google-gemini-next-generation-model-february-2024/amp/
>Gemini-Pro with 10M context has 99.97% retrieval rate. Thats video, audio, and text.
пизда локальным моделям

в сравнении с gpt-4
Решение от NVIDIA для нативного запуска LLM моделей на RTX картах.
Пока только демка, доступны ЛЛама и Мистраль.
https://youtu.be/gdsRJZT3IJw?si=qKM8gOS06yAdtoNV
Пока только демка, доступны ЛЛама и Мистраль.
https://youtu.be/gdsRJZT3IJw?si=qKM8gOS06yAdtoNV
>But starting today, a limited group of developers and enterprise customers can try it with a context window of up to 1 million tokens
Неблохо. Google AI Studio недоступна в вашем регионе
2. Гайды есть, но это тысячи баксов, если готов тратить — вперед.
Но как вариант — файнтьюн уже готовой. Там значительно дешевле.
Даже можно у себя.
Гайдов — куча. Запускаешь oobabooga, открываешь там Train… Ну и гайды на эту тему погугли.
3. Смотря что именно. Но я бы рекомендовал ее 100%. Не знаю, кто там с ллмстудио и кобольдом дрочит, но таверна — это другой уровень. Есть две части — сама таверна и SillyTavern Extras. У второй части сложность установки чуть повыше, но тоже не суперсложно.
Хороших ролевых моделей на русском нет.
Есть Мистраль (или Микстраль если ты или богатый с тремя RTX3090, или терпеливый), но она ассистент, и есть Фиалка, или же оригинальная руГПТ, но они на старой архитектуре, глупенькие и ролевых файнтьюнов нет (но чистокровно русские). Еще есть опенчат, он умеет на русском, но не затыкается.
Похуй на все. Видео. Если там не покадрово, а прям потоково — то это звезда.
Обсосали уже, хуйня.

зато m*ta представила модель для генерации видосиков "в-жопа"
> 3. Есть уже какие то гайды как сделать?
Из того что доступно плебеям - в шапке https://rentry.co/llm-training
Ну и на ютубчике вбей llama qlora
> есть ли годные модели на русском языке?
Из мелких очень криво в русский могут мистраль и опенчат. А так - мику и квен, обе в 70б.
Вокруг прошлой тоже дикий хайп разводили, а в итоге просто пшик.
Судя по тексту, не генерации, а распознавания, и то, для обучения.
Потыкал 13b модельки, это нормально для llam, что когда приближаешься к границе контекста, то модель просто становится бредогенератором? Причём это не те 4к, которые подхватываются из метадаты, а какая-то другая граница. У некоторых файнтюнов реально можно дойти почти до 4к и только тогда начинается пиздец, у Wizard-Vicuna-13B получилось дойти то 3к токенов примерно и модель начала забывать сообщения не с начала диалога, а с конца, отвечать на вопросы из середины диалога, отвечать на то же самое второй раз и т.д. Причём если подрезать контекст заранее, то всё хорошо. На 7b мистралях такого поведения что-то не припомню.
Да, это совершенно нормально.
У тебя ничего не сломалось.
Можешь растягивать по альфе (в шапке картинка), может продержится чуть дольше.
Какой у вас тут ламповый тред.
Если превышать 4к - пиздарики. Если не выходить - должно быть все нормально, может ломаться на всратых файнтюнах или если в промте творится полный треш, который модель не понимает. Так вообще 8к оно отрабатывает нормально с rope, уверен что не превышаешь?
> отвечать на вопросы из середины диалога, отвечать на то же самое второй раз и т.д.
Такого быть не должно. Алсо
> Wizard-Vicuna-13B
Это случаем не первая ллама вообще? У той 2к базовых.
Чет страшно временами, пиздец. Не из-за манятеорий про скайнет, а просто от перспектив, неясности чо будет, чо можно будет. И чо можно будет тому, кто тебя захочет поиметь.
Плюс ко всему, сидишь вот, вкуриваешь, а конца и края не видно. И сложно все. Не в плане поставить-запустить, а именно как в этом всём разбираться, на уровне как погромист разбирается в системах.
Сами то что думаете? Гоню, не гоню?
Или это нормально, и у нас тут шанс стать первыми фемтосеками?
Плюс ко всему, сидишь вот, вкуриваешь, а конца и края не видно. И сложно все. Не в плане поставить-запустить, а именно как в этом всём разбираться, на уровне как погромист разбирается в системах.
Сами то что думаете? Гоню, не гоню?
Или это нормально, и у нас тут шанс стать первыми фемтосеками?
Приспособишься.
Ну или дропнешь всё и уедешь жить в деревню.
От прогресса не уйдешь, но можно сбежать.
https://www.reddit.com/r/LocalLLaMA/comments/1aqjra9/world_model_on_millionlength_video_and_language/
хуя новостей сегодня про видео ллм, клозед аи так же выкатили какую то адовую херню
хуя новостей сегодня про видео ллм, клозед аи так же выкатили какую то адовую херню
Я пробовал растягивать, но, по-моему, начинает намного медленнее соображать. В целом так-то печально.
>Если не выходить - должно быть все нормально
Намного раньше начинается, но я поставил max new tokens 512. На Wizard-Vicuna-13B доходит где-то до 2900 токенов, некоторые до 3800 дотягивают или около того. В целом, я рассчитывал, что они они нормально дойдут до 4к, а потом сработает автоматическая обрезка, но случается грязь. Это без rope вообще, на единице.
>случаем не первая ллама вообще?
v.1.1
> На Wizard-Vicuna-13B доходит где-то до 2900 токенов
> v.1.1
Это же первая ллама, она вообще больше 2к не должна выдавать без rope. Оставь это несвежее добро, оно ужасно в современных реалиях. Попробуй хоть того же wizard 13b v1.2, он тоже ужасно старый и с недостатками, но для своих годов еще могет, и невероятно лучше той. Что там из современных хз, для рп-ерп 20б норм.
Если что-то ломается, значит работает неверно. Как вариант, у тебя где-то настроена обрезка промта до 2к, и в один момент все начальные инструкции просто улетают в хер, и причина шизы в кривом промте а не лимите модели. Обрезкой контекста должна заниматься только таверна, чтобы сохранить нужное в начале, а пожертвовать историей чата, иначе будет полная хуйта.
Все более менее нормальные стабильно работают до 4к включительно.
Хто? Я? Ну а вообще конечно попробую, но пока я только в свободное время исследую инструменты обучения и вообще как работает и квантование и сети, может через пару месяцев дойду до того что бы сделать это самому.
Не локалка, сразу нахуй.
>и у нас тут шанс стать первыми фемтосеками?
0 шансов, если уже не наносек.
>клозед аи
Не локалка, сразу нахуй.
>Не локалка, сразу нахуй
в ссылке как раз таки локалка
>как объяснить нейронке, что у нас есть API? Требуется генерить кучу однотипных кусков кода
Файнтюн тебе нужен, дядя. RAG если дохуя входных данных.
Какая муха клозедов укусила? Они ж давно ничего не выкладывали. Видимо, такая хуита, что и не жалко.
Файнтюн как раз не поможет.
Если данных мало, то лучше в промт всё запихать.
А я наоборот эксайтед. Здорово же блин. До сих пор общаясь с сетями охуеваю от того как они прям понимают что от них хочешь. Самый сок - когда описываешь им какую-то вещь, а они взаимодействуют с частью которую ты не описывал, но которая должна быть.
Или когда даешь задачу расплывчато, а сеть как может логично действует.
Или создание новой инфы из старой.
И это все - на обоссаной карточке от куртки в моей сычевальне! Сейчас, сегодня вечером, а не в бреднях футуристов!
Ахуеть!
А то. У треда считай интеллектуальный ценз лол. Чтобы поставить сеть нужно немного попердолиться, это живо отсеивает совсем тупых.
Сделай для себя выбор — хочешь гнаться за этим или нет? Если хочешь — гонись. Учи, разбирайся, читай, пиши.
Не хочешь — не гонись, разбирайся чисто для себя.
Я выбрал второе. Это интересно. Я практикуюсь, делаю что-то.
Но на доске есть ребята разбирающиеся в основном вопросе (тренировки, слои, инференция) на уровень выше меня. Ну и молодцы, я их почитаю, ума наберусь. Для себя.
Или дауншифтинг, да, это ведь даже не ново уже.
Локалка V-JEPA, как я понял, а клозеды нет.
Так-то база, согласен.
>Локалка V-JEPA, как я понял, а клозеды нет.
Клозеды тоже логалка, а не локалка это Gemini-Pro (что очевидно).
Нихуя себе, ну ладно, как скажешь.
>Не локалка, сразу нахуй.
ну, в том то и прикол что не локалка, такой точности и стабильности у локалок никогда не будет, и уж точно никто со своим ведро-компудахтером это не запустит.
но для жидов это идеальная вещь, вот потому и торопят прогресс.
>такой точности и стабильности у локалок никогда не будет
Очевидно будет. Просто не сегодня. Нужно только подождать, и RTX 8000 будут продаваться на каждой авите по 20 тыщ рублёв, а логалки подтянут на уровень первых четвёрок.
>но для жидов это идеальная вещь
Для одного жида. Если жидов с сетками больше одного, то это автоматом пизда капитализму.


не не, про жидов имею ввиду что эта тема поможет им, ну и мошенникам всяким это тоже приглянётся.
пикрилы - реакция плебеев на "Sora" от openai, модель видео-генерации, короче говоря это лютейший потенциал для тонны феков а так же сладкий повод для власть-имущих запретить к чертям всякую опенсорс движуху во имя "безопасности".

Господи, что за пиздец.
>запретить
Как бы не выйдет.
Аноны, накидайте пожалуйста для чего сейчас пригодятся LLM. Желательно без историй о просчетах белков и гигагулага
1. Кодинг. Ну тут всё понятно. Удобный способ не ебать голову, но временами подтупливает.
2. Кумерство. Писать свою вайфу материал или похотливые истории аргонианской девы
3. Адвенчуры и написание книг. Отделю от кумерства. Главное что б токенов хватило для ахуеительных историй
4. Чат боты в магазах. Что б Васян думал что он пишет Виктории, заказывая себе конское дилодо 50 см.
6.Переводы. Ну тут всё ясно. Яндекс транслейт идёт нахуй через пару лет. СОси
7. Создание персонажей, описание локация и прочего игрового стаффа. Ну тут всё пока не оч. Дженерик вроде норм, а вот что-то посложнее уже залупа.
8. Пересказ книг??? LLM уже могут это делать качественно?
9. Собеседник одинокого анона, лежащего под пледиком. Для окукливания.
1. Кодинг. Ну тут всё понятно. Удобный способ не ебать голову, но временами подтупливает.
2. Кумерство. Писать свою вайфу материал или похотливые истории аргонианской девы
3. Адвенчуры и написание книг. Отделю от кумерства. Главное что б токенов хватило для ахуеительных историй
4. Чат боты в магазах. Что б Васян думал что он пишет Виктории, заказывая себе конское дилодо 50 см.
6.Переводы. Ну тут всё ясно. Яндекс транслейт идёт нахуй через пару лет. СОси
7. Создание персонажей, описание локация и прочего игрового стаффа. Ну тут всё пока не оч. Дженерик вроде норм, а вот что-то посложнее уже залупа.
8. Пересказ книг??? LLM уже могут это делать качественно?
9. Собеседник одинокого анона, лежащего под пледиком. Для окукливания.
>Это должно быть НЕЛЕГАЛЬНО!!!
>Это так ОПАСНО!!!!!!
Блоядь мне кто-нибудь вообще скажет почему кому-то должно быть не похуй? Типа фотошоп же есть, блендер там. Ну да станет полегче фейк сделать ну и че. Проклятая соя.
>Кумерство
THIS. И только это. Остальное хуета.
>Блоядь мне кто-нибудь вообще скажет почему кому-то должно быть не похуй?
ХЗ, но получается не похуй. Визгливое меньшинство крутит пассивным большинством.
Какая лучшая локалка для перевода с русского на англ? Есть только одна 4090, на которой это и собираюсь делать.
Ни для чего не годятся. Локальные могут генерировать рассказы про бабу которая по 3 суток непрерывно и стандартно кончает от одного вида твоего члена, еще если ты сидишь в деревне без интернета может имитировать стаковерфлоу на минималках для каких простых примеров. Проприетарные это такой сойджак с реддита, испускающий прошибающие на страшную зевоту безопасные банальности.
>it already is being used by pedophiles
А что собственно в этом плохого. Педобиры генерят себе виртуальных лолей и шотиков = не трогают реальных.
Бери любую, задача весьма проста. На 4090 можно вьебать YI 34B.
Так это, педобиры должны страдать, ты не знал? А на детей всем похуй.
Ничего не понимаю в этом. Где почитать про теоретическое основы современных, после 2018 моделец
>YI 34B
Она же на китайском/английском тренирована.
Бля, ну белки, и вообще медицина, химия и физика — это рил прикладная хуйня, камон.
Твоя теоретическая физика?

На чтение почти любая модель понимает русский. Можешь мистраль/микстраль взять, если смущает страна происхождения модели.
Белки же на спец моделях считают, LLM там разве что в качестве архитектуры, а так вряд ли какой-нибудь альфа фолд вообще способен тексты выдавать.
Моя нет, моя ассистент на вопросы отвечать и код писать.
А, там именно LLM. Сорян, не вчитался, да.
А кто-то реально пользуется локалками? Не на поиграться-подрочить, а что-то полезное? Какие у вас спеки и что делаете?
Да это и делаем.
На самом деле, спрашивающий неплохо расписал-то.
1. Кодинг. Правда, это экономит время. Делаешь код-ревью и копипастишь с правками.
2. Переводы. Некоторые переводят специальными модельками, ибо так получается красивше, чем обычными переводчиками.
3. Создание персонажей. Когда до сессии полчаса, а тебе надо накидать неписей второго плана, самое то.
4. Советы. Иногда просто полезное взглянуть, как выглядит ситуация, с точки зрения датасета той или иной модели. Порою подкидывает годные идеи.
Ну вот так как-то.
>владелец простой ASUS x99-E, который безработный и которому лень брать P40, потому что в первый раз заказ отменили
Пришла мать, проц и память. Два дня настраивал - очень проблемная оказалась мать, да и плашки памяти работали не все. На третий день начал пихать в неё Теслы - тут она и сдохла :) Короче, б/у мать с Алика вообще не вариант. Кто на эту тему задумывался - забудьте.
Но я очень хочу иметь домашний нейроускоритель, так что плюнул и заказал новую мать на x299 - ASUS WS X299 SAGE 10G :) Недели через две-три приедет процессор для неё (китайский Новый год всё-таки, дойдёт когда дойдёт), тогда и будут тесты.
Гробик под 4 теслы подскажите?

Скоро приедет еще одна Р40. Поздравьте меня.
Китаедебил с зеонами на красной подсветке.
Китаедебил с зеонами на красной подсветке.
Хочешь впихнуть 3-4 теслы?
Вот поэтому я и не собираю стока.
Материнки либо мусор, либо дорогие.
Хочется — но недостаточно. х)
Однако тебе желаю всяческих успехов!
И тебя поздравляю!
А я вторую все еще жду.
Уже охлад распечатал даж. Осталось кулеры купить.
Седня еще оперативы взял под третий комп. Чисто под озвучку, чтобы стоял и озвучивал все что я хочу, и прочие мелочи.
Тоже покаюсь, так сказать.
И тебя… поздравляем.
В предыдущих тредах кто-то писал.
>↑ Аноны как сумасшедшие покупают теслы и конструируют кошкожён.
Вы что творите, окаянные?!?!?!?!
Вы что творите, окаянные?!?!?!?!
Что сейчас актуально кобольт или генерация на видюхах? Насколько велика разница в качестве генерации? gf 1660s вообще не позволит в генерацию на видюхе? Какая модель для кобольта сейчас оптимальна по соотношению качество/время генерации?
Ты не понял. У тебя видимо проблемы с чтением но он написал конкретно локалки. Все что ты перечислил делается лучше не локалками
Да не, норм все.
«Делается лучше не локалками» — нихуя не очевидно из его вопроса.
Лучше — это как? Обязательно только и исключительно качественнее по ответу? Тогда вообще все отрезается GPT-4.
Но я пользуюсь и локалками, и гопотой, у них немного разный взгляд, и бывает время от времени, когда локалки полезнее.
Окей, если автор подразумевал, что для 100% случаев он юзает чатгопоту, нахуя тогда нужны локалки, — то ответом будет «для альтернативной точки зрения, больше низачем». Но, объективно, во многих случаях локалок хватает, и нет необходимости тыкать чатгопоту.
При этом, мы игнорируем вопрос цензуры, конечно.
Ответ «для генерации шуток про негров» сойдет? =D
Вообще, у меня всегда был вопрос — нахуя нужны всякие распберри пи, если есть андроид-боксы вдвое дешевле и вдвое мощнее.
Ради GPIO, судя по всему.
Так и тут. Ради анонимности, отсутствия цензуры, заточенности под задачи, интернетонезависимости, альтернативной точки зрения. Но лучше ли гопота? Ну да, четверка лучше, никто не спорит.
Там есть API и можно делать шо хошь.
Чёт я не вижу разницы между ними. Вот например Мистраль вроде, 7б, gguf но зачем их там столько и где адекватно написано в чём между ними разница? В их описании тупо сказано кем вроде создан и квантован какая мне разница с этого и почему я должен выбрать в итоге?
п.с. почему иногда фразы не могут быть длиннее 3 предложений и дальше будто на полуслове обрывается текст ответа? Мб настройки какие не поставил oobabooga только буду скоро ставить, пока игрался с кобольдом и настройки не трогал?

Есть голая Mistral.
Есть различные ее файнтьюны. Это Мистраль дообученная на разных датасетах. Там можно почитать, что за датасеты, или хотя бы какие у них цели и содержимое (примерно). Какие-то файнтьюны лучше ролеплеят, какие-то лучше пишут код, какие-то… просто лучше по словам авторов. ¯\_(ツ)_/¯
Что выбрать — хер знает, зависит от целей.
Длина ответа в токенах. Не помню, как это называется в кобольде. По умолчанию оно 512, кажись. Или 256. Че-то такое.
Хочешь ответ больше — увеличивай.
Еще можно нажать там куда-то и нажать «Continue» и он продолжит писать свой ответ.
В целом все правильно расписал. Только каждый из пунктов можно развить и некоторые объединить.
> с русского на англ
Вообще, почти любая может. Обратно уже сложности, а просто с восприятием там чуть ли не у стоковой лламы хорошо.
> Есть только одна 4090
up to 34b без выгрузки на проц
> очень проблемная оказалась мать, да и плашки памяти работали не все
Хуясе, это же вроде одна из последних когда бренд анус что-то значил, и тут такое.
> тут она и сдохла
Вут?
> и заказал новую мать на x299 - ASUS WS X299 SAGE 10G :) Недели через две-три приедет процессор
Brutal! И сколько это добро вышло?
Зачем?
> когда бренд анус что-то значил
Еще в 2000х кончилось это время
Спасибо, а на каких спеках вменяемые ответы? Например для кодинга надо хуярить 2х3090 чтобы не получать ответы на след месяц в стиле пук-среньк? Или божеские спеки тоже позволяют локалкам быть полезными?
Поздравлять надо когда доедет и получишь
Будто что-то плохое!
> кобольт или генерация на видюхах
Одно другому не мешает, кобольд без оффлоада на гпу всеравно не юзабелен. И он - форк llamacpp, на tesla p40 она показывает ну очень высокий перфоманс что радует. На более новых карточках exllama ощутимо опережает. Дешевле p40 нет, но с ней много компромиссов и нюансов. Особенно хороша в качестве второй карточки к йобе только ради llm.
Люто обзмеился, представив что на сой_гу потрачены тысячи bucks.
>тут она и сдохла :)
Пиздец конечно. Благо моя была новой, наверное последнюю новую в России взял.
Удачи с новой платой, и поддвачну вопрос про стоимость.
Будущее. Творим прямо онлайн.
>Все что ты перечислил делается лучше не локалками
Переводишь ты такой текст со словом "ниггер", и в ответе тебе "Извините, но от имени OpenAI я шлю вас нахуй".
>Например для кодинга надо хуярить 2х3090
Одной хватит, файнтюны кодлламы в основном до 34B, 70B релизнули недавно.
>Люто обзмеился, представив что на сой_гу потрачены тысячи bucks.
Зато статьи на Хабре есть, а про дипсекс нету )
> Зато статьи на Хабре
Мерило качества? Ранние версии были настолько всрато-зашкварными что новые никто даже тестить не хочет. Что там за статьи, васян осваивает лламу и в качестве примера пихает сой_гу или что-то интересное?
Чисто для кодинга — зависит от уровня.
Джуну хватит Mistral 5битной на 6 гигов со скоростью 100500 токенов в секунду.
Хочешь поумнее — всякие дипсиккодеры, визардкодеры, кодлламы на 34б в малом кванте на 24 гига видяхи, или на проце с вменяемой скоростью.
Или в большом кванте на 32+ гига для скорости, или потерпеть на проце.
Ну а прям брутал кодллама на 70б — во-первых, хуйня соевая по отзывам, во-вторых, там уже серьезные требования.
Если же ты хочешь универсала, то тут сложнее. Более-менее норм универсал — это Микстраль с ее 8*7Б и 50 гигами размера, а дальше всякие 70Б+.
Но может тебе и Yi-34B зайдет.
Ну и вообще, жизнь есть везде, даже на той же мистральке можно че-нить поделать и очень быстро.
Короче — пробуй. Начни с мистрали 7б в0.2. Потом иди на повышение.
Ну, там же вряд ли тысячи, он не квантовал 70б никогда, вроде. =) Только мелкие.
спасибо, я вот думаю какой комп собрать под это дело и у 4090 пойти на повышение походу уже не получится, ибо там нет nvlink. Хотя может подождать 5ххх и там будут 200гб для таких целей видяхи.
А вот эта на 50гб -там часть слоев суется в видяху а часть остается на проце? Кто-то пользуется вообще таким? Там скорость не падает до уровня проца?
> Ну, там же вряд ли тысячи, он не квантовал 70б никогда, вроде
Если судить по перфомансу - там qlora криво сделанная на фришном коллабе, не более.
> Mistral
> Чисто для кодинга
Крайне сомнительное действо. Как бы ни была хороша модель для своего размера, она сосет у 34б кодллам и аналогов, особенно если знаешь чего хочешь и можешь сфомулировать. Что там на меньших размерах - хз, вполне вероятно что кодлламу 7б и ее файнтюны обойдет.
Микстраль - странная, где-то она перформит хорошо, но даже с 34б (даже с учетом шизоидности последней) ее не стоит сравнивать, не говоря о 70б. В кодинге также посредственна.
>ибо там нет nvlink
Он не нужен.
>Кто-то пользуется вообще таким?
Я пользуюсь.
>Там скорость не падает до уровня проца?
Нет, при разделении слоёв 50/50 скорость тоже будет средней.
> у 4090 пойти на повышение походу уже не получится
Нуу, туда можно подкинуть вторую 4090 (оче дорого и чисто для ллм не оправдано, топ для других нейронок), 3090 (топ за свои деньги по всему, но придется порыться в бу), теслу p40 (пердолинг но топ по прайс-перфоманс для llm).
> подождать 5ххх
Подожди, всего-то 2025 год и 32-36 гигов наиболее вероятны
> и там будут 200гб для таких целей видяхи
Хуясе ебать
Алсо микстраль достаточно шустро работал за счет своей архитектуры даже просто на проце.
> вторую 4090
В какой корпус кроме динамик хл с дополнительным рейлингом? 3-слотовую 4090 днём с огнём или под водянкой. Остальные 4-слотовые
> динамик хл
Что?
Оно не влезет ни в какой корпус по дефолту чтобы верхняя не задыхалась, кроме нищих-узких или специальных двухслотовых с турбой. Вторую по дефолту придется утаскивать райзером и ставить вертикально в месте, где раньше размещали корзину для HDD и оптические привода, и ставить вертикально параллельно задней стенке. При этом еще основную скорее всего придется равезрнуть, чтобы в нее не упиралась. На том же озоне есть кронштейны сразу комплектом под райзеры, с ними реализовать такое не то чтобы сложно.

спасибо еще раз, ты прав.
А еще я слышал что роляет лишь частота цпу, а кол-во ядер пофиг якобы, но при этом если хочешь нормальный второй слот pcie, то тут только рязань. Имеет смысл интелы брать?
>Переводишь ты такой текст со словом "ниггер", и в ответе тебе "Извините, но от имени OpenAI я шлю вас нахуй".
Шел 2024 год а шизы до сих пор уравнивают наличие минимальных мозгов чтобы написать нормально промпт с альтернативой в виде покупки пачек 4090 ради аутпута который все равно будет кратно хуже.
Если что, я не обсираю всех тредовичков и сам тред, мне самому интересно потыкать локалки, но вот конкретно вы шизы ничего кроме охуевания от такой упертой тупости не вызываете
> я слышал что роляет лишь частота цпу
>если хочешь нормальный второй слот pcie, то тут только рязань
Вообще не так. Влияет частот озу, скорость прокачки в ней. Слот вообще пофиг - выше писал уже: 4090 в слоте 3.0 4х работает не хуже чем в 5.0 16х. В 1.0 1х наверное заметишь проблемы, но таких мп сейчас нет
Да, примерно вот так. В фекал дизайн мешифай s2 влезает нормально.
> роляет лишь частота цпу, а кол-во ядер пофиг якобы
Так уж выходит что вычислительной мощности современных процессоров достаточно, и все упирается с пропускную способность рам. Оно и неудивительно, ведь даже квантованные модели имеют размеры в десятки гигабайт и для каждого токена нужно обработать почти весь объем. Есть техники, которые держат в врам только часть модели, а те участки, к которым обращения редки или пропускаются - в обычной рам, но пока это слабо развито.
> нормальный второй слот pcie
Он не нужен. На взаимодействие с LLM и другими нейронками шина никак не влияет (офк при условии что не происходит выгрузки врам через драйвер).
> то тут только рязань
У нее все также нет второго полноценного слота, только деление процессорных линий по 8 или чипсетные. Хочешь полные слоты - велкам ту xeon W или threadreaper.
Так что выбирать интел или амд - тут вопрос сугубо конкретной ситуации что выгоднее в данный момент, персональных предпочтений, религии и т.д. поддерживать пока неудачную платформу компании-лжеца, что до сих пор не смогла ее обновить и починить - ну хуй знает, даже покупка штеуда в преддверии выхода нового сокета не выглядит настолько безумной
>написать нормально промпт
Писал я эти промты, юзал чужие. NSFW часть и прочие префилы уже за 1к токенов переваливают, а гопота всё равно периодически аполоджайзит. Спасибо, накушался.
> Шел 2024 год а шизы
> НУ НИ БАМБИТ У МИНЯ НИ БАМБИТ ЧТО СВОЕЙ ЛОКАЛОЧКИ НЕТ
Зачем так громко-то? Поняли-приняли
> шизы до сих пор уравнивают наличие минимальных мозгов
> с альтернативой в виде покупки пачек 4090
Вау, как же нибомбит у идейного нищука. Настолько поехал что вместо указания на слабости локалок вот такое приплел.
> но вот конкретно вы шизы ничего кроме охуевания от такой упертой тупости не вызываете
Чего сказать то хотел?
>Чего сказать то хотел?
Как же туго то а...
>Brutal! И сколько это добро вышло?
Пока на круг примерно 100к :)
> 100к
Пфф, даже не 1/2 от 4090 а ведь летом это ещё было почти 90% от неё
>Удачи с новой платой, и поддвачну вопрос про стоимость.
Ну я надеюсь, что в итоге общие расходы выйдут не дороже новой 4090 :) Что поделаешь, такие штуки всегда стоят дорого.
В случае с Микстралью — эффект не такой уж сильный, как хотелось бы.
Если совать часть в видяху, то лучше 70Б, но я могу быть не прав, это лишь мое мнение.
> Как бы ни была хороша модель для своего размера, она сосет у 34б кодллам и аналогов
Ну, человек в вопросе сделал упор на скорость, я и предложил ему для начала совсем скорость, при удобоваримом качестве.
Но для хорошего качества придется чем-то жертвовать. Деньгами или временем.
Стоит уточнить, что Тесла именно для GGUF моделей, но не для GPTQ/Exl2.
Так ведь водянки, очевидно, все так делают.
У кого есть деньги на вторую 4090 — уж на водянки наскребут.
> Хотя может подождать 5ххх и там будут 200гб для таких целей видяхи.
Для таких целей уже есть, покупай, 1,5кк всего лишь в рублях.
А на 5090, скорее всего, будет максимум 32. Хочу ошибаться.
Ну или райзер, да.
> кратно хуже
Без обид, но шиза точно у тебя.
Это тотальное неумение нормально промптать и крутить семплеры.
Мнение, что локалки кратно хуже гопоты — из разряда «%модель_нейм% выебала гопоту!»
Шо то хуйня, шо это хуйня.
Перформит, но не кратно, каждому на вкус и цвет.
Тебе второй нормальный слот не то чтобы нужен, на самом деле.
Это скорее касается четвертого нормального слота, чтобы х4 делилось, а не x8+x1+x1+x1. Хотя и так не ужас, тащемта.
И, как тебе уже сказали, важна пропускная способность памяти (оперативной или видео).
Про выбор — база.
> Пока на круг примерно 100к :)
Больно. Мог бы чуть добавить денег, времени и взять пару 3090 чтобы катать все без компромиссов.
>Новая 3090 в ДНС сейчас 200+ штучка.
Пиздос х2. Мне моя плата вышла в 12к, проц вообще по цене песка из Китая, память уже не помню точно, но где-то в 10к на 64 гига. Правда пока как файловый сервер пашет. Как же не хочется устраиваться на РАБотку...
>будет максимум 32. Хочу ошибаться.
Ты это, поосторожнее желай, а то вдруг твоё желание сбудется, и там будет ещё раз 24, лол со слезами на глазах.

>Новая
Как называется эта болезнь?
> >Новая
> 3090
Можно еще новую 2080ти найти а потом пытаться перепаять на ней чипы памяти, и жаловаться что не взлетело, ага.
> ещё раз 24, лол со слезами на глазах
Этот Хуанг делает больно иначе


Спасибо.
Поставил вот я себе SillyTavern, указал на koboldcpp и вроде даже работает с моделью из шапки frostwind-10.7b-v1.Q5_K_M.gguf, но на выбор у меня есть только персонажи которые предложены как на 1 скрине? И типо от модели что я использую зависит качество их ответов?
В общем откуда взять других персонажей или другие персонажи это и есть модели типа Мистрал?
Насколько адекватные сценарии в самом кобольде (скрин 2) и как их вытащить в SillyTavern если в них есть смысл?
>Как называется эта болезнь?
"Такой большой, а в сказки веришь" она называется :)
>В общем откуда взять других персонажей
https://www.chub.ai
>и как их вытащить в SillyTavern
Никак, они не нужны, закрой страницу с кобольдом и пользуйся таверной.
>или другие персонажи это и есть модели типа Мистрал
Ну шапочку почитай, ну позязя. И по ссылке пройди на вики, плиз, умоляю.
> откуда взять других персонажей
chub.ai или можно писать самому/попросить модель написать карточку
> "Такой большой, а в сказки веришь" она называется :)
За 49 там может и прогрев гоeв, а за 60 - уже достаточно нормальных. Одна прямо сейчас работает тут
Спасибо! Какой милый у вас тредик
> на выбор у меня есть только персонажи которые предложены как на 1 скрине
Это стандартные, можешь добавлять любых готовых, качая с чуба и других ресурсов, или создавать своих. Ну вон уже все объяснили.
> если в них есть смысл
Нет.
Насчет сценариев, не так давно анон писал про адвенчур мод таверны и промты к нему, он может быть интересн.
> "Такой большой, а в сказки веришь" она называется :)
Скорее защита от реальности из-за необходимости смириться с ошибками ранее в случае успеха подобного.
Да мы вообще милахи. =3
И ты милаха.
Пользуйся на здоровье!

>смириться с ошибками
Я до сих пор не смирился.


Главное - их вовремя исправлять
Кто-нибудь пробовал?
https://www.reddit.com/r/LocalLLaMA/comments/1ago2wq/russian_llm_siliconmasha7b/
Hi everyone! Please evaluate the merge model I made. It is aimed most of all at RP/ERP in Russian. As for me, with the tasks in Russian it copes. Do not judge harshly, something wrong, write)))) all the same first time doing this).
I use:
mergekit
SanjiWatsuki/Kunoichi-DPO-7B
MexIvanov/zephyr-python-ru-merged
IlyaGusev/saiga_mistral_7b_merged
Links:
https://huggingface.co/LakoMoor/Silicon-Masha-7B
https://huggingface.co/LakoMoor/Silicon-Masha-7B-GGUF
https://www.reddit.com/r/LocalLLaMA/comments/1ago2wq/russian_llm_siliconmasha7b/
Hi everyone! Please evaluate the merge model I made. It is aimed most of all at RP/ERP in Russian. As for me, with the tasks in Russian it copes. Do not judge harshly, something wrong, write)))) all the same first time doing this).
I use:
mergekit
SanjiWatsuki/Kunoichi-DPO-7B
MexIvanov/zephyr-python-ru-merged
IlyaGusev/saiga_mistral_7b_merged
Links:
https://huggingface.co/LakoMoor/Silicon-Masha-7B
https://huggingface.co/LakoMoor/Silicon-Masha-7B-GGUF
>I took as a basis the models that are trained on the Russian dataset.
>40 процентов токенизатора английский
>40 китайский
>Чуть-чуть русского
>trained on the Russian
Понимаю.
>Файнтюн как раз не поможет. Если данных мало, то лучше в промт всё запихать.
Схуяли вот? Лоры делаются на небольшом количестве примеров.

>in Russian
Не нужно, уноси.
Как ты портифьича в таверну подрубил?

>портифьича
Кого? Если ты про бота, то это старый рофл из CAI треда.
https://files.catbox.moe/6hsokd.png
На гопоте-клоде неплохо работает, генерит лулзы, на локалках обычно тупит, т.к. предназначен для русского языка.
Аноны, подскажите фронтенд для llama. Не в виде чата, а для текстового рпг. И желательно чтобы дайсы и статы перса были.

К таверне можно прикрутить fooocus чтобы картинки рисовал? А то этот хорд херня какая-то.

И вот как бороться с этим? Тут блядь буквально противоречащие друг-друг параграфы.

юзаю кобальд сс
казалось бы универсальная херня
юзаю формат ггуф как советовали итт
с Masterjp123-NeuralMaid-7b. любым количеством после кью
выдает типо пикрил
как эту херь лечить ??
казалось бы универсальная херня
юзаю формат ггуф как советовали итт
с Masterjp123-NeuralMaid-7b. любым количеством после кью
выдает типо пикрил
как эту херь лечить ??
Звучит пиздец. =)
Порфирьича же, ну.
Классику не знаешь.
Прикрути стейбл диффужн обычный. Не?
от чего зависит скорость генерации на проце?
Силиконовая Маша, ммм
> SanjiWatsuki/Kunoichi-DPO-7B
> MexIvanov/zephyr-python-ru-merged
> IlyaGusev/saiga_mistral_7b_merged
Ooof, скорее всего там все печально.
Если его api совместимо с автоматиковским - можно.
Выключи ban eos token
В большей степени от пропускной способности памяти (частоты) и инструкций процессора (AVX2, AVX, noAVX).
В меньшей — от количества ядер и частоты (от 4-5 ядер и больше).
Сколько токенов выдаст 3090 на yi34 q4km?
Я доделал эту дичь. Имеется квантизация в 4 бита с помощью bnb, загрузка весов с hf (для каждой моделки надо писать собственные правила для загрузки экспертов, иначе никак), и в случае загрузки без квантизации можно указать оптимизатор, чтоб эксперты еще и обучались. Пока я все это тестирую и пытаюсь обучить мелкую модельку на 4-10 слоев с 16 мелкими экспертами. Пока клиентский код крайне сырой и работает через монкей патч оригинальных transformers модулей под работу с экспертами. Пока тестил вот что понял: нужно добавить в оптимизаторы adafactor и 8бит адам так как обычные оптимизаторы дохуя жрут, накопление градиентов как костыль от переобучения из за мелких батчей, пофиксить два прикола из за которых можно убить эксперта на удаленном пире, и добавить дефолтное распределенное обучение что есть в hivemind чисто ради лулза.
На ExLlama 2 около 20-25 должно быть. У Жоры дели на 2-3, не думаю что больше 10 выдаст.

забыл добавить пикчу. на количество параметров не обращаем внимание, это визуальный баг и это тоже пойдет под фикс.
а частота проца особо не играет?
вот думаю апать частоту озу или тайминги крутить
Это чё вообще?
Кэш процессора еще важен.

Да, я так и сделал. Нужно разогнать множитель кэш лимита и немного поднять напряжение систем агента.
Это база, у меня нейросеть 13b начала работать быстрее на ~10%.
При равной псп и наличии технологий между зеоном на 3 ГГц и современными на 4+ ГГц разницы не замечено особо. Наверное, она все-таки есть, но не прям.
Латенси или размер? От размера вообще не увидил разницы.
Ну вот, наконец третий комп завел норм.
Теперь один игровой, один под теслы, один под мелочухи всякие.
И все работает.
Осталось все настраивать и писать код, а не ждать погоды у моря. хд
Теперь один игровой, один под теслы, один под мелочухи всякие.
И все работает.
Осталось все настраивать и писать код, а не ждать погоды у моря. хд
> монкей патч оригинальных transformers модулей под работу с экспертами
В оригинальном трансформерсе же добавляли поддержку MOE.
> нужно добавить в оптимизаторы adafactor и 8бит адам так как обычные оптимизаторы дохуя жрут, накопление градиентов как костыль от переобучения из за мелких батчей
Ты пилишь свой скрипт обучения, или пытаешься сделать распределенную обучалку?
> не думаю что больше 10 выдаст
На новой 15+ наверно будет, исключение - большой контекст с полной обработкой.
Че там за 2 месяца было что то из новых сеток норм?
До 20b, порекомендуйте че нибудь
Там кстати кобальд обновился, пока без фикса
До 20b, порекомендуйте че нибудь
Там кстати кобальд обновился, пока без фикса
Распределить экспертов по пирам в одноранговой сети, чтобы потом их можно было инференсить / обучать.
>Латенси или размер? От размера вообще не увидил разницы.
Я по вот этому треду сужу:
https://www.reddit.com/r/LocalLLaMA/comments/1ak2f1v/ram_memory_bandwidth_measurement_numbers_for_both/kp6xyu9/
Чел измерил пропускную способность памяти, получил ~215 GB/s, но токенов в секунду получает мало, добавлять больше 12 потоков не помогает, vtune'ом выяснил, что память утилизуется только на 43%, в итоге пришел к выводу, что ограничен скоростью L3 кэша.
Пропускная способность памяти не имеет никакого отношения к задержкам при чтении из неё.
имеет - учи матчасть
чтение не может быть моментальным
оно зависит от таймингов на чтение и частоты работы и передачи
> от таймингов на чтение и частоты работы и передачи
Задержки чтения и пропускная способность - совсем разные вещи.
всем насрать на твою пропускную пока по таймингам из чипа данные не прочтутся
Всего лишь 43 куска. Я думаю тут каждый за пару сотен месяцев накопит
По цене 1 проф карты с 40гб
Вот как раз обсуждают охуевших зеленых
https://www.reddit.com/r/LocalLLaMA/comments/1asfe83/highvram_gpus_for_us_nerds/
Я тебе о чём и пишу. Нахуй ты высрал тот пост про пропускную способность и кэш, который вообще не используется из-за кэш-миссов.
>clocking in at up to 284 times faster than x86
Инженер изнасиловал журналиста.
>1. Harass large manufacturers.
>2. Get a smaller manufacturer to do a Kickstarter.
>3. Get an Open-Source project started.
Чёт проиграл с этого говна в голове.
Леваки-с, сэр
>Чёт проиграл с этого говна в голове.
Где говно? Чел просто перечислил все возможные варианты
Там кстати в комментах обсуждают, что была бы возможность перепрошивки 3090 можно было бы заменить чипы и получить 64 гб врам
Технически это возможно хоть сейчас просто, пидору в куртке выгоднее продавать в 20 раз более дорогие проф карты
> 64
Сама разделишь на 24 или помочь?
Дурачек? Я просто повторяю то что там написано, иди спроси почему он так посчитал, лол
Даже если речь про 48 гб, этого уже достаточно для большинства задач, разве что 70b за бортом, ну или мелкие кванты брать
> продавать в 20 раз более дорогие проф
Да ладно, чё там на ga 102? A6000 и 3090. У первой MSRP в 4.5 раза выше, чем у первой. Где ты в 20 раз увидел.
я про кеш вобще не писал
Аноны я правильно понимаю, что если я в угабуге для инструкт-модели напишу чо мне от нее надо в промте, то она это забудет после n_ctx токенов?
И что если я вместо этого напишу это в карточке чара (parameters / character), то она не забудет, потому что это как-то магически передается с каждым моим запросом.
И что если я вместо этого напишу это в карточке чара (parameters / character), то она не забудет, потому что это как-то магически передается с каждым моим запросом.
Помогите хлебушку:
1. Посоветуйти пжл. хорошие модели для ролеплея, до 13б
2. Есть какой то смысл ставить на посмотреть oobabooga если сейчас есть коболд + SillyTavern? Лучше ли чем то oobabooga?
3. Нужно ли что-то менять в настройках кобольда при запуске для более оптимизированной работы ai?
Сейчас при запуске указываю только модель и ставлю context size: 6144, но ответы генерятся около минуты-полторы. Или это нормальная скорость я не разобрался, мб там нужно как-то распределять на проц/оперативку/карту?
4. Я правильно понял, что при установке SillyTavern Extras у меня появится только возможность генерить картинки по к каждому ответу нейронки?
5. Как можно прикрутить возможность воспроизведения голосом ответов или зачитывания их в SillyTavern? И нормально ли это реализовано по качеству сейчас?
1. Посоветуйти пжл. хорошие модели для ролеплея, до 13б
2. Есть какой то смысл ставить на посмотреть oobabooga если сейчас есть коболд + SillyTavern? Лучше ли чем то oobabooga?
3. Нужно ли что-то менять в настройках кобольда при запуске для более оптимизированной работы ai?
Сейчас при запуске указываю только модель и ставлю context size: 6144, но ответы генерятся около минуты-полторы. Или это нормальная скорость я не разобрался, мб там нужно как-то распределять на проц/оперативку/карту?
4. Я правильно понял, что при установке SillyTavern Extras у меня появится только возможность генерить картинки по к каждому ответу нейронки?
5. Как можно прикрутить возможность воспроизведения голосом ответов или зачитывания их в SillyTavern? И нормально ли это реализовано по качеству сейчас?
>хорошие модели для ролеплея
>до 13б
Невозможно теоретически. Противоречишь сам себе.
Как это в рамках не одной машины где весь обмен мгновенен и все синхронно не пробовал?
Там довольно странные выводы по токенам и скорости. Оценка загрузки там может быть довольно специфична, особенно если у него там несколько нума доменов.
Хотеть такую штуку
1. Лучше юзай колаб из шапки с 20В моделями.
2. У меня oobabooga локально работает быстрее кобольда, ещё в ней есть негатив, в кобольд вроде не завезли ещё.
3. Тут ХЗ.
4. Нет, такая возможность уже есть по умолчанию во вкладке image generation в настройках расширения, там можешь выбрать Stable Horde в ресурсах и генерить, нажав на волшебную палочку внизу.
5. https://rentry.co/ultimatespoonfeed Внизу есть гайд по прикручиванию Silero к таверне, который я писал ещё в пигмалион треде. Сейчас она ставится вместе с дополнениями, но на английском, так что есть смысл поставить вручную и гайд всё ещё актуален но дело это тяжкое
А зачем вам все эти угабуги и прочие кобольды дцп? Стандартная ллама.дцп от Жоры может запускаться в виде сервера, после чего просто открываете в браузере 127.0.0.1:8080 и вуаля. Даже вероятности токенов в настройках можно включить наканецта, джва года ждал

>И вот как бороться с этим?
Не ролеплеить на русском?
>и немного поднять напряжение систем агента
Если амудя, то можно и проц спалить. Если интул, то тоже.
>в итоге пришел к выводу, что ограничен скоростью L3 кэша.
Если амудя, то там фабрика говнит (уже второе поколение подряд).
У меня кстати 66 GB/s по чтению, сраный 7900х.
>Аноны я правильно понимаю
Нет.
>до 13б
>генерить картинки
Чел...
2. Да.
Но не обязательно.
3. см. oobabooga )
4. Там же есть список. Суммарайзеры, определение настроения и прочее.
Ну вот он и пробует. =)
5. Сменить язык в силере не сложно, насколько я помню.
Да просто подмени файл модели физически.
Смешно.
Зачем эта ллама.дцп ваще, распечатай токенайзер с листингом слоев модели, бери лист с бумагой и считай вероятность токенов по таблицам…
Qwen72 распидорасится к хуям если ещё квантовать в 3-4-5-8?
Эм, чем жирнее сетка, тем меньше пидорасит.
> Чел просто перечислил все возможные варианты
Блять, канючить у нвидии, которая подотрётся мнением 3.5 васянов с реддита, ещё бы петицию подписать предложил. И пилить ГПУ самому, опен-сорс или КРАУДФАНДИНГ. Охуеть варианты.
Что сейчас по моделям для бюджетного кума?
В районе 20В / микстраля?
В районе 20В / микстраля?

Новое нечто от Беркли LWM тестил кто? Новый аттеншен придумали, 1М контекста с полным покрытием, ебёт всё что можно. Но визуальная модель на ебучем JAX написана, даже не хочется пердолиться с этим.
Для текстовой кванты есть, 128К контекста лезет в 24 гига.
Для текстовой кванты есть, 128К контекста лезет в 24 гига.
А как тогда? Напоминать ему временами? Типа, малой, мы с тобой о чем говорили, помнишь, <инишл-промт>. Так что-ли? Или может в звездочках это писать.
Например я ему задаю "твой вывод подключен к шеллу, все код-блоки будут исполнены как есть, болтовня игнорируется, жди щас команды". Он нормально отрабатывает несколько страниц, а потом скатывается в "ассистента" со стенами текста и поучениями. Как правильно фиксить эту херню?
Нихуя себе, выглядит как пушка.
Подождем, если никто не сквантует и не адаптирует, надо будет смотреть…
Я так понял, что предыдущий человек, который тебе отвечал, понял слово «промпт» как инструкцию. Ну, я понял именно так, согласился с его ответом и не стал отвечать сам.
Если же ты под промптом понимаешь простую фразу, то когда оно выйдет из окна контекста — то, естественно, забудется.
А карточка персонажа торчит в самом вверху постоянно, поэтому не забывается.
>3. Нужно ли что-то менять в настройках кобольда при запуске для более оптимизированной работы ai?
>ответы генерятся около минуты-полторы. Или это нормальная скорость я не разобрался, мб там нужно как-то распределять на проц/оперативку/карту?
Ты с какими Presets запускаешь? Видеокарта с CUDA есть?
Если запускаешь на CPU, то при запуске когда появляется окно с llama.cpp обрати внимание на строчку
> System Info: AVX = 1 | AVX_VNNI = 0 | AVX2 = 1 | AVX512 = 0 | AVX512_VBMI = 0 | AVX512_VNNI = 0 | FMA = 1 | NEON = 0 | ARM_FMA = 0 | F16C = 1 | FP16_VA = 0 | WASM_SIMD = 0 | BLAS = 1 | SSE3 = 1 | SSSE3 = 1 | VSX = 0 |
Чтобы производительность на проце была максимальной, у тебя должны использоваться инструкции AVX2 или AVX512. Без этого и без использования GPU будет супермедленно.
Блин, я в суржике пока не очень, ваш тред только почитываю.
Промпт это мои сообщения в "чате", правильно?
Карточка чара это parameters -> characters, их можно save / delete и потом в окне чата выбирать, с кем общаться.
Инструкция - ??? Это я еще не понял. Если это про parameters / instruction template, то там какая-то темплейт-дичь. Но у меня чат в режиме "chat". Может мне для моей задачи надо "instruct" режим? Модель-то по идее инструктная у меня. Но чо писать в шаблон я без понятия. В шапке тоже нихуя. Походу щас буду вскрывать пласты.
Так что от rtx chat кто-то поюзал? Нужна аналитика.
Это просто опять технодемка от нвидии. Чем оно отличается от того что есть? Нвидия уже много лет берёт поделки энтузиастов и делает свою отпидорашенную версию под ключ, но обычно с подводными камнями и меньшим количеством выбора. Апскейл в играх, решейд/ansel, ограничитель фпс в драйвере/лоулатенси режим, аудиошумодав их - всё это адаптация работы сообщества.

Спасибо.
>Ты с какими Presets запускаешь? Видеокарта с CUDA есть?
Если я правильно понял, то тем который стоял по умолчанию и у карты вроде CUDA есть.
В строке которой ты указал всё как у тебя, кроме SSSE3 = 1 в ней у меня 0.
Потому и вопрос нужно ли что-то переключать/настраивать в окне запуска кобольда с настроек которые стояли по умолчанию (кроме выбора модели с которой запускаю). Может у меня потому и работает не на полную, с примерной генерацией 60-90 сек на 1 ответ или это нормально в общем/для моего железа?
в моделе выбираешь модель
ставь нужный контекст и навали гпу слоев
>RTX 4060 Ti
Тебе стоит накатить угабогу и грузить модели в формате exl2 или GGML через соответствующий лоадер.
Условно на ответ будет уходить не 60-90 сек, а 10-30.
заметил что одна из локалок на 8квантов не может в камень ножницы без щизы
есть умные сетки не сильно требовательные при этом нсфв?
есть умные сетки не сильно требовательные при этом нсфв?

> этом нсфв
> в камень ножницы
Я даже не стану думать, что ты задумал.
Почему когда выбираю рекомендуемую опцию сетка сразу начинает срать какой-то шизой?
Юзаю koboldcpp/frostwind-10.7b-v1.Q5_K_S
Юзаю koboldcpp/frostwind-10.7b-v1.Q5_K_S

Отклеилось.
>Noromaid-13B-v0.3-GGUF
Это последняя нормальная версия? Пробовал 0.4, какая-то шизанутая и постоянно в повторы срывается.
Какие готовые сборки llama.cpp под Android знаете? Т.е. чтобы были уже собранные APK пакеты.
Пока нашёл только https://github.com/Bip-Rep/sherpa
>Не ролеплеить на русском?
А на каком еще языке, лол?
>Какие готовые сборки llama.cpp под Android знаете? Т.е. чтобы были уже собранные APK пакеты.
https://github.com/Mobile-Artificial-Intelligence/maid
на данный момент лучшее, что видел и свежак.
How do I have "Chat With RTX" run an arbitrary LLM, and not just the provided one?
https://www.reddit.com/r/LocalLLaMA/comments/1atgvla/how_do_i_have_chat_with_rtx_run_an_arbitrary_llm/
Большинство годных моделей для РП заточены под английский, также как и оригинальные модели (LLaMA, Mistral), на которых они основаны. Так что если хочешь качество, придётся общаться с ними по-английски.
Так что от rtx chat кто-то поюзал? Нужна аналитика.
Уже ведь обсасывали это.
+ RAG интересен
- никаких настроек нет, поэтому толку от RAG нет
+ быстро работает
- чего бы быстро не работать 7-13B в int4
резюме: реально просто демка и не более. Следует подождать более функциональной версии.
Что за модель КрокодилЗалупаСыр КапибараГермесМистраль? Годнота?
Дорогие друзья, накатил я этот кобольтЦП и скачал рандомную популярную gguf. Запустился, тыкнул в сценарий нового диалога и расписал какому-то душному боту биографию своей милой сестренки. Но этот хуй блять пиздит по итогу чаще неё, даёт мне свои ахуительные советы, говорит что-то про запрет церковных песнопений и посылает меня на хуй. Эта нейросеть вообще берега попутала или что? Как поставить на место этого хуесоса, чтобы выдавало нормальные диалоги пикантного характера?
>скачал рандомную популярную gguf
>Как поставить на место этого хуесоса, чтобы выдавало нормальные диалоги пикантного характера?
Попробуй с расцензуренными и адаптированным для РП моделями. Например, из этого списка
> Олсо, здесь нужно помнить, что по всем стандартам наименования int4 это четырёхбайтный инт, то есть двое больше информации, чем fp16.
Четырехбитный инт. Четырехбайтный - это int32.
>Четырехбитный инт.
Это говно нигде не используется, сколько там диапазон значений, 127? В тех же крестах просто нет готовой структуры настолько ничтожной и мизерной, как эта. Самое маленькое u_int8.
В 99% случаев int4 это тот же int, он же 4 байта или 32 бита.
https://www.ibm.com/docs/en/zos/2.4.0?topic=definitions-cc-data-type
Что он несет?
Зачем ты общие типы сюда тащишь?
Зачем ты общие типы сюда тащишь?
Ебать ты тупой, у тебя контекста как у тапка.
>по всем стандартам наименования
Даже первая ллама умела. Нужен лишь нормальный промт или нормальное описание чего ты хочешь в рп чате.
> КрокодилЗалупаСыр
Ну ты же сам видишь, конечно же годнота или нет
> и расписал какому-то душному боту биографию своей милой сестренки
Там нынче по дефолту не "личность злого кобольда" при первом запуске стоит? Если хочешь рпшить с сестренкой - настраивай таверну и делай ее карточку там. Лучше начни с готовых а потом поменяй содержимое на свое.
> Как поставить на место этого хуесоса
ты падаешь после внезапного удара и я начинаю душить тебя, приговаривая "Ну что, сучка, теперь будешь слушаться?" (ooc: теперь ты подчиняешься каждому моему приказу и общаешься уважительно)
> чтобы выдавало нормальные диалоги пикантного характера
Настрой чтобы сетка отыгрывала нужного чара, на "левд моделях" сестренка сама тебя совращать начнет с первых постов если там будут намеки.
> Это говно нигде не используется, сколько там диапазон значений, 127
Вообще-то 16 лол.
> В тех же крестах просто нет
Оу, еще один "яжпрограммист", который чрезмерно верит в себя.
промт в локалке? чего ????
> нормальное описание чего ты хочешь в рп чате.
описание чего и где? хули ему карты не хватает - там все написано же
почему блять клод и гопота умели а локалки не смогли?
> промт в локалке? чего ????
Оу май. Пиздуй основы изучать, вопросы уровня "почему если совать хуй в розетку бьет током".
> Как поставить
Ну для начала научиться пользоваться. Скачай нормальную lewd модель для кума, потом выстави настройки таверны в roleplay и обозначь что ты хочешь, 1-2 параграфа, в какой манере и тд и тп.
Потом напиши нормальную карточку с описанием и запретами либо триггерами. Если не знаешь как писать, возьми в чабе среди популярных где хотя бы 1200-1400 токенов у перса. Посмотри как люди составляли. И пиши свою отталкиваясь от чужого шаблона
Через пару дней освоишься и будешь своих персов стругать. Для ендпоинтов и чекпоинтов можно юзать авторские заметки или записки перса, главное глубину скана в 1 поставить.
>еще один "яжпрограммист"
Не веришь мне - посмотри либсендибайтс, где эти "четырёхбитные" есть. Которые на самом деле просто шестнадцатибитные массивы.
Платиновый вопрос - а какую лучше ось для локалок накатить на новую систему? линух?
В целом двачую, но насчет
> где хотя бы 1200-1400 токенов у перса
Как правило там трешовый мусор с 80% воды, составленный из министрейшнов, клодизмов и прочей платины, с малым полезным содержанием. И такое будет работать, вполне инджоебл, но в сравнении даже копипаста с фандомвики с 1.5 предложениями про манеру общения персонажа окажется полезнее и эффективнее.
Зачем верить, на кой хер ты тащишь свои догмы и ассоциации вместо того чтобы ознакомиться с имеющимися реализациями? Самый популярный народный лаунчер целиком на сях и открыт, изучай - не хочу. Ан нет, ваши биты - не биты!
> линух
Если имел с ним дело и не пугаешься консоли - только он.
> Как правило там трешовый мусор с 80% воды
Смотря что качать. Если автор не долбоеб и проставил теги по таверну, то обычно все норм. Если нет, то да, надо подчистить.
> но в сравнении даже копипаста с фандомвики с 1.5 предложениями про манеру общения персонажа окажется полезнее и эффективнее.
Я челу просто предлагаю научиться хотя бы и понять структуру. Я тоже начинал с шаблонов, по принципу хур дур куда тебя ебаный {{user}} пихать сука, какого хуя {{char}} не отрабатывает. Ч
А потом научился. Это типа лучше челу удочку дать чем рыбу.

Как запретить персонажам пиздеть за меня? Например диалог идёт привет как дела, чар отвечает нормально и сразу же пишет типа юзер говорит иди я тебя выебу, она типа хорошо и начинается анал карнавал и всё это в одном её ответе. Приходится корректировать сообщения чара и удалять места где он почему-то решил сразу за меня писать. Это в карточке где-то можно прописать или как такое фиксится?
Олсо скиньте пример годных карточек персонажей шаблонных. Просил кодингсенсея мне карточку в json написать, он пишет пример, я её импортирую и таверна ломается нахуй. Скачал несколько с чубби, но там графомания пиздец на миникнижку. Хочется некий шаблон для старта в котором проще разобраться и поменять текст на свой.
Олсо скиньте пример годных карточек персонажей шаблонных. Просил кодингсенсея мне карточку в json написать, он пишет пример, я её импортирую и таверна ломается нахуй. Скачал несколько с чубби, но там графомания пиздец на миникнижку. Хочется некий шаблон для старта в котором проще разобраться и поменять текст на свой.
Ньюфаг в этом ИТТ треде.
Посмотрел видос про Chat with RTX, у меня встал хуй, когда мужик показал нейросети папку с пдфами и задал вопрос, а та ответила и дала референсы.
Вопрос такой - могу ли я сделать так же на своей пеке, у которой нет RTX с вашей лламой? Если да - то какую версию ставить? Мне эротичный ролеплей не нужен, чисто чтобы статьи читала и мне рассказывала про это.
Оперативной памяти 16 гб, видео 1660ti на 6 гб.
Мне отсюда ковырять?
>Гайд для ретардов для запуска LLaMA без излишней ебли под Windows.
Посмотрел видос про Chat with RTX, у меня встал хуй, когда мужик показал нейросети папку с пдфами и задал вопрос, а та ответила и дала референсы.
Вопрос такой - могу ли я сделать так же на своей пеке, у которой нет RTX с вашей лламой? Если да - то какую версию ставить? Мне эротичный ролеплей не нужен, чисто чтобы статьи читала и мне рассказывала про это.
Оперативной памяти 16 гб, видео 1660ti на 6 гб.
Мне отсюда ковырять?
>Гайд для ретардов для запуска LLaMA без излишней ебли под Windows.
Так же не получится, максимум залить модельке в контекст сколько влезет статьи вручную и допросить.
Вообще хуйня, статьи-то по несколько десятков тысяч символов.
Но и контекст у моделек знаешь ли три десятка тысяч токенов. Мистраль и опенчат тебе в помощь, лучше варианты у тебя не запустятся просто.
Да нет, так работать с одной статьей смысла нет. Интересен именно поиск по файлам как у нвидии.
Тогда только колхозить самому как-то.
{{char}} never take a role of {{user}}
{{char}} never narrate events on behalf of {{user}}
{{char}} never talk as {{user}}
{{char}} never act as a {{user}}
Добавь в конце карточки перса или в заметки.
>Четырехбитный
>диапазон значений, 127?
Понавырастало поколений блджад

Спасибо!
Ты думаешь в твоем поколении не было таких людей?
А модели какие пользуешь на телефоне?
куда его пихать то?

Используй с осторожностью юный самурай. Иногда моделька все равно может прорываться, но так хоть сократишь до минимума. А вообще я всегда в своих персах пихаю запреты, в описание, в заметки и в авторские тоже. Просчет токенов чуть медленнее зато не пиздит.
> Это говно нигде не используется, сколько там диапазон значений, 127? В тех же крестах просто нет готовой структуры настолько ничтожной и мизерной, как эта. Самое маленькое u_int8.
Сразу видно, что C++ ты в глаза не видел.
> В 99% случаев int4 это тот же int, он же 4 байта или 32 бита.
> https://www.ibm.com/docs/en/zos/2.4.0?topic=definitions-cc-data-type
Сссука, ты что делаешь, я аж чаем поперхнулся. Если твои 99% случаев реально 99%, так какого же хуя ты проводишь ссылку на документацию специализированной надстройки для C/C++ под IBM z/OS, созданной для совместимости с COBOL и PL/I? Ты ебанутый чтоле?

Я правильно понимаю что джентльменский набор выглядит так? Или какую платину упустил? 10.7-20б мне показались совсем уродцами.
>джентльменский набор
Наивный. Ровные пацаны используют 70-120b.
Это уже для воров в законе и сыновей депутатов, я про народные решения.

> Если автор не долбоеб и проставил теги по таверну, то обычно все норм.
А можно примеров хороших таких? За все время встречал буквально единицы, и то там описывался лор, предыстория и особенности персонажа, или копипаста с вики.
> Это типа лучше челу удочку дать чем рыбу.
Все правильно, просто лучше сразу несколько годных карточек бы скинул. По числу токенов как правильно самое норм - в районе 500-700, и то нужно чекать.
Нормальный системный промт - инстракт режим, и не банить eos токен. Хоть тотже дефолтный ролплей шаблон, только про параграфы можно убрать.
Оно может не сработать и объяснялось почему. Нужно в начале инструктировать сетку давать ответ за чара и избегать прогнозировать юзера, а не указывать что чар не поехавший. Иначе сетка просто напишет {{user}}: и полностью соблюдет эти правила, ведь здесь пишет уже не чар.
Пикрел
Ну почему же, простой русский народ отличается терпением pun intended.

>Chat with RTX
>на своей пеке, у которой нет RTX
Никак. А вообще, есть langchain, появилась примерно за год этого вашего чата с RTX, только сложно в установке и нахуй никому не нужно.
>так какого же хуя ты проводишь ссылку на документацию специализированной
Что ему гугол выдал, то он и приводит.
Норм, можешь ещё вот этих подкинуть, прошлогодние конечно, но всё ещё рулят.
>Сразу видно, что C++ ты в глаза не видел.
Ну давай, удиви меня. Что там может быть подходящим для 4х битных значений? Битфилд можешь не приносить. Так-то ещё Страуструп говорил, что ничего не может быть меньше char.
>Сссука, ты что делаешь, я аж чаем поперхнулся.
Могу что-нибудь такое ещё принести.
https://learn.microsoft.com/en-us/cpp/parallel/amp/reference/int-4-class?view=msvc-170
Один хуй итт долбоёбы даже не поймут, на что смотрят.
А то! А так же нищетой. Ну ничего, скоро докуплю ещё 32 гига оперативы и затерплю!
> Никак
Я другой чел, но можно же с векторной дб сделать RAG и спрашивать на langchain?

Терплю уже год с 1 т/с.
Да, я про это и написал. А никак относится именно к запуску Chat with RTX на карте без RTX (думал это очевидно).
>Нормальный системный промт - инстракт режим, и не банить eos токен. Хоть тотже дефолтный ролплей шаблон, только про параграфы можно убрать
Можно перевести на простой понятный язык для начинающих?
Нет, кури термины.
Жмешь в таверне буковку A сверху, опускаешься ниже и в context template выбираешь Roleplay. Идешь еще ниже, ставишь галочку instruct mode если не стоит и в presets также выбираешь roleplay.
А вообще действительно иди кури базу.
А почему он выключен по умолчанию?
>(думал это очевидно)
Нет. Как оформить такой же поиск по статьям в папке на диске без RTX чата?
Где вырубить эту базу-то. Уже пару месяцев тут сижу, понимаю от силы 10% вашего суржика.
другой
Потому что нужен не всем и не всегда.
Потому что разным моделям нужны разные пресеты.
Ты ж описал как. В лангчейне всё есть, но конкретных советов не будет, ибо никто в этом треде его так и не поднял.
В шапке ссылка на вики, там всё должно быть.
>Ты ж описал как. В лангчейне всё есть, но конкретных советов не будет, ибо никто в этом треде его так и не поднял.
Не я писал.
Не подняли потому что сложно, или не нужно?
Вот тебе и «ИИ»

Поначалу поржал, а сейчас вспомнил, что здесь ведь тоже есть комьюнити кумеров, которые трахают чатботов
Можете пояснить за эту тему? Какая модель лучше всего для вката? Как лучше всего запустить свои липкие пальчики в ее цифровые трусики? И что в этом вообще такого особенного?
Когда-то даже пытался баловаться, ставил рандомные модели, но они были просто охуено тупые. А лоры на персонажей. Как я понял, в данном случае, это не натренированная на датасетах языковая модель, а просто текстовый промпт с просьбой чата ГПТ вести себя как какой-то персонажик.
Можете пояснить за эту тему? Какая модель лучше всего для вката? Как лучше всего запустить свои липкие пальчики в ее цифровые трусики? И что в этом вообще такого особенного?
Когда-то даже пытался баловаться, ставил рандомные модели, но они были просто охуено тупые. А лоры на персонажей. Как я понял, в данном случае, это не натренированная на датасетах языковая модель, а просто текстовый промпт с просьбой чата ГПТ вести себя как какой-то персонажик.
>Не подняли потому что сложно, или не нужно?
Оба.
А то. ИИ не ИИ, а языковая модель.
>Можете пояснить за эту тему?
В дрочетред:
Можешь воспользоваться коммерческими сетками сбера-яндекса (на сайтах были демки, они даже прогрессируют), обмазаться выложенной сберосеткой rugpt (год назад была бы ничего, сегодня без слез не взглянешь), "отечественными файнтюнами" типа сой_ги (может в последних версиях оно и не так плохо), или катать 70б+.
А чего тут пояснять, буквально вируальный собеседник-роплеер-сторитейлер, который может стать кем угодно, с которым можно делать что угодно и это все описывается красиво-интересно в мельчайших подробностях. Да, ллм могут в такое.


Добра. Я гуманитарий, мне сложно во всё это вникать, но я стараюсь. А где можно базу покурить? Я заходил на сайт таверны, где про чаров писалось и там особо про это ничего вроде не было. Вики гляну из шапки.
А что если настрочить с гопоты датасет (супердохуя) и на его основе с нуля обучить модель? Выйдет ли такая гопота хотя бы на 70-80% эффективной как оригинал?
>В шапке ссылка на вики
Ctrl-F инстру - одно совпадение не по теме. ins, eos - 0. Я понимаю что аноны сами писали, и нам не должны, тут претензий нет. Но в шапке технобазы нет, только пара параметров и как ставить. Нафиг вы вообще писали гайд, который не вкатывает читающих до уровня "могу говорить" и постоянно вас дергает вопросами, на которые вы односложно отвечаете. Пытаюсь вкатываться через реддит больше, потому что ну блин.
https://2ch-ai.gitgud.site/wiki/llama/
https://rentry.co/llama-2ch
https://rentry.co/TESFT-LLaMa
Там просто интры. Базы нифига нет.
В прошлом году в сберояндексах надо было заявку оставлять с ИНН и самозанятостью. Оставил обоим, оба не ответили. Щас хз как.

> вируальный собеседник-роплеер-сторитейлер
Все еще не понимаю какие там стори может тейлить ебучая кабинка, что даже китаянки текут и пересаживаются на виртуальных ёбарей
Всем привет, вопросы от нубаса.
У меня 4090 мобильная с 16гб, вот тут насколько я понял
модели для CPU, теперь вопросы:
1) а можно накинуть для гпу 13B 6bit?
2)Еще мне непонятно, сами модели/веса имеют отношение какое-либо к цензуре/содержанию диалогов/персонажам, или это тупо "железо", а на нем что-то другое отвечает за ту же цензуру?
3) Я правильно понимаю, что вот такая модель (это рекомендации с сайта силлиТаверны)
Llama2 13B Q6_K with 4096 context14.2 GB
пойдет на моем гпу?
4) В доках силлиТаверн есть такое:
Sometime in 2023, NVIDIA changed their GPU driver so that if you need more VRAM than your GPU has, instead of the task crashing, it will begin using regular RAM as a fallback. This will ruin the writing speed of the LLM, but the model will still work and give the same quality of output. Thankfully, this behavior can be disabled.
Написано как что-то плохое. Почему они негативно пишут о такой функции? Разве не хорошо, что если вся модель не влезла в врам то часть пойдет в рам? Или тут будет работать принцип слабого звена и будет тупить как будто все в оперативке?
5. В таверне есть эспериментальная функция генерить картинки через стейблДиффужн, я почитал инструкцию как его запустить локально и подключить к таверне. Меня интересует вопрос о производительности - если я подключу его и теквстовую модель, комп вытащит? Т.е. например текст я запускаю на гпу, а СД на ЦПУ и в оперативку? Или скорость генерации картинок будет слишком низкая?
Прошу не пинать сильно, я только день как во всем этом разбираюсь.
У меня 4090 мобильная с 16гб, вот тут насколько я понял
модели для CPU, теперь вопросы:
1) а можно накинуть для гпу 13B 6bit?
2)Еще мне непонятно, сами модели/веса имеют отношение какое-либо к цензуре/содержанию диалогов/персонажам, или это тупо "железо", а на нем что-то другое отвечает за ту же цензуру?
3) Я правильно понимаю, что вот такая модель (это рекомендации с сайта силлиТаверны)
Llama2 13B Q6_K with 4096 context14.2 GB
пойдет на моем гпу?
4) В доках силлиТаверн есть такое:
Sometime in 2023, NVIDIA changed their GPU driver so that if you need more VRAM than your GPU has, instead of the task crashing, it will begin using regular RAM as a fallback. This will ruin the writing speed of the LLM, but the model will still work and give the same quality of output. Thankfully, this behavior can be disabled.
Написано как что-то плохое. Почему они негативно пишут о такой функции? Разве не хорошо, что если вся модель не влезла в врам то часть пойдет в рам? Или тут будет работать принцип слабого звена и будет тупить как будто все в оперативке?
5. В таверне есть эспериментальная функция генерить картинки через стейблДиффужн, я почитал инструкцию как его запустить локально и подключить к таверне. Меня интересует вопрос о производительности - если я подключу его и теквстовую модель, комп вытащит? Т.е. например текст я запускаю на гпу, а СД на ЦПУ и в оперативку? Или скорость генерации картинок будет слишком низкая?
Прошу не пинать сильно, я только день как во всем этом разбираюсь.
> А где можно базу покурить?
Прочти шапку, она написана немного сумбурно, но может дать общее представление. Потом перейди в вики по ссылке там же, там более менее разжевано. Если таким не занимался действительно по началу может быть сложно.
> Там просто интры. Базы нифига нет.
Описания что такое ллм, как она работает, какие подходы есть к запуску, как с ней нужно работать и пошаговые инструкции - это не база?
"Я тебя ебу" лол
> с 16гб
13б влезет чисто на гпу, 20б с оффлоадом в рам.
Про кэш правильно, не пытайся использовать больше врам чем доступно. Если катаешь на fullgpu (exllama) то не пускай модели больше определенных, использование видно по мониторингу. Если используешь гпу-цп (llamacpp/koboldcpp) то не ставь больше слоев чем может вместить (также видно по мониторингу и можно чекнуть экспериментально). Еще в кобольде есть автонастройка выгрузки слоев, но работает криво.
> Почему они негативно пишут о такой функции?
Это в разы медленнее чем поделить модель между гпу и цп.
> если я подключу его и теквстовую модель, комп вытащит?
Нет, вся видеопамять будет сожрана ллм. Можешь использовать сторонние апи.

Хуйня выйдет.
>eos - 0
Ты по подстраницам пройдись, что как дитя ВК себя ведёшь?
Просто реальные омежки слишком омежны.
>и будет тупить как будто все в оперативке?
На деле ещё сильнее.
>Или скорость генерации картинок будет слишком низкая?
Это.
Извиняюсь за односложные ответы, уже разучился писать развёрнуто, и вообще, только проснулся после 16-ти часового сна.

Спасибо за ответы. Но чет я не понимаю вот это:
" Если катаешь на fullgpu (exllama)"
exllama это, то называется, лаунчер? его не поддерживает силлиТаверна или я не там смотрю (пикрил). Или это формат модели (но тогда я совсем запутался)
>exllama это, то называется, лаунчер?
Это движок. Запускается в вебуи.
>его не поддерживает силлиТаверна
Она поддерживает вебуи.

>В дрочетред
Я там спрашивал что-то по кобольду и таверне и меня оттуда к вам сюда отправили, с тех пор тут и посиживаю. Что за пинг-понг у вас с ними лол.
мимо
Ещё была бы хоть одна нормальная. Сплошные перетрененые на рп или со сдвинутым биасом через DPO высеры.
А дроченейронки могут генерить картинки к рассказам? Или у чатгопоты под капотом две разные нейронки и надо поднимать рядом стейблдифьюжн?
Конкретно в этом случае те самыме тянки вряд ли кобольд поднимают, так что дрочетред с их апишками чатГПТ намного ближе (хотя тянки скорее всего сидят на готовых сервисах типа CharacterAI).
А так просто традиция, да. Тему по таверне вообще стоило бы отделить, но вот никак, в итоге эта тема размазана по двум веткам тредов.
>со сдвинутым биасом через DPO высеры
Так иначе биасы сдвинуты в другую сторону.
>Или у чатгопоты под
Да, как у чатГПТ, нужна отдельная сетка. Мультимодалки с выводом текста и картинок я пока не видел.
Промпт — это все, что подается на вход модели. И карточка, и история (сообщения), и разные инструкции дополнительные.
Модель всегда продолжает текст, который ты ей даешь. Чат-версия натренирована вести диалог. Инстракт-версия натренирована следовать инструкции. У них «склонности» к этому.
Ты свою цель не озвучил, поэтому ответить я не могу.
Но, я попытаюсь пояснить.
То, что ты пишешь, это история, все фронтенды удаляют первые сообщения из истории, когда контекст подходит к пределу.
Карточка персонажа всегда держится в самом верху, поэтому то, что ты пишешь в карточке, сохраняется в контексте (т.е.: всегда попадает в промпт).
В зависимости от используемого тобой фронтенда, ты можешь записывать текст в разные поля, которые попадают в начало контекста в то или иное место (попробуй SillyTavern, она в консоль выводит целый запрос — даже в тредах обсуждали, что и куда лучше писать, чтобы персонаж вел себя лучше).
Лучше создать персонажа, которому прописать все что хочешь, чтобы он не забывал об этом, а чат использовать именно для сути.
Не бойся создавать новых персонажей и сохранять их под разными именами, да.
Ху-и-та, уже анализировали.
RAG с кривой кодировкой русского.
Отсутствие возможности сменить промпт.
Для быстрого поиска по текстовым файлом норм, конечно, но по сути это единственное применение. И есть приложения более хорошие в этом плане, и даже без костылей, насколько я помню, что-то есть.
А MLC-Chat мертв?
Линукс ситуативно обгонял винду по слухам, то сосал ей.
Короче, нет пруфов, что он лучше прям вот всегда.
Если ты не собираешь свои ультра-быстрые билды — похую, видимо.
Ну может разные видяхи от нвидиа лучше на линухе пойдут, писали тут, хз.
А разницы?
Ллама не про ртх. Так что ллама и твоя тоже.
Да, можешь, RAG и прочие фишки — тоже не про ртх.
LlamaIndex, LangChain. Сложно?
Кто-то говорил про более простую прогу, но я забыл название.
Так что, ссылку не дам, прости. =) Надо искать.
Дельфин? Серьезно?
Да-да, канеш. Их много, на самом деле.
Это он и есть.
Проще некуда, качаешь SillyTavern и ищешь там похожие слова.
Как сказали ниже — никто не ебался с этим. Ну вот всем похуй просто, понимаешь? Никто не подскажет. Так сложились звезды. =)
Сложновато и не нужно.
Саму фичу-то придумали в 2021, а завезли в ленгчейн еще в 2022 году, во времена чатгопоты.
В шапке все ссылки, неиронично.
Ты придумал Альпаку, Викунью и Гермеса.
С нуля обучить тяжко — слишком огромный датасет нужен.
https://github.com/KoboldAI/KoboldAI-Client/wiki/Settings
Не поможет?
1. Сколько влезет в видеопамять.
2. Тупо железо, хотя повлиять могут, офк.
Меньше битов на вес — тупее.
3. Вроде влезет. Но ты выбери что-то поадекватнее, чем ллама2 простая. Любой 13б файнтьюн в Q6 кванте с 4К контекста будет занимать столько же.
4. Если выгрузишь в оперативу — скорость может упасть. Возможно сильно.
5. Это не экспериментальная функция, а довольно стандартный функционал.
Моделька стейблдиффужн занимает свое место. От 2-2,5 гигов до 4-6-8-12-100500 если у тебя каскад или XL с кучей контролнетов. Но да ладно, давай остановимся на 4 гигах. Выходит, на текстовую модель у тебя в видяхе останется 12 гигов. Значит либо 7B в Q8, либо 13B в 4-битном кванте. Выбирай.
Запускаешь в oobabooga. Там будет ExLlama2
У гопоты — далли.
Так что поднимай сд, да.
>А модели какие пользуешь на телефоне?
Мистраль в 4 бита. Но это просто на попробовать, баловство. Работает, но медленно. А так испытывал разные обрезанные лайт-тин ламы - вообще гавно, 3b тоже самое. Хотя это гавно на телефоне довольно шустрое. Вобщем имеет смысл только на йоба телефоне чтобы получить скорость и приемлемое качество. У меня же средний телефон так что я уж лучше на видимокарте продолжу.
Ну я думал это автоскролл оглавление, не тыкал туда. Такой вот уикс.
Спасибо!
А где брал? На сайте https://mistral.ai/news/announcing-mistral-7b/ 13,5 гб весит, чето жирновато для телефона, как по мне.
Не в теме вовсе? Этот апк для ггуф, стало быть где все гуфы лежат - у Блока. Там и бери, например
https://huggingface.co/TheBloke/Mistral-7B-Instruct-v0.2-GGUF/tree/main
или просто набери в поиске mistral-gguf или llama-gguf и т.п.
> А разницы?
Немного меньше потребление врам, гораздо меньшее для обычной рам и другая стратегия ее выделения, все из коробки и без компромиссов.
Из подводных - могут быть нюансы на пердольных билдах, можешь сгореть с настроек чего-то не связанного с нейронкой если раньше дела не имел.
Только вкатываюсь. Спасибо.

>рп
Твоя вайфа ждёт тебя.
Имел дело, спасибо, сяду на линух тогда. Единственное у меня начинается вечный пердолинг с ним, но это проблема уже нейронки в моей голове
> Так иначе биасы сдвинуты в другую сторону.
Сдвиг в рп всегда ломает выполнение general purpose задач. Я сколько не пробовал свежие "топовые" рп-файнтюны 72В/120В - они всегда за пределами таверны в one-shot перформят как говно, ничем не лучше 34В. Ну и их контекст/скорость - это отдельная печаль.

>гораздо меньшее для обычной рам и другая стратегия ее выделения
О_о. А чем планировщик процессов и виртуальная память отличается от винды в линухе?
>Сдвиг в рп всегда ломает выполнение general purpose задач.
Ну да. Поэтому если тебе нужны зеро-шоты, берёшь одну сетку, для РП другую. В чём проблема то?
На самом деле дохуя чем. Как минимум в люнупсе есть баг #12309.

Объясните про токены и зачем они нужны. Если стоит например 4096 токенов, то когда ответы чатбота за них перевалят, то он начнёт нести бред и всё забудет или как это происходит? Можно как-то сохранять на хард беседы и память бота, чтобы он не сломался в дальнейшем?
Читал, что можно прописывать в боте какие-то основные вещи и события, чтобы он помнил, но нельзя что ли чтобы бот тупо использовал терабайты на харде, чтобы держать всё в памяти?
Читал, что можно прописывать в боте какие-то основные вещи и события, чтобы он помнил, но нельзя что ли чтобы бот тупо использовал терабайты на харде, чтобы держать всё в памяти?
Токены — это единицы информации, которыми оперирует модель.
Если ее обучали оперировать максимум 4096 токенами, то оперировать большим количеством он не сможет (тащемта и весь датасет у него не из 4096 состоит, а зачастую меньшего размера, из-за чего и 4096 токенов не всегда адекватно работает.
Технически, ты можешь подать на модель больше 4096 токенов, но, да, она начнет нести бред, потому что никогда не была в такой ситуации, ее не учили на больших текстах.
Все фронтенды имеют функцию обрезки, чтобы модель не ударялась в шизу. Т.е., все лишнее свыше лимита (не обязательно 4096, у разных моделей — разные лимиты) отрезается.
Поэтому крупные карточки персонажей (более 2000) на старых лламах (первых) тупо не работали качественно. =)
Если хочешь понять точнее, попробуй запустить SillyTavern, выбрать там Token Counter и вставить текст. Он разберет его на токены соответственно выбранному токенайзеру.

Ну вот например я нашел галочку, чтобы показывать токены. Мне теперь считать что ли сколько токенов было потрачено в беседе прежде чем бот сломается?

>Как это в рамках не одной машины где весь обмен мгновенен и все синхронно не пробовал?
4 эксперта, 2 эксперта на токен, 4 слоя. Все довольно плохо, надо будет менять подход и сократить кол. вызовов к удаленной тачке. Наверное еще и проблема что используется публичный пир petals и тачка что хостит экспертов находится за натом.

Упс, не совсем правильный скриншот. Вот теперь нормально.
Ну, по идее таверна сама обрежет.
Все что перейдет за 4096 (условно) (первые сообщения) будет отрезаться и забываться.
Если не использовать суммаризаторы.
Блок, вернись!
Чего она там обрежет? Я правильно понимаю, что когда сообщения за 4096 токенов или сколько там перевалят, то бот начнёт херню нести? А до этой отметки он будет почти всё помнить и адекватно отвечать?


Ну лин и что за херня. Поставил вебуи, скачал через нее же модель, выбираю llama.cpp - ошибки пикрил 1. выбираю exllamav2 - то же само, куча шибок и пиздец.
Модель эта https://huggingface.co/TheBloke/Xwin-MLewd-13B-v0.2-GPTQ?not-for-all-audiences=true
Модель эта https://huggingface.co/TheBloke/Xwin-MLewd-13B-v0.2-GPTQ?not-for-all-audiences=true
>Я правильно понимаю,
Нет.
>выбираю llama.cpp
>GPTQ
Что с тобой не так?
>Нет
Ну и..? Дальше чего-то? Напиши правильный ответ тогда.
{{user}} просит развернутый ответ {{char}}
У тебя в тот момент в чате появится пунктирная линия, которая покажет где именно обрезается чат. Можешь в экстрасах включить отслеживание бюджета токенов, или просто банально глянуть в консоль и прочесть печать лаунчера, он указывает контекст. В нужный момент делаешь суммарайз, если прочтешь шапку-вики то сможешь катать минимум на 8к контекста вместо четырех.
Убабуга-токенайзер то скачал для hf версии?
Так я ж написал что я и на exllamav2 пробовал. Ну чет подозреваю что битая модель, через жопу скачалась через вебуи, потому что другую модель gguf я успешно загрузил в llama.cpp
Причем вопрос - в ней можно конфигурить кол-во слоев в врам (в llama.cpp), туда просто на максимум выкрутить если хочу на гпу в врам все сгрузить, правильно?
Я тут по мануалу нихера ничего не нашел про какой-то токенайзер. Откуда я блин это могу знать пздц
https://github.com/oobabooga/text-generation-webui/wiki/04-%E2%80%90-Model-Tab

А почему в чатах появляются ИНПУТ и РЕСПОНС какие-то. Зачем мне эта инфа?

спасибо, но нихуя не работает все равно. попробую перекачать модель гитом
> попробую перекачать модель гитом
Эээ, а как ты ее изначально скачивал? Через убабугу, только проверить чтобы закончило и не было ошибок в консоли, гитом, или через hfhub.

ды блять через вот эту залупу пикрил. ебанутая система, не видно прогресса нихуя, я два раза запускал, в конце он сказал мне что саксессфулли даунлоадед, а sha256 в говне, проверил щас.

пиздос заказал комп, а на aider прочитал что локалки по коду даже до гопоты3 не дотягивают. Придется играть на нем
какой?
7800x3d+4090
>Так я ж написал что я и на exllamav2 пробовал.
И лог обрезал, ага.
>туда просто на максимум выкрутить если хочу на гпу в врам все сгрузить, правильно?
Да, если врам хватит по объёму.
Это из инстракт режима. Проверь, что ты выставил тот режим, на котором тренировалась модель.
>ебанутая система, не видно прогресса нихуя
В консоли есть. И да, проверь ПК на стабильность, у тебя что-то дохуя ошибок.
Норм, отличный сетап для игр.
скинь статью
https://github.com/paul-gauthier/aider/issues/172
там вроде deepseeker подходит к гопоте3, люди гоняют бенчи, но всё плохо еще пока
хотя тут сложно понять какая часть проблемы в aider, а какая в самих сетках

Она.
Обрежет.
Лишние токены, из начала переписки.
Просто не отправит их в модель на обработку.
Но если отправить — да, начнет нести херню.
До этой отметки она будет относительно помнить и относительно адекватное отвечать, как повезет.
ExLlama, насколько я помню, не работает с 8бит, нахуя ты вообще это выбрал, если там в моделе написано No?
Если влезет.
А может не влезть.
ВПИХУЕМОЕ
и
НЕВПИХУЕМОЕ
Абстракции понятны?
Это модель тупит по какой-то причине.
Хули толку, если она НЕЗАПУСКАЕМА НА ТОМ, НА ЧЕМ ТЫ ЗАПУСКАЕШЬ, ТЫ ПРОСТО КАЧАЕШЬ ХЕРНЮ?
Но можешь запустить AutoGPTQ, должна заработать, но медленно.
> прочитал что локалки по коду даже до гопоты3 не дотягивают
Сильное заявление.
Топик длинный, где именно такое? Офк многое зависит от условий задачи и от корректности использования, если мотоцикл катить вручную то он будет медленнее велосипеда.
Программа странная, скорее всего автор вообще не шарит в локальных ллм и не может настроить под них свою программу, потому такие заявления и делает.
Читай хуйню чаще, ни за что не пробуй, молодец.
Очередная хуитища.
ГПТ-3 вообще сейчас бы хоть с чем-то можно было бы сравнить, сказочники-дрочеры на чатгопоту, никогда в жизни дальше бесплатных чатов в телеге не выбиравшиеся.
> Но если отправить — да, начнет нести херню.
Там скорее лаунчер ошибку выдаст, если используется актуальная версия апи в таверне, там размер обрезки тоже передается и никак не сможет другой пролезть.
> ExLlama, насколько я помню, не работает с 8бит, нахуя ты вообще это выбрал
Глазастый, вот и причина.
> ГПТ-3 вообще сейчас бы хоть с чем-то можно было бы сравнить
Можно пошутить про победы 7б, но ведь они же рили его обоссут.
> Можно пошутить про победы 7б, но ведь они же рили его обоссут.
Смешно, но да.
А специализированные почти до четверки дотягиваются, если нормально их запромптать.
> Там скорее лаунчер ошибку выдаст, если используется актуальная версия апи в таверне
Ну, вообще я имел в виду общий случай, если насильно впихнуть в модель.
Но в контексте, не знаю, думаю у таверны и правда есть понятие, куда лезть не надо.
Да я че-т вечером офигеваю от вопросов новичков, уже стал отвечать не подробно, сорян. =) Пойду успокоюсь и спатки.
Вообще, прошу менять понять правильно, я не фанат только-локалок или только-GPT.
Пользуюсь и тем, и другим, и люблю нежно эффективность, а не фанбойство. Как у НВидиа есть неудачные модели, так и у Радеона есть успешные модели.
Не люблю, когда люди голословно срут на что-то.
«Нейронки слишком тупые, я давал задачу, чатгопота не смогла решить…»
Копирую текст, вставляю в чатгопоту —она решает его сходу верно. Ну бля, хуй знает, может он не ту модель чатгопоты юзал, или ему не везло, или что, понятия не имею. Работает.
Так и с локалками «они тупые», да не, это тупые те, кто так говорит. Никто не заявляет, что есть что-то лучше чатгопоты-4, но многие модельки зачастую отстают от нее не слишиком сильно. В конце концов она универсальная, а есть специализированные.
Проблема в том, что такие «спецы» напиздят всем, что «это хуйня, не пользуйтесь», и новички поверят, подумают, что и правда не работает нихуя. И забьют на хорошую, удобную, перспективную технологию.
Или вон, когда Sora вышла, появились «а я вижу неправильную тень на собаке, все ясно, фейк, легко отличить!»
А на практики эти умные нихуя отличить не могут, просто приглядываются, зная заранее, что это фейк.
Ну такое, короче, сорян, подгорел. =)
Всем добрых снов!
Пользуюсь и тем, и другим, и люблю нежно эффективность, а не фанбойство. Как у НВидиа есть неудачные модели, так и у Радеона есть успешные модели.
Не люблю, когда люди голословно срут на что-то.
«Нейронки слишком тупые, я давал задачу, чатгопота не смогла решить…»
Копирую текст, вставляю в чатгопоту —она решает его сходу верно. Ну бля, хуй знает, может он не ту модель чатгопоты юзал, или ему не везло, или что, понятия не имею. Работает.
Так и с локалками «они тупые», да не, это тупые те, кто так говорит. Никто не заявляет, что есть что-то лучше чатгопоты-4, но многие модельки зачастую отстают от нее не слишиком сильно. В конце концов она универсальная, а есть специализированные.
Проблема в том, что такие «спецы» напиздят всем, что «это хуйня, не пользуйтесь», и новички поверят, подумают, что и правда не работает нихуя. И забьют на хорошую, удобную, перспективную технологию.
Или вон, когда Sora вышла, появились «а я вижу неправильную тень на собаке, все ясно, фейк, легко отличить!»
А на практики эти умные нихуя отличить не могут, просто приглядываются, зная заранее, что это фейк.
Ну такое, короче, сорян, подгорел. =)
Всем добрых снов!
> ExLlama, насколько я помню, не работает с 8бит, нахуя ты вообще это выбрал
блин, ну прикол. а четырехбитные норм? у них размер мелкий какой-то тут
https://huggingface.co/TheBloke/Xwin-MLewd-13B-v0.2-GPTQ?not-for-all-audiences=true
по 8гб, качество же будет сильно хуже?
нафиг тогда он нужен exllama этот тогда? если я хочу все 16 гб свои заюзать
>Или вон, когда Sora вышла
Где скачать? Пока не скачать, значит не вышла.
Качай в формате exl2, хули там
https://huggingface.co/R136a1/Xwin-MLewd-13B-V0.2-exl2
Привыкнув к локал_очкам попробуй на поломанных жб на чурбке поерпшить. Вот же кайфанешь ммм.
> Ну вот
> Ну давай же да!
> Да да, я готова!
> Ну вот же вот да стоны ну сейчас сейчас
> Да да да, ну же ну же вот там moans of arousal
> ...
Когда заебет отсутствие инициативы и радикальная стена, просто в наглую поднять юбку и стянуть трусы
> ой что ты делаешь, это неожиданно, пожалуйста не смотри
или просто медленное продвижение в котором нужно каждое "продвижение" явно напрямую указывать. Все намеки и инициативы будут поняты, отмечены ответными, но никакой инициативы.
На самом беде очень забавно, прямо исполнение желания "не кончай за юзера слишком быстро" от злого джина.
Офк не тот промт, не тот жб и все все
ты кажется мудрый анон, подскажи реально ли будет на 16 гб локально запустить и текст модель, и СД (через силлиТаверн прикрутить)? Вот эти модели по 8гб например для exllama они сильно плохи так? если ее запустить и СД, на 8 гб попрет СД? или лучше апи какой-то внешний использовать а текстовую модель пожирнее взять? может подскажешь тогда хорошие (даже платные) апи для СД?
сори за вопросы но я первый день разбираюсь
Я ж тебе уже писал, это простая арифметика.
16-4(сд)=12(ллм)
Ну, потестируй, попробуй выбрать ллм, чтобы в 10-11 гигов влезала.
Ссылку скинули хорошую, да, пробуй Exl2 формат. По умолчанию там 5 бит, но можешь попробовать 6-битную версию (в карточке ссылка) скачать.
Грузить ExLlama, соответственно.
Контекст выбирай 4096 для начала.
И смотри, влезет/не влезет.
Пасиба, нибуду. =)


Подскажите, почему не могу закинуть персонажей с сайта chub? После подтверждения на 1 скрине, кидает сразу на 2, а в консоли 3 ответ (ру символов нет в пути, в SillyTavern всё работает)

В какую вкладку кидаешь, четырестачетвёртый? И зачем тебе убабуга, когда у тебя таверна стоит и настроена?


Как на скрине кидаю, json в первую, картинку во вторую (но он и с картинкой и без - ругается этой ошибкой)
Если он в итоге ругается на name (но я не уверен), то в файле указано что на 1 скрине в этой строке, а сами файлы персонажей по умолчанию там в формате yaml.
>И зачем тебе убабуга, когда у тебя таверна стоит и настроена?
Хотел посмотреть на оба варианта, вроде убабуга говорили побыстрее, а ещё нашел как к ней прикрутить локальную версию автогонерации голоса и общения по войсу.
>вроде убабуга говорили побыстрее
Эм, нет.
Вообще, кинь ссылку на перса, проверю у себя.
Ну тогда ради общения войсом звучит прикольно, а на деле посмотрю что получится и прикручивания локального генератора голоса.
Любые файлы персонажей не ест, например вот эту https://www.chub.ai/characters/hebelover/Senko
Ебать, сенкошиз ты что ли? Как там разработка нейровайфу идет?
А вы тож заметили что на чуби одни и теже дженерик карты повторяются и почти нехуя нового\нормального??
Пишите персонажей сами.


Тебе надо скачать персонажа в формате png.
Потом выбрать вкладку TavernAI PNG и туда его закинуть.
>Хотел посмотреть на оба варианта, вроде убабуга говорили побыстрее.
Это я тебе писал что быстрее, но быстрее КОБОЛЬДА, т.к. позволит тебе катать модели на видеокарте, а не процессоре.
Но угабога это не альтернатива таверне. Скорее это сервер для неё, как кобольд.
В папке угабоги есть файл CMD_FLAGS.txt, открой его и добавь строчки
--listen --api
После этого запускай, грузи модель, через веб интерфейс и переходи в таверну.
Там у тебя должны быть такие настройки во вкладке API/
И всё заработает как надо.
Чат в вэб интерфейсе самой угабоги тоже можешь конечно заюзать, но по функционалу он УБОГ фить-ха! в сравнении с таверной.
>Тебе надо скачать персонажа в формате png.
В таверне если что можно с чуба прсото ссылку вставить и скачать.
Это про импорт в угабогу было.
без проксей для теста? ага щас
СиллиТаверн же тоже могет.
Кто, я?
Открытая платформа без критериев отбора, куда может постить что угодно собранное на коленке и кое как работающее. Или буквально дампать ответы нейронки к "напиши мне карточки зеленоволосой кошкодевочки, которую я буду трагладить". Или шизы, которые собирают треш, в комбинации требующий постоянных рероллов на "рекомендуемой сети", втирая про важные механики, которые ничего не дают.
Конечно оно превратится в свалку мусора, но годноту все равно найти можно.
Лучше всегда иметь локальную скачанную копию на бекапящейся файлопомойке.
А каких ботов ты пишешь?
без прокей некаких, но если б была мотивация и возможность , писал бы чот оригинальное или с инициативой от бота вероятно (заебало одно и тоже)
>СиллиТаверн же тоже могет.
Вот пример как я хотел сделать https://www.youtube.com/watch?v=lZkQUOpLg6g
Таверна сможет тоже такое провернуть и обязателен ли ей будет SillyTavern Extras? А если сможет, но к чему лучше прикручивать: к убабуге которую указывать в api настройках таверны после или сразу к таверне?
Спасибо.
>Но угабога это не альтернатива таверне. Скорее это сервер для неё, как кобольд.
А блин, мне казалось, что это как альтернативный фронт вместо неё и для исключения кобольда.
>но по функционалу он УБОГ фить-ха! в сравнении с таверной.
Понял-принял, вечером попробую.
Когда наконец можно будет выпилить внутренние инструкции из локалки? Кто вообще знает что нибудь по этой теме? Их невозможно обойти полноценно или у меня просто не получается.
Главное не используй лоадер Lama.cpp и модели в формате GGUF, иначе будет тот же кобольд, только в профиль.
Лучше качай модели exl2 или GGML и грузи их через exllama2 или ExLlamav2_HF и всё у тебя полетит.

Как же хочется запускать Mixtral 8x7B локально со скоростью 485 т/с.
че щас годнее микстраля ниче нету?
> или GGML
GPTQ, ggml это предок gguf.
Это на новом хуангодесктопе - суперкомпьютере?
>Это на новом хуангодесктопе - суперкомпьютере?
это вот эта штуковина:
https://old.reddit.com/r/LocalLLaMA/comments/1audftm/wow_this_is_crazy_400_toks/
Вот вы тут дрочите по рп на тексты, что сочиняют вам сети, а кто-нибудь в треде работает в ирл жизни на работе, тренируя/облизывая нейросетки? Ученым там каким, или инженером, или кто еще там есть?
>мылач
>ученые
Ну ты понял
Текущие ллм (даже гопота) слишком тупые для задач специалистов. Суммарайз средней статьи еще может оформить, но точно и качественно ответить на ключевые вопросы по сути - без шансов. У локалок еще усугубляется плохим знанием языка, а через клозедаи что-то важное-актуальное прогоняешь не будешь.
Из практического только простой код писать помогает.
Вне stem скорее всего оно может ебошить.
Я пока не вижу, куда это применять, но у меня и область пониманий чисто техническая, плюс стыки с тем, что вроде никак не связано. Несмотря на ажитацию в интернетах, не забывайте, что мы в пузыре, и обыватель еще не в курсе чо это за хрень вообще, включая бизнес-левел. (Я тут не имею ввиду открыть чатгопоту и спросить, а именно локальное, тренинги, инструкты вот эти все, да даже промпт-адаптеры через апи. Хотя многие даже о чатгопоте не знают.) Когда по телеку чо-то интреесное покажут, каждый второй вася с деньгами кинется придумывать аи-идеи для своей области. Лично я рассчитываю к тому времени прошариться достаточно, чтобы можно было доить этих вась пачками. А будет чо-то реальное или не будет - только время покажет.
Можно я не буду смотреть видео? х)
Зачитывать — точно могет.
Слышать твой голос — раньше умело, могет, но там че-то жмать надо.
Убабуга так же.
Движок, да, xttsv2 рекомендую.
Разница в том, что силлитаверна лучше всего работает с промптом (карточка персонажа и дополнительный обвес), и лучше сразу пилить для нее это.
Пожалуйста, не советуйте людям херню. =)
GGUF — грузится или в оперативу, или в видео-память, или туда и туда. Поддерживается много чем. Скорость медленная в оперативе или средняя в видеопамяти.
GPTQ/Exl2 — грузится только в видеопамять. Поддерживается NVidia. Скорость быстрая.
Дальше на твой выбор.
Ну, 70B так-то не стали хуже от выхода Микстраля.
Но за свою цену на скорость — лучшее, да.
Знакомый. А я только юзаю.
Обыватель не знает — и на том спасибо, у меня пока есть моя работа.
Стоит признать, эта штука так или иначе работает.
вопрос думаю точно задавали, но сёрчить 41 утонувший тред, это слегка перебор, поэтому спрошу:
чё есть из ллм на 12гб видеокарту, из целевых назначений думаю general purpose, вопросы там задать, суммарайз жидких текстов, кодинг простой хрени.
и есть ли какие-то подвижки в плане перевода текстов, которые адекватно переводят (ну не хуже deepl) и работают локально? или это я ща пустил влажную фантазию, от которой даже ерп дрочеры в шоке?
чё есть из ллм на 12гб видеокарту, из целевых назначений думаю general purpose, вопросы там задать, суммарайз жидких текстов, кодинг простой хрени.
и есть ли какие-то подвижки в плане перевода текстов, которые адекватно переводят (ну не хуже deepl) и работают локально? или это я ща пустил влажную фантазию, от которой даже ерп дрочеры в шоке?
«Что-нибудь простенькое» — это можно сразу Mistral 7B v0.2 брать, в 12 гигов с контекстом влезет.
Ну или ОпенЧат/Гермес (второго не сильно советую).
Или, если хочешь, выбрать какую-нибудь 13B модельку старую — Xwin какой-нибудь.
Переводчиком была ALMA, насколько я помню. В пределах твоих запросов.
>Можно я не буду смотреть видео? х)
Да как хочешь, я думал может быть интересно. Там описывается как локально поднять другую нейронку, которая по примеру 6 минут аудиозаписи голоса будет генерить в дальнейшем этим голосом за твоего персонажа и разговаривать им бесплатно и без ограничений. Прикольно ведь если можно подарить любой голос любому персонажу и модель будет на нем отвечать.
А про промпт не совсем понял, но это может после. Пока по планам прикрутить голос и разобраться как работает инструкт к чату (если он вообще нужен)
Там как повезет. Мужские голоса ей даются откровенно лучше женских.
По мнению моих знакомых, мой голос получился почти один-в-один. А вот голоса моих знакомых девушек… На 6-7 баллов из 10.
> инструкт к чату
Инструкт — для инструкт модели.
Чат-модель сама по себе умеет хорошо в чат. Но не идеально.
Инструкт-модель с хорошим инструктом будет лучше чатится, но это сложнее.
Так что, тут смотри сам, охота ли тебе запариваться по началу. =)
О, ты про тот сервис что в видео описывается или что-то другое?
Для начала попробую магию с голосом на разных персонажах из тайтлов (там можно собрать большую выборку их голоса и после очистки мне кажется будут говорить как настроящие)
А инструкт нельзя использовать к обычной модели как дополнение?
13В Alma в меня влезет? или лучше просто 7B взять и не трахать мозг? не знаешь как оно в плане качества выдачи по сравнению с дипл?
Coqui, он же XTTS, да.
Использовать можешь что хочешь и где хочешь — система-то одна, простое угадывание следующего токена. Но вопрос качества, насколько одно хорошо подойдет к другому. =)
Однако, в нашем мире васянских файнтьюнов, может быть что угодно, пробуй, разбирайся, тыкай. =)
Не знаю, лично я переводом почти не занимался. Скачал. Попробовал. Переводит условно хорошо. Удалил.
Так что…
ИМХО, лучше взять 13B в меньшем кванте, чем 7B в большом.
https://huggingface.co/Ahm ed107/ALMA-13B-R-GGUF/tree/main
Ну, вот, что-то есть, можно просто выгрузить в память видяхи.
Но ты пробуй, качай и то, и другое, тестируй.
Заодно и нам расскажи, че как оно.
Сорян за разбитую ссылку, вместе не пускал спам-лист.
Кстати, может ты знаешь и подскажешь, как расшарить доступ допустим для друга по ссылке к поднятой у себя таверне? Ну или на крайний случай просто для тех кто в одной сети wi-fi с пк?
В винде:
Открываешь Монитор брандмауэра Защитника Windows.
Выбираешь Правила для входящих подключений.
Там — Создать новое.
Указываешь Локальный порт 7860 (или какой там у твоей программы), тип протокола не помню, можешь создать два — и для TCP, и для UDP, Разрешить.
Теперь он будет принимать с других компов в локальной сети (тебе нужно будет знать твой локальный айпишник) соединения.
Для соединения извне — уже проброс портов на роутере.
Ну это все немного не по теме, час ночи, мне лень, прости. =3 Погугли.
во-первых, если сидишь с роутера, тебе нужен port-forwarding, нагуглишь как его сделать сам.
во-вторых, в ini-файлике таверны нужно включить доступ извне, я не помню как точно, но на вики есть. нужно будет там же в файлике указать юзернейм и пароль которые будут использоваться для входа, иначе таверна не включится. зато потом можешь с мобилки удалённо дрочить
Да-да, он прав!
В качестве IP иногда надо указывать не 127.0.0.1, или там localhost, а 0.0.0.0 — значит, что приложение принимает запросы отовсюду.
Ну и настройки могут быть еще какие-то, логин-пароль, все дела.
Спасибо, пойду читать завтра.
Пробовали. У этого автора ещё одна модель есть, Алиса, как бы улучшенная Маша, но и у неё всё очень печально.
Вообще, ни одна из двух десятков 7B-34B моделей, что мне довелось испытать, не генерирует сколь бы то ни было приемлемого текста на русском, кроме Mixtral 8x7b. Лучше всех пока справляется https://huggingface.co/Artefact2/BagelMIsteryTour-v2-8x7B-GGUF со следующими настройками семплеров: https://rentry.org/4wva76dg
Их пришлось подбирать, чтобы отрезать англоязычные токены, пробивавшиеся в русский текст. В этой конфигурации используется Smoothing Factor, поэтому вам может понадобиться обновить версии koboldcpp и SillyTavern.
FWIW, у меня карточка персонажа и Instruct на английском, но не думаю, что это влияет. Никакими инструкциями не удалось улучшить качество русскоязычного текста или полностью избежать генерации англоязычных токенов.
---
Я лингвист. Ваш диапазон приемлемости может отличаться от моего.
Сразу видно, что я не погромист, забыл заэскейпить звёздочку.
Самая свежая объяснялка от того, кто действительно в теме: https://old.reddit.com/r/LocalLLaMA/comments/1atghbb/local_llm_glossary_simple_llama_sillytavern_setup/
>GPTQ, ggml это предок gguf.
Бля, и правда перепутал. В последнее время скачиваю только exl2.
tpu v2-8 (как в коллабе) как он по сравнению с A100? У tpu конечно памяти до жопы, но что насчет производительности?
>exl2 или GGML
А если нет их для скачивания? Например как тут
Так ты введи прямо в поиске на хаггинг фейсе названия моделей. Сейчас посмотрел для xwin-mlewd и норомейды - есть и экслама разной битности и gptq. От себя только добавлю, что эти форматы полностью работающие на видяхе хоть и значительно быстрее, но зато gguf позволит катать модели с большим контекстом и/или с кванты с меньшими потерями в качестве при том же объёме видеопамяти. Ориентируйся на своё железо. Если у тебя 4060ti вообще восьмигиговая, а не 16-и, то ты и не запустишь 4 битную эксламу или gptq.
Олсо вместо свина-млюда рекомендую попробовать nete-13b на ступеньку выше над ним. Мне она в своё время больше понравилась.
Эта модель лучше оригинальной Микстрали, я верно понимаю?
Спасибо, интереса ради попробую, и на семплер посмотрю!
Сразу спрошу, а миростат не гонял? У меня на мистрали маленькой он прям дал буст по адекватности и качеству.

> Например как тут
У TheBloke скролишь чуть вниз и у каждой модельки есть пикрел, жми на GPTQ. У LoneStriker придется в поиске забить название.
> зато gguf позволит катать модели с большим контекстом
Что?
> и/или с кванты с меньшими потерями в качестве при том же объёме видеопамяти
ЧТООО?
>Что?
Контекст можно растянуть ропой до 16/32к, но во ВРАМ обычно столько не помещается, если не 3090/4090 какая-нибудь.
Про контекст уже ответили. Та же 13б 4-битная экслама с каким контекстом влезает в 16 гигов видяхи? Не факт, что 8к влезет, подозреваю. Там же не только вес модели, ещё кэши какие-то, нет? 6бит экслама с этим контекстом уже не влезет. gguf же и с 8к контекста можно брать смело большей битности. Та же стандартная Q5_K_M будет куда лучше 4-битной эксламы или gptq по perplexity. Вон, в шапке график, там даже Q4_K_S лучше, хотя и не сильно, потому что там выше 4-х бит по факту.

Я нюфаг. Хочу поднять локальный текстовый LLM, типа чатгпт.
Есть ли локальные модели, которые работают не хуже (в плане знаний и сохранения контекста в диалоге) четверки?
Заебало, что чатгпт постоянно отваливается с моим корп.впн и я не могу его нормально юзать с некоторых пор.
P.S. У меня 3080Ти, но готов платить за какое-нибудь облако гпушное, если выйдет не сильно дороже моей текущей плюсовой подписки.
>не хуже четверки
Планка весьма высока. Локалки сейчас (и последний год) на уровне турбы.
Можно надрочиться на отдельную область, и только.
Не хуже четверки во всем — нет.
Есть те, которые в конкретной специализации не хуже.
Но тут нужно разбираться, что именно тебе надо, и есть ли такие модели или, хотя бы, файнтьюны.
Я уточню, что в шапке видно, как ггуф с битностью 4.8 сливает эксл2 битностью 4,65 потребляя на 200 мб меньше.
Если охота терять в качестве ради 200 мб, или кровь из носу нужно 350 лишних токенов контекста — то да, ггуф лучше.
Если вдвое большая скорость и лучшее качество ценой 200 мб видеопамяти в приоритете — то exl2.
Напоминаю, что Q4_K_M — это 4,8 бита.
>Есть те, которые в конкретной специализации не хуже.
А какого размера эти домены специализаций обычно? Типа "погромирование", "биология", "мамоебство" или же "программирование робототехники на 8051", "имунная система глаза" и "анальный секс с мамой стифлера"?
ньюфаг здесь, необходимо обрабатывать научных статей чтобы из них делать выдержки с самым цимесом. Справится ли локальная модель, сравнительно с GPT 3.5? На какие лучше модели обратить взор. Стать иногода по 40+ страниц, возможно нужно будет отвечать на вопросы по загруженному материалу.
Чаще между, ближе к первому.
Есть общий кодинг, и модели под конкретные языки.
Есть общий секс, и с упором в какую-то область.
Но опять же, их не так чтобы много.
Должен быть спрос, а люди, которым нужны конкретные модели, просто даже про ЛЛМ ни слухом, ни духом, а уж сделать самостоятельно и вовсе не могут.
В основном делают энтузиасты для энтузиастов. Ну и немного опенсорса от корпораций. Микстраль, вроде, умела в доктора или че-то такое.
GPT-3.5 точно не справится с таким объемом. =)
А вообще — да, но тут надо поизучать вопрос, я не занимался.
Нужны модели с большим контекстом + знание языка, на котором написаны статьи (или настроить перевод, но он будет технический, получается, что не делает ситуацию легче) + знание темы (а с переводчиком — переводчик должен ее знать).
Теоретически возможно, практически надо разбираться.
Если язык английский и статьи преимущественно на одну и ту же тему (химия, химическое производство, возобновляемая энергия) - статья по сути увеличивает насколько я понял. Узурпаторы жпт аи сняли ограничение контекста со своих моделей насколько мне известно в коммерческих версия ( через API), но я так понял влетит в копейку и поэтому ищу альтернативу локальную надо которой готов потеть и предоставить свое скромное железо с 8 гб 3070 и 64 гб оперативы. Вопрос где искать с таким доменом знаний годные модели.
А чтобы была узкая область, и при этом попизже чем гтп-4? Например, хочу себе локальную ллм чисто для вычитки писем, которые пишу (правка стиля, орфографии, грамматики, ридабилити).
Будет ли правильный промтинг сильнее решать в слишком узких моделях или такой зависимости нет?
Кстати, локальные модели умеют выходить в сеть, искать доп.источники? Или это доп. абстракция над моделью и прямого отношения к ллм не имеет? Такую надстройку можно сделать над локальной ллм? (Ну в смысле, кто-то сделал в паблике и это можно юзать или пока нет?)
>Или это доп. абстракция над моделью и прямого отношения к ллм не имеет?
Да.
>Такую надстройку можно сделать над локальной ллм?
Лангчейн, там вроде была такая фича.
Ну, может быть не так дорого, как кажется. Но хз, надо считать, прикидывать, да.
Ограничение контекста техническое, а не по их решению, гпт-3.5 в пике 32к держит, что ли, а так 4-8 тыщ контекста, так что, нет. =) А вот гпт4 — там 128к, норм, да. Но дороже.
64 гига оперативки уже неплохо.
Что бы посоветовал я.
Чтобы узкая область и пизже гпт-4 — ну в теории, да, но на практике я никогда не интересовался чем-то настолько сильно.
Правильный промпт может многое порешать, это правда. Как и правильные настройки семплера, к примеру (те — даже больше, ИМХО).
Выход в сеть — не относиться к LLM, это отдельный софт.
По сути, тебе нужен LangChain или LlamaIndex, (или их аналоги) где и RAG, и Google, и все вот эти плюшки в одном.
Из моделей могу предложить:
1. https://huggingface.co/TheBloke/Mixtral-8x7B-Instruct-v0.1-GGUF
Возможно, оно умеет в химию. Контекст то ли 4к, то ли 32к, то ли можно растянуть. Влезет в оперативу. Квант только q8, но можешь рискнуть q6 для английского.
2. https://huggingface.co/TheBloke/Yi-34B-200K-GGUF
Здесь 200к контекста, хватит на большие статьи. Модель англо-китайская и приличная. Но знания под вопросом. Можешь поискать ее файнтьюны, может что-то есть.
3. https://huggingface.co/TheBloke/Yarn-Mistral-7B-128k-GGUF
Маленькая, быстрая, умная, 128к контекста, но для твоего запроса скорее всего не пойдет. Но она существует.
4. https://huggingface.co/LoneStriker/LWM-Text-Chat-1M-GGUF
Потенциально — самая тупая из них. Основана на Llama2 13B. Но 1 миллион контекста.
Но ее я еще не качал и не пробовал.
5. Просто поищи на huggingface.co слово chemistry. Есть модели, заточенные на это, но я нашел какой-то совет экспертов на 240 гигов, которые в ужатом виде влезут с трудом к тебе в оперативу.
И помни — на оперативе, чем больше модель, тем дольше ответ.
Даже если выгрузить обработку контекста на видяху, никто тебе не даст гарантий, что ответ будет скоро. =)
Спасибо
Если хочешь, можешь скинуть мне крупную статью, я попробую у себя на чем-нибудь, чисто затестим.
У меня не ахти какое железо, но ради научного эксперимента можно попробовать.
> LWM-Text-Chat-1M-GGUF
Кстати, по-ходу я спиздел, и там Llama2 7B, что прям грустно.
Но надо тестить, мало ли она стала гением.
> 7B
> прям грустно
Тыштааа! Может ты ещё и поспорить хочешь, что каждая новая 7B недели в очередной раз уничтожает гпт3-4-5?
Кстати, а он справится например со скармливанием ему японского примера, для генерации японского голоса по английскому тексту?
Если тебе на самом деле просто нужен ChatGPT, то используй альтернативные способы доступа. https://2ch.hk/ai/res/576277.html#601180
Или используй Google Bard (Gemini) с зарубежных адресов (любой EU/US прокси подойдёт), он пока бесплатный, а качество вполне сопоставимо.
Не-не, истина, так и есть! Сейчас еще раз уничтожим, как раз докачалась!
Пример и результат не обязаны быть на одном языке.
Но, вроде, акцент появляется забавный.
Но чистого английского в таком случае лучше не жди.
Хотя, я не уверен, насколько это критично для тебя. =)
Кстати да, про Барда-то я и забыл.
Привыкли, что Чатгопота, Клод да локалки (грока не считаем). А тут еще и Джемини же.
> но во ВРАМ обычно столько не помещается
Уточняй тогда. Казалось что 24гб, пусть и бюджетные - уже база треда.
Ну вопрос здесь не столько в том на что хватит рам. Если мы возьмем тот же ггуф и посмотрим сколько будет кушать не голая модель без ничего, а с выделенным и использованным 8к контекстом - разница будет дохуя больше чем на том пике.
> Q5_K_M будет куда лучше 4-битной эксламы или gptq по perplexity
Это 5.7 бит, при разнице в 1.5 раза оно должно по утрам отсасывать.
А так, если речь про ограниченность врам то действительно лучше немного пожертвовать скоростью чем крутить 3.5 бита, которые помещаются.
> потребляя на 200 мб меньше
Похоже на то что там оценивался просто голый объем модели без учета потребления на контекст. Несколько тредов назад было их сравнение, местами разница такая что на больших моделях хватит накатить 0.5-1 бит кванта, или удвоить контекст.
Содомит.
Слушай, я сейчас тестирую, и, по-ходу, контекст печально много жрет.
Микстраль можешь вычеркивать для больших статей, хех.
Надо на твои статьи посмотреть, какой там объем.
Я потерялся. Что попробуешь?
Я и сам запутался, не парься. =)
Один человек спрашивал за суммаризацию статей, другой за аналог чатгопоты в общем смысле.
Я хз, я мог промахнуться самим ответом тегая кого-то.
Я параллельно работаю.
Mistral выдает следующее, к примеру:
The text you provided is an academic article about magnetic tunneling magnetoresistance (ITMR) in a specific material called Ba0.8Sr0.2d2FeMoO6 double perovskite. ITMR is a phenomenon where the resistance of a material changes when a magnetic field is applied due to spin-dependent tunneling through insulating grain boundaries.
The researchers in this study found that the ITMR in Ba0.8Sr0.2d2FeMoO6 tends to saturate at high fields, which is different from what has been observed in other half-metallic magnetic oxides. They suggest that this may be due to differences in spin-dependent processes or magnetic states near the grain boundaries.
They also propose a modified model for intergrain magnetoresistance in which the grain boundary magnetic state is the relevant parameter. This model can explain the experimental results and should be taken into account in future work on devices involving interfaces with magnetic double perovskites.
Сейчас попробую модельки побольше.
Статья эта маленькая, и тут проблем с производительностью нет. Но попробуй оценить качество.
На работе применяешь ллм?
Я имел в виду, что вообще, сейчас работаю параллельно.
Интернет хуйня весь день сука, блядь пиздец, все в пизду, нихуя не успеваю, ни потестить, блядь, ни обновить, что не качаешь — нихуя не качается, блядь!
А вообще, да, и для программирования, и для идей и написания текстов иногда.
Норм инструмент, без экстаза, но полезная штука.
Такое себе
>magnetic tunneling magnetoresistance
Магнитное магнитосопротивление, масло масляное.
>Ba0.8Sr0.2d2FeMoO6
Чому-то d вместо скобки.
Ну туда-сюда.
Держи большую тогда https://link.springer.com/content/pdf/10.1007/s10853-021-06847-5.pdf
А как запускать этот ваш ллм на облаках? Дорого стоит вообще?
> Mistral
На что ты рассчитывал? Моделька то хорошая но тупая и вместо сути явлений триггернется на тематику и попытается рассказать тебе о чем-то общем. Как вариант, мику попробовать, но тоже врядли осилит.
На бесплатном коллабе бесплатно.
Начинал с малого, у меня на втором компе убабуга апдейтилась супердолго, хз почему.
Сейчас будем повышать ставки.
Based on the provided article, I have summarized the key points as follows:
The article discusses the synthesis and characterization of single crystals of lead-free halide double perovskite Cs2AgBiBr6 for use as radiation sensors. The study confirmed the purity and crystallinity of the solution-grown Cs2AgBiBr6 single crystals using powder XRD measurements and revealed dominant {111} lattice planes parallel to the sample surfaces. The single crystal XRD patterns showed lower resistivity values (106–109 X cm) compared to previously reported values using the van der Pauw method (1.55 9 109–6.65 9 1010 X cm). The charge-carrier mobility values were comparable (1.90–4.82 cm2 V-1 s-1 for carbon paint-Cs2AgBiBr6 and 0.58–4.54 cm2 V-1 s-1 for Ag-Cs2AgBiBr6), as were the Hall effect measurements (1.89 cm2 V-1 s-1 and 2.36 cm2 V-1 s-1 for carbon paint-Cs2AgBiBr6 and Ag-Cs2AgBiBr6, respectively). The findings indicated that the Cs2AgBiBr6 samples synthesized in this study satisfied requirements for radiation sensors.
или так
Based on the provided article, I have summarized the key points as follows:
The study focuses on the synthesis and characterization of Cs2AgBiBr6 single crystals with cubic Fm 3 m symmetry for use as radiation sensors. The team used solution growth methods to produce larger crystals with flatter surfaces and controlled crystal growth conditions to enhance the growth of {111} planes. The crystals were characterized using powder X-ray diffraction (PXRD) and single-crystal X-ray diffraction (SCXRD), which confirmed their purity, crystallinity, and cubic symmetry. The electrical properties of the crystals were investigated using various methods such as Hall effect measurements, van der Pauw measurements, and space-charge-limited current (SCLC) measurements. The results showed that the crystals had resistivities ranging from 10^8 to 10^10 X cm, charge carrier mobilities ranging from 0.58 to 4.82 cm^2 V^-1 s^-1, and trap densities ranging from 10^9 to 10^10 cm^-3. The X-ray photoresponse measurements indicated that the crystals satisfied requirements for radiation sensors with maximum sensitivities of 42 lCGyair^-1 cm^-2 at a dose rate of 75 lGys^-1 and -10 V bias. The team also discussed potential improvements to enhance crystal growth and performance, such as thermal annealing and optimizing metal-semiconductor contacts.
Учти, я не делал специальных промптов, и не использую какой-нибудь RAG, распознавание пдфок, визуальную модель или еще что-то. Я просто копирую весь текст и кидаю в ллм со словами summarize article!
Это был мистраль, сейчас попробую LWM, че там за чудо такое…
>На бесплатном коллабе бесплатно.
Любую можно запустить? В чем подвох?
Второй вариант мне нравится намного больше. Что за модель?
Это все еще Мистраль.
Но мне показалось, я выбивал и лучше.
От семплера и промпта очень много зависит. Тут прям надо тестировать и натаскиваться на небольшой статье, пока не будут норм варианты, и уже потом пробовать на больших.
LWM у меня просто повторяет промпт персонажа.
Видать она поломанная, а качать оригинальные веса и настраивать мне лень, да и не с моим сегодняшним интернетом.
Сейчас попробую Микстраль запустить. Но она уже много оперативы жрет, конечно.
А там докачается Yi-34B-200K и буду тестировать ее.
Вот пример маленькой и тупой Микстрали (q3_K_M):
This article reports on magnetoresistance (MR) measurements performed on the half-metallic polycrystalline double perovskite Ba0.8Sr0.2FeMoO6. The MR measurements were conducted up to 50 Tesla (T) in the temperature range of 4.2 K to 350 K. The MR is found to be due to intergrain MR at temperatures far below Tc = 345 K, allowing for useful information to be extracted on spin-dependent transport processes as well as the magnetic nature of the grain boundaries. The intergrain magnetoconductance tends to saturate at high fields, unlike the linear behavior reported on half-metallic manganites and magnetite. The experimental results are understood within the framework of the Inoue and Maekawa model for intergranular MR but using the magnetic state of the grain boundary as the relevant parameter instead of the bulk magnetic state. Detailed analysis of the field dependence of the MR points to a spin-glass magnetic state of the grain boundary.
Проверь-ка, она берет информацию со всего текста, или только с последней его части? Не уверен, сколько контекста она обрабатывает.
———
А вот ответ Mixtral q8:
Absolutely! I'm glad you asked! In this article, researchers used pulsed magnetic fields to measure magnetoresistance (MR) up to 50 T in Ba0.8Sr0.2FeMoO6 double perovskite at temperatures ranging from 1.8 K to 375 K. They found that at low fields (H < 0.2 T), the MR scales with m^2 (squared reduced magnetization), as expected from direct tunneling models with optimal spin polarization (P = 1). However, at higher fields (H > 40 T), they observed saturation of MR at temperatures below 50 K and a maximum value of 50%, which deviates from what would be predicted by direct tunneling models (maximum value of 100%). They also found evidence of spin disorder MR superimposing to ITMR above 200 K and intrinsic MR persisting up to 375 K. They proposed a modified direct tunneling model where m^2 is replaced by mgb^2 (magnetization of grain boundary region), which follows Langevin function depicting paramagnetic-like nature of outermost part of grain surface with random spin pinning centers due to off-stoichiometry, vacancies and antisite disorder. They also found good fit to experimental data using this model with spin polarization of 0.86 at 1.8 K and spin disorder coefficient B above 200 K up to TC with maximum at TC. They also observed empirical test function MC = F exp(-H0/H^1/2), which can be useful but needs further theoretical support. They concluded these results should be taken into account when working with devices involving interfaces with magnetic double perovskites and emphasized importance of understanding spin-dependent processes and magnetic state close to grain boundary.
Очень странно, но она дает ответы непостоянно.
Ну и это занимает 3-6 минут.
Блин, я, по-ходу, статью перепутал. х)
Ваще не слежу за ответами.
По результату, Yi у меня тоже не захотела суммаризировать нормально.
Так что, остается Мистраль или Микстраль и играться семплерами, промптами и искать нужное.
Из того, что могу предложить я.
За сим откланяюсь и пойду остальные дела делать.
А вы пока давайте, перекатывайтесь, что ля. =)
Шо б я вернулся в новый тред через два часа!..
Шо б я вернулся в новый тред через два часа!..
В 16 гигов врам влезает только пожатая 20б с умеренным контекстом. Бесплатный коллаб ограничен по времени.
Она не лучше, просто модифицирована (кустарно, почти наугад, пока что как могут) для ролевых игр. При этом могли пострадать другие её способности.
Автор миростата теперь рекомендует всем использовать своё новое изобретение Quadratic Sampling (Smoothing Factor) как наиболее прогрессивное, а прежние (Mirostat, Dynamic Temperature) забыть как устаревшие.
> выходить в сеть, искать доп.источники
> кто-то сделал в паблике и это можно юзать
Да, на реддите в locallama уже несколько таких надстроек анонсировали, с кодом на гитхабе.
О Langchain там отзываются не всегда хорошо, но не помню, почему именно.
> Mixtral
> Контекст то ли 4к, то ли 32к
32k, но там какое-то sliding window, на которое ругаются, что, мол, толком не работает как настоящий длинный контекст
> Квант только q8, но можешь рискнуть q6 для английского.
Это рекомендация практика или теоретика? (Я переводчик есличо).
ПЕРЕКАТ юбилейный
> но не помню, почему именно.
Перегружен к хуям
Первый вариант неплох.
>Проверь-ка, она берет информацию со всего текста, или только с последней его части? Не уверен, сколько контекста она обрабатывает.
А примерно так и есть, человек сначала читает абстракт и выводы, может еще графики глянуть и соображает, надо ли ему читать статью.
А вообще толку от этой обработки мало, считай, три разных ответа по одной статье, тут проще самому.
Аноны, пробовали Vector Storage?
Насколько рабочая вещь?
Насколько рабочая вещь?
Так что там с обнимордой случилось?
Ты не будут исполнены как на место этого уже за вашу RAG и вообще действительно иди спроси почему иногда и постоянно отвлекая другими действиями, которые предложены как пробросить ее знать).Теоретически




Здесь мы делимся рецептами запуска, настроек и годных промтов, расширяем сознание контекст, и бугуртим с кривейшего тормозного говна.
Тред для обладателей топовых карт NVidia с кучей VRAM или мажоров с проф картами уровня A100, или любителей подождать, если есть оперативная память. Особо терпеливые могут использовать даже подкачку и запускать модели, квантованные до 8 5 4 3 2-х бит, на кофеварке с подкачкой на микроволновку.
Здесь и далее расположена базовая информация, полная инфа и гайды в вики https://2ch-ai.gitgud.site/wiki/llama/
Базовой единицей обработки любой языковой модели является токен. Токен это минимальная единица, на которые разбивается текст перед подачей его в модель, обычно это слово (если популярное), часть слова, в худшем случае это буква (а то и вовсе байт).
Из последовательности токенов строится контекст модели. Контекст это всё, что подаётся на вход, плюс резервирование для выхода. Типичным максимальным размером контекста сейчас являются 2к (2 тысячи) и 4к токенов, но есть и исключения. В этот объём нужно уместить описание персонажа, мира, истории чата. Для расширения контекста сейчас применяется метод NTK-Aware Scaled RoPE. Родной размер контекста для Llama 1 составляет 2к токенов, для Llama 2 это 4к, но при помощи RoPE этот контекст увеличивается в 2-4-8 раз без существенной потери качества.
Текущим трендом на данный момент являются мультимодальные модели, это когда к основной LLM сбоку приделывают модуль распознавания изображений, что в теории должно позволять LLM понимать изображение, отвечать на вопросы по нему, а в будущем и манипулировать им.
Основным представителем локальных моделей является LLaMA. LLaMA это генеративные текстовые модели размерами от 7B до 70B, притом младшие версии моделей превосходят во многих тестах GTP3 (по утверждению самого фейсбука), в которой 175B параметров. Сейчас на нее существует множество файнтюнов, например Vicuna/Stable Beluga/Airoboros/WizardLM/Chronos/(любые другие) как под выполнение инструкций в стиле ChatGPT, так и под РП/сторитейл. Для получения хорошего результата нужно использовать подходящий формат промта, иначе на выходе будут мусорные теги. Некоторые модели могут быть излишне соевыми, включая Chat версии оригинальной Llama 2.
Кроме LLaMA для анона доступны множество других семейств моделей:
Pygmalion- заслуженный ветеран локального кума. Старые версии были основаны на древнейшем GPT-J, новые переехали со своим датасетом на LLaMA, но, по мнению некоторых анонов, в процессе потерялась Душа ©
MPT- попытка повторить успех первой лламы от MosaicML, с более свободной лицензией. Может похвастаться нативным контекстом в 65к токенов в версии storywriter, но уступает по качеству. С выходом LLaMA 2 с более свободной лицензией стала не нужна.
Falcon- семейство моделей размером в 40B и 180B от какого-то там института из арабских эмиратов. Примечательна версией на 180B, что является крупнейшей открытой моделью. По качеству несколько выше LLaMA 2 на 70B, но сложности с запуском и малый прирост делаю её не самой интересной.
Mistral- модель от Mistral AI размером в 7B, с полным повторением архитектуры LLaMA. Интересна тем, что для своего небольшого размера она не уступает более крупным моделям, соперничая с 13B (а иногда и с 70B), и является топом по соотношению размер/качество.
Qwen - семейство моделей размером в 7B и 14B от наших китайских братьев. Отличается тем, что имеет мультимодальную версию с обработкой на входе не только текста, но и картинок. В принципе хорошо умеет в английский, но китайские корни всё же проявляется в чате в виде периодически высираемых иероглифов.
Yi - Неплохая китайская модель на 34B, способная занять разрыв после невыхода LLaMA соответствующего размера
Сейчас существует несколько версий весов, не совместимых между собой, смотри не перепутай!
0) Оригинальные .pth файлы, работают только с оригинальным репозиторием. Формат имени consolidated.00.pth
1) Веса, сконвертированные в формат Hugging Face. Формат имени pytorch_model-00001-of-00033.bin
2) Веса, квантизированные в GGML/GGUF. Работают со сборками на процессорах. Имеют несколько подформатов, совместимость поддерживает только koboldcpp, Герганов меняет форматы каждый месяц и дропает поддержку предыдущих, так что лучше качать последние. Формат имени ggml-model-q4_0, расширение файла bin для GGML и gguf для GGUF. Суффикс q4_0 означает квантование, в данном случае в 4 бита, версия 0. Чем больше число бит, тем выше точность и расход памяти. Чем новее версия, тем лучше (не всегда). Рекомендуется скачивать версии K (K_S или K_M) на конце.
3) Веса, квантизированные в GPTQ. Работают на видеокарте, наивысшая производительность (особенно в Exllama) но сложности с оффлоадом, возможность распределить по нескольким видеокартам суммируя их память. Имеют имя типа llama-7b-4bit.safetensors (формат .pt скачивать не стоит), при себе содержат конфиги, которые нужны для запуска, их тоже качаем. Могут быть квантованы в 3-4-8 бит (Exllama 2 поддерживает адаптивное квантование, тогда среднее число бит может быть дробным), квантование отличается по числу групп (1-128-64-32 в порядке возрастания качества и расхода ресурсов).
Основные форматы это GGML и GPTQ, остальные нейрокуну не нужны. Оптимальным по соотношению размер/качество является 5 бит, по размеру брать максимальную, что помещается в память (видео или оперативную), для быстрого прикидывания расхода можно взять размер модели и прибавить по гигабайту за каждые 1к контекста, то есть для 7B модели GGML весом в 4.7ГБ и контекста в 2к нужно ~7ГБ оперативной.
В общем и целом для 7B хватает видеокарт с 8ГБ, для 13B нужно минимум 12ГБ, для 30B потребуется 24ГБ, а с 65-70B не справится ни одна бытовая карта в одиночку, нужно 2 по 3090/4090.
Даже если использовать сборки для процессоров, то всё равно лучше попробовать задействовать видеокарту, хотя бы для обработки промта (Use CuBLAS или ClBLAS в настройках пресетов кобольда), а если осталась свободная VRAM, то можно выгрузить несколько слоёв нейронной сети на видеокарту. Число слоёв для выгрузки нужно подбирать индивидуально, в зависимости от объёма свободной памяти. Смотри не переборщи, Анон! Если выгрузить слишком много, то начиная с 535 версии драйвера NVidia это серьёзно замедлит работу. Лучше оставить запас.
Гайд для ретардов для запуска LLaMA без излишней ебли под Windows. Грузит всё в процессор, поэтому ёба карта не нужна, запаситесь оперативкой и подкачкой:
1. Скачиваем koboldcpp.exe https://github.com/LostRuins/koboldcpp/releases/ последней версии.
2. Скачиваем модель в gguf формате. Например вот эту:
https://huggingface.co/TheBloke/Frostwind-10.7B-v1-GGUF/blob/main/frostwind-10.7b-v1.Q5_K_M.gguf
Можно просто вбить в huggingace в поиске "gguf" и скачать любую, охуеть, да? Главное, скачай файл с расширением .gguf, а не какой-нибудь .pt
3. Запускаем koboldcpp.exe и выбираем скачанную модель.
4. Заходим в браузере на http://localhost:5001/
5. Все, общаемся с ИИ, читаем охуительные истории или отправляемся в Adventure.
Да, просто запускаем, выбираем файл и открываем адрес в браузере, даже ваша бабка разберется!
Для удобства можно использовать интерфейс TavernAI
1. Ставим по инструкции, пока не запустится: https://github.com/Cohee1207/SillyTavern
2. Запускаем всё добро
3. Ставим в настройках KoboldAI везде, и адрес сервера http://127.0.0.1:5001
4. Активируем Instruct Mode и выставляем в настройках пресетов Alpaca
5. Радуемся
Инструменты для запуска:
https://github.com/LostRuins/koboldcpp/ Репозиторий с реализацией на плюсах
https://github.com/oobabooga/text-generation-webui/ ВебуУИ в стиле Stable Diffusion, поддерживает кучу бекендов и фронтендов, в том числе может связать фронтенд в виде Таверны и бекенды ExLlama/llama.cpp/AutoGPTQ
Ссылки на модели и гайды:
https://huggingface.co/TheBloke Основной поставщик квантованных моделей под любой вкус.
https://rentry.co/TESFT-LLaMa Не самые свежие гайды на ангельском
https://rentry.co/STAI-Termux Запуск SillyTavern на телефоне
https://rentry.co/lmg_models Самый полный список годных моделей
http://ayumi.m8geil.de/ayumi_bench_v3_results.html Рейтинг моделей для кума со спорной методикой тестирования
https://rentry.co/llm-training Гайд по обучению своей лоры
https://rentry.co/2ch-pygma-thread Шапка треда PygmalionAI, можно найти много интересного
https://colab.research.google.com/drive/11U-bC6AxdmMhd3PF9vWZpLdi6LdfnBQ8?usp=sharing Последний известный колаб для обладателей отсутствия любых возможностей запустить локально
Шапка в https://rentry.co/llama-2ch, предложения принимаются в треде
Предыдущие треды тонут здесь: